Bonjour à tous,
Ceci est mon premier message et je vous remercie par avance de votre indulgence. Depuis 10 ans maintenant, je gère avec excel des résultats de compétition de rugby (top14, champions cup, coupe du monde, tournoi des 6 nations) avec la diffusion de stats d’avant match (voici un exemple : Castres Olympique / Stade Rochelais (J21) (e-monsite.com). Aujourd’hui, je souhaite tout redévelopper sous python mais étant débutant, je souhaiterai avoir des conseils, des confirmations de votre part. Je compte utiliser une base SQLite et une interface Tkinter. Qu’en pensez-vous ? Merci par avance de vos réponses.
Bien à vous,
Dans un de mes derniers projets (pour un de mes cours), en voulant faire du tests unitaires j’ai importé une de mes classes pour y faire des tests unitaires, et en lançant un test unitaire basique j’ai eu l’erreur suivante :
Traceback (most recent call last):
File "....\flopbox\tests\test_auth.py", line 1, in <module>
from src.flopbox.authentification import FlopBoxAuth
ModuleNotFoundError: No module named 'src'
Je tourne sur Python 3.10.6, et pour le moment durant mes projets python, j’ai été confronté toujours à ce problème. J’ai écumé pas mal les forums sur ce souci, et le seul qui fonctionnait c’est de mettre des fichiers __init__.py à chaque profondeur de mon projet.
Sauf que pour ce projet, cette solution sans que je trouve comment régler.
J’ai lu qu’utiliser les fichiers __init__.py ne devraient pas se faire pour ma version Python d’installé mais je n’ai trouvé que ça qui ne fonctionnait.
Si quelqu’un pourrait m’expliquer plus en détail ce qui ne va pas pour que je ne fasse plus l’erreur à l’avenir, je serai ravie.
Dans ce cadre-ci la structure de mon projet était :
from src.flopbox.authentification import FlopBoxAuth
import unittest
class TestString(unittest.TestCase):
def test_should_capitalize_string(self):
string = "hello"
expected_value = "Hello"
self.assertEqual(string.capitalize(), expected_value)
if __name__ == "__main__":
unittest.main()
Sachant que j’ai ce problème peu importe où je souhaite placer le package tests et peu importe si j’ajoute les fichiers __init__.py ou non. Egalement là je ne crée pas d’instance de ma classe dans les fichiers tests mais en le faisant ou non dans mes essais pour régler ceci.
J’ai tenté de changer mon import mais cela me rendait une autre erreur ImportError: attempted relative import with no known parent package.
Je suis encore débutante dans l’utilisation de Python en mode projet, je suis ouverte à toute critique (mauvais termes, mauvaises utilisations, non-respect de certaines conventions) afin de m’améliorer.
On organise à Grenoble mardi 23 avril un Meetup pour aider à proposer des sujets de conférences et à répondre à des CFP. J’ai vu que le site du CFP pour la PyconFR 2024 est ouvert (PyConFR 2024) mais je n’ai pas trouvé d’indication sur la date limite pour proposer à un sujet de conférence. Cette date est-elle fixée ? (comme ça je pourrai la transmettre aux participants du meetup)
Pour les besoins d’un projet sur lequel je travaille actuellement, je dois accéder à des scanners pour numériser des documents depuis un script Python sur différentes plateformes (principalement Windows et macOS). Aujourd’hui je vais donc vous parler de la numérisation de document sous Windows via l’API WIA (Windows Image Acquisition) à l’aide de la bibliothèque pywin32.
Je partage ma trouvaille du jour ici, parce que je suis refait. J’ai appris par hasard qu’on pouvait mettre en cache les fichiers jinja compilés.
En deux mots, le comportement par défaut d’une application Flask est de compiler les templates jinja en bytecode python la première fois qu’ils sont rendus. Ils sont ensuite stockés dans un cache en mémoire.
Dans un contexte de « production » ça ne pose pas de problème, mais dans un contexte de tests unitaires, c’est autre chose.
Dans les projets sur lesquels je travaille, une application Flask est créée à chaque test unitaire. C’est bien souvent nécessaire pour pouvoir tester comment se comporte l’application face à différents paramètres de configuration par exemple. Dans cette situation, les templates sont compilés à chaque fois qu’ils sont utilisés par un test, ce qui fait qu’un même template peut être compilé de nombreuses fois dans une même suite de tests.
C’est là qu’interviennent les caches bytecode de jinja. En une seule opération (j’exagère à peine) on peut indiquer à jinja de mettre les templates compilés en cache quelque part sur le système de fichier. De sorte par exemple à ce qu’ils soient réutilisés entre chaque tests.
En raccourci ça donnerait quelque chose comme ça :
from jinja2 import FileSystemBytecodeCache
app = Flask(__name__)
app.jinja_env.bytecode_cache = FileSystemBytecodeCache("/tmp/foobar")
Et voici un exemple dans le monde réel, dans une suite de tests utilisant pytest :
J’ai mis en place ces quelques lignes dans 3 différents projets, à chaque fois le gain de performances était de l’ordre de 30%. En fonction des projets ça représente 10s à 45s de gain. Évidemment chaque projet est différent, et dans les cas dont je parle le rendu des templates était effectivement le goulot d’étranglement en terme de performances.
Je serais curieux de savoir si ça améliore aussi votre vie
La prochaine session de #PythonRennes aura lieu le jeudi 18 avril 2024 à 18h30 chez Zenika ( pour l’accueil) : Comment builder, packager un projet Python ? Comment le publier automatiquement sur PyPI Github Actions ?
Les données de Redis sont stockées en RAM. Si ce système permet de fournir des temps de réponse imbattables, le volume de données que vous pouvez stocker est limité et cela peut avoir des conséquences sur vos applications. Infogérance Redis Chez Bearstech nous infogérerons fréquemment des systèmes avec un service Redis, et de temps en temps, il arrive qu'un développeur nous alerte parce que son application ne fonctionne plus, et en y regardant de plus près, on constate qu'un client Redis échoue à insérer ou modifier une valeur avec le message : OOM command not allowed when used memory > 'maxmemory'
Est-ce que le service Redis est en rade ? Ce qui est sûr c'est que l'application ne fonctionne plus correctement. Du point de vue de l'infogéreur, Redis fonctionne bien : il répond à toutes les requêtes, mais l'application lui a fait dépasser un quota et elle ne peut plus ajouter de données. C'est un problème applicatif / métier. Si nous intervenons pour effacer les données avec FLUSHALL, cela va faire disparaître l'erreur, mais comment savoir si ces données peuvent être effacées sans conséquences ? L'application doit prendre le relais Redis est une base de données "clé-valeur" qui fonctionne en RAM, et pour qu'à chaque instant les données soient bien en RAM physique (et non swap), elle limite l'usage à un quota prédéfini (normalement au plus la moitié de la RAM physique disponible). Dans la vaste majorité des cas Redis est utilisé pour stocker des données qui peuvent être "perdues" (cache, sessions). Pour ce cas d'usage, le programmeur insère des données en précisant qu'elles peuvent "expirer"; mais il est possible de les déclarer "non-expirables". Pour les données marquées "expirables", Redis peut être autorisé à les effacer avant même leur date d'expiration si jamais il vient à manquer d'espace. C'est documenté, et un gestionnaire de cache ou de sessions ne voit aucun problème à ce qu'un élément disparaisse (même si dans le cas des sessions ceci a pour effet de déloguer un utilisateur). Donc tout va pour le mieux si ces 2 conditions sont respectées :
toutes les valeurs stockées dans Redis sont expirables Redis est configuré pour être autorisé à évincer des éléments même s'ils n'ont pas encore expiré
Expiration des données Pour le premier point, consultez votre framework/app favorite. C'est votre code et seulement lui qui décide de l'expirabilité intrinsèque de vos données, le serveur n'y est pour rien. Ce sera donc bien la première chose à vérifier et corriger avant d'aller voir côté serveur. Pour vérifier votre situation, sollicitez votre serveur Redis directement et demandez-lui le statut de vos DBs : # redis-cli info keyspace # Keyspace db0:keys=259,expires=0,avg_ttl=0
Là on a une situation potentiellement problématique, il n'y a aucun élément expirable (expires=0). Dans le cas très courant cache/session, la bonne situation s'afficherait ainsi : # redis-cli info keyspace # Keyspace db0:keys=259,expires=259,avg_ttl=30306971994
(note: avg_ttl est en millisecondes) A noter que la non-expiration des données peut être voulue : typiquement quand Redis est utilisé comme pubsub et/ou stockage de workqueue (cf. Sidekick, RQ, etc.). Dans ce cas il est alors fortement recommandé de ne pas utiliser le même serveur Redis pour les deux usages opposés - cache/session et pubsub - car ils reposent sur une politique incompatible de gestion de la limite mémoire. Politique d'évincement automatique Enfin vérifiez que Redis a une politique d'évincement des clés, dans 99% des cas c'est ce que vous voulez : # grep ^maxmemory-policy /etc/redis/redis.conf maxmemory-policy volatile-lru
Les politiques qui font l'affaire sont toutes valables, sauf noeviction qui se trouve être la valeur d'usine de Redis. Ainsi ce dernier choisit sagement de vous laissez décider si des données peuvent être automatiquement effacées. Nous pouvons vous accompagner si vous souhaitez obtenir des conseils d'optimisation avec Redis, ou bénéficier de nos audits de performance pour vos applications.
Pour fortifier son équipe, Yaal Coop recrute 1 développeur·euse, avec une tête bien faite plutôt qu'avec une tête bien pleine !
Culture organisationnelle
Nous pensons que pour des résultats excellents, il est essentiel de constituer une équipe aux compétences complémentaires, prenant soin d'elles-même et de ses clients : fiable, réactive, astucieuse, apprenante, communicante et bienveillante.
Vous rejoignez une jeune coopérative à l'organisation horizontale, composée de cinq associé·es salarié·es polyvant·es qui partagent leurs activités entre :
trois quarts du temps consacrés à la production (développement, design, support utilisateur, gestion de projet) selon les besoins des produits et les appétences de chacun
un quart du temps réservé à la gestion et la vie du collectif, la stratégie et le commerce, la communication, la veille et la formation
Nos produits
Nous travaillons principalement sur des projets web en python, autant sur le backend (Flask, Django, etc.) que sur le frontend (HTMX, Svelte, etc.) et le devops (Linux, Conteneurs lxc/lxd et Docker, CI/CD, Ansible).
Nous sommes très attachés à l'utilisation, la contribution et la production de logiciels libres.
TDD, pair-programming et agilité font partie de nos pratiques quotidiennes.
Nous privilégions des produits et les clients qui ont du sens et qui s'inscrivent dans nos valeurs. À titre d'exemple nous comptons actuellement parmi nos clients : Beta.gouv, Telecoop et l’Éducation Nationale.
Mais nous investissons également sur des projets internes pour créer et tester librement des outils auxquels nous croyons !
Recherche actuelle
Nous recherchons actuellement une personne au goût prononcé pour la programmation, le travail en équipe, capable de prendre des initiatives, et désirant produire un travail de qualité.
Les compétences techniques que nous recherchons en particulier sont la conception logicielle (de l'architecture au développement dirigé par les tests) et la maintenance logicielle (du support client, à la résolution de bug et documentation). Une pratique ou une appétence pour les technologies que nous utilisons ou d'autres complémentaires seront appréciées.
Rémunération et condition
Selon le profil et l'expérience, nous offrons un salaire compris dans une fourchette entre 30k€ et 45k€ brut annuel.
Au delà du salaire, nous nous efforçons de créer les conditions de réussite :
En équipe plutôt que seul·e ;
En collaboration plutôt qu'en subordination ;
Sur du matériel efficace plutôt que sur une machine premier prix ;
Dans un endroit convivial et bien situé (local proche de la gare et du tramway C, entièrement rénové, salle de repos) ;
En conjuguant professionnalisme et plaisir au travail ;
Avec de la flexibilité (1 à 2 jours de télétravail possibles par semaine) ;
Sur des projets qui ont du sens ;
Mutuelle famille prise en charge à 100% ;
Abonnement transports en commun et mobilité douce remboursé à 100% ;
Tickets restaurant, PC et téléphone portables, etc.
Coopération
Au bout d'un an de salariat, si l'envie se concrétise, nous vous proposerons de devenir associé·e avec, comme dans toute société coopérative, une part du capital et une voix par personne !
Rencontrons-nous ! contact@yaal.coop
16 rue des terres neuves, 33130 Bègles
Quelqu’un(e) a-t-il déjà fait cela avec ce module ?
Je l’installe ainsi :
$ pip3 install SpeechRecognition
Il faut aussi le module “pyAudio” :
$ pip3 install --user pyAudio
Et au final j’obtiens une erreur :
Collecting pyAudio
Using cached PyAudio-0.2.14.tar.gz (47 kB)
Installing build dependencies: started
Installing build dependencies: finished with status 'done'
Getting requirements to build wheel: started
Getting requirements to build wheel: finished with status 'done'
Preparing metadata (pyproject.toml): started
Preparing metadata (pyproject.toml): finished with status 'done'
Building wheels for collected packages: pyAudio
Building wheel for pyAudio (pyproject.toml): started
Building wheel for pyAudio (pyproject.toml): finished with status 'error'
Failed to build pyAudio
ed-with-error
× Building wheel for pyAudio (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [17 lines of output]
running bdist_wheel
running build
running build_py
creating build
creating build/lib.linux-x86_64-3.10
creating build/lib.linux-x86_64-3.10/pyaudio
copying src/pyaudio/__init__.py ->
build/lib.linux-x86_64-3.10/pyaudio
running build_ext
creating build/temp.linux-x86_64-3.10
creating build/temp.linux-x86_64-3.10/src
creating build/temp.linux-x86_64-3.10/src/pyaudio
x86_64-linux-gnu-gcc -Wno-unused-result -Wsign-compare -DNDEBUG
-g -fwrapv -O2 -Wall -g -fstack-protector-strong -Wformat
-Werror=format-security -g -fwrapv -O2 -fPIC -I/usr/local/include
-I/usr/include -I/usr/include/python3.10 -c src/pyaudio/device_api.c -o
build/temp.linux-x86_64-3.10/src/pyaudio/device_api.o
src/pyaudio/device_api.c:9:10: fatal error: portaudio.h: Aucun
fichier ou dossier de ce type
9 | #include "portaudio.h"
> ^~~~~~~~~~~~~
compilation terminated.
error: command '/usr/bin/x86_64-linux-gnu-gcc' failed with exit
code 1
[end of output]
note: This error originates from a subprocess, and is likely not a
problem with pip.
ERROR: Failed building wheel for pyAudio
ERROR: Could not build wheels for pyAudio, which is required to install
pyproject.toml-based projects
La librairie python PySimpleGui qui est une surcouche a TkInter proposait (et propose toujours) une approche plus simple pour la création d'interface graphique en Python.
Le mois dernier, son auteur a décidé de passer PySimpleGUI sous une licence propriétaire. Encore mieux, il a supprimer tout l'historique et le dépot github contient maintenant que des commits qui datent d'il y a un mois.
En vrai, on aurait du s'en douter en voyant que le fichier CONTRIBUTING.md du le projet explicitait qu'il refusait les contributions externes et que PySimpleGUI is different than most projects on GitHub. It is licensed using the "Open Source License" LGPL3. However, the coding and development of the project is not "open source".
Pour ma part, j'ai utilisé PySimpleGui sur un projet pour un de mes clients. J'ai pas mal aimé au début mais j'ai trouvé que la définition d'interfaces à base de listes imbriquées ne passaient pas trop à l'échelle. J'avais rapidement l'impression de faire du lisp.
Et le style "direct" (en opposition à la programmation événementielle) était là aussi plus simple au début mais devenait un vrai problème avec une interface complexe. Du coup je pensais pas y revenir, avec le changement de licence, c'est confirmé.
Marco 'Lubber' Wienkoop pour son travail sur Fomantic-UI, un chouette framework CSS que nous utilisons dans canaille. Fomantic-UI est aussi utilisé par d'autres outils sur lesquels nous comptons, comme Forgejo.
Hsiaoming Yang pour son travail sur authlib, une bibliothèque python d'authentification que nous utilisons dans canaille.
GitHub et GitLab ont adopté des normes de sécurité SSH plus récentes et plus robustes pour renforcer la sécurité des connexions.
En remplacement, GitHub a introduit les clés hôtes ECDSA et Ed25519, qui sont basées sur la cryptographie à courbe elliptique, offrant ainsi de meilleures caractéristiques de sécurité pour des augmentations modestes de taille et de calcul.
Aujourd’hui, on recommande l’utilisation de clés SSH ED25519, qui sont plus sécurisées et devraient être disponibles sur n’importe quel système. Bien sûr quand on parle de système Linux on est sûr qu’elles sont déjà présentes.
Il est essentiel de générer des paires de clés SSH sûres et de les configurer correctement. Par défaut une clé de 1024 bits est générée, il faut donc impérativement changer la taille de la clé par au minimum 4096 :
Avec pyxhook j’obtiens les focus clavier sur les icones du Bureau.
Je ne sais faire que des CTRL+C avec xdotool pour récupérer le texte
associé à l’icone (quelque chose comme ce qui correspond à “Exec=” d’un
fichier .desktop).
Je voudrais obtenir plutôt le libellé situé sous l’icone (par exemple
“Corbeille”).
Avec le module Xlib ça me paraît impossible.
J’y ai cru avec la méthode query_tree() mais c’est un échec.
Sauriez-vous comment lire le texte associé d’une icone quand le focus
clavier est dessus ?
Une idée serait est d’amener le pointeur de la souris dessus
automatiquement.
J’ai fait aussi https://youtu.be/Uf3Ong9VUPc une animation de python dans une atmosphère ‘spatiale’.
Ceci est peut être le début, d’une saga sur python. Du moins tant que ça m’amuse!
Après de gros coup dur portés au collectif d’organisation, l’événement sera maintenu cette année
Nouvelle date, nouveaux lieux!
week-end du 25-26 mai 2024
ENS Lyon (site René Descartes) au 19 allée de Fontenay, 69007 Lyon
Venez avec votre stand, donner un coup de main ou proposez un sujet ou un atelier!
Voici le mail transmis par l’orga:
Vous recevez ce mail, car vous avez participé à une précédente édition des Journées du Logiciel Libre. Dans notre dernier courriel, nous vous informions des difficultés que nous avons rencontrées puisque la Maison pour tous, qui hébergeait notre évènement depuis une dizaine d’années, a mis fin à notre partenariat.
Mais nous revenons vers vous aujourd’hui avec de très bonnes nouvelles ! Les Journées du Logiciel Libre 2024 ont trouvé un nouveau lieu d’accueil, c’est l’ENS Lyon (site René Descartes) au 19 allée de Fontenay, 69007 Lyon (Node: 3114775537 | OpenStreetMap). Merci à eux pour leur accueil, ainsi qu’à l’association AliENS sans qui rien n’aurait été possible. Toutefois, comme anticipé, cette édition n’aura pas lieu à la date initialement prévue, mais le week-end du 25-26 mai 2024.
L’appel à participation est d’ores et déjà ouvert et vous le retrouverez ici : Journées du Logiciel Libre 2024 :: pretalx. Celui restera ouvert jusqu’au 31 mars au plus tard, il ne vous reste donc plus que 3 semaines pour proposer des interventions. En parallèle nous avons aussi ouvert notre campagne de financement participatif que vous trouverez ici : Jdll 2024 - éducation populaire : enfin libre !. N’hésitez pas à partager ces liens dans vos réseaux.
Nous comptons sur vous pour que cette édition soit tout aussi formidable que les précédentes !
Plutôt cool de voir autant de Python dans le service public. Il y a un paquet de sous-dépendences en Python là dedans qui pourraient faire de bonnes nominations pour un prix BlueHat.
Éthi’Kdo est une fintech de l’Économie Sociale et Solidaire fondée en 2019, dont la mission est de favoriser une consommation plus respectueuse des êtres humains et de l’environnement.
Pour servir cette mission et faire (re)découvrir la transition écologique 3 supports dont :
Ethi’Kdo - Première carte cadeau française des enseignes 100% éthiques et solidaires
Kadoresto - Première solution de bons et coffrets cadeaux pour les restaurants engagés
EthiK’avantages – Plateforme SAAS de réductions exclusives auprès d’enseignes web et physiques éco-responsables
En cohérence avec ses principes coopératifs, éthi’Kdo est administré par ses salariés, ses enseignes et assos partenaires et l’ensemble de son écosystème.
Ethi’Kdo est agréé d’Utilité Sociale depuis 2019, figure depuis 2021 dans le Top 50 de l’entrepreneuriat à impact, est double lauréat des Trophées de l’Economie Sociale et Solidaire et a intégré le collectif des Licoornes en 2023.
En tant que tech lead, vous serez responsable de la vision technologique, du management de l’équipe technique et de la mise en œuvre des solutions technologiques nécessaires pour atteindre les objectifs de l’entreprise.
Vous reporterez directement au CEO et managerez une équipe de 3 développeurs (code et no-code). Le CTO historique d’éthi’Kdo se rendra disponible pour vous conseiller et vous accompagner dans la découverte du stack technique.
Le rôle peut évoluer en fonction de la croissance de l’entreprise et de ses besoins spécifiques.
Les principales missions sont :
1. Définition de la stratégie technologique :
Collaborer avec le CEO et les autres dirigeants pour définir les choix technologiques et techniques de la coopérative, alignés sur les objectifs globaux.
2. Amélioration continue :
Garantir le bon fonctionnement, la disponibilité et la performance de l’environnement technique (applications web, bases de données, hébergements, automatisations…) dans une démarche d’amélioration continue. Le refactoring et la remise en question de l’existant sont les bienvenus.
3. Développement :
Superviser et contribuer activement au développement de nouvelles fonctionnalités, de l’écoute du besoin à la mise en œuvre, en proposant une ou plusieurs approches techniques et en garantissant la qualité des fonctionnalités livrées (réponse au besoin, tests automatisés, lisibilité du code, performance).
4. Direction de l’équipe technique :
Recruter, former et diriger une équipe technique, en s’assurant que les membres sont motivés et alignés sur la vision de l’entreprise, tout en apportant conseil et expertise pour favoriser leur épanouissement professionnel.
5. Veille technologique :
Se tenir à jour des tendances et des avancées technologiques pertinentes pour notre activité et s’assurer que l’entreprise reste à la page sur le plan technologique.
6. Sécurité informatique :
Mettre en place des protocoles et des politiques de sécurité robustes pour protéger les données et les systèmes de l’entreprise.
7. Collaboration interdépartementale :
Travailler en étroite collaboration avec d’autres départements tels que les partenariats, la communication, les ventes et la finance pour comprendre leurs besoins technologiques et les aider à atteindre leurs objectifs.
8. Gestion du budget technologique :
Élaborer et gérer le budget lié aux activités technologiques, en veillant à une utilisation efficace des ressources.
9. Participation à la planification stratégique :
Participer aux discussions stratégiques avec l’équipe de direction pour intégrer la vision technologique dans la planification globale de l’entreprise.
10. Innovation et recherche :
Encourager l’innovation au sein de l’entreprise et promouvoir la recherche de solutions novatrices.
11. Création et gestion de la documentation technique :
Mettre en place et s’assurer des mises à jour de la documentation technique afin d’assurer la maintenabilité et la pérennité de l’existant et des nouveautés.
12. Gestion des relations avec les fournisseurs :
Collaborer avec les fournisseurs de services technologiques externes pour s’assurer que l’entreprise dispose des outils nécessaires à son fonctionnement.
13. Résolution de problèmes techniques :
Intervenir pour résoudre les problèmes techniques complexes et guider l’équipe dans la résolution des défis rencontrés.
Profil recherché
Compétences recherchées
Vous avez une expérience de développeur full stack d’au moins 5 ans, et avez travaillé dans plusieurs contextes différents.
Vous avez acquis des compétences en gestion de projet et en résolutions de problèmes techniques.
Vous aimez le travail bien fait, le code bien écrit.
Vous avez une appétence pour le management d’équipes.
Compétences techniques :
Vous disposez d’une réelle expertise et d’expériences significatives sur les technologies suivantes :
Django (et donc, Python)
Web (HTML / CSS / JS)
Vous disposez éventuellement de compétences additionnelles pertinentes :
No-code (Zapier, AirTable, Softr, Wordpress, …)
Devops
UX design
Data science
etc…
Salaire et conditions de travail
Entre 40k€ et 50k€ selon profil et expériences
Mutuelle (Alan) prise en charge à 100%
Temps partiel possible (pour passer du temps avec ses enfants, développer des projets associatifs ou tout autre élément permettant un équilibre vie pro-vie perso)
Equipe jeune et dynamique avec forte cohésion d’équipe,
Bureaux au sein de l’espace de co-working du Village Reille, un ancien couvent en plein cœur du 14e arrondissement.
Télétravail possible.
Process de recrutement
Court appel avec Laure-Hélène, chargée de missions et office manager
Entretien en visio avec Antonin, CTO actuel d’éthi’Kdo
Entretien en présentiel avec Séverin, CEO et co-fondateur dans les locaux au 11, impasse Reille 75 014 PARIS
Pour candidater : envoyez un mail à bonjour@ethikdo.co avec pour objet “CDI - Tech”
Nous organisons un meetup en mixité choisie le jeudi 14 mars.
Vous êtes bienvenue si vous vous reconnaissez dans le genre féminin ou êtes une personne non-binaire.
Pour ce meetup, nous sommes accueillies par Hashbang (métro Brotteaux).
Au programme de cette session :
Si tu n’es pas designer, tu ne changes pas la couleur : une introduction à Wagtail par Pauline
Cher nal, récemment je ré-étudiais pour la n-ième fois le problème de concevoir des schémas simplement par un langage de description graphique (je n'aime pas les éditeurs visuels) avec potentiellement une partie générée procéduralement, pour faciliter certaines constructions. J'avoue que je suis plutôt du style « à l'ancienne », donc j'ai regardé le classique tikz (vraiment trop ésotérique quand on n'est pas un habitué du Latex), xfig (j'aime bien les vieilles interfaces, mais là bof), dia (que j'ai utilisé à ses débuts, mais ici trop spécifique aux diagrammes), mais aucun ne me convenait.
Comme le média de destination de ces schémas est le Web, j'ai essayé de regarder directement le format vectoriel standard pour celui-ci : Scalable Vector Graphics, ou SVG. Je l'ai souvent vu comme un format plutôt « bas-niveau », uniquement destiné à être le format final issu de sources plus « haut-niveau ». Mais j'ai eu une expérience il y a quelques années d'écriture directe de SVG qui retranscrivait une courbe de Bézier qui m'a bien plu, au point que je me suis dit que je devrais le regarder de plus près pour voir si ça ne serait pas possible d'écrire du SVG directement pour mon besoin.
Je me suis alors penché sur la très bonne documentation de Mozilla sur SVG et ça m'a permis de me mettre le pieds à l'étrier. J'ai d'abord trouvé un petit projet d'exemple de dessiner un minuteur, avec des formes pas trop compliquée : un cercle, quelques segments, etc. Et finalement, j'ai été supris par la simplicité d'écrire directement du SVG. Mais très vite j'ai eu besoin de générer une partie de ce SVG « procéduralement » (avec des constructions de répétition propres à un langage de programmation).
Comme vous le savez, SVG est basé sur XML, la technologie des années 20001 par excellence : un langage de balisage issu de HTML et SGML qui respecte un ensemble de règles bien définies, comme le fait d'être une structure arborescente. J'ai l'habitude de travailler sur du XML avec XSLT, un langage de transformation que je trouve super utile, même si sa syntaxe horripile tout le monde, moi y compris à certains moments. J'ai essayé d'imaginer comment faire ce que je voulais avec, mais l'orientation algorithmique du problème (générer 60 marques, dont une marque plus grosse toutes les cinq marques) commençait à me faire peur, vu les limitations du langage2.
J'ai alors pensé à une vieille connaissance que j'avais utilisé il y a deux décennies, à la grande époque de Python comme langage révolutionnaire pour le Web (au début des années 20000 ; ce qui a un peu foiré) : Zope. Pas pour tout le framework ORM qui l'accompagnait, mais pour son langage de templating (patronnage ça fait bizarre en français)TAL, qui respecte les principes de XML jusqu'au bout : le langage de template n'est pas invasif et respecte la structure du document (qui reste donc un fichier XML valide) contrairement à de nombreux moteurs de template modernes qui utilisent des syntaxes qui se superposent mal à XML ; il utilise avantageusement un namespace séparé pour ne pas rendre invalide le document ; il est basé sur Python, qui est le langage que je visais tout à fait pour l'écriture de la partie procédurale.
Seul problème : je veux TAL, mais je ne veux pas le reste de Zope. Et de toutes façons, Zope n'est plus disponible sur Debian depuis des lustres. Je regarde alors les alternatives, qui sont listées sur Wikipédia.
Je vois tout d'abord Simple TAL, qui semble répondre à mes besoins : pas de dépendance, simple, stable, etc. J'essaye, et ça marche plutôt bien : ça fait étrange de retrouver la syntaxe verbeuse de TAL, mais j'aime bien, même si la gestion d'erreur très rudimentaire fait que je me retrouve parfois avec des bouts de message d'erreurs mélangés à mon contenu… Bof bof, mais ça peut passer pour des petits travaux. Ça donne ça :
<svgxmlns="http://www.w3.org/2000/svg"version="1.1"width="200"height="200"><gid="minutes"z="1"><circlecx="100"cy="5"r="2"tal:repeat="angle python:[i*6 for i in range(60) if i%5]"tal:attributes="transform string:rotate(${angle}, 100, 100)"/></g><gid="fives"z="1"><rectx="98.5"y="0"width="3"height="10"tal:repeat="angle python:[i*30 for i in range(12)]"tal:attributes="transform string:rotate(${angle}, 100, 100)"/></g><gid="slice"tal:define="timeangle python:int(path('time'))*6"><!-- XXX fix z --><!-- XXX if angle is more than 180, 4th and 5th args to A have to change --><pathfill="red"z="0"tal:define=" timesegx python:100-95*math.sin(path('timeangle')/360*2*math.pi); timesegy python:100-95*math.cos(path('timeangle')/360*2*math.pi)"tal:attributes="d string:M 100 5 L 100 100 L ${timesegx} ${timesegy} A 95 95 0 0 1 100 5 Z"/><rectx="98.5"y="5"width="3"height="95"/><rectx="98.5"y="5"width="3"height="95"tal:define="angle python:-path('timeangle')"tal:attributes="transform string:rotate(${angle}, 100, 100)"/></g></svg>
Mais quelques semaines après, pour une seconde utilisation, je trouve cette approche pas encore assez à mon goût. Cette fois-ci, je veux reprendre un SVG existant, et le « génériciser ». Ce fichier c'est une représentation des flottants en informatique https://en.wikipedia.org/wiki/File:IEEE_754_Double_Floating_Point_Format.svg
Je reprends la liste des alternatives ZPT, et je regarde de plus près Chameleon (disponible sur Debian avec le package python3-chameleon) : le projet semble lié à Pyramid, un framework Web que j'aime beaucoup et que j'ai utilisé il y a dix ans, basé sur des idées vraiment bonnes selon moi (allez voir ce que font les mecs du projet Pylons pour avoir une meilleure idée). Par exemple, il parse la template en bytecode Python directement, pour éviter le jonglage avec des traductions intermédiaires de source, ça me semble bien. Il est fourni uniquement sous forme de bibliothèque, pour faciliter son intégration3.
Du coup, après avoir passé au départ un gros temps de nettoyage du SVG généré par Inkscape, je commence à tester, et ça marche vraiment bien : assez vite, j'utilise le fait que le type d'expression par défaut est Python, et non les chemins d'objet ZPT (qui sont bien adaptés pour l'ORM de Zope, mais moins quand on a un code Python simple à 100%), ce qui simplifie beaucoup le code. Puis je remplace les très XML-èsque tal:attributes (qui me rappellent les xsl:attribute) par l'utilisation de l'insertion de texte directe sur des attributs, qui sont donc littéralement écrits avec comme valeur une expression utilisant la syntaxe ${…}, issue de Genshi. Elle remplacera même plus tard même les tal:replace ou tal:content pour les contenus d'élément texte. Certes, on se rapproche ainsi plus des moteurs de template classiques, mais ça ne casse au moins pas la structure, qui serait plus amochée si je n'utilisais pas les tal:repeat, ou la définition de variables utiles avec tal:define.
J'ai au début uniquement programmé la répétition des barres de l'image, puis des points sous la barre. Puis je suis allé encore plus loin pour ce cas précis de flottant en informatique, en généricisant pour n'importe quelle taille d'exposant ou de fraction. Enfin j'ai rendu dynamique le positionnement du texte au-dessus, ce qui me permet au passage de le passer en français. Et au final, ça donne ça :
<?xml version="1.0" encoding="UTF-8"?><!-- This work is adapted from "IEEE 754 Double Floating Point Format" <https://commons.wikimedia.org/wiki/File:IEEE_754_Double_Floating_Point_Format.svg> by Codekaizen <https://commons.wikimedia.org/wiki/User:Codekaizen>, used under CC BY SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0/>. This work is licenced under CC BY SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0/> by Benjamin Cama <benoar@dolka.fr>. Date: 2024-02--><!--! Parameters: exponent: The float’s exponent size, in bits. fraction: The float’s fraction size, in bits.--><?pythondef nbars(n): "Size of `n` bars." return n * 9?><svgxmlns="http://www.w3.org/2000/svg"xmlns:tal="http://xml.zope.org/namespaces/tal"tal:define="exponent int(exponent); fraction int(fraction); start 28"width="${ start + nbars(1 + exponent + fraction + 1) }"height="100"><defs><rectid="bar"width="${nbars(1)}"height="28"/></defs><style>
#bar { stroke: black; }
.above { stroke: black; fill: none; }
text { font-size: 12px; text-align: center; text-anchor: middle; font-family: sans }
circle { stroke: black; fill: black; fill-opacity: 0.25; }
</style><g><!-- bars --><usehref="#bar"tal:repeat="i range(1)"style="fill:#d5ffff"x="${ start + nbars(i) }"y="44"/><usehref="#bar"tal:repeat="i range(1, 1+exponent)"style="fill:#a4ffb4"x="${ start + nbars(i) }"y="44"/><usehref="#bar"tal:repeat="i range(1+exponent, 1+exponent+fraction)"style="fill:#ffb2b4"x="${ start + nbars(i) }"y="44"/><!-- sign --><gtal:define="x start + nbars(0 + 1/2)"><textstyle="text-anchor: end"><tspanx="${ x + 2 }"y="25">signe</tspan></text><pathclass="above"d="M ${x},31.5 L ${x},41.5"/></g><!-- exponent --><texttal:define="x start + nbars(1 + exponent/2)"><tspanx="${x}"y="12.5">exposant</tspan><tspanx="${x}"y="25">(${exponent} bits)</tspan></text><pathtal:define="x1 start + nbars(1); x2 start + nbars(1 + exponent)"class="above"d="M ${x2-1},41.5 L ${x2-1},31.5 L ${x1},31.5 L ${x1},41.5"/><!-- fraction --><texttal:define="x start + nbars(1 + exponent + fraction/2)"><tspanx="${x}"y="12.5">fraction</tspan><tspanx="${x}"y="25">(${fraction} bits)</tspan></text><pathtal:define="x1 start + nbars(1 + exponent); x2 start + nbars(1 + exponent + fraction)"class="above"d="M ${x2},41.5 L ${x2},31.5 L ${x1+1},31.5 L ${x1+1},41.5"/><!-- bit dots --><gtal:repeat="b (0, fraction, fraction+exponent)"><gtal:omit-tag=""tal:define="x start + nbars(1/2+exponent+fraction - b)"><circlecx="${x}"cy="79"r="3.7"/><textx="${x}"y="93">${b}</text></g></g></g></svg>
Et je suis vraiment content du résultat. C'est plutôt propre, relativement conforme à ce qu'on attend d'un XML, au point où j'imagine même une chaîne de traitement qui pourrait combiner TAL et XSLT ! Ah, et pour voir le résultat, sur un double par exemple :
Le seul bémol par rapport à la « standardicité » de ce template utilisant TAL, c'est que Chameleon ré-utilise l'espace de nommage (namespace) original de Zope alors qu'ils ont en fait étendu le dialecte pour l'insertion directe par exemple, ou le fait que les expressions soient en Python par défaut (il y a d'autres nouveautés également). Dans un soucis de compatibilité ascendante, idéalement, ils auraient dû définir un nouveau namespace pour ces extensions4.
Mais justement, rien que le fait d'utiliser un namespace pour intégrer de la « procéduralité » dans un SVG va permettre de montrer une possibilité géniale de XML : de pouvoir être une structure de données mélangeant divers aspects de manière non-intrusive (ou orthogonale), ce qui permet par exemple dans notre cas de modifier le SVG avec Inkscape par exemple, et de continuer à obtenir un template valide ! Ça fonctionne moyennement avec le template ci-dessus, car le dessin ne ressemble à rien vu que par exemple les coordonnées des objets n'ont pas de valeur correcte : on utilise l'insertion directe avec des ${x} par exemple, qui n'est pas une coordonnée valide. C'est pour ce cas où rester avec la syntaxe strictement XML d'origine de TAL peut être utile : ces attributs auront une valeur qui est utile pour présenter ce dessin dans un logiciel d'édition de SVG comme Inkscape, mais seront remplacés lors de l'instanciation du template par TAL ! Essayez avec cette version du dessin, vous verrez que le template continue d'être utilisable et applique les modifications que vous y avez effectué.
Et ça c'est la puissance de XML qui n'a malheureusement jamais été beaucoup développée : pouvoir intégrer plusieurs dialectes ou formats (avec son propre namespace) au sein d'un même fichier pour qu'il soit « multiforme ». J'avais il y a quelques années ainsi intégré une extension à un diagramme à état en SCXML qui me permettait de travailler sur un aspect orthogonal au diagramme, en utilisant au passage un namespace que j'avais créé pour l'occasion en utilisant les Tag URI. Vous voyez d'ailleurs qu'Inkscape intègre lui-même ses propres données au fichier SVG standard à travers le namespace souvent préfixé « sodipodi » (le nom d'origine du projet) pour y stocker ses paramètres. Dans un autre contexte, RDFa est une manière d'étendre le HTML pour faire du RDF, en trouvant un entre-deux n'utilisant que des attributs préfixés et non pas des éléments spécifiques, afin de concilier le divorce du HTML moderne avec XML (mais faites du XHTML5 même s'il n'a pas de schéma !).
Bref, j'espère que ce journal t'auras un peu réconcilié avec XML, et puis donné envie de lier Python et XML pour ton prochain projet. Tu trouveras tous les fichiers de mon expérimentation ici : http://dolka.fr/bazar/tal-svg-experiment/
j'ai toujours trouvé ça étrange mais quand on dit « les années XXXX », on parle de la dizaine d'année qui commence par l'année citée ; dans notre cas, les années 2000--2010. ↩
en fait, XSLT n'est vraiment pas fait pour de la génération procédurale, mais pour du traitement de données en flux. Il est idéal pour transformer un document en un autre, mais laissez tomber dès que la part de calcul devient trop importante. À la limite, vous pouvez partir d'un programme dans un langage classique pour la partie calcul, et sortir un document « de base » – en utilisant même des printf() à la barbare avec une structure simple – à transformer plus aval par XSLT. Mais n'essayez pas de tout faire en XSLT. ↩
du coup Chameleon étant une bibliothèque seulement, j'ai créé un petit outil talproc pour traiter les templates TAL. Il s'utilise à la manière de xsltproc avec les paramètres du template passés en --stringparam. Par exemple, pour générer le fichier du flottant double précision : talproc --stringparam exponent 11 --stringparam fraction 52 IEEE_754_Floating_Point_Format-direct-template.svg ↩
We’re currently running a Call for Contributors for the conference in 2024.
We published a short blog post last week explaining how anyone in the community can get involved either by joining one of the core teams, helping with reviewing the proposals or mentoring the speakers.
The deadline for the Team Members form is today, but the other form (for Reviewers and Mentors) will stay open.
We would be really happy if French community members would like to join us with shaping the conference this year, and if you have any questions I’m happy to answer them
bat permet d’afficher le contenu d’un fichier en activant la coloration syntaxique par défaut. bat permet aussi de changer le thème (DarkNeon dans les captures d’écran suivant) ou les informations affichées.
Avec le code Python suivant contenu dans un fichier nommé futilite.py :
L’ensemble des décorations possibles est affiché avec le paramètre full.
bat futilite.py --style="full"
Au contraire, la version sans décoration (et donc celle qui est le plus proche du comportement de cat) s’obtient avec le style plain. C’est aussi équivalent à l’utilisation de pygmentize avec un alias (cf. un article précédent).
bat futilite.py --style="plain"
Plusieurs blocs sont activables ou non en ajoutant des éléments au paramètre style. La liste des éléments est disponible dans la page de man. Par exemple, changes pour afficher des différences Git, header-filesize pour afficher la taille du fichier, rule pour afficher une ligne entre deux fichiers, etc.).
Par exemple, si on veut limiter l’affichage aux numéros de ligne, à la taille du fichier (et son contenu évidemment) :
bat futilite.py --style="numbers, header-size"
Personne n’ayant envie de retaper ce paramètre style en permanence, il est enregistrable dans le fichier $HOME/.config/bat/config (le chemin est modifiable par une variable d’environnement). Un contenu d’exemple est montré dans le README.md de bat.
J'ai créé un script python dont le but est de modifier la basse de données SQLite générée par l'application androïd MyLibrary.
Le problème est que au vu des log tout semble fonctionner, les requêtes sql semble bonnes…
2024-02-10 18:36:59 mypc __main__[14467] DEBUG (238, '[]', 'Le secret des Eïles', 1382, None, None, None, '0', 0, '9782302024380', 48, '05/12/2012', 'Soleil', 1, None, '[{"title":"legende","volume":6.0}]', "Après avoir reconquis son trône et passé quelques mois à remettre les choses en bon ordre, le chevalier Tristan s'aperçoit qu'il n'est pas fait pour régenter une cour. Il l'abandonne alors, choisissant une vie plus proche de la Nature qui l'a vu grandir.Mais ses nuits sont hantées par les Eïles, créatures envoûtantes qui essaient de lui voler son âme pendant son sommeil... Une crainte étrange s'éveille alors en lui, plus inquiétante encore que tous les combats périlleux menés jusqu'alors...", 'Le secret des Eïles', None, None, None)
coucou
YOLO
2024-02-10 18:36:59 archbertha __main__[14467] DEBUG UPDATE COMIC SET FNAC_URL = coucou AND AMAZON_URL = yolo AND IS_COMIC = 1 WHERE ID = 238
UPDATE COMIC SET FNAC_URL = coucou AND AMAZON_URL = yolo AND IS_COMIC = 1 WHERE ID = 238
Sauf que quand, après avoir executer le scriptp je vérifie avec un select, rien n'a été modifier dans le base de donnée.
> $ sqlite3 mylibrary.db 'SELECT * FROM COMIC WHERE ID IS 239;'
239|[]|Les forêts profondes|1383||||0|0|2845657927|48|08/12/2004|Soleil Productions|1||[{"title":"legende","volume":2.0}]||Les forêts profondes|||
> $ # Ca devrait etre
239|[]|yolo|1383||||coucou|0|2845657927|48|08/12/2004|Soleil Productions|1||[{"title":"legende","volume":2.0}]||Les forêts profondes||1|
Le script est le suivant:
#!/usr/bin/env python3importargparseimportloggingimportpathlibimportsqlite3importcoloredlogsclassBook:def__init__(self,row)->None:self.is_comic=""self.id=row[0]self.additional_authors=row[1]self.amazon_url=row[2]self.author=row[3]self.categories=row[4]self.comments=row[5]self.cover_path=row[6]self.fnac_url=row[7]self.in_wishlist=row[8]self.isbn=row[9]self.pages=row[10]self.published_date=row[11]self.publisher=row[12]self.read=row[13]self.reading_dates=row[14]self.series=row[15]self.summary=row[16]self.title=row[17]self.amazon_small_cover_url=row[18]self.amazon_cover_url=row[19]defcorrect_amazon_url(self):ifnotself.amazon_url.startswith("http"):print("YOLO")self.amazon_url="yolo"defcorrect_fnac_url(self):ifself.fnac_url!="":print("coucou")self.fnac_url="coucou"defmain(args):logger.debug(args)connection=sqlite3.connect(args.db)cursor=connection.cursor()cursor.execute(f"SELECT * FROM {args.table}")forrowincursor.fetchall():book=Book(row)logger.info("id:"+str(book.id)+":isbn:"+str(book.isbn))logger.debug(row)book.correct_fnac_url()book.correct_amazon_url()ifargs.table=="BOOK":book.is_comic="0"else:book.is_comic="1"sql_command=f"UPDATE {args.table} SET FNAC_URL = {book.fnac_url} AND AMAZON_URL = {book.amazon_url} AND IS_COMIC = {book.is_comic} WHERE ID = {book.id} "logger.debug(sql_command)cursor.execute(f"UPDATE {args.table} SET FNAC_URL = ? AND AMAZON_URL = ? AND IS_COMIC = ? WHERE ID = ?",(book.fnac_url,book.amazon_url,book.is_comic,book.id),)connection.commit()connection.close()if__name__=="__main__":coversPath=pathlib.Path(pathlib.Path(),"covers")dbPath=pathlib.Path(pathlib.Path(),"mylibrary.db")parser=argparse.ArgumentParser()parser.add_argument("-v","--verbose",action="count",help="increase output verbosity",default=0)parser.add_argument("-d","--db",action="store",help="DB path",type=pathlib.Path,default=dbPath)parser.add_argument("-t","--table",choices=["BOOK","COMIC"],help="Wich table ?",required=True)args=parser.parse_args()logger=logging.getLogger(__name__)formatter=logging.Formatter("%(asctime)s%(hostname)s%(name)s[%(process)d] %(levelname)s%(message)s")ifnotargs.verbose:coloredlogs.install(level="ERROR",logger=logger)elifargs.verbose==1:coloredlogs.install(level="WARNING",logger=logger)elifargs.verbose==2:coloredlogs.install(level="INFO",logger=logger)elifargs.verbose>=3:coloredlogs.install(level="DEBUG")else:logging.critical("Log level fail !!!")main(args)
Merci par avance.
PS: Connaissez vous une application du même style opensource ?
Meetup Python le jeudi 7 mars 2024-03-07T17:30:00Z UTC- 13 Rue de la Rabotière, 44800 Saint-Herblain
Bus 23, 59, 81 ou 91 arret Maison des arts + Tram 1 arret Frachon a 15 minutes a pied Porte de Saint Herblain
Des apps Django construites pour durer par Olivier Tabone de Ripple Motion
Stratégies de tests, mise à jour de Django, outillage, architecture,… mon retour d’expérience sur la construction d’applications Django et leur évolution sur une durée de 10 ans et plus.
30 minutes
L’intégration de nouveaux développeurs par Lucas Guérin de Ripple Motion
Découvrez nos bonnes pratiques pour intégrer sereinement des profils développeurs débutants dans nos projets. Comment leur permettre de se former, de développer et de monter en compétence sur les projets sans craindre les erreurs.
Comment écrire un moteur de recherche en 80 lignes de Python ? Cet article décrit les principaux composants d’un moteur de recherche : le Crawler, l’Inverted index et le Ranker.
Meetup Django le 26 mars dans les locaux d’Octopus Energy 6 Bd Haussmann, Paris.
L’occasion de se retrouver et d’en apprendre plus sur les channels Django et également de comprendre comment optimiser le Cycle de Vie des Domaines Métiers avec Django-FSM.
Janvier 2024 c’est Python 3.10 qui devient la version la plus utilisée, qui l’avait vu venir ?
Python 3.8 est restée la plus utilisée 7 mois consécutifs, alors que la 3.7 était restée la plus utilisée 32 mois consécutifs, ça s’accélère, ou ça se lisse (en fait c’est pareil).
Et Python 3.9 n’a jamais été la plus utilisée
Je pense que les gros pics d’utilisation qu’on a pu voir dans le passé (plus de 75% sur Python 2.7, plus de 40% sur Python 3.7) sont terminés pour deux raisons :
Ils ont été crées artificiellement par la migration de 2 à 3.
Le cycle de release est passé d’un an et demi à un an (PEP 602).
Et en effet ça se “lisse” encore ce mois-ci : la version la plus utilisée n’est qu’à 19.79% (contre 19.91% le mois dernier).
Ahh et ça fait deux mois que Python 3.12 est plus utilisé que Python 2.7, si quelqu’un avait encore besoin d’un argument contre Python 2.7…
En de nombreuses occasions, je voudrais pouvoir masquer une partie d’un document pdf à imprimer.
Masque positif: ne garder que telle partie.
Masque négatif: enlever telle partie.
Non, pas enlever: rendre non visible à l’impression.
Une des applications visées: je prends souvent le train, j’ai le “billet” disponible sur l’appli sncf-connect, mais je suis dépendant de mon smartphone, qui peut me lacher, faute de batterie… Solu, imprimer le billet! Mais le billet comporte de larges à-plat colorés, qui bouffent de l’encre! Je voudrais donc soit masquer ces à-plat, avant impression (masque négatif), soit n’imprimer que le qr-code (masque positif).
Je peux me contenter d’une appli, android ou de préférence linux, ou mettre les mains dans le cambouis, et faire du script avec reportlab: montée en compétence, sans doute valorisable ailleurs.
Merci d’avance de vos suggestions.
Pierre
En adhérant, vous permettez à l’APFy de financer ses frais de fonctionnement, d’engager les dépenses pour l’organisation de la PyConFR et d’assurer la promotion du langage Python en francophonie
Être membre de l’AFPy vous permet également de prendre part à la vie de l’association en votant lors de l’Assemblée Générale.
Nous travaillons actuellement sur l’organisation de la prochaine PyConFR qui reprendra son créneau “classique” après les vacances d’été.
Si votre entreprise est intéressée pour soutenir un évènement gratuit, ouvert à toutes et tous, autour du langage Python, n’hésitez pas à consulter les différentes offres de sponsoring disponibles !
Pour ne manquer aucune nouvelle sur l’AFPy, les meetups locaux et la PyConFR, vous pouvez nous suivre sur nos différents réseaux (Mastodon, Twitter / X, LinkedIn) et participer sur le forum ou le salon Discord
David Louapre propose un notebook Python avec une version simplifiée de Lenia en Python. Ce notebook est très facile à installer et à exécuter, car il ne dépend que de scipy, numpy et matplotlib.
Par contre, l'installation du modèle de Bert Wang-Chak est un peu plus retors, notamment pour satisfaire les dépendances. Comme j'ai peur de ne plus me souvenir de ce que j'ai fait, voici une petite recap des commandes effectuées :
## clonage de https://github.com/Chakazul/Lenia
git clone https://github.com/Chakazul/Lenia.git
## creation d'un env python dedié avec conda
conda create -n lenia pip python=3.8
## activation de l'env conda
conda activate lenia
## installation des dépendances
pip install funcsigs==1.0.2 Mako==1.1.3 MarkupSafe==1.1.1 numpy==1.21 pillow==8.3.1 reikna==0.7.5 scipy==1.3.3
## on file dans le bon répertoire...cd Lenia/Python
## et on execute Lenia !
python LeniaNDKC.py -c3 -k3
Scrapy : automatiser le puzzlescraping par Mouna d’OctopusMind
Non, ce n’est pas la dernière tendance instagrammable, mais une façon de me renseigner sur ma passion préférée : les puzzles. Découvrons ensemble le fonctionnement de Scrapy, framework complet qui permet d’automatiser la collecte de données, notamment pour des projets web ou data. Au programme, un bestiaire numérique qui met en scène un python, un poulpe, une araignée, des pandas, et peut-être aussi des chats. Wagtail : Un CMS pour Django, mais pas que par Seb de Rgoods
Préparez-vous pour une exploration de Wagtail, le CMS qui allie la puissance de Django à une UI léchée. Cette session de meetup s’adresse aux développeurs connaissant déjà Python, offrant un aperçu détaillé de Wagtail, de son architecture basée sur les modèles Django, et des fonctionnalités qui en font le choix idéal pour la gestion de contenu. Mais pas que ! Découvrez comment RGOODS a fait de Wagtail la brique centrale de sa plateforme de dons SaaS.
Ahh je vis dans une bulle dans une bulle selon statcounter : en France Firefox est à 9.35%.
Alors je me demandais, sur discuss.afpy.org, on est dans une bulle dans une bulle, ou pas ?
Bon c’est pas joli joli niveau vie privée, sorry les gens, mais un petit one-liner awk pour sortir le dernier user-agent de chaque IP des logs du Discourse :
Nous recherchons un·e développeur·se avec déjà une première expérience significative en Python poursuivre le développement de notre application www.j360.info
Type d’emploi : CDI ou CDD, temps plein ou 4/5, présentiel sur Nantes 1/2 jours hebdo.
Ce n’est pas un poste de data scientist, une proposition d’alternance ou de stage.
Qui est OctopusMind ?
OctopusMind, spécialiste de l’Open Data économique, développe des services autour de l’analyse des données. Nous éditons principalement une plateforme mondiale de détection d’appels d’offres : www.j360.info
L’entreprise, d’une dizaine de personnes, développe ses propres outils pour analyser quotidiennement une grande masse de données, en alliant intelligence humaine et artificielle www.octopusmind.info
Une partie de l’équipe technique est dans d’autres villes. Aussi, nous recherchons pour ce poste un collaborateur pouvant venir régulièrement dans nos bureaux à Nantes (centre ville/gare).
Nous vous proposons
L’équipe IT, sans lead developer, est en lien avec l’équipe R&D ML et l’équipe de veille des marchés. Nous suivons un SCRUM “maison”, ajusté régulièrement selon nos besoins. Nous discutons ensemble de nos priorités et nous les répartissons à chaque sprint selon les profils et envies de chacun·e.
Vous participerez :
Au développement back de j360 (Python/Django, PostgreSQL, ElasticSearch).
Au déploiement des applications (Docker/Docker-Compose, Ansible).
Au développement front de l’application j360 (Vue3/Quasar/Typescript).
Aux scripts de collecte de données (Python/Scrapy).
À la relecture de code de vos collègues
À la réflexion produit, analyse technique et à la définition des priorités de l’entreprise.
À l’ajustement de nos méthodes de travail au sein de l’équipe et de l’entreprise.
Avantages :
Horaires flexibles - RTT - Titres-restaurant - Participation au transport - Plan d’intéressement et plan épargne entreprise
Télétravail & présentiel (domicile/travail possible facilement dans la journée)
Statut cadre en fonction du diplôme/l’expérience ( Syntec)
Processus de recrutement
CV + une présentation de votre profil - qu’est qui vous intéresse par rapport à l’entreprise et aux missions proposées - à adresser par mail à job @ octopusmind.info
Vous pouvez illustrer vos compétences techniques avec des exemples de projets
Échanges et précisions par mail ou téléphone
Test technique
Entretien dans nos bureaux avec des membres de l’équipe IT
Offre (salaire en fonction de l’expérience/niveau)
SVP pas de démarchage pour de l’outsouring, cabinet RH, freelance merci
Docker se distingue par sa flexibilité et ses possibilités de personnalisation. Cette liberté, si elle n'est pas gérée avec prudence, peut mener à des pratiques suboptimales, compromettant la performance et la sécurité de vos systèmes. Dans cet article, nous vous présentons notre méthodologie, rigoureuse, pour minimiser ces risques, assurer la maintenabilité et optimiser vos applications sur nos infrastructures Docker. Dans un article précédent, on vous avait parlé des bonnes pratiques de Bearstech pour la gestion et la mise à jour sécurisée des images Docker. Les images Docker qui sont maintenues par Bearstech bénéficient de la même rigueur que nous apportons au reste de notre infrastructure, en particulier du point de vue de la sécurité, le tout en proposant à nos clients un moyen de s'assurer que les images qu'ils utilisent sont bien à jour. Ces images dérivent toutes de notre image de base bearstech/debian et grâce au système de "layers" de Docker, l'image de base Debian est partagée par toutes les images de notre arborescence : au final le coût de stockage des images sur les serveurs reste très modeste et n'est PAS proportionnel au nombre d'images. A partir de nos images de base, vous pouvez builder facilement votre image pour vos applications : Nodejs, Php, Python, Ruby ... Principe d'unicité de Docker Afin de respecter le principe d'unicité de Docker : 1 conteneur = 1 service (voir la documentation de Docker ou cette conversation), nos images sont généralistes, elles ne contiennent que les librairies nécessaires à l'exécution des tâches dédiées à l'instance applicative et à son lien avec les autres services dont elle aura besoin pour fonctionner (serveur web, bdd, cache ...). Exemple de build d'une application utilisant l'image PHP de Bearstech Par exemple, dans le cas de l'image Docker PHP maintenue par Bearstech, le build de l'image d'une application PHP va hériter de 3 images:
Debian php-cli : intègre les éléments de base de php (php-cli, mysql, gd ...) php : intègre les éléments pour un runtime web (fpm, cache, redis, xdebug ...)
Comme Bearstech assure le suivi en permanence des mises à jour de sécurité Debian sur toutes les images que nous maintenons, ceci inclut PHP. Les versions de PHP maintenues dépendent donc de la version de Debian afin que les images contiennent bien tous les patch de sécurité à jour. A l'heure actuelle, les versions suivantes sont maintenues sous Docker:
Nous maintenons également des versions intermédiaires de PHP selon le principe du "Rolling Release": la versions déployée suit les mises à jour mineures PHP au fil de l'eau, mais quand le projet PHP les abandonne, elles ne reçoivent plus de patches de sécurité :
Pour les applications qui ont besoin d'ajouter des librairies ou un framework (Symfony, Laravel ...) via Composer, vous avez la possibilité d'utiliser notre image php-composer qui est maintenue selon la même logique :
Optimiser le build sur une CI avec Gitlab Comme chacune des images importe les couches des images précédentes, la mise en cache au niveau du serveur d'intégration continue (CI) est efficiente, et tout ce qu'aura à faire le build de votre image sera d'ajouter l'opération qui consiste à copier le code de votre application. Un simple Dockerfile comme suit devrait suffire: FROM bearstech/php:8.2
ARG UID=1001
RUN useradd app --uid $UID --shell /bin/bash COPY . /var/www/app
USER app
CMD ["/usr/sbin/php-fpm"]
De cette manière, depuis l'image de base Debian à celle de votre application, en passant par l'image de l'environnement d'application, chaque image bénéficie des mises à jour de sécurité héritées de la version parente. A noter également, pour les applications qui ont besoin d'installer des librairies via Composer, l'utilisation de l'image bearstech/php-composer permet de traiter cette étape en amont du build de votre application dans la CI Gitlab, via une commande du type: docker run --rm -u `id -u` -v `pwd`:/var/www/app -w /var/www/app bearstech/php-composer:8.2 bash -c "composer install"
Layer caching Vous pouvez aussi optimiser le temps de build de l'image de votre application en suivant les principes du "Layer Caching" Dans la CI, vous allez récupérer la dernière version de votre image via un docker pull qui sera utilisée comme cache pour builder la nouvelle version de votre image grâce à l'argument --cache-from donné à la commande docker build: docker build --cache-from $CI_REGISTRY_IMAGE:latest --tag $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA --tag $CI_REGISTRY_IMAGE:latest .
Il est donc important de labelliser correctement vos images afin de savoir quelle version a été versionnée en dernier ("latest") et de l'inclure dans un flux d'imbrication des couches ("layer"), au fur et à mesure des montées en version de votre application. Toutes ces étapes sont reproductibles et automatisables grâce à notre workflow devops. Celui-ci permet d'organiser de manière efficace le travail des développeurs en plaçant en continu notre travail d'infogérance (OPS) dans les procédés d'intégration et de déploiement de vos applications. Vous pouvez lire aussi à ce sujet nos articles qui expliquent en quoi notre workflow vous permet d'améliorer la fiabilité de vos applications, et vous assure des déploiements cohérents et reproductibles.
by Yann Larrivee,Benoît Sibaud,Ysabeau 🧶 🧦 from Linuxfr.org
Voulez-vous être à l’avant-garde de l’industrie ? Réservez votre calendrier pour la 22ᵉ édition de ConFoo en février 2024 à Montréal !
Avec plus de 170 présentations, offertes par des conférenciers de partout à travers le monde, ConFoo est une conférence destinée aux développeurs Full-Stack, couvrant tout, du backend au frontend : JavaScript, PHP, Java, Dotnet, Sécurité, Intelligence Artificielle, DevOps et bien plus encore.
ConFoo apporte une remarquable diversité de contenu pour élargir vos connaissances, augmenter votre productivité et amener vos compétences en développement au niveau supérieur.
Avec un choix de présentations axé sur les technologies de pointe, il y a une raison pour laquelle les participants qui reviennent de ConFoo disent avoir appris davantage en ces trois jours que pendant trois années à l’université !
Inscrivez-vous dès maintenant pour participer, rencontrer les conférenciers de renom qui contribuent aux projets Open Source que vous utilisez tous les jours.
Bonjour,
Nous recrutons des profils d’Ingénieur Software Python pour venir renforcer nos équipes.
Société innovante en très forte croissance, nous travaillons dans le secteur de l’efficacité énergétique. Pour compléter notre équipe, nous recherchons nos futurs talents qui interviendront sur des sujets de développement de notre solution. Nous utilisons les technos Python, FastAPI, Flask… Nous recherchons des personnes passionnées voulant rejoindre une structure type startup qui évolue rapidement et qui est tournée vers l’innovation et l’international.
Merci pour vos retours.
Sophie
Je ne sais pas si vous accepterez de m’aider (parce qu’il y a du taff :D) mais je tente tout de même le coup on sait jamais.
Je suis total débutant sur Python, jusque là j’ai développé tout mes projets avec AutoIt mais pour celui ci je tourne en rond alors après recherche je pense qu’il serait réalisable sur Python.
concrètement, j’ai besoin de développer une app pour effectuer le traitement de pdf selon le process suivant :
les fichiers pdf a traiter son des numérisation de plusieurs documents de plusieurs page en une seule numérisation dont chaque première page contient 2 informations en bas de page (1 pour le renommage et 1 mot clé indiquant le début d’un nouveau document)
premier traitement a réaliser, séparer chaque pdf a chaque fin d’un document en utilisant le mot clé.
second traitement, renommer les pdf généré en fonction de l’information de renommage qui n’est pas toujours la même (exemple “recu_2401102501”, “naiss_01011005” ou encore procctx_24051206_05… j’en ai une cinquantaine comme ça et les partie en chiffre n’est pas toujours sur le même nombre de caractères
troisième traitement déplacer les fichier pdf dans des dossiers réseaux en fonction de la première partie de leur nom (la partie en lettres)
dernier traitement, supprimer les fichiers d’origine.
Information supplémentaire : les fichiers arrivent au fil de l’eau il est donc possible qu’entre le lancement et la fin des traitements, de nouveaux fichiers soient déposé. Il ne faut donc pas les prendre en compte dans la dernière étape de suppression.
Idéalement il faudrait alimenter un fichier log a chaque étape de traitement.
Comme je l’ai dit je suis total débutant et je suis donc très vite coincé. pour le moment je n’arrive qu’a séparer en plusieurs fichiers sur détection du mot clé et uniquement pour des fichiers sur lesquels il y a eu de l’OCR de faite par le copieur servant aux numérisation. Problème certain fichier font pas loin de 100 pages donc l’OCRisation (si je puis dire) est très longue et le poids du fichier on en parle même pas… De plus je n’arrive a le faire qu’en ciblant un fichier en particulier.
Bref vous l’aurez compris a ce stade c’est même pas de l’entraide c’est limite de l’assistanat j’en suis conscient.
pour info j’ai utilisé PyPDF2
Je vous remercie par avance pour vos retour.
Ptiseb
Arrêter de s’auto-héberger implique d’utiliser Framatalk (ou autre ?) comme on faisait avant.
Garder BBB implique que je dois me coltiner une mise à jour à la main (nouvelle machine, install from scratch, migration des comptes et des enregistrements, ça prend du temps).
Jitsi me semble un peu plus simple à administrer, ça semble gérable via Ansible (c’est un apt install, pas un curl | sh).
Mais bon, 3.10, 3.9, 3.8, et 3.7 sont toutes les 4 autour de 19% d’utilisateurs :
Autres points notables :
3.12 est plus utilisée que 2.7 (1.67% contre 1.58%).
Il aura fallu 21 mois pour que la 3.7 passe de 0% à 1% d’utilisateurs, contre seulement 14 mois pour la 3.8, 11 mois pour la 3.9, 17 mois pour la 3.10, 10 mois pour la 3.11, et 1 mois pour la 3.12 !!
Décembre 2023 c’est la première fois qu’on a aucune version de Python avec plus de 20% d’utilisateurs. Alors que 2.7 avait 75% d’utilisateurs en janvier 2016, et que la 3.7 avait 42% d’utilisateurs en août 2021.
Je vais donc proposer un aperçu plus ou moins complet des différents outils, et de ce qu’ils font ou ne font pas, en essayant de les comparer. Mais je parlerai aussi des fichiers de configuration, des dépôts où les paquets sont publiés, des manières d’installer Python lui-même, et de l’interaction de tout ceci avec les distributions Linux. En revanche, je laisse de côté pour l’instant les paquets écrits en C, C++ ou Rust et la complexité qu’ils apportent.
L’installeur de paquets pip est un outil fondamental et omniprésent. Son nom est un acronyme récursif signifiant « Pip Installs Packages ». Il permet d’installer un paquet depuis le PyPI, mais aussi depuis une copie locale du code source, ou encore depuis un dépôt Git. Il dispose, bien sûr, d’un résolveur de dépendances pour trouver des versions à installer qui soient compatibles entre elles. Il possède aussi un certain nombre de fonctionnalités standard pour un gestionnaire de paquets, comme désinstaller un paquet, lister les paquets installés, etc.
S’il y a un outil de packaging quasi universel, c’est bien pip. Par exemple, la page de chaque paquet sur PyPI (exemple) affiche une commande pour l’installer, à savoir pip install <paquet>. Quand la documentation d’un paquet donne des instructions d’installation, elles utilisent généralement pip.
De plus, la distribution officielle de Python permet de boostraper très simplement pip avec la commande python -m ensurepip. Cela rend pip très facile à installer, et lui donne un caractère officiel, soutenu par les développeurs de Python, caractère que n’ont pas la plupart des autres outils que je vais mentionner.
Même les autres outils qui installent aussi des paquets depuis le PyPI (comme pipx, Hatch, tox, etc.) le font presque tous en utilisant, en interne, pip (sauf Poetry qui est un peu à part).
Dans l’univers parallèle de Conda et Anaconda, les utilisateurs sont souvent obligés d’utiliser pip dans un environnement Conda parce qu’un paquet donné n’est pas disponible au format Conda (ce qui crée, d’ailleurs, des problèmes de compatibilité, mais c’est un autre sujet).
Les dangers de pip sous Linux
Malheureusement, sous Linux spécifiquement, l’interface en ligne de commande de pip a longtemps été un moyen très facile de se tirer une balle dans le pied. En effet, la commande simple
pip install <paquet>
tentait d’installer le paquet au niveau du système, de manière visible pour tous les utilisateurs de la machine (typiquement dans /usr/lib/pythonX.Y/site-packages/). Bien sûr, il faut des permissions pour cela. Que fait Monsieur Toutlemonde quand il voit « permission denied error » ? Élémentaire, mon cher Watson :
sudo pip install <paquet>
Or, sous Linux, installer des paquets avec pip au niveau du système, c’est mal. Je répète : c’est MAL. Ou plutôt, c’est valable dans 0,1% des cas et dangereux dans 99,9% des cas.
J’insiste : ne faites JAMAISsudo pip install ou sudo pip uninstall. (Sauf si vous savez parfaitement ce que vous faites et que vous avez scrupuleusement vérifié qu’il n’y a aucun conflit.)
Le souci ? Les distributions Linux contiennent, elles aussi, des paquets écrits en Python, qui sont installés au même endroit que celui dans lequel installe la commande sudo pip install. Pip peut donc écraser un paquet installé par le système avec une version différente du même paquet, potentiellement incompatible avec le reste, ce qui peut avoir des conséquences catastrophiques. Il suffit de penser que DNF, le gestionnaire de paquets de Fedora, est écrit en Python, pour avoir une idée des dégâts potentiels !
Aujourd’hui, heureusement, la commande pip install <paquet> (sans sudo), au lieu d’échouer avec une erreur de permissions, installe par défaut dans un emplacement spécifique à l’utilisateur, typiquement ~/.local/lib/pythonX.Y/site-packages/ (ce qui devait auparavant se faire avec pip install --user <paquet>, l’option --user restant disponible si on veut être explicite). De plus, pip émet un avertissement sous Linux lorsqu’exécuté avec les droits root (source). Ainsi, pip install <paquet> est devenu beaucoup moins dangereux.
Attention, j’ai bien dit moins dangereux… mais dangereux quand même ! Pourquoi, s’il n’efface plus les paquets du système ? Parce que si un paquet est installé à la fois par le système, et par pip au niveau de l’utilisateur, la version de pip va prendre le dessus, car le dossier utilisateur a priorité sur le dossier système. Le résultat est que le conflit, en réalité, persiste : il reste possible de casser un paquet système en installant une version incompatible avec pip au niveau utilisateur. Seulement, c’est beaucoup plus facile à corriger (il suffit d’un rm -rf ~/.local/lib/pythonX.Y/site-packages/*, alors qu’un conflit dans le dossier système peut être quasi irréparable).
La seule option qui soit sans danger est de ne jamais rien installer en dehors d’un environnement virtuel (voir plus bas pour les instructions).
Pour finir, la PEP 668 a créé un mécanisme pour qu’une distribution Linux puisse marquer les dossiers de paquets Python qu’elle contrôle. Pip refuse (par défaut) de modifier ces dossiers et affiche un avertissement qui mentionne les environnements virtuels. Debian (à partir de Debian Bookworm), Ubuntu (à partir d’Ubuntu Lunar) et d’autres distributions Linux, ont choisi de mettre en place cette protection. Donc, désormais, sudo ou pas, pip install en dehors d’un environnement virtuel donne une erreur (on peut forcer l’opération avec l’option --break-system-packages).
En revanche, Fedora n’a pas implémenté la protection, espérant réussir à créer un dossier pour pip qui soit au niveau système mais séparé du dossier de la distribution Linux, pour que pip install soit complètement sûr et qu’il n’y ait pas besoin de cette protection. Je recommande la présentation de Miro Hrončok à la conférence PyCon polonaise en janvier 2023, qui explique le casse-tête dans les menus détails. Petite citation en avant-goût : « The fix is quite trivial when you design it, and it only strikes back when you actually try to do it ».
Pip est un outil de bas niveau
Pip a une autre chausse-trappe qui est surprenant quand on est habitué au gestionnaire de paquets d’une distribution Linux. Petite illustration :
$ python -m venv my-venv/ # crée un environnement isolé vide pour la démonstration
$ source my-venv/bin/activate # active l’environnement
$ pip install myst-parser
[...]
Successfully installed MarkupSafe-2.1.3 Pygments-2.16.1 alabaster-0.7.13 [...]
[...]
$ pip install mdformat-deflist
[...]
Installing collected packages: markdown-it-py, mdit-py-plugins, mdformat, mdformat-deflist [...]
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
myst-parser 2.0.0 requires markdown-it-py~=3.0, but you have markdown-it-py 2.2.0 which is incompatible.
myst-parser 2.0.0 requires mdit-py-plugins~=0.4, but you have mdit-py-plugins 0.3.5 which is incompatible.
Successfully installed markdown-it-py-2.2.0 mdformat-0.7.17 mdformat-deflist-0.1.2 mdit-py-plugins-0.3.5 [...]
$ echo $?
0
Comme on peut le voir, la résolution des dépendances par pip ne prend pas en compte les paquets déjà installés dans l’environnement. Autrement dit, pour installer un paquet X, pip va simplement regarder quelles sont les dépendances de X (y compris les dépendances transitives), trouver un ensemble de versions qui soient compatibles entre elles, et les installer. Pip ne vérifie pas que les versions des paquets sont aussi compatibles avec ceux qui sont déjà installés. Ou plutôt, il les vérifie, mais seulement après avoir fait l’installation, à un moment où le mal est déjà fait, et uniquement pour afficher un avertissement. Dans l’exemple ci-dessus, on installe d’abord myst-parser, dont la dernière version dépend de markdown-it-py version 3.x, puis on installe mdformat-deflist, qui dépend de markdown-it-py version 1.x ou 2.x. En installant mdformat-deflist, Pip installe aussi, comme dépendance, markdown-it-py 2.x, ce qui casse le myst-parser installé précédemment.
Ceci n’est naturellement pas du goût de tout le monde (je me rappelle d’ailleurs d’une enquête utilisateur faite par les développeurs de Pip il y a quelques années, où ils posaient la question de savoir ce que Pip devait faire dans cette situation). La morale est que pip est surtout un outil conçu pour créer un environnement virtuel où se trouvent toutes les dépendances dont on a besoin, pas pour s’en servir comme de apt ou dnf, en installant et désinstallant manuellement des dépendances. Et surtout, que pip install X; pip install Yn’est absolument pas équivalent à pip install X Y, et c’est la seconde forme qui est correcte.
Les environnements virtuels permettent de travailler avec des ensembles de paquets différents, installés de façon indépendante entre eux. L’outil d’origine pour les créer est virtualenv. Néanmoins, le plus utilisé aujourd’hui est venv, qui est une version réduite de virtualenv intégrée à la bibliothèque standard. Malheureusement, venv est plus lent et n’a pas toutes les fonctionnalités de virtualenv, qui reste donc utilisé également…
Pour créer un environnement virtuel (avec venv), on exécute :
python -m venv nom-de-l-environnement
Cela crée un dossier nom-de-l-environnement/. Chaque environnement est donc stocké dans un dossier. À l’intérieur de ce dossier se trouve notamment un sous-dossier bin/ avec des exécutables :
un exécutable python, qui ouvre un interpréteur Python ayant accès aux paquets de l’environnement virtuel (et, par défaut, seulement eux),
un exécutable pip, qui installe les paquets à l’intérieur de l’environnement.
De plus, pour simplifier l’utilisation dans un shell, on peut « activer » l’environnement, avec une commande qui dépend du shell. Par exemple, sous les shells UNIX classiques (bash, zsh), on exécute
source nom-de-l-environnement/bin/activate
Cette commande modifie la variable PATH pour y ajouter nom-de-l-environnement/bin/ afin que (par exemple) la commande python invoque nom-de-l-environnement/bin/python.
Malgré cela, les environnements virtuels restent un niveau de confort en dessous du Python du système, puisqu’il faut activer un environnement avant de s’en servir, ou écrire à chaque fois le chemin dossier-environnement/bin/. Bien sûr, il faut aussi mémoriser les commandes, et puis c’est si facile de faire pip install dans l’environnement global (non virtuel). Donc, beaucoup n’y prêtent malheureusement pas attention et installent au niveau global, ce qui cause des conflits de dépendances (c’est maintenant refusé par défaut sous Debian et dérivés, comme je l’expliquais dans la section précédente, mais c’est toujours majoritaire sous macOS et Windows).
C’est aussi pour rendre plus pratiques les environnements virtuels qu’existent pléthore d’outils qui les créent et/ou activent pour vous. Je termine avec l’un de ces outils, lié à la fois à pip et aux environnements virtuels, j’ai nommé pipx. À première vue, pipx a une interface qui ressemble à celle de pip, avec par exemple des sous-commandes pipx install, pipx uninstall et pipx list. Mais, à la différence de pip, qui installe un paquet dans un environnement déjà créé, pipx va, pour chaque paquet installé, créer un nouvel environnement virtuel dédié. Pipx est principalement destiné à installer des outils dont l’interface est en ligne de commande, pas sous forme d’un module importable en Python. Pipx utilise pip, pour ne pas trop réinventer la roue quand même. Au final,
Pour résumer, pipx permet d’installer des outils en ligne de commande, de manière isolée, qui n’interfèrent pas avec le système ou entre eux, sans avoir à gérer les environnements virtuels soi-même.
Pour déposer son projet sur PyPI, il faut d’abord obtenir deux fichiers : une sdist (source distribution), qui est essentiellement une archive .tar.gz du code avec des métadonnées ajoutées, et un paquet installable au format wheel, d’extension .whl. L’outil build sert à générer ces deux fichiers. Il s’invoque comme ceci, dans le dossier du code source :
python -m build
Petit exemple dans le dépôt de Sphinx (l’outil de documentation le plus répandu dans le monde Python) :
$ python -m build
* Creating venv isolated environment...
* Installing packages in isolated environment... (flit_core>=3.7)
* Getting build dependencies for sdist...
* Building sdist...
* Building wheel from sdist
* Creating venv isolated environment...
* Installing packages in isolated environment... (flit_core>=3.7)
* Getting build dependencies for wheel...
* Building wheel...
Successfully built sphinx-7.3.0.tar.gz and sphinx-7.3.0-py3-none-any.whl
$ ls dist/
sphinx-7.3.0-py3-none-any.whl sphinx-7.3.0.tar.gz
Comme on peut le comprendre, build est un outil très simple. L’essentiel de sa documentation tient en une courte page. Il crée un environnement virtuel pour installer le build backend, en l’occurrence Flit, puis se contente d’invoquer celui-ci.
À l’image de build, twine est un outil fort simple qui remplit une seule fonction et la remplit bien : déposer la sdist et le wheel sur PyPI (ou un autre dépôt de paquets). En continuant l’exemple précédent, on écrirait :
twine upload dist/*
Après avoir fourni un login et mot de passe, le projet est publié, il peut être installé avec pip, et possède sa page https://pypi.org/project/nom-du-projet.
La configuration d’un projet : le fichier pyproject.toml
pyproject.toml est le fichier de configuration adopté par à peu près tous les outils de packaging, ainsi que de nombreux outils qui ne sont pas liés au packaging (par exemple les linters comme Ruff, les auto-formateurs comme Black ou le même Ruff, etc.). Il est écrit dans le langage de configuration TOML. On a besoin d’un pyproject.toml pour n’importe quel projet publié sur PyPI, et même, souvent, pour les projets qui ne sont pas distribués sur PyPI (comme pour configurer Ruff).
Dans ce fichier se trouvent trois sections possibles — des « tables », en jargon TOML. La table [build-system] détermine le build backend du projet (je reviens plus bas sur le choix du build backend). La table [project] contient les informations de base, comme le nom du projet, la version, les dépendances, etc. Quant à la table [tool], elle est utilisée via des sous-tables [tool.<nom de l'outil>] : tout outil peut lire de la configuration dans sa sous-table dédiée. Rien n’est standardisé par des spécifications PyPA dans la table [tool], chaque outil y fait ce qu’il veut.
Avant qu’on me dise que pyproject.toml est mal documenté, ce qui a pu être vrai, je précise que des efforts ont été faits à ce niveau dans les dernières semaines, par moi et d’autres, ce qui donne un guide du pyproject.toml normalement complet et compréhensible, ainsi qu’une explication sur ce qui est déprécié ou non concernant setup.py et un guide sur la migration de setup.py vers pyproject.toml. Tout ceci réside sur packaging.python.org, qui est un site officiel de la PyPA rassemblant des tutoriels, guides et spécifications techniques.
Les build backends pour code Python pur
Le build backend est chargé de générer les sdists et les wheels que l’on peut ensuite mettre sur PyPI avec twine ou autre. Il est spécifié dans le fichier pyproject.toml. Par exemple, pour utiliser Flit, la configuration est :
requires est la liste des dépendances (des paquets sur PyPI), et build-backend est le nom d’un module (qui doit suivre une interface standardisée).
Il peut sembler étrange qu’il faille, même pour un projet simple, choisir son build backend. Passons donc en revue les critères de choix : de quoi est responsable le build backend ?
D’abord, il doit traduire les métadonnées du projet. En effet, dans les sdists et wheels, les métadonnées sont encodées dans un format un peu étrange, à base de MIME, qui est conservé au lieu d’un format plus moderne comme TOML ou JSON, pour des raisons de compatibilité. La plupart des build backends se contentent de prendre les valeurs dans la table [project] du pyproject.toml et de les copier directement sous la bonne forme, mais setuptools permet aussi de configurer les métadonnées via setup.py ou setup.cfg, également pour préserver la compatibilité, et il y a aussi des build backends comme Poetry qui n’ont pas adopté la table [project] (j’y reviens dans la section sur Poetry).
De plus, les build backends ont souvent des façons de calculer dynamiquement certaines métadonnées, typiquement la version, qui peut être lue depuis un attribut __version__, ou déterminée à partir du dernier tag Git.
C’est aussi le build backend qui décide des fichiers du projet à inclure ou exclure dans la sdist et le wheel. En particulier, on trouve généralement des options qui permettent d’inclure des fichiers autres que .py dans le wheel (c’est le wheel qui détermine ce qui est installé au final, alors que la sdist peut aussi contenir les tests etc.). Cela peut servir, par exemple, aux paquets qui doivent être distribués avec des icônes, des données en JSON, des templates Django…
Enfin, s’il y a des extensions en C, C++, Rust ou autre, le build backend est chargé de les compiler.
Il existe aujourd’hui de nombreux build backends. Beaucoup sont spécifiques à un type d’extensions compilées, ils sont présentés dans la troisième dépêche. Voici les build backends principaux pour du code Python pur.
C’est le build backend historique. Il reste très largement utilisé.
Avant qu’arrive pyproject.toml, il n’y avait qu’un build backend, setuptools, et il était configuré soit par le setup.py, soit par un fichier en syntaxe INI, nommé setup.cfg (qui est l’ancêtre de pyproject.toml). Ainsi, il existe aujourd’hui trois manières différentes de configurer setuptools, à savoir setup.py, setup.cfg et pyproject.toml. On rencontre les trois dans les projets existants. La façon recommandée aujourd’hui est pyproject.toml pour tout ce qui est statique, sachant que setup.py, qui est écrit en Python, peut toujours servir s’il y a besoin de configuration programmable.
Aujourd’hui, setuptools ne se veut plus qu’un build backend, mais historiquement, en tant que descendant de distutils, il a beaucoup de fonctionnalités, désormais dépréciées, pour installer des paquets ou autres. On peut se faire une idée de l’ampleur des évolutions qui ont secoué le packaging au fil des années en parcourant l’abondante documentation des fonctionnalités obsolètes, notamment cette page, celle-ci ou encore celle-là.
Flit est l’exact opposé de setuptools. C’est le build backend qui vise à être le plus simple et minimal possible. Il n’y a pratiquement pas de configuration autre que la configuration standardisée des métadonnées dans la table [project] du pyproject.toml.
Flit se veut volontairement inflexible (« opinionated »), pour qu’il n’y ait pas de choix à faire. Avec Flit, un projet appelé nom-projet doit obligatoirement fournir un module et un seul, soit nom_projet.py, soit nom_project/. De même, il est possible d’inclure des fichiers autres que .py, mais ils doivent obligatoirement se trouver tous dans un dossier dédié au même niveau que le pyproject.toml.
Flit dispose aussi d’une interface en ligne de commande minimale, avec des commandes flit build (équivalent de python -m build), flit publish (équivalent de twine upload), flit install (équivalent de pip install .), et flit init (qui initialise un projet).
Hatchling est le build backend associé à Hatch, un outil tout-en-un dont il sera question plus loin.
Contrairement à setuptools, il est plutôt facile d’utilisation, et il fait plus souvent ce qu’on veut par défaut. Contrairement à Flit, il offre aussi des options de configuration plus avancées (comme pour inclure plusieurs modules dans un paquet), ainsi que la possibilité d’écrire des plugins.
De même que hatchling est associé à Hatch, PDM-Backend est associé à PDM. Je n'en ai pas d'expérience, mais à lire sa documentation, il me semble plus ou moins équivalent en fonctionnalités à hatchling, avec des options un peu moins fines.
Comme les deux précédents, Poetry-core est associé à un outil plus vaste, à savoir Poetry.
Par rapport à hatchling et PDM-backend, il est moins sophistiqué (il ne permet pas de lire la version depuis un attribut dans le code ou depuis un tag Git).
L’une des difficultés du packaging Python est que l’interpréteur Python lui-même n’est généralement pas compilé upstream et téléchargé depuis le site officiel, du moins pas sous Linux (c’est davantage le cas sous Windows, et plus ou moins le cas sous macOS). L’interpréteur est plutôt fourni de l’extérieur, à savoir, sous Linux, par le gestionnaire de paquets de la distribution, ou bien, sous macOS, par XCode, Homebrew ou MacPorts. Cela peut aussi être un Python compilé à partir du code source sur la machine de l’utilisateur.
Ce modèle est différent d’autres langages comme Rust, par exemple. Pour installer Rust, la plupart des gens utilisent Rustup, un script qui télécharge des exécutables statiques compilés upstream (le fameux curl | bash tant décrié…).
Le but de pyenv est de simplifier la gestion des versions de Python. On exécute, par exemple, pyenv install 3.10.2 pour installer Python 3.10.2. Comme pyenv va compiler le code source, il faut quand même installer soi-même les dépendances (avec leurs en-têtes C).
À partir du moment où un projet grossit, il devient souvent utile d’avoir de petits scripts qui automatisent des tâches courantes, comme exécuter les tests, mettre à jour tel fichier à partir de tel autre, ou encore compiler des catalogues de traduction en format MO à partir des fichiers PO. Il devient également nécessaire de tester le projet sur différentes versions de Python, ou encore avec différentes versions des dépendances.
Tout cela est le rôle de tox. Il se configure avec un fichier tox.ini. Voici un exemple tiré de Pygments:
[tox]
envlist = py
[testenv]
description =
run tests with pytest (you can pass extra arguments for pytest,
e.g., "tox -- --update-goldens")
deps =
pytest >= 7.0
pytest-cov
pytest-randomly
wcag-contrast-ratio
commands =
pytest {posargs}
use_develop = True
On peut avoir plusieurs sections [testenv:xxx] qui définissent des environnements virtuels. Chaque environnement est créé avec une version de Python ainsi qu’une certaine liste de dépendances, et peut déclarer des commandes à exécuter. Ces commandes ne passent pas par un shell, ce qui garantit que le tox.ini reste portable.
Interlude : vous avez dit lock file?
Pour faire simple, un lock file est un fichier qui décrit de manière exacte un environnement de sorte qu’il puisse être reproduit. Prenons un exemple. Imaginons une application Web déployée sur plusieurs serveurs, qui a besoin de la bibliothèque requests. Elle va déclarer cette dépendance dans sa configuration. Éventuellement, elle fixera une borne sur la version (par exemple requests>=2.31), pour être sûre d’avoir une version compatible. Mais le paquet requests a lui-même des dépendances. On souhaiterait que l’environnement soit vraiment reproductible — que des serveurs différents n’aient pas des versions différentes des dépendances, même si les environnements sont installés à des moments différents, entre lesquels des dépendances publient des nouvelles versions. Sinon, on risque des bugs difficiles à comprendre qui ne se manifestent que sur l’un des serveurs.
La même problématique se pose pour développer une application à plusieurs. Sauf si l’application doit être distribuée dans des environnements variés (par exemple empaquetée par des distributions Linux), il ne vaut pas la peine de s’embarrasser de versions différentes des dépendances. Il est plus simple de fixer toutes les versions pour tout le monde.
Dans la vraie vie, une application peut avoir des centaines de dépendances, dont quelques-unes directes et les autres indirectes. Il devient très fastidieux de maintenir à la main une liste des versions exactes de chaque dépendance.
Avec un lock file, on s’assure de geler un ensemble de versions de tous les paquets qui sera le même pour tous les contributeurs, et pour tous les déploiements d’une application. On sépare, d’un côté, la déclaration des dépendances directes minimales supposées compatibles avec l’application, écrite à la main, et de l’autre côté, la déclaration des versions exactes de toutes les dépendances, générée automatiquement. Concrètement, à partir de la contrainte requests>=2.31, un générateur de lock file pourrait écrire un lock file qui fixe les versions certifi==2023.11.17, charset-normalizer==3.3.2, idna==3.4, requests==2.31.0, urllib3==2.1.0. À la prochaine mise à jour du lock file, certaines de ces versions pourraient passer à des versions plus récentes publiées entre-temps.
Le concept de lock file est en revanche beaucoup plus discutable pour une bibliothèque (par opposition à une application), étant donné qu’une bibliothèque est faite pour être utilisée dans d’autres projets, et que si un projet a besoin des bibliothèques A et B, où A demande requests==2.31.0 alors que B demande requests==2.30.0, il n’y a aucun moyen de satisfaire les dépendances. Pour cette raison, une bibliothèque doit essayer de minimiser les contraintes sur ses dépendances, ce qui est fondamentalement opposé à l’idée d’un lock file.
Il existe plusieurs outils qui permettent de générer et d’utiliser un lock file. Malheureusement, l’un des plus gros problèmes actuels du packaging Python est le manque criant, sinon d’un outil, d’un format de lock file standardisé. Il y a eu une tentative avec la PEP 665, rejetée par manque de consensus (mais avant qu’on soupire qu’il suffisait de se mettre d’accord : il y a de vraies questions techniques qui se posent, notamment sur l’adoption d’un standard qui ne permet pas de faire tout ce que font certains outils existants, qui risquerait de fragmenter encore plus au lieu d’aider).
pip-tools est un outil assez simple pour générer et utiliser un lock file. Il se compose de deux parties, pip-compile et pip-sync.
La commande pip-compile, prend un ensemble de déclarations de dépendances, soit dans un pyproject.toml, soit dans un fichier spécial requirements.in. Elle génère un fichier requirements.txt qui peut être installé par pip.
Quant à la commande pip-sync, c’est simplement un raccourci pour installer les dépendances du requirements.txt.
Les locks files sont donc des fichiers requirements.txt, un format pas si bien défini puisqu’un requirements.txt est en fait essentiellement une série d’arguments et d’options en ligne de commande à passer à pip.
Les outils « tout-en-un »
Face à la prolifération d’outils à installer et mémoriser, certains ont essayé de créer une expérience plus cohérente avec des outils unifiés. Malheureusement, ce serait trop simple s’ils s’étaient accordés sur un projet commun…
Poetry est un outil un peu à part qui fait à peu près tout par lui-même.
Poetry se destine aux développeurs de bibliothèques et d’applications. Toutefois, en pratique, il est plutôt orienté vers les applications.
La configuration se fait entièrement dans le fichier pyproject.toml. Poetry s’utilise toujours avec son build backend Poetry-core, donc la partie [build-system] du pyproject.toml est configurée comme ceci :
En revanche, contrairement à la plupart des autres build backends, Poetry n’accepte pas la configuration dans la table [project]. À la place, il faut écrire les métadonnées sur le projet (nom, version, mainteneurs, etc.) dans la table [tool.poetry], dans un format différent du format standard.
La particularité de Poetry qui le rend à part est d’être centré profondément sur le concept de lock file, d’insister fortement sur le Semantic Versioning, et d’avoir son propre résolveur de dépendances. Poetry n’installe jamais rien dans l’environnement virtuel du projet avant d’avoir généré un lock file qui trace les versions installées. Sa configuration a aussi des raccourcis typiques du semantic versioning, comme la syntaxe nom_du_paquet = "^3.4", qui dans la table [project] s’écrirait plutôt "nom_du_paquet >= 3.4, < 4.
Je ne vais pas présenter les commandes de Poetry une par une car cette dépêche est déjà bien trop longue. Je renvoie à la documentation. Disons simplement qu’un projet géré avec Poetry se passe de pip, de build, de twine, de venv et de pip-tools.
Je l’avoue, je connais mal PDM. D’après ce que j’en ai compris, il est assez semblable à Poetry dans son interface, mais suit tout de même plus les standards, en mettant sa configuration dans la table [project], et en utilisant le résolveur de dépendances de pip. (Je parlerai tout de même, dans la quatrième dépêche, de la motivation à l’origine du développement de PDM, qui cache toute une histoire. Pour ceux qui ont compris, oui, c’est bien résumé par un nombre qui est multiple de 97.)
Hatch est plus récent que Poetry et PDM. (Il n’est pas encore au niveau de Poetry en termes de popularité, mais loin devant PDM.) Il est encore en développement rapide.
Comparé à Poetry et PDM, il ne gère pas, pour l’instant, les lock files. (Ici aussi, il y a une histoire intéressante : l’auteur a d’abord voulu attendre que les discussions de standardisation aboutissent à un format commun, mais vu l’absence de progrès, il a fait savoir récemment qu’il allait implémenter un format non standardisé, comme Poetry et PDM le font déjà.)
En contrepartie, Hatch gère aussi les versions de Python. Il est capable d’installer ou de désinstaller une version très simplement, sachant que, contrairement à pyenv, il ne compile pas sur la machine de l’utilisateur mais télécharge des versions précompilées (beaucoup plus rapide, et aucune dépendance à installer soi-même). Il a aussi une commande fmt pour reformater le projet (plutôt que de définir soi-même un environnement pour cela dans Poetry ou PDM), et il est prévu qu’il gagne bientôt des commandes comme hatch test et hatch doc également.
De plus, dans Poetry, lorsque l’on déclare, par exemple, un environnement pour compiler la documentation, avec une dépendance sur sphinx >= 7, cette dépendance est résolue en même temps que les dépendances principales du projet. Donc, si votre générateur de documentation demande une certaine version, mettons, de Jinja2 (ou n’importe quel autre paquet), vous êtes forcé d’utiliser la même version pour votre propre projet, même si l’environnement pour exécuter votre projet n’a rien à voir avec l’environnement pour générer sa documentation. C’est la même chose avec PDM. Je trouve cette limitation assez frustrante, et Hatch n’a pas ce défaut.
La création d’exécutables indépendants et installeurs : PyInstaller, cx_freeze, briefcase, PyOxidizer (etc.)
Distribuer son projet sur PyPI est bien beau, mais pour installer un paquet du PyPI, il faut d’abord avoir Python et savoir se servir d’un terminal pour lancer pip. Quid de la distribution d’une application graphique à des gens qui n’ont aucune connaissance technique ?
Pour cela, il existe une pléthore d’outils qui créent des installeurs, contenant à la fois Python, une application, ses dépendances, une icône d’application, et en bref, tout ce qu’il faut pour satisfaire les utilisateurs qui n’y comprennent rien et réclament juste une « application normale » avec un « installeur normal », un appli-setup.exe ou Appli.dmg. Les plus connus sont PyInstaller et py2exe. Plus récemment est aussi apparu briefcase.
Il y a aussi d’autres outils qui ne vont pas jusqu’à créer un installeur graphique, mais se contentent d’un exécutable qui peut être lancé en ligne de commande. Ce sont notamment cx_freeze et PyOxidizer, mais il y en a bien d’autres.
Malheureusement, toute cette classe d’usages est l’un des gros points faibles de l’écosystème actuel. PyInstaller, par exemple, est fondé sur des principes assez douteux qui datent d’une époque où le packaging était beaucoup moins évolué qu’aujourd’hui (voir notamment ce commentaire). Pour faire simple, PyInstaller détecte les import dans le code pour trouver les fichiers à inclure dans l’application, au lieu d’inclure toutes les dépendances déclarées par les mainteneurs. Il semble que briefcase soit meilleur de ce point de vue.
De manière plus générale, embarquer un interpréteur Python est techniquement compliqué, notamment à cause de l’interaction avec des bibliothèques système (comme OpenSSL), et chacun de ces projets résout ces difficultés d’une manière différente qui a ses propres limitations.
Conda, un univers parallèle
Comme expliqué dans la première dépêche sur l’historique du packaging, Conda est un outil entièrement indépendant de tout le reste. Il ne peut pas installer de paquets du PyPI, son format de paquet est différent, ses environnements virtuels sont différents. Il est développé par une entreprise, Anaconda Inc (mais publié sous une licence libre). Et surtout, bien que chacun puisse publier des paquets sur anaconda.org, il reste principalement utilisé à travers des dépôts de paquets comprenant plusieurs milliers de paquets, qui sont gérés non pas par les auteurs du code concerné, mais par des mainteneurs propres au dépôt de paquets, à la manière d’une distribution Linux, ou de Homebrew et MacPorts sous macOS. En pratique, les deux dépôts principaux sont Anaconda, qui est maintenu par Anaconda Inc, et conda-forge, maintenu par une communauté de volontaires.
Quelques outils gravitent autour de Conda (mais beaucoup moins que les outils compatibles PyPI, car Conda est plus unifié). Je pense notamment à Condax, qui est à Conda ce que pipx est à pip. Il y a aussi conda-lock pour les lock files.
Grâce à son modèle, Conda permet une distribution très fiable des extensions C et C++, ce qui constitue son atout principal. Un inconvénient majeur est le manque de compatibilité avec PyPI, qui reste la source unique pour la plupart des paquets, Conda n’ayant que les plus populaires.
Petite comparaison des résolveurs de dépendances
Les résolveurs de dépendances sont des composants invisibles, mais absolument cruciaux des systèmes de packaging. Un résolveur de dépendances prend un ensemble de paquets, et de contraintes sur ces paquets, de la forme « l’utilisateur demande le paquet A version X.Y au minimum et version Z.T au maximum », ou « le paquet A version X.Y dépend du paquet B version Z.T au minimum et U.V au maximum ». Il est chargé de déterminer un ensemble de versions compatibles, si possible récentes.
Cela paraît simple, et pourtant, le problème de la résolution de dépendances est NP-complet (c’est facile à démontrer), ce qui signifie que, sauf à prouver fausse l'hypothèse du temps exponentiel (et si vous le faites, vous deviendrez célèbre et couronné de gloire et du prix Turing), il n’existe pas d’algorithme pour le résoudre qui ait une complexité meilleure qu’exponentielle. Les algorithmes utilisés en pratique se fondent soit sur des heuristiques, soit sur une traduction en problème SAT et appel d’un SAT-solveur. Le bon résolveur est celui qui réussira à résoudre efficacement les cas rencontrés en pratique. Pour revenir à Python, il y a aujourd’hui trois résolveurs de dépendances principaux pour les paquets Python.
Le premier est celui de pip, qui est implémenté dans resolvelib. Il utilise des heuristiques relativement simples. Historiquement, il s’est construit sur une contrainte forte : jusqu’à récemment (PEP 658), il n’y avait aucun moyen sur PyPI de télécharger seulement les métadonnées d’un paquet sans télécharger le paquet entier. Donc, il n’était pas possible d’obtenir tout le graphe de dépendances entier avant de commencer la résolution, car cela aurait nécessité de télécharger le code entier de toutes les versions de chaque dépendance. Or, il n’y a aucun solveur SAT existant (à ma connaissance) qui permette de modifier incrémentalement le problème. Par conséquent, pip était de toute façon forcé d’adopter une stratégie ad-hoc. La contrainte a été levée, mais l’algorithme est resté.
Le deuxième résolveur est celui de Conda. (En fait, le résolveur est en train de changer, mais l’ancien et le nouveau sont similaires sur le principe.) Contrairement à pip, Conda télécharge à l’avance un fichier qui donne les dépendances de chaque version de chaque paquet, ce qui lui permet de traduire le problème de résolution entier en problème SAT et d’appliquer un solveur SAT.
Enfin, le troisième résolveur fait partie de Poetry. Si j’ai bien compris ceci, il utilise l’algorithme PubGrub, qui ne traduit pas le problème en SAT, mais le résout plutôt avec une méthode inspirée de certains solveurs SAT.
En pratique, dans mon expérience, le solveur de pip se montre rapide la plupart du temps (sauf dans les cas vraiment complexes avec beaucoup de dépendances et de contraintes).
Toujours dans mon expérience, la résolution de dépendances dans Conda est en revanche franchement lente. À sa décharge, je soupçonne que le résolveur lui-même n’est pas spécialement lent (voire, plus rapide que celui de pip ? je ne sais pas), mais comme Conda a pour principe de ne prendre quasiment rien dans le système, en ayant des paquets comme wget, freetype, libxcb, pcre2, etc. etc. etc., certains paquets ont un nombre absolument effrayant de dépendances. Par exemple, il y a quelque temps, j’ai eu à demander à conda-lock un environnement satisfaisant les contraintes suivantes :
Sur mon ordinateur, il faut environ 7 minutes pour que Conda calcule l’environnement résultant — j’insiste sur le fait que rien n’est installé, ce temps est passé uniquement dans le résolveur de dépendances. Le lock file créé contient environ 250 dépendances (!).
À titre illustratif : « Conda has gotten better by taking more shortcuts and guessing things (I haven't had a 25+ hour solve in a while) » — Henry Schreiner
Quant au résolveur de Poetry, même si je n’ai jamais utilisé sérieusement Poetry, je crois savoir que sa lenteur est l’une des objections les plus fréquentes à cet outil. Voir par exemple ce bug avec 335 👍. (Je trouve aussi révélateur que sur les premiers résultats renvoyés par une recherche Google de « poetry dependency resolver », une moitié environ se plaigne de la lenteur du résolveur.)
D’un autre côté, le solveur de Poetry n’est appelé que lorsque le lock file est mis à jour, donc beaucoup moins souvent que celui de pip ou même Conda. Il y a un vrai compromis à faire : le résolveur de Poetry se veut plus précis (il est censé trouver plus souvent une solution avec des versions récentes), mais en contrepartie, la mise à jour du lock file peut prendre, apparemment, une dizaine de minutes dans certains cas.
Conclusion et avis personnels
Je termine en donnant mes choix très personnels et partiellement subjectifs, avec lesquels tout le monde ne sera pas forcément d’accord.
D’abord, il faut une manière d’installer des outils en ligne de commande distribués sous forme de paquets Python. Il est sage de donner à chacun son environnement virtuel pour éviter que leurs dépendances n’entrent en conflit, ce qui peut arriver très vite. Pour cela, on a essentiellement le choix entre pipx, ou créer à la main un environnement virtuel à chaque fois. Sans hésiter, je choisis pipx.
(Il y a un problème de boostrap parce que pipx est lui-même un outil du même genre. La solution consiste à l’installer avec un paquet système, que la plupart des distributions fournissent, normalement sous le nom python3-pipx.)
Ensuite, pour travailler sur un projet, on a le choix entre utiliser build et twine à la main pour générer la sdist et le wheel et les distribuer sur PyPI, ou bien utiliser un outil plus unifié, soit Flit, soit Poetry, soit PDM, soit Hatch. Dans le premier cas, on peut utiliser n’importe quel build backend, dans le deuxième, on est potentiellement restreint au build backend associé à l’outil unifié (c’est le cas avec Flit et Poetry, mais pas avec PDM, et plus avec Hatch depuis très récemment).
Parlons d’abord du build backend. À vrai dire, lorsque les builds backends ont été introduits (par la PEP 517, voir dépêche précédente), la motivation était largement de permettre l’émergence d’alternatives à setuptools au vu du triste état de setuptools. L’objectif est atteint, puisqu’il y a désormais des alternatives mille fois meilleures. L’ennui, c’est qu’il y a aussi un peu trop de choix. Donc, comparons.
D’abord, il y a setuptools. Sa configuration est franchement compliquée, par exemple je ne comprends pas précisément les douze mille options de configuration qui contrôlent les modules qui sont inclus dans les wheels. De plus, setuptools est vraiment excessivement verbeux. Dans le dépôt de Pygments, un module dont je suis mainteneur, python -m build | wc -l comptait 4190 lignes de log avec setuptools, à comparer à 10 lignes depuis que nous sommes passés à hatchling. Mais surtout, le problème avec setuptools, c’est qu’il y a mille et une fonctionnalités mutantes dont on ne sait pas très bien si elles sont obsolètes, et la documentation est, pour moi, tout simplement incompréhensible. Entendons-nous bien : j’ai beaucoup de respect pour les gens qui maintiennent setuptools, c’est absolument essentiel vu le nombre de paquets qui utilisent setuptools parce que c’était historiquement le seul outil, mais aujourd’hui, peu contestent que setuptools est moins bon qu’à peu près n’importe quel build backend dans la concurrence, et on ne peut pas le simplifier, justement à cause de toute la compatibilité à garder.
Alors… Flit ? Pour les débutants, ce n’est pas mal. Mais la force de Flit, son inflexibilité, est aussi son défaut. Exemple ici et là où, suite à un commentaire de Ploum sur la dépêche précédente, je l’ai aidé à résoudre son problème de packaging, dont la racine était que Flit ne permet tout simplement pas d’avoir plusieurs modules Python dans un même paquet.
Alors… Poetry-core ? PDM-backend ? Hatchling ? Les différences sont moins marquées, donc parlons un peu des outils unifiés qui leur sont associés.
D’abord, que penser de Poetry ? Je précise que ne l’ai jamais utilisé moi-même sur un vrai projet. À ce que j’en ai entendu, la plupart de ceux qui l’utilisent l’apprécient et le trouvent plutôt intuitif. Par ailleurs, comme décrit plus haut, il a son propre résolveur de dépendances, et celui-ci est particulièrement lent au point que la génération du lock file peut prendre du temps. Soit. Mais je suis un peu sceptique à cause de points plus fondamentaux, notamment le fait que les dépendances de votre générateur de documentation contraignent celles de votre projet, ce que je trouve assez idiot. Je recommande aussi ces deux posts très détaillés sur le blog d’Henry Schreiner : Should You Use Upper Bound Version Constraints? et Poetry versions. Pour faire court, Poetry incite fortement à mettre des contraintes de version maximum (comme jinja2 < 3), ce qui est problématique quand les utilisateurs de Poetry se mettent à en abuser sans s’en rendre compte. Et il a aussi des opinions assez spéciales sur la résolution de dépendances, par exemple il vous force à mettre une contrainte < 4 sur Python lui-même dès qu’une de vos dépendances le fait, alors que tout projet Poetry le fait par défaut. J’ajoute le fait qu’on ne peut pas utiliser un autre build backend avec Poetry que Poetry-core. En corollaire, on ne peut pas utiliser Poetry sur un projet si tout le projet n’utilise pas Poetry, ce qui implique de changer des choses pour tous les contributeurs (alors que PDM et Hatch peuvent fonctionner avec un build backend différent). C’est pour moi un gros point noir.
Alors… PDM ? Honnêtement, je n’en ai pas assez d’expérience pour juger vraiment. Je sais qu’il corrige la plupart des défauts de Poetry, mais garde le « défaut du générateur de documentation ».
Alors… Hatch ? C’est celui que j’utilise depuis quelques mois, et jusqu’ici, j’en suis plutôt satisfait. C’est un peu dommage qu’il n’ait pas encore les lock files, mais je n’en ai pas besoin pour mes projets.
Je n’utilise pas pyenv. Déjà avant Hatch, je trouvais qu’il représentait trop de travail à configurer par rapport au service rendu, que je peux facilement faire à la main avec ./configure && make dans le dépôt de Python. Et depuis que j’utilise Hatch, il le fait pour moi, sans avoir à compiler Python.
De même, je n’utilise plus tox, je fais la même chose avec Hatch (avec la nuance que si j’ai déjà tanné mes co-mainteneurs pour remplacer make par tox, j’hésite à re-changer pour Hatch…). J’ai fini par me méfier du format INI, qui est piégeux (c’est subjectif) et mal spécifié (il y en a mille variantes incompatibles).
Donc, en résumé, j’utilise seulement deux outils, qui sont pipx, et Hatch. (Et j’espère n’avoir bientôt plus besoin de pipx non plus.) Mais si vous avez besoin de lock files, vous pourriez remplacer Hatch par PDM.
Je termine la comparaison avec un mot sur Conda. À mon avis, entre écosystème Conda et écosystème PyPI, le choix est surtout pragmatique. Qu’on le veuille ou non, l’écosystème Python s’est historiquement construit autour de PyPI, qui reste prédominant. Malheureusement, la réponse de Conda à « Comment installer dans un environnement Conda un paquet PyPI qui n’est pas disponible au format Conda ? » est « Utilisez pip, mais à vos risques et périls, ce n’est pas supporté », ce qui n’est pas fantastique lorsque l’on a besoin d’un tel paquet (cela arrive très vite). D’un autre côté, pour le calcul scientifique, Conda peut être plus adapté, et il y a des pans entiers de ce domaine, comme le géospatial, qui fonctionnent avec Conda et ne fonctionnent pas du tout avec PyPI.
J’espère que ce très long panorama était instructif et aidait à y voir plus clair dans l’écosystème. Pour la troisième dépêche, je vous proposerai un focus sur la distribution des modules d’extension écrits dans des langages compilés, sur ses difficultés inextricables, et sur les raisons pour lesquelles le modèle de Conda en fait une meilleure plateforme que PyPI pour ces extensions.
Marco 'Lubber' Wienkoop pour son travail sur Fomantic-UI, un chouette framework CSS que nous utilisons dans canaille. Fomantic-UI est aussi utilisé par d'autres outils sur lesquels nous comptons, comme Forgejo.
Hsiaoming Yang pour son travail sur authlib, une bibliothèque python d'authentification que nous utilisons dans canaille.
Playwright: python testing for front end apps by Felix ?
Django ORM by ???
Install party - aider au setup Python / Conda / Django …
Préparer un talk pour le Meetup / PyCon / DevFest / …
Lightning Talks non-préparés en avance
Barcamp – on choisi 5 sujets ensemble, on se divise en petits groupes pour en parler
Sponsors
Merci a nos sponsors qui nous permettent une organisation avec beaucoup plus de confort et de snacks! Onepoint, Lengow, Wild Code School, Acernis Innovation
Organisateurs
Nantes a besoin de vous - vous pouvez aider a organiser un seul Meetup, la série, la publicité, …
Emploi ouvert aux contractuels (Catégorie A+ ), deux jours de télétravail par semaine.
Descriptif de l’employeur
Le service à compétence nationale (SCN) dénommé « Pôle d’Expertise de la Régulation Numérique » (PEReN), a pour mission d’apporter son expertise et son assistance techniques aux services de l’État et autorités administratives intervenant dans la régulation des plateformes numériques. Il est placé sous l’autorité des ministres chargés de l’économie, de la communication et du numérique et rattaché au Directeur Général des Entreprises pour sa gestion administrative et financière.
Le PEReN réunit les expertises humaines et ressources technologiques principalement dans les domaines du traitement des données, de la data science et de l’analyse algorithmique. Il fournit son savoir-faire technique aux services de l’État et autorités administratives qui le sollicitent (par exemple, Autorité de la concurrence, ARCOM, CNIL, ARCEP, ou directions ministérielles telles que la DGE, la DGCCRF, la DGT ou la DGMIC) en vue d’accéder à une compréhension approfondie des écosystèmes d’information exploités par les grands acteurs du numérique.
Le PEReN est également un centre d’expertise mutualisé entre les différents services de l’État qui conduit une réflexion sur la régulation des plateformes numériques et les outils de cette régulation, dans une approche à la pointe des avancées scientifiques. Il a également vocation à animer un réseau de recherche dédié à la régulation des grandes plateformes numériques et peut être amené à réaliser à son initiative des travaux de recherche académique liés aux différentes thématiques.
Description du poste
L’administratrice (ou administrateur) système participe aux évolutions fonctionnelles et de sécurité du système d’information du PEReN, permettant à ce service de développer et d’opérer les outils nécessaires à la réalisation de ses missions. En particulier, elle ou il :
assure une veille en terme de sécurité informatique et applique les mises à jour adéquates
gère l’infrastructure et les services existants
développe et met en production la configuration de nouveaux services pour répondre aux besoins des utilisateurs
analyse et corrige les problèmes signalés par les utilisateurs ou par les alertes de supervision
participe aux rituels du PEReN et s’implique dans l’équipe de gestion de l’infrastructure (3 membres).
Description du profil recherché
connaissance des outils de développement (pratique usuelle de git),
bonne connaissance de l’administration de systèmes Linux/Debian et des processus de CI/CD,
bonne connaissance des outils d’Infrastructure / Config as Code (Ansible),
maîtrise des enjeux de sécurité informatique dans un environnement GNU/Linux,
expérience(s) au service d’équipe(s) de développement logiciel (Python).
Les expériences suivantes seront considérées comme des atouts sans pour autant être strictement requises dans le contexte de cette fiche de poste :
la participation à des projets open-source (en tant que mainteneur, contributeur, ou encore d’animation de communauté, …).
comprendre les droits et obligations liés aux licences logicielles et les sujets liés à la propriété intellectuelle
Je continue avec Python ei j’ai écrit un Player qui utilise espeak pour vocaliser un texte.
Dans une petite interface tkinter j’ai “bindé” des raccourcis pour réaliser des fonctions.
Je voudrais aller plus loin et récupérer le focus clavier des icones du bureau comme on le ferait avec les widgets de tkinter.
Evidemment ce n’est pas avec tkinter que je ferais cela.
J’étudie le module Xlib et je tourne autour uniquement du type window sans deviner où trouver les objets comme les icones.
Une icone pourrait-elle être une window “réduite” ?
Pour ce dernier meetup de 2023, nous vous proposons un format Lightning Talks !
Si vous souhaitez parler de quelque chose, d’une bibliothèque, d’un outil, d’un projet… N’hésitez pas à me contacter pour que je rajoute sur la liste des sujets
Nous serons accueillis par Lowit (métro Part-Dieu).
Bon c’est à la wikidata : chaque objet a un identifiant opaque. Donc ma fonction c’est Z12391, elle est de type Z8, son implémentation en Python c’est Z12392, elle a un seul test : Z12393, elle prend en paramètre Z6 et renvoie Z6. J’ai du mal à m’y faire mais je crois comprendre le besoin d’internationalisation derrière.
Rien que sur mes petits “projets”, je finis par avoir un conftest.py de plusieurs centaines de lignes et des noms de pytest.fixture qui ne veulent rien dire.
Je suis à la recherche de ressources (idéalement, PAS des tutoriels vidéo) sur les bonnes pratiques autour de pytest et conftest
et plus particulièrement sur la gestion des fixtures.
Par exemple :
Comment organiser ceux-ci (dans des fichiers et/ou une arborescence ?) plutôt que de les laisser dans un conftest.py à rallonge.
Est-il pertinent d’utiliser le même fixture pour plusieurs tests ?
Quelles règles de nommage adopter ?
…
Si vous avez des idées, des conseils de lecture, et pourquoi pas des exemples de projets qui ont mis en place de trucs autour de conftest (Si en plus, je peux aider à des trucs simples pour progresser autour de pytest et du reste), n’hésitez pas
Moi qui suis hésitant à tester d’autres backends que setuptools, je suis content de voir qu’il est toujours premier.
Bon pour combien de temps je l’ignore… en tout cas c’est très cool d’avoir ce genre de graph !
Ou sans ceux qui ont moins de 5 utilisations (qui peuvent être des petits wrappers persos typiquement) :
Source (et retoots bienvenus) :
Je suis un peu déçu que flit ne fasse pas plus, il colle bien à la philosophie « ne faire qu’une seule chose mais le faire bien », et pendant qu’on y est il colle bien à « keep it simple » aussi (en essayant pas de gérer les venvs, les dépendances, la vie, et le reste en même temps). S’il y en a un que j’essayerai plus volontiers que les autres (et que j’ai déjà essayé j’avoue) c’est bien celui-là.
Ce sujet est ma tentative de faire connaître pipenv dont on parle peu, j’ai l’impression, alors même qu’on continue de parler de venv et de comment lui tordre le bras — parce que, oui, venv a des défauts notoires. Il serait grand temps que venv prenne la retraite pour laisser place à ce qui se fait de mieux, actuellement.
pipenv : petite intro
Extrait de la note d’intention (non traduite en français) publiée sur le site officiel du projet pipenv :
Pipenv: Python Dev Workflow for Humans
Pipenv is a Python virtualenv management tool that supports a multitude of systems and nicely bridges the gaps between pip, python (using system python, pyenv or asdf) and virtualenv. Linux, macOS, and Windows are all first-class citizens in pipenv.
Pipenv automatically creates and manages a virtualenv for your projects, as well as adds/removes packages from your Pipfile as you install/uninstall packages. It also generates a project Pipfile.lock, which is used to produce deterministic builds.
Pipenv is primarily meant to provide users and developers of applications with an easy method to arrive at a consistent working project environment.
The problems that Pipenv seeks to solve are multi-faceted:
You no longer need to use pip and virtualenv separately: they work together.
Managing a requirements.txt file with package hashes can be problematic. Pipenv uses Pipfile and Pipfile.lock to separate abstract dependency declarations from the last tested combination.
Hashes are documented in the lock file which are verified during install. Security considerations are put first.
J’imagine que ce non-problème à déjà été résolu 200 fois, et qu’on en a déjà parlé un peu, parlons de création et d’activation de venv…
Déjà voilà à quoi ça ressemble chez moi :
Au début : pas de logo Python ça signifie que je ne suis pas dans un venv. Ensuite je tape venv pour créer et activer un venv, mon prompt change avec un logo Python et sa version pour m’indiquer qu’il est activé.
(Oui mon laptop s’appelle seraph et oui j’utilise un thème clair pour mon terminal, oui j’utilise bash. Rohh, c’est pas fini de juger les gens !?)
Donc en ce moment côté création/activation/désactivation de venv j’utilise direnv, avec une petite fonction bash de deux lignes pour se souvenir de ce qu’il faut taper :
de cette manière dès que je cd dans un dossier qui contient un venv, pouf il est activé, et dès que j’en sors pouf il est déactivé. Pour créer un venv dans un dossier j’ai juste à taper venv, c’est le “layout python3” de direnv qui s’occupe de la création et de l’activation. le VIRTUAL_ENV=.venv c’est pour dire à layout python3 où mettre le venv.
Ensuite il me faut une indication que mon venv est activé dans mon prompt, car direnv ne le fait pas. À force de voir des élèves utiliser des prompts “kikoo-lol” je me suis demandé quels caractères unicode ils utilisaient pour faire ces “effets”. Bon bah rien de magique c’est juste 🭮 et 🭬, ou des trucs du genre, avec un peu de couleur.
Et donc une petite fonction bash pour décider s’il faut écrire quelque chose et quoi écrire, injecter ça dans PS1 avec un peu de couleurs et un peu d’unicode, une petite fonte ajoutée contenant un logo Python, et le résultat me convient.
Le code (attention, 42 lignes…):
Ça s’imbrique parfaitement dans emacs avec le module envrc qui met à jour les variables d’environnement au niveau de chaque buffers. Et donc ça marche aussi parfaitement avec lsp-mode, en tout cas avec jedi-language-server qui découvre le venv grâce à la variable d’environnement VIRTUAL_ENV :
J’imagine que ce non-problème à déjà été résolu 200 fois, et qu’on en a déjà parlé un peu, parlons de création et d’activation de venv…
Déjà voilà à quoi ça ressemble chez moi :
Au début : pas de logo Python ça signifie que je ne suis pas dans un venv. Ensuite je tape venv pour créer et activer un venv, mon prompt change avec un logo Python et sa version pour m’indiquer qu’il est activé.
(Oui mon laptop s’appelle seraph et oui j’utilise un thème clair pour mon terminal, oui j’utilise bash. Rohh, c’est pas fini de juger les gens !?)
Donc en ce moment côté création/activation/désactivation de venv j’utilise direnv, avec une petite fonction bash de deux lignes pour se souvenir de ce qu’il faut taper :
de cette manière dès que je cd dans un dossier qui contient un venv, pouf il est activé, et dès que j’en sors pouf il est déactivé. Pour créer un venv dans un dossier j’ai juste à taper venv, c’est le “layout python3” de direnv qui s’occupe de la création et de l’activation. le VIRTUAL_ENV=.venv c’est pour dire à layout python3 où mettre le venv.
Ensuite il me faut une indication que mon venv est activé dans mon prompt, car direnv ne le fait pas. À force de voir des élèves utiliser des prompts “kikoo-lol” je me suis demandé quels caractères unicode ils utilisaient pour faire ces “effets”. Bon bah rien de magique c’est juste 🭮 et 🭬, ou des trucs du genre, avec un peu de couleur.
Et donc une petite fonction bash pour décider s’il faut écrire quelque chose et quoi écrire, injecter ça dans PS1 avec un peu de couleurs et un peu d’unicode, une petite fonte ajoutée contenant un logo Python, et le résultat me convient.
Le code (attention, 42 lignes…):
Ça s’imbrique parfaitement dans emacs avec le module envrc qui met à jour les variables d’environnement au niveau de chaque buffers. Et donc ça marche aussi parfaitement avec lsp-mode, en tout cas avec jedi-language-server qui découvre le venv grâce à la variable d’environnement VIRTUAL_ENV :
Je souhaite réaliser une boucle sur les 3 champs de BT0 ou BT1 ou BT2
sachant que le 0,1 ou 2 (de chaque BT) est une variable par exemple i, donc BT[i].
Cette dernière syntaxe ne fonctionne pas. Je n’arrive pas à construire une variable composée de BT et de i
Une fois ce point réglé, je souhaite réaliser une deuxième boucle sur le contenu
de LGx, CLx et GRx en fonction du BT[i] sélectionné.
Bonjour
J’ai développé une application Python en local. Celle-ci dialogue avec une base de données Mysql située chez l’hébergeur Ikoula
Ikoula ne supportant pas Python (du moins sur serveur mutualisé) je cherche un autre hébergeur…le moins cher possible !
L’idéal pour moi serait :
appli Python et base de données chez l’hébergeur à trouver (j’ai vu Pythonanywhere et Hidora, mais c’est très complexe pour moi)
accès à la base de données depuis un navigateur, en l’occurrence via une application PHP
lancement de l’application Python depuis cette appli PHP
Depuis un certain temps l’équipe de Yaal Coop travaille sur Canaille, un logiciel de gestion d’identité et d’accès.
Nous profitons de la fin de travaux financés par la fondation NLNet pour vous raconter l’histoire autour de Canaille.
Au début étaient les annuaires
À Yaal Coop (comme presque partout ailleurs) nous utilisons une palette d’outils qui nous permettent de travailler ensemble.
Emails, fichiers, carnets de contacts, gestion de projet, suivi du temps, comptabilité, intégration continue, collecte de rapports de bugs… la liste est longue.
Pour des raisons de praticité (et de sécurité) on cherche généralement à connecter une telle collection d’outils à un logiciel central qui se charge de la gestion des utilisateur·ices et de leurs accès.
Traditionnellement, c’est LDAP1 qui est utilisé pour cet usage, on parle alors d’annuaire.
Si un outil est connecté à un annuaire, vous n’avez pas besoin de vous y créer un compte, vous pouvez vous connecter en utilisant votre mot de passe habituel, celui que vous avez renseigné dans l’annuaire.
C’est pratique pour vous puisque vous n’avez qu’un unique mot de passe à retenir (ou à oublier), on parle généralement d’inscription unique ou Single Sign On (SSO).
C’est aussi pratique pour les personnes qui gèrent les comptes dans votre organisation, puisqu’elles peuvent créer et révoquer des comptes utilisateur·ices une seule fois pour tous les outils à la fois.
LDAP, c’est vieux et c’est robuste. Pour des logiciels, ce sont des qualités.
Les quelques décennies d’expérience de LDAP en font une technologie éprouvée et compatible avec un énorme choix de logiciels.
Mais LDAP, c’est aussi compliqué et austère.
C’est une base de donnée en arbre qui ressemble à peu d’autres choses, la documentation est éparse et absconse, les conventions sont curieuses, pleines d’acronymes angoissants, l’outillage est rare…
Et puis c’est conçu pour les données qui sont lues souvent mais écrites rarement.
Les modèles de données utilisables dans LDAP sont eux aussi peu évolutifs.
Généralement quelques uns sont fournis d’office et permettent de manipuler des attributs de base sur des utilisateur·ices et des groupes.
Et si on veut que son système puisse gérer d’autres attributs comme les couleurs préférées, alors il faut écrire ses propres modèles de données, et on a intérêt à être sûr de soi puisqu’aucun mécanisme de mise à jour des schémas ou de migration des données n’est prévu2.
Si on souhaite ensuite partager ces modèles de données, alors il est conseillé de s’enregistrer à l’IANA3, et de fournir une référence en ligne de ses schémas.
Quand on se plonge dans l’univers de LDAP, on a l’impression qu’une fois mises en place, les installations ne bougent pas pendant des années ;
et donc les personnes qui ont la connaissance fuient l’austérité de cette technologie sans avoir à s’y ré-intéresser (puisque ça fonctionne), et sans trop documenter leurs aventures.
J’exagère à peine, si on compare4 le nombre de questions sur stackoverflow, pour ldap on en dénombre environ 1000 tandis que postgresql ou mongodb en comptent environ 14 000 et mysql 45 000.
Puis vint l’authentification unique
Lors de temps de bénévolat à Supercoop5, nous avons notamment travaillé à installer, comme pour chez nous, plusieurs outils numériques de collaboration.
Évidemment tous les outils étaient branchés sur un annuaire LDAP.
Nous nous sommes rendus compte que l’équipe dite de gestion des membres, passait un certain temps à traiter des demandes de réinitialisation de mot de passe, à aider des personnes qui échouaient à utiliser les outils dès les premières étapes de connexion.
Ce constat nous a donc poussé à chercher des outils (libres, évidemment) d’authentification unique et de gestion d’utilisateur·ices, en complément ou remplacement de l’annuaire.
Ce que l’authentification unique ou Single Login Identification (SLI) apporte au SSO fourni par LDAP, c’est que les utilisateur·ices peuvent naviguer entre les outils sans avoir à s’identifier à nouveau.
On peut passer de l’interface mail à son calendrier en ligne sans repasser par l’écran d’identification, tandis qu’avec un simple annuaire, il aurait été nécessaire d’entrer son mot de passe une fois pour chaque outil.
Pour un public non technophile, c’est l’opportunité de se passer de quelques écrans techniques, et limiter les sources d’erreur et de frustration.
Actuellement les protocoles de prédilection pour faire du SLI sont OAuth2 et OpenID Connect (OIDC)6. On note qu’il existe d’autres standards, plus historiques ou bien plus orientés vers les grosses organisations, tels SAML ou CAS.
Les normes OAuth2 et OIDC sont modernes mais bénéficient d’une dizaine d’années de retours d’expérience.
Les outils et les documentations sont nombreuses, la communauté est active, et les standards évoluent en ce moment même grâce au groupe de travail oauth de l’IETF7.
Mais là encore tout n’est pas rose et OIDC vient avec son lot de difficultés.
Tout d’abord, OAuth2 et OIDC c’est environ 30 standards complémentaires, dont certains contredisent et apportent des corrections sur des standards antérieurs.
Tous ne sont pas pertinents dans l’usage que nous visons, mais ne serait-ce que simplement comprendre le fonctionnement de ceux qui nous intéressent demande déjà du temps et de la réflexion.
Les implémentations d’OIDC — par les logiciels de gestions d’utilisateur·ices, ou par les outils qui s’y branchent — sont généralement partielles, et parfois bugguées.
Pour ne rien arranger, les gros acteurs de l’industrie prennent délibérément des libertés avec les standards et forcent le développement de spécificités pour être compatibles avec leurs logiciels.8
Mais revenons à nos moutons. Pour Supercoop nous souhaitions trouver un outil qui soit d’une grande simplicité à plusieurs points de vue :
pour les utilisateur·ices : les coopérateur·ices du magasin. L’utilisation doit se faire sans aucune connaissance technique préalable, et sans assistance ;
pour l’équipe de gestion des membres du magasin. Nous voulions un outil simple à prendre en main.
Un apprentissage de l’outil est envisageable mais non souhaitable.
En effet le magasin fonctionnant grâce à la participation de bénévoles, il y a un enjeu à ce que le temps passé soit le moins rébarbatif possible, afin de ne décourager personne.
enfin pour l’équipe informatique, il y a là aussi un enjeu de simplicité.
Si les outils déployés pour le magasin requièrent trop de connaissances, nous aurons des problèmes pour trouver des gens compétents pour nous aider.
Et la nature de la participation du magasin fait que les coopérateur·ices contribuent ponctuellement, tournent souvent, et n’ont pas nécessairement le temps d’apprendre toute la pile technique mise en œuvre.
Idéalement, l’équipe informatique devrait pouvoir administrer l’outil que nous recherchons avec une connaissance superficielle des protocoles concernés.
Et vues les descriptions que j’ai faites de LDAP et OIDC, vous commencez à cerner une partie du problème.
Notre recherche nous a montré qu’il existait une quinzaine d’outils pouvant répondre aux besoins que nous avons identifiés.
Pour autant, aucun outil ne nous semblait cocher toutes les cases.
En fait, par leur nature, les outils de gestion d’identité et d’autorisations ou Identity and Authorization Management (IAM) sont destinés à de grosses organisations, qui peuvent donc s’offrir les services de personnes qualifiées pour s’en occuper.
Ce sont donc des logiciels lourds mais puissants, supportant beaucoup de protocoles qui ne nous concernent pas, requiérant une certaine technicité pour l’installation, la maintenance ou la gestion.
Motivés par notre curiosité nous avons fini par bricoler quelque chose dans notre coin.
Canaille
Quelques temps après, notre prototype a grossi et a donné Canaille.
Les fonctionnalités
Canaille est un logiciel qui permet de gérer des utilisateur·ices et des groupes d’utilisateur·ices, de créer, modifier et administrer des comptes, de réinitialiser des mots de passes perdus, d’inviter des nouveaux utilisateur·ices.
En plus de ça, Canaille implémente OIDC et fournit donc une authentification unique aux utilisateur·ices vers d’autres outils. Son interface est personnalisable et … c'est tout.
Nous tâchons de garder le périmètre fonctionnel de Canaille assez restreint pour qu'il reste simple.
Canaille peut être utilisé pour :
apporter une interface web épurée de gestion des comptes utilisateur·ices au dessus d’un annuaire LDAP.
L’outillage autour de LDAP étant comme on l’a dit plutôt épars, Canaille peut être utilisé pour modifier facilement un profil utilisateur·ice ou réinitialiser un mot de passe perdu.
amener du SLI sur un annuaire LDAP.
Si vous avez historiquement un annuaire LDAP et que vous voulez moderniser votre pile logicielle avec une couche d’authentification unique, Canaille peut s’intégrer discrètement au-dessus de votre installation existante sans rien modifier,
et vous laisser le temps de prévoir – ou pas – une migration.
développer des applications utilisant OIDC.
Si, comme nous, vous faites du développement logiciel et travaillez régulièrement sur des applications nécessitant une connexion OIDC, alors vous pouvez utiliser Canaille dans votre environnement de développement.
Canaille étant très léger, c'est désormais pour nous la solution de choix comme IAM pour travailler sur nos applications.
tester des applications utilisant OIDC.
Nous utilisons aussi Canaille dans des suites de tests unitaires python, grâce à pytest-iam.
Ce greffon de pytest embarque Canaille, le prépare et l’instancie pour que vos suites de tests puissent effectuer une réelle connexion OIDC.
Les choix techniques
Canaille est un logiciel écrit en python, avec flask pour le côté serveur et fomantic-ui et htmx pour la partie client utilisateur·ice.
Nous apprécions la simplicité de python et celle de flask et croyons sincèrement que ce sont autant de freins en moins à la participation d’éventuels contributeur·ices.
Nous avons été sidérés par notre découverte récente de HTMX, qui en deux mots nous permet de créer des pages web dynamiques sans plus écrire de Javascript.
Un langage en moins dans un projet c'est autant de complexité en moins.
Sous le capot, Canaille peut se brancher au choix à un annuaire LDAP ou à une base de données SQL.
Les techniques de développement
Nous utilisons Canaille en production, à Supercoop donc où il est utilisé pour gérer environ 1800 membres, mais aussi chez nous à Yaal Coop et au sein de notre offre mutualisée de services Nubla, et sur des instances dédiées Nubla Pro.
Cette large base d’utilisateur·ices nous permet de récolter des retours d’expérience, et nous améliorons le logiciel au fur et à mesure des besoins.
Canaille suit le principe du développement dirigé par les tests, ou Test Driven Development (TDD), dans la mesure du possible.
La couverture du code est de 100% (branches comprises), et c’est un pré-requis pour toute contribution.
En plus d’avoir confiance dans nos tests, cela nous a permis à plusieurs reprises de simplement supprimer du code qui n’était plus utilisé, et simplifier d’autant le projet.
On débusque plus facilement les bugs quand il y a moins de code.
Canaille utilise tous les analyseurs et formatteurs de code source modernes, au sein de pre-commit, et les test unitaires sont joués sur toutes les versions de Python officiellement supportées.
Enfin la traduction de l’interface de Canaille se fait de manière communautaire sur weblate.
Contributions
Comme la plupart des logiciels modernes, Canaille réutilise des bibliothèques logicielles existantes pour que nous n’ayions pas à ré-inventer ce que d’autres ont déjà fait.
Lorsque nous rencontrons des erreurs dans ces bibliothèques, nous suivons une stratégie qui consiste à implémenter les corrections à la fois dans Canaille et dans les logiciels.
D’une part nous amenons donc les corrections dans Canaille, de manière temporaire et efficace.
Mais tout ce code que nous écrivons nous-même est un fardeau de maintenance à venir, nous tâchons donc en parallèle de proposer des solutions mieux conçues aux mainteneur·euses desdites bibliothèques, en discutant avec eux en amont.
C'est pour nous la garantie que les briques logicielles sur lesquelles nous nous appuyons sont pérennes, et c’est un moyen de contribuer à cet écosystème nécessaire qu’est celui du logiciel libre.
Par ailleurs lorsque nous souhaitons des fonctionnalités supplémentaires dans ces bibliothèques, nous expliquons nos motivations aux mainteneur·euses et parfois proposons des implémentations. Nous avons par exemple développé le support des spécifications OIDC RFC7591 et RFC9068 dans authlib, une brique utilisée pour la partie OIDC de Canaille.
Le résultat de ces efforts est visible dans nos articles trimestriels de contributions à des logiciels libres.
Le hasard des contributions nous a amené à partager la maintenance de certaines des bibliothèques que nous utilisons, comme wtforms qui permet de gérer les formulaires dans Canaille, ou encore nextcloud-oidc-login et OpenIDConnect-PHP qui permettent à nextcloud (le gestionnaire de fichiers proposé par Nubla) de se connecter à Canaille.
Nous sponsorisons aussi modestement tous les mois les mainteneur·ices de fomantic-ui et authlib.
L’aide de la fondation NLNet
Canaille a été développé pour répondre aux besoins spécifiques que nous avons rencontrés : à l’origine Canaille s’interfaçait donc seulement avec des annuaires LDAP.
L’écosystème évoluant, nous nous sommes aperçus que de plus en plus de logiciels étaient capables de communiquer avec OIDC en plus de LDAP.
In fine, si plus aucun des logiciels que nous utilisons ne dépend directement de LDAP, alors nous pouvons envisager un outil de remplacement avec lequel nous nous sentons plus à l’aise.
Pour aller dans cette direction, nous avons sollicité fin 2022 l’aide de 7 000€ au fond NGI Zero Entrust de la fondation NLNet pour financer le support de travaux dans Canaille :
pytest-iam, un outil qui permet de préparer et lancer une instance de Canaille, afin d'être utilisée dans des suites de tests unitaires avec pytest.
Ces développements ont été achevés fin novembre 2023, et ont été la source de nombreux réusinages, de nombreuses corrections de bogues, et plus généralement d’une meilleure conception et d’une meilleure fiabilité de Canaille.
Nous sommes particulièrement reconnaissant·es à la fondation NLNet de nous avoir permis de travailler sur notre outil, et de nous aider à contribuer à notre échelle à l’écosystème du logiciel libre.
Et la suite ?
Passer en version bêta
Nous avons depuis le début gardé Canaille en version alpha, nous sommes à l’heure actuelle à la version 0.0.35.
Nous indiquions que le logiciel était impropre aux environnements de production.
C’était pour nous un moyen de pouvoir expérimenter dans notre coin sans avoir à se soucier de rétrocompatibilité.
Nous souhaitons sévir une dernière fois en remettant à plat la manière de configurer Canaille avant de passer Canaille en bêta, et lever les mises en garde d’usage.
Nous regroupons les tickets pour le passage en version bêta de Canaille dans ce jalon.
Passer en version stable
Les travaux que nous immaginons réaliser pour passer d’une version bêta à une version finale sont principalement des efforts de documentation, d’installation et de prise en main de Canaille.
L’objectif est pour nous de rendre Canaille facile d’accès, afin de créer de l’usage et collecter des retours utilisateurs.
Nous regroupons les tickets pour le passage en version stable de Canaille dans ce jalon.
Et au-delà…
Pour l’avenir nous souhaitons travailler sur le provisionnement, en implémentant la norme SCIM.
Ce travail permettra de découpler l’authentification des utilisateur·ices et la création des comptes utilisateur·ices.
En effet aujourd’hui dans les outils externes que nous avons branchés à Canaille, les comptes des utilisateur·ices sont créés à la première connexion.
Cela peut s’avérer problématique dans certaines situations : par exemple si l’on veut partager des fichiers dans Nextcloud avec un utilisateur·ice qui ne s’est encore jamais connecté.
SCIM permet aussi de supprimer des comptes utilisateur·ices sur ces outils externes, tâche qui doit être réalisée plus ou moins manuellement à l’heure actuelle.
Parmi les chantiers à venir, nous voyons aussi le travail sur la déconnexion unique, ou Single Log-Out (SLO).
C’est un développement qui devra être réalisé en premier lieu dans authlib, et qui permettra aux utilisateur·ices de se déconnecter de tous les outils en une seule action.
C’est une fonctionnalité qui apportera de la sécurité et du confort d’utilisation.
Enfin, nous aimerions travailler sur une gestion avancée des groupes d’utilisateur·ices et des droits, ainsi que sur des mécanismes d’authentification multi-facteurs.
Si tout cela vous intéresse, vous pouvez tester Canaille immédiatement sur notre interface de demo. Canaille est évidemment ouvert aux contributions, alors si vous souhaitez nous aider dans tout ça, la porte est ouverte !
enfin, un logiciel qui implémente LDAP, ici je parle indifféremment du protocole ou de ses implémentations ↩
ce que nous avons fait, notre numéro à l’IANA est le 56207↩
d’accord, la comparaison est fallacieuse puisque ces différentes bases de données ne répondent pas aux mêmes besoins, mais l’ordre de grandeur est révélateur de l’intérêt autour de ces technologies ↩
le supermarché coopératif de l’agglomération bordelaise ↩
Since a while, the Yaal Coop team is working on Canaille, an identity and authorization management software (or IAM).
At the occasion of the end of an endeavour that benefited the help of the NLNet foundation, we want to tell the history around Canaille.
At first was the Single Sign On
At Yaal Coop (like anywhere else) we use a bunch of tools to work together as a team.
Emails, files, address book, project management, time tracking, accountability, continuous integration, bug reporting… and the list goes on.
For the comfort of use (and for security), those tools are generally plugged to a central software that manages user accounts and accesses.
Usually, LDAP[ref]or more exactly, a software implementing the LDAP protocol[/ref] is used for that, and this is called a directory.
If a service is connected to a directory, you do not need to register to that service, you can just use your usual password, the one you set in the directory.
It is convenient for you since you just have one single password to remember (or to forget). This is what is called Single Sign On (SSO).
It is also convenient for people managing the user accounts in your organization, as they can create and revoke accounts for all the plugged services at a time.
LDAP is old and robust, and for software those are qualities.
The few decades of experience behind LDAP make it a battle-tested technology compatible with a large selection of services.
But unfortunately LDAP is also complicated and abstruse.
Its tree model looks like few other things you might know, the documentation is rare and obscure, conventions are intriguing, with a lot of distressing acronyms, tooling is sparse…
Also, this was made for data oftenly read but rarely written.
The data models LDAP offers cannot easily evolve.
Generally, the provided ones allow to handle basic attributes on users and groups.
If you want to manage more advanced aspects like the favourite color of users, then you need to write your own data models[ref]that are called schemas[/ref].
And you'd better be confident when you do it, because no update mechanism is provided for neither data nor data models[ref]at least with OpenLDAP[/ref].
Then, if you wish to share your data models with the world, it is advised that your register at the IANA[ref]what we did, our IANA number is 56207[/ref], and provide an online reference of your schemas.
When we took a close look at the LDAP universe, we had the impression that once set up, LDAP installation were left alone for years ;
like if people who might had knowledge to share had flew the austerity of that technology without documenting their adventures, and without need to returning to it because it just works.
I am barely exagerating, if we have a look[ref]OK, the comparison has limits since those different databases are not used for the same needs, but the magnitude of the numbers says something about the interest around those technologies[/ref] at the number of questions in stackoverflow, ldap has approximately 1000 questions, while postgresql or mongodb have around 14.000, and mysql has 45.000.
Then came the Single Log In
During our volunteer time at Supercoop[ref]a cooperative supermarket near Bordeaux, France[/ref], among other tasks, we worked to install collaboration software, like we did for ourselves.
Obviously, those tools were plugged on a LDAP directory.
We noticed that the members management team of the supermarket was spending a certain amount of time dealing with user support, notably with password reset demands.
People were failing to use the tools we deployed for them as soon as the first login step.
This verdict pushed us to look for Single Login Identification (SLI) software (free and open-source, obviously), in replacement or in addition to our historical directory.
What SLI brings, is that users can navigate between services without having to sign in every time.
They can switch from the webmail interface to the calendar without having to make a step by the authentication screen, while with a simple directory, they would have to enter their password once for each service.
For a non tech-savvy public, this is the opportinity to get rid of several technical screens, limit the error sources and the frustration.
Currently the predilection protocols for SLI are OAuth2 and OpenID Connect (OIDC)[ref]for sake of simplicity, I will keep to OIDC[/ref].
(There are other existing standards, more historical or more focused towards big organizations, like SAML or CAS.)
The OAuth2 and OIDC specifications are recent but they still benefit from a decade of feedback.
Tooling and documentation are numerous, the community is alive and active, and standards are still evolving at this day with the work of the IETF oauth workgroup.
But here again, everything is not perfect and OIDC comes with its difficulties.
First of all, OAuth2 and OIDC make about 30 different standards, some of which contradicting or bringing corrections upon prior standards.
All of those are not pertinent for what we want to do, but simply understanding how work the few standards that actually interests us already requires a certain amount of time and work.
The OIDC implementations – by the IAMs or the services connected to IAMs – are sometimes partial or bugged.
To make nothing better, big industry actors sometimes deliberately take some liberties with the standards, and make some additional developments a requirements to be compatible with their software.[ref]They can also be a driving force for new features, like RFC7628 or RFC9068 that were commonly used before they became standards.[/ref]
Let's get back on topic. For Supercoop, we wanted to find a tool that would be utterly simple from several point of views:
for the final users: the volunteers of the shop.
They must be able to use the tool without any prior technical knowledge, and without help;
for the members management team.
We wanted a relatively simple tool where a little bit of learning would be acceptable but not desirable.
As the cooperative supermarket operates with benevolent labour, we want to take care of the volunteer time and avoid disagreeable tasks.
for the IT team.
Here again simplicity is at stake.
If there is a too steep learning curve on the tools the supermarket uses, there will be an issue for recruiting competent people to help us.
The nature of the benevolent participation of the shop make that volunteers are helping punctually, and rarely engage for years, so they do not always have the time to learn the whole technical stack.
Ideally the IT team should be able to administrate the tool we are seeking with a superficial knowledge of the underlying protocols.
And with the descriptions I made of LDAP and OIDC, you start to make an idea of the problem we have.
Our search showed us that there was a dozen of tools that could answer our needs.
However, none was fitting all our expectations.
Actually, by their very nature, the IAM softwares are intended to big organizations, that consequently can afford to hire competent people to administrate them, so complexity is not really an issue.
Those are mostly big powerful software, with a large protocol compatibility not pertinent for us, and requiring some technical knowledge for installation, maintainance and administration.
Pushed by our curiosity, we finally hacked something on our side.
Canaille
A few times later, our prototype had grown bigger and became Canaille.
The features
Canaille is a user and group management software that allows account creation, edition, administration, registration, forgotten password reset, user invitation etc.
In addition, Canaille implements OIDC and provide a SLI layer for other services. Its interface is customizable and… that's all.
We try to keep the functionnal scope tight so Canaille can stay simple to maintain and to operate.
Canaille can be used for:
bringing an account edition interface on top of a LDAP directory.
The tooling around LDAP being quite sparse, Canaille can be a convenient option and allow utilities like password reset.
bringing a SLI layer on top of a LDAP directory.
If your organization has a historical LDAP directory and you want to modernize your stack with SLI, Canaille can discretely integrate your existing stack (almost) without modifying anything, and let you the time to prepare (or not) a migration.
develop applications relying upon an OIDC server.
If, like us, you are doing software development and regularly work on applications that needs to connect to a OIDC server, then you can use Canaille in your development environment.
Canaille being very light, this is now our tool of choice to work on client applications.
test applications relying upon an OIDC server.
We also use canaille in unit tests suites, with pytest-iam.
This is a pytest plugin that configures and run a Canaille instance so your unit tests suite can achieve actual OIDC connections.
The technical choices
Canaille is written in Python, with Flask for the backend and fomantic-ui and htmx for the frontend.
We like the simplicity of Python and Flask, and strongly believe those are arguments that make contributions easier and increase software longevity.
We have been shocked by our discovery of HTMX earlier this year, that in short allows us to build dynamical pages without writting Javascript.
One language less is as much less complexity in the project.
Under the hood, Canaille can be plugged to a LDAP directory or a SQL database.
The development techniques
We use Canaille in production, at Supercoop where it is used to manage 1800 users, but also in our own stack in our Nubla mutualized cloud services, and on dedicated Nubla Pro instances.
That large userbase allows us to collect user feedback, and we improve Canaille gradually in reaction to demands and according to our roadmap.
Cannaille development follows the principles of the Test Driven Development (TDD) when possible.
The code coverage reaches 100% (including branches), and this is a prerequisite for new contributions.
In addition to giving us confidence in our tests, this allowed us to simply delete unused pieces of code.
Bugs are easier to find when there is less code to search them into.
Canaille uses all the modern Python source code linters and formatters, with pre-commit, and the unit tests are run on all the officially supported Python versions.
Finally, the translation of Canaille is done by the community with Weblate.
Contributions
Like most of modern software, Canaille relies on libraries so we don't have to re-invent what is already existing.
At Yaal Coop for all our projects, when we find bugs in libraries, we follow a strategy that consists in implementing fixes both in our code and the libraries at the same time.
At first we patch our code with temporary but functional fixes.
However all that code we write is a maintenance burden to come, so in parallel we discuss with the maintainers of those libraries, and propose better conceived long term fixes.
This is for us a guarantee of the sustainability of those pieces of software we rely upon, and this is a way to contribute to that necessary FLOSS ecosystem.
Once the upstream library is patched, we delete our quick fix.
In the same fashion when we wish additional features in libraries, we discuss our motivations with maintainers and sometimes provide implementations.
We have for instance developped the OIDC specifications RFC7591 and RFC9068 in authlib, a library Canaille uses to deal with OIDC.
The results of those efforts can be seen in our seasonal blogposts about our FLOSS contributions.
The chance of the contributions brought us to share the maintenance of certain libraries we rely upon, like wtforms that is a form management tool, or nextcloud-oidc-login and the underlying OpenIDConnect-PHP that allow nextcloud (the file manager integrated in Nubla) to connect with Canaille.
We also modestly sponsor the maintainers of fomantic-ui and authlib on a monthly basis.
The help of the NLNet foundation
Canaille has been developped to answer specific needs we met: initially Canaille was only made to work with LDAP directories.
Watching the ecosystem, we noticed that more and more software became compatible with OIDC in addition to LDAP.
Ultimately, if no service we use directly rely upon LDAP, then we could consider a replacement database with which we feel more comfortable.
In addition to this, it is more likely that people interested by the Canaille approach will have experience with things like SQL than with LDAP.
To go towards this directory, we sollicitated the NGI Zero Entrust fund of the NLNet foundation in the late 2022, for a amount of 7.000€, to help us realize tasks on Canaille (and around):
SQL databases support.
This allows Canaille to connect to a lot of widespread databases like postgresql, mariadb and sqlite, thanks to sqlalchemy.
pytest-iam.
This is a tool that can prepare and run a Canaille instance in the purpose of unit testing Python applications with pytest.
Those developments have been achieved in november 2023, and have implied numerous refactoring, bugfixes, and better conception and reliability on Canaille.
We are very grateful towards the NLNet foundation for having allowed us to work on our tool, and help at our scale to contribute to the free and open source ecosystem.
What's next?
Go in beta version
From the beggining we have kept Canaille in alpha, we are currently at version 0.0.35.
We advise in the documentation that the software is still not suited for production environments.
This was for us a way to experiment and break things without having to be worried about compatibility.
We would like to break one last little thing by re-thinking the configuration files before we let Canaille go in bêta, and remove usage warnings.
The work we intend to realize to go from a bêta version to a finale version will essentially consists in documentation efforts and ease of installation and usage of Canaille.
The goal is to make Canaille really easy to access, in order to create usage and collect more user feedback.
In the future, we would like to work on provisioning, by implementing the SCIM specification.
This will allow to decouple user authentication and account creation.
Indeed, at the moment user accounts are created the first time users log in at our services.
This can raise issues in some situations: for instance one cannot share files in Nextcloud with users who have not log in yet.
SCIM also provides a mechanism to delete user accounts in those services, that is a thing we do more or less manually at the moment.
Among the things we look forward to implement, there are also the Single Log-Out (SLO) OIDC specifications.
This will allow users to disconnect from all the services in a single action.
SLO is a feature that will bring security and comfort of use.
This will need to be developped in authlib in a first time.
At last, we would like to work on advanced group management and permissions, and on multi-factor authentication to bring even more flexibility and security in Canaille.
Canaille is open to contributions, if you want to help us in this endeavour, the door is open!
En plein apprentissage de Python, j’ai commencé les exercices proposés sur Hackinscience. Là, je suis arrivé à celui qui s’appelle “Vendredi 13”. J’ai écrit cette version qui semble tourner à perfection quand je l’exécute sur mon pc avec Visual Studio et Python 3.12.
Je précise que la dernière ligne me sert juste à faire mes tests en local.
Pourriez vous m’expliquer - simplement - pourquoi le code ne fonctionne pas une fois envoyé sur Hackinscience ? J’ai le message suivant :
TypeError: FakeDatetime.date() takes 1 positional argument but 4 were given
Je trouve ça un peu étrange car je n’ai pas utilisé cette fonction, et je ne savais même pas qu’elle existait.
Voici mon code :
# Vendredi 13
import datetime
def friday_the_13th():
# date actuelle
aujourdhui = datetime.datetime.now()
jour = int(aujourdhui.strftime('%d'))
mois = int(aujourdhui.strftime('%m'))
annee = int(aujourdhui.strftime('%Y'))
# on teste si aujourd'hui, nous sommes un vendredi 13
if jour == 13 and aujourdhui.date(annee, mois, jour).weekday() == 4:
vendredi13 = str(annee) + "-" + str(mois) + "-13"
else:
# sinon, on boucle sur les 13 des mois successifs
# pour voir si ça tombe un vendredi
while datetime.date(annee, mois, 13).weekday() != 4:
if mois < 12:
mois += 1
elif mois == 12:
mois = 1
annee += 1
# le prochain vendredi 13
# avec un ajustement sur le mois pour l'avoir avec 2 chiffres
mois = str(mois).rjust(2, "0")
vendredi13 = str(annee) + "-" + str(mois) + "-13"
return vendredi13
# test
print(friday_the_13th())
Bonjour,
Ci-dessous le code en question (qui ne fonctionne pas). Quand j’appuis sur n’importe quel bouton, c’est toujours le dernier bouton qui change de texte.
je souhaite que le texte change en rapport au bouton utilisé.
Par ailleurs si on pouvait m’expliquer comment “indexer” un bouton cela serait super.
exemple btn[i] ne fonctionne pas. Comment faire pour sélectionner un bouton particulier . Mon projet doit comporter à terme 81 boutons
Merci
import tkinter as tk
def update(i):
btn.configure(text=‘X %d’ % i)
for i in range(10):
btn = tk.Button(text=‘b %d’ % i, command=lambda i=i: update(i))
btn.grid(row=i, column=0)
Offpunk est un navigateur web, gemini, gopher et lecteur RSS en ligne de commande. Il n’y a ni clic, ni raccourcis clavier: tout se fait en tapant des commandes. Pour suivre un lien, on entre le numéro de ce lien.
Mais la fonctionnalité majeure d’Offpunk est qu’il fonctionne en mode déconnecté: toute ressource accédée depuis le réseau est en effet gardée dans un cache permanent ("~/.cache/offpunk/"), ce qui permet d’y accéder plus tard.
Et si une ressource n’est pas encore cachée, elle est marquée comme devant être téléchargée plus tard, ce qui sera fait lors de la prochaine synchronisation ("offpunk --sync").
S’habituer à Offpunk demande un peu d’effort mais, une fois la philosophie générale comprise (les listes, le tour, la synchronisation régulière), Offpunk peut se révéler un redoutable outil de navigation et de gestion de favoris et de liens tout en supprimant la lourdeur souvent inutile du web. On revient au texte et aux images.
La version 2.0 offre désormais certaines fonctionnalités de Offpunk sous forme d’outils en ligne de commande indépendants:
netcache : sorte de wget/curl mais utilisant le cache d’offpunk et permettant d’accéder aux ressources hors-ligne ("option --offline")
ansicat : comme "cat" mais en effectuant un rendu des formats HTML/RSS/Gemtext et même images.
opnk : un "open" universel qui tente d’afficher n’importe quel fichier ou URL dans le terminal et, si il n’y arrive pas, se réduit à utiliser xdg-open.
Je viens également de lancer un salon Matrix pour ceux qui souhaite discuter en direct sur le salon #offpunk:matrix.org ou https://matrix.to/#/#offpunk:matrix.org
Si vous utilisez offpunk, je serais ravi d’avoir vos retours et suis curieux d’entendre comment vous utilisez cet outil.
Nous gérons pour nos clients des centaines de plateformes, il nous arrive donc souvent de devoir assister au débogage ce qui peut impliquer de valider si les réponses d'un site/API sont bien cohérentes avec les requêtes qu'il reçoit. Si le gros du travail de débogage se fait du côté de la réponse, il est parfois utile de vérifier en premier lieu que la requête est correctement formée. Dans notre cas on cherchait à débugger une réponse passant par une série de proxies (Apache et Nginx), et on voulait vérifier que différents éléments étaient bien transmis de proxy en proxy (headers d'authentification, URI, paramètres, etc.) dont certains ne se retrouvent pas dans les logs du serveur HTTP. Tout ce travail de débogage peut aussi être utile au développeur qui travaille sur son API (pour les mêmes raisons que nous) ou avec une API tiers pour vérifier que les appels partants de son code sont bien formés selon les spécifications de cette API. Voyons ensemble comment debugger nos appels via un serveur qui répondra à chaque requête son contenu (on l'appellera "echo"). TL;DR L'idée de départ de ce post est de simplifier cet outil qui s'est trouvé très utile lors d'une séance de debug: https://code.mendhak.com/docker-http-https-echo/. En une ligne plutôt que mille : print_r($_SERVER);
Le kit de débogage Pour une mise en place rapide de ce kit de débogage, partons de nos images docker. Voici l'arborescence nécessaire : |____docker-compose.yml |____echo | |____Dockerfile | |____echo.php |____nginx-echo.conf
On y trouve le 'docker-compose.yml' contenant simplement un conteneur nginx (qui servira sur 'localhost:8000') et un conteneur PHP : services: nginx: image: bearstech/nginx container_name: echo-nginx restart: unless-stopped volumes: - ./nginx-echo.conf:/etc/nginx/conf.d/default.conf ports: - 127.0.0.1:8000:80
J'essaie de me mettre à l'IA. Il faut bien être hype, non ?
Bon, j'essaie surtout de faire du speech to text comme on dit en bon français.
J'ai vu passé des commentaires pas trop négatif sur whisper
J'ai aussi vu des incantations avec pip mais quand j'essaie ces incantations sur ma debian, j'ai le message suivant :
error: externally-managed-environment
× This environment is externally managed
╰─> To install Python packages system-wide, try apt install
python3-xyz, where xyz is the package you are trying to
install.
If you wish to install a non-Debian-packaged Python package,
create a virtual environment using python3 -m venv path/to/venv.
Then use path/to/venv/bin/python and path/to/venv/bin/pip. Make
sure you have python3-full installed.
If you wish to install a non-Debian packaged Python application,
it may be easiest to use pipx install xyz, which will manage a
virtual environment for you. Make sure you have pipx installed.
See /usr/share/doc/python3.11/README.venv for more information.
note: If you believe this is a mistake, please contact your Python installation or OS distribution provider. You can override this, at the risk of breaking your Python installation or OS, by passing --break-system-packages.
hint: See PEP 668 for the detailed specification.
Comme je suis un garçon pas contraire, j'ai installé python3-whisper.
Puis, j'ai fait un petit doc avec les lignes de codes suggérées par Internet
import whisper
model = whisper.load_model("large")
result = model.transcribe("audio.mp3")
print(result["text"])
Mais mon ordinateur, il est pas content quand j'essaie de faire tourner ce programme. Il me dit
Traceback (most recent call last):
File "/home/user/Documents/Tanguy/test.py", line 3, in <module>
model = whisper.load_model("base")
^^^^^^^^^^^^^^^^^^
AttributeError: module 'whisper' has no attribute 'load_model'
Comme la ligne import ne pose pas problème, je me dis que j'ai bien installé quelque chose sur mon PC et que ce qq chose doit bien être importé lorsque le programme tourne. Mais je suis déçu et surtout je ne comprend pas que mon PC m'indique une AttributeError
Si vous avez une piste d'explication, je suis preneur. Si vous avez en plus une piste pour que whisper fonctionne, je suis tout ouïe.
J'essaie de me mettre à l'IA. Il faut bien être hype, non ?
Bon, j'essaie surtout de faire du speech to text comme on dit en bon français.
J'ai vu passé des commentaires pas trop négatif sur whisper
J'ai aussi vu des incantations avec pip mais quand j'essaie ces incantations sur ma debian, j'ai le message suivant :
error: externally-managed-environment
× This environment is externally managed
╰─> To install Python packages system-wide, try apt install
python3-xyz, where xyz is the package you are trying to
install.
If you wish to install a non-Debian-packaged Python package,
create a virtual environment using python3 -m venv path/to/venv.
Then use path/to/venv/bin/python and path/to/venv/bin/pip. Make
sure you have python3-full installed.
If you wish to install a non-Debian packaged Python application,
it may be easiest to use pipx install xyz, which will manage a
virtual environment for you. Make sure you have pipx installed.
See /usr/share/doc/python3.11/README.venv for more information.
note: If you believe this is a mistake, please contact your Python installation or OS distribution provider. You can override this, at the risk of breaking your Python installation or OS, by passing --break-system-packages.
hint: See PEP 668 for the detailed specification.
Comme je suis un garçon pas contraire, j'ai installé python3-whisper.
Puis, j'ai fait un petit doc avec les lignes de codes suggérées par Internet
import whisper
model = whisper.load_model("large")
result = model.transcribe("audio.mp3")
print(result["text"])
Mais mon ordinateur, il est pas content quand j'essaie de faire tourner ce programme. Il me dit
Traceback (most recent call last):
File "/home/user/Documents/Tanguy/test.py", line 3, in <module>
model = whisper.load_model("base")
^^^^^^^^^^^^^^^^^^
AttributeError: module 'whisper' has no attribute 'load_model'
Comme la ligne import ne pose pas problème, je me dis que j'ai bien installé quelque chose sur mon PC et que ce qq chose doit bien être importé lorsque le programme tourne. Mais je suis déçu et surtout je ne comprend pas que mon PC m'indique une AttributeError
Si vous avez une piste d'explication, je suis preneur. Si vous avez en plus une piste pour que whisper fonctionne, je suis tout ouïe.
Nous organisons un premier meetup en mixité choisie le lundi 27 novembre.
Vous êtes bienvenue si vous vous reconnaissez dans le genre féminin ou êtes une personne non-binaire.
Pour ce meetup nous sommes accueillies par Hashbang (métro Brotteaux).
Au programme de cette session, trois sujets !
Qu’est-ce que PyLadies ? par Chiara
Scrapy, automatiser le puzzlescraping, par @MounaSb
Les gens ne savent pas ce qu’ils font, la plupart du temps ! par Léa
by jeanas,Benoît Sibaud,alberic89 🐧,L'intendant zonard,nonas,palm123,gUI from Linuxfr.org
Quelques dépêches précédentes ont parlé des outils de packaging Python, comme ici, là ou encore là. Je vais chercher à faire un tour complet de la question, non seulement du point de vue de l’utilisateur qui cherche à comprendre quelle est « la bonne » solution (← ha ha ha rire moqueur…), mais aussi en expliquant les choix qui ont été faits, les évolutions, la structure de la communauté autour des outils, et les critiques qui leur sont souvent adressées, à tort ou à raison.
Il est question ici de packaging, terme pris dans un sens très large :
L’installation de paquets,
L’installation de Python lui-même,
L’administration d’environnements isolés,
La gestion de dépendances (lock files notamment),
La distribution de son code, en tant qu’auteur d’un paquet Python,
La compilation de code natif (écrit en C, C++, Rust…) pour être utilisé depuis Python.
Le langage Python, avec son écrasante popularité (premier au classement TIOBE), est vanté pour sa simplicité. Hélas, c’est devenu un lieu commun que cette simplicité ne s’étend pas aux outils de packaging, qui sont tout sauf faciles à maîtriser. Personnellement, j’y ai été confronté en voulant soulager la situation de Frescobaldi, une application écrite avec Python et PyQt. Frescobaldi possède une dépendance qui setrouveconcentrerquelquesdifficultésdedistributionetd’installationcoriaces, enraisondecodeC++.
Ce problème d’ensemble a conduit à des évolutions rapides au cours des dernières années, qui tentent de garder un équilibre fragile entre l’introduction de nouvelles méthodes et la compatibilité avec l’existant. Parmi les utilisateurs, une confusion certaine a émergé avec cette cadence des changements, qui fait que des tutoriels écrits il y a quelques années voire quelques mois à peine sont complètement obsolètes, de même que des outils encore récemment recommandés.
Bien que de nombreux progrès soient indéniables, il existe un scepticisme très répandu concernant le degré de fragmentation déconcertant de l’écosystème, qui met l’utilisateur face à un labyrinthe d’outils qui se ressemblent.
Pour illustrer ce labyrinthe, voici une liste des outils que, personnellement, j’utilise ou j’ai utilisé, ou dont j’ai au moins lu sérieusement une partie de la documentation :
Et quelques librairies de plus bas niveau : importlib.metadata, packaging, distlib, installer
Face à cette profusion, le classique aujourd’hui est de citer le XKCD qui va bien, et de renchérir en comparant au langage Rust, connu pour la simplicité de ses outils, à savoir :
cargo, rustup
Et c’est tout. Alors, pourquoi a-t-on besoin de plusieurs douzaines d’outils différents pour Python ?
Cela s’explique largement par des facteurs techniques, que j’expliquerai, qui font à la fois que le packaging Python est intrinsèquement plus compliqué, et qu’on lui demande beaucoup plus. En vérité, dans ces outils, on trouve des projets qui ont des cas d’utilisation complètement différents et ne s’adressent pas au même public (comme pip et repairwheel). Le hic, c’est qu’il y a, aussi, beaucoup de projets dont les fonctionnalités se recouvrent partiellement, voire totalement, comme entre pip et conda, entre venv et virtualenv, entre hatch et poetry, entre pyinstaller et briefcase, etc. Ces projets sont en concurrence et ont chacun leurs adeptes religieux et leurs détracteurs, à la manière des vieilles querelles Vim/Emacs et compagnie.
Cette dépêche est la première d’une série de quatre, qui ont pour but de décortiquer comment tout cela fonctionne, de retracer comment on en est arrivés là, et de parler des perspectives actuelles :
L’histoire du packaging Python
Tour de l’écosystème actuel
Le casse-tête du code compilé
La structure de la communauté en question
Les outils historiques : distutils et setuptools
Guido van Rossum a créé le langage Python en 1989. Rappelons qu’à l’époque, le World Wide Web n’existait pas encore, ni d’ailleurs le noyau Linux, les deux ayant été créés en 1991. D’après Wikipédia (source), le premier logiciel comparable aux gestionnaires de paquets actuels a été CPAN — destiné au langage Perl — qui ne date que de 1995. Python a donc grandi en même temps que l’idée des paquets, des gestionnaires de paquets et des dépôts sur Internet prenait racine.
C’est en 1998 (source) que le module distutils est né pour répondre au même besoin que CPAN pour Perl, dans le monde Python encore balbutiant. Ce module servait à compiler et installer des paquets, y compris des paquets écrits en C. Historiquement, il permettait aussi de générer des paquets au format RPM de Red Hat, et d’autres formats pour des machines de l’époque comme Solaris et HP-UX (source).
distutils faisait partie de la bibliothèque standard du langage. Il était configuré avec un fichier écrit en Python, nommé conventionnellement setup.py, qui prenait généralement cette forme :
On pouvait alors exécuter le setup.py comme un script, en lui passant le nom d’une commande :
$ python setup.py install # installe le paquet
$ python setup.py bdist_rpm # génère un RPM
Le téléchargement de paquets depuis un dépôt partagé ou la résolution des dépendances n’ont jamais fait partie des fonctions de distutils. De façon peut-être plus surprenante, distutils n’offre pas de moyen simple ou fiable pour désinstaller un paquet.
Le projet setuptools est arrivé en 2004 (source) pour pallier les limitations de distutils. Contrairement à distutils, setuptools a toujours été développé en dehors de la bibliothèque standard. Cependant, il était fortement couplé à distutils, le modifiant par des sous-classes… et par une bonne dose monkey-patching (source).
Lesdites limitations ont également conduit à un fork de distutils, nommé distutils2, démarré en 2010. Parmi les raisons citées par son initiateur figure le désir de faire évoluer distutils à un rythme plus soutenu que ce qui était raisonnable pour un module de la bibliothèque standard, surtout un module largement utilisé au travers de setuptools et son monkey-patching (source). Mais distutils2 a cessé d’être développé en 2012 (source).
De même, entre 2011 et 2013 (source), il a existé un fork de setuptools appelé distribute. Ses changements ont fini par être fusionnés dans setuptools.
Pour finir, distutils a été supprimé de la bibliothèque standard dans la version 3.12 de Python, sortie en octobre 2023, au profit de setuptools. Mais cela ne signifie pas que distutils n’est plus utilisé du tout : setuptools continue d’en contenir une copie qui peut être utilisée (bien que ce ne soit pas recommandé).
Il est aussi à noter que NumPy, la bibliothèque Python quasi universelle de calcul scientifique, maintient elle aussi son propre fork de distutils, numpy.distutils, qui est en train d’être remplacé (source). Cela montre à quel point le code de distutils s’est révélé à la fois essentiel, omniprésent à travers divers avatars ou forks, et difficile à faire évoluer.
La montée en puissance de pip et PyPI
Avec le développement d’Internet et la croissance de la communauté Python, il devenait nécessaire d’avoir un registre centralisé où pouvaient être déposés et téléchargés les paquets. C’est dans ce but qu’a été créé PyPI, le Python Package Index, en 2002 (source). (Ne pas confondre PyPI avec PyPy, une implémentation alternative de Python. PyPy se prononce « paille paille » alors que PyPI se prononce « paille pie aïe »).
distutils pouvait installer un paquet une fois le code source téléchargé, mais pas installer le paquet depuis PyPI directement, en résolvant les dépendances. Le premier outil à en être capable a été setuptools avec la commande easy_install (source), apparue en 2004.
Puis est arrivé pip en 2008. Entre autres, pip était capable, contrairement à tout ce qui existait jusque là, de désinstaller un paquet ! En quelques années, easy_install est devenu obsolète et pip s’est imposé comme l’outil d’installation standard. En 2013, la PEP 453 a ajouté à la bibliothèque standard un module ensurepip, qui bootstrapepip en une simple commande : python -m ensurepip. De cette manière, pip a pu continuer d’être développé indépendamment de Python tout en bénéficiant d’une installation facile (puisqu’on ne peut évidemment pas installer pip avec pip) et d’une reconnaissance officielle.
L’introduction du format « wheel »
Sans rentrer trop dans les détails à ce stade, le format principal pour distribuer un paquet jusqu’en 2012 était le code source dans une archive .tar.gz. Pour installer un paquet, pip devait décompresser l’archive et exécuter le script setup.py, utilisant setuptools. Bien sûr, cette exécution de code arbitraire posait un problème de fiabilité, car il était critique de contrôler l’environnement, par exemple la version de setuptools, au moment d’exécuter le setup.py.
setuptools avait bien un format de distribution précompilé, le format egg (le nom est une référence aux Monty Python). Un paquet en .egg pouvait être installé sans exécuter de setup.py. Malheureusement, ce format était mal standardisé et spécifique à setuptools. Il était conçu comme un format importable, c’est à dire que l’interpréteur pouvait directement lire l’archive (sans qu’elle soit décompressée) et exécuter le code dedans. C’était essentiellement une façon de regrouper tout le code en un seul fichier, mais il n’y avait pas vraiment d’intention de distribuer les .egg.
La PEP 427 a défini le format wheel pour que les paquets puissent être distribués sous forme précompilée sur PyPI, évitant l’exécution du setup.py durant l’installation.
Parmi les innovations, les fichiers wheels sont nommés d’après une convention qui indique avec quelle plateforme ils sont compatibles. Ceci a grandement facilité la distribution de modules Python codés en C ou C++. Jusqu’ici, ils étaient toujours compilés sur la machine de l’utilisateur, durant l’exécution du setup.py. Avec les wheels, il est devenu possible de distribuer le code déjà compilé, avec un wheel par système d’exploitation et par version de Python (voire moins, mais c’est pour la troisième dépêche).
Les débuts des environnements virtuels
Voici un problème très banal : vous voulez utiliser sur la même machine les projets foo et bar, or foo nécessite numpy version 3.14 alors que bar nécessite numpy version 2.71. Malheureusement, en Python, il n’est pas possible d’installer deux versions du même paquet à la fois dans un même environnement, alors que d’autres langages le permettent. (Plus précisément, il est possible d’installer deux versions en parallèle si elles ont des noms de module différents, le nom de module Python n’étant pas forcément le même que le nom de paquet, cf. Pillow qui s’installe avec pip install pillow mais s’importe avec import PIL. Mais tant que le module Python n’est pas renommé, les deux sont en conflit.)
La solution est alors de se servir d’un environnement virtuel, qui est un espace isolé où on peut installer des paquets indépendamment du reste du système. Cette technique a été développée dans le projet virtualenv, créé par Ian Bicking, qui est aussi l’auteur originel de pip. La première version date de 2007 (source).
Plus tard, en 2012 (source), un module venv a été ajouté à la bibliothèque standard. C’est une version réduite de virtualenv. On peut toutefois regretter que virtualenv soit encore nécessaire dans des cas avancés, ce qui fait que les deux sont utilisés aujourd’hui, même si venv est largement prédominant.
La création de la Python Packaging Authority (PyPA)
La première réaction naturelle en entendant le nom « Python Packaging Authority » est bien sûr de penser qu’à partir de 2012, date de sa création, ce groupe a été l’acteur d’une unification, d’une standardisation, d’une mise en commun des efforts, etc. par contraste avec la multiplication des forks de distutils.
Sauf que… le mot « Authority » était au départ une blague (sérieusement !). La preuve sur l’échange de mails où le nom a été choisi, les alternatives proposées allant de « ianb-ng » à « Ministry of Installation » (référence aux Monty Python), en passant par « Politburo ».
La Python Packaging Authority a démarré comme un groupe informel de successeurs à Ian Bicking (d’où le « ianb ») pour maintenir les outils qu’il avait créés, pip et virtualenv. Elle est un ensemble de projets, reconnus comme importants et maintenus.
Au fil du temps, la partie « Authority » son nom a évolué progressivement de la blague vers une autorité semi-sérieuse. La PyPA d’aujourd’hui développe des standards d’interopérabilité, proposés avec le même processus que les changements au langage Python lui-même, sous forme de PEP (Python Enhancement Proposals), des propositions qui ressemblent aux RFC, JEP et autres SRFI. La PyPA est également une organisation GitHub, sous l’égide de laquelle vivent les dépôts de divers projets liés au packaging, dont la plupart des outils que je mentionne dans cette dépêche, aux exceptions notables de conda, poetry et rye.
La PyPA n’est pas :
Un ensemble cohérent d’outils. Il y a beaucoup d’outils redondants (mais chacun ayant ses adeptes) dans la PyPA. Pour ne donner qu’un exemple, tout ce que peut faire flit, hatch peut le faire aussi.
Une véritable autorité. Elle reste composée de projets indépendants, avec chacun ses mainteneurs. Le fait qu’un standard soit accepté ne garantit pas formellement qu’il sera implémenté. J’ai lu quelque part une allusion à un exemple récent de « transgression » dans setuptools, mais je n’ai pas retrouvé de quel standard il s’agissait. Concrètement, cela ne veut pas dire que les transgressions sont fréquentes, mais plutôt qu’une PEP risque de ne pas être acceptée s’il n’est pas clair que les mainteneurs des outils concernés sont d’accord.
La décision finale sur une PEP est prise par un « délégué », et normalement, cette personne ne fait que formaliser le consensus atteint (même s’il peut y avoir des exceptions).
Il n’y a donc pas de place dans la PyPA actuelle pour des décisions du type de « flit devient officiellement déprécié au profit de hatch ».
Le développement d’un écosystème alternatif, conda et Anaconda
Pour compléter la liste de tout ce qui s’est passé en 2012, c’est aussi l’année de la première version de conda.
Cet outil a été créé pour pallier les graves lacunes des outils classiques concernant la distribution de paquets écrits en C ou C++ (Rust était un langage confidentiel à l’époque). Jusque là, on ne pouvait redistribuer que le code source, et il fallait que chaque paquet soit compilé sur la machine où il était installé.
Le format wheel introduit plus haut a commencé à résoudre ce problème, mais toutes ces nouveautés sont concomitantes.
Contrairement à tous les autres outils mentionnés dans cette dépêche, Conda, bien qu’open source, est développé par une entreprise (d’abord appelée Continuum Analytics, devenue Anaconda Inc.). C’est un univers parallèle à l’univers PyPA : un installeur de paquets différent (conda plutôt que pip), un format de paquet différent, un gestionnaire d’environnements virtuel différent (conda plutôt que virtualenv ou venv), une communauté largement séparée. Il est aussi beaucoup plus unifié.
conda adopte un modèle qui se rapproche davantage de celui d’une distribution Linux que de PyPI, en mettant le packaging dans les mains de mainteneurs séparés des auteurs des paquets. Il est possible de publier ses propres paquets indépendamment d’une organisation, mais ce n’est pas le cas le plus fréquent. On pourrait comparer cela à ArchLinux, avec son dépôt principal coordonné auquel s’ajoute un dépôt non coordonné, l’AUR.
Cette organisation permet à conda de faciliter énormément la distribution de modules C ou C++. En pratique, même avec les wheels, cela reste une source infernale de casse-têtes avec les outils PyPA (ce sera l’objet de la troisième dépêche), alors que tout devient beaucoup plus simple avec conda. Voilà son gros point fort et sa raison d’être.
Il faut bien distinguer conda, l’outil, d’Anaconda, qui est une distribution de Python contenant, bien sûr, conda, mais aussi une flopée de paquets scientifiques ultra-populaires comme NumPy, SciPy, matplotlib, etc. Anaconda est très largement utilisée dans le monde scientifique (analyse numérique, data science, intelligence artificielle, etc.). Il existe aussi Miniconda3, qui est une distribution plus minimale avec seulement conda et quelques autres paquets essentiels. Enfin, conda-forge est un projet communautaire (contrairement à Anaconda, développé au sein de l’entreprise Anaconda Inc.) qui distribue des milliers de paquets. On peut, dans une installation d’Anaconda, installer un paquet depuis conda-forge avec conda - c conda-forge (le plus courant), ou bien (moins courant) installer une distribution nommée « Miniforge », qui est un équivalent de Miniconda3 fondé entièrement sur conda-forge.
Les PEP 517 et 518, une petite révolution
S’il y a deux PEP qui ont vraiment changé le packaging, ce sont les PEP 517 et 518.
La PEP 518 constate le problème que le fichier de configuration de setuptools, le setup.py, est écrit en Python. Comme il faut setuptools pour exécuter ce fichier, il n’est pas possible pour lui, par exemple, de spécifier la version de setuptools dont il a besoin. Il n’est pas possible non plus d’avoir des dépendances dans le setup.py autres que setuptools (sauf avec un hack nommé setup_requires proposé par setuptools, qui joue alors un rôle d’installeur de paquets comme pip en plus de son rôle normal… ce pour quoi setuptools n’excellait pas). Elle décrit aussi explicitement comme un problème le fait qu’il n’y ait pas de moyen pour une alternative à setuptools de s’imposer. En effet, le projet setuptools souffrait, et souffre toujours gravement, d’une surcomplication liée à toutes ses fonctionnalités dépréciées.
Pour remédier à cela, la PEP 518 a introduit un nouveau fichier de configuration nommé pyproject.toml. Ce fichier est écrit en TOML, un format de fichier de configuration (comparable au YAML). C’est l’embryon d’un mouvement pour adopter une configuration qui soit déclarative plutôt qu’exécutable. Le TOML avait déjà été adopté par l’outil Cargo de Rust.
Le pyproject.toml contient une table build-system qui déclare quels paquets doivent être installés pour exécuter le setup.py. Elle se présente ainsi :
[build-system]requires=["setuptools>=61"]
Cet exemple pourrait être utilisé dans un projet dont le setup.py a besoin de setuptools version 61 au moins.
Mais ce n’est pas tout. La PEP 518 définit aussi une table tool avec des sous-tables arbitraires tool.nom-d-outil, qui permet à des outils arbitraires de lire des options de configuration, qu’ils soient des outils de packaging, des reformateurs de code, des linters, des générateurs de documentation,… pyproject.toml est donc devenu un fichier de configuration universel pour les projets Python. (Anecdote : au départ, il n’était pas prévu pour cela, mais il a commencé à être utilisé comme tel, si bien que la PEP 518 a été modifiée a posteriori pour structurer cela dans une table tool.)
La deuxième étape a été la PEP 517. Elle va plus loin, en standardisant une interface entre deux outils appelés build frontend et build backend. Le build frontend est l’outil appelé par l’utilisateur, par exemple pip, qui a besoin de compiler le paquet pour en faire un wheel installable (ou une sdist, soit une archive du code source avec quelques métadonnées, mais c’est un détail). Le build backend est un outil comme setuptools qui va créer le wheel.
Le rôle du build frontend est assez simple. Pour schématiser, il lit la valeur build-system.requires du pyproject.toml, installe cette liste de dépendances, puis lit la valeur build-system.build-backend, importe le build backend en Python, et appelle la fonction backend.build_wheel().
Voici un exemple de pyproject.toml utilisant les PEP 517 et 518 avec setuptools comme build backend :
Ainsi, il est devenu possible d’écrire et utiliser des build backends complètement différents de setuptools, sans même de fichier setup.py. L’un des premiers build backends alternatifs a été flit, qui cherche à être l’opposé de setuptools : le plus simple possible, avec le moins de configuration possible.
La PEP 517 décrit bien son objectif :
While distutils / setuptools have taken us a long way, they suffer from three serious problems : (a) they’re missing important features like usable build-time dependency declaration, autoconfiguration, and even basic ergonomic niceties like DRY-compliant version number management, and (b) extending them is difficult, so while there do exist various solutions to the above problems, they’re often quirky, fragile, and expensive to maintain, and yet (c) it’s very difficult to use anything else, because distutils/setuptools provide the standard interface for installing packages expected by both users and installation tools like pip.
Previous efforts (e.g. distutils2 or setuptools itself) have attempted to solve problems (a) and/or (b). This proposal aims to solve (c).
The goal of this PEP is get distutils-sig out of the business of being a gatekeeper for Python build systems. If you want to use distutils, great ; if you want to use something else, then that should be easy to do using standardized methods.
La PEP 621, un peu de standardisation
Suite aux PEP 518 et 517, plusieurs build backends alternatifs ont émergé. Bien sûr, tous les build backends avaient des manières différentes de spécifier les métadonnées du projet comme le nom, la version, la description, etc.
La PEP 621 a standardisé cette partie de la configuration, en définissant une nouvelle section du pyproject.toml, la table project. Concrètement, elle peut ressembler à :
[project]name="my-project"version="0.1"description="My project does awesome things."requires-python=">=3.8"authors=[{name="Me",email="me@example.com"}]...
En effet, écrire les métadonnées n’est pas la partie la plus intéressante d’un build backend. Les vraies différences se trouvent, par exemple, dans la prise en charge des extensions C ou C++, ou bien dans des options de configuration plus avancées. La PEP 621 permet de changer plus facilement de build backend en gardant l’essentiel de la configuration de base.
De plus, elle encourage la configuration statique, par opposition au setup.py de setuptools. L’avantage d’une configuration statique est sa fiabilité : aucune question ne se pose sur l’environnement d’exécution du setup.py, sa portabilité, etc.
Pour donner un exemple concret, on apprend dans cette section de la PEP 597 que les développeurs écrivaient souvent dans le setup.py un code qui lit le README avec l’encodage système au lieu de l’UTF-8, ce qui peut rendre le paquet impossible à installer sous Windows. C’est le genre de problèmes systémiques qui sont éliminés par la configuration statique.
Malgré tout, la configuration dynamique reste utile. C’est typiquement le cas pour la valeur de version, qui est avantageusement calculée en consultant le système de contrôle de version (par exemple avec git describe pour Git). Dans ces situations, on peut marquer la valeur comme étant calculée dynamiquement avec
[project]dynamic=["version"]
C’est alors au build backend de déterminer la valeur par tout moyen approprié (éventuellement configuré dans la table tool).
L’émergence d’outils tout-en-un alternatifs
Cet historique est très loin d’être exhaustif, et pourtant on sent déjà la prolifération d’outils différents. Face à la confusion qui en résulte, des développeurs ont tenté d’écrire des outils « tout-en-un » qui rassemblent à peu près toutes les fonctionnalités en une seule interface cohérente : installation, build frontend, build backend, gestion des environnements virtuels, installation d’une nouvelle version de Python, mise à jour d’un lock file, etc. Parmi eux, on peut notamment citer poetry, développé depuis 2018 (source), qui se distingue en ne participant pas à la PyPA et en réimplémentant bien plus de choses que d’autres (notamment en ayant son propre résolveur de dépendances distinct de celui de pip). On peut penser aussi à hatch, qui, lui, fait partie de la PyPA et ne fait pas autant de choses, mais s’intègre mieux à l’existant. Et pour mentionner le dernier-né, il y a également rye, qui cherche à modifier la façon dont Python est boostrapé, en utilisant exclusivement des Pythons gérés par lui-même, qui ne viennent pas du système, et en étant écrit lui-même en Rust plutôt qu’en Python.
Conclusion
J’espère que cet historique permet de mieux comprendre pourquoi le packaging est tel qu’il est aujourd’hui.
L’un des facteurs majeurs est l’omniprésence des extensions C, C++ ou maintenant Rust qui doivent être précompilées. C’est la raison essentielle pour laquelle conda et tout son écosystème existent et sont séparés du monde de la PyPA.
Un autre facteur est à chercher dans les problèmes de conception de distutils, un code qui date de l’époque des premiers gestionnaires de paquets et qui n’était pas prêt à accompagner Python pour vingt ans. C’est pour cela qu’il a été forké si souvent, et c’est pour en finir avec l’hégémonie de son fork setuptools que les PEP 518 et 517 ont volontairement ouvert le jeu aux outils alternatifs.
Il faut enfin voir que la PyPA n’a jamais été un groupe unifié autour d’un outil, et qu’il est difficile de changer de modèle social.
Dans la deuxième dépêche, je ferai un tour complet de l’état actuel, en présentant tous les outils et les liens entre eux.
Nous recrutons ! Pouvez-vous mettre en ligne l’offre suivante ?
"
Offre d’emploi Développeuse/Développeur
HashBang est une société coopérative (SCOP) de services informatiques basée à Lyon. Nous sommes une équipe de 7 personnes.
Nous développons des applications sur mesure avec une approche de co-construction. Nous intervenons sur toute la chaîne de production d’un outil web, de la conception à la maintenance. Nos technologies préférées sont Python, Django, Vue.js, Ansible. Nos méthodes s’inspirent des méthodes agiles. Vous pouvez consulter nos références ici : https://hashbang.fr/references/.
Nos clients sont des startups/TPEs/PMEs/associations et en particulier des organisations qui font partie de l’Économie Sociale et Solidaire.
Nous sommes attachés aux questions de qualité du code et de maintenabilité ainsi qu’au bien-être au travail.
Nous privilégions la prise de décision collective. Notre organisation est horizontale basée sur la sociocratie. Après une phase d’intégration chaque salarié·e est amené·e à intervenir et participer à la gestion de la coopérative dans différent domaines (ressources humaines, comptabilité, gestion du planning, commercial, etc.).
Le poste
Contexte
Hashbang crée un poste de développeuse/développeur en contrat à durée indéterminée pour agrandir et dynamiser son équipe de production.
Missions
Vous aurez pour principales missions :
Développer des applications web à l’aide de frameworks tels que Django, Django REST, Vue.js
Faire des tests unitaires et fonctionnels de votre code
Faire des revues de code
Savoir traduire les besoins du client en une solution fonctionelle
Communiquer régulièrement avec le client sur l’avancée du projet
Participer à la vie de la coopérative
Conditions
Le poste est à pourvoir dans nos locaux : Hashbang, 13 ter Place Jules Ferry, 69006 LYON. Le télétravail partiel ou total est possible après une période d’intégration.
Le contrat proposé est à durée indéterminée. Le temps de travail est de 35h par semaine (80% possible).
Le salaire est fixé selon une grille en fonction de votre niveau d’étude et de votre expérience passée, et évolue périodiquement avec l’ancienneté. Nous proposons des tickets restaurants et un forfait mobilité durable qui prend en charge les frais de transport en commun et/ou de déplacement à vélo.
En tant que SCOP, une partie des bénéfices est reversée aux salarié·e·s. Vous pourrez également devenir associé.e de la coopérative.
Compétences recherchées
Pré-requis techniques
Pour occuper ce poste, vous aurez besoin de :
Savoir chercher de l’information par vous-même, rester en veille technologique
Savoir utiliser un logiciel de gestion de version type git
Être à l’aise avec Python / Javascript / HTML et CSS
De préférence, avoir déjà utilisé Django et Vue.js
Être à l’aise dans la relation client et la gestion de projet
Qualités professionnelles
Pour ce poste et pour vous épanouir dans notre coopérative, vous aurez besoin :
D’être curieux·se ;
D’une forte attirance pour le travail collaboratif ;
D’un sens de la communication afin de vous exprimer en groupe, ainsi qu’avec nos clients;
D’une capacité à prendre des décisions en groupe et individuellement ;
De savoir prendre des initiatives, tester, rater, recommencer, réussir;
D’être capable de travailler en autonomie.
Vous êtes en phase avec nos valeurs et êtes intéressé·e par le modèle coopératif, l’informatique libre et l’organisation horizontale.
Candidater
Envoyez un mail de candidature à rh@hashbang.fr avec un CV et la description de vos motivations pour cette offre en particulier.
Bonjour,
Je cherche une librairie pour gérer des graphes au sens mathématique du mot. C’est a dire un objet avec des sommets, des arêtes et les centaines de fonctionnalités liées à ce sujet. (Voir Lexique de la théorie des graphes. J’ai trouvé entre-temps: " Networkx". Mais peut-être y a t’il mieux?
Qui je n’ai pas encore tanné avec mes tas de sables ?
Pour ceux qui suivent, et pour les autres, j’explore en ce moment les tas de sables abéliens, du moins une petite partie, celle qui consiste à construire une « colonne » de grains de sable, puis de la regarder s’effondrer.
La seule règle pour l’effondrement est : « Si une pile fait plus de 4 grains de haut, elle s’écroule en envoyant un grain au nord, un au sud, un à l’ouest, et un à l’est ».
Donc en Python on peut construire un tas assez simplement :
for x in range(width):
for y in range(width):
if terrain[x][y] >= 4:
terrain[x][y] -= 4
terrain[x - 1][y] += 1
terrain[x + 1][y] += 1
terrain[x][y + 1] += 1
terrain[x][y - 1] += 1
Un seul écroulement n’est peut-être pas suffisant, on peut donc recommencer à écrouler jusqu’à ce que le tas soit bien étalé, qu’il soit « stable », que toutes les piles fassent moins de 4 grains.
Alors déjà en augmentant le nombre de grains placés au centre on constate deux choses :
C’est lent (très lent).
C’est beau (très beau).
Côté lenteur, je vous laisse tester.
Côté beauté voilà ce que ça donne avec 2**26 grains de sable (après 22h de calcul) :
Oui il n’y a que 4 couleurs, et oui mon choix de couleur n’est probablement pas le meilleur :
A l'occasion de cette rentrée 2023, nos rencontres autour du langage Python reprennent à Strasbourg. Nous sommes désormais accueillis par la Plage Digitale.
Prochaine rencontre le jeudi 26 octobre à 18h00
Adresse: Plage Digitale, 13 rue Jacques Peirotes à Strasbourg (Bourse/Place de Zurich)
On parlera rapidement de l'organisation de l'événement (sa fréquence, ses règles…), de quelques ressources pour apprendre ou perfectionner son code puis nous verrons une démonstration de l'outil Google Collab.
On terminera par un temps d'échange et d'entraide. Les personnes débutantes sont la bienvenue car l'équipe organisatrice cherche au mieux à démontrer les possibilité du langage Python dans le cursus universitaire (analyse de données, scrapping web, etc).
Entr’ouvert a du succès et grandit au rythme de son chiffre d’affaires. Nous cherchons actuellement un·e développeur·euse Python/Django.
Entr’ouvert est un éditeur de logiciels libres dont l’activité s’est développée autour de la gestion de la relation usager. Notre mission, c’est de simplifier les démarches des citoyens puis de les proposer en ligne… en ce moment cela a un certain succès.
Entr’ouvert est une SCOP fonctionnant depuis 2002 de manière démocratique, détenue intégralement et à parts égales par ses salarié·es et où chacun, en tant qu’associé·e, participe aux prises de décision. Et parce que nous ne faisons pas les choses à moitié, nous avons institué la stricte égalité salariale.
Nous sommes actuellement 26 : 14 développeuses·eurs, 11 chef·fes de projet et une responsable administrative.
Nous n’utilisons et ne produisons que des logiciels libres. Nous avons développé une relation de confiance avec nos clients, basée sur la qualité, l’importance accordée aux détails, le travail bien fait. Et cela ne nous empêche pas de rigoler, c’est même recommandé, l’esprit de sérieux étant un mauvais esprit. Au-delà des compétences professionnelles, nous recherchons des personnes qui sauront intégrer notre équipe et s’impliquer dans notre structure coopérative.
Nous cherchons un·e développeur·euse :
Vous connaissez bien Python et Django, vous possédez des connaissances basiques en HTML, CSS et Javascript.
Vous savez faire un git commit et un git push (sans -f).
Vous êtes à l’aise avec l’écriture de tests, unitaires ou fonctionnels.
On suit les recommandations PEP8, on aime le code propre et maintenable et on espère que vous aussi.
Vous savez exprimer une situation ou une solution à vos collègues et aux clients.
Vous appréciez la relation directe avec les client·e·s afin de bien cerner leurs demandes.
Vous savez gérer les priorités et aimez tenir vos échéances.
A priori pour savoir faire tout cela, vous avez déjà quelques années d’expérience.
Votre mission :
Après un temps de formation avec l’équipe, vous travaillerez à l’amélioration et sur les évolutions de Publik suivant les tickets et la roadmap.
Vous relirez des patches proposés par les collègues, chercherez à les améliorer, bref, vous ferez du code review.
Selon les projets vous serez développeur·euse ou chef·fe de projet technique (c’est-à-dire en charge de la coordination des développements et de la relation technique avec le client).
CDI de 52 000 € brut annuel, soit environ 3300 € net par mois — même salaire pour tout le monde
Participation, intéressement et primes correspondant à 84% des bénéfices répartis à parts égales entre les travailleuses·eurs.
Organisation du temps de travail sur 4 jours de la semaine.
Travail depuis nos locaux à Paris XIVème ou à Lyon, télétravail total ou partiel possible depuis partout en France.
Douche disponible (à Paris) pour les sportives·fs du matin (très encouragé !) (la douche, le sport lui n’est pas obligatoire). Local vélo & vestiaires.
Chèques déjeuner, mutuelle familiale, 8,5 semaines de congés payés.
50% de la carte Navigo, café, thé et chocolat inclus dans les bureaux parisiens et lyonnais.
Un bon ThinkPad, accompagné d’un grand écran, avec un beau clavier et une souris optique qui brille dans le noir (sans oublier un budget annuel pour tout type de matériel utile pour le télétravail).
Coopératrice·teur, associé·e de la SCOP, à part égale de tous les autres.
Le processus de recrutement :
Un entretien de présentation mutuelle, suivi de l’envoi d’un court test technique puis un second entretien de debrief et discussion avec des membres de l’équipe technique. Les deux entretiens peuvent avoir lieu en visio ou dans nos locaux parisiens.
Pour les Pythonistes : un article qui donne des bonnes pratiques pour écrire du clean code avec Django. Réduire le couplage, granularité des tests, utilisation des modèles et des vues, etc.
by GuieA_7,Xavier Teyssier,Benoît Sibaud,gUI from Linuxfr.org
Le 11 septembre 2023 est sortie la version 2.5 du logiciel de gestion de la relation client Crème CRM (sous licence AGPL-3.0), un peu plus de sept mois après Creme 2.4 (1ᵉʳ février 2023).
Au programme notamment, le passage à Django 4.2, un nouveau mode de navigation ou la configuration visuelle des serveurs SMTP pour les campagnes de courriels. Les nouveautés sont détaillées dans la suite de la dépêche.
Crème CRM est un logiciel de gestion de la relation client, généralement appelé CRM (pour Customer Relationship Management). Il dispose évidemment des fonctionnalités basiques d’un tel logiciel :
un annuaire, dans lequel on enregistre contacts et sociétés : il peut s’agir de clients, bien sûr, mais aussi de partenaires, prospects, fournisseurs, adhérents, etc. ;
un calendrier pour gérer ses rendez‐vous, appels téléphoniques, conférences, etc. ; chaque utilisateur peut avoir plusieurs calendriers, publics ou privés ;
les opportunités d’affaires, gérant tout l’historique des ventes ;
les actions commerciales, avec leurs objectifs à remplir ;
les documents (fichiers) et les classeurs.
Crème CRM dispose en outre de nombreux modules optionnels le rendant très polyvalent :
campagnes de courriels ;
devis, bons de commande, factures et avoirs ;
tickets, génération des rapports et graphiques…
L’objectif de Crème CRM est de fournir un logiciel libre de gestion de la relation client pouvant convenir à la plupart des besoins, simples ou complexes. À cet effet, il propose quelques concepts puissants qui se combinent entre eux (entités, relations, filtres, vues, propriétés, blocs), et il est très configurable (bien des problèmes pouvant se résoudre par l’interface de configuration) ; la contrepartie est qu’il faudra sûrement passer quelques minutes dans l’interface de configuration graphique pour avoir quelque chose qui vous convienne vraiment (la configuration par défaut ne pouvant être optimale pour tout le monde). De plus, afin de satisfaire les besoins les plus particuliers, son code est conçu pour être facilement étendu, tel un cadriciel (framework).
Du côté de la technique, Crème CRM est codé notamment avec Python/Django et fonctionne avec les bases de données MySQL, SQLite et PostgreSQL.
Principales nouveautés de la version 2.5
Voici les changements les plus notables de cette version :
Décalages des sorties de version & passage à Django 4.2
Cette version est plus courte que d’habitude, puisque les versions sortent une fois par an habituellement. Cela vient du fait que nous avons décidé de faire les sorties au milieu de l’année plutôt qu’au début (nous essaierons de sortir Creme 2.6 vers juin 2024), afin de mieux profiter des périodes de support de Django.
En effet, comme on peut le voir ici, depuis quelques années les nouvelles versions de Django sortent tous les huit mois, et toutes les trois versions (une fois tous les deux ans en avril), sort une version gérée pendant trois ans (Long Term Support). On a eu le cycle 3.0/3.1/3.2 (3.2 est la LTS), puis est arrivé le cycle 4.0/4.1/4.2 (4.2 est la LTS) et ainsi de suite.
Les versions de Creme, elles, sortent une fois par an, et utilisent les versions LTS de Django. Comme auparavant nous sortions en début d’année, lorsqu’une nouvelle version LTS sortait (en avril je le rappelle) il fallait attendre le mois de janvier suivant pour profiter de cette version, tandis que la version LTS précédente n’était plus alors gérée que pendant quelques mois.
En sortant en milieu d’année la période pour monter votre version de Creme pendant laquelle les versions de Django sous-jacentes sont gérées devient nettement plus grande (de genre juin à avril de l’année suivante).
Creme 2.5 utilise donc Django 4.2 sorti en avril 2023. Avec ce changement Python 3.7 est abandonné (Python 3.8 devient la version minimale), la version minimale de MySQL devient la 8, celle de MariaDB la 10.4 et celle de PostGreSQL la 12.
Le mode exploration
Il est courant de se préparer, depuis une vue en liste, un ensemble de fiches (Contacts, Sociétés…) à traiter, en utilisant les divers outils de filtrage (filtre, recherche rapide par colonne) et d’ordonnancement, puis en ouvrant les différentes vues détaillées de ces fiches dans des onglets de son navigateur Web. Cependant ça peut devenir un peu fastidieux, on peut facilement oublier des lignes etc.
C’est pour rendre ce genre de tâche plus facile que le mode « exploration » a été créé. Une fois votre vue en liste filtrée & ordonnée afin de contenir les fiches que vous souhaitez traiter, il suffit d’appuyer sur le bouton présent dans l’entête de la liste.
Vous êtes alors redirigé vers la vue détaillée de la première fiche de votre liste. Une fois que vous l’avez traitée, vous pouvez passer à la fiche suivante grâce au bouton présent en haut dans la barre de menu.
Vous allez ainsi pouvoir passer de fiche en fiche sans risque d’oubli. Lorsque toutes les fiches ont été passées en revue, une page vous indique la fin de l’exploration et vous permet de revenir à la liste de départ.
La configuration visuelle des serveurs SMTP pour les campagnes de courriels.
Creme permet depuis longtemps de créer des campagnes d’envoi de courriels. Une campagne est associée à des listes d’envoi (créées par exemple en filtrant vos contacts), et à chaque envoi vous choisissez un patron de message qui va permettre de générer le sujet et le corps des e-mails.
La configuration du serveur SMTP utilisé pour envoyer les e-mails était définie dans un fichier Python de configuration (le fameux fichier « settings.py »). Ce n’était pas évident à comprendre que c’est là qu’il fallait chercher (car pas forcément très bien documenté), et en plus cela limitait cette configuration à l’administrateur uniquement.
Cette configuration se réalise désormais graphiquement. De plus, vous avez désormais la possibilité de configurer autant de serveurs SMTP que vous le voulez.
Réinitialisation des formulaires personnalisés
Les utilisateurs ont bien apprécié la possibilité, arrivée avec Creme 2.2, de pouvoir personnaliser les formulaires des fiches. Certains se sont beaucoup amusés avec même, à tel point que parfois à force d’expérimentation ils obtiennent des formulaires pas géniaux, et souhaitaient pouvoir repartir sur des bases saines.
Avec cette version, il est désormais possible de remettre un formulaire personnalisé dans son état d’origine (et donc de pouvoir tester des choses sans crainte—les expérimentations c’est bien).
Quelques améliorations en vrac
Le nom affiché pour les utilisateurs peut être configuré (afin de garder des noms courts tout en gérant les collisions de noms comme vous le souhaitez).
des couleurs personnalisables ont été ajoutées dans plein de petits modèles, comme les statuts d’Activité ou de Facture.
les lignes de produits & services dans les devis/factures peuvent être ré-ordonnées (détails).
le rendu des graphes a été amélioré, notamment quand il y a beaucoup de choses à afficher.
Le futur
Des améliorations sur le calendrier ont d’ores et déjà été intégrées (et d’autres sont bientôt prêtes) et on planche notamment sur une amélioration des notifications. À l’année prochaine !
Chargée de recrutement chez Meanquest, j’ai contacté Lucie Anglade qui m’a conseillé de déposer une annonce sur le Discourse de l’AFPy via la section “Offres d’emplois” de votre site.
Je me permets donc de vous écrire car je recherche un développeur Python.
Le poste est basé à Genève et nécessite une relocalisation à proximité mais pas obligatoirement en Suisse. Le full remote n’est pas possible. Il y a, après période d’essai validée, 2 jours de télétravail par semaine. Le candidat doit plutôt être sénior (mini 4 ans d’expérience) et avoir un bon niveau d’anglais.
Les conditions et l’environnement de travail sont plutôt agréables. Il s’agit d’une chouette opportunité, tant sur le plan humain que technique.
Voici l’annonce :
Développeur Fullstack (H/F) à dominante Backend Python et avec d’excellentes connaissances en Angular et Javascript.
Missions:
Développer, déployer et améliorer des systèmes d’information complexes selon la méthodologie Agile
Effectuer l’assurance et le contrôle de la qualité
Maintenir et gérer les environnements techniques y compris l’automatisation des processus dans les systèmes CI/CD
Assurer le respect des bonnes pratiques et normes du secteur, en éclairant les décisions de conception de haut niveau et la sélection des normes techniques
Participer à la mise à jour et l’enrichissement de la base de connaissances
Profil recherché:
Formation Ingénieur IT ou équivalent
Minimum 5 ans d’expérience professionnelle en tant qu’Ingénieur / développeur logiciel
Maîtrise du langage Python 2 et/ou 3
Maîtrise des technologies Front-End : JavaScript/TypeScript, Framework Angular 2+, Flask ou Django, NodeJS
Connaissances des bases de données : PostgreSQL, MySQL, SQL Server
Maîtrise de Git
Bonnes connaissances des technologies HTML5/CSS3/Bootstrap, protocole HTTP, REST
Connaissances des technologies de conteneurisation et orchestration (Docker)
Connaissances des Cloud Amazon, Azure et Google
Connaissances en sécurité : SSO, OAuth, OpenID Connect, Saml2, JWT
Connaissances des données géospatiales, concepts et technologies associées, un plus
Vous êtes bilingue français / anglais
Pourquoi postuler ?
Environnement international
Bonne ambiance dans l’équipe
Possibilité de télétravail
Avantage prévoyance professionnelle
…
Pourriez-vous publier cette offre d’emploi sur votre « job board », svp ?
Je viens de trouver un bug python 2!
Question: est-ce que ça présente le moindre intérêt?
C’est un vieux script où je veux, dans certains cas, rajouter une ligne vide sur stdout.
Je fais un print()… et je trouve () au lieu d’une ligne vide!
Si intérêt, faut que je réduise le script au cas minimal significatif…
Makina Corpus développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz. Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
La mission
L’objectif de ce stage est de concevoir et développer un outil de gestion documentaire simple en utilisant le CMS Django Wagtail pour la partie “back-office” et le framework Javascript Vue.js pour la partie “front-office”, avec pour objectif de pouvoir l’intégrer facilement dans tout projet Django (nouveau ou existant). Un des challenges sera de permettre aux contributeurs de configurer finement et de superviser les droits d’accès aux différents contenus.
Vous aurez pour missions de :
• Réaliser des maquettes fonctionnelles pour définir les interactions,
• Développer avec Wagtail (Django) la partie “back-office” de l’application, les API REST nécessaires pour l’exploitation des données dans le front-
office,
• Développer avec Vue.js la partie “front-office” de l’application,
• Réaliser les tests unitaires et fonctionnels,
• Rédiger la documentation technique,
• Publier en Open Source l’application sur Github avec la documentation nécessaire.
Profil
Vous êtes en fin de cursus informatique (Bac +5) et recherchez un stage à partir de janvier 2024. Vous êtes compétent.e pour faire du développement Web en Front et en Back,
• Une expérience en Python et/ou JavaScript est requise,
• Idéalement une expérience en Django, Django Rest Framework et Wagtail; ainsi qu’une expérience en VueJS. Nous attachons avant tout de l’importance aux compétences, à la passion du métier et à une forte motivation.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée -grâce à la souplesse des horaires et au télétravail encadré-, collaboratif…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ? Venez nous rencontrer, vos futurs collègues pourront vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique rejoignez-nous !
Écrivez-nous et racontez-nous qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités. Montrez-nous un peu de code si vous voulez:)
Makina Corpus développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz. Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Au sein d’une équipe interdisciplinaire composée de développeurs front end et back end, et sous la responsabilité de développeurs front end vous aurez pour missions de :
Développer des webapps
Vous imprégner des méthodes de développement des logiciels libres
Faire évoluer des librairies de cartographie
Apprendre les méthodes de tests et de déploiement continu.
L’objectif de ce stage sera, selon votre profil et vos envies, de travailler sur l’un des sujets suivants :
Vous êtes en cours ou en fin de cursus informatique (Bac +5) et vous recherchez un stage pouvant débuter en janvier 2024.
Vous êtes compétent(e) et motivé(e) pour faire du développement web front end, de préférence en React, Angular ou Vue.js.
Vous maîtrisez la communication API/Rest et possédez un véritable intérêt pour les logiciels libres.
Nous attachons avant tout de l’importance aux compétences, à la passion du métier et à une forte motivation.
Pourquoi faire votre stage chez nous ?
Dans la ruche collaborative Makina Corpus on dit ce qu’on fait : les équipes évoluent dans une ambiance motivante et stimulante (projets et contrib Opensource, participations encouragées à des évènements/meetup , émulation entre personnes passionnées, technos innovantes à tester, veille…) et contribuent aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée, collaboratif…).
Mais surtout chez Makina on fait ce qu’on dit : vous avez besoin de le voir pour le croire ? Venez nous rencontrer, un makinien pourra vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique nous vous attendons !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités. Montrez-nous un peu de votre code si vous voulez
Makina Corpus développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz. Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Au sein d’une équipe interdisciplinaire composée de développeurs front end et back end et sous la responsabilité de développeurs back end, vous aurez pour missions de :
Développer des applications Django
Vous imprégner des méthodes de développement des logiciels libres
Faire évoluer des bibliothèques de cartographie
Apprendre les méthodes de tests et de déploiement continu
L’objectif de ce stage sera, selon votre profil et vos envies, de travailler sur l’un des sujets suivants :
Création d’une application pour la gestion de l’altimétrie / les géometries 3D depuis Geotrek-admin/altimetry utilisable dans Geotrek-admin mais aussi GeoCRUD
Mise a jour du site de gestion des utilisateurs Geotrek
Permettre de brancher Geotrek sur un back end d’authentification unifiée
…
Profil
Vous êtes en cours ou en fin de cursus informatique (Bac +4 à +5) et êtes compétent(e) et motivé(e) pour faire du développement back end (Python/Django).
Vous possédez un véritable intérêt pour les logiciels libres.
Nous attachons avant tout de l’importance aux compétences, à la passion du métier et à une forte motivation.
Pourquoi faire votre stage chez nous ?
Dans la ruche collaborative Makina Corpus on dit ce qu’on fait : les équipes évoluent dans une ambiance motivante et stimulante (projets et contrib Opensource, participations encouragées à des évènements/meetup , émulation entre personnes passionnées, technos innovantes à tester, veille…) et contribuent aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée, collaboratif…).
Mais surtout chez Makina on fait ce qu’on dit : vous avez besoin de le voir pour le croire ? Venez nous rencontrer, un makinien pourra vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique nous vous attendons !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités. Montrez-nous un peu de votre code si vous voulez:)
Makina Corpus développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz… Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Vous renforcerez notre équipe pluridisciplinaire (ergonome, graphistes, développeurs back end/front end, SIG, DBA, mobile…) et interviendrez en tant que sénior(e) technique sur toutes les phases de différents projets (chiffrage, conception, architecture, production, tests, livraison etc) tels que :
Réalisations d’applications et de back end (Django, Flask)
Applications métier manipulant de gros volumes de données, avec des règles de gestion métier spécifiques ou nécessitant des interconnexions avec d’autres applications du système d’information
Vous accompagnerez la montée en compétences de profils moins expérimentés et partagerez votre savoir, en interne ou en externe (formation) et en présentiel/distanciel.
Vous aurez l’opportunité de :
Choisir vos propres outils de travail, et évoluer dans une ambiance motivante et stimulante (projets et contributions à des logiciels libres, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technologies innovantes à tester, veille…)
Évoluer dans un environnement technique interdisciplinaire permettant à chacun d’avoir un véritable impact sur les décisions et où l’initiative personnelle est valorisée.
Évoluer dans une organisation du travail en mode hybride (mix présentiel-télétravail)
Participer activement à la vie de l’entreprise : avec vos collègues, vous la représenterez au sein de la communauté Python / Django.
Jouer un rôle visible dans les communautés du logiciel libre : création et amélioration de logiciels libres / Participation à la vie de communautés de développeurs / Coordination de sprints, de bugfests / Réalisation de présentations, conférences, bar camps, formations, lightning talks / Écriture de livres blancs…
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine ou en télétravail complet (sous conditions avec un retour en présentiel de 4 jours/mois).
Ingénieur en études et développement informatiques
Profil
Niveau Bac +5 en informatique de préférence**.** Vous justifiez d’une expérience similaire d’au minimum 3 ans des technologies Python et Django, et êtes à l’aise dans un environnement GNU/Linux. Nous apprécierions que vous possédiez certaines des compétences suivantes :
PostgreSQL/PostGIS
OpenStreetMap
MapBox GL GS / Leaflet
Tuilage Vectoriel
Flask
Elasticsearch
Docker
Vous aurez à comprendre les besoins métiers à réaliser et être force de proposition pour toute amélioration. Votre goût du travail en équipe, votre curiosité et votre adaptabilité aux évolutions technologiques seront des atouts indispensables.
Vous appréciez accompagner la montée en compétences de profils moins expérimentés et partager votre savoir.
Nous attachons beaucoup d’importance aux compétences, à la passion du métier et à une forte motivation.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée - grâce à la souplesse des horaires et au télétravail encadré -, travail collaboratif, solide couverture santé…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ?Venez nous rencontrer, un.e makinien.ne pourra vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique rejoignez-nous !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités. Montrez-nous un peu de code si vous voulez:)
Makina Corpusdéveloppe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz… Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Vous renforcerez notre équipe pluridisciplinaire (ergonome, graphistes, développeurs back end/front end, SIG, DBA, mobile…) et interviendrez sur toutes les phases de différents projets (chiffrage, conception, architecture, production, tests, livraison etc) tels que :
Réalisations d’applications et de back end (Django, Flask)
Applications métier manipulant de gros volumes de données, avec des règles de gestion métier spécifiques ou nécessitant des interconnexions avec d’autres applications du système d’information
Vous serez accompagné(e) tout au long de votre montée en compétences: encadrement par un développeur sénior (pair-programming, codes reviews…), interactions/transmission de compétences avec les équipes, formations, autoformation etc.
Vous aurez l’opportunité de :
Choisir vos propres outils de travail, et évoluer dans une ambiance motivante et stimulante (projets et contributions à des logiciels libres, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technologies innovantes à tester, veille…)
Évoluer dans un environnement technique interdisciplinaire permettant à chacun d’avoir un véritable impact sur les décisions et où l’initiative personnelle est valorisée.
Jouer un rôle visible dans les communautés du logiciel libre : création et amélioration de logiciels libres / Participation à la vie de communautés de développeurs / Coordination de sprints, de bugfests / Réalisation de présentations, conférences, bar camps, formations, lightning talks / Écriture de livres blancs…
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine).
Profil
De préférence niveau Bac +5 en informatique. Votre parcours vous permet de justifier d’une première expérienceen développement web avec lestechnologies Python et Django, vous êtes plutôt à l’aise dans un environnement GNU/Linux.
Vous avez envie d’acquérir certaines des compétences suivantes :
PostgreSQL/PostGIS
OpenStreetMap
MapBox GL JS / Leaflet
Tuilage Vectoriel
Flask
Elasticsearch
Docker
Vous aurez à comprendre les besoins métiers à réaliser et être force de proposition pour toute amélioration. Votre goût du travail en équipe, votre curiosité et votre adaptabilité aux évolutions technologiques seront des atouts indispensables.
Nous attachons beaucoup d’importance aux compétences, à la passion du métier et à une forte motivation.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée - grâce à la souplesse des horaires et au télétravail encadré -, travail collaboratif, solide couverture santé…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ?Venez nous rencontrer, un.e Makinien.ne pourra vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique rejoignez-nous !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités. Montrez-nous un peu de code si vous voulez:)
Makina Corpusconçoit et développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz etc. Nos applications innovantes utilisent exclusivement des logiciels libres et répondent aux enjeux de la transition numérique : mobilité, innovation, environnement, économie, stratégie, développement durable, aménagement du territoire, santé, évolution de la population, etc.
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Vous rejoindrez l’équipe responsable de l’exploitation du système d’information de Makina Corpus, moderne, automatisé et basé à 100 % sur des logiciels libres. Makina Corpus héberge la plupart des services qu’elle utilise tel qu’une instance de GitLab, une registry Docker, des services de messagerie instantané, partage et édition collaborative de documents, CRM, etc.
Votre rôle transverse sur les projets vous permettra d’aborder de nombreuses technologies et d’interagir avec une équipe interdisciplinaire (ergonome, graphistes, développeurs Back/Front, SIG, DBA, mobile…), répartie entre Toulouse, Nantes et Paris.
Vos missions en ingénierie infrastructure/administration système et devops consisteront à :
1) Exploitation du SI de la société (partie administration systèmes) :
Assurer le suivi des mises à jour de nos outils et services internes, les maintenir en condition opérationnelle
Gérer la sécurité des serveurs qui supportent l’infra (Debian et Ubuntu, LXC)
Maintenir et faire évoluer les rôles Ansible permettant la gestion automatisée de la configuration des machines
Superviser les environnements clients (préproduction et production)
Assurer une veille technologique et proposer et faire évoluer l’infrastructure existante ainsi que nos processus de déploiement suivant les bonnes pratiques
Développer des outils d’aide aux tâches d’administration système et de supervision
2) Orchestrer le déploiement de nos applications métiers (partie devops) :
Mettre en œuvre et optimiser les processus d’intégration et de déploiement de nos applications métiers Python/Django et PHP (Drupal/Symfony) en fonction des spécificités et besoins des développeurs par le biais de l’intégration continue/déploiement continu (GitLab-CI, Ansible)
Conseiller et assister les équipes de développement sur les bonnes pratiques liées au déploiement, aux solutions techniques et enjeux de performance et de sécurité en production
Maintenir et faire évoluer des outils, modèles et bases de projet, documentations à destination des développeurs pour les accompagner dans la livraison des applications.
Vous aurez l’opportunité de :
Choisir vos propres outils de travail, et évoluer dans une ambiance motivante et stimulante (projets et contributions à des logiciels libres, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technologies innovantes à tester, veille…)
Évoluer dans environnement technique interdisciplinaire permettant à chacun d’avoir un véritable impact sur les décisions et où l’initiative personnelle est valorisée.
Évoluer dans une organisation du travail en mode hybride (mix présentiel-télétravail)
Participer activement à la vie de l’entreprise : avec vos collègues, vous la représenterez au sein de la communauté
Jouer un rôle visible dans les communautés des logiciels libres : création et amélioration de logiciels libres / Participation à la vie de communautés de développeurs / Coordination de sprints, de bugfests / Réalisation de présentations, conférences, bar camps, formations, lightning talks / Écriture de livres blancs…
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine).
Le profil
Vous avez d’excellentes connaissances et une expérience dans l’administration de systèmes Linux (Debian/Ubuntu) ainsi que dans ces technologies :
Ainsi qu’une connaissance des technologies suivantes :
PostgreSQL
Scripting bash
Prometheus/Grafana
Kubernetes
Une connaissance des langages de programmation Python et PHP serait un véritable avantage.
Vous savez travailler en équipe, à distance et en mode asynchrone dans l’objectif d’évangéliser, expliquer et transmettre. Vous savez être force de proposition sur les solutions techniques mises en œuvre.
Faire évoluer vos connaissances pour apprendre de nouvelles techniques vous stimule, vous êtes curieux et appréciez de sortir de votre zone de confort.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée - grâce à la souplesse des horaires et au télétravail encadré -, travail collaboratif, solide couverture santé…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ? Venez nous rencontrer, un.e makinien.ne pourra vous en parler !
Nos équipes sont mixtes, femmes du numérique rejoignez-nous !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités.
Makina Corpusdéveloppe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz. Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Vous intégrerez un pôle interdisciplinaire (chefs de projets, ergonomes, graphistes, développeurs Back/Front/Mobile, SIG, DBA…) réparti entre Toulouse, Nantes et Paris, au sein duquel vous aurez pour mission de piloter les projets de nos clients et de participer au développement commercial.
Vos missions consisteront à :
Identifier et mettre en œuvre au sein du projet les besoins technico-fonctionnels des clients
Formaliser, organiser, planifier et contrôler les phases de réalisation
Piloter et coordonner l’équipe projet
Assurer le suivi du planning et le contrôle de la qualité
Gérer les engagements vis-à-vis du client et s’assurer de sa satisfaction
Fidéliser, entretenir et développer le portefeuille client existant
Participer aux phases d’avant-vente en relation avec le client et avec nos équipes, rédiger une proposition commerciale
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine).
Profil
Vous maîtrisez les méthodes et outils de gestion de projets web, et possédez impérativement une expérience confirmée sur ce type de posteet dans une entreprise dont les activités sont similaires à la notre.
Comprendre les besoins du client, s’approprier son métier et lui proposer des solutions adaptées vous stimule.
Vous êtes très très à l’aise avec le monde du web , manipuler et faire manipuler des sites web et des applications ne vous fait pas peur.
Votre goût du travail en équipe, votre curiosité, vos excellentes qualités relationnelles seront des atouts indispensables. Apprendre toujours plus vous stimule !
Serait également un plus un background technique dans le développement web.
Nous ne précisons pas de diplôme ou de niveau d’études minimumcar nous attachons avant tout de l’importance aux compétences et à la passion du métier.
Informations complémentaires
Dans la ruche collaborative Makina Corpus, on dit ce qu’on fait : les makiniens évoluent dans une ambiance motivante et stimulante (projets et contrib opensource, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technos innovantes à tester, veille…) et contribuent aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée, collaboratif, télétravail…).
Mais surtout chez Makina on fait ce qu’on dit : vous avez besoin de le voir pour le croire ? Venez nous rencontrer, un.e makinien.ne pourra vous en parler ! Nos équipes sont mixtes, femmes et hommes du numérique nous vous attendons.
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités.
Meetup Django le 24 octobre dans les locaux d’Octopus Energy 6 Bd Haussmann, Paris.
L’occasion de se retrouver et entre autre d’en apprendre plus sur les synergies entre Django et Jupyter Notebook et de tirer des leçons de la construction d’un monolithe Django de 3 millions de lignes.
Bon, je me suis laissé entraîner. Je savais que ça finirait mal. Il y a quelques années, j'ai ouvert un compte Github. J'en avais probablement besoin pour participer à un projet hébergé sur cette plateforme. Et puis j'ai commencé à y mettre mes propres projets, parce que c'était pratique de pouvoir créer un dépôt Git en 3 clics. Je me suis bientôt retrouvé avec plus de 100 projets sur Github.
Seulement voilà, Github, ce n'est pas un logiciel libre. Et en plus, maintenant ils se concentrent sur l'intelligence artificielle et plus sur les outils pour écrire du logiciel. Et en plus, ils ont rendu l'authentification à 2 facteurs bientôt obligatoire et j'ai pas envie de leur donner mon numéro de téléphone (surtout que j'ai eu des problèmes avec mon téléphone il y a quelques jours et c'était déjà assez pénible comme ça).
J'aurais pourtant dû le voir venir: j'avais déjà dû quitter Google Code Project Hosting ainsi que BerliOS il y a quelques années. Je m'étais mis en place un Trac et un Subversion sur mon serveur personnel pour héberger mes projets.
Ces derniers mois j'ai commencé à migrer quelques-uns de mes petits projets à nouveau sur mon propre serveur. J'ai remis Trac à jour (la version 1.6 vient de sortir il y a quelques jours, c'est la première version stable à supporter Python 3, mais j'utilisais déjà les versions 1.5 qui sont aussi en Python 3 depuis longtemps). J'avais aussi installé Gerrit pour pouvoir recevoir des patchs pour mes projets. Il ne reste plus qu'à déplacer les projets en essayant de ne pas perdre trop d'informations.
Migrer le dépôt Git est la partie facile: Git est un système décentralisé, on peut récupérer les commits, branches, tags, etc et les pousser ailleurs très facilement (avec l'option --mirror par exemple). Le problème, c'est tout le reste, c'est à dire dans le cas de GitHub, les pages de wiki et les "issues", qui sont l'endroit ou un peu tout l'historique de l'activité du projet est conservé: tous les bugs corrigés, les discussions sur comment implémenter une nouvelle fonctionnalité, etc.; et aussi le futur du projet: les bugs encore à corriger et les nouvelles fonctionalités à implémenter.
Étrangement, personne n'avait encore écrit de script pour faire cette migration. J'ai dû donc m'atteler à la tâche, en m'inspirant fortement d'un script destiné à migrer de Mantis vers Trac. Ce dernier n'avait été mis à jour ni pour Python 3, ni pour les changements d'APIs survenus dans les versions 1.0, 1.2, 1.4 et 1.6 de Trac. Le premier problème a été rapidement corrigé par 2to3, et le deuxième par une lecture de la documentation d'API et un changement assez répétitif sur le code.
Du côté de Github, l'interfaçage est plutôt simple avec une API REST exposant toutes les informations nécessaires. Du côté de Trac, il s'agit d'une API Python permettant, au choix, d'utiliser des classes fournissant une interface haut niveau, soit de manipuler directement la base de données de Trac à l'aide de requêtes SQL.
Au total, l'implémentation du script a demandé moins d'une journée (j'ai commencé hier soir et je termine aujourd'hui en début d'après-midi). Il me reste encore quelques petites choses à faire, mais je vais peut-être les faire à la main pour aller plus vite. Ainsi que finaliser la configuration du Trac pour le projet que je viens d'importer (avec un joli thème, un logo, la description du projet, etc).
Ah septembre, la fin de l'été, le début de l'automne, les couleurs qui changent, les feuilles au sol qui rendent les pistes cyclables dangereuses…
Septembre c'est aussi la rentrée scolaire et pour moi qui n'ai pas d'enfant mais tiens une librairie, c'est une période très, très, très chargée. Je n'ai donc pas eu le temps de me déplacer à la rencontre des GULL.
Mais (et oui, il y a un mais), je ne suis pas restée toute seule dans mon coin à lire des livres… (enfin si, mais pas tout le temps!)
J'ai eu la chance de pouvoir aller parler de logiciels libres (mais pas que) à différentes occasions:
UÉMSS (Université d'Été des Mouvements Sociaux et des Solidarités) => bon je triche un peu vu que c'était en août mais ça vaut le coup de vous en toucher quelques mots. Les UEMSS sont organisées tous les deux ans depuis 2018 par un large collectif d’associations, de syndicats et de collectifs citoyens. Moi je les ai découvertes grâce à ATTAC et j'ai pu y participer toute une journée lors d'un forum ouvert où chacun proposait un sujet à débattre. Les niveaux en informatique étaient très variés et j'ai pu parler de notre collectif fétiche des chatons afin d'apporter des solutions éthiques et concrètes mais aussi d'éthique et de politique. Enrichissant et loin de ma zone de confort. On en a beaucoup discuté après, entre libristes, ce qui a engendré ce texte que vous avez peut-être déjà lu.
La fête de l'Humanité => L'April, Framasoft et d'autres associations ont tenu des stands lors de la fête cette année encore! Après la grande Halle Simone de Beauvoir les années précédentes, la tente sans électricité ni internet de l'année dernière, nous avons eu l'agréable surprise d'avoir un espace vitré, fermé, avec des chaises et une scène pour organiser des débats. Nous le partagions avec les associations scientifiques qui avaient fait une exposition sur les femmes dans les sciences. Ce fut, pour moi, l'occasion d'animer trois conférences:
«Quels outils pour militer?», avec l'April, Framasoft, Libre-en-commun et FDN.
«Les femmes dans le numérique» avec Isabelle Cholet (une enseignante, chercheuse autrice incroyable et passionnante!!), Mathilde Saliou (journaliste de Nextinpact) et Florence Chabanois (Deputy CTO et Data Protection Officer qui représentait l'association Duchess France). Véritable succès, toutes les chaises étaient occupées, il y avait des gens assis par terre et plein d'autres debout à l'arrière.
«Pour un service public du numérique au service des citoyens» avec Haïkel Guemar (Solidaires Informatique) et Sébastien Elka (Pcf, commission numérique). Il aurait dû y avoir également les députés Andy Kerbrat (LFI) et Adrien Taché (EELV), mais l'un a eu des problèmes de train et l'autre a disparu après s'être présenté. Dommage, j'avais préparé de très nombreuses questions sur le projet de loi SREN (Sécuriser et Réguler l'Espace Numérique) que nous surveillons à l'April.
Week-end épuisant mais plus que satisfaisant! Merci à toutes les associations qui ont composé ce village libriste!
La fresque du climat => J'ai pu participer à cette fresque (dont oui, je sais, les documents ne sont pas sous licence libre) avec une dizaine d'autres membres de l'April. L'ambiance était sereine et studieuse. Pour résumer en une phrase: sous forme de jeux, nous avons pu constater que l'activité humaine a des conséquences néfastes sur la planète, la biodiversité animale et végétale mais aussi les océans.
Les 30 ans de Debian => Un apéro a été organisé à l'April pour fêter cet anniversaire particulier! Beaucoup de monde (de tous les âges, milieux) comme d'habitude (faudrait voir à agrandir ce local) et des discussions intéressantes. 30 ans déjà, ça passe trop vite.
Apéro commun entre l'AFPy (Association Francophone Python) et l'April => Nous avons profité du passage sur Paris de la présidente mais aussi d'autres membres de l'AFPy, pour les accueillir, autour d'un verre, et même plusieurs. Toutes les bouteilles (bière et jus de pommes bio) étaient vides en fin de soirée, mais pas les paquets de chips que nous avons dû nous partager! J'ai choppé quelques adresses mail et j'espère avoir le temps de recroiser certaines…
Le tour des GULL se termine pour le mois de septembre, et comme nous allons bientôt changer de mois, je vous donne une info (spoiler alerte): en octobre j'irai à Toulouse et Lyon!
Cet été nous avons décidé de sponsoriser deux auteurs d'outils desquels nous dépendons. C'est un petit montant pour le moment, mais nous espérons qu'à l'avenir il augmentera ou que la liste des récipiendaires s'élargira.
Nous avons mis une partie de notre énergie sur Canaille, en implémentant le gros morceau de notre engagement à la subvention NLNet, à savoir la généricité des backends de base de données. L'implémentation de la base de données en mémoire nous a permis d'utiliser Canaille dans pytest-iam, un outil qui permet de lancer un serveur OpenID Connect dans des tests unitaires.
Mécénat
Marco 'Lubber' Wienkoop pour son travail sur Fomantic-UI, un chouette framework CSS que nous utilisons dans canaille. Fomantic-UI est aussi utilisé par d'autres outils sur lesquels nous comptons, comme Forgejo.
Hsiaoming Yang pour son travail sur authlib, une bibliothèque python d'authentification que nous utilisons dans canaille.
This summer we decided to sponsor two authors of tools we are depending on. This is a small amount for the moment, but hopefuly this will grow or we add more recipients to the list.
We spent a bit of energy on Canaille, and implementing the big part of our NLNet subsidy, that is the database backend genericity. The inmemory backend allowed us to use canaille in pytest-iam, a tool that bring a lightweight OpenID Connect provider to be used in your unit tests.
Pour l’édition Novembre 2024 on est en contact avec l’université Math-Info de Strasbourg (5-7 rue rené Descartes ou en face du 5 rue du Général Zimmer) Lien OSM
Ces bâtiments sont sur le campus principal, pas loin du centre ville et desservi par trois lignes de Tram (C, E, F) qui passent par deux arrêts proches: Université au Nord et Esplanade à l’Est. Le trajet par la ligne C est direct depuis la gare, il faut compter 12minutes de tram et 5 minutes de marche maxi).
Il y a un grand parking au sud du batiment, vers l’Alinea, mais il est accessible que par bornes (pour des résidents). La rue René Descartes est fermée à la circulation par de gros bloc de pierre (ça semble définitif); L’orga pourra laisser des voitures Allée Gaspard Monge et Konrad Roentgen mais c’est très limité en place sachant que les foodtrucks seront probablement dans ce coin. Le public peut stationner Allée du Général Rouvillois, c’est pas trop loin et gratuit.
Laura pensait réserver les deux amphis et deux grandes salles. J’ai fais un plan du bâtiment (le haut du plan correspond au sud). Je suis passé, il y avait encore des travaux et les cours avaient repris, donc j’ai pas pu ouvrir toute les portes et connaitre le sens de certaines pièces. Et je me suis basé sur un plan d’évacuation (donc sans indication des usages, je pense qu’on a un autre ensemble de WC vers la seconde entrée.
Entrée principale coté EST allée Gaspard Monge (l’allée remonte jusqu’au Tram sans changer de nom) mais elle est pas tout a fait alignée avec l’arrêt) - Possible d’arriver par la rue Zimmer mais c’est moins sympa/visible.
En entrant notre stand d’accueil serait probablement sur la gauche, on laisserait les sponsors autour du petit jardin sur la droite (c’est des patios fermés, on peut aller ni dans le petit ni dans le grand). On a la place pour mettre les sponsors en face a face mais je pense qu’on aura assez d’emplacement pour éviter ça.
le petit-déjeuner serait dans la Cafétéria, c’est assez grand, y’a des distributeur de snack du coté de la cloison avec la grande Salle 1 (espéreront que ça atténue bien le bruit). J’ai pas le souvenir la cloison dans la cafet.
En dessous de la cafet et entre la salle 1 et la salle 2 on a 3 autres salles de cours (sans ordis)
De souvenir les salles tout en bas du plan (avec 3 portes) sont des salles avec des ordis, donc on aura pas accès.
On imaginait faire les ateliers dans la colonne verticale de salle à l’opposé des amphis (mais c’est pas accessible)
Y’a pas mal d’amménagement et de tables en exterieur, plutot du coté Descartes que Roentgen de souvenir
En intérieur en dessous de l’escalier d’accès au grand amphi et derrière le petit amphi on a des tables, le probleme c’est que c’est accessible que par escalier. Les tables bougent pas de ce que j’ai vu.
Accessibilité
J’ai mis un hachuré jaune-noir pour les escaliers, en vif ceux qui gênent plus ou moins, en foncé/sombre ceux qui sont pas problématiques
On peut entrer dans les amphis par le bas (petites fleches bleu pointillés) de chaque cotés.
la salle 1, tout comme la cafet, c’est de plain pied
la salle 2 en revanche on doit soit monter trois marches et y’a rien pour se tenir, soit contourner par l’extérieur et entrer par la porte2 (il y a des escaliers mais je crois qu’on a aussi une rampe)
les salles qu’on prévoyait pour les ateliers ont, d’après mon plan, des escaliers (quelques marches) mais j’ai pas le souvenir de les avoir vu lors de ma rencontre avec le directeur. C’est des points que je vais re-vérifier
Si jamais vous avez des questions, hésitez pas à ma faire un retour rapide (Ici ou en MP) je vais tenter de repasser pour lever quelques doutes.
Je me suis trouvé un nouveau défi: faire un tout petit wiki.
C’est désormais chose faite : Il pourrait être “le plus petit code source de wiki du monde en python3” (laissez moi y croire 5 minutes ) avec ses 532 octets.
Il obéit à quelques contraintes de base pour tout wiki :
Génération automatique de lien : Toute chaîne de caractères en CamelCase est transformée en lien vers une nouvelle page.
Contenu éditable par tout le monde : Aucune sécurité, toute page affiche sa source qui peut être modifiée.
Contenu facilement éditable ; C’est du texte brut, hormis les sauts de ligne qui font un paragraphe et donc les liens vers les autres pages à mettre en CamelCase.
Rétro-liens : Si une page A pointe vers une page B, cette dernière affichera automatiquement un lien vers la page A.
Le code source pour les curieux :
#!/usr/bin/env python3
import cgi,json as j,re as r
p,s,c=map(cgi.parse().get,"psc")
p,o=p[0],open
s and o(p,"w").write(s[0])
o(p,"a");o("b","a")
l,k,v=j.loads(o("b").read()or"{}"),r"(([A-Z][\w]+){2})",r"<a href=?p=\1>\1</a>"
c=s[0] if s else o(p).read()
l[p]=[x[0] for x in r.findall(k,c)]
h=r.sub(k,v,c,r.M)
h=r.sub(r"\n","<p>",h,r.M)
j.dump(l,o("b","w"))
print('Content-Type: text/html\n\n%s<form method=POST><textarea name=s>%s</textarea><input type=submit></form>'%(h,c))
[n==p and print(r.sub(k,v,m)) for m in l for n in l[m]]
L’école navale, à Brest, recherche un doctorant assistant d’enseignement et de recherche.
Quelques détails sur l’offre:
Titulaire d’un master (ou équivalent) en informatique, la personne recrutée devra s’investir dans les activités d’enseignement et au sein du laboratoire dans des travaux de recherche liés au traitement de l’information maritime, à l’intelligence artificielle et plus généralement aux sciences des données. La thèse s’effectuera au sein de l’équipe de recherche MoTIM dans l’objectif de contribuer au domaine du Traitement de l’Information Maritime issue de sources hétérogènes (données capteurs, signaux, images, vidéos, informations géographiques, données textuelles) à l’aide d’algorithmes d’intelligence artificielle.
Avec @liZe, nous serons sur Paris pour la Paris Web.
Est-ce qu’il y a des gens sur Paris qui seraient chô pour aller boire un coup et/ou manger quelque part le vendredi 29 septembre en fin de journée / soirée ?
J’ai une question un peu tordue pour les férus de packaging.
Je développe actuellement un projet que je découpe en plusieurs paquets Python (qui seront publiés sur PyPI) dont certains peuvent être hébergés sur un même dépôt git.
Pas de soucis jusque là mais pour visualiser disons que j’ai un dépôt git avec deux répertoires pouet-engine et pouet-more contenant le code des deux paquets respectifs.
En plus de ça, je fournis des tests pour ces projets, hébergés sur le même dépôt (logique) mais non inclus dans les paquets Python publiés.
Comme les tests de pouet-engine et pouet-more peuvent avoir besoin de fonctions communes mais que je ne veux pas encombrer les paquets principaux des détails des tests, j’ajoute dans l’histoire un paquet pouet-test-fixtures hébergé dans le même dépôt pour contenir tout ça, mais pas publié sur PyPI (il n’a pas de raison d’être installé en dehors de l’env de test).
J’ai ainsi pouet-engine qui n’a pas de dépendance particulière, pouet-engine[dev] qui dépend de pouet-test-fixutres @ git+ssh://..., pouet-test-fixtures qui dépend de pouet-engine, pouet-more qui dépend de pouet-engine et pouet-more[dev] qui dépend de pouet-engine[dev].
Là encore, ça fonctionne plutôt bien.
On en arrive maintenant à mon soucis : je suis dans mon env de dev et j’ai envie de tout installer en mode éditable à partir des fichiers locaux (sans aller chercher de dépendances internes sur PyPI ou sur git). Parce que je veux que mes modifications locales dans le répertoire pouet-test-fixtures soient considérées quand j’exécute les tests de pouet-engine.
Et c’est le cas de la dépendance git qui fait que ça coince.
Lorsque j’essaie un pip install -e './pouet-engine[dev]' ./pouet-test-fixtures j’obtiens une erreur de résolution parce que j’essaie à la fois d’installer pouet-test-fixtures @ git+ssh://... et pouet-test-fixtures depuis le dossier local.
ERROR: Cannot install pouet-test-fixtures 0.0.0 (from /tmp/pouet/pouet-test-fixtures) and pouet[dev]==0.1.0 because these package versions have conflicting dependencies.
The conflict is caused by:
The user requested pouet-test-fixtures 0.0.0 (from /tmp/pouet/pouet/test-fixtures)
pouet[dev] 0.1.0 depends on pouet-test-fixtures 0.0.0 (from git+ssh://****@github.com/entwanne/pouet.git#subdirectory=pouet-test-fixtures)
Là j’ai bien une solution alternative qui est de séparer et dupliquer la commande : d’abord installer ./pouet-engine[dev] qui ira tirer la dépendance depuis git puis de réinstaller ./pouet-test-fixtures pour l’écraser avec la version locale, mais ça passe mal à l’échelle quand il y a plusieurs paquets, parce que si j’installe ./pouet-more[dev] ensuite je suis obligé de recommencer toute la manip.
Des idées pour trouver une solution acceptable à ce soucis ?
Au besoin je peux mettre à disposition un tel projet-jouet pouet qui reproduit le problème.
L’objectif de cet article n’est pas de critiquer la technologie Kubernetes en elle-même, mais plutôt d’évaluer son usage et sa pertinence en fonction des besoins spécifiques de nos clients. Dans cet article, nous nous concentrerons principalement sur les enjeux liés à l’autoscaler; les autres fonctionnalités de Kubernetes n’étant pas critiques pour nos clients et ne sont pas compatibles avec notre méthodologie, laquelle repose sur 19 ans d’expertise et de travail en commun. Notre position n’est pas dogmatique, lorsque les besoins de nos clients le justifient nous savons adapter la complexité de nos réponses à leurs exigences. Nous proposons notre propre méthode d’ajustement automatisé des ressources. Il nous arrive même d’utiliser l’autoscaler d’AWS … Il convient toutefois de noter que la grande majorité de nos clients ont un trafic relativement prévisible. Pour les projets sur lesquels nous avons travaillés, K8S ne constitue pas une solution qui pouvait apporter un gain significatif sur le rapport scalabilité / rentabilité. Même si l'élasticité du système K8S permet d'aborder directement les problématiques de montée en charge en allouant des ressources dynamiquement, nous recommandons de garder le contrôle sur la prévisibilité et l'optimisation des coûts en optant pour des règles d'infogérance maîtrisées de bout en bout. K8s ne rend pas automatiquement les applications élastiques / scalables, l'essentiel du travail demeurant applicatif En effet, sur la partie horizontale, un autoscaler ne gère que l'ajout de CPU/RAM, ce qui revient à une scalabilité horizontale, mais ce n'est qu'un problème que les applications peuvent rencontrer parmi d'autres (contention des IO, surcharges SQL, API tierces, etc ...) Le redimensionnement des ressources CPU/RAM est le problème le plus trivial sur lequel nous pouvons agir, en changeant les specs d'une VM suite à une alerte : cela ne prend que quelques minutes chez Bearstech. L'autoscaler ne réagit qu'avec un temps de retard sur une situation déjà dégradée (en général au moins 5 minutes), et sans contrôle, l'autoscaler peut faire les montagnes russes aussi longtemps qu'il le souhaite... Il ne règle donc pas le problème de la continuité de service et de la tenue en charge 24/7 de l'application. Ce dernier point nécessite une réflexion en amont et une expertise en architecture et performance des infrastructures d'hébergement.
Nous proposons une scalabilité basée sur des métriques, un monitoring spécifique adapté aux applicatifs que nous infogérons Le monitoring est le coeur de notre métier, chez Bearstech, chaque ressource ajoutée dans l'infra doit être entièrement provisionnée (OS, services, code applicatif, données) et intégrée (monitorée, connectées aux services tiers). Si l'environnement d'exploitation a besoin de plus de ressources, il faut prévoir également un déploiement d’application automatique en préalable (mais non suffisant), et il faut une intégration intime avec la partie système. Si un automate est plus rapide qu’un opérateur pour réagir à une surcharge, il n’est par contre pas instantané (un délai de 5min est typique) ni forcément mieux informé qu’un opérateur (il peut y avoir des sur-déclenchements). Un point important à prendre en compte: si l’application n’est pas limitée par la ressource gérée par l’automate, il ne pourra pas apporter de solution utile. En effet, des seuils sont à définir afin de ne pas risquer des effets d'emballement à cause de modules de développement qui n'ont pas été désactivés, ou d'un système de cache non prévu pour le multi-serveur ... Mais aussi, toutes les ressources ne sont pas scalables horizontalement (SQL l’est par exemple très difficilement) ; Malgré ses envies de scalabilité infinie, l'automate doit être paramétré pour avoir un niveau de contrôle sur la consommation des ressources. Chez Bearstech, ce contrôle a lieu au niveau du service de monitoring qui dépend de notre système de supervision. Chez K8S, ce contrôle se fait via un paramétrage de variables définissant le niveau de QoS (quotas, limits et requests ...). Il nous a donc semblé contre-productif d'empiler plusieurs systèmes de contrôles, voire de les mettre en concurrence. Notre expertise de l'infogérance de systèmes d'informations nous permet donc de concevoir des architectures qui garantissent l'optimisation constante de la consommation énergétique des infrastructures que nous maintenons en exploitation. Nous considérons qu'il en va de notre responsabilité d'opérateur dans un secteur où l'empreinte carbone doit être aussi limitée que possible. Nos solutions d'élasticité sont plus transparentes, prévisibles et responsables Nous avons mis au point des procédures pour industrialiser les méthodes de virtualisation afin de dimensionner des machines qui correspondent pour le mieux aux besoins en ressources des applications qui nous sont confiées. Ces procédures sont consolidées et déployables en quelques minutes. Elles peuvent ainsi faire l'objet de procédures automatisables, dans la condition que les applications puissent bénéficier d'une architecture adaptée. 1. Déploiement applicatif Lorsqu’un autoscale décide de rajouter par exemple une VM, c’est lui qui va devoir installer l’application et la connecter aux services dont elle a besoin (SQL, NFS, etc). Il doit donc savoir à chaque instant quelle est la version de l’application en production, et comment la déployer. Bearstech va vous conseiller et vous accompagner pour spécifier les modalités de livraison de l’application en production. Notre workflow devops est particulièrement adapté pour ce type de besoin. 2. Ressources partagées Nous effectuons un travail d'identification des données que les processus exécutant l’application devront partager à chaque instant, car celles-ci seront gérées par une infrastructure tierce. On y trouve en général :
les fichiers manipulés par l’application via le filesystem de l’OS les fichiers manipulés par l’application via un protocole objet une base de données : cluster SQL une base de données NoSQL des sessions : cluster Redis …
Chacun de ces services peut être déployé et infogéré par Bearstech, et devra lui-même être dimensionné en fonction des dimensions minimales et surtout maximales de l’autoscaler. Il est important de réaliser que chacune de ces ressources partagées peut être un goulet d’étranglement de l’application et nécessite donc une attention particulière. Le seul fait d’avoir déployé un autoscaler est loin de garantir un succès en production lors du prochain pic de charge sans avoir mis en oeuvre avec nous, les analyses requises. 3. Configuration, test et exploitation Une application est plus qu’une somme de services reliés entre eux, les interactions peuvent être rapidement complexes. Notre expérience nous permet de choisir des architectures et dimensions cohérentes et fonctionnelles sans connaître l’application a priori, mais il demeure indispensable d’effectuer un test de charge sur une infrastructure:
le test permet de configurer l’autoscaler en fonction des performances attendues de l’application le test permet d’anticiper comment réagit l’autoscaler et avoir un modèle de référence le test permet de vérifier où se trouve le goulet d’étranglement à chaque palier de charge
En exploitation, il est important d’effectuer une analyse régulière du comportement de l'autoscaler, à la fois d’un point de vue fonctionnel (absorbe les pics de charge) et financier (ne se déclenche pas à l’excès). La surveillance de l’autoscaler est donc intimement liée au suivi des performances de l’application au cours de ses évolutions, et nous pouvons vous fournir l'outillage pour surveiller la qualité de votre code. Là aussi notre workflow devops est doté d'outils qui répondent à ce type de besoin. Edit :
Correction de l'affirmation "En effet, un autoscaler ne gère que l'ajout de CPU/RAM" par "En effet, sur la partie horizontale, un autoscaler ne gère que l'ajout de CPU/RAM" Correction introduction
Makina Corpus développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz. Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
La mission
L’objectif de ce stage est de concevoir et développer un outil de gestion documentaire simple en utilisant le CMS Django Wagtail pour la partie “back-office” et le framework Javascript Vue.js pour la partie “front-office”, avec pour objectif de pouvoir l’intégrer facilement dans tout projet Django (nouveau ou existant). Un des challenges sera de permettre aux contributeurs de configurer finement et de superviser les droits d’accès aux différents contenus.
Vous aurez pour missions de :
• Réaliser des maquettes fonctionnelles pour définir les interactions,
• Développer avec Wagtail (Django) la partie “back-office” de l’application, les API REST nécessaires pour l’exploitation des données dans le front-
office,
• Développer avec Vue.js la partie “front-office” de l’application,
• Réaliser les tests unitaires et fonctionnels,
• Rédiger la documentation technique,
• Publier en Open Source l’application sur Github avec la documentation nécessaire.
Profil
• Vous êtes en fin de cursus informatique (Bac +5) et recherchez un stage à partir de janvier 2024. Vous êtes compétent.e pour faire du développement Web en Front et en Back,
• Une expérience en Python et/ou JavaScript est requise,
• Idéalement une expérience en Django, Django Rest Framework et Wagtail; ainsi qu’une expérience en VueJS. Nous attachons avant tout de l’importance aux compétences, à la passion du métier et à une forte motivation.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée -grâce à la souplesse des horaires et au télétravail encadré-, collaboratif…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ? Venez nous rencontrer, vos futurs collègues pourront vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique rejoignez-nous !
Écrivez-nous et racontez-nous qui vous êtes et ce qui vous motive. Expliquez-nous en quoi vos motivations et vos
compétences sont en adéquation avec nos valeurs et nos activités.
Makina Corpusdéveloppe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz. Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Vous intégrerez un pôle interdisciplinaire (chefs de projets, ergonomes, graphistes, développeurs Back/Front/Mobile, SIG, DBA…) réparti entre Toulouse, Nantes et Paris, au sein duquel vous aurez pour mission de piloter les projets de nos clients et de participer au développement commercial.
Vos missions consisteront à :
Identifier et mettre en œuvre au sein du projet les besoins technico-fonctionnels des clients
Formaliser, organiser, planifier et contrôler les phases de réalisation
Piloter et coordonner l’équipe projet
Assurer le suivi du planning et le contrôle de la qualité
Gérer les engagements vis-à-vis du client et s’assurer de sa satisfaction
Fidéliser, entretenir et développer le portefeuille client existant
Participer aux phases d’avant-vente en relation avec le client et avec nos équipes, rédiger une proposition commerciale
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine).
Profil
Vous maîtrisez les méthodes et outils de gestion de projets web, et possédez impérativement une expérience confirmée sur ce type de posteet dans une entreprise dont les activités sont similaires à la notre.
Comprendre les besoins du client, s’approprier son métier et lui proposer des solutions adaptées vous stimule.
Vous êtes très très à l’aise avec le monde du web , manipuler et faire manipuler des sites web et des applications ne vous fait pas peur.
Votre goût du travail en équipe, votre curiosité, vos excellentes qualités relationnelles seront des atouts indispensables. Apprendre toujours plus vous stimule !
Serait également un plus un background technique dans le développement web.
Nous ne précisons pas de diplôme ou de niveau d’études minimumcar nous attachons avant tout de l’importance aux compétences et à la passion du métier.
Informations complémentaires
Dans la ruche collaborative Makina Corpus, on dit ce qu’on fait : les makiniens évoluent dans une ambiance motivante et stimulante (projets et contrib opensource, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technos innovantes à tester, veille…) et contribuent aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée, collaboratif, télétravail…).
Mais surtout chez Makina on fait ce qu’on dit : vous avez besoin de le voir pour le croire ? Venez nous rencontrer, un.e Makinien.ne pourra vous en parler ! Nos équipes sont mixtes, femmes et hommes du numérique nous vous attendons.
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités.
Makina Corpusdéveloppe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz… Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Vous renforcerez notre équipe pluridisciplinaire (ergonome, graphistes, développeurs back end/front end, SIG, DBA, mobile…) et interviendrez sur toutes les phases de différents projets (chiffrage, conception, architecture, production, tests, livraison etc) tels que :
Réalisations d’applications et de back end (Django, Flask)
Applications métier manipulant de gros volumes de données, avec des règles de gestion métier spécifiques ou nécessitant des interconnexions avec d’autres applications du système d’information
Vous serez accompagné(e) tout au long de votre montée en compétences: encadrement par un développeur sénior (pair-programming, codes reviews…), interactions/transmission de compétences avec les équipes, formations, autoformation etc.
Vous aurez l’opportunité de :
Choisir vos propres outils de travail, et évoluer dans une ambiance motivante et stimulante (projets et contributions à des logiciels libres, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technologies innovantes à tester, veille…)
Évoluer dans un environnement technique interdisciplinaire permettant à chacun d’avoir un véritable impact sur les décisions et où l’initiative personnelle est valorisée.
Jouer un rôle visible dans les communautés du logiciel libre : création et amélioration de logiciels libres / Participation à la vie de communautés de développeurs / Coordination de sprints, de bugfests / Réalisation de présentations, conférences, bar camps, formations, lightning talks / Écriture de livres blancs…
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine).
Profil
De préférence niveau Bac +5 en informatique. Votre parcours vous permet de justifier d’une première expérienceen développement web avec lestechnologies Python et Django, vous êtes plutôt à l’aise dans un environnement GNU/Linux.
Vous avez envie d’acquérir certaines des compétences suivantes :
PostgreSQL/PostGIS
OpenStreetMap
MapBox GL JS / Leaflet
Tuilage Vectoriel
Flask
Elasticsearch
Docker
Vous aurez à comprendre les besoins métiers à réaliser et être force de proposition pour toute amélioration. Votre goût du travail en équipe, votre curiosité et votre adaptabilité aux évolutions technologiques seront des atouts indispensables.
Nous attachons beaucoup d’importance aux compétences, à la passion du métier et à une forte motivation.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée - grâce à la souplesse des horaires et au télétravail encadré -, travail collaboratif, solide couverture santé…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ? Venez nous rencontrer, vos futurs collègues pourront vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique rejoignez-nous !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités. Montrez-nous un peu de code si vous voulez:)
Makina Corpus développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz… Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Vous renforcerez notre équipe pluridisciplinaire (ergonome, graphistes, développeurs back end/front end, SIG, DBA, mobile…) et interviendrez en tant que sénior(e) technique sur toutes les phases de différents projets (chiffrage, conception, architecture, production, tests, livraison etc) tels que :
Réalisations d’applications et de back end (Django, Flask)
Applications métier manipulant de gros volumes de données, avec des règles de gestion métier spécifiques ou nécessitant des interconnexions avec d’autres applications du système d’information
Vous accompagnerez la montée en compétences de profils moins expérimentés et partagerez votre savoir, en interne ou en externe (formation) et en présentiel/distanciel.
Vous aurez l’opportunité de :
Choisir vos propres outils de travail, et évoluer dans une ambiance motivante et stimulante (projets et contributions à des logiciels libres, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technologies innovantes à tester, veille…)
Évoluer dans un environnement technique interdisciplinaire permettant à chacun d’avoir un véritable impact sur les décisions et où l’initiative personnelle est valorisée.
Évoluer dans une organisation du travail en mode hybride (mix présentiel-télétravail)
Participer activement à la vie de l’entreprise : avec vos collègues, vous la représenterez au sein de la communauté Python / Django.
Jouer un rôle visible dans les communautés du logiciel libre : création et amélioration de logiciels libres / Participation à la vie de communautés de développeurs / Coordination de sprints, de bugfests / Réalisation de présentations, conférences, bar camps, formations, lightning talks / Écriture de livres blancs…
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine ou en télétravail complet (sous conditions avec un retour en présentiel de 4 jours/mois).
Ingénieur en études et développement informatiques
Profil
Niveau Bac +5 en informatique de préférence**.** Vous justifiez d’une expérience similaire d’au minimum 3 ans des technologies Python et Django, et êtes à l’aise dans un environnement GNU/Linux. Nous apprécierions que vous possédiez certaines des compétences suivantes :
PostgreSQL/PostGIS
OpenStreetMap
MapBox GL GS / Leaflet
Tuilage Vectoriel
Flask
Elasticsearch
Docker
Vous aurez à comprendre les besoins métiers à réaliser et être force de proposition pour toute amélioration. Votre goût du travail en équipe, votre curiosité et votre adaptabilité aux évolutions technologiques seront des atouts indispensables.
Vous appréciez accompagner la montée en compétences de profils moins expérimentés et partager votre savoir.
Nous attachons beaucoup d’importance aux compétences, à la passion du métier et à une forte motivation.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée - grâce à la souplesse des horaires et au télétravail encadré -, travail collaboratif, solide couverture santé…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ? Venez nous rencontrer, vos futurs collègues pourront vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique rejoignez-nous !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités. Montrez-nous un peu de code si vous voulez:)
Makina Corpus développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz. Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Au sein d’une équipe interdisciplinaire composée de développeurs front end et back end et sous la responsabilité de développeurs back end, vous aurez pour missions de :
Développer des applications Django
Vous imprégner des méthodes de développement des logiciels libres
Faire évoluer des bibliothèques de cartographie
Apprendre les méthodes de tests et de déploiement continu
L’objectif de ce stage sera, selon votre profil et vos envies, de travailler sur l’un des sujets suivants :
Création d’une application pour la gestion de l’altimétrie / les géometries 3D depuis Geotrek-admin/altimetry utilisable dans Geotrek-admin mais aussi GeoCRUD
Mise a jour du site de gestion des utilisateurs Geotrek
Permettre de brancher Geotrek sur un back end d’authentification unifiée
…
Profil
Vous êtes en cours ou en fin de cursus informatique (Bac +4 à +5) et êtes compétent(e) et motivé(e) pour faire du développement back end (Python/Django).
Vous possédez un véritable intérêt pour les logiciels libres.
Nous attachons avant tout de l’importance aux compétences, à la passion du métier et à une forte motivation.
Pourquoi faire votre stage chez nous ?
Dans la ruche collaborative Makina Corpus on dit ce qu’on fait : les équipes évoluent dans une ambiance motivante et stimulante (projets et contrib Opensource, participations encouragées à des évènements/meetup , émulation entre personnes passionnées, technos innovantes à tester, veille…) et contribuent aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée, collaboratif…).
Mais surtout chez Makina on fait ce qu’on dit : vous avez besoin de le voir pour le croire ? Venez nous rencontrer, un makinien pourra vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique nous vous attendons !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités. Montrez-nous un peu de votre code si vous voulez:)
f"{self.label}" utilise le mécanisme d’interpolation de chaînes de caractères de Python qui peut être légèrement plus rapide parce qu’il est optimisé pour concaténer des littéraux de chaîne et des variables ;
str(self.label) appelle explicitement le constructeur de la classe str, ce est un peu plus lent en raison de l’appel de fonction.
Makina Corpusconçoit et développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz etc. Nos applications innovantes utilisent exclusivement des logiciels libres et répondent aux enjeux de la transition numérique : mobilité, innovation, environnement, économie, stratégie, développement durable, aménagement du territoire, santé, évolution de la population, etc. Découvrez quelques uns de nos projets : Références | Makina Corpus
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
La mission
Vous rejoindrez l’équipe responsable de l’exploitation du système d’information de Makina Corpus, moderne, automatisé et basé à 100 % sur des logiciels libres. Makina Corpus héberge la plupart des services qu’elle utilise tel qu’une instance de GitLab, une registry Docker, des services de messagerie instantané, partage et édition collaborative de documents, CRM, etc.
Votre rôle transverse sur les projets vous permettra d’aborder de nombreuses technologies et d’interagir avec une équipe interdisciplinaire (ergonome, graphistes, développeurs Back/Front, SIG, DBA, mobile…), répartie entre Toulouse, Nantes et Paris.
Vos missions en ingénierie infrastructure/administration système et devops consisteront à :
1) Exploitation du SI de la société (partie administration systèmes) :
• Assurer le suivi des mises à jour de nos outils et services internes, les maintenir en condition opérationnelle
• Gérer la sécurité des serveurs qui supportent l’infra (Debian et Ubuntu, LXC)
• Maintenir et faire évoluer les rôles Ansible permettant la gestion automatisée de la configuration des machines
• Superviser les environnements clients (préproduction et production)
• Assurer une veille technologique et proposer et faire évoluer l’infrastructure existante ainsi que nos processus de déploiement suivant les bonnes pratiques
• Développer des outils d’aide aux tâches d’administration système et de supervision
2) Orchestrer le déploiement de nos applications métiers (partie devops) :
• Mettre en œuvre et optimiser les processus d’intégration et de déploiement de nos applications métiers Python/Django et PHP (Drupal/Symfony) en fonction des spécificités et besoins des développeurs par le biais de l’intégration continue/déploiement continu (GitLab-CI, Ansible)
• Conseiller et assister les équipes de développement sur les bonnes pratiques liées au déploiement, aux solutions techniques et enjeux de performance et de sécurité en production
• Maintenir et faire évoluer des outils, modèles et bases de projet, documentations à destination des développeurs pour les accompagner dans la livraison des applications.
Vous aurez l’opportunité de :
• Choisir vos propres outils de travail, et évoluer dans une ambiance motivante et stimulante (projets et contributions à des logiciels libres, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technologies innovantes à tester, veille…)
• Évoluer dans environnement technique interdisciplinaire permettant à chacun d’avoir un véritable impact sur les décisions et où l’initiative personnelle est valorisée.
• Évoluer dans une organisation du travail en mode hybride (mix présentiel-télétravail)
• Participer activement à la vie de l’entreprise : avec vos collègues, vous la représenterez au sein de la communauté
• Jouer un rôle visible dans les communautés des logiciels libres : création et amélioration de logiciels libres / Participation à la vie de communautés de développeurs / Coordination de sprints, de bugfests / Réalisation de présentations, conférences, bar camps, formations, lightning talks / Écriture de livres blancs…
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine).
Le profil
Vous avez d’excellentes connaissances et une expérience dans l’administration de systèmes Linux (Debian/Ubuntu) ainsi que dans ces technologies :
• Écosystème Docker (conteneurs, registry, orchestration)
• Intégration continue GitLab-CI
• Gestion de configuration avec Ansible
Ainsi qu’une connaissance des technologies suivantes :
Une connaissance des langages de programmation Python et PHP serait un véritable avantage.
Vous savez travailler en équipe, à distance et en mode asynchrone dans l’objectif d’évangéliser, expliquer et transmettre. Vous savez être force de proposition sur les solutions techniques mises en œuvre.
Faire évoluer vos connaissances pour apprendre de nouvelles techniques vous stimule, vous êtes curieux et appréciez de sortir de votre zone de confort.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée - grâce à la souplesse des horaires et au télétravail encadré -, travail collaboratif, solide couverture santé…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ? Venez nous rencontrer, un.e makinien.ne pourra vous en parler.
Nos équipes sont mixtes, femmes du numérique rejoignez-nous !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités.
J’ai avec Qt designer, j’ai créé une interface utilisateur que j’ai exportée et nommée gui.ui grâce à pyuic je les transformer en gui. Py, mais maintenant, je ne sais pas comment lancer l’interface pour le lancer, j’ai utilisé ce code.
Toute la coloration syntaxique est bonne et tout est bonne … Mais j’ai une erreur
R/ATCIFR/ATC-IFR/src/resources/app.py"
Traceback (dernier appel le plus récent) :
Fichier "d:\Dev\Py\Projet\ATC IFR\ATCIFR\ATC-IFR\src\resources\app.py",
ligne 21, dans le fichier main() "d:\Dev \Py\Projet\ATC IFR\ATCIFR\ATC-IFR\src\resources\app.py",
ligne 15, dans le fichier principal main_window.setupUi(main_window) "d:\Dev\Py\Projet\ATC IFR\ATCIFR\ ATC-IFR\src\resources\gui\gui.py",
ligne 14, dans setupUi MainWindow.setObjectName("MainWindow")
^^^^^^^^^^^^^^^^^^^^^^ ^^
AttributeError : l'objet 'Ui_MainWindow' n'a pas d'attribut 'setObjectName'
France BioImaging, organisation nationale regroupant les plateformes de microscopie en France, recrute un administrateur système et réseau pour participer au déploiement de solutions de gestion de données dans des datacenters régionaux.
Vous rejoindrez une équipe d’une dizaine de personnes distribuée entre Nantes, Montpellier et Bordeaux pour aider à la sauvegarde et à l’archivage des données de la recherche.
Venez travaillez sur des technos 100% open source (OpenStack - Ansible - Debian), pour aider les équipes de recherches dans leur transition vers des pratiques de science ouverte.
by Yann Larrivee,Nÿco,Benoît Sibaud,Xavier Teyssier from Linuxfr.org
La conférence ConFoo est de retour pour sa 22e édition ! Du 21 au 23 février 2024 à l’Hôtel Bonaventure de Montréal, venez découvrir pourquoi ConFoo est devenu l’un des événements phares pour les développeurs de partout en Amérique du Nord !
Nous sommes présentement à la recherche de conférenciers avides de partager leur expertise et leur savoir dans une multitude de domaine des hautes technologies ; PHP, Ruby, Java, DotNet, JavaScript, bases de données, intelligence artificielle et plus encore !
Pouvant être offertes en français ou en anglais, nos présentations sont généralement dans un format de 45 minutes, incluant un 10 minutes de questions des participants. Nos conférenciers invités profitent d’un traitement privilégié ; avec notamment la couverture de leurs frais de déplacement et d’hébergement, en plus de l’accès à l’expérience complète de l’événement (présentations, repas, etc.).
Si vous souhaitez simplement vous inscrire en tant que participant, profitez dès maintenant d’un rabais de 400$ en réservant votre inscription d’ici le 16 octobre prochain !
Bonjour à toutes et à tous,
En relançant le groupe Python sur Strasbourg, @Jeffd, @c24b et moi-même avons estimé que nous pouvions déjà solliciter les sponsors en prévision de la PyConFR 2024, indépendamment du lieu et de la date.
Pourquoi ?
Les communicants devraient logiquement faire valider leurs budgets pour 2024 au cours du 2ème semestre.
Si nous pouvons déjà entrer en relation avec eux, nous pouvons avoir l’espoir d’obtenir plus de réponses positives. Tandis qu’attendre début 2024 pour les solliciter risquerait de les conduire à nous attribuer uniquement des queues de budget.
Bonjour,
Je suis débutant avec python, et je suis en train d’apprendre le langage.
Je constate une différence au niveau du résultat obtenue dans mes variables Exemple : Invite de commande :
Voici une offre d’emploi pour un développeur Python expérimenté en banque-finance : [Confidentiel] est une start-up qui propose une plateforme d’investissement offrant une connexion aux marchés financiers ainsi que des services de transfert et de gestion d’argent, à destination des particuliers. Afin de renforcer son équipe et de poursuivre sa croissance, notre client recherche un Développeur Back-end H/F pour développer, maintenir et améliorer ses systèmes de trading.
Localisation : Lyon
Rémunération proposée : 45000 - 60000 euros / an
Stack technique :
Python (ou expert en JAVA / C#)
AWS Lambdas / DynamoDb, Timestream, APIGateway
Linux Servers
SQL
NoSQL
Websockets / Rest API
Télétravail : 2 jours / semaine
Profil recherché : Expérience d’au-moins 5 ans sur du développement back-end dans un environnement banque / finance Autonome, désireux/euse de partager son expérience Proactif/ve
Pour ceux et celles qui pensent être dans le cadre, contactez-moi en DM et je transmettrai votre profil au chasseur de têtes qui a le mandat.
Et si vous pensez que l’offre est genre mouton à 5 pattes jamais rencontré, dites-le moi aussi, y compris sur le forum: cela me permettra d’aider le chasseur de têtes dans la relation avec le client.
Ma question est plutôt historique : si le GIL était un si gros frein, pourquoi avoir basé Python sur ce dispositif mono-thread ? Est-ce qu’en 1991, on ne savait pas que les ordinateurs allaient devenir multiprocesseurs et mutli-thread ? Pourquoi ne pas avoir codé Python directement sans GIL (TCL est un langage interprété sans GIL) ? Est-ce juste par ce que c’était plus facile vis à vis de la libc ?
( et j’espère qu’il y aura un guide migration en fr …)
Grosse annonce pour les Pythonistes : la proposition de retirer le GIL (Global Interpreter Lock) a été acceptée, permettant le multi-threading natif en Python, une version expérimentale va bientôt être publiée
Y-a-t-il des gens qui s’intéressent aux pointclouds avec Python ici ? J’en utilise pour mon travail via les libs pye57, open3d, pyntcloud et autres - je serai content d’échanger avec d’autres autour du sujet - dans ce thread ou via DM.
J’ai aussi commencé a travailler un nouveau lib pour lecture (et écriture?) des fichiers au format .e57 car pye57 n’est pas trop maintenu en ce moment et pour apprendre un peu de rust. Contributions, commentaires et demandes de features par ici …
si jamais des gens sont intéressés je peux faire un retour d’expérience sur l’utilisation (du dev jusqu’à la production) de docker pour une application python.
Cela pourra commencer par une brève introduction à ce qu’est docker.
Si vous êtes intéressé n’hésitez pas à vous manifester et éventuellement lister des points particuliers que vous souhaiteriez voir abordé
Merci d’utiliser le bouton “Modifier” en bas a droite du message pour ajouter des infos ou répondre en dessous si vous préférez / n’avez pas de droits de modification…
Une librairie préférée? Un projet open source? Un sujet data science / web / IoT / autre…? Merci de répondre ci-dessous avec des propositions de sujet. Vous pouvez me contacter, ou un autre organisateur directement. On peut également faire des meetups en mode “barcamp” sans sujet prévu d’avance.
Playwright: python testing for front end apps by Felix ?
Django ORM by ???
Install party - aider au setup Python (et Conda, django , …?)
Préparer un talk pour le Meetup / PyCon / DevFest / …
L’ESTBB (école de biotechnologies sur Lyon) recherche un·e intervenant·e externe pour des cours de Python sur l’année scolaire 2023/2024.
Les cours de Python sont à destination des premières années de la license SVH.
Il y a au total 7 groupes d’élèves. J’interviens pour 4 de ces groupes et l’école cherche une personne pour assurer les cours des 3 autres groupes.
Le contenu et les supports des cours sont déjà prêts. Lors du premier semestre, les élèves voient les bases de Python et pour le second semestre, c’est un projet en petit groupe.
Niveau volume horaire, ça donne 84h de cours (7 cours de 2h pour 3 groupes x 2 semestres).
N’hésitez pas à me contacter directement en MP ou par mail (lucie@courtbouillon.org) si ça vous intéresse et/ou si vous avez des questions !
Récemment j’ai créé une application django, j’aime beaucoup la facilité avec laquelle je peux crée ce dont j’ai besoin avec.
Mais comme à chaque fois quand je crée une app django, une étape m’effraies, le déploiement. J’arrive toujours à m’entremeler les pinceaux avec les statics, les médias, la sécurité .
Est-ce que vous avez des conseils pour déployer facilement, mettre en place un déploiement automatique, voir une ressource externe pour m’aider à comprendre comment fonctionne le déploiement.
Pour le Meetup de juillet à Grenoble, on sera sur un format “estival” : on échangera autour d’un verre sur le bilan des 10 Meetups de la saison 2022-2023.
j’ai cette erreur en essayant d’exécuter un script python: can't open file 'C:\\Users\\smain\\Desktop\\scrappython\\search.py': [Errno 2] No such file or directory chatgpt ne m’a pas aidé beaucoup donc je viens vers vous en vous remerciant par avance.
Salut à toute la communauté. Je vous contacte parce que depuis 2h je je sui confronté au problème suivant. Chaque fois que je tape un valeur et un variable (par exemple nom=Pierre) je reçois le message suivant:
Traceback (most recent call last):
File "/Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/pydevconsole.py", line 364, in runcode
coro = func()
^^^^^^
File "<input>", line 1, in <module>
NameError: name 'nom_nom' is not defined
Je fais alors appel à votre sagesse et connaissance.
######################fromPyQt5importQtCore,QtGui,QtWidgetsfromprojetimportUi_MainWindowimportsysimportstclassBd(QtWidgets.QMainWindow):def__init__(self):super(Bd,self).__init__()self.ui=Ui_MainWindow()self.ui.setupUi(self)self.Bd=st.Bd()self.ui.page.setCurrentIndex(0)self.setWindowFlags(QtCore.Qt.FramelessWindowHint)# Menu de Navigationself.ui.MenuPrincipalBtn.clicked.connect(lambda:self.ui.page.setCurrentIndex(0))self.ui.CreerCompteMenuBtn.clicked.connect(lambda:self.ui.page.setCurrentIndex(2))self.ui.SeconnecterMenuBtn.clicked.connect(lambda:self.ui.page.setCurrentIndex(1))self.ui.QuitterBtn.clicked.connect(lambda:self.close())# Fin de Navigationself.ui.CreerCompteBtn.clicked.connect(self.CreateUserAccount)self.ui.SeconncterBtn.clicked.connect(self.ValideUser)defCreateUserAccount(self):Nom=self.ui.lineEditNomCreerCompte.text()Email=self.ui.lineEditMailCreerCompte.text()Password=self.ui.lineEditPasswordCreerCompte.text()Data=(Nom,Email,Password)ifself.Bd.ConnectUser(Data,)==0:self.ui.CreerComptelabel.setText("Votre compte a été bien créé")self.ui.CreerComptelabel.setStyleSheet("color:green; font:13px")self.ui.lineEditNomCreerCompte.setText('')self.ui.lineEditMailCreerCompte.setText('')self.ui.lineEditPasswordCreerCompte.setText('')defValideUser(self):Email=self.ui.lineEditMailSeConnecter.text()Password=self.ui.lineEditPasswordSeConnecter.text()try:self.Bd.ValideUser(Email,Password)# Pass Email and Password separatelyself.ui.labelSeConnecter.setText("Votre compte est bien connecté!")finally:self.ui.labelSeConnecter.setText("Les informations saisies ne sont pas correctes !")if__name__=="__main__":App=QtWidgets.QApplication([])Win=Bd()Win.show()sys.exit(App.exec())
st.py fichier base de donnée
#######################importsqlite3,smtplib,sslfromemail.messageimportEmailMessageclassBd():def__init__(self):self.Connexion=sqlite3.connect("ctl.db")self.Cursor=self.Connexion.cursor()defConnectUser(self,Data):Req="INSERT INTO user(Nom,Email,Password) VALUES(?,?,?)"self.Cursor.execute(Req,Data)self.Connexion.commit()return0defValideUser(self,Email,Password):Req="SELECT Email FROM user WHERE Email = ?"self.Cursor.execute(Req,(Email,Password))returnprint(self.Cursor.fetchall()[0][0])
main.py fichier principal Besoin d'aide def ValideUser concernant la logique du try pour se connecter
######################fromPyQt5importQtCore,QtGui,QtWidgetsfromprojetimportUi_MainWindowimportsysimportstclassBd(QtWidgets.QMainWindow):def__init__(self):super(Bd,self).__init__()self.ui=Ui_MainWindow()self.ui.setupUi(self)self.Bd=st.Bd()self.ui.page.setCurrentIndex(0)self.setWindowFlags(QtCore.Qt.FramelessWindowHint)# Menu de Navigationself.ui.MenuPrincipalBtn.clicked.connect(lambda:self.ui.page.setCurrentIndex(0))self.ui.CreerCompteMenuBtn.clicked.connect(lambda:self.ui.page.setCurrentIndex(2))self.ui.SeconnecterMenuBtn.clicked.connect(lambda:self.ui.page.setCurrentIndex(1))self.ui.QuitterBtn.clicked.connect(lambda:self.close())# Fin de Navigationself.ui.CreerCompteBtn.clicked.connect(self.CreateUserAccount)self.ui.SeconncterBtn.clicked.connect(self.ValideUser)defCreateUserAccount(self):Nom=self.ui.lineEditNomCreerCompte.text()Email=self.ui.lineEditMailCreerCompte.text()Password=self.ui.lineEditPasswordCreerCompte.text()Data=(Nom,Email,Password)ifself.Bd.ConnectUser(Data,)==0:self.ui.CreerComptelabel.setText("Votre compte a été bien créé")self.ui.CreerComptelabel.setStyleSheet("color:green; font:13px")self.ui.lineEditNomCreerCompte.setText('')self.ui.lineEditMailCreerCompte.setText('')self.ui.lineEditPasswordCreerCompte.setText('')defValideUser(self):Email=self.ui.lineEditMailSeConnecter.text()Password=self.ui.lineEditPasswordSeConnecter.text()try:self.Bd.ValideUser(Email,Password)# Pass Email and Password separatelyself.ui.labelSeConnecter.setText("Votre compte est bien connecté!")finally:self.ui.labelSeConnecter.setText("Les informations saisies ne sont pas correctes !")if__name__=="__main__":App=QtWidgets.QApplication([])Win=Bd()Win.show()sys.exit(App.exec())
st.py fichier base de donnée Besoin d'aide au niveau de def ValideUser et def ValideUser
#######################importsqlite3,smtplib,sslfromemail.messageimportEmailMessageclassBd():def__init__(self):self.Connexion=sqlite3.connect("ctl.db")self.Cursor=self.Connexion.cursor()defConnectUser(self,Data):Req="INSERT INTO user(Nom,Email,Password) VALUES(?,?,?)"self.Cursor.execute(Req,Data)self.Connexion.commit()return0defValideUser(self,Email,Password):Req="SELECT Email FROM user WHERE Email = ?"self.Cursor.execute(Req,(Email,Password))returnprint(self.Cursor.fetchall()[0][0])
Cette nouvelle édition fait 100 pages de plus, en fait 99 pages pour être exact et j'ai compté 194 scripts en tout, téléchargeables sur le site de l'éditeur bien entendu.
De nouveaux sujets sont abordés comme par exemple AWS et boto3, Scapy, RRDTool, OpenStreetMap et Folium, le tout accompagné d'exemples pertinents et de difficulté progressive.
Je tiens particulièrement à remercier chaleureusement tous ceux qui ont lu et apprécié la première édition, dont certain sont présent sur LinuxFR ;)
Bearstech propose une série d'images Docker pour des clients les utilisant, en lien étroit avec notre métier d'hébergeur (Nginx, PHP, Nodejs, ...) : https://hub.docker.com/u/bearstech. Ces images sont maintenues avec la même rigueur que nous apportons au reste de notre infrastructure, en particulier du point de vue de la sécurité, le tout en proposant à nos client un moyen de s'assurer que les images qu'ils utilisent sont bien à jour. Voyons quelles sont les bonnes pratiques que nous avons mis en place à ce sujet. L'arborescence de nos images Docker On peut définir une arborescence de ces images Docker à partir du champ "FROM" défini au début de chaque Dockerfile. Toutes nos images dérivent donc de notre image de base (bearstech/debian), qui est disponible avec les tags de chaque version Debian encore maintenue (Buster, Bullseye et Bookworm au moment de la rédaction de cet article). Cette image n'est pas créée à partir d'un Dockerfile mais "from scratch" grace à l'outil mmdebstrap. Afin de maintenir ses images Docker, il est important de connaître cette arborescence :
La nécessité de reconstruire une image à n'importe quel niveau implique la nécessité de reconstruire toutes les images qui en dérivent (si image1 est rebuildée, alors image1.1, image1.2, image1.2.1 et image1.3 doivent être reconstruites). De même il n'est pas utile de vérifier la nécessité de reconstruire une image si son image "mère" le nécessite. Cette arborescence peut être formalisée dans un fichier plat, par exemple en YAML, même si ce n'est pas la solution que nous avons retenue : image1: image1.1: image1.2: image1.2.1: image1.3: image2: image2.1: [...]
Suivi des mises à jour des images Docker Afin de suivre en interne les mises à jour de nos images, nous utilisons le système de labels des images Docker, soit dans un Dockerfile: LABEL votre.label=valeur-du-label
On peut alors obtenir les informations d'une image via : $ docker inspect --format='{{json .Config.Labels}}' bearstech/debian:buster | jq { "org.opencontainers.image.authors": "Bearstech", "org.opencontainers.image.revision": "2244cebd8a4a2226cfa409ed8d2d0adf722f9e48", "org.opencontainers.image.url": "https://hub.docker.com/r/bearstech/debian", "org.opencontainers.image.version": "bearstech/debian:buster-2023-07-01" }
Les deux labels utiles pour nous étant:
org.opencontainers.image.revision contient un hash de commit et nous permet donc de savoir l'état du dépôt au moment du build, org.opencontainers.image.version que nous avons formalisé en bearstech/IMAGE:TAG-DATE (ici bearstech/debian:buster-2023-07-01), ce tag n'étant pas déployé sur le hub Docker mais a son existence propre en interne.
Ce deuxième tag permet d'avoir immédiatement une information pratique sur la nature et version de l'image, alors que la plupart des images se contentent du hash qui laisse en général assez perplexe (par ex: où consulter une table de correspondance hash -> date ?). Pourquoi Debian Vous aurez remarqué que nous n'avons pas choisi une distribution "légère spéciale conteneur" telle que la fameuse Alpine. Il y a plusieurs raisons à ceci :
la principale est que notre modèle de maintenance est basée sur le principe Debian des branches stables + patches de sécurité. Le comfort pour les développeurs (environnement stable pendant 2 ans) et pour l'infogéreur (garantie de pouvoir déployer des patches de sécurité sans incidents et sans demander la permission aux développeurs) est incomparable
nous avons par ailleurs plus de 20 ans d'expérience, de recettes et d'outils sur les systèmes Debian, il aurait été dommage de ne pas en profiter...
et enfin il n'y a pas de contre-indication, car grâce au système de "layers" de Docker, l'image de base Debian est partagée par toutes nos images de notre arborescence : au final le coût de stockage des images sur les serveurs reste très modeste et n'est PAS proportionnel au nombre d'images
Quand mettre à jour les images Docker Pour la plupart de nos images, nous appliquons la même règle de sécurité que nos serveurs en suivant les mises à jour de sécurité Debian de la pile logicielle que nous maintenons. Nous avons donc opté pour un système nous notifiant quotidiennement des mises à jour de sécurité sur les différentes images. Voici par exemple le mail reçu ayant déclenché la mise à jour de l'image bearstech/debian:buster du 7 juillet: error: security upgrades on debian:buster: debian-archive-keyring 2019.1+deb10u1 -> 2019.1+deb10u2 (Debian-Security:10/oldoldstable)
Les images dérivant de bearstech/debian:buster nécessitent également d'être reconstruites au moins à cause de ces mises à jour de sécurité et ne sont donc ni testées (pour un gain de temps substentiel), ni mentionnées car leur reconstruction est automatique dans le processus de reconstruction de l'image bearstech/debian:buster. Certaines images nécessitent des tests supplémentaires :
images utilisant des logiciels en "rolling release" (PHP dans une version non packagée par Debian, Node.js, etc.) via des dépôts APT hors Debian (nous appliquons alors toute mise à jour de paquet dès qu'elles sont mises à disposition) logiciels spécifiques hors dépôt apt (Ruby, Gitlab, ...) pour lesquels il faut écrire des scripts "maison" pour vérifier l'existence de nouvelles mises à jour
KISS and generic Comme souvent, le meilleur moyen garantir un niveau de maintenance satisfaisant est de garder le fonctionnement et le processus de mise à jour aussi simples que possible, et de rendre générique tout ce qui peut l'être. Le processus de publication d'une image est chez nous toujours le même:
build de la nouvelle image tests effectuées sur l'image archivage interne et publication sur le hub Docker mêmes étapes pour les images dérivant de cette image
Voici donc le résultat pour la publication de l'image bearstech/debian:buster: $ docker-bearstech-full-build debian:buster info: building image debian:buster info: testing image debian:buster info: pushing image debian:buster info: image debian:buster published info: rebuilding debian:buster dependencies: php-cli:7.3 info: building image php-cli:7.3 info: testing image php-cli:7.3 info: pushing image php-cli:7.3 info: image php-cli:7.3 published info: rebuilding php-cli:7.3 dependencies: php-composer:7.3 php:7.3 info: building image php-composer:7.3 info: testing image php-composer:7.3 info: pushing image php-composer:7.3 info: image php-composer:7.3 published info: building image php:7.3 info: testing image php:7.3 info: pushing image php:7.3 info: image php:7.3 published
Chaque étape est bloquante (pas de publication sur le hub Docker si les tests ne passent pas) et peut être rejouée indépendemment : $ docker-bearstech-test debian:buster [...] # Résultats de tests laissés à notre discrétion [...] info: image bearstech/debian:buster-2023-07-01 tested successfully
Enfin, si certaines étapes du build peuvent être rendues génériques, cela allègera les Dockerfiles et vous y gagnerez en homogénéité. Voici par exemple un Dockerfile utilisé à la fin de chaque build d'image pour y ajouter nos labels : $ cat labels/Dockerfile ARG IMAGE ARG TAG ARG BUILD_DATE FROM bearstech/$\{'IMAGE'}:$\{TAG}-$\{BUILD_DATE}
Sur l'image sans labels bearstech/debian:buster-2023-07-01 qui vient d'être buildée, il nous suffit de lancer cette commande (intégrée au processus de construction) pour y ajouter nos labels : $ docker build --build-arg IMAGE=debian --build-arg TAG=buster --build-arg BUILD_DATE=$(date +%Y-%m-%d) --build-arg GIT_REVISION=$(git rev-parse HEAD) labels/
Avertir de la mise à jour d'une image Il est de notre responsabilité de mettre à jour les images que nous proposons mais il revient à nos clients de mettre à jour leurs propres images qui en dérivent. Pour cela, nous avons intégré à notre dashboard multicloud un module affichant les mises à jour d'images Docker disponibles.
Si de plus vous avez souscrit à notre système de workflow, il ne vous reste plus qu'un clic pour redéployer vos applications et profiter de ces mises à jour sans effort et en toute sérénité. Conclusion Dans un article précédent nous avions détaillé la position de bearstech vis-à-vis de Docker, en particulier son utilisation en production. Cet article vient préciser comment nous gérons dans les faits les images dont nous avons la résponsabilité. Comme toujours, notre approche vise plusieurs objectifs : mettre en œuvre les images les plus simples et sécurisées possible, tout en facilitant autant que faire se peut le quotidien de nos clients dans le cadre de nos prestations d'infogérance. La maintenance et la mise jour des images Docker est une tâche complexe qui requièrent une grande rigueur et organisation. Notre approche méthodique nous permet de relever ces défis efficacement !
RGOODS est LA plateforme SaaS en marque blanche qui permet aux organisations à but non lucratif de recruter de nouveaux donateurs grâce à des services innovants: boutiques en ligne, formulaire de dons, média de communication au sein des entreprises afin de développer le mécénat.
Un impact clair, fort et traçable tout en construisant une entreprise rentable. La société dispose d’un financement solide et est dirigée par des fondateurs ayant une vaste expérience dans le lancement et la croissance d’entreprises numériques avec un chiffre d’affaires de plus de 2 milliards d’euros.
RGOODS s’adresse au marché européen et collabore avec les principales ONG et marques européennes comme Médecin Sans Frontières, Amnesty International, Handicap International. Notre engagement est simple : les aider à tisser des liens forts avec leurs sympathisants et à collecter des fonds, afin qu’elles mènent à bien leurs missions.
Dans ce contexte, nous lançons le développement d’un nouveau produit, basé sur Python, Django et VueJS. L’équipe de développement est composée de 3 développeurs seniors (15 ans d’expérience moyenne) et est destinée à grandir.
Notre culture du développement logiciel est simple:
Utiliser des technologies modernes mais éprouvées
Rester simple, agile et respecter les standards
Penser expérience utilisateur, fiabilité et sécurité
Vos missions
Concevoir, développer, tester et déployer des applications web à l’aide des technologies en Python/Django et VueJS,
Assurer la qualité du code en effectuant des revues de code, des tests unitaires et des tests d’intégration,
Participer activement à l’optimisation et la sécurisation des applications en identifiant et en résolvant les problèmes de performances et les vulnérabilités de sécurité,
Participer à la mise en place et à la maintenance de l’infrastructure technique supportant les applications ainsi que les outils de développement et de déploiement (hébergement, CI/CD, monitoring, etc.),
Participer à la rédaction des documentations techniques et documentations utilisateur, ainsi qu’à la formation et au support technique des utilisateurs en interne.
Votre profil
Vous êtes issu·e d’une école d’ingénieur ou d’un master en informatique (Bac+5),
Vous avez une expérience de 5 ans minimum dans le développement d’applications web en utilisant Python/Django, Vue.js, HTML5 & CSS
Votre expérience inclut le développement d’applications à forte exigence de sécurité, forte charge, et haute disponibilité,
Vous maîtrisez les patterns reconnus d’architecture logicielle et de développement, aussi bien côté backend que frontend,
Vous savez vous mettre à la place des utilisateurs et avez pour principal objectif de leur fournir un outil fiable, sécurisé et ergonomique,
Vous aimez travailler en équipe et savez que les échanges sont primordiaux dans la réussite d’un projet.
Pourquoi nous rejoindre ?
Vous désirez vous engager dans une mission qui a du sens, et êtes fier·e de contribuer à l’impact de grandes associations comme APF France Handicap, Petits frères des Pauvres, ou encore Surfrider Foundation ?
Vous rêvez de travailler sur un produit nouveau, sans dette technique, sur lequel tout est à construire ?
Vous souhaitez collaborer avec une équipe dynamique et amicale, qui aime se retrouver autour d’un tableau blanc, mais aussi autour d’un repas ou d’un verre ?
Vous avez envie d’un cadre de travail agréable et d’un équilibre vie pro/perso respecté ?
… alors il est probable que votre place soit parmi nous.
Type de poste
Salaire : Entre 50 et 65K, selon expérience
Avantages : Tickets restaurant
Disponibilité : ASAP
Contrat : CDI cadre - forfait jours
Lieu de travail : Centre ville de Nantes
Présentiel/Télétravail : Hybride flexible
Processus de recrutement
Envoyez votre candidature en expliquant pourquoi vous souhaitez venir travailler avec nous, accompagnée de votre CV à florent@rgoods.com
Le seul souci c’est qu’on ne peut pas coder en Python dans minetest, que en Lua (je parle bien de coder dans le jeu).
Pour revenir à Python ce serait tentant de se faire une lib Python pour se connecter à un serveur minetest, j’ai essayé 10 minutes mais le protocole n’est (n’était ?) pas documenté. Jouer à ce genre de jeu, pourquoi pas, mais c’est trop chronophage. Développer une IA qui « joue » pour moi là ça peut m’amuser ! Ça ouvre plein de possibilités, comme faire des PNJ avec (ou sans) ChatGPT (dans l’eau ça fait des bulles c’est rigolo), j’imagine très vite un PNJ marchand à qui tu peux acheter des choses, un PNJ banquier (qui proposerai des prêts et des dépôts), un PNJ pour harceler ceux qui sont en retard de paiement sur le remboursement de leur emprunt au banquer, un PNJ allumeur de réverbères qui fait le tour de la ville tous les soirs pour allumer les réverbères, et un tour le matin pour les éteindre, une équipes de PNJ employables (que tu peux payer à entretenir ton champ ou ta mine), … beaucoup de ces features existent déjà mais sous forme de blocs un peu basiques et implémentés server-side, le côté PNJ rendrait le truc un peu plus vivant qu’un bloc.
Je pense qu’on peut y passer deux vies, gros minimum. Il faut que je retourne a hackinscience (qui prend environ une vie je pense) et sphinx-lint (qui prend du temps aussi). Ah et la trad de la doc de Python qui prend une vie aussi.
Je travaille sous debian 11, qui vient avec python 3.9; j’ai voulu installer des python plus récents, 3.10, 3.11 et 3.12; Je les ai installés sans problème, suivant recette How to install Python 3.10 on Debian 11 - Tutorials and How To - CloudCone essentiellement upload, compile et make altinstall.
Bout de l’history:
523 time wget https://www.python.org/ftp/python/3.12.0/Python-3.12.0a1.tgz
524 lrtail
525 time tar zxvf Python-3.12.0a1.tgz
526 lrtail
527 cd Python-3.12.0a1
528 history
529 time ./configure --enable-optimizations
530 history
531 time sudo make altinstall
532 python3.10 -V
533 python3.11 -V
534 python3.12 -V
Puis j’ai voulu les essayer dans des environnements virtuels.
Créé sans problème avec mkvirtualenv -p:
(p3.10) ~ 09:43:17 > pip install ipython
Traceback (most recent call last):
File "/home/virt/p3.10/bin/pip", line 5, in <module>
from pip._internal.cli.main import main
File "/home/virt/p3.10/lib/python3.10/site-packages/pip/_internal/cli/main.py", line 10, in <module>
from pip._internal.cli.autocompletion import autocomplete
File "/home/virt/p3.10/lib/python3.10/site-packages/pip/_internal/cli/autocompletion.py", line 9, in <module>
from pip._internal.cli.main_parser import create_main_parser
File "/home/virt/p3.10/lib/python3.10/site-packages/pip/_internal/cli/main_parser.py", line 7, in <module>
from pip._internal.cli import cmdoptions
File "/home/virt/p3.10/lib/python3.10/site-packages/pip/_internal/cli/cmdoptions.py", line 23, in <module>
from pip._vendor.packaging.utils import canonicalize_name
ModuleNotFoundError: No module named 'pip._vendor.packaging'
Le pip invoqué vient bien de l’environnement installé par mkvirtualenv.
Le problème semble connu, dans différents contextes, aucune des solutions proposées, sur stackoverflow ou autre, ne semble résoudre le problème.
Coincé.
Je ne tiens pas à basculer vers pipenv, mkvirtualenv m’a toujours donné pleine satisfaction, mais peut être faut-il le ré-installer?
On y utilise une clef asymétrique (ECC) et ses "clés dérivées".
On y accède aux données par leur contenu.
On y partage tout en pair à pair.
On y trouve des blockchain.
Salut à tout le monde je m’appelle Konstantinos et je suis complément novice à la programmation avec Python.
Depuis quelques jours je casse ma tête pour le problème suivant.
Quand je suis sur IDLE et je tape
7
7
14
Il fait le calcul des chiffres automatiquement contrairement aux deux autres logiciels. Chaque foi que je tape “enter” il va juste à ligne. J’ai cherché sur les paramètres mais c’est un chaos. Pour cette raison je 'adresse à vous.
J’ai toutes les derniers versions python: 3.11.4 53.11.4), Visual Studio code:Version : 1.79.2 (Universal) et pour pycharm Build #PC-231.9161.41.
Et bien, un peu dans le même domaine, je regardais en famille sur la plateforme Auvio le très sympathique dessin animé Justin et la légende des chevaliers. Loin d'être révolutionnaire, on a bien rit et passé un excellent moment en famille. Mais ce n'est pas pour cela que je t'en parle.
Au moment du générique de fin, j'ai sursauté en voyant quelques noms que j'ai plus l'habitude de rencontrer sur DLFP que dans un dessin animé:
Aucune idée si ces applications sont une part importante ou négligeable de tout ce qui a été utilisé pour la production de ce film mais je trouvais cela amusant de voir cela.
Porte-toi bien !
P.S. : tu as remarqué ? C'est la première photo que je partage à partir de mon cloud, Nubo en esperanto. À ce stade-ci, cela semble bien fonctionner :-)
Pour le Meetup Python du mois de juin à Grenoble, Emmanuel Leblond (co-fondateur et directeur technique chez Scille) viendra nous parler cybersécurité durant les primaires de l’élection présidentielle de 2022.
J’utilise une 3.10 (installée sur un dérivé d’Ubuntu 22.04) mais je rencontre quelques soucis avec beeware (https://beeware.org/) pour lesquels je souhaite pouvoir faire des essais avec la version 3.8 (cf msg briefcase “Warning: Python version 3.10 may have fewer packages available. If you experience problems, try switching to version 3.8.” )
Quelle est la meilleure façon d’installer la 3.8 sans mettre (trop) le bazar sur la 3.10 ?
Merci de votre aide
L’EuroPython souhaite rapprocher les différentes personnes qui organisent des évènements (meetups et conférences) autour de Python.
Le but est de souder la communauté, de partager plus facilement les évènements et les expériences d’orga.
Artur de l’EuroPython récupère les adresses mails des gens intéressés par rejoindre ce groupe (probablement une mailing list ou un groupe Google).
Si ça vous dit, vous pouvez m’envoyer votre mail en mp et je transmettrai tout ça à Artur !
Edit : vous pouvez préciser si vous êtes ok pour un groupe Google ou non dans le mp.
Outil Unix pour administrer les journaux sur un système produisant de nombreux journaux
Passage du code de sortie à 0 quand l'erreur provoque l'arrêt de l'exécution du programme. Cela correspond au comportement attendu d'un utilitaire Unix.
Ruby Video, est un projet inspiré par Python pyvideo.org. L’ambition de Rubyvideo.dev est d’agréger toutes les vidéos liées à Ruby en un seul endroit, avec des capacités de recherche pour faciliter la découverte. Pour cette première version, il y a 707 vidéos de 537 intervenants. Il s’agit uniquement des vidéos de RailsConf de 2012 à 2022.
Rubyvideo.dev est construit avec Rails 7.1 alpha, Hotwire, Litestack et déployé en utilisant MRSK sur un VPS bon marché.
Ce site utilise aussi l’API de transition de vue : testez-la sur un navigateur Chromium pour profiter de ces transitions de page fluides. Il a été assez facile de la faire fonctionner avec Turbo et Adrien Poly, le créateur, espère que ce repo peut aider à l’adoption de la technologie dans le monde de Rails. Il prévoit d’écrire à ce sujet prochainement.
Sweep is young company fighting climate change, helping large enterprises taclek their carbon emissions.
We’re hiring a Data Integration Specialist , tasked with ensuring seamless integration of data across various systems and platforms within our organization.
Climate change is the defining issue of our time. By empowering companies with technology that helps them manage their climate impact, we believe Sweep can make a meaningful contribution to a better future for all of us.
To be more specific, this includes:
1. Manage data integration
Follow and maintain high quality in the data integration process and data adaptation
Collaborate with cross-functional teams, including IT, software developers, and business stakeholders, to gather data integration requirements and understand the overall business needs.
Integrate historical carbon footprint files of our customers to facilitate the start on the tool for them
Develop and maintain data mapping and transformation rules to integrate our customers data sources into Sweep and set up for automated data collection
Identify and evaluate existing data sources to determine compatibility and integration feasibility and, support to set up APIs and integrations
2. Ensure quality and compliance
Perform data profiling and analysis to identify data quality issues and propose appropriate solutions.
Create and execute data integration test plans to validate the accuracy, completeness, and reliability of integrated data.
Troubleshoot and resolve data integration issues, working closely with technical teams to identify root causes and implement timely resolutions.
Monitor data integration processes, identify areas for optimization, and implement performance tuning measures to enhance overall system efficiency.
Stay up to date with emerging data integration technologies, tools, and best practices, and propose innovative solutions to improve data integration processes.
3. Pursue quality
Document data integration processes, configurations, and procedures for future reference and knowledge sharing.
Test different data integration and qualification solutions together with the team
Run ad-hoc data analyses to understand opportunities for improvement
That sounds just right for me. What do I need to bring?
Glad you asked. This is who we’re looking for:
Qualifications
You have 2+ years of experience in data integration, data warehouse, big-data-related initiatives, development and implementation
Excellent quantitative analysis skills and comfortable in working with large datasets
Demonstrated ability to navigate, wrangle and validate data from structured and unstructured data sources in R, Python, SQL, and Excel.
Experience with data transformation techniques and services
Qualities
You are enthusiastic, self motivated and autonomous
Excellent problem-solving skills with the ability to analyze complex data integration issues and provide effective solutions.
Strong communication and interpersonal skills, with the ability to collaborate effectively with both technical and non-technical stakeholders.
You are a team player and aim for velocity
You care about our mission of creating a better future for all of us
Copy that. And what’s in it for me?
You will be joining an exciting young business that has the humble ambition to change the world. With a proven track record in starting companies, we’re planning to hit the ground running and have an impact fast. Joining this journey right at the beginning allows you to really help shape our path.
Our hybrid work model, with hiring focussed around our head offices in Paris, London and Montpellier, allows us to balance our personal and professional lives while staying connected and engaged with colleagues and clients.
We’re big believers in creating successful businesses that are good for everyone, including society and the planet. That’s why we have a B Corporation status.
We think this will be the ride of our lives. And maybe yours, too.
Dans l'article précédent, nous avons vu les principes sur lesquels le workflow devops de Bearstech repose (opensource, transparence, mesure de la fiabilité des applications). Dans cet article, nous allons vous présenter son fonctionnement et quelques cas pratiques qui peuvent s'appliquer aux différentes étapes du cycle de vie des projets informatiques. Notre workflow Notre but étant de viser la fiabilité des applications, nous avons conçu un environnement de travail sécurisé et transparent qui peut s'adapter à tous types de projets. Il respecte les bonnes pratiques d'un développement qui prend au sérieux les questions de sécurité et de performance applicatives. Bearstech propose un workflow modulaire, qui n’impose que peu de règles prédéfinies, qui se paramètrent dans des fichiers, de manière transparente. Il effectue pour le développeur les opérations de préparation de l'environnement d'exploitation:
provisionner un serveur paramétrer des services web générer des certificats pour authentifier l’application provisionner un service de BDD définir un système de cache ...
De plus, il apporte un environnement de travail complet, maintenu par Bearstech :
pour versionner le code, créer des branches et des merge requests pour automatiser des tâches sur la CI selon les étapes de livraison du code : intégration, tests, recette, staging, production échanger avec mon équipe, suivre les sorties de tests, des déploiements, analyser la productivité ...
Les développeurs disposent ainsi d'une plateforme qui regroupe un ensemble d'outils qui leur permettent d'assembler les couches logicielles plus simplement, de valider l'intégration de leurs applications dans un contexte d'exploitation stable, tout en gardant le contrôle sur propres leurs environnements de travail. Instancier l'application sur la CI Le workflow devops de Bearstech est modulaire, il peut donc couvrir pas mal de cas d'usages pour les applications courantes. Les services à invoquer se paramètrent dans le fichier .gitlab-ci.yml des projets. Dans le cas d'un scénario de workflow qui souhaite valider le bon fonctionnement d'une application par des tests d'intégration et des tests fonctionnels, il faudra spécifier à la CI les règles nécessaires pour instancier l'application de manière temporaire avant son déploiement vers les environnements de staging ou de production. Fichiers requis Dans ce cas, il sera souhaitable d'utiliser d'embarquer l'application dans des conteneurs. Le workflow aura besoin au moins de 3 fichiers pour fonctionner:
.gitlab-ci.yml pour lister les actions à exécuter sur la CI. Dans le cas de notre scénario, il faudra au moins 2 étapes: le build de l'image Docker, et le déploiement. Dockerfile pour l'image de l'application et ses dépendances à embarquer. docker-compose.yml pour lister les services utilisés par l'application.
Reverse proxy Notre workflow met à disposition un reverse-proxy qui permet d'exposer publiquement et de manière sécurisée les conteneurs. Nous utilisons Traefik car il permet de gérer dynamiquement les configurations. Dans le workflow c'est lui qui dispatche les requêtes aux conteneurs. Le workflow inclut les directives Docker pour lier Traefik à votre application. Traefik va écouter la socket Docker (docker.sock) pour ouvrir les connexions sur le réseau privé créé par Docker, et permet ensuite de s'y connecter en http pour intéragir avec le ou les conteneurs. En production, Traefik ne tourne pas dans un conteneur, mais il écoute la socket docker.sock, il intercepte les événements de création de conteneurs, il les inspecte, récupère l'ip du réseau et expose l'application proprement: le workflow interdit d'exposer publiquement les ports des applications qui tournent sous Docker, seul le port du reverse-proxy Traefik est public (80 et 443). Réaliser les tests dans la CI Tests unitaires Grâce à la CI et à Docker, il est désormais possible d'automatiser les tests unitaires qui doivent être réalisés avant le build de l'image de l'application. Dans la documentation du workflow, nous avons décrit une procédure pour réaliser des tests unitaires sur une application écrite en Python en utilisant l'utilitaire pytest. Tests fonctionnels Une fois l'application et le reverse-proxy instanciés sur la CI, il est ensuite possible de lancer des tests directement sur l'infrastructure temporaire qui, dans notre workflow, tourne dans un conteneur LXC afin de bien sécuriser l'environnement. Nous avons écrit pas mal d'article sur le sujet des tests fonctionnels qui permettent de valider la pile logicielle d'une applicaton (Tests fonctionnels avec browserless et Cas d'usage pour des tests fonctionnels avancés), aussi nous n'allons pas nous étendre à nouveau sur les outils qui permettent d'émuler un navigateur headless afin d'obtenir dans la CI une sortie propre pour le résultat des tests. Un déploiement flexible Les contraintes ne sont pas les mêmes en production et en staging, c'est pourquoi notre workflow s'adapte aux besoins de flexibilité pour les environnements de recette et aux besoins de stabilité et de performance pour les environnements de production. Par son aspect modulaire, notre système de déploiement prend en compte les besoins de flexibilité pour les phases de développement et de recette, pour ensuite couvrir les besoins de stabilité en préprod et en production. Pour plus de détails sur ces deux aspects du déploiement, nous vous invitons à consulter la documentation de notre workflow pour les principes de déploiement d'application hébergées en natif avec son quick-start, et ceux pour les applications conteneurisées avec son quick-start. Ce déploiement modulaire permet de couvir les besoins d'organisation des projets informatiques actuels. Voici quelques exemples pratiques de déploiement qui démontrent la souplesse du workflow: L'agilité L'app-review Cette méthode de déploiement permet de comparer plusieurs versions de l'application simultanément. Cette méthode est particulièrement utile en développement pour valider telle ou telle fonctionnalité. Couplée à Docker, notre workflow permet de déployer des conteneurs en fonction des branches de votre projet, et configure automatiquement un point d'accès HTTP qui reprend le nom de la branche dans l'url. Cela permet de publier l’application sur une url temporaire, à côté des url “officielles” déployées sur les environnements (staging et production). Le workflow devops de Bearstech implémente cette technique au moyen du reverse-proxy en déployant les conteneurs dans un environnement spécifique à la branche de commit (voir notre documentation technique à ce sujet). Le Déploiement "Blue/green" Cette méthode de publication permet à un nombre limité d'utilisateurs d'accéder à certaines fonctionnalités, avant de les diffuser à tous les autres. Notre workflow permet lier la branche du dépôt qui déclenche le déploiement et la machine cible (target). Ainsi, les fonctionnalités qui sont destinées à être validées dans un environnement spécifique peuvent être livrées au moment voulu. Attention, ce mode de déploiement doit être adjoint à un loadbalancer qui s'occupe de répartir le trafic entre les différents environnements. Le paramétrage du loadbalancer est une opération distincte du workflow (voir exemple un exemple de paramétrage chez OVH pour une répartition du trafic en fonction des ports). Le rollback En cas de dysfonctionnement de l'application en production qui n'a pas pu être détecté en amont (typiquement lors la mise à jour de modules tiers), pouvoir revenir à une version précédente de l'application est une opération que le système de déploiement permet de simplifier considérablement. En effet, que ce soit dans le cadre d'un déploiement natif ou avec des conteneurs, chaque déploiement a lieu en identifiant l'ID d'un commit:
le déploiement natif effectue un git pull sur l'id de commit qui a déclenché la pipeline, et cela permet de rejouer en cas de besoin une pipeline qui utilisera une version précédente du code de l'application. le déploiement de conteneurs utilisera un principe similaire, en permettant de rejouer le build d'une image Docker qui utilise une version précédente du code de l'application.
A noter qu'en ce qui concerne les données stockées en BDD ou leurs structures, il faudra utiliser une procédure de restauration qui s'appuiera sur un backup (dump) auquel on pourra adjoindre une reconstruction de sa structure, si ces modifications sont également versionnées dans le code du projet. Infogérance Une fois la gestion des dépendances fiabilisée grâce à la CI et aux bonnes pratiques du workflow, la continuité passe par l'infogérance des services en exploitation. L'infogérance des dépendances système et applicative consiste à automatiser leurs mises à jour de sécurité, et à disposer d'un monitoring pour déclencher des alertes. Notre workflow intègre la mise à disposition des sondes de surveillance nécessaires à la mise en oeuvre d'un monitoring efficace pour les services exploités par l'application. Nous mettons à la disposition de nos clients une interface web dédiée qui leur permet d'accéder à une synthèse de leurs environnements. L'infogérance s'organise différemment selon le mode de déploiement utilisé: Infogérance pour les services natifs L'infogérance se fait de manière classique: les paquets bénéficient des mises à jour de sécurité selon la version stable de la distribution exploitée en production. Les métriques sont récoltées en provenance des ressources du système (CPU, RAM, Réseau, Disque ...) et des services instanciés (serveurs web, SGBD, systèmes de cache ...) Les mises à jour de sécurité et la surveillance des métriques se fait au niveau système. C'est à dire que l'automatisation des procédures de mise à jour et de récolte des mesures intervient dans le cadre des procédures de maintenance définies par la version de Debian utilisée. Vous n'avez donc rien à faire pour garantir que votre application bénéficie d'un environnement système stable et sécurisé. Si vos applications ont besoin de librairies spécifiques (Imagick, ClamAV, Memcached, Composer ...) nous pouvons les installer à la demande.
Synthèse visible dans l'interface web de l'infogérance Bearstech pour les dépendances applicatives d'une application Wordpress exploitée nativement: la version du wordpress core et des modules qui l’accompagnent est analysée afin d’indiquer si une version supérieure est disponible (dans ce cas le badge de version s’affiche en rouge).
Infogérance des services conteneurisés Les applications conteneurisées ont une pile système indépendante du système hôte. Bearstech ne peut donc pas intervenir directement sur cette partie, car le choix du système sur lequel repose l'application devient la responsabilité des développeurs. L'infogérance s'applique donc à 2 niveaux : sur l'environnement d'exploitation (maintenance de l'OS de la machine hôte), et sur l'image Docker de base qui sert à builder l'application. Bearstech maintient à jour les images pour les distributions Debian Buster et Bullseye, et selon l'applicatif. A l'heure actuelle, nous maintenons les images Docker pour PHP (de la version 7.0 à 8.2), NodeJS (versions 16, 18 et 20), Ruby (version 3), et Nginx (latest). En production, les métriques de chaque conteneur sont récoltées au niveau de leur consommation CPU, RAM, Réseau et Disque. Afin de garantir une sécurité optimale pour les images Docker, nous maintenons des images applicatives pour les projets courants. Ces images reposent sur les procédures de mises à jour de sécurité des releases Debian. Nous encourageons donc fortement les développeurs à utiliser nos images afin de builder leurs applications.
Synthèse visible dans l'interface web de l'infogérance Bearstech pour les conteneurs instanciés sur un serveur, avec l'état de mise à jour de l'image de base: La colonne “FROM” à droite indique le statut de l’image Docker de base (le “from” du Dockerfile) à partir de laquelle l’image de l’application est construite:
vert: l’image de base est à jour, rouge: l’image de base est plus récente que celle utilisée par l’application. L’image de l’application doit être rebuildée et redéployée pour bénéficier des dernières mises à jour de sécurité jaune: le statut de l’image de base est inconnu.
Conclusion Le workflow devops que propose Bearstech n'est pas seulement un ensemble d'outils qui permettent de mettre en oeuvre les bonnes pratiques (sécuriser, tester, améliorer ...) pour intégrer et déployer les applications. C'est aussi un cadre logiciel générique qui repose sur des services opensource qui ont fait leur preuve (Gitlab, Grafana, Telegraf, Ansible ...) et que Bearstech maintient pour vous afin de vous garantir la transparence des processus, et la robustesse d'une plateforme qui vous accompagnera tout au long du cycle de vie de vos applications, et vous fera gagner en rentabilité sur vos projets. Plus qu'un service, c'est l'expérience de 18 ans d'expertises dans l'infogérance des applications sur le web qui vous sont transmises avec ce workflow.
Vous souhaitez en savoir plus ? Découvrez notre workflow DevOps et échangeons sur vos enjeux technologiques.
Makina Corpusdéveloppe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz. Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Geotrek est une suite logicielle SIG open source composée de plusieurs briques et utilisée par plusieurs dizaines de structures en France (parc nationaux et régionaux, départements) pour administrer leur territoire et valoriser les activités de pleine nature auprès du public. Makina Corpus assure le suivi, l’assistance et la maintenance de ce logiciel pour plus d’une trentaine de clients.
En collaboration avec l’équipe Geotrek composée de développeurs front end, back end, chef de projet et UX designer, vos missions consisteront à :
Accueillir et pré-qualifier les demandes des utilisateurs (questions d’usage, bug techniques, demandes de développements, etc.)
Contribuer, au premier niveau, au traitement des demandes ou à la résolution des incidents (fournir une assistance fonctionnelle complète sur plusieurs logiciels, configurer les outils, rediriger vers la documentation)
Faire prendre en charge les demandes plus avancées par les ressources capables d’y apporter une solution
Suivre les incidents et suivre le traitement des demandes clients
Selon l’envie et les compétences, vous aurez l’opportunité de :
Pouvoir configurer des briques logiciels, déployer des instances en production
Développer des scripts et morceaux de code en Python/Django
Réaliser de l’intégration web
Donner des formations à l’utilisation du logiciel
Nous mettrons en place un plan de formation adapté pour vous permettre d’acquérir rapidement une très bonne connaissance de Geotrek et de son écosystème.
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine).
Profil
Vous êtes issu.e d’une formation minimum Bac+2 en informatique (en développement, intégration ou administration systèmes) et recherchez un poste alliant la relation client et la technique.
Vous êtes capable de prendre en main un outil de ticketing et une plateforme de gestion d’incidents.
Vous aimez chercher, tester, reproduire des incidents, expliquer et vulgariser.
Ce serait un plus si :
Vous possédez une expérience en développement Python/Django, ou en intégration web. Vous avez déjà participé à du support logiciel
Vous connaissez le milieu de la randonnée / ou aimez pratiquer un sport de nature; vous avez une véritable appétence pour la cartographie.
Ce poste requiert d’excellentes qualités relationnelles permettant d’identifier au mieux les besoins clients.
Vous possédez une excellente expression orale et écrite, et vous épanouissez dans le travail en équipe car vous serez l’interface principal entre nos clients et l’équipe technique.
Vous appréciez de gérer en simultané de nombreux clients passionnés et avez le sens des priorités.
Apprendre toujours plus vous stimule !
Informations complémentaires
Dans la ruche collaborative Makina Corpus on dit ce qu’on fait : les équipes évoluent dans une ambiance motivante et stimulante (projets et contrib Opensource, participations encouragées à des évènements/meetup , émulation entre personnes passionnées, technos innovantes à tester, veille…) et contribuent aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée, esprit collaboratif…).
Mais surtout chez Makina on fait ce qu’on dit : vous avez besoin de le voir pour le croire ? Venez nous rencontrer, un.e makinien.ne pourra vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique nous vous attendons !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités.
Makina Corpusdéveloppe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz… Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Vous renforcerez notre équipe pluridisciplinaire (ergonome, graphistes, développeurs back end/front end, SIG, DBA, mobile…) et interviendrez sur toutes les phases de différents projets (chiffrage, conception, architecture, production, tests, livraison etc) tels que :
Réalisations d’applications et de back end (Django, Flask)
Applications métier manipulant de gros volumes de données, avec des règles de gestion métier spécifiques ou nécessitant des interconnexions avec d’autres applications du système d’information
Vous serez accompagné(e) tout au long de votre montée en compétences: encadrement par un développeur sénior (pair-programming, codes reviews…), interactions/transmission de compétences avec les équipes, formations, autoformation etc.
Vous aurez l’opportunité de :
Choisir vos propres outils de travail, et évoluer dans une ambiance motivante et stimulante (projets et contributions à des logiciels libres, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technologies innovantes à tester, veille…)
Évoluer dans un environnement technique interdisciplinaire permettant à chacun d’avoir un véritable impact sur les décisions et où l’initiative personnelle est valorisée.
Jouer un rôle visible dans les communautés du logiciel libre : création et amélioration de logiciels libres / Participation à la vie de communautés de développeurs / Coordination de sprints, de bugfests / Réalisation de présentations, conférences, bar camps, formations, lightning talks / Écriture de livres blancs…
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine).
Profil
De préférence niveau Bac +5 en informatique. Votre parcours vous permet de justifier d’une première expérience des technologies Python et Django, vous êtes plutôt à l’aise dans un environnement GNU/Linux.
Vous avez envie d’acquérir certaines des compétences suivantes :
PostgreSQL/PostGIS
OpenStreetMap
MapBox GL JS / Leaflet
Tuilage Vectoriel
Flask
Elasticsearch
Docker
Vous aurez à comprendre les besoins métiers à réaliser et être force de proposition pour toute amélioration. Votre goût du travail en équipe, votre curiosité et votre adaptabilité aux évolutions technologiques seront des atouts indispensables.
Nous attachons beaucoup d’importance aux compétences, à la passion du métier et à une forte motivation.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée - grâce à la souplesse des horaires et au télétravail encadré -, travail collaboratif, solide couverture santé…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ? Venez nous rencontrer, vos futurs collègues pourront vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique rejoignez-nous !
Écrivez-nous et racontez qui vous êtes et ce qui vous anime. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités. Montrez-nous un peu de code si vous voulez:)
Une interview passionnante du créateur de Mojo: un superset de Python orienté IA et ML, jusqu’à 35000 fois plus rapide. Ils discutent C, C++, Python, Swift, hardware, perf, et le futur de la programmation.
Le prochain meetup Python a lieu le jeudi 22 juin dès 19h. Nous serons hébergés par Socotec (vers Sans Souci / Manufacture).
Au programme : gRPC avec Django, présenté par Adrien et Léni !
Cela commence à faire pas mal de temps qu'on ne vous a pas raconté ce que devenait notre projet coopératif ! En fait on n'a pas vraiment pris le temps d'en discuter publiquement depuis le 24 septembre 2021 dans notre article de blog De Yaal à Yaal Coop qui raconte la genèse de Yaal Coop 🙈.
Pour remédier à ça, on a décidé de publier ici notre rapport de gestion 2022. Le rapport de gestion, rédigé annuellement à l'intention des associé·es avant l'Assemblée Générale Ordinaire (AGO) validant les comptes annuels, permet de faire le point sur la situation de l'entreprise durant l'exercice écoulé et de mettre en perspective celui à venir. On n'est pas encore rompu à l'exercice mais on s'est dit que c'était une bonne idée de le partager avec vous 🙌.
Notre AGO (la deuxième seulement depuis le début de l'aventure !) s'est déroulée mi-mai, en présence de tous nos associés, ou presque (quelle idée aussi d'avoir tenté un vol plané à vélo pendant mes vacances une semaine plus tôt 🤕😗🎶). L'AGO, au-delà de son caractère officiel et obligatoire, est surtout pour nous l'occasion de faire un pas de côté, regarder le chemin parcouru et vérifier qu'on ne s'est pas perdu en route. En discuter avec les associé·es non salarié·es qui ne vivent pas notre projet au quotidien est aussi très salutaire ! L'occasion d'échanger sur les bonnes (ou moins bonnes) pratiques, s'inspirer... En buvant quelques bières 🍻 !
Sans plus de transition, voici le rapport que nous leur avons adressé.
N'hésitez pas à passer nous voir pour en discuter plus largement si vous le souhaitez ! (Mais toujours pas le mercredi, c'est resté le jour du télétravail collectif 😉)
Cher·e sociétaire,
Nous avons l’honneur de vous présenter notre rapport sur les opérations de l’exercice clos le 31 décembre 2022, ainsi que sur les comptes annuels dudit exercice soumis aujourd’hui à votre approbation. Ce rapport a été rédigé collectivement par le collège des salarié·es de Yaal Coop.
Un peu d'histoire : les faits marquants de l'année 2022
janvier : Yaal Coop obtient l'agrément CII : toutes nos prestations liées au développement de prototypes et aux installations pilotes de nouveaux produits sont dorénavant éligibles au CII (Crédit d'Impôt Innovation) pour nos clients. Janvier marque aussi le début d'une mission pour Telecoop, premier opérateur télécom coopératif, d'assistance et développement de nouveaux outils sur quelques jours par mois.
février : Nous démarrons une prestation pour le Ministère de l'Éducation nationale afin de remettre à niveau et poursuivre le développement de leur projet informatique B3Desk (frontal OpenIDConnect de gestion simplifiée des visioconférences BigBlueButton de l'Éducation nationale et des agents de l'État).
mars : Un gros chantier de séparation de l'infrastructure technique de Yaal Coop et Yaal SAS est mené à l'occasion d'une migration de serveurs de notre hébergeur historique Scaleway. On bascule alors notre infrastructure interne sur nos serveurs hébergés chez notre hébergeur associatif local Aquilenet sur lesquels nous gérons un cluster lxc/lxd de conteneurs linux. Yaal SAS devient par la même occasion le premier client officiel de notre offre Nubla Pro !
avril : Nous réalisons une journée de formation en équipe sur le DDD (Domain Driven Design), une technique de conception logicielle orientée métier, animée par Bertrand Bougon.
mai : Un temps fort de la vie coopérative de Yaal Coop, c'est l'heure de sa toute première Assemblée Générale Ordinaire, en présence de l'ensemble de ses associé·es. 🎉
juin : Une petite mission démarre avec Freexian pour retravailler son identité graphique et refondre ses deux sites web statiques ainsi que son fil d'actualités.
août : C'est la fin de notre mission régulière pour Sinch sur Myelefant, le projet historique de Yaal SAS racheté en 2019. Yaal Coop vole maintenant complètement de ses propres ailes !
septembre : Notre associé Yaal SAS est remplacé par Gruyère SAS (formé d'un sous ensemble plus réduit des anciens associés de Yaal SAS) dans le collège des investisseurs de Yaal Coop. C'est aussi le début de notre intervention sur la startup d'État Projet Impact pour lancer le développement d'une plateforme française d'aide aux entreprises à satisfaire leurs obligations réglementaires en matière de performance extra-financière.
octobre : Une petite mission est réalisée pour PodEduc, une plateforme vidéo pour les agents de l'Éducation nationale, via deux contributions au logiciel libre Esup-Pod.
novembre : Notre projet interne Canaille, logiciel libre de gestion d'identité et d'autorisations, obtient un financement de la fondation NLNet d'un montant de 7 000€ pour développer quelques fonctionnalités prévues en 2023.
décembre : Nubla, notre service d'hébergement e-mail et cloud, fait officiellement partie des 6 nouveaux CHATONS du Collectif des Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires ! Nos services sont disponibles gratuitement sur demande aux premiers beta-testeurs. Enfin, nous préparons l'embauche de Julien qui rejoint la coopérative à la toute fin du mois pour travailler sur une mission avec NEHS Digital, éditeur de solutions santé pour améliorer l'efficience du parcours de soin.
Notre projet coopératif
Sociétariat
Excepté Julien, arrivé le 27 décembre 2022, tous·tes les salarié·es sont également associé·es au sein de Yaal Coop sur l'année 2022 et détiennent chacun·e une voix égale au sein du collège des salarié·es, conformément à nos statuts.
Seul changement notable au sein des autres collèges : Yaal SAS est remplacé par Gruyère SAS dans le collège des investisseurs en septembre 2022, ce qui ne modifie pas le capital social de la coopérative.
Nous proposons à Colin Garriga-Salaün, le Président de Yaal SAS, de devenir associé en son nom propre dans le collège des observateurs. Celui-ci accepte en avril 2023.
La composition des collèges en date du 9 mai 2023 est la suivante :
Collège des salariés - 50% des droits de vote
Prénom NOM / RAISON SOCIALE
Nombre de parts
Brunélie LAURET
100
Camille DANIEL
100
Loan ROBERT
100
Stéphane BLONDON
100
Éloi RIVARD
100
Collège des investisseurs - 16,66% des droits de vote
Prénom NOM / RAISON SOCIALE
Nombre de parts
GRUYERE
50 000
Collège des bénéficiaires - 16,66% des droits de vote
Prénom NOM / RAISON SOCIALE
Nombre de parts
FINACOOP NOUVELLE-AQUITAINE
100
Collège des observateurs - 16,66% des droits de vote
Prénom NOM / RAISON SOCIALE
Nombre de parts
Arthur LEDARD
100
Colin GARRIGA-SALAÜN
100
(sous réserve de validation de l'entrée de Colin GARRIGA-SALAÜN par la prochaine Assemblée Générale)
Favoriser une organisation horizontale
Mise en place d'une forme d'holacratie dans Yaal Coop
Après quelques discussions et ateliers organisés en interne, nous avons décidé de nous inspirer de l'holacratie pour définir des rôles tournants permettant d'assurer la prise en main commune de la gouvernance de la coopérative par les salarié·es. Ces rôles nous donnent un cadre pour protéger le fonctionnement horizontal souhaité dans Yaal Coop et nous protéger de la spécialisation des associé·es salarié·es.
Le système, la pertinence et la répartition des rôles sont améliorés au fil du temps, à chaque nouvelle réunion de gouvernance du collège des salarié·es, actuellement organisée tous les 3 mois.
Depuis sa mise en place, nous avons notamment fait la révision de la durée de certains rôles (pouvant aller de 2 semaines pour le rôle de Facteur·rice 💌 -qui relève le courrier entrant sur nos différentes boîtes aux lettres- ou Sentinelle 📟 -qui surveille et réagit aux alertes de monitoring-, à 2 ans avec backup pour le rôle d'Argentier·e 🪙 -qui met à jour et surveille la trésorerie-). Nous avons également ajouté des précisions sur les attentes d'autres rôles lors de ces réunions, en questionnant les manquements auxquels nous avons pu faire face.
Ces réunions de gouvernance viennent en complément de nos réunions de suivi hebdomadaire lors desquelles nous faisons le point sur l'ensemble des tâches et projets en cours dans la coopérative.
Enfin des réunions de stratégie sur l'investissement réunissent également le collège des salarié·es tous les 3 mois pour faire le bilan de l'investissement réalisé au trimestre précédent et fixer les priorités du trimestre suivant.
Changement de présidence proposé en 2023
Les mandats concernant la présidence et la direction générale de la coopérative sont établis statutairement pour une durée de 4 ans. Nous avons décidé de mettre fin prématurément à ceux courant depuis le lancement de la coopérative en septembre 2020 afin de renforcer une représentativité et une responsabilité tournante au sein de Yaal Coop. Nous vous proposons donc d'élire notre nouvelle Présidente, Brunélie, dès la prochaine AGO !
Favoriser l'activité et les acteurs ayant un impact social ou environnemental, de préférence locaux
Investissement technique
Nous sommes toujours associés avec Lum1, premier annuaire collaboratif dédié et réservé aux professionnels du social et de la santé, projet pour lequel nous effectuons du développement en continu, à un rythme plus réduit que lors du développement intensif de la deuxième version de la plateforme l'année précédente.
En 2022, nous n'avons pas signé de nouveau projet associé, toutefois certains de nos prospects montrent de l'intérêt pour cette forme de coopération qui permet d'aller au delà du lien unissant prestataire et client.
Investissement interne
Notre projet Nubla, développé en interne, est un service d'hébergement cloud membre des CHATONS (Collectif des Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires) depuis décembre 2022. Son ambition est de proposer un service basé sur des solutions libres pour permettre à tous et toutes de se libérer des géants du web afin de mieux maîtriser l'utilisation de ses données et de soutenir l'écosystème numérique local.
Économie Sociale et Solidaire (ESS)
Parmi nos clients, conformément à nos engagements en tant que SCIC, figurent des acteurs de l'économie solidaire et sociale comme Telecoop.
Nous avons également été en contact et en discussion avec d'autres acteur·ices de ce milieu comme prospects, sans forcément aboutir à une prestation.
En 2022 nous avons souscrit des parts chez plusieurs de nos fournisseurs coopératifs : notre banque Crédit Coopératif et notre cabinet de paie Assistea, ainsi que Telecoop, notre fournisseur téléphonique mobile et notre client sur une mission du premier semestre 2022.
BetaGouv et direction du numérique pour l'éducation
Toutes nos prestations ne sont pas du domaine de l'ESS, mais en 2022, nous avons multiplié les prestations pour des projets de l'État (La startup d'État Projet Impact développée par la direction générale des entreprises en lien avec BetaGouv, le frontal de visioconférence B3Desk et la plateforme de vidéos PodEduc portés par la direction du numérique pour l'éducation).
Via ces missions, nous pouvons espérer participer à l'amélioration des services publics impactés par ces réalisations, sur du code source libre.
Ces missions qui se poursuivent en 2023 nous permettent en outre d'assurer une certaine pérennité dans l'activité et les revenus de Yaal Coop, et participent à l'étendue de notre réseau de clients et au rayonnement de la coopérative dans le milieu.
Acteurs locaux
Tous nos clients et prospects ne sont pas des acteurs locaux, mais une partie sont bien basés à Bordeaux. Notre client Lum1 et plusieurs de nos prospects sur l'année étaient des organismes bordelais ou girondins.
Nubla, notre service d'hébergement cloud membre des CHATONS, voit une bonne part de ses utilisateurs situés dans la région, que ce soit sur l'offre publique ou sur l'offre Pro. Notre communication et nos ambitions s'orientent en partie sur son aspect local et souverain.
Impact environnemental
Comme beaucoup, nous sommes sensibles aux enjeux environnementaux et tentons de limiter à notre échelle l'impact environnemental de la coopérative.
La question du numérique soutenable est une question de plus en plus posée. En tant que société informatique, nous sommes évidemment concernés. Plutôt qu'un greenwashing de façade, nous nous concentrons aujourd'hui sur des actions concrètes :
le choix des projets sur lesquels nous travaillons, qu'on souhaite le plus possible porteurs de sens et proches des valeurs que nous défendons. Le premier levier pour diminuer l'impact environnemental du numérique est avant tout de ne PAS construire des produits ou des fonctionnalités inutiles, irresponsables, ou incompatibles avec le matériel existant.
limiter le renouvellement de notre matériel informatique en privilégiant en 2022 la réparation d'un de nos ordinateurs plutôt que son remplacement, l'achat d'un serveur d'occasion pour compléter notre infrastructure et le remplacement de ventilateurs défectueux par du matériel d'occasion sur un serveur existant.
La séance de projection du documentaire libre "Responsables du Numérique" produit par Nouvelle-Aquitaine Open Source (NAOS) en juillet 2022 nous a confortés dans l'importance de ces choix et le rôle à jouer du logiciel libre.
Réseau Libre Entreprise
Le réseau Libre-entreprise regroupe des entreprises à taille humaine ayant des spécialités proches ou complémentaires dans le domaine du logiciel libre. Ces entreprises partagent des valeurs et modes de fonctionnement proches des nôtres, basés sur la démocratie d'entreprise, la transparence et la compétence. C'est pourquoi nous avons candidaté à les rejoindre dans l'espoir de pouvoir s'aider mutuellement. Nous sommes actuellement en période d'observation. Cette période est un préalable obligatoire avant d'être validé par les membres du réseau Libre-entreprise.
Favoriser l'utilisation et le développement de logiciels libres
L'ensemble de nos contributions à des logiciels libres sont visibles sur ces différents articles de blog, publiés de façon saisonnière :
Au delà de ces contributions, la valorisation du logiciel libre est une valeur forte de la coopérative, que ce soit dans le choix même de nos missions de prestation (BetaGouv, Freexian, etc.) ou le développement de notre projet interne Nubla.
Pour appuyer cet attachement, nous avons adhéré en juillet 2022 à Nouvelle-Aquitaine Open Source (NAOS), un pôle de compétences régional en logiciels et technologies libres et open source.
Son objectif est de promouvoir le développement d’une filière économique pour les technologies libres et open source sur le territoire de la région Nouvelle-Aquitaine.
Enfin en novembre 2022, nous avons contribué financièrement à hauteur de 500€ à l'AFPy (Association Francophone Python) pour sponsoriser l'organisation de l'édition 2023 de la PyconFR qui a eu lieu du 16 au 19 février 2023 à Bordeaux. La PyconFR est une conférence nationale gratuite dédiée au regroupement des personnes intéressées par le langage de programmation Python, principal langage utilisé au sein de la coopérative.
Bilan financier et compte de résultat 2022
Comme nous nous y attendions, le résultat du bilan 2022 est nettement en deça de celui du premier exercice comptable de 2020-2021 avec un chiffre d'affaires de 220 028€. La fin du contrat avec Sinch, le ralentissement du rythme de développement de Lum1 et la plus petite durée de l'exercice comptable (12 mois versus 16, dont 14 mois d'activité lors du précédent exercice) en sont les principales raisons.
Il est tout de même excédentaire avec un résultat net comptable de 46 987€. Ce bénéfice est toutefois à nuancer par l'annulation de 42 492€ de produits constatés d'avance de l'exercice précédent (règlements perçus d'avance lors de l'exercice précédent et comptabilisés en 2022). Nous n'avons pas enregistré de nouveaux produits constatés d'avance pour le prochain exercice. Sur la base de ce résultat encore fragile, nous n'avons pas jugé raisonnable d'augmenter les salaires comme nous avions envisagé de le faire, et ce malgré l'inflation.
Le détail du bilan est disponible dans les comptes annuels 2022 rédigés par notre cabinet d'expertise comptable Finacoop.
Conformément à la dernière décision d'Assemblé Générale, l'intégralité du bénéfice 2022 est affecté aux réserves impartageables de la coopérative, dont 15% à la réserve légale.
Aucun dividende n'a été versé depuis le premier exercice comptable de Yaal Coop et les dirigeants ne touchent aucune rémunération liée à leur statut de dirigeant.
Perspectives
L'exercice 2023 a commencé et devrait se poursuivre en continuité avec la fin de l'exercice 2022 : les principales missions pour l'État ont été reconduites (Projet Impact, B3Desk) et le développement de Lum1 se poursuit à un rythme plus réduit. En parallèle des discussions s'engagent ou se poursuivent avec plusieurs prospects.
Le financement de NLNet pour le développement de notre logiciel libre Canaille va nous permettre de le faire évoluer pour favoriser son adoption par d'autres acteurs. Nous sommes également en recherche de financement pour finaliser notre solution Nubla et son ouverture au grand public !
Le déménagement de Yaal Coop dans nos futurs locaux à Bègles est prévu pour l'été 2023 ! La gestion des travaux et la recherche de futurs colocataires se poursuivent.
Enfin, nous avons l'ambition d'un meilleur résultat pour 2023, en vue d'augmenter collectivement les salaires, sans quoi nous mettrions en doute la réussite de notre projet coopératif.
Conclusion
Nous espérons que les résolutions qui vous sont proposées recevront votre agrément et que vous voudrez bien donner au Président et à la Directrice Générale quitus de leur gestion pour l’exercice écoulé.
Rédigé collectivement par l'équipe salariée de Yaal Coop,
Signé par Éloi Rivard, Président de Yaal Coop, et Camille Daniel, Directrice Générale de Yaal Coop.
Parmi les élèves de première générale et technologique, moins de 10% ont choisi la spécialité numérique et sciences informatiques (contre 25% en moyenne pour l’ensemble des spécialités), et moitié moins parmi les élèves de terminale (source).
Par ailleurs, 92% (chiffres 2018) des 12-18 ans possèdent un smartphone, aussi ce journal va-t-il développer les points abordés dans ce journal et du projet sur lequel il a débouché.
Programmer avec son smartphone
Pourtant incomparablement plus puissant que les ordinateurs avec lesquels beaucoup d'entre nous ont connus leurs premiers émois numériques… et parfois digitaux (ceux qui ont fait leurs premières armes avec le Sinclair ZX81 et son clavier à membrane comprendront), s'adonner à la programmation est loin d'être facile avec un smartphone, même en dehors de toute considération concernant leur praticité pour cette tâche.
Replit apporte une réponse, à la fois assez complète et facilement accessible, en proposant un EDI sous la forme d'une application mobile, pour Android et pour iOS, mais également de service web, donc accessible avec un ordinateur personnel.
Il est néanmoins nécessaire de posséder un compte (gratuit) pour accéder aux fonctionnalités d'édition, mais, concernant l'utilisation de l'application mobile ou web sur smartphone, on peut utiliser le même compte que celui qui est (hélas) généralement requis pour l'utilisation d'un dispositif Android ou iOS.
Programmer pour son smartphone
Replit donne accès à de nombreux langages qui, pour la plupart, ne permettent que de manipuler, de base, une interface texte, donc non adaptée aux smartphones.
Pour Python, on dispose certes de Tkinter et d'autres bibliothèques graphiques, mais les conditions dans lesquelles s'affichent les interfaces graphiques qui en résultent les rendent difficilement utilisables avec un smartphone.
Replit permet également de programmer avec le trio HTML/CSS/JS, ce qui permet d'obtenir des interfaces nettement plus adaptées aux smartphones, mais JS comme langage d'apprentissage de la programmation est loin de faire consensus.
La réponse apportée par le toolkitAtlas consiste à s'appuyer sur HTML/CSS, mais d'utiliser Python pour la programmation. Utiliser le toolkitAtlas revient à développer une application web, donc avec une interface utilisable avec smartphone, mais sans avoir à utiliser JS, ni à se préoccuper de l'infrastructure logicielle et matérielle généralement associée aux applications web.
Programmer pour son smartphone (bis)
La démocratisation des smartphones et de l'informatique en général doit beaucoup aux interfaces graphiques, mais aussi à la généralisation de la mise en réseau des appareils, qui permet notamment à leurs utilisateurs d'interagir entre eux. Cependant, les fonctionnalités réseaux ne sont guère accessibles aux débutants, de par les concepts à maîtriser mais également des bibliothèques logicielles à manipuler, quelque soit le langage considéré.
Avec le toolkitAtlas, la gestion des interfaces est réalisée au sein d'un programme qui fait également office de backend. Toutes les actions requises par des évènements occurrant dans une session peuvent ainsi facilement être répercutées sur toutes les autres sessions, et ce de manière totalement transparente.
Replit
Replit est quasiment indispensable dans un premier temps, car, en permettant l'exécution des programmes Python sans avoir à installer l'interpréteur correspondant, il permet d'entrer dans le vif du sujet en quelques clics.
Pyodide pourrait être une solution de remplacement à terme, malheureusement inenvisageable dans l'immédiat à cause de cette limitation.
Il y a aussi Termux (Android) et iSH(iOS) qui permettent d'installer un interpréteur Python directement sur le smartphone/la tablette et ainsi de se passer de Replit pour l'exécution des programmes.
À noter que Termux/iSH disposent de git et permettent ainsi de jongler entre ordinateurs personnels et smartphones/tablettes en s'appuyant sur les forges logicielles.
Zelbinium
Zelbinium n'est pas un énième site d'apprentissage de la programmation. Son but est de donner accès à des applications ayant la particularité d'être utilisables avec un smartphone, avec tous les outils permettant en quelque sorte de "démonter" ces applications pour en comprendre le fonctionnement, comme l'on démonterait un quelconque appareil dans le même but.
Le site est pour le moment pensé pour être introduit dans le cadre d'un atelier. Le rôle des intervenants de ces ateliers ne serait pas d'expliquer le fonctionnement des applications, mais d'indiquer aux participants où et comment trouver les ressources nécessaires à la compréhension de ce fonctionnement, de manière à ce qu'ils puissent ultérieurement progresser dans l'apprentissage de la programmation de manière autonome.
Pour le code source des applications, la licence est MIT, pas trop contraignante concernant la réutilisation de ce code tout en étant compatible avec la licence des programmes qui ne sont pas une création originale pour le projet.
Concernant les fichiers du site web, le choix de la licence fait encore l'objet d'une réflexion. Une licence trop permissive facilite la réutilisation, mais peut rebuter les éventuels contributeurs qui pourraient craindre un "pillage" de leurs contributions par des structures commerciales sans scrupules. Une licence trop restrictive, à l'inverse, peut rassurer les contributeurs sur ce point, mais freiner la réutilisation…
Zelbinium et les réseaux sociaux
Les réseaux sociaux occupent un partie importante du temps que les jeunes passent sur leur smartphone, mais ils sont hélas également l'objet de dérives à l'origine d'évènements dramatiques, comme nous le rappelle régulièrement l'actualité.
En rendant la programmation plus attrayante et accessibles sur smartphone, les jeunes consacreront peut-être moins de temps aux réseaux sociaux au profit d'activités de programmation.
Cependant, il est illusoire, voire préjudiciable, de vouloir les détourner complètement des réseaux sociaux, vu la part qu'ont pris ces derniers dans leurs interactions sociales. Aussi est-il important de relever qu'avec Replit, ou les forges logicielles, il est possible d'utiliser les réseaux sociaux pour partager ses réalisations et en discuter.
Par ailleurs, le toolkitAtlas facilite la création d'applications permettant à plusieurs personnes d'interagir, chacun avec son propre smartphone, auxquelles on accède grâce à un simple lien aisément partageable via les réseaux sociaux.
Ainsi, une des ambition de Zelbinium, outre de leurs offrir de nouvelles perspectives quant à leur avenir professionnel, est d'assainir les échanges des jeunes sur les réseaux sociaux en faisant de la programmation un des sujets de leurs conversations.
Je viens d'assister à une présentation sur l'utilisation des AI génératives dans le cadre de l'analyse des données.
Chat GPT nous a montré comme il était capable de pisser rapidement du code pas trop mal foutu. Il nous a aussi montré qu'il n'avait aucune réflexion critique sur les résultats. Par exemple, cela ne le gênait pas du tout d'arriver à la conclusion qu'un train connaissait son retard le plus important dans une gare qui a priori ne faisait pas partie du trajet normal du train.
Quoiqu'il en soit, cela démontrait quand même un potentiel intérêt à utiliser ce type d'AI quand on doit écrire des scripts Python. J'aurais bien envie de tester un peu cette piste mais pas trop envie d'utiliser une boite noire disponible sur internet avec bien des incertitudes sur ce que peuvent bien devenir nos données. C'est là que ton avis m'intéresse :
Quels modèles d'AI génératives installable sur un PC perso aurais-tu tendance à utiliser pour pisser des scripts python ?
Chez Bearstech, nous utilisons des procédés "devops" depuis toujours, déjà motivés par une approche éco-responsable pour l'optimisation des ressources allouées sur de nombreuses infrastructures cloud dont nous assurons l'infogérance, nous avons opté pour la technologie Xen dès 2007 afin de créer des machines virtuelles qui fonctionnent au plus près des besoins des applications. Petit à petit notre démarche a évolué pour stocker les rôles d'installation et la définition de notre infrastructure sur des dépôts de version tels que SVN puis Git dans une approche "GitOps" qui nous a permis de consolider l'automatisation du déploiement d'une partie de notre infrastructure, en respectant les principes qui ont été décrits par RedHat:
Un workflow standard pour le développement d'applications Une sécurité renforcée avec la définition des besoins de l'application dès le départ Une meilleure fiabilité grâce à la visibilité et au contrôle de versions via Git La cohérence entre tous les clusters, clouds et environnements sur site
Bearstech est donc une société qui a su industrialiser son infrastructure afin de concevoir, sécuriser, déployer, et maintinir des systèmes informatiques fiables. Mais alors pourquoi proposer un workflow devops pour le déploiement d’applications ? Le devops c'est quoi ? D’un point de vue business, la mouvance "devops" est un moyen de rentabiliser les projets informatiques en intégrant la qualité dans le processus de développement. C'est un mouvement qui vise à optimiser les indicateurs clés de l’avancement des projets informatiques:
“lead time” : vise à réduire le délai de mise en œuvre “process time” : vise améliorer le temps de traitement des demandes “percent complete and accurate” : vise à augmenter le taux des fonctionnalités finalisées dans un cycle de développement.
Pour tenir ces objectifs, il faut réduire la fragilité des applications. La dette technique La fragilité des applications, c’est ce qu’on appelle la "dette technique". Elle peut être causée par l'accumulation de code dupliqué qui multiplie les risques de bugs, ou par des régressions : le code de librairies / modules / dépendances qui n'est pas à jour ou qui est obsolète. Pour ça, il "suffit" faire face au problème en factorisant le code et en augmentant la couverture de code par les tests. Ensuite il y a aussi le fait que l'environnement de développement est difficilement reproductible pour le rendre compatible avec ce qui sera utilisé en production, surtout quand on travaille à plusieurs: mon environnement est-il bien à jour ? mes dépendances sont-elles bien toutes installées ? bénéficient-elles de la bonne version ? et mes collègues aussi ? etc... Tester dans un environnement reproductible, et qui soit commun à tout le monde, et à chaque étape du développement, n'est pas aussi simple que cela peut paraître, et c'est là que Bearstech intervient afin de mettre à disposition son expertise pour déterminer un cadre méthodologique (avec ses outils) qui permet d'apporter des preuves de la fiabilité d'une application dans ses différents environnements d'exploitation. Limites de la conteneurisation Docker a l'avantage de définir un langage commun entre les devs et les admins pour régler la question des dépendances logicielles pour une application donnée, et assurer un environnement prévisible et reproductible sur toute la chaîne d'intégration de l'application, jusqu'à son déploiement en production. Toutefois, la reproductibilité a ses limites et on n'est jamais à l'abri d'une différence de version mineure entre 2 images Docker et cela peut entraîner quelques effets de bords. C'est pourquoi l'utilisation d'un serveur de CI qui va builder l'image contenant l'application afin d'y effectuer des tests d'intégration peut être particulièrement utile:
gain de temps puisque cette tâche est automatisée historique des tests consultable pour tous les membres du projet systématisation des tests d'intégration
En conteneurisant une application on peut facilement définir un environnement stable, et même de manière temporaire pour valider la fiabilité de l’application en faisant jouer des tests unitaires ou des tests fonctionnels, avant la publication en production. Mais tous les projets n’ont pas vocation à être conteneurisés en production, notamment les projets qui n’évoluent pas souvent, pourtant ce travail d’empaquetage des dépendances a un intérêt: les devs et les admins se mettent d'accord sur les dépendances, leurs versions, et le tout est décrit dans des fichiers. C'est une sorte de contrat. Infrastructure As Code Les technologies utilisées par le workflow devops de Bearstech sont toutes open-source et exploitent ce qu’on appelle l’Infrastructure As Code. Bearstech utilise ces outils depuis de nombreuses années, dès lors que nous nous sommes mis à écrire des rôles Xen pour provisionner des machines virtuelles. Notre workflow devops est centré sur un Gitlab, avec sa facilité pour versionner le code, créer des demandes, valider des merge-request, jouer avec les branches … Et avec son serveur de CI, nous définissons des runners pour les projets qui lancent des traitements automatiques sur le code des applications dans un environnement shell ou docker. A chaque étape du workflow, nous utilisons des procédés spécifiques d'IaC.
Développer: Pour le développement, il est probable que les développeurs préféreront travailler dans un environnement Docker. Les dépendances logicielles peuvent ainsi être gravées (dans le silicium) de fichiers (Dockerfile et docker-compose) afin de permettre à la CI de reproduire l'environnement applicatif utilisé par les développeurs.
Intégrer: Afin de valider l'intégration de l'application dans un environnement système, la CI va reproduire les étapes d'installation des composants, et lancer les services de l'application directement sur la CI. C'est le rôle du fichier .gitlab-ci d'enchaîner ces différentes étapes, puis d'ajouter les tests puis le déploiement. Le workflow se sert de la registry Gitlab qui permet de stocker les éléments construits dans la CI. Chacun des éléments est lié au job d'une pipeline dont il est originaire. On peut y stocker:
des images Docker des artefacts des assets packagés
Tester: Une fois l'application intégrée et instanciée sur la CI, il est possible de définir des tests fonctionnels sur l'application qui seront joués grâce à des images Docker qui embarquent des navigateurs headless (voir notre article sur les tests fonctionnels avancés)
Déployer: Le déploiement suit la phase des tests. Il va s'appuyer sur les variables (d'environnement et personnalisées) transmises par Gitlab, et exécuter les phases d'installation des éléments construits durant l'intégration (images Docker, assets, artefacts ...) à partir du code contenu dans le projet Gitlab. Notre workflow prévoit plusieurs modes de déploiements selon les besoins des projets:
Le système de déploiement prévu par notre workflow peut s'adapter aux besoins les plus fréquents des applications web. Il s'appuie sur des procédés écrits en shell ou sur des recettes Ansible.
Newsletter Inscrivez-vous à notre newsletter pour être tenu informé de notre actualité, de nos prochains webinars et articles.
Abonnez-vous à notre newsletter
Profiter des bonnes pratiques Échouer tôt Échouer tôt pour réduire le temps et les coûts de réparation : il est moins coûteux de corriger un défaut au fur et à mesure qu'il est détecté tôt dans le cycle. Dans notre workflow, le procédé du "Shift Left" s'appuie sur l'utilisation des pipelines de Gitlab et le retour d'information qu'elles apportent lors du build de l'application, ou lors des tests, ou lors de la phase de déploiement facilitent la vie du développeur. Il peut ainsi déterminer les points bloquants à mettre en place lors des tests d'intégration ou des tests fonctionnels pour valider ou non le déploiement de l'application. Un scénario d'intégration et de déploiement simple
Le test d'intégration dans la CI permet de valider le bon fonctionnement des dépendances logicielles. Si le test ne passe pas, le push de l'image Docker et le déploiement ne se lancent pas:
Déployer sereinement Déploiement de conteneurs Le workflow de Bearstech permet de lever une bonne partie de la fragilité des conteneurs en exploitation :
Dans le workflow, les conteneurs ne bénéficient jamais de super-privilèges: il est obligatoire de spécifier un utilisateur non root dans les images de vos applications il est interdit de définir des volumes dans les images, ils sont créés au déploiement par le workflow, et correctement partagés sur la machine hôte les services publiés dans les conteneurs ne sont jamais exposés publiquement, ils sont derrière un reverse-proxy (Traefik) qui s'occupe de la couche TLS les services sensibles comme les BDD sont déployés de manière native, elles ne tournent pas dans des conteneurs les logs de vos applications sont centralisés et accessibles directement depuis le conteneur en cours d'exploitation
Déploiement d'applications natives Tous les projets n’ont pas vocation à être conteneurisés, c’est pourquoi notre workflow n’impose aucune règle prédéfinie, et s’adapte aussi aux modes de déploiement natifs, sans avoir besoin de builder des images Docker (mais on peut aussi mixer les 2 modèles).
le projet sera déployé et instancié vers une machine cible de manière native, en utilisant les ressources d'une VM derrière un serveur web. La CI s’occupe de compiler les assets, si besoin, et de les mettre à disposition dans les packages de Gitlab. Ensuite, le workflow s'occupe de récupérer le code et les packages, puis de les déployer en configurant convenablement l'environnement d’exploitation. Il s’occupe aussi des certificats via LetsEncrypt.
Un workflow qui couvre toutes les étapes du cycle de développement Du développement à la mise en production, le workflow enchaîne les tâches nécessaires à la validation des applications avant leur livraison, et permet ensuite de les déployer selon les besoins :
en staging, il peut être utile d'utiliser les conteneurs pour réaliser des déploiements différentiables selon les branches, pour faire de l'app-review. en production, on pourra opter pour un déploiement de l'application en natif pour bénéficier d'une infogérance qui privilégie la stabilité et la sécurité du système.
Dans cet exemple de pipeline qui contient 2 points bloquants, une application est intégrée, testée, puis déployée en staging puis en production, depuis un serveur de CI infogéré, en utilisant les services de déploiement fournis par Bearstech.
A noter que le serveur de CI infogéré par Bearstech bénéficie également d'une infogérance. C'est un serveur qui doit être sécurisé car il peut être soumi à des opérations sensibles notamment si il utilise des conteneurs peu respectueux des règles de sécurité. C'est pourquoi nos serveurs de CI intègrent la technologie LXC (Linux Conteneurs) afin d'isoler les environnements d'exécution du reste de l'infrastructure du workflow. Services infogérés en production La stabilité de l'environnement d'exploitation est une condition nécessaire pour améliorer la fiabilité des applications. Il est pratique de développer (et de tester) avec des services directement fournis par les images Docker. Mais pour la production, les contraintes sont différentes: il est vivement conseillé de profiter de réglages fins du service, du backup, d’une potentielle réplication, mais surtout de métrologie et d’une astreinte. Les services pris en charge par Bearstech bénéficient d'infogérance et d'hébergement (mise à jour, maintenance, astreinte). En choisissant cette option avec le workflow, pour un ou plusieurs services, il est alors possible d'ordonner à l’infrastructure et à nos outils de créer les ressources nécessaires pour permettre aux applications de consommer le service infogéré (routage, authentification ...). La supervision et le monitoring sont fournis par les outils de Bearstech. Analyser pour s'améliorer Le workflow devops de Bearstech est trans-disciplinaire, il apporte des outils d'analyse aux développeurs front et back pour améliorer leur code, aux administrateurs pour obtenir des mesures et tracer les logs, aux devops pour ajouter librement des étapes dans les procédures d'intégration, et aux chefs de projets pour pouvoir déployer plus fréquemment et sereinement. Voici quelques exemples de services qui peuvent être ajoutés au workflow et qui peuvent aider à l'amélioration des applications. Pa11y Pa11y est un service d’analyse d’accéssibilité de votre site web. Il génère un rapport en se basant sur le respect des directives fournies par le Web Content Accessibility Guidelines (WCAG). Bearstech peut intégrer dans le workflow un accès à Pa11y afin de générer un rapport d'accessibilité afin de vous aider à valider la compatiblité du code produit avec ses directives. Sitespeed Bearstech peut mettre à dispostion un accès au service Sitespeed qui analyse la performance de votre site web côté client. La génération du rapport Sitespeed peut être intégré à la CI du projet en invoquant un script qui sera joué à chaque déploiement, et vous donner ensuite à la performance de chargement des pages web, et un indice de bilan carbone calculé par rapport à une évaluation de la consommation énergétique de l’application. Les métriques récoltées par Sitespeed peuvent aussi être reportées dans notre outil de supervision sous Grafana.
Sonarqube Sonarqube est un service d’analyse de qualité de code. L’outil analyse et fournit des indices sur la détection de bugs, de vulnérabilités, le taux de couverture des tests, le taux de duplication de code. Beartech peut mettre à dispostion un service Sonarqube pour lancer une analyse du code de l'application par l'intermédiaire de la CI. Par exemple après la validation de la recette, au moment de passer sur un serveur d'homologation, il peut être judicieux de finaliser les développements en s'aidant du rapport de vulnérabilités produit par Sonarqube. Conclusion Les principes du workflow reposent donc sur la reproductibilité des applications dans des environnements conformes à ce qui sera déployé en production afin de pouvoir mesurer leur fiabilité par des tests. La conformité des environnements doit valider la compatiblité des dépendances système et logicielles entre elles par une procédure de conteneurisation de l'application ou la mise à disposition d'un environnement de recette. Notre workflow permet de déployer les applications de manière native ou sous la forme de conteneurs. Les environnements d'exploitation bénéficient tous de l'infogérance de Bearstech, et en y adjoignant des services d'analyse de performance, notre workflow vous permet le suivi en continu de la qualité de service de vos applications.
Vous souhaitez en savoir plus ? Découvrez notre workflow DevOps et échangeons sur vos enjeux technologiques.
j’ai écrit ce blog post il y a quelques semaines, après avoir utilisé, ou évalué, une grande partie des projets et outils mentionnés dans le post:
Il manque une partie sur les LLM (grands modèles de langage), cela fera peut-être l’objet d’un post complémentaire dans quelques mois quand j’aurai suffisamment utilisé ces outils pour ne pas trop dire de bêtises.
Si vous avez de retours, je suis preneur (ca peut passer, mais pas nécessairement, par une pull-request).
Suite à ma relance sur Discord pour évoquer le sujet Mobilizon en éventuel remplacement des multiples groupes Python meetup.com, il y a eu quelques échanges au sujet de Mobilizon donc je les rassemble ici :
Ça ne marche pas hyper bien sur certains trucs (notamment les notifications - c’est très con :/)
Par contre, le Breizhcamp va probablement demander à Framasoft de nous développer quelques trucs contre rémunération.
L’avis de @yoan qui l’a testé : Je l’ai essayé pour un mini-groupe pour l’instant, il y a un BIG avantage c’est qu’on peut s’inscrire à un événement par mail sans créer de compte.
L’UI est moins fluide et naturelle que meetup.com mais j’ai un ressenti globalement positif.
Pour l’instant je regrette juste que quand on publie un commentaire à un événement ça envoie juste un mail qui dit “quelqu’un a écrit un commentaire à l’événement où vous participer” sans dire lequel, mais je ne suis pas sûr que meetup.com gère beaucoup mieux cette situation ? (ni si c’est possible)
C’est cool si à isocoût (environ 140€/an par groupe, avec des frais de banque pour payer en $) on met plutôt cet argent dans le développement de Moblizon plutôt que dans de multiples abonnements meetup.com pour chaque ville des meetups.
J’avais commencé l’an dernier un compilateur (ou transpilateur) PHP → Python. Au bout d’un week-end, j’avais dû passer à d’autres projets et n’avais jamais eu le temps de le publier. Un événement fortuit m’en a donné l’occasion cette semaine.
L’idée est que si vous avez du code PHP (ancien) que vous devez réécrire en Python, cela peut automatiser au moins une première passe, à vous ensuite de travailler sur le résultat pour faire un programme Python correct.
En termes d’architecture :
Le front-end est en fait un analyseur PHP écrit en PHP qui produit du JSON.
Le JSON est transformé en un AST (Arbre Syntaxique Abstrait)
Ensuite, un traducteur, qui est la seule partie intéressante du projet, le transforme en un AST Python. Ce traducteur utilise le pattern matching de Python 3.10+ (au lieu du pattern “visiteur” qui est en général utilisé pour ce type de projets, en tout cas dans les langages à objets).
L’AST Python est finalement sérialisé en code Python, en utilisant le module ast de la bibliothèque standard.
Comme le transformateur traite beaucoup de code répétitif, je me demandais si des techniques de réécriture d’arbre de haut niveau (à la Stratego/XT ou des outils similaires) pourraient être utilisées, mais je n’avais pas eu le temps d’approfondir les ressources Python que j’avais trouvées (cf. Compilation Python - Abilian Innovation Lab ).
J’avais proposé la poursuite du projet en sujet de stage l’an dernier, mais je n’ai pas eu de candidats, et je n’ai pas la possibilité de le reproposer cette année. Par contre, ça peut être un sujet de projet de travail en groupe pour des étudiants BAC+4 ou Bac+5 (il me semble). Si ça vous intéresse (en tant qu’étudiant ou enseignant) vous pouvez me contacter.
C’est vraiment un prototype, alors ne vous attendez pas à faire quelque chose d’utile avec. Je ne suis même pas sûr qu’un tel projet soit encore (potentiellement) utile à l’ère des LLMs.
Néanmoins je serais heureux d’entendre vos commentaires à ce sujet, si vous en avez.
HashBang est une société coopérative (SCOP) de services informatiques basée à Lyon. Nous sommes une équipe de 9 personnes.
Nous développons des applications sur mesure avec une approche de co-construction. Nous intervenons sur toute la chaîne de production d’un outil web, de la conception à la maintenance. Nos technologies préférées sont Python, Django, Wagtail, Vue.js, Ansible.
Vous aurez pour principales missions d’être l’interface entre Hashbang et son environnement commercial. À ce titre, vos principales missions seront:
• Développer le portefeuille clients de HashBang :
◦ Prospecter de nouveau clients, en organisant et participant à des événements autour du logiciel libre et des SCOP
◦ Fidéliser des clients existants, en réalisant des entretiens de suivi client avec nos chef·fe·s de projet
◦ Suivre les objectifs de ventes et de l’état du carnet de commande
◦ Communiquer : créer des posts LinkedIn, Twitter, Mastodon, des articles de blog sur notre site internet, créer et diffuser des supports de communication sur notre offre de service.
• Réaliser la vente :
◦ Analyser les besoins client
◦ Être en lien avec l’équipe projet pour traduire le cahier des charges
◦ Faire des propositions technico-commerciales adaptées
◦ Participer à la rédaction de réponses à appel d’offres / devis
Dans le cadre du développement Tracim et d'une collaboration avec un des clients historiques de l'entreprise, Algoo recherche rapidement une personne expérimentée en développement avec une forte appétence pour le développement web, l'ingénierie du logiciel et les technologies libres : python/javascript/react, usines logicielles github/gitlab, bonnes pratiques de développement, principes d'architecture, performance, pragmatisme, stratégies de test, travail en équipe.
mission de lead developer à temps partiel sur un projet client au sein de l'équipe de développement. Travaux de conception et développement, architecture. Posture de lead developer, force de proposition, transmission de connaissances et compétences. Contexte technique : python web async / sqlite, environnement linux embarqué Yocto, intégration continue gitlab, fortes problématiques autour de la performance. Métier : instrumentation scientifique.
mission de lead developer à temps partiel sur le logiciel libre Tracim édité par l'entreprise. Travaux de conception et développement, architecture technique. Contexte technique : python web / postgresql, API REST & sockets SSE, linux, docker, JS, react. usines logiciels github / gitlab, contributions sur des briques libres. Posture "produit" pragmatique attendue. Métier : collaboration d'équipe tout public.
missions d'architecture et investigations techniques sur les différents projets menés par Algoo. Interventions ponctuelles en tant qu'expert technique, formateur, architecte.
En complément comme pour l'ensemble des salariés Algoo, les missions suivantes font partie intégrante du travail :
participation active à l'organisation et à la vie de l'équipe ainsi qu'aux problématiques économiques - l'entreprise est dans une démarche de libération afin de donner la main aux équipes opérationnelles,
participation à la promotion de l'entreprise et des ses domaines d'expertise à travers la participation aux événements techniques et libristes, en tant que spectateur mais également animateur et conférencier.
La collaboration d'équipe est dans l'ADN de l'entreprise ; nous recherchons un développeur attiré conjointement par la dimension technique et la dimension humaine du travail de développement logiciel.
L'entreprise
Algoo est une société créée en février 2015 spécialisée dans les technologies logicielles libres. Elle a aujourd'hui 3 activités principales :
édition du logiciel libre Tracim de collaboration d'équipe
prestation de développement sur mesure - technologies web python/JS/React ainsi que client lourd - C++, QT, Rust.
prestation autour des infrastructures et de l'infogérance : infogérance de serveurs, prise en charge d'infrastructures linux / windows / virtualisation, hébergement de logiciels libres, accompagnement clients.
La mission de l'entreprise est d'accompagner ses clients dans une démarche d'émancipation et de souveraineté numérique. Nous développons et déployons des logiciels, un maximum de logiciels libres dans une démarche pragmatique et progressive.
Nous contribuons activement au logiciel libre et il nous semble inconcevable de recruter quelqu'un qui ne serait pas impliqué d'une manière ou d'une autre dans l'écosystème technologique et libriste.
L'entreprise poursuit une démarche de "libération de l'entreprise" afin de donner les rennes aux équipes opérationnelles. Elle est également dans une phase exploratoire pour aller vers une transformation en SCOP à échéance de 1 ou 2 ans.
Les recrutements sont faits en CDI, l'entreprise cherche à recruter sur le long terme pour renforcer son équipe.
Profil et compétences attendues
Nous recherchons un développeur expérimenté, curieux, à l'aise avec des environnements techniques complexes et des équipes pluri-disciplinaires.
Bac+5 en informatique ou expérience équivalente
Expérience de 8 ans ou plus
Forte connaissance du développement web, des standards et bonnes pratiques
Compétences en architecture logicielle et architecture système
Compétences en génie logiciel et industrialisation (CI/CD, Test, usines logicielles, interopérabilité, standards, etc), démarche devops
Maîtrise des bases de données relationnelles
Connaissance et maîtrise du système GNU/Linux et connaissances de base en administration système
Points d'attention
intérêt pour le transfert de connaissances / compétences
travail en équipe, volonté de réussite collective
curiosité intellectuelle, veille technologique
mobile pour participer à des événements techniques et libristes
note : comme pour toute proposition de recrutement, il s'agit d'un description "idéale imaginée". Si vous pensez faire l'affaire sans répondre à l'ensemble des critères, vous pouvez candidater
Avantages
participation aux conférences techniques et libristes dans le cadre du travail
participation aux bénéfices (25+15% sont redistribués à l'équipe)
organisation souple du travail (équipe hybride présentiel, télétravail partiel, "presque full-remote") - à noter que pour ce poste une présence sur Grenoble est obligatoire car une partie des missions se déroule chez le client en présentiel
1 semaine de séminaire d'équipe chaque fin d'année (conférences internes, ateliers d'équipe)
Mission de l'entreprise "éthique" : accompagner les clients dans leur démarche d'émancipation et de souveraineté numérique (notamment à travers le développement et le déploiement de logiciels libres)
possibilité de travail à temps partiel - 1/3 de l'équipe est en temps partiel
mutuelle familiale moyen de gamme (la même que le dirigeant)
horaires de travail plutôt souples
Offre
CDI, période d'essai de 3 mois
Contrat 35h
rémunération fixe 48/60K€ + participation aux bénéfices (cf. ci-dessus)
recrutement rapide, démarrage immédiat
contribution au logiciel libre
possibilité de temps partiel
télétravail partiel sur cette opportunité
le poste est évolutif vers des responsabilités accrues
Processus de recrutement
sélection des candidatures au fil de leur réception
3 à 4 séries d'entretiens :
entretiens "savoir-faire" avec un ou plusieurs développeurs,
entretiens "savoir-être" avec des membres (non dév) de l'équipe,
entretien "philosophie et stratégie d'entreprise" avec le dirigeant,
entretien complémentaire optionnel si nécessaire.
Pour candidater : envoyer un email à damien point accorsi arobase algoo point fr avec un CV en pièce jointe et un message d'introduction faisant office de "motivation".
Pas de blabla attendu, mais un minimum d'informations : les CV sont traités à la main, j'attends donc l'initiation d'un échange qui donne envie d'aller plus loin et de découvrir votre candidature.
En France, la CADA ou Commission d’accès aux documents administratifs est une autorité administrative indépendante qui a pour objectif de faciliter et contrôler l’accès des particuliers aux documents administratifs. Et Wikipédia ajoute : elle « émet des conseils quand elle est saisie par une administration, mais son activité principale est de fournir des avis aux particuliers qui se heurtent au refus d’une administration de communiquer un ou plusieurs documents qu’elle détient. »
Le site de la Commission d’accès aux dossiers administratifs : https://www.cada.fr/
Ma Dada (demande d’accès aux dossiers administratifs) https://madada.fr/
Note 1: en Belgique aussi il existe une CADA, mais je serais bien en peine d’évoquer les similitudes ou différences. Ce travail est laissé aux commentaires :).
Note 2: ne pas confondre avec un autre CADA français qui n’a pas de rapport
Contexte (mi CADA su CADA)
On m’a récemment demandé un coup de main pour pouvoir faire des recherches dans les avis et conseils CADA publiés. Sur data.gouv.fr, on peut trouver tout cela en fichier CSV, et sinon il est possible d’utiliser l'API de la CADA pour faire des recherches. Mais bon ouvrir un fichier CSV de plusieurs centaines de MiB et des dizaines de milliers de lignes dont des cellules de plusieurs écrans, ça peut être compliqué ou peu lisible pour le commun des mortels. Et puis tout le monde ne sait pas utiliser une API (ou gérer l’Unicode dans les résultats ou les requêtes ou… n’a pas envie d’avoir besoin d’un accès Internet permanent pour cela).
Bref coup de téléphone, question « est-ce que c’est compliqué de produire un PDF à partir d’un CSV ? », évaluation mentale hyperprécise de développeur débutant en Python « tranquille, 5 min » et réponse « oui, j’essaie de te faire ça ce week-end ».
Yapuka (ou abraCADAbra)
Je vais sur le site data.gouv.fr, je vois 1 fichier principal, 49 mises à jour. Je télécharge donc 50 fichiers. Bon, première erreur, il faut comprendre « mises à jour » du même jeu de données, bref la dernière version contient tout.
Au final je vais pondre ce code Python qui lit un CSV et produit du Markdown, en validant un peu ce qui passe à tout hasard.
La fonction display indique ce qu’on trouve dans le CSV (selon l’entête de chaque CSV).
La fonction markdown sort de façon basique du Markdown à partir de ça (ma stratégie de saut de page n’a pas marché, mais je dirais tant mieux vu le nombre de pages en sortie…).
La fonction validate me donne une idée de ce que je traite et si jamais il y a des surprises sur une prochaine mise à jour des données. J’ai notamment été surpris par le nombre de champs pouvant être vides.
Et côté main de quoi gérer un offset/limit à la SQL, pour ne pas tout traiter en une fois (cf la suite de ce journal).
Anecdote : j’ouvre un CSV au pif pour avoir un exemple, et je tombe direct sur une décision concernant ma ville de naissance.
Bref, voici le code Python mi-anglais mi-français mi-sérable :
#!/usr/bin/env python3# -*- coding: utf-8 -*-importargparseimportcsvfromdatetimeimportdatetimenumero_de_dossier=''administration=''type_donnee=''annee=''seance=''objet=''theme=''mots_cles=''sens_motivation=''partie=''avis=''defdisplay(row):foriin["Numéro de dossier","Administration","Type","Année","Séance","Objet","Thème et sous thème","Mots clés","Sens et motivation","Partie","Avis"]:print(f"{i} : {row[i]}")defmarkdown(row):print(f"\n# Dossier {row['Numéro de dossier']}\n")foriin["Administration","Type","Année","Séance","Objet","Thème et sous thème","Mots clés","Sens et motivation","Partie","Avis"]:print(f"**{i} :** {row[i]}")print("\n\\newpage\n")defvalidate(row):assertlen(row['Numéro de dossier'])==8annee_dossier=int(row['Numéro de dossier'][0:4])assertannee_dossier<=datetime.now().yearandannee_dossier>=1984assertint(row['Numéro de dossier'][4:8])# row['Administration'] can be emptyassertrow['Type']in['Avis','Conseil','Sanction']ifrow['Année']!='':annee=int(row['Année'])assertannee<=datetime.now().yearandannee>=1984datetime.strptime(row['Séance'],'%d/%m/%Y').date()# row['Objet'] can be empty# row['Thème et sous thème'] can be empty# row['Mots clés'] can be empty# row['Sens et motivation'] can be empty# row['Partie'] can be empty# row['Avis'] can be emptydefmain():parser=argparse.ArgumentParser(description="Avis et conseils CADA")parser.add_argument("--csv",type=str,required=True,help="export.csv")parser.add_argument("--limit",type=int,required=False,help="nb de dossiers à traiter en partant de l'offset",default=1000000)parser.add_argument("--offset",type=int,required=False,help="position du premier dossier à traiter",default=0)args=parser.parse_args()export=args.csventries_input=0entries_output=0withopen(export,newline='')ascsvfile:reader=csv.DictReader(csvfile,delimiter=',')forrowinreader:# display(row)validate(row)ifentries_input>=args.offset:markdown(row)entries_output+=1ifentries_output>=args.limit:returnentries_input+=1if__name__=='__main__':main()
et un bout de code bash pour lancer tout ça (la boucle for inutile date de mon erreur de traiter les 50 fichiers CSV au lieu d’un…) : on vérifie le code Python, et ensuite on produit des Markdown de 10000 enregistrements et les PDF associés.
#!/bin/bashset -e
flake8 cada.py
mkdir -p markdown pdf
for csv in data.gouv.fr/cada-2023-04-12.csv
dobase=$(basename "$csv"".csv")limit=10000#TODO no check 50000+limit < real totalfor nb in $(seq 0$limit50000)domd="markdown/${base}_${nb}.md"
./cada.py --csv "$csv" --limit $limit --offset $nb > "$md"pdf="pdf/${base}_${nb}.pdf"
pandoc "$md" -o "$pdf" --pdf-engine=weasyprint --metadata title="cada-2023-04-12 ($nb)"donedone
Entrées/sorties (petite CADAstrophe)
Le fichier cada-2023-04-12.csv contient 50639 enregistrements et fait déjà 156 MiB.
Chaque fichier Markdown de 10 000 enregistrements fait environ 30 MiB.
Chaque PDF fait de 40 à 50 MiB.
La découpe par 10 000 est due à une raison assez simple : la machine utilisée a saturé ses GiB de RAM (après prélèvement du noyau et autres), swappé, ramé sévèrement, et la génération du PDF a été tuée par le OutOfMemory-killer (oom-killer) du noyau.
kernel: [ 4699.210362] Out of memory: Killed process 6760 (pandoc) total-vm:1074132060kB, anon-rss:13290136kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:51572kB oom_score_adj:0
Bref ça donne :
$ ls -lnh markdown/
total 164M
-rw-r--r-- 110001000 29M 14 mai 18:31 cada-2023-04-12_0.md
-rw-r--r-- 110001000 29M 14 mai 18:41 cada-2023-04-12_10000.md
-rw-r--r-- 110001000 32M 14 mai 18:53 cada-2023-04-12_20000.md
-rw-r--r-- 110001000 34M 14 mai 19:06 cada-2023-04-12_30000.md
-rw-r--r-- 110001000 38M 14 mai 19:20 cada-2023-04-12_40000.md
-rw-r--r-- 1100010003,4M 14 mai 19:35 cada-2023-04-12_50000.md
$ ls -lnh pdf/
total 442M
-rw-r--r-- 110001000 39M 14 mai 18:41 cada-2023-04-12_0.pdf
-rw-r--r-- 110001000 39M 14 mai 18:53 cada-2023-04-12_10000.pdf
-rw-r--r-- 110001000 43M 14 mai 19:06 cada-2023-04-12_20000.pdf
-rw-r--r-- 110001000 45M 14 mai 19:20 cada-2023-04-12_30000.pdf
-rw-r--r-- 110001000 50M 14 mai 19:35 cada-2023-04-12_40000.pdf
-rw-r--r-- 1100010004,4M 14 mai 19:35 cada-2023-04-12_50000.pdf
-rw-r--r-- 110001000 224M 14 mai 19:41 cada-2023-04-12.pdf
Les personnes attentives auront noté le pdf obèse de 224 MiB. Il a été obtenu via
Le PDF final fait 52 019 pages (!) et evince (et probablement la plupart des lecteurs de PDF) arrive à l’ouvrir et à rechercher dedans. Mission accomplie.
Mais pas en 5min… il suffit de regarder les dates des fichiers plus haut d’ailleurs (et sans compter les essais multiples)…
Bref j’ai produit un gros PDF, et le résultat convenait, donc je vous partage ça. Rien d’extraordinaire mais bon ça représente quand même 5min de boulot quoi…
Pour le Meetup Python du mois de mai à Grenoble, nous organisons un atelier d’exploration de données avec Datasette. L’occasion pour tous les niveaux de découvrir cet écosystème open-source trouvant de nouveaux adeptes année après année !
Je coordonne un afpyro “à l’arrache” sur bordeaux vendredi 12/05/2023 à 19h au brique house.40 Allées d’Orléans, 33000 Bordeaux
Au pire vous ne croiserez que moi tout seul. Au mieux on sera si nombreux qu’on devra réfléchir à trouver un amphithéatre pour des “vrais” rencontre pythonique sur bordeaux
Objectifs du soir:
-(re)faire connaissance
-(re)lancer une dynamique locale
-parler python
-manger et sortir
Je recherche, pour les projets en cours et à venir de notre société, Content Gardening Studio, une personne passionnée par Python et désirant s’orienter vers la Data Science et/ou le Data Engineering.
Contrat de travail en Alternance,
Offre interne de formations accélérées sur Python et les techniques pour la Data.
Revenons d’abord sur ce qu’il s’est passé ce mois-ci :
Rapport de transparence
La PyConFr s’étant déroulé en février, les retours sur les incidents ne se sont pas fait attendre. L’équipe de gestion des incidents au code de conduite, composée de Grewn0uille, Mindiell et ReiNula ont rédigé le rapport de transparence que vous pouvez retouvez dès à présent ici.
Vidéos des conférences
De plus, les vidéos des conférences nous ont été transmise par l’association Raffut, qui s’était occupé de la captation. Elle sont disponible sur IndyMotion
Seules 3 conférences manquent :
-Éric Dasse & Dimitri Merejkowsky - Faire du Python professionnel
-Bérengère Mathieu OCR : apprenez à extraire la substantifique moelle de vos documents scannés
-Anne-Laure Gaillard - Contribuer à l’open source sur des projets Python… sans coder
Paf’py, le pastebin de l’AFPy
Un nouveau service est arrivé au catalogue de l’AFPy : Paf’py , un pastebin, qui vous permet de partager vos codes et documents markdown sur le web simplement depuis votre terminal.
Abilian DevTools est une collection sélectionnée avec soin d’outils de développement Python:
Formateurs (black, isort, docformatter)
Frameworks de test (pytest et ses amis, nox)
Vérificateurs de style (ruff, flake8 et ses amis)
Vérificateurs de type (mypy, pyright)
Audit de la chaîne d’approvisionnement (pip-audit, security, reuse, vulture, deptry)
Et plus encore.
Au lieu de devoir suivre les plus de 40 projets et plugins que nous avons sélectionnés, vous avez juste besoin d’ajouter abilian-devtools = '*' dans le fichier requirements.in ou pyproject.toml de votre projet.
Nous avons également écrit un outil CLI simple, adt, qui fournit les tâches suivantes :
all Run everything (linters and tests).
audit Run security audit.
bump-version Bump version in pyproject.toml, commit & apply tag.
check Run checker/linters on specified files or directories.
clean Cleanup cruft.
format Format code in specified files or directories.
help-make Helper to generate the `make help` message.
test Run tests.
Motivation
Voici quelques raisons pour lesquelles nous avons créé ce projet :
Collection d’outils rationalisée : Abilian Devtools rassemble une large gamme d’outils de développement Python comme dépendances d’un seul package. Cela permet aux développeurs de se concentrer sur leur travail sans perdre de temps à chercher et à intégrer des outils individuellement.
Cohérence : En utilisant un ensemble sélectionné d’outils, notre équipe peut facilement veiller à la cohérence de qualité de code, de style et de sécurité dans ses projets.
Gestion de dépendances simplifiée : Au lieu de gérer des dépendances individuelles pour chaque outil, les développeurs ont simplement besoin d’ajouter abilian-devtools aux exigences de leur projet. Cela facilite la maintenance et la mise à jour des dépendances au fil du temps.
Interface CLI facile à utiliser : L’interface de ligne de commande adt simplifie les tâches de développement courantes telles que l’exécution de tests, le formatage de code et les audits de sécurité. Cela peut faire gagner du temps et des efforts, en particulier pour ceux qui sont nouveaux dans ces outils.
Ensemble d’outils à jour : Abilian Devtools vise à fournir une collection d’outils à jour, garantissant que les développeurs ont accès aux dernières fonctionnalités et améliorations sans avoir à suivre et à mettre à jour manuellement chaque outil.
Cette présentation de 2017 a été donnée lors du Paris Open Source Summit (POSS). De nombreux outils ont évolué ou sont apparus depuis lors, mais les principes généraux restent valables.
Cette présentation de 2005 a été donnée (en français) lors des Rencontres Mondiales du Logiciel Libre à Bordeaux. Elle est clairement obsolète, mais conservée pour des raisons nostalgiques
Numpy et Pandas n’ont pas exactement les mêmes objectifs.
Dans la plupart des cas, NumPy peut être légèrement plus rapide que pandas, car NumPy est plus bas niveau et a moins de surcharge. Cependant, pandas offre des structures de données et des fonctionnalités plus avancées, ce qui peut faciliter le travail avec des ensembles de données complexes. Les performances relatives de NumPy et pandas dépendent également des opérations spécifiques effectuées sur les données, de sorte que les différences de performances peuvent varier en fonction des tâches spécifiques. Certaines fonctions n’existent qu’avec pandas, et qui n’ont pas d’équivalents NumPy sont : read_csv, read_excel, groupby, pivot_table, merge, concat, melt, crosstab, cut, qcut, get_dummies et applymap.
Résultats
Résultat : image générée : notez bien que j’ai appelé des fonctions « bas niveau » pour qu’on voie ce que NumPy a dans le ventre et des fonctions qui n’existent que dans pandas, que ré-implémentées en Python pur + NumPy.
Code source
Voici le code source que j’ai fait, qui appelle quelques fonctions connues de NumPy et de pandas.
The @AFPy , organizer of the event, apologizes for this inconvenience. And we strongly thank the Raffut association for its work in capturing the conference, as well as all the speakers and participants in the PyConFr.
Unfortunately 3 conferences could not be saved. These are :
-Éric Dasse & Dimitri Merejkowsky - Faire du Python professionnel -Bérengère Mathieu OCR : apprenez à extraire la substantifique moelle de vos documents scannés -Anne-Laure Gaillard - Contribuer à l’open source sur des projets Python… sans coder
L' @AFPy , organisatrice de l'évènement, s'excuse pour ce désagrément. Et nous remercions fortement l'association Raffut pour son travail de captation et de restitution des conférences, ainsi que tout les orateurs et participants à la PyConFr.
Malheureusement 3 conférences n'ont pas pu être sauvés. Ce sont :
-Éric Dasse & Dimitri Merejkowsky - Faire du Python professionnel -Bérengère Mathieu OCR : apprenez à extraire la substantifique moelle de vos documents scannés -Anne-Laure Gaillard - Contribuer à l’open source sur des projets Python… sans coder
J'ai publié ce matin une nouvelle mouture du compilateur pour codes scientifiques écrits en Python nommé Pythran. C'est la version 0.13.0 et elle porte le joli sobriquet bouch'hal.
Les plus impatients téléchargeront immédiatement la dernière version sur PyPi ou Github tandis que les plus curieux s'empresseront de lire le changelog associé.
Mais ce serait louper la suite de ce billet, où j'aimerai vous parler des bienfaits de l'émulation. Lors de ma veille, je suis tombé sur le projet de compilateur pyccel qui partage plusieurs caractéristiques avec le projet Pythran : compilateur source à source, en avance de phase, ciblant le calcul numérique. Avec quelques différences : support (encore plus) limité des constructions Numpy et du langage Python, mais surtout possibilité d'utilisé C ou Fortran comme langage cible. Sympa !
Ce projet a publié une suite de benchmark permettant des points de comparaison avec Pythran. Et sur certains noyaux, Pythran n'était vraiment pas bon. J'ai creusé un peu (car oui, mon ego en a pris un coup) et de manière fascinante, les compilateurs clang et gcc peinent à générer un code équivalent pour les deux fonctions C++ suivantes (cf. godbolt pour les plus saint Thomas d'entre vous):
Pythran générant du code générique, il m'a fallu pas mal d'heures de réflexions pour circonvenir le problème et arriver à un patch. Mais c'est bon, problème de performance corrigé !
Numpy et Pandas n’ont pas exactement les mêmes objectifs.
Dans la plupart des cas, NumPy peut être légèrement plus rapide que pandas, car NumPy est plus bas niveau et a moins de surcharge. Cependant, pandas offre des structures de données et des fonctionnalités plus avancées, ce qui peut faciliter le travail avec des ensembles de données complexes. Les performances relatives de NumPy et pandas dépendent également des opérations spécifiques effectuées sur les données, de sorte que les différences de performances peuvent varier en fonction des tâches spécifiques. Certaines fonctions n’existent qu’avec pandas, et qui n’ont pas d’équivalents NumPy sont : read_csv, read_excel, groupby, pivot_table, merge, concat, melt, crosstab, cut, qcut, get_dummies et applymap.
Résultats
Résultat : image générée : notez bien que j’ai appelé des fonctions « bas niveau » pour qu’on voie ce que NumPy a dans le ventre et des fonctions qui n’existent que dans pandas, que ré-implémentées en Python pur + NumPy.
Code source
Voici le code source que j’ai fait, qui appelle quelques fonctions connues de NumPy et de pandas.
Suite à différents tickets et à différents souhaits par rapport au site de l’AFPy.
Il s’agissait d’un site dynamique fait en Flask. J’ai décidé que, vus les besoins actuels, il était plus intéressant de le refaire en mode statique qui se met à jour basé sur ce forum (actualités et offres d’emploi).
Vous avez donc une proposition ici : https://afpy.mytipy.net/
Il ne met pas à jour les articles en direct (j’ai pas activé ça), mais il sait le faire, la preuve vous pouvez retrouver les dernières offres d’emploi et les threads de la rubrique “Actualités”.
Il sait également proposer des articles spécifiques qu’on peut écrire en markdown et stocker dans les sources (qui sont ici : Mindiell/refonte - refonte - Le Gitea de l'AFPy) (et oui, c’est libre, j’ai pas ajouter de licence pour le moment).
Le statique apporte également de la sécurité (logiquement) et de l’éco-nomie-logie-etc…
N’hésitez pas à donner votre avis, toute critique est la bienvenue !
Ya une commune en France qui s’appelle pithon: OpenStreetMap
C’est ptet un peu petit pour la prochaine pycon, je sé pas si on tiendrait dans la salle paroissiale. Afpyro, peut-être, si ya un troquet?
Je serai pas vexé si personne ne rebondit sur le sujet.
Vous avez une solide expérience en programmation (Python / Web / …)
et un goût pour les sciences et l’enseignement; vous souhaitez
contribuer au logiciel libre – et notamment à l’écosystème Jupyter –
et soutenir l’innovation pédagogique au sein d’une équipe plurielle?
PyCon France (PyConFR) est une conférence qui a lieu chaque année (sauf circonstances exceptionnelles) en France. Cette année, elle a eu lieu du 16 au 19 février à Bordeaux, rassemblant des personnes de la communauté Python. Les participantes à la conférence sont tenues de respecter le Code de Conduite de l’Association Francophone Python, l’association qui organise l’événement.
Le but de ce document est d’améliorer l’accueil et la sécurité des participantes ainsi que de donner aux organisateurs et organisatrices des indicateurs sur le comportement de la communauté. En effet, pour pouvoir entendre, il faut pouvoir écouter. C’est maintenant devenu une pratique courante, pour les organisations ayant un Code de Conduite, de publier un rapport de transparence suite à la tenue d’une conférence. C’est le but de ce document.
Je suis en cours de visionnage (j’en suis à la moitié actuellement) une conférence super intéressante (Où sont les femmes - DevFest de Nantes 2018 : lien youtube) et j’ai donc décidé de faire quelques statistiques sur les PyConFR depuis 2008.
Points importants
Les données sont parfois très complexes à récupérer
Certaines vidéos semblent manquantes par rapport à certains programmes (il en manque)
Je n’ai aucune trace des PyConFR 2011 et 2012
Typiquement, la conférence listée sur le site : Python et architecture Web scalable ne donne pas d’orateur / oratrice et je n’ai pas de vidéo associée pour vérifier et c’est pareil pour toutes les confs de 2011
Les confs de 2010 listées contiennent également celles de 2009 /o\
J’ai regardé chaque vidéo de 2008, 2009, et 2010 : j’ai pu faire des erreurs
Lorsque les conférences ont des noms associés, je me suis permis de “deviner” le genre des orateurs/oratrices pour ne pas passer trop de temps à vérifier sur chaque vidéo
Pour les noms étrangers (typiquement indien, europe de l’est, etc…), j’ia fait une recherche sur internet assez rapide (et donc potentiellement fausse)
Bref, les données ne sont pas parfaites, loin de là. J’ai également tâché de répertorier les durées de chaque talk/conférence/atelier/autre pour faire d’autres stats (ou pas).
Voici donc un tableau représentant le nombre comparée d’orateurs et d’oratrices aux différentes PyConFR (une même personne qui fait 2 conférences est comptée 2 fois)
On n’était donc ps vraiment mieux en 2018. Mais je suis heureux de voir l’évolution 2019 et 2023 !
L'année dernière à Open Food Facts, nous avons profité de Google Summer of Code pour démarrer un projet d'éditeur de taxonomies.
C'est quoi les taxonomies ?
La base de données Open Food Facts contient de nombreuses informations sur les produits alimentaires, telles que les ingrédients, les étiquettes, les additifs, etc.
Parce que ces domaines changent et qu'il peut y avoir des particularités locales, nous laissons toujours une saisie libre des informations (avec des suggestions) et nous cherchons à structurer à posteriori. Les informations structurées peuvent être mieux exploités (par exemple pour le calcul de Nutri-Score, la détection d'allergènes, etc.)
Ceci permet également de faire des liens avec des bases exetrens (agribalyse, wikidata, etc.).
le problème
Pour le moment, une taxonomie dans Open Food Facts est un fichier texte brut contenant un graphe acyclique dirigé (DAG) où chaque nœud feuille a un ou plusieurs nœuds parents.
Les fichiers de taxonomie présents dans Open Food Facts sont longs à lire (la taxonomie ingrédients.txt compte à elle seule environ 80000 lignes !) et lourds à éditer par les contributeurs, et impossible pour un utilisateur occasionnel.
De plus il est difficile d'avoir une image de haut niveau des taxonomies.
le projet
Ce projet vise à fournir une interface Web conviviale pour éditer facilement les taxonomies.
Il doit permettre pas mal de choses:
* activer la recherche et la navigation dans la taxonomie
* permettre aux utilisateurs occasionnels d'apporter des traductions et des synonymes et ainsi d'enrichir la taxonomie
* aider à repérer les problèmes dans la taxonomie (traductions manquantes, chemins manquants, etc.), obtenir des statistiques utiles à ce sujet
* fournir des assistants pour aider les contributeurs puissants à enrichir la taxonomie (par exemple, trouver l'entrée wikidata correspondante)
* proposer une API à la taxonomie pour les applications tierces (en complément de l'API existante)
pourquoi c'est intéressant ?
c'est en Python et ReactJS
ça utilise une base de données de graphes : Neo4J et vous pouvez faire beaucoup de requêtes utiles et intéressantes
projet pas trop gros et bien focalisé, vous pouvez rapidement le prendre en main
cela peut avoir un impact énorme sur Open Food Facts :
support sur plus de langues : être utile à plus d'utilisateurs autour du monde
meilleure analyse des ingrédients : plus de détection des allergies, calcul potentiellement plus fin du score environnemental
meilleure classification des produits : permettre des comparaisons de produits, des calculs de score environnemental, etc.
permettant plus de taxonomies : par exemple sur les marques pour connaître les producteurs alimentaires
pourquoi comme ça ?
Lors d'un précédent post on m'a fait remarquer que des formats (et des outils) existent déjà pour les taxonomies. C'est vrai, mais, à part notre ignorance, il y a quelques points qui nous font continuer ce projet:
il serait difficile de changer le format du tout au tout coté serveur d'open food facts (c'est malheureusement ancré à plein d'endroit dans le code) et les formats que j'ai vu sont dur à éditer à la mano.
nous avons une forte emphase sur les synonymes et les traductions, je ne suis pas sur que ce soit des choses privilégiés par les autres formats
je n'ai pas vu d'outil libre vraiment facile d'approche pour des contributeurs noob
il nous faut un chemin de changement incrémental. Le projet actuel ne change pas le format final et permet de continuer le workflow actuel (on passe par des PR github pour valider in fine). Mais il ouvre la possibilité d'un changement de workflow dans le futur
dans la suite du projet, nous voulons pouvoir intégrer des aides très spécifiques (ex: identifier les entrées wikidata correspondantes, voir les entrées voisines manquantes, etc.)
Pour le Meetup Python du mois d’avril à Grenoble, nous organisons une session de “lightning talks”. Tout le monde peut participer, quelque soit l’expérience de présentation et le sujet, tant qu’il y a un lien de près ou de loin avec l’écosystème Python !
Pour le Meetup Python du mois d’avril à Grenoble, nous organisons une session de “lightning talks”. Tout le monde peut participer, quelque soit l’expérience de présentation et le sujet, tant qu’il y a un lien de près ou de loin avec l’écosystème Python !
Qui se propose pour présenter quelque chose ? Durée maximum 20min, faites vos propositions en réponse à ce fil, ou en message privé si vous préférez en discuter avant.
Qui se propose pour présenter quelque chose ? Durée maximum 20min, faites vos propositions en réponse à ce fil, ou en message privé si vous préférez en discuter avant.
Qui se propose pour présenter quelque chose ? Durée maximum 20min, faites vos propositions en réponse à ce fil, ou en message privé si vous préférez en discuter avant.
Article intéressant de la PSF sur une proposition de loi EU liée à la Cyber Resilience Act et qui n’est pas sans risque pour le monde de l’open source y compris l’écosystème autour de Python.
Mon anglais étant ce qu’il est, il va me falloir plusieurs lectures pour en comprendre toutes les subtilités. Mais pour celles et ceux qui le souhaitent, en fin d’article, un appel est lancé pour interpeler nos députés Européens sur le sujet avant le 26 avril (C’est court).
Après une pause de près de 2 ans sans développer (c’est pas mal la retraite, vous devriez essayer!), je cherche à rattraper le temps perdu, et combler mes lacunes.
Sujet: dunder, ou “double_underscore”.
Ces identifiants, comme __init__, qui commencent et finissent par 2 underscores.
Comme nous tous, j’en utilise pleins, mais, au moment de chercher une définition officielle de ces “fonctions magiques” (effectivement appellées “magic functions” en plein d’endroits), macache! Pas de def officielle, ou bien je ne sais pas chercher!
Ah! Ah! Bien sur, en rédigeant ma question, je la creuse, et je tombe sur de nouveaux indices!
Il semblerait que “dunder” soit le nom vernaculaire de la chose, un peu comme en botanique il y a le nom courant, connu du pékin de base, et le nom latin, connu des seuls savants.
dans le glossaire (Glossary — Python 3.11.3 documentation) on trouve une entrée :
magic method
An informal synonym for special method.
lui-même défini plus loin:
special method
A method that is called implicitly by Python to execute a certain operation on a type, such as addition. Such methods have names starting and ending with double underscores. Special methods are documented in Special method names.
J’ai Les Cast Codeurs dans mes podcasts, c’est beaucoup de Java (mais pas que) et je suis souvent largué (quand ça parle Java ). Mais de temps en temps ça éveille ma curiosité.
Dans la dernière interview, autour de maven, à été abordé le sujet des reproductable builds, c’est à dire qu’à chaque compilation on obtient un artefact qui est strictement identique (la même valeur de hash).
De ma faible expérience en packaging python, je n’ai pas l’impression que ça possible. En effet, sur freeBSD, il faut fournir le hash de l’archive à poudriere et donc, j’ai eu des problèmes de cet ordre lors de mes essais.
Mais comme il est probable que certaines méthode de packaging me soient inconnues, je voulais savoir si parmis vous on déjà vu ou réalisé ce genre de build.
by Stéphane Blondon <stephane@yaal.coop> from Yaal
La conférence PyConFR est constituée de deux jours de sprints puis deux jours de conférences. Cette année elle a eu lieu à Bordeaux, l'occasion pour Yaal Coop de s'y rendre à plusieurs et de sponsoriser l'évènement pour soutenir l'organisation.
Les sprints sont l'occasion de découvrir des projets écrits en Python, mettre le pied à l'étrier pour les utiliser, idéalement, réussir à faire quelques contributions dessus. Ce fut l'occasion de tester zou ainsi qu'avoir une Pull Request acceptée sur cpython (merci à Julien Pallard) et d'en faire une autre, suite à la précédente. :)
C'est aussi l'occasion de rencontrer et discuter dans les allées avec d'autres pythonistes.
Lors de la seconde partie de la PyCon, plusieurs conférences se déroulaient en même temps, dans les amphithéatres différents. Parmi celles que nous avons vues:
Django Admin comme framework pour développer des outils internes
Il est possible d'adapter l'interface d'admin de django pour créer des applications CRUD pour un usage interne. L'intérêt est de gagner du temps en utilisant la capacité de django-admin à produire des interfaces listant et modifiant des objets rapidemment. Parmi les astuces et personnalisation, on notera :
la possibilité de modifier le nom 'Django admin' dans l'interface de connexion pour rassurer les utilisateurs
l'utilisation de 'create views' dans un script de migration permettant de faire des visualisations en lecture seule.
Le présentateur indique que, si le besoin devient plus complexe par la suite, la solution est de passer au developpement classique d'un service django.
Uncovering Python’s surprises: a deep dive into gotchas
Une présentation en anglais montrant des curiosités plus ou moins connues du langage. Une partie des exemples sont issus de wtfpython.
Faire du Python professionnel
Typer ou ne pas typer en python, telle est la question... Plusieurs conférences ont abordé le sujet, dont celle-ci. Globalement ses avantages semblent faire de plus en plus consensus au sein de la communauté. Une référence d'article de blog intéressante néanmoins, avec des arguments contre les annotations de type.
Et un conseil pertinent : ne pas faire d'annotation sans mettre en place un outil (type mypy) dans la CI pour les vérifier. 😇
Portage Python sur Webassembly
WebAssembly est un langage fonctionnant dans les navigateurs. Il est possible d'écrire du code Python et de le convertir en WebAssembly. Arfang3d est un moteur 3D qui fonctionne ainsi.
python -m asyncio -> pour avoir un shell python asynchone
C'est aussi un moyen de convertir des jeux écrits avec pygame pour les exécuter dans un navigateur. Une liste de jeu compatible est disponible sur pygame-web.github.io.
Fear the mutants. Love the mutants.
Comment être sûr que les tests vérifient bien ce qu'ils sont censés vérifier ?
mutmut modifie le code source à tester et vérifie que les tests sont en erreur après la modification. La commande principale est mutmut run.
Pour changer le comportement du code, mutmut accède et modifie l'AST (Abstact Syntax Tree) grâce à la bibliothèque parso.
Python moderne et fonctionnel pour des logiciels robustes
Il s'agissait ici de s'inspirer de quelques principes et règles souvent utilisées dans le fonctionnel pour pouvoir coder en python de façon plus propre des services plus résistants et moins endettés.
Il a été question de typage avec les hints de Mypy mais aussi avec Pyright, moins permissif et donc contraignant à des règles de propreté. Avec Python3.8 sont arrivés les Protocols, un cas spécifique d'utilisation des Abstract Base Classes sans héritage où il suffit de reproduire une signature.
Faire remonter les impuretés et les effets de bord a également été abordé avec l'architecture en oignon (comme la connexion à la persistance, les modifications à sauvegarder, les configurations, etc.) avec l'idée de pouvoir tester le cœur de son code sans dépendre de tout un environnement.
Le paramètre frozen du décorateur @dataclass(frozen=True) permet de rendre les instances immutables.
La classe typing.Protocol, décrite dans la PEP 544 et introduite dans Python 3.8 permet de définir des interfaces.
Accessibilité numérique : faire sa part quand on est développeur·euse backend
Une introduction aux problématiques de l'accessibilité avec une démo percutante en vidéo de l'expérience que peut avoir une personne aveugle en naviguant sur internet.
Saviez vous qu'aujourd'hui, 1 personne sur 5 était en situation de handicap ?
L'objectif était ici de sensibiliser le public, en majorité des développeurs back-end, aux questions d'accessibilité, et d'appuyer le fait que ce n'était pas qu'une question réservée aux design ou au front.
Quelques petites choses glanées :
quand on construit une plateforme diffusant du contenu utilisateur, prévoir l'ajout possible d'un texte alternatif/de sous titres à stocker avec l'image/la vidéo de l'utilisateur
se méfier des inputs utilisateurs que certains arriveront à détourner pour mettre du contenu en forme (des émojis, des caractères mathématiques...) qui sera ensuite illisible pour les lecteurs d'écrans
l'attribut html lang peut être utilisé avec n'importe quelle balise, pas seulement dans l'en-tête de la page, pour signaler une citation dans une langue étrangère par exemple ! Cela permet aux logiciels de lecture d'écran d'adopter la bonne prononciation 🤯
préferer le server side rendering et faire de la mise en cache pour accélerer l'affichage : un loader à l'écran n'est pas forcément explicite pour tous les utilisateurs (ou lecteurs...)
FALC (Facile à lire et à comprendre) est une méthode/un ensemble de règles ayant pour finalité de rendre l'information facile à lire et à comprendre, notamment pour les personnes en situation de handicap mental
Sensibiliser les producteurs d'une part significative des mediums d'information est toujours une bonne chose.
Interactive web pages with Django or Flask, without writing JavaScript
htmx est une bibliothèque javascript dont le but est de permettre la fourniture de code HTML qui sera intégré dans le DOM. L'idée est de remplacer le code javascript as-hoc et les transferts en JSON (ou autre). Si le principe semble adapté à certains cas, il ne remplacera pas de gros framework produisant des Single Page App.
pyScript est un projet encore très jeune qui permet l'exécution de code Python dans le navigateur.
Merci à l'équipe de bénévoles pour l'organisation de la conférence. À l'année prochaine !
Bonjour je suis en première spécial NSI et mon professeur nous a donné un projet et j’ai une erreur dans mon programme que je ne comprend pas (Je tiens à préciser que j’ai bien le dossier ressource sur mon ordinateur. Dans ce dossier il y a trois fichier french.lg, english.lg et russian.lg et dans ces fichier six mots de chaque langue sont inscrit dedans)
Quand je lance mon programme cette erreur apparait:
Traceback (most recent call last):
File "/Users/ethan/Desktop/eleveProjet/hangman.py", line 580, in <module>
dictionary = read_dictionary_file(name_of_dictionaries[language])
File "/Users/ethan/Desktop/eleveProjet/hangman.py", line 213, in read_dictionary_file
raise FileNotFoundError("Le fichier "+name_file+" n\'est pas présent dans le répertoire resources/")
FileNotFoundError: Le fichier english.lg n'est pas présent dans le répertoire resources/
Que puis je faire ?
En tout cas merci d’avance pour vos réponses
Voici mon programme
# -*- coding: utf-8 -
"""
Created on Mon Oct 17 15:17:07 2022
@author: Louis Sablayrolles
"""
"""
base (12 ptns)
IMP1 vérifier que l'utilisateur n'a pas déjà rentré une lettre (2 pnts)
IMP2 gérer en entrée des minuscules ou des majuscules (==> conversion) (1pnts)
IMP3 gestion de langues multiples (on leur fournira 3 fichiers: français, anglais et russe) (3pnts)
Lettres russe : https://www.lexilogos.com/russe_alphabet_cyrillique.htm
on considère les lettres Е Ё comme une seule et même lettre Е
'А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я'
'а б в г д е ё ж з и й к л м н о п р с т у ф х ц ч ш щ ъ ы ь э ю я'
IMP4 utilisation des fréquences de lettres en français puis dans les autres langues pour recommander à l'utilisateur la prochaine lettre
(4 pnts + 1 pnts si multi langues)
https://fr.wikipedia.org/wiki/Fr%C3%A9quence_d%27apparition_des_lettres
https://www.apprendre-en-ligne.net/crypto/stat/russe.html
IMP5 dessiner le pendu avec un module graphique (2pnts)
"""
import os
import sys
import random
# ------------------------------------------------------------------------------------------------------
# CONSTANTS & GLOBALS
NOM_ELEVE1 = ""
CLASSE_ELEVE1 = 100
NOM_ELEVE2 = ""
CLASSE_ELEVE2 = 100
# améliorations implémentées
IMP1 = True
IMP2 = True
IMP3 = True
IMP4 = True
IMP5 = True
NUMBER_OF_ERRORS_MAX = 10
name_of_dictionaries = {
"en": "english.lg",
"fr": "french.lg",
"ru": "russian.lg"
}
# ------------------------------------------------------------------------------------------------------
# BASIC FONCTIONS
def isValidLanguage(language):
"""
Vérifie si la langue donnée en paramètre fait partie de la liste des langues autorisées.
:param language: la langue à vérifier
:type language: str
:return: le résultat du test
:rtype: bool
"""
global name_of_dictionaries
if type(language) != str or len(language) != 2:
return False
return language in name_of_dictionaries.keys()
def is_number_of_errors_correct(nb_errors):
"""
Vérifie si le nombre d'erreurs passé en paramètre est valide.
Args:
nb_errors (int): Le nombre d'erreurs à vérifier.
Returns:
bool: True si le nombre d'erreurs est valide, False sinon.
"""
global NUMBER_OF_ERRORS_MAX #we get the constant
return 0 <= nb_errors <= NUMBER_OF_ERRORS_MAX
assert type(nb_errors) == int, "le nombre d'erreurs à tester n'est pas un entier"
def get_list_of_letters_possibles(language="en"):
"""
Return a list of possible letters according to the selected language.
:param language: the name of the language (default is 'en' for English)
:type language: str
:return: the list of possible letters
:rtype: list
"""
assert isValidLanguage(language), "Invalid language"
if language == "en":
letters = "abcdefghijklmnopqrstuvwxyz"
elif language == "fr":
letters = "abcdefghijklmnopqrstuvwxyzàâéèêëîïôùûüÿç"
elif language == "ru":
letters = "абвгдеёжзийклмнопрстуфхцчшщъыьэюя"
else:
letters = ""
return list(letters)
def is_letter(variable, language="en"):
valid_letters = set("ABCDEFGHIJKLMNOPQRSTUVWXYZ")
if variable in valid_letters:
return True
else:
return False
"""
Test if a particular letter (string) is correct in a specific language
:param variable: the variable to check
:type variable: X
:param language: the name of the language in which we need to check the letter
:type language: str
:return: the result of the test
:rtype: bool
"""
assert isValidLanguage(language), "la langue n'est pas valide"
pass
def is_a_letter_list(variable, language="en"):
for letter in variable:
if not is_letter(letter, language):
return False
return True
"""
Test if a variable is a list of letters (string) in a specific language
:param variable:The variable to check.
:type variable: list
:param language: the name of the language in which we need to check the letter
:type language: str
:return:Returns True if the input variable is a list of valid letters, False otherwise.
:rtype:bool
"""
assert isValidLanguage(language), "la langue n'est pas valide"
pass
def is_a_mask(variable):
"""
Vérifie si une variable est un masque valide.
Args:
variable (any): la variable à vérifier
Returns:
bool: True si la variable est un masque valide, False sinon
"""
if not isinstance(variable, list): # Vérifie si la variable est une liste
return False
for element in variable:
if not isinstance(element, bool): # Vérifie si chaque élément de la liste est un booléen
return False
return True
"""
Test if a variable is a mask (a list of boolean)
:param variable: the variable to check
:type variable: X
:return: the result of the test
:rtype: bool
"""
pass
def is_a_frequency(variable):
"""
Test if a variable is a frequency (float between 0.0 and 100.0)
:param variable: the variable to check
:type variable: X
:return: the result of the test
:rtype: bool
"""
pass
def is_a_dictionnary_of_frequencies(variable, language="en"):
"""
Test if a variable is a dictionnary of frequencies (float between 0.0 and 100.0)
with as indices the letters
:param variable: the variable to check
:type variable: X
:param language: the name of the language in which we need to check the dictionnary of frequencies
:type language: str
:return: the result of the test
:rtype: bool
"""
assert isValidLanguage(language), "la langue n'est pas valide"
pass
# ------------------------------------------------------------------------------------------------------
def read_dictionary_file(name_file):
"""
Read the file name_file and extract each word one per ligne and export it as a list of words
:param name_file: name of the file with words
:type name_file: str
:return: list of string (words)
:rtype: list
raise an FileNotFoundError if the file doesn\'t exist
raise an ValueError if the list of words is empty
"""
print("Le fichiers du dossier courant sont:",os.listdir("."))
if not os.path.exists("./resources/"+name_file) or not os.path.isfile("./resources/"+name_file):
raise FileNotFoundError("Le fichier "+name_file+" n\'est pas présent dans le répertoire resources/")
list_of_words = []
file = open("./resources/"+name_file, "r", encoding="utf8")
for ligne in file.readlines():
word = ligne.split("\n")[0]
list_of_words.append(word)
file.close()
if len(list_of_words) == 0:
raise ValueError("Le fichier "+name_file+" dans le répertoire resources/ est vide.")
return list_of_words
def pick_a_word(list_of_words):
"""
Choose a random word from a list of words
:param list_of_words: an not empty list of the words
:type list_of_words: list<str>
:return: a word picked randomly from the list
:rtype: str
raise an TypeError if list_of_words is not a list of string or if the list is empty
raise an ValueError if the word picked is empty
"""
if type(list_of_words) != list or any([type(list_of_words[i]) != str for i in range(len(list_of_words))]):
raise TypeError("La liste de mots n\'est pas du bon type.")
if len(list_of_words) == 0:
raise TypeError("La liste de mots est vide.")
indice_word = random.randint(0, len(list_of_words)-1)
word = list_of_words[indice_word]
if len(word) == 0:
raise ValueError("Le mot a l\'indice "+str(indice_word)+" est vide.")
return word
def convert_string_to_char_list(word):
"""
Converts a word represented as a string into a list of characters.
Args:
word (str): The word to convert.
Returns:
list: A list of characters representing the input word.
Raises:
ValueError: If the input word is an empty string or contains invalid characters.
"""
if not isinstance(word, str):
raise TypeError("Input must be a string")
if not word:
raise ValueError("Input string cannot be empty")
char_list = []
for i in range(len(word)):
if not is_letter(word[i]):
raise ValueError(f"Invalid character '{word[i]}' in input string")
char_list.append(word[i])
if not is_a_letter_list(char_list):
raise ValueError("Input string contains non-letter characters")
return char_list
"""
Convert a word to a list of characters
:param word: the word to convert
:type word: str
:return: the list of each characters of the word
:rtype: list<str>
"""
pass
def ask_for_a_letter(language="en"): #base et (IMP2)
"""
Asks the user to input a valid letter between 'A' and 'Z'.
Args:
language (str): The language to use. Currently only supports "en" for English.
Returns:
str: The valid letter input by the user.
Raises:
ValueError: If the input is not a valid letter between 'A' and 'Z'.
"""
valid_letters = set("ABCDEFGHIJKLMNOPQRSTUVWXYZ")
while True:
letter = input("Please enter a valid letter between A and Z: ").strip().upper()
if letter in valid_letters:
return letter
else:
raise ValueError("Invalid input. Please enter a valid letter between A and Z.")
#base et (IMP2)z
#def ask_for_a_letter(list_of_letters_picked, language="en"): #(IMP1)
#def ask_for_a_letter(list_of_letters_picked, list_of_letters_possibles, language="en"): #(IMP1, IMP3)
"""
Ask a letter to the user and check if the letter is valid and not previously asked
:param list_of_letters_picked:
:type list_of_letters_picked:
:param list_of_letters_possibles:
:type list_of_letters_possibles:
:param language: the language in which we need to ask the letter to the user
:type language: str
:return:
:rtype:
"""
assert isValidLanguage(language), "la langue n'est pas valide"
#(IMP1)
#assert ...
#------
#(IMP3)
#assert ...
#------
pass
def display_word(word, mask, language="en"):
# Vérification des pré-conditions
assert isinstance(word, list) and len(word) > 0, "Le mot doit être une liste non vide"
assert isinstance(mask, list) and len(mask) == len(word), "Le masque doit être une liste de booléens de même longueur que le mot"
assert isinstance(language, str) and len(language) == 2, "La langue doit être une chaîne de 2 caractères représentant une langue prise en charge par le programme"
# Affichage du mot avec le masque
display_word = ""
for i in range(len(word)):
if mask[i]:
display_word += word[i] + " "
else:
display_word += "? "
print("Mot à trouver : " + display_word)
"""
Display the word showing only the letters found, in a specific language
:param word: a list with all the letters to find
:type word: list<str>
:param mask: a list with bool indicating if a letter if found or not
:type mask: list<bool>
:param language: the language in which we need to display the word
:type language: str
:return: -
:rtype: None
"""
assert isValidLanguage(language), "la langue n'est pas valide"
#assert ...
pass
def is_letter_in_word(word, letter, language="en"):
"""
Vérifie si une lettre est présente dans un mot dans une langue donnée.
Args:
word (str): le mot dans lequel on cherche la lettre
letter (str): la lettre à chercher
language (str): la langue dans laquelle le mot et la lettre sont représentés (par défaut en anglais)
Returns:
bool: True si la lettre est présente dans le mot, False sinon
"""
# Vérifie si le mot et la lettre sont valides
assert is_a_word(word, language), "Le mot est invalide."
assert is_a_letter(letter, language), "La lettre est invalide."
# Recherche la lettre dans le mot
return letter in word
"""
:param word:
:type word:
:param letter:
:type letter:
:param language: the language in which we need to check the letter
:type language:
:return:
:rtype:
"""
assert isValidLanguage(language), "la langue n'est pas valide"
#assert ...
pass
def get_mask(word, language="en"):
"""
Retourne le masque associé à un mot dans une langue donnée.
Args:
word (str): le mot dont on veut le masque
language (str): la langue dans laquelle le mot est représenté (par défaut en anglais)
Returns:
list: le masque associé au mot
"""
# Vérifie si le mot est valide
assert is_a_word(word, language), "Le mot est invalide."
# Convertit le mot en tableau de caractères
word_list = convert_string_to_char_list(word)
# Initialise le masque à False pour chaque lettre du mot
mask = [False] * len(word_list)
return mask
"""
:param word:
:type word:
:param language:
:type language:
:return:
:rtype:
"""
# in the mask if the letter is found the value at the indice i will be True, False if not
assert isValidLanguage(language), "la langue n'est pas valide"
pass
def update_mask(word, mask, letter_to_reveal, language="en"):
"""
Update the mask for a word in a specific language
:param word:
:type word:
:param mask:
:type mask:
:param letter_to_reveal:
:type letter_to_reveal:
:param language:
:type language:
:return:
:rtype:
"""
assert isValidLanguage(language), "la langue n'est pas valide"
#assert ...
pass
def is_game_finished(mask, nb_errors):
"""
Vérifie si le jeu est terminé en fonction du masque et du nombre d'erreurs.
Args:
mask (List[bool]): Le masque représentant les lettres trouvées et manquantes.
nb_errors (int): Le nombre d'erreurs commises par le joueur.
Returns:
bool: True si le jeu est terminé, False sinon.
"""
assert isinstance(mask, list), "Le masque doit être une liste de booléens."
assert isinstance(nb_errors, int), "Le nombre d'erreurs doit être un entier."
assert is_number_of_errors_correct(nb_errors), f"Le nombre d'erreurs doit être compris entre 0 et {NUMBER_OF_ERRORS_MAX}."
if nb_errors >= NUMBER_OF_ERRORS_MAX:
return True
if False not in mask:
return True
return False
#assert
pass
# --- IMPROVEMENTS ---
def menu_choose_a_language(): #(IMP3)
"""
Show a menu to the user and return the language selected
:return: the language selected ('fr', 'en', 'ru')
:rtype: str
"""
global name_of_dictionaries
pass
def change_lowercase_to_uppercase(letter, language="en"): #(IMP2)
"""
TO DO
"""
assert isValidLanguage(language), "la langue n'est pas valide"
pass
def get_frequencies_of_letters_in_language(language="en"): #(IMP3, IMP4)
"""
Return a the frequencies of the letters in a particular language given in parameter
:param language: the language in which we need to generate the frequencies
:type language: str
:return: the frequencies of the letters
:rtype: dict<str, float>
"""
assert isValidLanguage(language), "la langue n'est pas valide"
frequence_fr = {}
frequence_en = {}
frequence_ru = {}
#TO COMPLETE
pass
def get_values(x):
"""
Return the second value of a 2-uplets
:param x: the 2_uplets
:type x: tuple<X>
:return: the second value of the 2_uplets
:rtype: X
"""
return x[1]
def recommend_next_letter(frequencies, list_of_letters_picked, language="en"): #(IMP3, IMP4)
"""
Return the second value of a 2-uplets
:param frequencies: the frequencies of the letters
:type frequencies: dict<str, float>
:param list_of_letters_picked: a list with all the previous letters asked
:type list_of_letters_picked: list<str>
:param language: the language in which we need to recommend the letter
:type language: str
:return: the letter recommended
:rtype: str
"""
#assert ...
pass
def display_hanged_man(nb_errors): #(IMP5)
"""
Display the hanged man in the console
:param nb_errors: the nb of errors
:type nb_errors: int
:return: -
:rtype: None
"""
pass
##################################################
if __name__ == "__main__":
#choice of the language and import of the dictionary
language = "en" # langue par défaut
#language = english_words() #(IMP3)
#name_of_dictionaries = {"en": "english_words.txt", "fr": "mots_francais.txt"}
dictionary = read_dictionary_file(name_of_dictionaries[language])
# operation with language selected
#list_of_letters_possibles = get_list_of_letters_possibles(language) #(IMP4)
#frequencies = get_frequencies_of_letters_in_language(language) #(IMP4)
# choice of the word
word = pick_a_word(dictionary)
list_char = get_list_of_characters(word)
# initialisation
mask = is_a_mask(word)
nb_errors = 0
# initialisation des lettres
#letters_picked = [] (IMP1)
# boucle de jeu
while not is_game_finished(mask, nb_errors):
# affichage du mot courant
display_word(list_char, mask, language)
# affichage de la lettre recommandée (IMP4)
#recommend_letter = recommend_next_letter(frequencies, letters_picked, \# language)
#print("Nous vous recommandons la lettre suivante :", recommend_letter)
# get the letter and update the list of letters_picked
letter = ask_for_a_letter(language) #base & (IMP2)
#letter = ask_for_a_letter(letters_picked, language) #(IMP1)
letter = ask_for_a_letter(letters_picked, list_of_letters_possibles, \
language)
#(IMP1, IMP3)
# update depending of the result of the test
isPresent = is_letter_in_word(list_char, letter, language)
letters_picked.append(letter)
# update the list of the letters picked #(IMP1)
if isPresent:
update_mask(list_char, mask, letter)
else:
nb_errors += 1
# affichage du pendu
print("Il vous reste", NUMBER_OF_ERRORS_MAX - nb_errors, "erreurs disponibles.")
#display_hanged_man(nb_errors)
print()
# affichage du mot courant
display_word(list_char, mask, language)
# affichage du résultat final
if is_winning(mask):
print("\nVous avez gagné :)")
else:
print("\nVous avez perdu !!")
Nous recherchons un·e développeur·se avec déjà une première expérience professionnelle significative en Python pour poursuivre le développement de nos services. Avoir également de l’expérience avec Vue, Typescript, Docker ou Ansible est un plus.
Type d’emploi : CDI ou CDD, temps plein ou 4/5, poste sur Nantes (présentiel mini 2/3 jours par semaine)
Ce n’est pas un poste de data scientist.
Qui est OctopusMind ?
OctopusMind, spécialiste de l’Open Data économique, développe des services autour de l’analyse des données. Nous éditons principalement une plateforme mondiale de détection d’appels d’offres : www.j360.info
L’entreprise, d’une dizaine de personnes, développe ses propres outils pour analyser quotidiennement une grande masse de données, en alliant intelligence humaine et artificielle www.octopusmind.info
Nos bureaux, dans le centre ville de Nantes, sont adaptés au télétravail. Une partie de l’équipe technique est dans d’autres villes. Aussi, nous recherchons pour ce poste un collaborateur habitant à proximité de Nantes.
Nous vous proposons
L’équipe IT, sans lead developer, est en lien avec l’équipe R&D ML et l’équipe de veille des marchés. Nous suivons un SCRUM maison, ajusté régulièrement selon nos besoins. Nous discutons ensemble de nos priorités et nous les répartissons à chaque sprint selon les profils et envies de chacun·e.
Vous participerez :
Au développement back de j360 et son back-end (Python/Django, PostgreSQL, ElasticSearch).
Aux scripts de collecte de données (Python/Scrapy).
À la relecture de code et l’accompagnement vos collègues en leur fournissant du mentorat sur les bonnes pratiques, l’architecture, les design patterns, etc.
En fonction de vos centres d’intérêts :
Au développement front de l’application j360 (Vue3/Quasar/Typescript).
Au déploiement des applications (Docker/Docker-Compose, Ansible) et intégration des services R&D (Gitlab CI).
À la réflexion produit, analyse technique et à la définition des priorités de l’entreprise (Trello).
À l’ajustement de nos méthodes de travail au sein de l’équipe et de l’entreprise.
Avantages :
Horaires flexibles - RTT - Titres-restaurant - Participation au transport - Épargne salariale - Plan d’intéressement et plan épargne entreprise
Télétravail/présentiel
Statut cadre en fonction du diplôme/l’expérience (Syntec)
Processus de recrutement :
CV + présentation de vous et de ce qui vous intéresse à adresser par mail à job @ octopusmind.info
Vous pouvez illustrer vos compétences techniques avec des exemples de projets ou passer notre test technique.
Echanges et précisions par mail ou téléphone avec le dirigeant d’OctopusMind (~ 30 minutes).
Test technique.
Entretien final dans nos bureaux (avec quelques membres de l’équipe IT, ~1h), puis vous serez invité·e à déjeuner avec nous.
Offre (salaire en fonction de l’expérience/niveau)
SVP pas de démarchage pour de l’outsouring ou cabinet RH, merci
Je le sentais venir depuis un moment, ça y est, Python 3.8 a réussi à détrôner Python 3.7 !
Ça faisait depuis mars 2020 que Python 3.7 était la plus utilisée, 3 ans en tête c’est un joli score je trouve (ok Python 2.7 à fait mieux, mes stats ne remontent pas assez loin pour compter ça exactement). Et avec la cadence d’une version par an maintenant on est pas près de retrouver cette situation je pense.
Côté « gros score » je pense que Python 3.7 « gagne » aussi sur la version la plus largement adoptée avec 42% d’utilisateurs en août 2021. OK OK OK ça reste très loin derrière Python 2.7 et ses 75% d’utilisateurs en 2017
Python 3.8 est déjà en train de redescendre après avoir touché 30% par 3.9, 3.10, et 3.11 qui montent vite.
Bon ce qui est effrayant sur ce graph c’est la croissance du nombre total de téléchargements sur PyPI, regardez l’échelle à gauche, c’est en centaines de millions de téléchargements par jour !!! C’est des centaines de milliers CI sans cache ?
Faire appel à une prestation d’infogérance est une tâche délicate : la complexité des enjeux techniques et la perte de contrôle qu’elle implique rendent la sélection d’un prestataire complexe et parfois anxiogène. Toutefois, externaliser la gestion de son système d’information (SI) peut s’avérer pertinent, voire largement préférable dans certains cas. En effet, internaliser systématiquement la gestion des infrastructures peut être une distraction ou une source de tension au sein de vos équipes. Dans cet article, nous vous proposons une liste partielle et partiale des facteurs clés pour séléctionner votre futur prestataire d’infogérance. Afin de clarifier au mieux les ambitions et limites de cet article, nous précisons que notre perspective est façonnée par notre métier : l’hébergement et l’infogérance Cloud. Bien sûr, l’infogérance regroupe un gradient de missions pouvant inclure : téléphonie, support poste de travail ou encore la TMA de mainframe … Mais nous pensons que les conseils que nous vous apportons ici peuvent s'appliquer à l'essentiel des prestations d'infogérance. L’infogérance présente plusieurs avantages, tels que la réduction des coûts, l’accès à des compétences spécialisées et la possibilité de se concentrer sur son cœur de métier. Dans cet article, nous vous guiderons à travers les étapes clés pour choisir le bon prestataire d’infogérance qui répondra à vos besoins et vous accompagnera dans la réussite de vos projets. Bearstech propose ses missions d’infogérance depuis 2004. Fort de notre expérience diversifiée dans de nombreux contextes techniques et opérationnels, notre équipe accompagne un grand nombre de clients de tout type (taille, métier, exigence technique). C’est en nous appuyant sur cet historique que nous vous proposons de passer en revue les critères essentiels à prendre en compte pour choisir un prestataire d’infogérance, afin d’assurer une collaboration fructueuse et durable, car dans de nombreux cas, le prestataire d’infogérance sera au cœur de vos enjeux métiers. Dans cette page, nous passerons en revue les éléments clés pour bien choisir votre prestataire d’infogérance et ainsi établir une relation satisfaisante et durable. Évaluer précisément vos besoins Avant tout, il est essentiel de bien comprendre vos besoins en matière d’infogérance. Notons, qu’une évaluation approfondie va au-delà d’une simple liste de technologies et de ressources matérielles. Il est également important de prendre en compte les méthodes de travail de vos équipes. Comment fonctionnent-elles au quotidien ? Quelles sont les pratiques et les processus mis en œuvre pour répondre à vos besoins métier ? Cette compréhension approfondie est cruciale, car l’un des principaux défis lorsque l’on collabore avec un expert en charge de la gestion de votre système d’information (et des responsabilités associées) est d’aligner les visions et les pratiques de travail. En ce qui concerne les pratiques, il s’agit généralement de l’aspect le plus simple à résoudre : il suffit de trouver un terrain d’entente et d’adopter des solutions alternatives. Toutefois, harmoniser les visions peut s’avérer plus complexe. Il est bien sûr important de bien présenter les enjeux techniques pour que votre prestataire valide la faisabilité et le coût de la prestation. Mais d’experience, lorsque le positionnement du prestataire est clair, les points de frictions les plus complexes à résoudre sont ceux qui relève des méthodes et de la vision. Préciser le niveau d’exigence en terme de sécurité et de disponibilité N’oubliez pas de préciser le niveau d’exigence et vos attentes en termes de sécurité et de disponibilité, ces informations essentielles doivent être incluses dans la présentation de votre projet. Une communication claire sur ces aspects permettra à votre prestataire d’infogérance potentiel de comprendre vos besoins spécifiques et d’adapter son offre en conséquence. Exemple : Une infrastructure Haute disponibilité avec deux serveurs tournant en permance pour prendre le relais est effectivement le meilleur moyen pour limiter les indisponibilités liées aux pannes matérielles mais : La plupart du temps les indisponibilités sont dues à la performance des applications, aux pics de fréquentations non prévus ou à des problèmes de configuration et autres erreurs humaines. Dans ce contexte, les surcoûts (budgétaires et écologiques) lié au déploiement de deux serveurs pour répondre aux enjeux de disponibilité ne se justifie pas nécessairement. Nota : Pour savoir si la haute-disponibilité se justifie, il convient d’évaluer le coût d’une indisponibilité jusqu'à le redéployement du serveur. Si ce coût multiplié par la probabilité de perdre le dit serveur est supérieur aux coûts de location du matériel supplémentaire et sa gestion opérationnelle sur le long terme, la haute disponibilité se justifie.
Intéressé par un webinar sur le sujet ? Souhaitez-vous assister à un webinar traitant ce sujet ? Avez-vous une autre idée de conférence ? Faites-le nous savoir
Fournissez les informations techniques nécessaires Il est également indispensable de décrire avec précision les éléments techniques concernés par la prestation, tels que les besoins en ressources matérielles, les versions logicielles concernées, les configurations spécifiques, etc. En fournissant ces informations détaillées, vous permettrez à votre prestataire d’infogérance d’évaluer la faisabilité et le coût de la prestation, tout en évitant les mauvaises surprises ou les malentendus ultérieurs. Une bonne communication des informations techniques facilitera la mise en place d’une collaboration fructueuse avec votre prestataire d’infogérance. Assurez-vous donc de bien définir vos attentes et de communiquer clairement vos besoins et vos objectifs à votre prestataire d’infogérance potentiel. Cela facilitera la collaboration et permettra d’établir une relation solide et durable, basée sur une compréhension mutuelle des enjeux et des responsabilités. Demandez des références Bien que les références client ne soient pas le critère de sélection le plus important, elles peuvent néanmoins fournir un aperçu de l’expérience et de la qualité du prestataire. Souvent, les prestataires sont fiers de partager leurs réussites en mentionnant des clients prestigieux. Il est important de ne pas se contenter d’une simple liste de noms. Essayez, autant que possible, de demander des exemples concrets de projets et de prestations qui couvrent les points clés que vous avez identifiés. Les références sont utiles, mais assurez-vous qu’elles correspondent vraiment à la mission pour laquelle vous sollicitez le prestataire. Exemple: si vous recherchez un prestataire pour une mission récurrente sur le long terme, demandez des références qui correspondent à ce type de mission. Les prestations de conseil ponctuelles auront moins de poids dans votre évaluation. Vérifiez également que le prestataire a travaillé avec des clients similaires à votre entreprise. Même si vous n’appréciez pas d’entendre le nom de vos concurrents, leur présence dans une liste de références peut en réalité être un atout, car cela indique que le prestataire a de l’expérience dans votre secteur d’activité. Demandez une description synthétique de l’offre Les contrats d’infogérance peuvent être complexes et difficiles à comprendre, surtout si vous êtes en quête d’un prestataire pour la première fois. C’est pourquoi il est essentiel de disposer d’une synthèse décisionnelle claire et concise, contenant uniquement les informations les plus importantes pour faciliter votre prise de décision. Cette synthèse doit mettre en avant les critères essentiels pour votre projet et refléter ce que votre interlocuteur considère comme prioritaire. Elle permettra également de mieux comprendre les offres et d’identifier rapidement les points forts et les faiblesses de chaque proposition. Lorsque vous consultez plusieurs prestataires, disposer d’un document synthétisant les éléments clés de chaque offre vous aidera à comparer plus efficacement les différentes propositions. Cela facilitera également la création de tableaux comparatifs et vous permettra d’analyser les avantages et les inconvénients de chaque option de manière rationnelle. Si vous constatez qu’une information essentielle est manquante dans la synthèse fournie par un prestataire, n’hésitez pas à demander des précisions. Cela garantira une comparaison équilibrée et éclairée entre les différentes offres, vous permettant de choisir le prestataire d’infogérance le plus adapté à vos besoins et à vos attentes. Comprendre les SLA Il est essentiel de bien comprendre et comparer les niveaux de service proposés. Comparer des pommes et des poires est un risque de tous les instants lorsque l’on cherche un prestataire d’infogérance. Pour éviter de comparer des éléments incomparables, assurez-vous de bien comprendre les notions clés telles que le GTI (Garantie de Temps d’Intervention) et le GTR (Garantie de Temps de Rétablissement). Il est également important de connaître les modalités d’astreinte et les conditions de leur sollicitation. Les aspects liés à la surveillance des systèmes et aux méthodes de stockage des données doivent également être pris en compte. Interrogez-vous sur les éléments suivants : Qu’est-ce qui est surveillé et comment ? Où sont stockées les données et comment sont-elles sauvegardées (localisation et fréquence) ? Exemple : Vous pensez que vous pouvez demandez une intervention d’astreinte directement via ticket, alors que seule les sondes peuvent activer l’astreinte. Toutes ces informations sont cruciales, car elles constituent souvent l’essentiel d’une prestation d’infogérance. En les prenant en considération, vous serez en mesure de comparer efficacement les offres des différents prestataires et de choisir celui qui répond le mieux à vos besoins et exigences. Choisissez un partenaire qui vous ressemble Comme mentionné précédemment, il est crucial de s’assurer que vous et votre prestataire partagez une vision commune de la prestation d’infogérance. Dans le cadre des services, un piège courant est de penser acheter un type de service, alors que le prestataire en propose un autre. Pour éviter ce problème, il est important d’aller au-delà des aspects pratiques de la prestation et d’évaluer votre proximité en termes de vision. Pour ce faire, échangez avec le prestataire sur vos objectifs à long terme, vos attentes en matière d’évolution et d’adaptation aux changements technologiques, ainsi que sur les valeurs qui guident vos décisions. Cela permettra d’identifier si le prestataire est en phase avec votre approche et s’il est capable de vous accompagner efficacement dans la réalisation de vos objectifs. Il est également judicieux de discuter de la manière dont le prestataire envisage la collaboration et la communication avec votre équipe. Un partenariat réussi repose sur une communication fluide, des échanges réguliers et une compréhension mutuelle des besoins et des attentes. Vérifiez que le prestataire est prêt à s’adapter à vos méthodes de travail et à s’engager dans une relation de confiance et de transparence. Exemple : Chez Bearstech nous n’intervenons que sur ticket, refusant les e-mails et les appels téléphoniques. Il est tout à fait possible d'organiser des réunions pour traiter des problématiques techniques complexes ou pour faciliter la prise de décision. Toutefois, ces réunions sont exceptionnelles et elles doivent être planifiées à l'avance. C’est une façon de procéder qui a des impacts pratiques et qui illustre très bien notre vision du métier : les demandes doivent passer par un outil sécurisé et doivent alimenter l'historique de la relation client et de la prestation. C’est un choix qui illustre selon nous les valeurs cardinales dans notre méthodologie : rigueur, transparance et collaboration. Tous nos collaborateurs et les équipes de nos clients, doivent avoir accès au contexte de la mission, correctement notée dans un outil centralisé. En mesurant votre proximité en termes de vision, vous pourrez établir une relation solide et durable avec un prestataire d’infogérance qui vous ressemble et qui est en mesure de répondre à vos besoins spécifiques. Dans le doute choississez Bearstech pour vos missions d’infogérance Cloud Nous avions averti en début d'article que cet article serait partial … Choisir un prestataire d’infogérance est un moment sensible, un prestataire d’infogérance se doit d’agir comme un partenaire de long terme et pour cause il contrôle souvent des aspects critiques de vos processus métier. Nous espérons que cet article vous aidera à aborder le sujet mieux outillé et à choisir votre futur prestataire idéal !
L’Institut du Cerveau est une Fondation privée reconnue d’utilité publique, dont l’objet est la recherche fondamentale et clinique sur le système nerveux. Sur un même lieu, 700 chercheurs, ingénieurs et médecins couvrent l’ensemble des disciplines de la neurologie, dans le but d’accélérer les découvertes sur le fonctionnement du cerveau, et les développements de traitements sur des maladies comme : Alzheimer, Parkinson, Sclérose en plaques, épilepsie, dépression, paraplégies, tétraplégies, etc…
L’équipe d’Informatique Scientifique, au sein de la DSI, a pour mission d’accompagner les chercheurs et ingénieurs de l’Institut dans tous leurs projets informatiques. En particulier, nous développons des applications web-based ou mobiles pour structurer, analyser, visualiser des données de toute nature : cliniques, biologiques, génomiques, neuroimagerie, éléctrophysiologie…
Le poste
Vous êtes un.e développeur.se d’applications web/mobile full-stack axé Python (et si possible Django), avec également de bonnes compétences front-end.
Vous aimez résoudre des problèmes complexes, vous ne lâchez pas tant que votre code ne fonctionne pas parfaitement ou qu’il ne coche pas toutes les cases de critères qualité. Vous aimez travailler en équipe, prêt à donner ou accepter un coup de main. Vous pouvez prendre le lead sur une partie du code. Vous avez envie de monter en compétences et de relever des challenges, rejoignez notre équipe !
Missions principales :
Concevoir, développer, déployer et maintenir des applications (web-based ou mobiles) conçues en interne pour répondre aux besoins des scientifiques.
Développer et intégrer des plugins pour des applications scientifiques spécialisées, généralement open-source.
Mettre en place les tests unitaires, d’intégration, de performance et de sécurité.
Déployer dans le cloud ou on-premise en utilisant nos outils de CI/CD.
Maintenir et faire évoluer notre usine logicielle en proposant et en mettant en place des améliorations à nos outils, nos pratiques, nos process.
Favoriser l’adoption par les scientifiques des outils que vous mettez en place (interactions avec les utilisateurs, ateliers, publications).
Stack technique
Python (+Django), et quelques applications PHP (+Symfony) et Java (+Spring)
Maîtrise de Python + un framework web, idéalement Django, et bonne connaissance des bases de données relationnelles, idéalement PostgreSQL. La connaissance d’autres langages et/ou frameworks web est un plus (PHP/Symfony…). La connaissance et la pratique des librairies scientifiques en python est aussi un plus.
Connaissance d’un framework front-end (idéalement React)
Expérience en développement full-stack en milieu professionnel, incluant la participation à plusieurs facettes de différents projets; back-end, réalisation d’APIs, front-end, tests, déploiement…
Master en informatique ou équivalent
Pratique du développement en environnement Agile, CI/CD, TestDriven…
Utilisation d’outils de développement collaboratif (git, intégration continue, outils de gestion de projet)
Capacité à parler et écrire en anglais
Envie de travailler en milieu scientifique / santé / recherche
Esprit d’équipe, autonomie, curiosité
Conditions
CDI
Rémunération selon profil et expérience
Démarrage: dès que possible
Télétravail : 2 jours / semaine (après 6 mois d’ancienneté)
A Paris 13ème, dans l’hôpital de la Pitié-Salpêtrière
Interessé.e ? Merci d’envoyer votre CV, une lettre/mail de motivation, et des liens vers des dépôts de code à : recrutement**@icm-institute.org** en indiquant « Développeur fullstack Python » dans l’objet.
Makina Corpus développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz. Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Au sein d’une équipe interdisciplinaire composée de dev Front et Back et sous la responsabilité de dev Back, vous aurez pour missions de :
Développer des applications Django
Vous imprégner des méthodes de développement Open Source
Faire évoluer des librairies de Cartographie
Apprendre les méthodes de tests et de déploiement continu
L’objectif de ce stage sera, selon votre profil et vos envies, de travailler sur l’un des sujets suivants :
Création d’une application pour la gestion de l’altimétrie / les géometries 3D depuis Geotrek-admin/altimetry utilisable dans Geotrek-admin mais aussi GeoCRUD
Mise a jour du site de gestion des utilisateurs Geotrek
Permettre de brancher Geotrek sur un backend d’authentification unifiée
… Le profil
Vous êtes en cours ou en fin de cursus informatique (Bac +3 à +5) et êtes compétent.e et motivé.e pour faire du développement Back (Python/Django).
Vous possédez un véritable intérêt pour l’Open source.
Nous attachons avant tout de l’importance aux compétences, à la passion du métier et à une forte motivation.
## Informations complémentaires
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Pourquoi faire votre stage chez nous ?
Dans la ruche collaborative Makina Corpus on dit ce qu’on fait : les équipes évoluent dans une ambiance motivante et stimulante (projets et contrib Opensource, participations encouragées à des évènements/meetup , émulation entre personnes passionnées, technos innovantes à tester, veille…) et contribuent aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée, collaboratif…).
Mais surtout chez Makina on fait ce qu’on dit : vous avez besoin de le voir pour le croire ? Venez nous rencontrer, un.e makinien.ne pourra vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique nous vous attendons !
Makina Corpus développe des projets web ou mobiles d’envergure combinant notamment la cartographie, l’intelligence artificielle, le traitement et l’analyse de données, la dataviz… Nos applications phares sont au service de domaines tels que la randonnée et la gestion d’espaces naturels (Geotrek), l’aménagement du territoire (Actif), l’accès aux cartographies pour les déficients visuels (Accessimap), des systèmes d’information territoriale, des interfaces d’exploration de données…
Notre organisation et nos prestations se construisent sur trois piliers : les logiciels libres, le respect de l’humain et l’engagement en faveur de l’environnement; trois valeurs fondamentales que nous développons et renforçons grâce à notre charte RSE.
Vous renforcerez notre équipe pluridisciplinaire (ergonome, graphistes, développeurs back end/front end, SIG, DBA, mobile…) et interviendrez sur toutes les phases de différents projets (chiffrage, conception, architecture, production, tests, livraison etc) tels que :
Réalisations d’applications et de back end (Django, Flask)
Applications métier manipulant de gros volumes de données, avec des règles de gestion métier spécifiques ou nécessitant des interconnexions avec d’autres applications du système d’information
Vous aurez l’opportunité de :
Choisir vos propres outils de travail, et évoluer dans une ambiance motivante et stimulante (projets et contributions à des logiciels libres, participations encouragées à des évènements/meetup, émulation entre experts passionnés, technologies innovantes à tester, veille…)
Évoluer dans un environnement technique interdisciplinaire permettant à chacun d’avoir un véritable impact sur les décisions et où l’initiative personnelle est valorisée.
Évoluer dans une organisation du travail en mode hybride (mix présentiel-télétravail)
Participer activement à la vie de l’entreprise : avec vos collègues, vous la représenterez au sein de la communauté Python / Django.
Jouer un rôle visible dans les communautés open source : création et amélioration de logiciels libres / Participation à la vie de communautés de développeurs / Coordination de sprints, de bugfests / Réalisation de présentations, conférences, bar camps, formations, lightning talks / Écriture de livres blancs…
Ce poste est ouvert au télétravail partiel (jusqu’à 3 jours/semaine ou en full remote sous conditions avec un retour en présentiel de 4 jours/mois).
Profil
Niveau Bac +5 en informatique de préférence**.** Vous justifiez d’une première expérience des technologies Python et Django, et êtes à l’aise dans un environnement GNU/Linux. Nous apprécierions que vous possédiez certaines des compétences suivantes :
PostgreSQL/PostGIS
OpenStreetMap
MapBoxGL / Leaflet
Tuilage Vectoriel
Flask
ElasticSearch
Docker
Vous aurez à comprendre les besoins métiers à réaliser et être force de proposition pour toute amélioration. Votre goût du travail en équipe, votre curiosité et votre adaptabilité aux évolutions technologiques seront des atouts indispensables.
Nous attachons beaucoup d’importance aux compétences, à la passion du métier et à une forte motivation.
Informations complémentaires
Vous contribuerez activement aux valeurs humaines ancrées dans l’ADN de l’entreprise (environnement, équilibre vie pro/vie privée - grâce à la souplesse des horaires et au télétravail encadré -, travail collaboratif, solide couverture santé…) même si nous n’avons pas du tout la prétention d’être parfaits…
Vous avez besoin de le voir pour le croire ? Venez nous rencontrer, vos futurs collègues pourront vous en parler !
Nos équipes sont mixtes, femmes et hommes du numérique rejoignez-nous !
Écrivez-nous à recrutement@makina-corpus.com, racontez qui vous êtes et ce qui vous motive. Expliquez-nous en quoi vos motivations et vos compétences sont en adéquation avec nos valeurs et nos activités.
Salut à tous,
dans le cadre d’un projet en cours, on utilise Python pour des traitements d’un objet “pluviomètre”. Il est possible cependant qu’on utilise PHP pour certains bouts de code.
Sachant que
1) nous ne sommes pas des développeurs professionnels, juste des bricoleurs amateurs
2) il peut y avoir des traces de PHP dans certains bouts de code (mais restera a majorité du Python)
3) le projet sera mis sous licence libre
est-il possible d’utiliser le Gitea pour partager entre nous du code?
(Je crois comprendre que oui mais je préfère vérifier avant )
J'ai fait un script python… le site utilise une requête get pour afficher les données iptv de action iptv-info.php la requête avec des paramètres est une option de connexion le problème est que je ne peux pas obtenir les données iptv juste une source de page ou un fichier vide :
une chose que je n'ai pas compris c'est qu'après avoir lancé la requête get from action iptv-info.php les données iptv apparaissent sur la page ./iptv.php je suppose que les paramètres des données ne sont pas corrects
il y a aussi un bouton input dont je ne vois pas le name qui correspond à la valeur de value="Custom List Option".
<input type="button" onclick="myFunctiona5()" class="btn btn-default btn-sm" value="Custom List Option"
import requests
s = requests.Session()
LINKFILE= '/tmp/link'
URL = "https://cp.fcccam.com/userpanel/iptv-info.php"
def get_clipmails():
Post_Hdr={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/81.0',
'Accept':'*/*',
'Accept-Language':'fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection':'keep-alive',
'Content-Type':'application/x-www-form-urlencoded',
'Host':'cp.fcccam.com',
'Referer':'https://cp.fcccam.com/index.php',
'Accept-Encoding':'gzip, deflate, br'}
post_data='login=salem&pass=123456&pass_conf=123456&email=012@gmail.com&submit= Register Account '
post_account=s.post('https://cp.fcccam.com/index.php?action=register',headers=Post_Hdr,data=post_data,verify=False,allow_redirects=True).text
post_data2='login='+NAME_TARGET+'&pass='+RND_PASS+'&submit=Login In'
post_account=s.post('https://cp.fcccam.com/index.php?action=login',headers=Post_Hdr,data=post_data2,verify=False,allow_redirects=True).text
params='bid=5&plan=11&conx=1&category_9=Custom List Option&myfsrc1=Search in channels categories..&myfsrc2=Search in movies categories..&myfsrc3=Search in series categories..&mych[]=submit=submit'
html_data=s.get(URL,headers=Post_Hdr,data=params,verify=False,allow_redirects=True).text
with open(LINKFILE, "a") as f: f.write(html_data)
I’m Artur, one of the people responsible for EuroPython Conference in Prague this year. Some of you might remember me from pycon.fr in Bordeaux a month ago.
For everyone who participated in EuroPython before – this year we’re planning even bigger and better conference, and it’s happening in July, in Prague, you can find all the details on our website https://ep2023.europython.eu
For everyone who never been to EuroPython – it’s a 7 days long conference (two days of Tutorials, three days of Talks and other Conference activities, then two days of Sprints). It’s been travelling around Europe for the last 20+ years, and this year it’s going to happen in the Czech Republic.
During Conference days we’re planning 6 parallel tracks, about ~150 talks and we’re expecting more than a thousand people during the conference days.
The overall layout would be very similar to last year, so you can check https://ep2022.europython.eu to get a better idea of what you can expect.
If you’d like to speak at EuroPython – Call For Proposals is still open for the next few days (until Monday noon CEST), and you can find all the details here: https://ep2023.europython.eu/cfp
As part of our programme selection we run Comunity Voting – where everyone who has the ticket or attended EuroPython in the last few years can vote on their favourite talks.
Separately we gather feedback from experts in the field. We would like to ask for your help with the review. If you have some spare time over the next week or two, and would be kind enough to share your opinion please sign up here https://forms.gle/abeyB5pJMJKyZcS26 and we will explain everything in more detail once the review process starts next week.
I hope to see all of you in Prague, and that this post will motivate some of you who haven’t submitted their proposals yet to send them this weekend.
Thanks,
Artur
P.S. Dear admins – I’m not sure if I put in a correct category. Please move it somewhere else if it’s a wrong one
As a new user I couldn’t add more than two clickable links so I just put them in quotes if you could please convert them to clickable links it would be greatly appreciated. Thank you!
Hopla
Bon comme j’ai passablement flood mon manager au sujet de notre participation (mon employeur et moi) à cette PyConFr, il me demande (déjà) des info sur la prochaine éditions.
Rien n’est fais, mais j’aimerai beaucoup proposer du sprint.
Je sais que la date limite du questionnaire est au 15 avril (je fais le mien ce WE) du coup je suis probablement trop en avance… Sait-on déjà si la prochaine PyConFr restera sur la période de février ou va-t-on changer de période pour revenir en automne?
Bonjour à tous,
je travaille chez l’éditeur Temporal qui s’occupe d’un projet opensource de “workflow as code” qui permet de réaliser facilement des executions longues. Par exemple un traitement qui dépend de services externes pour lesquels il faudrait gérer un timeout, des rejeux en cas d’erreur, paralléliser les appels, attendre x jours pour continuer…
Le SDK python de Temporal est sorti récemment et donc nous sommes preneurs de retours de la part de développeurs Python.
Je partage deux liens pour en savoir plus :
Article sur la réalisation d’une application en python
Programme
La contribution du meetup Python Rennes est : Doc-tracing : outiller les discussions d’architecture avec des diagrammes d’exécution des tests fonctionnels.
Je parcours pas mal les sujets féministes, on en a d’ailleurs parlé lors du dernier CD. Et je viens d’avoir le plaisir de trouver un lien vers notre code de conduite pour la PyConFR depuis le site de la place des grenouilles (asso anti-sexiste) : Outils de diversité et inclusion – La Place des Grenouilles
Avec l’environnement de développement open source Blender/UPBGE + Python + Arduino, j’ai développé des jumeaux numériques sur trois maquettes : portail coulissant, monte-charge et volet roulant.
L’intérêt de cet environnement de développement est de s’appuyer sur des écosystèmes généralistes, riches et actifs. Python est au cœur, il sert à définir le comportement des jumeaux (numérique et réel) et il sert aussi de liant avec les bibliothèques utilisées (Blender, Matplotlib, pySerial, Qt5, …).
Je suis enseignant et j’utilise ces jumeaux avec mes élèves (Lycée option Sciences de l’Ingénieur) pour découvrir la programmation de système physique (entrée/sortie, machine à états, …).
Co-organisateur “historique” des meetups sur Bordeaux, j’aimerais redynamiser un peu tout ça, relancer les présentations & apéro conviviales.
Je cherche à fois des personnes pour proposer des sujets et/ou les présenter, et aussi des gens pour aider à animer la communauté, activer du réseaux, trouver des lieux, etc.
Co-organisateur “historique” des meetups sur Bordeaux, j’aimerais redynamiser un peu tout ça, relancer les présentations & apéro conviviales.
Je cherche à fois des personnes pour proposer des sujets et/ou les présenter, et aussi des gens pour aider à animer la communauté, activer du réseaux, trouver des lieux, etc.
We develop open source apps to help millions of employees save time in their day-to-day job.
Our projects include:
→ Business Apps: from point of Sales, to logistics and accounting, we have plenty of projects around business apps (improvement, creation of new features,…)
→ Frontend UI: Odoo Spreadsheet (an open source Google Spreadsheet alternative), a react/vue style JS framework (the fastest VDOM ever developed).
→ Python Framework: It’s all about perf and optimizations. (ORM based on PostgreSQL)
→ Mobile: All Odoo apps run on iOS and Android hybrid mobile apps.
→ Website / Builder: An open source website builder & eCommerce, to help entrepreneurs launch their website by themselves, without technical hassle.
→ API / Connectors: Integrate Odoo with payment processors, carriers, or other services.
→ Security: from product security (code reviews, security patches) to system administration issues (pentesting, best practices, etc.).
After 3 weeks of initial training (both functional & technical), we’ll present you teams looking for new members and you’ll choose the one you prefer.
What’s great in the job?
Great team of very smart people, in a friendly and open culture.
Large apps scope - Diversity in the job, you’ll never get bored.
No customer deadlines - Time to focus on quality, refactoring and testing
No solution architect, no business analysts, no Gantt chart, no boring manager… just great developments.
Real responsibilities and challenges in a fast evolving company.
Friendly working environment located in a renovated farm in the countryside.
An attractive and flexible package: car, fuel card, up to 35 days off per year, meal vouchers (8€/day), eco-cheques (250€/year), hospital insurance, representation fees to cover all your expenses, and much more!
A Chef cooking delicious meals every day at the office
CDI full time (38h/week) with homeworking 2 days/week and flexible hours
Amarena est une jeune entreprise qui travaille dans le secteur de la vente au détail. Filiale d’un grand groupe qui possède de nombreuses activités commerciales dans les DOM-TOM, Amarena a pour objectif d’accompagner ce groupe dans sa transformation digitale, aujourd’hui devenue prioritaire.
Propriétaire de plusieurs site e-commerce et travaillant activement sur la finalisation d’une place de marché qui se veut devenir le futur “Amazon des DOM-TOM”, nous avons également plusieurs projets de développement d’outils internes en préparation, notamment un ERP qui sera central dans les activités du groupe.
Les projets en cours étant variés et prenant toujours plus d’ampleur, nous cherchons aujourd’hui à agrandir notre équipe de développement par le recrutement d’un dev supplémentaire.
Composition et organisation de l’équipe :
Nous sommes une petite entreprise : 15 personnes, pour une moitié de tech. Vous rejoindrez une équipe de quatre développeurs, tous fullstack, et un admin sys. Nous fonctionnons en suivant une méthodologie SCRUM adaptée, avec des sprints de deux semaines en collaboration avec notre équipe produit composée de 2 Product Owners. Nous tenons à garder une ambiance bienveillante dans nos équipes et à ce que tout le monde soit à son aise.
Localisation :
L’équipe est très flexible au niveau du remote (full ou partiel) mais nous avons deux bureaux.
Le principal au Pré-Saint-Gervais, près du métro Hoche. L’immeuble entier appartient au groupe, dans lequel nous avons nos bureaux dédiés. Nous pouvons profiter d’un toit-terrasse, tables de ping-pong, flipper, babyfoot, petite salle de sport avec douche, …
Un deuxième bureau se trouve également au Lamentin en Martinique, depuis lequel travaille une partie de l’équipe en poste.
Stack technique :
Outils et framework de développement
Django (dernière version) + drf + django-ninja
Angular 2+ (dernière version)
Gitlab-CI
Écosystème partiel (à titre informatif) :
Kubernetes (tous nos outils tournent dans notre cluster)
ArgoCD
Prometheus
Sentry
Loki
Grafana
Terraform
Ansible
Pare-feux PFsense
Cluster de VMs Proxmox
Cloud baremetal d’OVH
Profil Recherché :
Plusieurs années d’expériences en entreprise (5+)
De solides connaissances en Django (avoir déjà travaillé sur au moins un projet d’entreprise).
Avoir des bases sur un framework front (Angular, React, VueJS) ; bonus si déjà travaillé avec un système de store
Une expérience dans le domaine du e-commerce est un plus
A envie d’apprendre et n’hésite pas à demander de l’aide en cas de difficulté
Aime travailler en équipe
Journée type :
Ma journée démarre, je commence par le daily dev matinal. On se réparti les tickets préparés avec amour par notre équipe produit, je me créé ma branche de travail et c’est parti. Ah, je bloque sur cette feature, je vais envoyer un petit message à l’équipe, il me semble que X a fait un truc similaire il y a quelques mois. Pfiouu une bonne chose de faite, avec X on a pu faire ça tous les deux bien plus efficacement. Après le déjeuner, je passe ensuite en revus quelques bugs remontés par Sentry et je corrige les plus évidents, puis je vais regarder la Merge Request de Y qu’on m’a attribué. Je lui fais quelques remarques qui sont aussitôt adressées et pour finir la journée, d’un geste théâtral je clique enfin sur le bouton qui lance le déploiement du résultat du travail de toute l’équipe sur l’environnement de staging.
Autre :
Un minimum d’aisance en anglais est attendu (notre communication écrite passe beaucoup par l’anglais)
Flovea a été créé en 2012 et elle est située dans les Landes (Saint-Paul-Lès-Dax, à proximité de Dax). Elle compte aujourd’hui 45 collaborateurs et une filiale à Dubai a été ouverte en 2022.
Elle est spécialisée dans la plomberie hors site (ou préfabriquée) qui permet aux plombiers d’être plus efficace lors de la pose d’éléments de plomberie en chauffage et sanitaires (colonne, dosserets de chaudière, etc) sur leurs chantiers. Cette efficacité se retrouve aussi dans l’industrialisation des procédés d’assemblages et des optimisations de ressources en matériaux.
Flovea possède sa propre usine en France (au siège), ainsi que son propre bureau d’études permettant de concevoir des équipements sur mesure et d’innover de façon permanente.
En 2019, Flovea se lance dans le projet FLOWBOX, un projet de compteur d’eau intelligent permettant le suivi de sa consommation d’eau et récemment enrichi d’un module de détection de consommation anormale, voire de fuites. Un prix de l’innovation a été obtenu au CES de 2019. Début 2022, en vue d’une commercialisation de la FLOWBOX, elle monte une équipe en interne pour la réalisation du logiciel de la carte de la FLOWBOX et la plateforme logicielle de stockage et traitement des données.
En marge de ces activités, Flovea s’est aussi lancé dans la réalisation d’un banc pédagogique « FlowDidact » à destination des apprentis plombiers ou encore à des projets tels que BaityKool aux Emirats Arabes Unis avec un concept de maison durable (https://baitykool.com/)
Le Poste
Après un an avec des indépendants pour initialiser la nouvelle plateforme et réaliser le logiciel embarqué, nous souhaitons renforcer l’équipe interne avec un développeur Python/FastAPI et une appétence soit pour le frontend avec du VueJS ou une appétence vers le Machine Learning / Data Science.
L’équipe est aujourd’hui composée de la façon suivante :
1 Dev Backend Python/FastAPI - indépendant
1 Dev Front VueJS - indépendant
1 Dev Système Embarqué - indépendant
1 Data Scientiste – salariée
1 DSI/CTO qui fait du back et de l’ops en plus de la coordination globale.
Coté expérience, tout le monde a au moins 5 ans d’expérience, sauf notre Data Scientiste qui est encore très junior.
Les projets actuels utilisent les technologies suivantes :
Profil principalement Back + appétence Front ; bonus : appétence OPS
Par appétence, j’entends la capacité à être intéressé par le sujet et pouvoir faire des choses en collaboration avec les autres / sous les directives d’un autre, voir en autonomie idéalement et de façon progressive :
Appétence ML, c’est aussi travailler avec la Data Scientiste pour récupérer ce qui sort de ces algos et les intégrer dans notre backend.
Appétence Ops, c’est pouvoir seconder le DSI/CTO dans la gestion de l’infra du projet au quotidien : gérer les déploiements, suivre la production pendant les périodes de vacances, etc
Appétence Front, c’est pouvoir modifier un existant en VueJS 3 et idéalement pouvoir faire une webapp simple en VueJS3 dans le cadre de la refonte des projets Flowdidact/Baitykool pour les passer de Python/Flask à Python/FastAPI/VueJS afin d’avoir une stack unique pour les projets. Les interfaces sont assez simples.
Coté expérience, il faudrait une personne qui a déjà de l’expérience pour travailler en autonomie et en remote.
Pour ce qui est nécessaire :
Une bonne première expérience avec FastAPI est demandée,
Une connaissance de base avec MQTT (ou outil similaire tel que Kafka, RabbitMQ ou autre broker de message en mode pub/sub)
Pour le reste, les connaissances de bases suffisent (Postgresql, Redis) et pour Warp 10, nous vous expliquerons comment l’utiliser.
Des connaissances en matière de scalabilité (on espère 1000+ Flowbox déployées d’ici la fin d’année et ensuite plusieurs milliers supplémentaires par année).
La fourchette de salaire suivant l’expérience de la personne est de [40-60K€]
Scille est une start-up (10 ingénieurs en CDI), qui développe Parsec, une solution open-source de partage de données et d’édition collaborative zero-trust en end2end (tl;dr: on fait un Dropbox avec un très haut niveau de sécurité puisque tout est chiffré côté client).
Depuis sa création en 2014, notre entreprise a toujours privilégié le télétravail. et la confiance au sein de l’équipe (par exemple on a des gens à Paris, Grenoble, Angers, Rouen, Bordeaux et Beauvais). La compétence, l’autonomie et le sens des responsabilités sont donc capitaux chez nous !
Le poste
L’application Parsec est originellement écrite intégralement en Python et disponible sur desktop (Linux/Windows/macOS) et Android. Cette dernière plateforme a mis en évidence les limites de Python en matière de portabilité et a motivé la réécriture de la partie client de Parsec en Rust avec une interface graphique Ionic/Vue, notamment afin de rendre l’application disponible sur le web.
Notre stack technologique:
Server: Python, Trio, PostgreSQL
Ancien Client: Python, Trio, PyQt5
Nouveau Client (core): Rust, Tokio
Nouveau Client (GUI): Typescript, Vuejs, Ionic
De fait nous recherchons des dev(e)s pour rejoindre notre équipe, aussi bien sur la partie nouvelle GUI, que core Rust et serveur Python.
Qualités recherchées :
Rigueur et volonté à aller au fond des choses quand vous travaillez sur un sujet
Expérience (pro ou perso) dans le développement de logiciels non triviaux (100k SLOC, architecture client/serveur, support de multiples plateformes, problématique de compatibilité ascendante etc.)
Expérience (pro ou perso) dans l’écosystème Python / Rust / Js, ou l’envie de monter dessus
Capacité à travailler en équipe, et notamment à partager ses connaissances pour faire monter en compétences le reste de l’équipe
(bonus) expérience en systèmes asynchrones
(bonus) expérience en cryptographie
(bonus) expérience dans les écosystèmes exotiques: WebAssembly / Android / iOS / MacOS
Le cadre de travail
Le poste est un CDI en télétravail à 100%, toutefois nous essayons de multiplier les occasions de se retrouver afin d’éviter l’isolement et de tisser du lien social entre collègues:
Pour les nouveaux: une semaine d’intégration sur nos locaux de Gentilly pour rencontrer les parisiens de l’équipe et prendre ses marques plus sereinement.
Tous les 3 mois un séminaire d’entreprise (généralement 1 journée sur Paris, et en été 3 jours dans un cadre sympa)
Enfin nous participons aux conférences: PyConFR bien sûr mais aussi Europython et FOSDEM:belgium:
On aime beaucoup l’open-source dans la société, quelques projet pour lesquels on a contribué de manière importante:
Le Muséum National d’Histoire Naturelle recrute un développeur web (Python Flask - Angular - PostgreSQL) sur le projet opensource GeoNature (biodiversité).
Ce poste sera basé au Parc national des Écrins à Gap.
CDD de 2 ans renouvelable.
GeoNature est un logiciel libre, désormais utilisé par une centaine de structures en France pour saisir, gérer et diffuser leurs observations et suivis de la biodiversité (faune/flore/habitats).
te donne un dossier qui contient un fichier EXTERNALLY-MANAGED, alors il est interdit d’utiliser pip avec cet interpréteur, (pour installer il faut donc passer par le gestionnaire de paquets de sa distrib).
Pourquoi ?
Parce qu’utiliser deux gestionnaires de paquets en même temps est un aimant à bugs, le plus méchant pouvant rendre le gestionnaire de paquet de votre distrib inutilisable, une situation inextricable.
Alors, comment on fait ?
On utilise le gestionnaire de paquet de son système d’exploitation, à la place de pip install django on apt install python3-django sur Debian par exemple.
On peut aussi utiliser des venv, la règle ne s’applique pas dans les venvs :
J’espère que tu n’utilisais pas sudo pip install, c’était déjà un aimant à problèmes, maintenant c’est terminé.
J’ai qu’à sudo rm /usr/lib/python3.11/EXTERNALLY-MANAGED donc ?
C’est un garde-fou, le déboulonner ne me semble pas sage. As-tu déjà eu l’idée de déboulonner le garde-fou de ton balcon « parce qu’il te gêne » ? Peut-être, mais tu ne l’as pas fait, c’est sage.
dans le premier cas python, python3python3.11 sont ceux de votre distrib’, utilisez le gestionnaire de paquets de votre distrib pour leur installer des paquets.
dans le second cas python, python3python3.11 sont ceux que vous avez compilés, utilisez pip.
Conclusion
Avant, chez moi, la frontière entre le Python de ma distrib et le Python de même version compilé maison, était floue : je pouvais utiliser /usr/bin/python3.11 pour installer dans ~/.local/lib/python3.11, ça se mélangeait un peu les pinceaux.
Maintenant c’est super clair :
~/.local/bin/python3.11 -m pip fait ses installations dans ~/.local/lib/python3.11/, et uniquement ici.
/usr/bin/python3.11 ne reçois de paquets Python que de ma distrib.
Chacun chez soi et les serpents seront bien gardés !
Je viens de croiser Taichi pour la première fois (mais bon ça date de 2016), développé par Yuanming Hu qui à monté sa boite sur sa lib : https://taichi.graphics.
C’est un JIT pour compiler et déléguer au GPU des calculs fortement parallélisés, ça rappelle donc numba.
Quand on présente une lib comme ça, la tradition c’est de présenter un ensemble de Mandelbrot implémenté avec, donc le voici :
Corsica Sole est une PME créée en 2009 spécialisée dans le développement & l’exploitation de
projets photovoltaïques, avec également une forte spécialisation sur les projets de stockage
d’énergie en France et en Europe.
Engagée dans la transition énergétique, la société Corsica Sole est en innovation constante pour
produire une énergie propre, intégrée aux territoires et créatrice d’emplois.
Forte d’une équipe dynamique de plus de 75 personnes, Corsica Sole est implantée à Paris, Bastia, Lyon, Marseille, Bordeaux, Toulouse, la Réunion, la Guadeloupe, la Martinique et la Guyane.
Acteur majeur du photovoltaïque et 1er exploitant de stockage d’énergie en France, Corsica Sole
exploite actuellement 100 MWc de puissance solaire et plus de 150 MWh de capacité de stockage.
Corsica Sole développe également des projets innovants de production d’hydrogène et possède
une filiale dédiée à la conception et au développement de solutions de recharge pour véhicules
électriques, sa filiale Driveco.
Corsica Sole a levé plus de 350 M€ pour le financement court terme et long terme de ses projets.
Rejoindre Corsica Sole vous permet d’intégrer une structure dynamique à taille humaine, porteuse de sens et de valeurs humaines fortes.
Votre mission
Sous la responsabilité du Directeur Technique, vous avez la charge de piloter le développement, le déploiement et la maintenance des logiciels EMS (Energy Management System) qui permettent de planifier et de contrôler la charge et la décharge de batteries situées sur différents sites en France.
Votre mission consiste notamment à :
• Coordonner le développement du logiciel et piloter les travaux des différents experts ;
• Développer, déployer et maintenir des logiciels informatiques en étant en parfaite harmonie
avec l’infrastructure de l’entreprise : logiciel de pilotage de centrale, applicatif d’échanges
de données, serveur web d’affichage et de remontée des indicateurs, logiciels d’analyse de
données ;
• Automatiser, organiser et piloter tous les tests afin de garantir le bon fonctionnement ;
• Apporter conseils et expertise pour l’administration, le maintien à niveau et le fonctionnement
des outils informatiques, notamment les serveurs de pilotage et de supervision ;
• Participer à l’amélioration des algorithmes d’optimisation et de planification de l’utilisation
des batteries selon les cahiers des charges techniques et les opportunités des marchés ;
• Traiter les évènements d’exploitation informatique (alertes, défaillances, …) ;
• Être force de proposition dans l’amélioration et l’évolution des produits.
Votre Profil
Diplômé(e) d’une grande école d’ingénieur, vous justifiez d’une expérience d’au moins 3 ans dans
des missions de développement informatique.
Vous connaissez ou maitrisez :
• Le pilotage de projet informatique
• L’environnement de travail git (github) et de déploiement sous Linux.
• Le développement logiciel (Python), sûreté de fonctionnement, redondance, …
• Le déploiement de logiciels : ansible, docker, scripts shell, …
• Les protocoles d’échanges de données (SFTP, HTTP, SMTP, …).
La gestion de base de données et la maitrise du développement web avec Django seraient un plus.
Doté(e) d’une bonne capacité organisationnelle, vous savez gérer vos priorités et mener plusieurs
processus en parallèle. Dynamique et rigoureux(se), vous savez faire preuve d’autonomie ainsi que
d’un bon esprit d’équipe.
Informations clés
Localisation : Paris
Type de contrat : CDI
Rémunération : fixe à définir en fonction du profil + avantages
Processus de recrutement
Si cette offre vous intéresse, merci d’envoyer votre CV et votre lettre de motivation par mail à
l’adresse suivante : diane.deproit-ext@corsicasole.com
Corsica Sole est une PME créée en 2009 spécialisée dans le développement & l’exploitation de
projets photovoltaïques, avec également une forte spécialisation sur les projets de stockage
d’énergie en France et en Europe.
Engagée dans la transition énergétique, la société Corsica Sole est en innovation constante pour
produire une énergie propre, intégrée aux territoires et créatrice d’emplois.
Forte d’une équipe dynamique de plus de 75 personnes, Corsica Sole est implantée à Paris, Bastia, Lyon, Marseille, Bordeaux, Toulouse, la Réunion, la Guadeloupe, la Martinique et la Guyane.
Acteur majeur du photovoltaïque et 1er exploitant de stockage d’énergie en France, Corsica Sole
exploite actuellement 100 MWc de puissance solaire et plus de 150 MWh de capacité de stockage.
Corsica Sole développe également des projets innovants de production d’hydrogène et possède
une filiale dédiée à la conception et au développement de solutions de recharge pour véhicules
électriques, sa filiale Driveco.
Corsica Sole a levé plus de 350 M€ pour le financement court terme et long terme de ses projets.
Rejoindre Corsica Sole vous permet d’intégrer une structure dynamique à taille humaine, porteuse de sens et de valeurs humaines fortes.
Votre mission
Sous la responsabilité du Directeur Technique, vous avez la charge de piloter le développement, le déploiement et la maintenance des logiciels EMS (Energy Management System) qui permettent de planifier et de contrôler la charge et la décharge de batteries situées sur différents sites en France.
Votre mission consiste notamment à :
• Coordonner le développement du logiciel et piloter les travaux des différents experts ;
• Développer, déployer et maintenir des logiciels informatiques en étant en parfaite harmonie
avec l’infrastructure de l’entreprise : logiciel de pilotage de centrale, applicatif d’échanges
de données, serveur web d’affichage et de remontée des indicateurs, logiciels d’analyse de
données ;
• Automatiser, organiser et piloter tous les tests afin de garantir le bon fonctionnement ;
• Apporter conseils et expertise pour l’administration, le maintien à niveau et le fonctionnement
des outils informatiques, notamment les serveurs de pilotage et de supervision ;
• Participer à l’amélioration des algorithmes d’optimisation et de planification de l’utilisation
des batteries selon les cahiers des charges techniques et les opportunités des marchés ;
• Traiter les évènements d’exploitation informatique (alertes, défaillances, …) ;
• Être force de proposition dans l’amélioration et l’évolution des produits.
Votre Profil
Diplômé(e) d’une grande école d’ingénieur, vous justifiez d’une expérience d’au moins 3 ans dans
des missions de développement informatique.
Vous connaissez ou maitrisez :
• Le pilotage de projet informatique
• L’environnement de travail git (github) et de déploiement sous Linux.
• Le développement logiciel (Python), sûreté de fonctionnement, redondance, …
• Le déploiement de logiciels : ansible, docker, scripts shell, …
• Les protocoles d’échanges de données (SFTP, HTTP, SMTP, …).
La gestion de base de données et la maitrise du développement web avec Django seraient un plus.
Doté(e) d’une bonne capacité organisationnelle, vous savez gérer vos priorités et mener plusieurs
processus en parallèle. Dynamique et rigoureux(se), vous savez faire preuve d’autonomie ainsi que
d’un bon esprit d’équipe.
Informations clés
Localisation : Paris
Type de contrat : CDI
Rémunération : fixe à définir en fonction du profil + avantages
Locaux bien situés à Paris (75014), Ticket restaurant, Transport métro, bus : en bas d’immeuble
Processus de recrutement
Si cette offre vous intéresse, merci d’envoyer votre CV et votre lettre de motivation par mail à
l’adresse suivante : diane.deproit-ext@corsicasole.com
Attention, je ne parle pas de Discord, je parle bien d’un chat sur notre « https://discuss.afpy.org ».
Discourse permet depuis la dernière version d’activer un chat (vous pouvez le tester sur meta.discourse.org).
J’ignore si c’est une bonne idée de l’activer chez nous, mais en tant que juste sysadmin je laisserai volontiers cette décision aux membres de l’asso, et peut-être le dernier mot au CD.
J’y vois un avantage : quelqu’un qui ne voudrait ni rejoindre IRC ni sur Discourse pourrait discuter ici.
J’y vois un inconvénient : on a déjà IRC et Discord, est-ce qu’on veut un 3ème chat ? Est-ce qu’on veux encore un relai ?
Regarde bien dans les yeux le bout de code suivant
deffoo():x=1classbar:x=x+1returnbarfoo()
exécute le mentalement. Rien d'exceptionnel ?
Et pourtant si,
NameError: name 'x' is not defined
Maintenant essayons avec :
deffoo():x=1classbar:y=x+1returnbarfoo()
Et là… non, rien.
Intuitivement, j'imagine que le x = x + 1 rend Python tout confus, mais j'aimerai mettre le doigt sur une source officielle et je n'la trouve point. Sauras-tu faire mieux que moi ?
Pour le Meetup Python du mois de mars à Grenoble, ce sera un talk sur l’écosystème Jupyter et plus particulièrement sur Jupyter Lite par Jérémy Tuloup (Directeur Technique chez QuantStack et Code Développeur du projet Jupyter).
Ne connaissant pas la nature des échanges entre l’afpy et raffut.media, je pose ça là
Les équipes de https://www.raffut.media/ ont mis en ligne, sur leur compte peertube (raffut_media - Peertube.fr), les captations vidéos de la PyconFr 2023. Et ça, c’est top pour celleux qui n’ont pu s’y rendre.
Les vidéos sont un peu bruts de captage par salle physique, sans être découpées par conférence. Du coup, c’est un peu compliqué de s’y retrouver. Quelque chose est il prévu pour proposer, par exemple : une conf = une capsule vidéo ?
Si oui, comment peut-on aider sur le sujet
Si non, comment faire pour proposer quelque chose ? (Peut on reprendre les vidéos faites par raffut, les découper, les mettre à dispo (où ?) …
Pendant la PyCon, j’ai été approché par l’équipe de captation car iels désiraient les vidéo de ma conférence pour assurer que la rediffusion serait propre. On devait se recroiser pour avoir leur contact mais ça n’a pu avoir lieu.
Est-ce que l’un d’entre vous aurait un contact pour pouvoir leur envoyer ces éléments demandés ? Merci d’avance !
P.-S. Première fois que je poste ici, j’espère que ce n’est pas trop petit pour ouvrir un sujet dédié .
Le prochain aura lieu chez Logilab (merci à eux pour l’accueil !), 104 boulevard Louis-Auguste Blanqui
75013 Paris, avec un format habituel d’une présentation ou deux suivies de pizzas (ou autre) pour discuter.
Qui se propose pour présenter quelque chose ? Durée maximum 20min, faites vos propositions en réponse à ce fil, ou en message privé si vous préférez en discuter avant.
Je relaie une offre d’emploi d’un lieu apprécié des nantais :
TECHNICIEN-NE INFORMATIQUE / BIDOUILEUR-SE DE GENIE (ET IDEALEMENT SERVEUR.SE A PIOCHE).
MISSIONS EN INFORMATIQUE
• Maintien en fonctionnement et mise à jour des matériels informatiques, électroniques et des logiciels (réseau, salles de jeu, postes fixes et portables).
• Gestion et ajustement des paramètres des jeux en lien avec l’équipe.
• Suivi et/ou développement de projets informatiques liés à la création de jeux dans des formes variées (de la rédaction de cahier des charges jusqu’au test, au recettage et à la mise en place d’une documentation pour le reste de l’équipe).
• Maintien en fonctionnement et mise à jour du site internet (hors design et contenu).
LES MISSIONS AU BAR =
à discuter, de 1 soir/mois à 2,5 soir/semaine
• Activités liées au service et à l’animation du bar
• Animer et piloter des groupes de joueur•ses au sein de Pioche
• Créer une relation chouette avec les client-es
• En option: animer des événements autour des enjeux du numérique (type conférence/jeu/atelier).
PROFIL
• Formation initiale ou continue en informatique, électronique, ou électro-technique.
• Expérience forte en environnement LINUX, si possible avec création de systèmes interactifs (ordinateur - micro- contrôleur - multiples capteurs/actionneurs)
• Autonomie dans l’organisation, rigueur et capacité à travailler dans un environnement dynamique et atypique
• Esprit critique et envie de faire la révolution
PARTICULARITÉS DU POSTE
• Collègues incroyables et ambiance de travail idyllique
• Réunion d’équipe hebdomadaire
• Travail majoritairement en semaine et en journée (lundi au vendredi). Horaires mensualisés.
• Solidarité et transparence des salaires au sein de l’équipe.
Ouverture du poste dès que possible Pour candidater ou pour obtenir plus d’infos, écrivez nous à lequipe@pioche.co
PIOCHE - JOUEZ COLLECTIF
Le 1ᵉʳ février 2023 est sortie la version 2.4 du logiciel de gestion de la relation client Crème CRM (sous licence AGPL-3.0). La précédente version, la 2.3, était sortie quasiment un an auparavant, le 15 février 2022.
Au programme notamment, le passage à Python 3.7, l'utilisation de la bibliothèque JavaScript D3.js pour de meilleurs graphiques, une nouvelle synchronisation des e-mails. Les nouveautés sont détaillées dans la suite de la dépêche.
Crème CRM est un logiciel de gestion de la relation client, généralement appelé CRM (pour Customer Relationship Management). Il dispose évidemment des fonctionnalités basiques d’un tel logiciel :
un annuaire, dans lequel on enregistre contacts et sociétés : il peut s’agir de clients, bien sûr, mais aussi de partenaires, prospects, fournisseurs, adhérents, etc. ;
un calendrier pour gérer ses rendez‐vous, appels téléphoniques, conférences, etc. ; chaque utilisateur peut avoir plusieurs calendriers, publics ou privés ;
les opportunités d’affaires, gérant tout l’historique des ventes ;
les actions commerciales, avec leurs objectifs à remplir ;
les documents (fichiers) et les classeurs.
Crème CRM dispose en outre de nombreux modules optionnels le rendant très polyvalent :
campagnes de courriels ;
devis, bons de commande, factures et avoirs ;
tickets, génération des rapports et graphiques…
L’objectif de Crème CRM est de fournir un logiciel libre de gestion de la relation client pouvant convenir à la plupart des besoins, simples ou complexes. À cet effet, il propose quelques concepts puissants qui se combinent entre eux (entités, relations, filtres, vues, propriétés, blocs), et il est très configurable (bien des problèmes pouvant se résoudre par l’interface de configuration) ; la contrepartie est qu’il faudra sûrement passer quelques minutes dans l’interface de configuration graphique pour avoir quelque chose qui vous convienne vraiment (la configuration par défaut ne pouvant être optimale pour tout le monde). De plus, afin de satisfaire les besoins les plus particuliers, son code est conçu pour être facilement étendu, tel un cadriciel (framework).
Du côté de la technique, Crème CRM est codé notamment avec Python/Django et fonctionne avec les bases de données MySQL, SQLite et PostgreSQL.
Principales nouveautés de la version 2.4
Voici les changements les plus notables de cette version :
Passage à Python 3.7
Python 3.6 n'est désormais plus géré, Python 3.7 devient la version minimale. Cela nous a permis d'améliorer les annotations de types.
Des graphiques améliorés
La bibliothèque D3.js a remplacé jqPplot afin de pouvoir faire des graphiques plus complexes et plus performants (utilisation de SVG natif, moins de re-téléchargement de données). Les graphiques sont capables de se redimensionner lorsque la fenêtre est elle-même redimensionnée, et on peut zoomer à l'envi.
Creme dispose depuis toujours d'une app (un module au sens Django) "graphs" qui permet de représenter graphiquement les relations entre des fiches. Jusqu'à Creme 2.3, le rendu était effectué par la célèbre bibliothèque graphviz du coté serveur lorsqu'on demandait à télécharger l'image PNG correspondante. Mais maintenant, un bloc affiche directement le résultat sur la page du graphique avec un rendu coté client (on peut cependant télécharger l'image correspondante afin de l'utiliser ailleurs).
Cette transition va surtout permettre dans le futur de créer de nouveaux types de graphique et d'ajouter de nouvelles fonctionnalités à ceux existants.
Modification de champs multiples
Creme propose depuis des années de modifier un champ spécifique d'une fiche (exemple : le champ "téléphone" de M. Jules Verne), que ce soit depuis un bloc sur la vue détaillée de cette fiche ou depuis la vue en liste correspondant à ce type de fiche. Cela permet d'éviter d'ouvrir le gros formulaire de modification de cette fiche si on veut juste modifier un champ qu'on a déjà sous les yeux.
Il est fréquent que dans un bloc on affiche plusieurs champs d'une même fiche ; si on veut modifier plusieurs champs à la suite (typiquement une personne au téléphone qui vous précise plusieurs de ses coordonnées), il fallait jusqu'à présent passer par plusieurs modifications de champs (ou bien ouvrir le gros formulaire) ce qui n'était pas optimal.
Pour améliorer cette situation, Creme 2.4 introduit la possibilité de modifier les différents champs affichés par un bloc en une seule fois. Par exemple voici un classique bloc d'information de Société :
Si vous cliquez sur le bouton "Modifier" en haut à droite du bloc, un formulaire (qui reprend bien les différents champs de notre bloc) apparaît :
Il était possible dès Creme 1.0 d'importer des e-mails envoyés depuis (et reçus dans) d'autres applications (votre client e-mail typiquement), afin de garder des traces d'échange dans votre CRM même si les e-mails ont été échangés en dehors de Creme. Cependant cette synchronisation avait pas mal de soucis :
La configuration se faisait via le fichier "settings.py" (par l'administrateur uniquement donc, et pas en visuel).
Il n'y avait pas d'IMAP (que du POP).
Il n'y avait pas de mécanisme de bac à sable (les fiches E-Mails étaient créés dans tous les cas et pouvaient recevoir le statut SPAM)…
La synchronisation a été entièrement revue et corrige entre autres tous les soucis énumérés ci-dessus :
On peut configurer les adresses e-mail de synchronisation via l'interface de configuration des e-mails ; POP & IMAP sont acceptés.
On a un bac à sable permettant de voir et de corriger les e-mails avant de les accepter (c'est-à-dire les transformer en vraie fiche Creme), voire de les supprimer.
Plus de widgets de formulaire adaptés aux gros volumes
Si la sélection dans les formulaires d'autres fiches (entités) s'est toujours faite via un widget maison gérant la recherche, la pagination et le chargement dynamique des résultats (et donc le fait de gérer sans problème de grands nombres de fiches), ce n'était pas le cas pour la sélection des petits modèles auxiliaires accompagnant ces fiches (exemples: statut de devis, secteur d'activités…).
Nous sommes passés à la bibliothèque JavaScript Select2 (nous utilisions auparavant Chosen) pour afficher dans les formulaires des sélecteurs qui se chargent désormais dynamiquement (lorsque c'est nécessaire) et gèrent la recherche.
Changement de mot de passe
Il a toujours été possible dans la configuration des utilisateurs qu'un super-utilisateur change le mot de passe d'un utilisateur.
Avec Creme 2.4, les utilisateurs peuvent désormais :
changer leur propre mot de passe en étant déjà connecté.
réinitialiser leur mot de passe en cas d'oubli.
La réinitialisation se fait via la page de connexion qui dispose maintenant par défaut d'un lien "Vous avez perdu votre mot de passe ?" en dessous du bouton "Se connecter" :
Quelques autres améliorations en vrac
Lorsqu'on clone un rôle, les configurations de blocs, formulaires et recherche peuvent être clonées en même temps.
Un job qui supprime périodiquement les sessions expirées a été ajouté.
Les entrées du menu principal peuvent maintenant être personnalisées par rôle ; l'icône du menu peut être personnalisée globalement.
Les types de relation peuvent être désactivés. Dans le cas où vous ne vous servez pas d'un type, cela permet de réduire les choix possibles et donc de rendre les formulaires plus légers/agréables.
Les alertes peuvent avoir une date de déclenchement dynamique (détails).
Le futur
La prochaine version, la 2.5, marquera un changement dans nos dates de releases. En effet, Django sort, depuis quelques années, une nouvelle version tous les 8 mois, et surtout une version gérée à long terme (LTS) tous les 2 ans, en Avril. Donc en sortant en début d'année nous nous privions d'une période de support de plusieurs mois, et lorsque nous passions d'une version LTS à la suivante celà ne laissait qu'une période de quelques mois pour mettre à jour son instance de Creme pendant laquelle l'ancienne et la nouvelle version de Django recevaient au moins des correctifs de sécurité. Même si ce n'était pas dramatique, nous voulons améliorer cette situation. Ainsi nous avons décidé que les prochaines versions de Creme sortiraient en milieu d'année (aux alentours de Juillet).
Creme 2.5 sera donc une version plus petite qu'à l'accoutumée en sortant cette été, et utilisera Django 4.2 qui sortira en Avril 2023. La version minimale de Python sera la 3.8. Si on ne sait pas encore quelles sont toutes les fonctionnalités qu'on aura le temps d'inclure, une réinitialisation des formulaires personnalisés à par exemple déjà été incluse dans la branche main.
Docker s'est imposé au fil des ans comme une solution universelle pour gérer les environnements de développement. Il faut dire que la conteneurisation, popularisée par Docker, présente un avantage substantiel lorsqu'il est question d'installer des environnements et travailler localement.
Docker est reproductible ; Docker offre des silos isolant l'environnement de travail ; Docker permet de gérer le système comme une stack de développement.
Mais le passage en production est souvent un exercice complexe : le réseau, les volumes et autres briques viennent complexifier les opérations sur les machines de production. Avant d'entrer dans le cœur du sujet, nous devons préciser que Docker est une solution tout à fait satisfaisante pour un grand nombre d'entreprises qui souhaitent le déployer et ont les compétences techniques, et les ressources humaines adéquates. Chez Bearstech nous déployons très régulièrement des conteneurs Docker notamment dans le cadre de notre workflow DevOps. Mais lorsque qu'un projet est prêt pour la production, nous faisons souvent le choix de la VM sans conteneur. Cet article vise à expliciter cette démarche et communiquer sur notre conception de l'administration système. Nous avons organisé une série de webinars sur les limites de Docker : Le côté obscur de Docker où nous parlons d'exemples concrets où Docker se comporte d'une drôle de façon. Les avantages de Docker en production Docker en production présente des avantages notables que nous reprenons ici pour contextualiser notre perspective, c'est en pleine connaissance de cause que nous faisons le choix de ne pas déployer Docker systématiquement en production et nous devrons donc répondre à ces enjeux lorsque nous présentons notre approche.
D'abord, il peut permettre dans certaines conditions de densifier l'infrastructure en exploitant un maximum des ressources de la machine hôte. Les applications sont isolées dans des containers ce qui offre en principe des niveaux de sécurité supplémentaires. Le développement, la pré-production et la production sont identiques et facilement reproductibles. L'ensemble des éléments nécessaires pour le fonctionnement des apps peuvent être gérés directement par les développeurs en éditant les Dockerfile et Docker Compose.
Pourquoi nous ne déployons pas Docker en production Les inconvénients de Docker en production Abordons d'abord les contraintes de Docker en général, puis nous explorerons ensemble les enjeux de Docker dans notre cas particulier. Passé un certain nombre de conteneurs déployés, un orchestrateur devient incontournable, ajoutant une couche de complexité supplémentaire. La gestion du réseau et la communication entre les conteneurs est elle aussi complexe et nécessite l'usage de reverse proxy comme træfik. L'immense latitude qu'offre Docker présente des risques de sécurité : quand on peut tout faire… on peut aussi faire n'importe quoi. D'autant, qu'il peut devenir très délicat de vérifier et auditer les images Docker. Ceci est d'autant plus délicat que l'on demande à des développeurs de prendre la responsabilité (et donc le savoir-faire) des administrateurs systèmes (par ex. penser à mettre à jour le paquet système SSL en plus de ses propres dépendances applicatives, etc.) Pour finir, Docker ajoute un grand nombre de couches logicielles supplémentaires qui coûtent en ressources. Par exemple un conteneur Nginx par projet, alors qu'il peut être mutualisé et fournir ainsi une scalabilité bien supérieure (colle : comment "tuner" 100 NGinxes de façon coopérative sur une même VM ?). Pour nombre de projets, Docker coûte plus qu'il apporte. Docker dans le cadre de nos prestations d'infogérance Bearstech gère des infrastructures informatiques depuis 2004 et nous travaillons au quotidien pour améliorer la performance, la sécurité et la disponibilité des services de nos clients. Pour répondre à ces objectifs, nous avons déployé une large expertise de la gestion des VMs. Cela constitue évidemment un biais, mais nous savons bien sûr dépasser nos a priori et proposer les solutions les mieux adaptées à nos clients. Nous travaillons depuis 2014 avec Docker, notamment dans le cadre de notre Workflow DevOps. Le conteneur n'était alors pas une nouveauté pour nous, puisque nous exploitions LXC depuis 2009 pour des projets spécifiques à haute densité. Mais pour assurer nos missions dans les meilleurs conditions et à un coût raisonnable, nous faisons le choix de l'homogénéité sur l'ensemble de notre infrastructure, ne dérogeant à cette approche que lorsque le besoin client ne peut pas être satisfait par cette règle générale. Il faut noter, qu'il s'agit de la même raison pour laquelle nous ne déployons pas de bare metal pour nos clients. Par ailleurs, Docker n'offre pas les garanties satisfaisantes lorsqu'il est question de bases de données :
En premier lieu, sur les gros volumes de données Docker perd en performance et en maintenabilité. Or, chez Bearstech, nous pensons que la base de données est le componsant le plus sensible des systèmes que nous infogérons. Ensuite, les possibilités offertes par Docker permettent de contourner les bonnes pratiques de sécurité auxquelles nous nous astreignons, particulièrement dans un contexte de données sensibles.
Mais quid de la reproductibilité ? Certainement Docker nous permettrait d'accélérer la portabilité des environnements ? Oui, c'est indiscutable, Docker est un avantage sur ce point. C'est d'ailleurs son principal argument. Mais notons que nous avons chez Bearstech une démarche infrastructure as code qui nous offre la flexibilité et l'efficacité nécessaire pour répondre aux attentes spécifiques de chaque client. De notre point de vue, les apports de Docker en la matière nous imposent des contreparties parfois bien trop coûteuses, pour un objectif déjà rempli par nos solutions de virtualisation (et conteneurisation). Un autre avantage qui s'accompagne de compromis trop coûteux : la question de l'exploitation optimale des ressources. Nous avons souligné que Docker est très souvent un facteur favorable pour la densification de l'infrastructure. L'exploitation maximale des ressources déployées est nécessaire aussi bien sur le plan budgétaire, qu'écologique. Mais au final, le choix entre virtualisation et conteneurisation dépend de stratégies plus ou moins établies. Docker peut ironiquement mener souvent à des infrastructures moins denses : il nous est souvent demandé de déployer des clusters entiers de VMs avec des conteneurs pour une poignée d'applications en production - ce qui se justifie techniquement quand on doit garantir des performances prévisibles -, alors qu'une infrastructure nettement plus simple sans conteneur fournirait un service équivalent avec moins de ressources matérielles. Chez Bearstech nous avons atteint un niveau de densification de notre infrastructure satisfaisant sans avoir à complexifier nos systèmes et nos procédures en ajoutant une technologie comme Docker, aussi puissante soit-elle. La conteneurisation est redondante avec notre approche de la virtualisation et les contraintes de Docker dépassent largement d'hypothétiques gains. Docker présente un autre problème majeur dans le cadre de nos prestations : nous l'avons dit, il permet aux développeurs de gérer le système comme du code. Cet avantage, lors de la phase de prototypage devient un écueil pour l'exploitation des services en production. Nos garanties en tant que prestataire (l'exploitation irréprochable des services, leur sécurité, les temps de réponse de notre d'astreinte) n'est pas compatible avec la possibilité donnée par Docker aux développeurs de gérer ses environnements via les Dockerfiles et Docker Compose. Nous pourrions mettre en place des protocoles restreignant cette liberté, en imposant des Dockerfiles et des fichiers docker-compose.yml made in Bearstech mais dans cas, les contraintes apportées par cette approche rendent le choix de Docker beaucoup moins pertinent. Notre rôle en tant qu'infogérant, que ce soit sur notre infrastructure, sur les services d'OVHCloud, de Google ou AWS est d'apporter des garanties quant à la sécurité, la disponibilité et la performance des applications. Nous pouvons répondre à toutes les attentes de nos clients sans surcouche Docker et en tant qu'acteurs rationnels, nous préférons généralement la simplicité, sauf si la complexité est justifiée par des avantages clairs et mesurables.
Un poste est ouvert chez Labellevie pour un(e) developpeur(euse) backend qui travaillera egalement avec le responsable d’infra. Ce poste est intéressant pour toute personne à l’aise en backend python qui souhaite se mettre à Ansible et approfondir ses connaissance admin sys. Il y aura des problématiques backend classique (pg , DRF) .
La fourchette de salaire est entre 40KE et 60KE. J’ai envie de dire que l’ambiance est sympa, mais je suis forcement pas objectif .
pour me contacter : louis.perrier at deleev.com , avec un CV idealement
voila l’annonce :
“La Belle Vie by Deleev" est une startup parisienne dans le secteur de la foodtech. Notre spécialité : livrer vite et bien à nos clients des produits du quotidien de qualités !
Notre équipe apporte les meilleurs outils possibles aux équipes opérationnelles pour leurs permettre de supporter notre croissance rapide. Via la mise en place d’automatismes, d’api et d’interfaces soignées, nous leurs permettons de profiter d’outils innovants dans le secteur de la grande distrib.
Rejoins-nous pour bousculer le monde de la grande distrib !
Chez nous
On est en phase de structuration, si tu aimes “mettre ta pierre à l’édifice”, c’est le bon moment !
Chacun a une responsabilité sur une partie déterminée du code (stats, logistique, ecommerce ….), et est relativement libre des choix sur cette partie (même si il y a relecture).
“Labellevie” est une organisation “remote first”. La majorité des gens travaille au moins à 50% en remote.
Dans la mesure du possible, l’équipe tech est “protégée” des interruptions car on considère que la concentration fait gagner en efficacité.
Nous cherchons une personne
qui maitrise SQL, Javascript et un autre langage de programmation
pour qui Le monde de containérisation n’est pas étranger (ex : docker, docker-compose …)
qui connais ou souhaite apprendre python
qui aime les challenges techniques et fonctionnels
de curieux et d’autonome.
qui a plaisir à voir le résultat de son travail, et qui en saisit les enjeux.
qui a déjà au moins 2 ans d’expériences en développement web ou programmation en général.
Notre stack est faite en Python / Django REST Framework / Vuejs / React js.
Hello à tous,
J’ai monté ma config récemment et j’ai beaucoup de problèmes de BSOD et d’instabilité. Je n’arrive pas vraiment à en determiner la cause. Si quelqu’un était dispo sur Paris ( avec de bonnes connaissances hardware et de l’xp dans ce domaine) pour me donner un coup de main moyennant finances…
Merci beaucoup
Le temps du bilan a sonné. Les participants recevront un questionnaire afin de recueillir leur sentiment concernant cette PyConFR. Ce qui a été et aussi ce qui a moins été, afin de nous permettre une encore meilleure PyConFR l'année prochaine.
Il nous faut aussi remercier beaucoup de monde sans qui la PyConFr n'aurait pas été une aussi bonne réussite :
Le service à compétence nationale (SCN) dénommé « Pôle d’Expertise de la Régulation Numérique » (PEReN), a pour mission d’apporter son expertise et son assistance techniques aux services de l’État et autorités administratives intervenant dans la régulation des plateformes numériques. Il est placé sous l’autorité des ministres chargés de l’économie, de la communication et du numérique et rattaché au Directeur Général des Entreprises pour sa gestion administrative et financière.
Le PEReN réunit les expertises humaines et ressources technologiques principalement dans les domaines du traitement des données, de la data science et de l’analyse algorithmique. Il fournit son savoir-faire technique aux services de l’État et autorités administratives qui le sollicitent (par exemple, Autorité de la concurrence, ARCOM, CNIL, ARCEP, ou directions ministérielles telles que la DGE, la DGCCRF, la DGT ou la DGMIC) en vue d’accéder à une compréhension approfondie des écosystèmes d’information exploités par les grands acteurs du numérique.
Le PEReN est également un centre d’expertise mutualisé entre les différents services de l’État qui conduit une réflexion sur la régulation des plateformes numériques et les outils de cette régulation, dans une approche à la pointe des avancées scientifiques. Il mène notamment certains de ses projets en partenariat avec Inria.
Il a également vocation à animer un réseau de recherche dédié à la régulation des grandes plateformes numériques, et peut être amené à réaliser à son initiative des travaux de recherche académique liés aux différentes thématiques.
Description du profil recherché
Recherche d’une/un data scientist, disposant d’au moins 3 ans d’expérience professionnelle ou d’un portefeuille de productions personnelles conséquentes ou d’une thèse de doctorat dans le domaine de la science des données ou de l’informatique. A ce titre, elle/il saura notamment mobiliser ses savoirs en autonomie aussi bien en programmation qu’en data science :>
Connaissance des bonnes pratiques de développement en Python (Python 3.9) et maîtrisee des bibliothèques usuelles (numpy, pandas, requests, etc.), développement d’API (FastAPI) ;
Maîtrise du requêtage des bases de données SQL (PostgreSQL) ;
Maîtrise de Git ;
Maîtrise des principales bilbiothèques d’apprentissage machine (Tensorflow, PyTorch, scikit-learn).
La/le data scientist devra démontrer une aisance à l’orale et une capacité à vulgariser des notions techniques complexes à un public large et non-spécialiste.
Les expériences suivantes seront considérées comme des atouts sans pour autant être strictement requises dans le contexte de cette fiche de poste :
une expérience dans l’animation d’un réseau de contributeurs, ayant pu conduire à la mise en œuvre de la formalisation de positions communes autour de thématiques numériques ;
la participation à des projets open-source (en tant que mainteneur ou contributeur) ;
une spécialisation dans la collecte et l’exploitation de traces réseaux ;
une spécialisation dans le domaine du traitement du signal audionumérique, d’image ou du NLP.
Description du poste
La/Le data scientist contribue à différents projets du PEReN menés conjointement avec d’autres administrations, au sein d’équipes-projets dédiées de 2 à 4 personnes. Un projet dure en moyenne 6 mois. Elle/il pourra par exemple :
Analyser les données d’entrée et de sortie d’un algorithme, afin d’en déterminer ses grands principes de fonctionnement ou ses biais éventuels.
*Étudier la performance des algorithmes de l’état de l’art en apprentissage profond, par exemple en vision ou en traitement automatique des langues.
Concevoir des dispositifs expérimentaux pour la collecte de données sur mobile.
Afin de mener à bien ces missions, la/le data scientist sera en charge, avec les autres membres de l’équipe-projet, de réaliser les collectes, analyses, croisements et exploitations de données pertinentes. Elle/il pourra également être amené à apporter son expertise sur de nouvelles politiques publiques, par exemple via l’analyse technique de nouvelles régulations françaises ou européenne, l’analyse critique des arguments avancés par les plateformes numériques, ou encore la vulgarisation d’éléments techniques à destination des membres du gouvernement ou du parlement.
Les projets sont développés sur les systèmes informatiques opérés en propre par le PEReN et sont conduits par l’équipe dans leur entièreté.
Elle/il pourra également participer à des projets structurels du PEReN : veille, développement et maintien de briques techniques transverses (mises à disposition par API de modèles à l’état de l’art, etc.).
Salle Charles Darwin : « GEMSEO : une bibliothèque pour l’optimisation multi-disciplinaire » présenté par Jean-Christophe Giret, Antoine Dechaume, c'est maintenant !
Salle Thomas Edison : « The power of AWS Chalice for quick serverless API development in Python » présenté par @NamrataKankaria@twitter.com, c'est maintenant !
Salle Henri Poincaré : « Transformez vos algorithmes de données/IA en applications web complètes en un rien de temps avec Taipy » présenté par @Taipy_io@twitter.com, c'est maintenant !
Salle Rosalind Franklin : « Apport du langage Python dans un service de recherche hospitalière pour mener des analyses de deep learning » présenté par Clément Benoist, c'est maintenant !
Salle Henri Poincaré : « REX analyse antivirus des fichiers de la plateforme emplois de l’inclusion » présenté par François Freitag, c'est maintenant !
Salle Charles Darwin : « Traitement de données géographiques avec Rasterio, NumPy, Fiona et Shapely » présenté par @ArnaudMorvan@twitter.com, c'est maintenant !
Salle Henri Poincaré : « Une bonne quantité de Python peut-elle rendre Firefox moins vulnérable aux supply chain attacks ? » présenté par @mozilla_france@twitter.com, c'est maintenant !
Salle Charles Darwin : « Monorepo Python avec environnements de développement reproductibles et CI scalable » présenté par @smelc3@twitter.com, c'est maintenant !
Voici ma dernière copie d’un démineur agréable codé en Python avec le module tkinter.
Dans le contexte, là où je travail, je n’ai accès qu’à Python 3.5 Portable sur de vieux P4 Windows XP… (sans PyGame par exemple) C’est donc le défi…, faire des jeux en tkinter, sans son pour l’instant, mais c’est pas grave…
J’apprends moi-même Python, je prépare des supports d’apprentissage et j’accompagne déjà quelques élèves…
Par contre, je n’avais pas de réponse concernant la limite de récursivité que je rencontrais pour ma fonction d’exploration… Alors je l’ai réécrite autrement…
J’ai amélioré l’affichage, les couleurs, … Je vous laisse découvrir…
Salle Rosalind Franklin : « CoWorks, a compositionnal microservices framework using Flask/AWS Lamba and Airflow » présenté par Guillaume Doumenc, c'est maintenant !
Salle Charles Darwin : « OCR : apprenez à extraire la substantifique moelle de vos documents scannés » présenté par Bérengère Mathieu, c'est maintenant !
Salle Rosalind Franklin : « Un membre très discret de la famille Jupyter mais pourtant si utile ! » présenté par Pierre-Loic Bayart, c'est maintenant !
Salle Henri Poincaré : « NucliaDB, une base de données pour le machine learning et les données non-structurées » présenté par @ebrehault, c'est maintenant !
Bonjour la Communauté,
Je recherche pour Absys un(e) Développeur(euse) Back End Python passionné.
Bac +3 mini en développement informatique et expérience de 2 ans mini.
Notre proposition :
des projets qui font chauffer les neurones
en full télétravail ou alternance avec présentiel
35h en 5 jours ou 4,5 ou …
salaire entre 30 et 38 K€ + accord d’intéressement + titres restaurant
formation en interne au sein de l’équipe et en externe par des pros de chez pros + participation à Europython et autres grands messe de communauté de dev.
Bref, une PME différente : une ambiance sereine, du temps pour mener à bien les projets, de la solidarité entre dev, un projet RSE de forêt nourrissière …
Tu veux plus d’infos ou candidater, c’est par ici Dev Info Back End ((H/F)
A+
Michelle
Dans 4 jours exactement, salle Henri Poincaré : « Une bonne quantité de Python peut-elle rendre Firefox moins vulnérable aux supply chain attacks ? » présenté par @mozilla_france@twitter.com
Dans 4 jours exactement, salle Charles Darwin : « Monorepo Python avec environnements de développement reproductibles et CI scalable » présenté par @smelc3@twitter.com
Dans 4 jours exactement, salle Rosalind Franklin : « Supercharging Jupyter notebooks for effective storytelling » présenté par @matlabulous@twitter.com
by pulkomandy,Florent Zara,devnewton 🍺,dourouc05 from Linuxfr.org
Trac est un outil de gestion de « tickets » (rapports de bugs) développé en Python. Il était beaucoup utilisé à l’époque de SVN mais a aujourd’hui laissé la place, dans beaucoup de cas, à des outils plus gros comme GitHub (pas libre) ou GitLab. Il continue toutefois son développement et est toujours utilisé par certains projets, en particulier parce qu’il est assez simple à personnaliser à l’aide de plug-ins et facile à déployer.
Les versions 1.5.x sont les versions de développement avant la publication d'une version stable 1.6.x. La branche 1.4 continue également des corrections de bugs. Le rythme de développement n'est pas très rapide puisque la version 1.5.3 date de mai 2021, et il y a finalement assez peu de changements d'une version à la suivante.
La grosse nouveauté que tout le monde attend dans la version 1.6, c'est la possibilité d'utiliser Python 3. Le code principal de Trac est prêt depuis longtemps, mais certains plug-ins ont encore besoin d'un peu de travail pour être adaptés. Malheureusement, cela a conduit par exemple au retrait de Trac dans les paquets Debian il y a quelques années avec la mise à la retraite de Python 2.
Petit historique
Le projet Trac a démarré en 2003. Il s'agit au départ d'une adaptation de CVSTrac pour pouvoir l'utiliser avec Subversion à la place de CVS.
Il est publié au départ sous licence GPL (version 2), mais en 2005, la licence choisie est finalement la licence BSD (version à 3 clauses).
La version 0.10 a introduit le système de plug-ins qui rend Trac entièrement personnalisable.
Les versions suivantes ont connu des évolutions assez importantes, le système de rendu HTML a été remplacé. Dans la version 0.10, Trac utilisait ClearSilver, dans la version 0.11 c'était Genshi (un moteur développé dans le cadre de Edgewall, pour Trac et d'autres projets associés), et dans la version 1.4 c'est finalement Jinja qui est utilisé. À chacune de ces migrations, les plug-ins ont dû être adaptés. Cependant, les branches stables 1.0 et 1.2 sont toujours maintenues pour les équipes utilisant Trac avec de vieux plug-ins pas encore migrés vers ces nouveaux moteurs.
Depuis la version 1.0, les versions paires (1.0, 1.2, 1.4) sont des versions avec un support à long terme. Les versions impaires (1.1, 1.3 et 1.5) sont les versions en cours de développement sur lesquelles il n'y a pas de support.
Principales fonctionnalités
Le cœur de Trac est plutôt minimaliste. Il propose les fonctionnalités suivantes:
Un explorateur de dépôt de code source ;
Un gestionnaire de tickets pour les remontées de bugs ;
Un wiki ;
Une "timeline" avec les dernières modifications.
Il n'y a pas d'outil intégré pour la revue de code (équivalent des "merge requests" de GitHub ou GitLab), il faudra pour cela associer un outil externe comme Gerrit, ou bien un des plug-ins prévus pour cet usage: la version IEC 61508 avec tout son process compliqué, ou la version simplifiée.
L'intégration entre les différents composants permet par exemple de lister les tickets correspondant à certains critères de recherche directement dans une page de wiki. Les messages de commit sont analysés et peuvent déclencher des actions automatiques (fermeture d'un ticket de bug par exemple).
De plus, il est facilement possible de récupérer le contenu des pages (listes de tickets, pages de wiki, etc) via des requêtes HTTP avec un résultat en CSV, qui peut être utilisé pour une intégration simple avec d'autres outils. Des flux RSS sont également disponibles dans de nombreux cas (en plus des classiques notifications par e-mail).
Historiquement, Trac est associé à Subversion, mais il permet aujourd’hui d'utiliser Git, et des plug-ins sont disponibles pour Mercurial et plusieurs autres outils.
Les plug-ins
Ce qui fait tout l'intérêt de Trac, c'est de pouvoir personnaliser entièrement le système. Pour cela, on peut se baser sur les Trac Hacks, de nombreux plug-ins et macros qui peuvent être ajoutés à l'installation de base.
Le développement de plug-ins ou de modifications sur le cœur du projet est assez simple, tout est écrit en Python et on peut facilement déployer un environnement de test (installation avec pip et lancement d'une instance Trac avec une base de données sqlite et le serveur http embarqué). Il est donc assez courant de voir des versions de Trac plus ou moins modifiées et des plug-ins maintenus pour des usages assez spécifiques.
Qui utilise Trac?
Une liste de projets est disponible sur le site de Trac, mais pas très bien tenue à jour. Beaucoup de projets ont migré vers d'autres outils.
Parmi les projets qui restent fidèles à Trac, citons par exemple:
Dans 7 jours exactement, salle Charles Darwin : « GEMSEO : une bibliothèque pour l’optimisation multi-disciplinaire » présenté par Jean-Christophe Giret, Antoine Dechaume
Dans 7 jours exactement, salle Rosalind Franklin : « Interactive web pages with Django or Flask, without writing JavaScript » présenté par Coen de Groot
Dans 7 jours exactement, salle Thomas Edison : « The power of AWS Chalice for quick serverless API development in Python » présenté par @NamrataKankaria@twitter.com
Dans 7 jours exactement, salle Rosalind Franklin : « Save Sheldon: Sarcasm Detection for the Uninitiated! » présenté par @festusdrakon@twitter.com, Ananya
Dans 7 jours exactement, salle Henri Poincaré : « Nua, un PaaS open source en Python pour l'auto-hébergement de vos applications » présenté par @sfermigier
Dans 7 jours exactement, salle Henri Poincaré : « Transformez vos algorithmes de données/IA en applications web complètes en un rien de temps avec Taipy » présenté par @Taipy_io@twitter.com
Dans 7 jours exactement, salle Workshop / Atelier 2 : « Le réseau de neurones qui écrivait des romans » présenté par Bérengère Mathieu, Cécile Hannotte
Dans 7 jours exactement, salle Rosalind Franklin : « Apport du langage Python dans un service de recherche hospitalière pour mener des analyses de deep learning » présenté par Clément Benoist
Dans 7 jours exactement, salle Thomas Edison : « « Fixed bugs » n’est peut-être pas le meilleur message de commit » présenté par @alphare33@twitter.com
Dans 7 jours exactement, salle Workshop / Atelier 1 : « Initiation à Django à travers la création d'un blog » présenté par Mauranne Lagneau, @charletpierre@twitter.com
Dans 7 jours exactement, salle Henri Poincaré : « REX analyse antivirus des fichiers de la plateforme emplois de l’inclusion » présenté par François Freitag
Dans 7 jours exactement, salle Charles Darwin : « Traitement de données géographiques avec Rasterio, NumPy, Fiona et Shapely » présenté par Arnaud Morvan
Dans 7 jours exactement, salle Rosalind Franklin : « Accessibilité numérique : faire sa part quand on est développeur·euse backend » présenté par @AmauryPi
Dans 7 jours exactement, salle Workshop / Atelier 1 : « Mettre le web en page(s) : générer un document PDF avec HTML et CSS » présenté par @grewn0uille@twitter.com
Dans 7 jours exactement, salle Rosalind Franklin : « CoWorks, a compositionnal microservices framework using Flask/AWS Lamba and Airflow » présenté par Guillaume Doumenc
Dans 7 jours exactement, salle Charles Darwin : « OCR : apprenez à extraire la substantifique moelle de vos documents scannés » présenté par Bérengère Mathieu
Dans 7 jours exactement, salle Workshop / Atelier 1 : « Meme Saheb: using Dank Learning to generate original meme captions » présenté par @festusdrakon@twitter.com, Ananya
Dans 7 jours exactement, salle Rosalind Franklin : « Un membre très discret de la famille Jupyter mais pourtant si utile ! » présenté par Pierre-Loic Bayart
Dans 7 jours exactement, salle Workshop / Atelier 2 : « Comment créer des applications web de data science époustouflantes en Python - Tutoriel Taipy » présenté par @Taipy_io@twitter.com
Dans 7 jours exactement, salle Henri Poincaré : « NucliaDB, une base de données pour le machine learning et les données non-structurées » présenté par @ebrehault
Vous l'aurez peut-être compris, mais pendant 2 jours on va tooter les conférences pile 7 jours avant leurs commencement à la #PyConFR. Et ce dans le but de toutes vous les présenter.
by franckdev,Pierre Jarillon,Benoît Sibaud from Linuxfr.org
La conférence Mercurial Paris 2023, est une conférence internationale dédiée au gestionnaire de version Open Source Mercurial. Elle se tiendra du 5 au 7 avril 2023 dans les locaux de l'IRILL (Center for Research and Innovation on Free Software) à Paris, Université Paris Sorbonne.
Mercurial est un gestionnaire de versions, libre et multi-plateforme, qui aide les équipes à collaborer sur des documents tout en conservant l’historique de l’ensemble des modifications. Équivalent fonctionnellement aux biens connus Git ou Svn, il s’en distingue sur de nombreux points techniques, ergonomiques et pratiques.
Doté d’une interface orientée utilisateur facile d’accès et simple à comprendre, il offre des capacités avancées de personnalisation du workflow et s’illustre aussitôt qu’il y a besoin de performances adaptées aux très gros dépôts. (Les équipes de Google et Facebook utilisent en interne des solutions basées sur Mercurial pour gérer l’ensemble de leur code source.).
Après une première édition en 2019, l’équipe d’Octobus aidée de Marla Da Silva, organisent cette nouvelle mouture qui se déroulera du 05 au 07 avril 2023 dans les locaux de l’Irill (Initiative de Recherche et Innovation sur le Logiciel Libre), Université Sorbonne, Paris.
La participation à l'évènement nécessite votre contribution pour absorber les frais d'organisation. 40€ pour la journée de workshop, 40€ pour la journée de conférence, repas du midi compris. Les sprints sont gratuits.
Si vous avez un statut étudiant et n'avez pas le budget pour participer aux trois jours, contactez-nous.
Vous trouverez l’ensemble des informations sur le site https://mercurial.paris dont voici le résumé du programme :
Mercredi 5 avril, Workshops
La première journée sera dédiée aux ateliers. L’occasion de découvrir, se former, évoluer sur le sujet.
Mercurial usage and workflow
Heptapod: Using Mercurial with the GitLab DevOps platform
Jeudi 06 avril, Talks
Présentations d’experts internationaux et retours d’expérience en entreprise.
Stability and innovation
Mercurial and Logilab
Using Mercurial, evolve and hg-git in an academic context
Coffee Break
Mercurial usage at XCG Consulting
Toolings
Heptapod, three years of Mercurial in GitLab and growing
Mercurial at Scale
How Mercurial is used to develop Tryton
Mercurial usage at Nokia: scaling up to multi-gigabyte repositories with hundreds of developers for fun and games
Mercurial usage at Google
Development Update
Mercurial Performance / Rust
State of changeset evolution
Vendredi 7 avril, Sprints
Enfin, le vendredi 7 se dérouleront les “sprints”, groupes de travail pour faire évoluer Mercurial, sa documentation, son écosystème, etc.
Pour toute personne contributrice, expérimentée en développement Python, Rust ou simplement curieuse, c’est le moment de contribuer !
À propos d'Octobus
Octobus est une société de service française dédiée au logiciel libre, spécialiste des langages Rust et Python, son équipe totalise le plus grand nombre de contributions au logiciel Mercurial dont elle maintient l’infrastructure de développement et est en charge de la distribution des nouvelles versions.
Octobus est également éditrice de la solution Heptapod, forge logicielle et plate-forme Devops libre prenant en charge Mercurial Hg et Git.
Vous pouvez utiliser Heptapod en auto hébergement ou via la solution d’hébergement clef en main proposée en partenariat avec Clever Cloud (Data center en France et en Europe).
Enfin, Une instance publique dédiée à l'hébergement de logiciels libres est disponible sur foss.heptapod.net (Vos projets versionés avec Hg ou Git y sont les bienvenus ! pour soumettre).
by Melcore,Benoît Sibaud,Pierre Jarillon,ted from Linuxfr.org
La PyConFR, l'évènement de la communauté francophone du langage de programmation python, aura lieu du 16 au 19 février 2023 à Bordeaux. L'évènement est gratuit mais l'inscription au préalable est obligatoire.
Le programme vient de paraître, le sommaire des conférences, des ateliers et des sprints vous attend dans la suite de cette dépêche.
Je t'écris aujourd'hui pour te parler d'un petit programme de quelques lignes serpentines, qui permet d'écrire du texte dans un fichier audio.
Le programme
importwave# Texte d'entréestring_data=input("Tapez du texte :")encrypted_data=bytes(string_data,'utf-8')# On peut aussi ouvrir directement un fichier texte#filename = str(input("Nom du fichier :"))#encrypted_data = bytes(open(filename).read(), 'utf-8')# Écrit le texte dans nouveau fichier tmp.wavnew_audio_file=wave.open('tmp.wav','wb')new_audio_file.setparams((1,2,44100,0,'NONE','NONE'))new_audio_file.writeframes(encrypted_data)new_audio_file.close()# Pour lire le fichier#f = wave.open(filename, 'rb')#string_data = f.readframes(f.getnframes())#f.close()#print(string_data.decode('utf8'))
C'est bête et ça marche. Incroyable.
Exemple
Lancez simplement le script et tapez du texte.
Vous remarquerez que de manière aléatoire, certaines chaines sont diminuées de leur dernier caractère.
J'ai fait un test sur The Time Machine de H. G. Wells que j'ai téléchargé au format texte UTF-8 ici.
Pensez à commenter/décommenter les quatre premières lignes.
Vous n'y comprenez rien en l'entendant ? Normal, c'est en anglais ! Mais vous pouvez retrouver le texte original en le passant à la moulinette du troisième bloc de code ci-dessus en commentant/décommentant les bonnes lignes. Vous n'y comprenez toujours rien ? Normal, ce script ne sert pas à rendre l'anglais compréhensible.
Utilité
Comment ?! Il faut en plus que ce soit utile !!
(Vite Jean-Marc, trouve quelque chose !)
Euh, et bien, en fait, ça pourrait servir à plusieurs machines à communiquer via leur port audio. Ou bien pour mettre un easter-egg dans une musique de jeu vidéo. Ou tout ce que tu pourras inventer de loufoque, on te fait confiance pour ça, Nal.
Conclusion
Je ne savais pas quoi en faire, alors je te l'offre, Nal, en espérant que tu en fasses bon usage. Bien sûr, il est perfectible, on peut ajouter un système pour choisir ce que l'on veut faire au lieu de tripatouiller le code, une interface graphique, un système pour chiffrer la chaîne de départ, et mille autres choses. Je ne réclame aucun copyright sur ce code, tu peux considérer qu'il t'appartient.
Pour ceux qui suivent, ou veulent suivre, l’admin sys de l’AFPy, je viens de mettre en place un munin. Ça ne fait pas très “2023”, pas de buzzwords, c’est pas hype, hashtag-sorry. Mais bon ça permet de voir ce qui se passe sur les machines, d’être alerté sur certains seuls, moi ça me convient très bien.
(Si vous voulez faire mieux, vous êtes les bienvenus .)
Je travaille aussi, très doucement, sur un woodpecker pour notre gitea, pour le moment ce n’est pas fonctionnel du tout, c’est balbutiant disons : ça tourne sur un raspi posé par terre chez moi, et il n’a pas d’agents donc il ne peut pas bosser.
Et j’ai migré, cette nuit, notre Discourse sur sa propre machine, parce que la cohabiation sur deb2 ça commencait à faire pour cette toute petite machine qui héberge pas mal de choses (pycon.fr, PonyConf, munin, discord2irc, …), si vous reprérez des problèmes avec la migration du Discourse, dites-le moi
Pour le Meetup Python du mois de février à Grenoble, ce sera un atelier sur les données en Python avec l’association Data for Good pour collaborer sur des données ouvertes.
Hopla
Je suis en train d’essayer de m’organiser pour faire le déplacement. Si dans celles et ceux qui ont plus anticipé que mois il vous reste une place, contactez moi
Vous souhaitez rejoindre une jeune entreprise française (et singapourienne) à taille humaine et en forte croissance, tournée vers l’innovation et l’international ?
Vous êtes soucieux(se) des défis énergétiques et environnementaux de notre époque, et vous voulez contribuer concrètement à la sobriété énergétique et à la réduction des émissions de CO2 ?
Alors rejoignez-nous !
Implantée à Lyon et à Singapour, et forte d’une expertise transdisciplinaire (IT, data-science, génie thermique), BeeBryte propose des services innovants de contrôle prédictif optimal distant 24/7 et de support aux opération & maintenance pour aider nos clients industriels et tertiaires à augmenter l’efficacité énergétique et la performance de leurs systèmes de CVC-R (chauffage, ventilation, climatisation, réfrigération).
Pour cela nous mettons en œuvre une surcouche intelligente, portée par notre plateforme Industrial-IoT, qui exploite les informations profondes des systèmes existants et de leur contexte pour maximiser en permanence leur performance énergétique.
En anticipant besoins et facteurs d’influence, nous permettons à nos clients de réduire efficacement leur empreinte carbone, de circonscrire leurs risques, et de réaliser jusqu’à 40% d’économies sur leurs factures énergétiques.
Description
Missions :
Concevoir et réaliser des solutions logicielles innovantes et performantes répondant à des problématiques industrielles
Définir et mettre en œuvre des architectures extensibles, évolutives et scalables
Concevoir et développer des interfaces ergonomiques pour une meilleure expérience utilisateur
Industrialiser et automatiser les tests et le déploiement des applications
Maintenir les solutions BeeBryte à la pointe de la technologie pour l’amélioration énergétique
Génie logiciel (conception & développement logiciel, gestion de versions, tests automatisés, tests d’intégration et intégration et déploiement continus)
Principes de conception et architectures logicielles (Architecture 3-tiers / MVC / Micro Services)
Structures de données et algorithmique
Connaissance UML
Autres compétences appréciées :
Connaissances en DevOps / DevSecOps / GitOps (Container, CI CD)
Connaissances en Data Science et Informatique industrielle (Protocoles MODBUS / BACNET) est un plus
Maîtrise de méthodes agiles (Scrum / Kanban)
Connaissance de Jira Software est un plus
Bonne maîtrise de l’anglais
Vous recherchez une certaine diversité dans votre activité et la possibilité d’intervenir sur différents projets.
Vous considérez que le développement d’une application serveur robuste et scalable et le design d’une interface ergonomique et intuitive constituent les deux faces d’une même pièce.
Vous êtes autonome, rigoureux.euse et animé.e d’un fort esprit d’équipe.
Contrat de travail :
Type de contrat : CDI
Mois de démarrage : Janvier 2022
Lieu de travail : Lyon
Statut : Cadre
Déplacements : Pas de déplacement
Salaire annuel brut (fourchette) : Selon profil
Temps plein
Conditions : télétravail ponctuel autorisé, tickets-restaurant , forfait mobilité durable ou prise en charge 50% du coupon mensuel.
Lead Dev / Ingénieur.e Logiciel Expérimenté h/f – (Lyon)
Notre entreprise :
Vous souhaitez rejoindre une jeune entreprise française (et singapourienne) à taille humaine et en forte croissance, tournée vers l’innovation et l’international ?
Vous êtes soucieux(se) des défis énergétiques et environnementaux de notre époque, et vous voulez contribuer concrètement à la sobriété énergétique et à la réduction des émissions de CO2 ?
Alors rejoignez-nous !
Implantée à Lyon et à Singapour, et forte d’une expertise transdisciplinaire (IT, data-science, génie thermique), BeeBryte propose des services innovants de contrôle prédictif optimal distant 24/7 et de support aux opération & maintenance pour aider nos clients industriels et tertiaires à augmenter l’efficacité énergétique et la performance de leurs systèmes de CVC-R (chauffage, ventilation, climatisation, réfrigération).
Pour cela nous mettons en œuvre une surcouche intelligente, portée par notre plateforme Industrial-IoT, qui exploite les informations profondes des systèmes existants et de leur contexte pour maximiser en permanence leur performance énergétique.
En anticipant besoins et facteurs d’influence, nous permettons à nos clients de réduire efficacement leur empreinte carbone, de circonscrire leurs risques, et de réaliser jusqu’à 40% d’économies sur leurs factures énergétiques.
Description
Missions :
Concevoir et réaliser des solutions logicielles innovantes et performantes répondant à des problématiques industrielles
Définir et mettre en œuvre des architectures extensibles, évolutives et scalables
Concevoir et développer des interfaces ergonomiques pour une meilleure expérience utilisateur
Industrialiser et automatiser les tests et le déploiement des applications
Maintenir les solutions BeeBryte à la pointe de la technologie pour l’amélioration énergétique
Génie logiciel (conception & développement logiciel, gestion de versions, tests automatisés, tests d’intégration et intégration et déploiement continus)
Principes de conception et architectures logicielles (Architecture 3-tiers / MVC / Micro Services)
Graphe / Structures de données et algorithmique
Lead d’une équipe de développement (Suivi / Coaching)
Lead several Software Engineers for Follow up / Mentoring
Autres compétences appréciées :
Connaissances en DevOps / DevSecOps / GitOps (Container, CI CD)
Connaissances en Data Science et Informatique industrielle (Protocoles MODBUS / BACNET / OPC UA / PROFINET) est un plus
Maîtrise de méthodes agiles (Scrum / Kanban), expérience de Scrum Master
Connaissance de Jira Software est un plus
Bonne maîtrise de l’anglais
Vous recherchez une certaine diversité dans votre activité et la possibilité d’intervenir sur différents projets.
Vous considérez que le développement d’une application serveur robuste et scalable et le design d’une interface ergonomique et intuitive constituent les deux faces d’une même pièce.
Vous êtes autonome, rigoureux.euse et animé.e d’un fort esprit d’équipe.
Contrat de travail :
Type de contrat : CDI
Mois de démarrage : Janvier 2023
Lieu de travail : Lyon
Statut : Cadre
Déplacements : Pas de déplacement
Salaire annuel brut (fourchette) : Selon Profil
Temps plein
Conditions : télétravail ponctuel autorisé, tickets-restaurant , forfait mobilité durable ou prise en charge 50% du coupon mensuel.
Le CFP est fermé, mais les portes seront ouverte et l’entrée gratuite
Bon OK, python ne sera pas au centre de la journée, mais c’est pas grave on est toutes et tous curieux ici, non?
Vous pourrez y croiser @david.aparicio, @voltux et moi. Mais peut-être que d’autres Pythonistes feront le déplacement? Faites le savoir avec un message
#VeryTechTrip : une convention pour les aventuriers de la Tech !
Rester à la page des dernières technologies, innover sans céder aux effets de mode, adopter les préceptes du cloud native, coder plus efficacement, automatiser, sécuriser ses applications, gérer intelligemment ses données et réduire le coût énergétique de son infra… Les défis sont nombreux, si vous travaillez dans la tech !
Découvrir comment font les autres, échanger les best practices et vous donner des idées, c’est l’aventure collective qu’on vous propose de vivre le jeudi 2 février 2023 à la Cité des sciences et de l’industrie à Paris.
Une journée entre pairs, réservée aux sysadmins, développeurs, SRE, data scientists, cloud architects, étudiants en informatique… Bref, que du beau monde embarqué dans ce voyage. Et un dress code peu contraignant : vous êtes adepte du tee-shirt à message et du short en hiver ? Vous pourrez entrer quand même.
Bonjour,
mon fils m'a posé une colle hier soir et j'avoue que je ne sais pas comment le dépanner, surtout que mes connaissances en python sont très limitées.
Le fiston travaille sur un ordinateur avec lubuntu et exécute ses programmes directement dans l'éditeur de code geany (qui peut lancer des programmes python depuis son interface).
Et ce module processing, je ne vois définitivement pas à quoi il peut bien faire référence. Il y a bien un module de ce nom dans pip, mais c'est in vieux machin qui n'a pas bougé depuis 10ans et qui semble sans rapport avec le sujet.
J'ai essayé d'installer "la vraie" dépendance p5 (pip install p5) à la place du fichier fourni, mais ça ne fonctionne pas non plus.
Ce programme fonctionne dans l'environnement web trinket, aussi je me dis que processing est forcément un module installable comme dépendance, ce n'est pas un fichier du projet.
Mais malgré avoir passé un peu de temps à chercher, j'avoue je bloque. Est ce que quelqu'un aurait une piste, ou autre?
Merci!
Tout d’abord meilleurs voeux pour cette année 2023 de la part du bureau de l’Association Francophone Python !
Vous recevez ce courriel aujourd’hui car vous êtes ou avez été membre de l’association ces dernières années. De ce fait, si vous êtes toujours membre cette année, vous êtes cordialement convoqué pour notre assemblée générale annuelle qui se tiendra durant la PyConFR 2023 ce dimanche 19 février à 9h.
Pour rappel, la PyConFR 2023 se tiendra à l’université de Bordeaux-Talence du jeudi 16 février au dimanche 19 février (plus d’informations ici À propos − PyConFr 2023), l’inscription est obligatoire pour des raisons d’organisation donc faites passer le mot ! Nous sommes en train d’éplucher les propositions de conférences/d’ateliers afin de constituer le programme de cette édition, on vous tient au courant ! D’ailleurs nous manquons cruellement de volontaires pour aider durant l’évènement, si vous êtes motivés rendez-vous sur PyConFr 2023 !
Nous vous rappelons que si l’adhésion à l’association n’est pas obligatoire pour nous suivre et participer à nos événements, elle est néanmoins indispensable pour pouvoir voter aux résolutions lors de l’assemblée générale. De plus, votre adhésion est un soutien important pour les futures activités de l’association et, espérons-le, l’organisation d’une prochaine PyConFR, donc si vous pouvez vous le permettre nous vous en sommes reconnaissants !
L’ordre du jour de cette assemblée générale sera le suivant :
Le président présentera le bilan moral général de l’association (avec vote d’approbation);
Le trésorier présentera le bilan financier de l’association pour les deux années passées avec une projection éventuelle sur l’année en cours (avec vote d’approbation);
L’assemblée générale validera la dernière version des statuts;
L’assemblée générale procédera ensuite au renouvellement d’une partie du Comité de Direction (CD) de l’association;
Le nouveau Comité de Direction proposera finalement un(e) président(e) à l’approbation de l’assemblée générale.
Des questions ou remarques diverses non assujetties à un vote de la part de l’assemblée pourront également être évoquées par les membres du Bureau, du Comité de Direction et/ou par les membres, cotisants ou non, de l’association. N’hésitez pas à nous transmettre par avance en réponse à ce mail les sujets que vous souhaiteriez potentiellement aborder lors de cette assemblée générale.
Pour votre information, selon l’article 11 de nos statuts, il sera nécessaire de renouveller un tiers des membres du Comité de Direction de l’association.
Vous trouverez ci-dessous la liste de l’ensemble des membres au Comité de Direction avec leur année de début de mandat ainsi que leur poste éventuel au sein du Bureau :
Marc Debureaux (2017, Président, sortant)
Jules Lasne (2018, Vice-Président)
Pierre Bousquié (2020, Trésorier)
Thomas Bouchet (2020, Vice-Trésorier)
Antoine Rozo (2020, Secrétaire)
Jean Lapostolle (2022, Vice-Secrétaire)
Bruno Bonfis (2020)
Laurine Leulliette (2022)
Lucie Anglade (2019, sortante)
Dans le cas où il vous serait impossible de participer à l’assemblée générale de l’association, nous vous encourageons vivement à transmettre votre pouvoir à un autre membre (lui-même à jour de cotisation et présent lors de cette assemblée) de façon à ce que votre voix soit entendue. Pour cela, vous devez nous faire parvenir par courriel à l’adresse comite-directeur@afpy.org (en utilisant votre adresse d’adhésion) l’ensemble de vos coordonnées ainsi que celles du membre qui vous représentera en le mettant lui-même en copie de votre message et en y stipulant explicitement que vous lui accordez votre pouvoir de décision/vote.
Nous réfléchissons encore à une solution le jour J qui permettra à celles et ceux qui n’ont pas pu faire le déplacement sur Bordeaux d’assister malgré tout à l’AG à distance, mais pour le moment nous attendons de voir les dispositifs techniques sur place avant de communiquer sur la procédure. Nous vous enverrons une communication supplémentaire lorsque nous en saurons plus.
Je profite également de cette communication pour vous rappeler les liens et ressources importantes pour rester en contact avec nous :
Nous avons un “forum” (Discourse, les membres de la PSF connaissent bien) sur lequel retrouver nos actualités et échanger avec les membres, n’hésitez pas à nous rejoindre : https://discuss.afpy.org/
Si vous préférez communiquer de manière immédiate, nous sommes également présents sur LiberaChat IRC : irc://irc.libera.chat:6697/afpy
Nous avons également une guilde Discord (qui relaie les messages depuis et vers IRC) : AFPy
Nous communiquons autant que possible sur Twitter, abonnez-vous à @asso_python_fr et @pyconfr
Et finalement si vous êtes perdus, vous pouvez retrouver toutes les informations sur notre site officiel : https://afpy.org
Merci à tous pour votre temps de lecture, j’espère vous retrouver toutes et tous à la PyConFR 2023 et surtout à notre assemblée générale ce dimanche 19 février à 9h !
“Tester c’est douter” ? Viens donc nous voir pour apprendre à douter avec nous.
Nicolas vous présentera pourquoi et comment tester. Avec différents niveaux que l’on peut mettre en place sur un projet. Et ensuite une introduction de pytest.
Michel nous fera un retour d’expérience sur l’utilisation des “Property-Based Testing” avec la bibliothèque Hypothesis. Nous verrons comment il est possible d’étendre sa couverture de tests en s’appuyant sur une génération automatique et optimisée des données de test. On passe alors d’un mode “Arrange - Act - Assert” avec un jeu de données unique à un mode “Given - When - Then”, en augmentant la robustesse du test (et de votre code !).
Et enfin vous aurez quelques tips avant un petit pot pour échanger autour de tout ça et du reste.
Biographies
Nicolas Ledez est “devops” depuis 1995, développeur Python depuis 2003. Il participe à la communauté Breizhcamp, DevOps, Python Rennes, etc. Il travaille chez CG-Wire où il déploie du Python Flask à tout va.
Michel Caradec est lead data engineer chez Reech, et travaille sur l’offre Reech Influence Cloud, solution d’influence marketing. Après un passé de développeur, Michel se concentre maintenant sur les problématiques liées au traitement des données, dans un contexte distribué et Cloud.
On se retrouve pour le premier meetup de 2023 le mercredi 25 janvier dès 19h à l’Atelier des médias.
Kara viendra nous parler de python dans le monde scientifique.
L'association avec laquelle je travaille recherche un renfort en développement. Nous avons déjà fait appel à la communauté avec succès, donc on y revient ! J'espère avoir respecté les formes attendues, n'hésitez pas à me dire s'il y a des choses à améliorer ;)
MàJ Février 2023 : l'offre a été pourvue, merci pour vos relais.
--
Énergies citoyennes en Pays de Vilaine (EPV) cherche les services d’un.e développeur.se Python habitué.e du logiciel libre pour participer à un projet collaboratif traitant de la répartition locale de l’énergie. Durée de la mission 20 à 30 jours.
Le contexte
Le but de la mission est de coder le contrôle-commande d’un système de gestion de l’énergie pour le projet ELFE (Expérimentons Localement la Flexibilité Énergétique). Ce projet citoyen embarque 120 foyers et 40 acteurs économiques ou publics sur le pays de Redon-Pontchateau, et vise à optimiser la consommation d’énergie produite localement. Pour cela, des équipements domotiques sont installés chez des particuliers et des professionnels afin de commander à distance des machines, des radiateurs, des chargeurs de véhicule électrique…
Un groupe de 8 bénévoles a impulsé le projet ELFE en novembre 2021, pour une durée de 2,5 années, et l’équipe opérationnelle comporte 3 salariés et plusieurs partenaires aux compétences complémentaires. Le projet bénéficie du soutien et du financement de collectivités locales, ainsi que d’acteurs économiques locaux.
Le projet est dans une phase d’expérimentation, et la stratégie est d’utiliser un maximum de logiciels libres sur étagère (Proxmox, Debian, Zabbix, PosgreSQL, Mosquitto, OpenHasp). L’architecture système et logicielle ont déjà été définies. Plusieurs composants logiciels vont se connecter à une base de données de coordination pour notamment enregistrer des configurations et des consignes. A contrario, un seul composant logiciel va, en fonction du contenu de cette base, envoyer des ordres aux équipements domotiques par l’intermédiaire d’un broker MQTT : c’est l’objet de cette mission.
Le Client
Énergies citoyennes en Pays de Vilaine (EPV) est une association qui vise la réappropriation de l’énergie par les citoyens en les impliquant le plus possible dans la transition énergétique et sociétale. Active depuis 20 ans sur les pays de Redon et de Pontchateau, EPV a permis l’émergence des premiers parcs éoliens 100 % citoyens, et défend une démarche de sobriété collective. Elle compte 10 salarié-es et plus de 110 adhérent-es.
Prestations attendues
Après la découverte de l’architecture système et logicielle déjà définie, Vous devez réaliser les programmes suivants :
Transcription des consignes du système de gestion de l’énergie : essentiellement de la transcription d’informations (volume estimé 5j)
Commande des équipements domotiques : envoi d’ordres via protocole MQTT (vers les équipements domotiques), écoute de topics MQTT (pour les messages de stimulation envoyés par d’autres programmes ou interfaces), commande des équipements domotiques par la réalisation de machines à états (déjà définies) . (volume estimé 12j)
Gestion des afficheurs utilisateur : participation aux spécifications techniques, commandes en MQTT, en lien avec le firmware OpenHASP sur un M5Stack CORE2. (volume estimé 7j)
Monitoring des équipements domotiques : écoute de topics MQTT pour mettre à jour l’état des équipements domotiques en base de donnée (volume estimé 3j)
Les programmes devront être testés et opérationnels (implémentés dans l’infrastructure SI du projet) pour la fin de la mission. Les réalisations seront publiées sous licence EUPL, dans une logique de partage citoyen.
Qualités attendues
Pouvoir travailler dans un mode collaboratif et collectif à distance, parfois en autonomie, parfois en groupe de travail.
Écoute, respect, bienveillance et organisation sont de mise.
Nous avons besoin d’une personne expérimentée dans le domaine du développement.
Avoir la fibre du logiciel libre et idéalement avoir déjà contribué au logiciel libre en général.
Connaissances attendues
Maîtrise de la programmation Python.
Travailler sous environnement Linux.
Maîtriser le concept de machine à états et idéalement avoir déjà eu une expérience d’implémentation.
La connaissance de MQTT est un plus.
Conditions de la mission
Début : Dès que possible
Fin : Compte-tenu des phases de test/mise en production et des délais visés par le projet, les réalisations seront réparties en deux temps : une section minimale (estimée à 20j) pour fin Février, et une section complémentaire (5-7j) attendue fin Mars.
Nombre de jours équivalent temps plein de prestations estimé : 20 à 27
Lieu : le centre de l’équipe de projet est à Redon. La mission peut être réalisée à distance, possibilité de venir sur site ponctuellement suivant le besoin (bureau partagé possible),
Conditions financières : à négocier. [fourchette estimée TJM : 300 à 400€HT]
Comment répondre
Faire une proposition commerciale détaillée avec votre taux journalier.
Délais : proposition commerciale à faire avant fin janvier.
Un mail décrivant votre motivation et intérêt à travailler pour le projet est souhaité, avec des références de réalisations justifiant votre expérience.
Proposition à envoyer par mail à elfe@enr-citoyennes.fr (commencer le sujet par [ELFE RECR DEV])
Je voudrais utiliser argparse dans un cas où on a différents arguments selon la valeur du premier.
Soit par exemple un programme python appelé en ligne de commande qui admet les arguments suivants :
<arg1> 'op1' ou 'op2' ou 'op3' # argument obligatoire
<arg2> : une chaîne de caractères # argument obligatoire
puis
si arg1 == op1 alors pas d'autres arguments
si arg1 == op2 alors l'argument supplémentaire suivant :
<arg3> : une chaîne de caractères # argument obligatoire
si arg1 == op3 alors les arguments supplémentaires suivants :
<arg3> : 'red' ou 'green' ou 'blue' # argument optionnel
<arg4> : '--simu' # argument optionnel
Les éditions précédentes de pycon, du moins celles auxquelles j’ai assisté, comportaient des “ateliers”, sur divers sujets. Y en a-t-il de prévu pour celle de Bordeaux?
J’initie ma petite fille à Python, et on pense venir à Pycon. Mais elle débute, et le niveau d’un atelier, s’adressant à des pythoniens aguerris, peut être redoutable. Un atelier d’initiation serait idéal.
Elle est sous Fenetre, moi sous Linux, et je n’ai pas la culture Fenetre. Hier installation de pip, sans même virtualenv, pas bin facile…
Type de contrat : Stage
Localisation : PLEUDIHEN SUR RANCE (CÔTE D’ARMOR)
Pays : France
Un Groupe, des Métiers, le Vôtre…
Avec ses 6 marques de prêt-à-porter (Cache-Cache, Bréal, Bonobo, Morgan, Vib’s et Caroll), 1 Milliard de CA à fin février 2021, 13000 collaborateurs et 2400 points de vente dans le monde, le Groupe Beaumanoir poursuit son développement et recrute pour sa filiale logistique C-log.
Prestataire reconnu en Supplychain E-Commerce et Retail, C-Log propose des solutions logistiques et transport sur-mesure aux marques d’équipement de la personne (prêt-à-porter, beauté, chaussures, maroquinerie, sports, accessoires…). C-Log, en bref : 210 000 m² de surface, 8 sites en France, 1 site à Shanghai, 750 collaborateurs, 97 millions de pièces expédiées/an, 7500 points de vente livrés à travers plus de 90 pays. Des marques reconnues font aujourd’hui confiance à C-Log : Cache-Cache, Morgan, Bonobo, Eden Park, Damart, Sandro, Maje, Claudie Pierlot, Kickers,…
En cohérence avec une politique de Ressources Humaines favorisant l’épanouissement des collaborateurs, C-LOG recherche des collaborateurs curieux, désireux de réussir et toujours prêts à apprendre.
Détails du poste
Vous êtes intégrés au sein du bureau d’étude et d’innovation, structure à taille humaine dédiée aux problématiques de mécanisation et robotisation des entrepôts. Vous participerez au développement de solutions mécatroniques innovantes afin d’assister les
opérateurs.
Dans le cadre du déploiement d’une solution robotisée à base d’AGV pour la logistique de nos entrepôts, nous recherchons un stagiaire Développeur python pour une durée de 6 mois, pour nous assister sur le développement backend du logiciel de supervision de la flotte. Et plus particulièrement sur le développement d’un simulateur de production.
Ce stage pourra se concentrer sur un ou plusieurs des sujets suivants :
• Développement du modèle dynamique d’un AGV
Simulation du comportement dynamique d’un AGV calqué sur nos robots
Émulation du logiciel embarqué
Génération d’erreurs selon un profil statistique (perte en navigation, déviation de trajectoire, perte de connexion, dérapage, etc…)
Connexion avec le superviseur
• Traitement et analyse de données statistiques
Mise à disposition des données statistiques des résultats des scénarios de simulation
Analyse au regard des KPIs demandées
Génération de nouveaux indicateurs en lien avec les productivités du site d’exploitation
Pour chaque sujet traité, vous serez assistés par le reste de l’équipe de développeurs et les étapes de développement suivantes seront à mettre en place :
• Analyse et compréhension des solutions déjà existantes
• Amélioration continue : optimisation du code existant, développement de nouvelles fonctionnalités
• Essais et tests, validation
• Documentation
• Industrialisation
Profil, Expérience, Formation
Nous recherchons avant tout un passionné de python, curieux et débrouillard. Vous intégrerez une équipe restreinte et donc multidisciplinaire, vous saurez faire preuve d’autonomie et de bonne humeur, vous serez une véritable force de proposition et
d’innovation.
Vous recherchez l’optimisation de vos codes, et passez du temps à confronter votre code aux essais réels ne vous fait pas peur.
Une bonne maîtrise de l’algorithmie est essentielle, l’art de construire une architecture logicielle et une bonne compréhension des blagues geeks sont des atouts indéniables.
Ouvert à tous les talents, l’ensemble de nos postes sont handi-accueillants.
est ce que quelqu'un aurait un retour sur https://www.futureengineer.fr/?
Ce serait pour initier un enfant à la programmation en python (à sa demande, je précise). Je cherche un complément à ce parcours qui me semble bien mais très scolaire (très formel) http://www.france-ioi.org/algo/chapters.php. S'agissant d'un enfant assez jeune, j'aimerais avoir un petit à-côté ludique à proposer si jamais la motivation s’essoufflait.
Ce programme m'a été recommandé par d'autres parents, mais le logo d'amazon me fait un peu peur. Je n'ai pas trop envie d'avoir du placement de produit toutes les pages…
Bref, je préférerais savoir dans quoi je m'aventure avant d'y lancer mon fiston.
by MeAndMyKeyboard,Pierre Jarillon,Ysabeau from Linuxfr.org
Depuis quelques années (10/15, mince ça passe vite), j’héberge mes services à la maison au frais dans le garage sur un serveur physique, des VMs et depuis peu des instances cloud. Moi, ma petite famille et un cercle d’amis en sont les seuls utilisateurs. Un peu comme beaucoup de monde ici sans doute.
Un soir, j’installe Grafana/Prometheus pour me former et constate les scans en continu des bots sur tout ce qui est exposé. Bon, je ne suis pas un jeunot, je m’en doutais, mais quand même, ça se bouscule pas mal…
N’étant pas à l’abri de louper une mise à jour de temps en temps, ça ne me plaît pas beaucoup et je cherche comment améliorer tout ça, et voici comment…
Jour 1 : la solution VPN ! C’est cool, ça protège des virus selon le VPN du Nord ou OpenOffice en son temps. Ah non, la ministre pensait que c’était un pare-feu… (cf lien 5)
Et oui, c’est bien, mais il faut gérer les authentifications, installer les clients, croiser le regard de ses proches (« Mais pourquoi 😢 »). La nuit passe, il faut trouver autre chose.
Jour 2 : le bastion ssh, les proxies socks. C’est marrant, tout terrain et ça fonctionne. Mais bon on va garder ça pour soi au travail. Ce serait un remake en pire du jour un… Next !
Jour 3 : port-knocking ! On toque à la porte d’un serveur avec la bonne séquence udp ou tcp et il ouvre des règles de pare-feu. C’est propre, il y a des clients disponibles sur quasiment tous les appareils. C’est presque idéal, mais ça reste quand même technique, très, trop…
Jour 4 : 😰 pas grand-chose de neuf.
Jour 5 : je me rappelle mes quelques mois à développer un premier projet opensource 🤔. Si ça n’existe pas, on le code et on le partage ! C’était le bon temps ! Go, on se retrousse les manches.
On code !
Mois 1 : maquette sous django, base de données mariadb et installation conteneurisée. Ça fait le boulot, mais ce n’est pas superléger. J’ai l’impression d’enfoncer un clou avec une masse.
Mois 2 : ça fait le boulot et c’est quand même bien pratique. Mes instances nextcloud et bitwarden par exemple sont accessibles via des liens « tiers » que je donne à mes proches. Quand ils vont dessus, leurs ip clientes sont lues et le pare-feu les autorise directement. Ils sont redirigés quelques secondes après et utilisent tout ce qu’ils connaissent normalement sans nouveau passage par MySafeIP.
C’est aussi la première fois que j'ai si peu d’état d’âme à avoir des données personnelles en ligne.
Les bots eux se cassent les dents, je jubile 😏.
Mois 3 : le partager en l’état ? Il faudrait faire plus léger. Découverte de Fastapi, bootstrap. On ressort clavier/souris. Fastapi est bluffant dans un autre registre que Django 🤩. Le potentiel est là et la documentation est pléthorique pour un projet aussi jeune. C’est très, très motivant et j’ai quelques idées pour la suite :).
MySafeIP en bref
Après cette longue introduction, mais qui résume bien le besoin et les contraintes de ce genre d'outil, voici en bref ce qu'est MySafeIP.
MySafeIp est une application opensource (Apache-2.0) servant de tiers de confiance pour tenir à jour dynamiquement des IPs de confiance :
soit déclarées manuellement après authentification ;
soit automatiquement via des liens à la manière d’un raccourcisseur d’url mais dont la redirection permet la lecture de l’IP cliente et son autorisation.
L’ensemble est basé sur les framework Fastapi (backend) et Bootstrap/jinja (UI). L’interface d’administration web est compatible pc/smartphone.
Ça s’installe facilement :
L’installation est conteneurisée côté serveur et un petit module python est disponible pour assurer la récupération des IPs côté pare-feu. Je fournis aussi le script permettant de régler à minima iptables en se basant sur ipset 🥳.
En bref, cela s’installe en 5 minutes via docker-compose (oui, c’est un peu vendeur, disons 15 minutes en comptant le client 😜) et ajoute un filtrage fin en entrée de tous vos services sans effaroucher pour autant vos utilisateurs.
Côté authentification, login/mot de passe et deux facteurs (TOTP) pour l’administration web, Tokens pour le module client (gérables depuis l’application).
Vous pouvez enfin autoriser ou non l’enregistrement d’utilisateurs qui voudraient s’en servir pour leurs propres services. Il est, de plus, disponible en français et anglais.
Vous savez presque tout, j’espère qu’il vous rendra autant service qu’à moi.
Je le considère en version Alpha le temps de m’atteler à la réorganisation des routes et l’ajout des tests unitaires. Il fonctionne cependant « out of the box » et vous donnera déjà un bon aperçu de son utilité.
Et, avant que vous ne vous précipitiez sur les captures d’écran : très mais alors très bonne année à tout le monde !
WPO développe notamment une plateforme logicielle de référence pour les gestionnaires de sites de production d électricité renouvelable, principalement éolien et solaire. Conçue autour d une stack technologique moderne, elle permet de collecter et d agréger un grand volume de données provenant de plusieurs milliers de sites de production et de sources hétérogènes. Ces données sont ensuite fiabilisées, traitées et restituées à nos utilisateurs sous forme de visualisation ou de modélisation prédictive pour leur permettre de prendre les meilleures décisions d exploitation.
Pour accompagner le succès grandissant de cette plateforme, nous recherchons un Développeur(euse) Web Python / SaaS pour rejoindre une équipe produit qui fonctionne de manière agile et qui dispose d une grande autonomie dans ses décisions quotidiennes.
La mission
Rattaché(e) à l’Engineering Manager et au sein d’une équipe de 6 personnes (Data scientists, Développeurs Backend / mobile, AdminSys), vous vous verrez attribuer les tâches suivantes :
Ecrire et maintenir du code de qualité : python (backend) + frontend (Plotly ou HTMX + AlpinJS + Tailwind CSS) : lint, tests, refactos
Participer à la conception de la plateforme logicielle fullstack de la société en veillant à optimiser la performance, la modularité et la maintenabilité
Surveiller et maintenir les performances et l organisation du code: python, HTML, CSS, Javascript, Robot Framework pour les tests UI
Etre force de proposition concernant la partie UX / UI, les visualisations …
Maintenir une veille technologique pertinente pour les produits de WPO.
Notre stack :
Cloud services : AWS à 90%, quelques services de Microsoft Azure comme la gestion des utilisateurs
CI/CD: Gitlab, Docker, Ansible, Terraform, Unix
Backend: Python 3.8+ / Flask / FastAPI
Frontend: Plotly Dash, HTMX, Alpine.JS / Tailwind CSS ou Bootstrap
by Cédric Krier,orfenor,vmagnin,Ysabeau,dourouc05,Benoît Sibaud,Xavier Teyssier from Linuxfr.org
Le 31 octobre 2022 sortait la version 6.6 de Tryton. Cette version apporte une série de correctifs et d’améliorations et voit l’ajout de dix nouveaux modules dont une consolidation comptable, l’authentification via SAML, le support de contrat cadre pour l’achat et la vente et un système de recommandation de produit basé sur des règle d'association, ainsi que l’ajout de l’ukrainien parmi les langues supportées. Comme d’habitude, la montée de version est prise en charge entièrement (et cette fois-ci sans intervention manuelle).
Tryton est un progiciel de gestion intégré modulaire et multiplateforme. Tryton se concentre sur la stabilité et les modules essentiels de gestion, qui sont très aboutis. Des tierces parties développent des modules spécifiques à certaines activités ou permettant l’intégration à d’autres outils. C’est notamment le cas du projet GNU Health qui s’appuie sur Tryton depuis 2008.
Tryton est utilisable à travers un client desktop, un client web responsive et un client en ligne de commande. Tous ces clients sont légers et multiplateformes (Linux, BSD, Windows et macOS).
Les messages d’erreur de validation générique ont été revus pour fournir plus d’informations à l’utilisateur comme le nom de l’enregistrement et la valeur du champ causant le problème. Ceci devrait permettre à l’utilisateur de corriger son erreur plus facilement.
Délégation de dette
Un assistant permet de déléguer une dette à un tiers. Quand cette dette vient d’une facture, le nouveau bénéficiaire est enregistré sur celle-ci. Il est même possible de le remplir avant de valider la facture pour déléguer directement.
Pays, organisations et régions
Le module country vient maintenant avec deux nouveaux concepts : les organisations et les régions.
Par défaut Tryton crée les organisations les plus fréquemment utilisées comme l’Europe, le Benelux, NAFTA, Mercosur, etc. Notez l’affichage des drapeaux de chaque pays qui est aussi une nouvelle fonctionnalité.
Les régions sont basées sur l'UN M49 qui regroupe les pays par régions géographiques, principalement pour faire du reporting. Les rapports sur les ventes l’utilisent entre autres.
Index
Tryton utilise maintenant une nouvelle syntaxe pour déclarer les besoins d’index. Le mécanisme de mise à jour de la base de données s’assure de créer, mettre à jour ou supprimer les index. En déclarant le besoin uniquement, Tryton peut choisir le meilleur type d’index à créer en fonction des possibilités de la base de données. Il est prévu dans une future version d’avoir en plus une détection d’index redondant.
L’ORM définit par défaut les index dont il a besoin sans intervention du développeur.
Voici l’exemple de la vente qui définit le besoin :
un index pour rechercher « Full-Text » sur le champ reference
un autre sur party (qui contient une clé étrangère) pour les jointures
un index partiel sur state uniquement pour certains états (utilisé pour afficher le nombre de ventes en cours)
Un autre point marquant de cette fin d’année pour le projet est sa migration sur la plateforme Heptapod (une version de GitLab adaptée pour Mercurial).
Le code source réparti dans plusieurs dépôts a été fusionné dans un mono-dépôt (sans réécriture).
Les issues de l'ancien bug tracker ont été migrées sur Heptapod en gardant le même identifiant.
La fondation Tryton a pour but d’aider le développement et de supporter les activités autour du projet. Elle maintient aussi les infrastructures nécessaires au projet (site web, forum, chat, etc.). Elle est gérée par un conseil d’administration dont les membres sont cooptés depuis la communauté. Celui-ci a été renouvelé cette année après les cinq ans maximums de service du précédent conseil.
Auriez-vous des conseils sur l’utilisation de Travis via github, ou bien une autre solution, afin de tester des projets Python sous Windows avant “livraison” ?
Si vous avez besoin de produire des fichiers via des templates, ou patrons, j’ai fabriqué un projet permettant de faciliter l’emploi de jinja2 (qui fait le gros du boulot).
En regardant le code de gaufre.py · main · gopher / gaufre · GitLab, et étant confronté dans un code récent à cette question, je me demande à partir de quel critère il est conseillé de découper un module en sous-modules (longueur, clarification, …).
Pour ma part (pour des raisons pédagogiques, j’ai tendance à faire plein de fonctions donc j’arrive à des codes longs et peu pratiques en maintenance/correction.
Je me demande donc quelles sont les bonnes pratiques en la matière.
A rendre le dimanche 22 janvier 2023 minuit au plus tard
Projet individuel
NB : excepté lorsqu’on se connecte, et se déconnecte, une seule page = aucun rechargement.
C’est totalement différent du projet que vous avez appris/fait en Php cette année.
Comment le rendre
Faites un fichier README.txt et déposez-le ici
Dans le fichier README.txt, précisez :
le sujet choisi
l’adresse de votre site
un nom d’utilisateur
un mot de passe
(et plusieurs nom/mot de passe, s’il y a plusieurs niveaux de droits (administrateur/visiteur etc.))
si vous avez utilisé des librairies spécifiques que je vous ai autorisées, merci de le re-préciser
Sujet
Ce que vous voulez tant que c’est dans le cadre de ce que l’on a vu. Vous avez tout le Web comme inspiration ! N’oubliez pas de me donner le nom et le mot de passe pour se connecter ! Si vous gérez des profils différents (admin / user ou autre), donnez moi les noms et mots de passe de différents profils !
Fonctionnalités obligatoires
Connexion + déconnexion (vu en cours)
Effets jQuery sur les éléments
Appels JSON : au moins deux appels en plus de ceux vus en cours
Sujets possibles
Site de partage de photos
Site de cocktails (cf ci-dessus)
e-rated : site d’appréciations (selon des sujets, à définir)
Ask-a-question : site où l’on pose des questions sur des sujets divers, et des gens répondent
Write-a-book-together : site où l’on se connecte et où on peut écrire un livre à plusieurs
Wedding-couple-site : site où l’on uploade + partage des photos de mariage + livre de commandes
Playing-cards-collection : site où on scanne + échange des cartes (Magic the gathering)
Polls-and-surveys : site de création de sondages (= QCM, exemple très beau ici : quipoquiz)
Poems-generator : faire un cadavre exquis qui génère des poèmes + possibilité pour les utilisateurs de les noter / d’ajouter des mots
The-future-of-post-it : faire un carnet de choses à faire pour les utilisateurs, qui envoie des mails de rappels de ces choses à des dates données
Gift-ideas : un site où l’on va faire des idées de cadeaux / suggérer des idées de cadeaux + les noter (les meilleurs ressortent en premier)
Le-bon-recoin : refaire le bon coin en plus simple
Suggest-crawlers : site de suggestions : on clique sur un mot, il en suggère plein d’autres avec + définitions / liens de sites pour chacuns
Tv-fans : site de présentations + notes d’émissions télé
Faire le jeu SokoBan vu en cours, avec la possibilité de login, enregistrement. Pour les appels JSON supplémentaires, lorsque l’utilisateur choisit un tableau, s’en souvenir (= AJAX) et lorsqu’il se reconnecte, le remettre directement. Puis enregistrer son score lorsqu’il a terminé un niveau + montrer les meilleurs scores.
Pour les sujets qui suivent, ils sont possibles mais plutôt complexes et demandent plus d’investissement. Si vous êtes motivés, demandez-moi plus d’informations, je vous expliquerai les difficultés que vous allez rencontrer.
Turn-by-turn : faire un jeu multijoueurs en tour par tour (jeu de cartes, de poker, ou de plateau etc)
Chat-with-someone : site de chat/discussion
A-maze-ing : site où l’on peut se ballader dans un labyrinthe et essayer d’en trouver la sortie
Sujet imposé si vous n’avez pas d’idée
Cocktails : on se connecte, on a une liste d’éléments (récupérés en JSON) disponibles, on coche ceux qui nous intéressent, on valide, c’est envoyé, et le retour en JSON affiche les cocktails qu’il est possible de faire avec ce que l’on a coché.
Note pour ceux qui connaissent / font / du React : la librairie est autorisée, mais il me faut le code d’origine, et non pas le code minifié / de production.
Interdiction d’utiliser une librairie JavaScript qui ne vienne pas des sites autorisés précédemment
Retard
Après le dimanche 11 avril minuit
Passé ce délai ce sera 1 pt par 2 heures de retard (je prendrai en compte la date de réception du mail).
Pour ceux qui essaient vraiment d’aller jusqu’à la dernière minute, toute heure entamée est comptée comme une heure complète. Exemple : un point en moins si je le reçois le 12 avril à 00:01.
N’oubliez pas de me donner le nom et le mot de passe pour se connecter !
Copier-coller
Copie sur une autre personne (« je se savais pas comment implémenter telle ou telle fonctionnalité dont j’avais besoin pour aller plus loin, je l’ai copiée sur un autre ») :
si la personne est clairement nommée : note pour la fonctionnalité divisée par 2 (uniquement la moitié du travail a été faite) ;
0 aux deux personnes sinon ;
Si je m’aperçois que vous avez bêtement copié collé des sources Internet, je vous convoquerai pour vous demander de m’expliquer la fonctionnalité, et :
si vous ne savez pas m’expliquer le code alors 0 ;
si vous savez m’expliquer tout le code alors votre note totale sera divisée par vous + le nombre de contributeurs à ce projet, ce qui se rapprochera certainement de 0 aussi.
A rendre le dimanche 12 février 2023 minuit au plus tard
Projet individuel
Comment le rendre
Faites un fichier README.txt et déposez-le ici
Dans le fichier README.txt, précisez :
le sujet choisi
l’adresse de votre site
un nom d’utilisateur
un mot de passe
(et plusieurs nom/mot de passe, s’il y a plusieurs niveaux de droits (administrateur/visiteur etc.))
si vous avez utilisé des librairies spécifiques que je vous ai autorisées, merci de le re-préciser
Sujet
Ce que vous voulez tant que c’est dans le cadre de ce que l’on a vu. Vous avez tout le Web comme inspiration ! N’oubliez pas de me donner le nom et le mot de passe pour se connecter ! Si vous gérez des profils différents (admin / user ou autre), donnez moi les noms et mots de passe de différents profils !
Fonctionnalités obligatoires
Nouveaux modèles
Nouvelles relations à mettre en oeuvre : ForeignKey, ManyToMany, OneToOne
Au moins un formulaire
Connexion + déconnexion (vu en cours)
Visualisation de tout dans l’interface d’administration
Sujets possibles
Site de partage de photos
Site de cocktails (cf ci-dessus)
e-rated : site d’appréciations (selon des sujets, à définir)
Ask-a-question : site où l’on pose des questions sur des sujets divers, et des gens répondent
Write-a-book-together : site où l’on se connecte et où on peut écrire un livre à plusieurs
Wedding-couple-site : site où l’on uploade + partage des photos de mariage + livre de commandes
Playing-cards-collection : site où on scanne + échange des cartes (Magic the gathering)
Polls-and-surveys : site de création de sondages (= QCM, exemple très beau ici : quipoquiz)
Poems-generator : faire un cadavre exquis qui génère des poèmes + possibilité pour les utilisateurs de les noter / d’ajouter des mots
The-future-of-post-it : faire un carnet de choses à faire pour les utilisateurs, qui envoie des mails de rappels de ces choses à des dates données
Gift-ideas : un site où l’on va faire des idées de cadeaux / suggérer des idées de cadeaux + les noter (les meilleurs ressortent en premier)
Le-bon-recoin : refaire le bon coin en plus simple
Suggest-crawlers : site de suggestions : on clique sur un mot, il en suggère plein d’autres avec + définitions / liens de sites pour chacuns
Tv-fans : site de présentations + notes d’émissions télé
Faire le jeu SokoBan vu en cours, avec la possibilité de login, enregistrement. Pour les appels JSON supplémentaires, lorsque l’utilisateur choisit un tableau, s’en souvenir (= AJAX) et lorsqu’il se reconnecte, le remettre directement. Puis enregistrer son score lorsqu’il a terminé un niveau + montrer les meilleurs scores.
Pour les sujets qui suivent, ils sont possibles mais plutôt complexes et demandent plus d’investissement. Si vous êtes motivés, demandez-moi plus d’informations, je vous expliquerai les difficultés que vous allez rencontrer.
Turn-by-turn : faire un jeu multijoueurs en tour par tour (jeu de cartes, de poker, ou de plateau etc)
Chat-with-someone : site de chat/discussion
A-maze-ing : site où l’on peut se ballader dans un labyrinthe et essayer d’en trouver la sortie
Sujet imposé si vous n’avez pas d’idée
Cocktails : on se connecte, on a une liste d’éléments (récupérés en JSON) disponibles, on coche ceux qui nous intéressent, on valide, c’est envoyé, et le retour en JSON affiche les cocktails qu’il est possible de faire avec ce que l’on a coché.
Note pour ceux qui connaissent / font / du React : la librairie est autorisée, mais il me faut le code d’origine, et non pas le code minifié / de production.
Interdiction d’utiliser une librairie JavaScript qui ne vienne pas des sites autorisés précédemment
Retard
Après la date et heure limite
Passé ce délai ce sera 1 pt par 2 heures de retard (mon robot qui analyse les mails prend en compte la date de réception du mail, tout est fait automatiquement).
Pour ceux qui essaient vraiment d’aller jusqu’à la dernière minute, toute heure entamée est comptée comme une heure complète.
Exemple : un point en moins si je le reçois un jour après à la minute près, soit date limite plus 00:01 minute.
N’oubliez pas de me donner le nom et le mot de passe pour se connecter !
Copier-coller
Copie sur une autre personne (« je se savais pas comment implémenter telle ou telle fonctionnalité dont j’avais besoin pour aller plus loin, je l’ai copiée sur un autre ») :
si la personne est clairement nommée : note pour la fonctionnalité divisée par 2 (uniquement la moitié du travail a été faite) ;
0 aux deux personnes sinon ;
Si je m’aperçois que vous avez bêtement copié collé des sources Internet, je vous convoquerai pour vous demander de m’expliquer la fonctionnalité, et :
si vous ne savez pas m’expliquer le code alors 0 ;
si vous savez m’expliquer tout le code alors votre note totale sera divisée par vous + le nombre de contributeurs à ce projet, ce qui se rapprochera certainement de 0 aussi.
WeatherForce est une startup toulousaine spécialisée dans la création d’indicateurs prédictifs à destination des entreprises impactées par les aléas météorologiques et climatiques. Nous avons créé et opérons une plateforme technique permettant le traitement massif de données géospatiales. Conçue de façon ouverte, cette plateforme ouvre la voie à une collaboration effective avec les institutions météorologiques locales au bénéfice des entreprises et des populations locales.
Mission
Au sein de notre équipe Technique et Weather & Data Science, votre objectif sera de participer à la construction de modules clés de la plateforme WeatherForce, en lien avec le traitement massif de données. Vous serez chargé.e en particulier de :
Créer et améliorer les approches permettant de traiter les données de façon efficiente
Participer à la construction de la plateforme de traitement de données et à son
déploiement opérationnel
Établir et promouvoir les bonnes pratiques de traitement de données en étroite
collaboration avec nos data scientistes,
Participer à la promotion des bonnes pratiques de programmation en vigueur.
Dans le cadre de nos projets, vous pourrez également être amené à effectuer des missions ponctuelles à l’étranger pour former les usagers à la solution et vérifier « sur le terrain » sonb on fonctionnement.
Profil recherché
Issu(e) d’une formation scientifique et/ou informatique, vous bénéficiez d’une expérience significative en tant que Développeur Python, et dans le traitement de données géospatiales.
Doté de bonnes connaissances système (Linux, Docker, File system, Cloud Storage), Web (protocole HTTP, API RESTful), et de l’écosystème Python scientifique (NumPy, Pandas, Xarray,Dask) vous appréciez travailler avec des méthodes de développement modernes (tests, CI/CD, revues de code) et maîtrisez GIT.
Vous produisez du code clair et structuré, et vous savez être pédagogue !
Vous avez également un intérêt marqué pour les problématiques liées au climat et ses enjeux, ainsi qu’un premier niveau de compréhension des enjeux et contextes de mise à disposition de ces nouveaux services intelligents.
Vous avez une solide expérience en langage de programmation Python et dans l’usage de librairies telles que pandas, numpy, xarray ou Dask pour des applications nécessitant une programmation scientifique.
A l’aise avec l’environnement GNU/Linux/GitLab et l’open source, vous portez un intérêt à la performance de traitement des données, et au suivi de documentation du travail accompli, et vous avez la capacité de résonner en mode Agile.
Vous justifiez également de compétences dans l’usage d’un environnement Jupyter/notebook
de calcul distribué sur le cloud. Vous avez un niveau d’anglais courant aussi bien à l’écrit qu’à l’oral. L’espagnol serait un plus.
Doté(e) de bonnes qualités relationnelles, appréciant le travail en équipe, vous savez
coordonner vos actions et partager l’information avec les autres membres de l’équipe. Vous avez un esprit d’initiative et de synthèse, le sens de l’organisation, et savez travailler en autonomie.
Vous faites preuve de rigueur et respectez les délais pour délivrer une solution opérationnelle correspondant aux besoins des usagers finaux.
Le poste est à pourvoir tout de suite, basé sur Toulouse (centre-ville quartier Esquirol).
Télétravail jusqu’à 2 jours par semaine possible.
Vous souhaitez rejoindre l’équipe ?
Contact
Envoyez-nous votre CV en nous expliquant votre motivation à l’adresse suivante : jobs@weatherforce.org. en précisant en objet de mail “SENIOR PYTHON”.
WeatherForce est une entreprise toulousaine spécialisée dans la création d’indicateurs prédictifs à destination des entreprises impactées par les aléas météorologiques et climatiques.
Nous avons créé et opérons une plateforme technique permettant le traitement massif de données géospatiales. Conçue de façon ouverte, cette plateforme ouvre la voie à une collaboration effective avec les institutions météorologiques locales au bénéfice des entreprises et des populations locales.
Mission
Nous recherchons un expert cloud avec de solides compétences Python pour nous aider dans les domaines suivants :
packaging et CI pour des projets Python orientés data science
maintenance de nos cluster JupyterHub et Dask déployés sur Kubernetes à l’aide d’un outil maison codé en Python
gestion de notre infrastructure Azure avec Terraform
migration vers Kubernetes de services actuellement déployés sur VM avec Ansible
Je suis Romain Clement, un des organisateurs du Meetup Python Grenoble depuis 2019. Nous avons eu vent de ce forum il y a quelques semaines et de la possibilité de poster les annonces de nos événements auprès de la communauté.
Nous organisons notre premier Meetup de l’année le jeudi 26 janvier 2023 à partir de 19h dans les locaux de La Turbine.coop (5 esplanade Andry Farcy, 38000 Grenoble) : " Retour ludique sur l’année pythonique 2022"
Que vous ayez suivi ou non l’actualité autour de l’écosystème Python, venez tester et approfondir vos connaissances avec la communauté grenobloise lors de ce quiz rétrospective !
Un forum / podcast que je fréquente m’a fais réagir et je me suis un peu étalé au sujet de Python.
Il n’est pas nécessaire d’écouter l’épisode du dit podcast, pour lire mon commentaire, si j’ai commis des erreurs ça vous sautera aux yeux tout seul.
Et comme je fini par un coup de pub pour l’AFPy je préfère être relu pour éviter tout malentendu
WeatherForce est une startup toulousaine spécialisée dans la création d'indicateurs prédictifs à destination des entreprises impactées par les aléas météorologiques et climatiques. Nous avons créé et opérons une plateforme technique permettant le traitement massif de données géospatiales. Conçue de façon ouverte, cette plateforme ouvre la voie à une collaboration effective avec les institutions météorologiques locales au bénéfice des entreprises et des populations locales.
Mission
Au sein de notre équipe Technique et Weather & Data Science, votre objectif sera de participer à la construction de modules clés de la plateforme WeatherForce, en lien avec le traitement massif de données. Vous serez chargé.e en particulier de :
1. Créer et améliorer les approches permettant de traiter les données de façon efficiente
2. Participer à la construction de la plateforme de traitement de données et à son
déploiement opérationnel
3. Établir et promouvoir les bonnes pratiques de traitement de données en étroite
collaboration avec nos data scientistes,
4. Participer à la promotion des bonnes pratiques de programmation en vigueur.
Dans le cadre de nos projets, vous pourrez également être amené à effectuer des missions ponctuelles à l'étranger pour former les usagers à la solution et vérifier « sur le terrain » sonb on fonctionnement.
Profil recherché
Issu(e) d’une formation scientifique et/ou informatique, vous bénéficiez d’une expérience significative en tant que Développeur Python, et dans le traitement de données géospatiales.
Doté de bonnes connaissances système (Linux, Docker, File system, Cloud Storage), Web (protocole HTTP, API RESTful), et de l’écosystème Python scientifique (NumPy, Pandas, Xarray,Dask) vous appréciez travailler avec des méthodes de développement modernes (tests, CI/CD, revues de code) et maîtrisez GIT.
Vous produisez du code clair et structuré, et vous savez être pédagogue !
Vous avez également un intérêt marqué pour les problématiques liées au climat et ses enjeux, ainsi qu’un premier niveau de compréhension des enjeux et contextes de mise à disposition de ces nouveaux services intelligents.
Vous avez une solide expérience en langage de programmation Python et dans l'usage de librairies telles que pandas, numpy, xarray ou Dask pour des applications nécessitant une programmation scientifique.
A l'aise avec l'environnement GNU/Linux/GitLab et l'open source, vous portez un intérêt à la performance de traitement des données, et au suivi de documentation du travail accompli, et vous avez la capacité de résonner en mode Agile.
Vous justifiez également de compétences dans l’usage d’un environnement Jupyter/notebook
de calcul distribué sur le cloud. Vous avez un niveau d'anglais courant aussi bien à l'écrit qu'à l'oral. L'espagnol serait un plus.
Doté(e) de bonnes qualités relationnelles, appréciant le travail en équipe, vous savez
coordonner vos actions et partager l'information avec les autres membres de l’équipe. Vous avez un esprit d’initiative et de synthèse, le sens de l’organisation, et savez travailler en autonomie.
Vous faites preuve de rigueur et respectez les délais pour délivrer une solution opérationnelle correspondant aux besoins des usagers finaux.
Le poste est à pourvoir tout de suite, basé sur Toulouse (centre-ville quartier Esquirol).
Télétravail jusqu'à 2 jours par semaine possible.
Vous souhaitez rejoindre l’équipe ?
Contact
Envoyez-nous votre CV en nous expliquant votre motivation à l’adresse suivante : jobs@weatherforce.org. en précisant en objet de mail "SENIOR PYTHON".
Python, comme de nombreux autres langages ainsi que des implémentations matérielles, suit la norme IEEE 754 pour manipuler les nombres à virgule (le type float en Python). Cette norme définit les tailles possibles de mémoire allouée pour contenir le nombre. La taille étant fixe, certains nombres ne sont pas représentables et la valeur enregistrée peut être légèrement erronée.
Cette situation n’est donc pas spécifique à Python. L’écart entre la valeur saisie et la valeur en mémoire est visible avec un interpréteur Python :
Ce type d’erreur ne se rencontre pas uniquement dans les domaines spatial ou scientifique. Par exemple, des calculs de TVA et TTC peuvent produire des erreurs visibles pour l’utilisateur.
Pour éviter ces erreurs, il est possible d’utiliser la bibliothèque decimal incluse dans la bibliothèque standard :
Un autre moyen est de faire des calculs en n’utilisant que des entiers et faire des conversions au dernier moment. Dans le cas de la TVA, cela signifie de ne travailler qu’en centimes et de ne convertir en euro que lors de l’affichage à l’utilisateur (avec l’arrondi adapté, limité à deux décimales).
La société Alexandria recherche un.e développeur.euse python / Django pour renforcer son équipe informatique.
La société
Alexandria est un groupe spécialisé dans le e-commerce sur les marketplaces, présent dans sept pays.
Nous exerçons cette activité depuis maintenant 9 ans. Nos locaux se trouvent à quelques minutes à pied du métro Flachet (Villeurbanne).
L’équipe informatique est composée de 5 personnes confirmées et expérimentées.
Les missions
Vos missions seront multiples :
Assurer le développement et l’intégration de nouvelles marketplaces dans le système existant
Développer et améliorer des fonctionnalités de notre applicatif (Django) pour les différents pôles de la société
Optimiser les performances et les méthodes de calcul de prix de notre système
Prise en main de notre base de données Postgres
Les méthodes
Nous prenons à coeur d’utiliser la méthode “Test Driven Developpment” afin de garantir au mieux la pérennité et la qualité du code.
Nous utilisons les outils de développement opensource communs à la plupart des projets actuels comme git, docker, jenkins
Les postes de travail tournent sous linux et vous pourrez profiter de l’expérience de l’équipe pour apprendre à utiliser vim par exemple.
Le poste
Les débutant⋅e⋅s sont accepté⋅e⋅s
Contrat à durée indeterminée, salaire 45-55k brut annuel
Télétravail 4 jours par semaine possible
Pour toute question, n’hésitez pas à nous contacter par mail dev@abc-culture.fr
Bonjour le monde !
J'ai un petit problème très pythonesque à vous soumettre aujourd'hui.
J'ai codé un petit script qui me génère toutes les situations « gagnantes » au jeu de Marienbad.
Il génère des combinaisons de tas de jetons, et teste si elles sont gagnantes, et les montre à l'écran si oui.
Pour la génération des combinaisons, j'utilise itertools avec la fonction combinations_with_replacement().
Seulement, quand on commence à passer à des générations avec une quinzaine de tas pouvant aller jusqu'à 20 jetons, le nombre de combinaisons générées explose et remplit mes 4 Go de RAM avant de se faire tuer par l'OS.
Pour résoudre ce problème, il faudrait pouvoir tester les combinaisons au fur et à mesure qu'elles sont générées par itertools, et non pas quand il a fini de générer une fournée de combinaisons.
Quelqu'un aurait-il une idée sur la façon de procéder, sachant que le module itertools est écrit en C, mais il existe une version python dans les libs de Pypy ?
Bonjour le monde !
J'ai un petit problème très pythonesque à vous soumettre aujourd'hui.
J'ai codé un petit script qui me génère toutes les situations « gagnantes » au jeu de Marienbad.
Il génère des combinaisons de tas de jetons, et teste si elles sont gagnantes, et les montre à l'écran si oui.
Pour la génération des combinaisons, j'utilise itertools avec la fonction combinations_with_replacement().
Seulement, quand on commence à passer à des générations avec une quinzaine de tas pouvant aller jusqu'à 20 jetons, le nombre de combinaisons générées explose et remplit mes 4 Go de RAM avant de se faire tuer par l'OS.
Pour résoudre ce problème, il faudrait pouvoir tester les combinaisons au fur et à mesure qu'elles sont générées par itertools, et non pas quand il a fini de générer une fournée de combinaisons.
Quelqu'un aurait-il une idée sur la façon de procéder, sachant que le module itertools est écrit en C, mais il existe une version python dans les libs de Pypy ?
Ho! Ho! Ho! En cette période de fête, je déballe un cadeau avec l’ouverture d’un poste de Développement python dans le domaine du storage.
L’équipe est à Montreal, Lyon, Rennes, Nantes, Bordeaux, Toulouse, Roubaix et ouvert au télétravail partiel (3jours par semaine)… Nous aimons les blagues carambar, partager nos recettes de cuisine, bosser dans l’opensource, manipuler des pools zfs! Bref, nous bossons dans le stockage de données, une des pierres angulaires de toute infrastructure et pour avancer nous recherchons une personne qui comprend le perl, parle le python et si possible le go.
Tu as envie de nous rejoindre? Tu peux me contacter!
J'ai eu l'occasion de développer un petit logiciel open-source pour mon travail, donc j'en profite pour partager ici.
Motivation
Sur les grappes de calculs (clusters) dédiés à l'intelligence artificielle, il y a un problème assez récurrent lié au stockage et à l'accès aux données.
Dans ces installations, on trouve généralement d'un côté une baie de stockage avec des jeux de données composés de millions de petits fichiers, et de l'autre côté les nœuds de calcul qui lisent ces fichiers.
La baie est montée sur tous les noeuds (ex: nfs, gpfs, lustre, etc.).
Quelques ordres de grandeurs et précisions :
Une expérience (un job) travaille pendant quelques jours, et sur un jeu de données à la fois.
Plusieurs expériences de différents utilisateurs peuvent se partager un nœud de calcul (c'est très bien géré par slurm avec des cgroups).
Les fichiers sont assez petits (entre 100ko et 10mo), chaque jeu de données pèse entre une centaine de giga et un téra.
Les fichiers sont lus aléatoirement, autour d'une centaine de fois chacun.
En termes de stockage, ces millions de fichiers sont déjà un problème en soi pour le système de fichier.
Pour la charge de travail, les centres de calculs adoptent plusieurs politiques avec leurs avantages et inconvénients :
Option 1: Obliger les utilisateurs à copier les données sur un disque local du nœud au début de l'expérience, puis à nettoyer à la fin. L'ennui, c'est qu'il faut répéter l'opération à chaque expérience, hors elles peuvent s’enchaîner assez fréquemment en phase de mise au point d'un modèle. D'autre part, si l'expérience plante, le nettoyage des fichiers n'est pas garanti. Enfin, différentes expériences sur un même nœud ne partagent pas le cache, on pourrait donc se retrouver avec le même jeu de données en doublon.
Option 2: Opter pour une solution de mise en cache matérielle ou logicielle, ce qui est coûteux mais transparent pour l'utilisateur.
Option 3: Imposer l'utilisation d'une base de données spécifiquement étudiée pour ce type d'usage (ex: S3 avec minio), ce qui oblige les utilisateurs à modifier leur code de chargement des données et à convertir les données.
Approche
Pour scratch_manager, la liste des objectifs était donc la suivante :
Regrouper les fichiers dans des archives pour que le nombre de fichiers sur la baie reste faible.
Garder un accès aux données via une API de filesystem posix.
Pas de délai pour démarrer une expérience.
Mise en cache transparente pour l'utilisateur.
Mutualiser le cache entre les expériences et aussi entre les utilisateurs.
Pour 1 et 2, l'astuce consiste à utiliser des images disques qui rassemblent les fichiers d'un jeu de données. J'ai opté pour squashfs mais de l'ext4 en lecture seule fonctionnerait aussi.
Pour 3, on monte les images stockées sur la baie afin que le contenu soit immédiatement accessibles. Bien sûr, toutes les lectures occasionnent alors de la charge de travail sur la baie de stockage.
Pour 4, on utilise un démon qui copie les images localement sur les nœuds et les monte par-dessus le premier montage. Linux gère ça très bien à chaud même s'il y a des fichiers ouverts. Après ça, les nouveaux accès pointent vers les disques locaux.
5 est résolu par le fait qu'un démon système gère ça pour tout le monde.
Voilà la nimage qui récapitule le bazar :
Détails d'implémentation
Mesure du traffic: Du fait que l'on travaille avec des images disques, le débit sur chaque jeu de donnée est accessible en consultant /proc/diskstats. Il faut juste faire le lien entre les /dev/loop* et les images.
Allocation du cache: L'optimisation des images à mettre en cache est un problème de Knapsack, j'ai honteusement copié-collé le code qui résout ça.
Démontage et suppression des images: Pour appeler umount, il faut penser à passer le flag --lazy pour attendre la fermeture des fichiers encore ouvert. Étonnamment, la suppression d'une image montée ne pose pas de problème, le fichier disparaît quand on fait un ls, mais subsiste en fait jusqu'au démontage.
Comme proposé ce soir à la réunion mensuelle du comité directeur, il serait sympathique et utile d’avoir une petite affiche (A4) pour présenter l’association. On pourrait l’afficher lors d’événements externes (JDLL à Lyon, FOSDEM à Brussels …) ou la laisser pour des club informatiques d’écoles, dans des fablab-hacklab, donc plus viser des personnes étudiantes ou novices/curieuses.
On pourrait indiquer
les outils sociaux mis à disposition (discuss, discord, irc)
le projet d’apprentissage et perfectionnement Hackinscience
l’annuaire d’offre d’emploi
le Gitea pour l’hébergement
le planet pour l’actualité (si il existe encore)
et la PyconFR
Donc ça serait une liste de liens, je sais pas quel design sympa on pourrait lui donner.
On pourrait aussi mettre un QR-Code en plus du lien (le lien textuel reste indispensable pour les gens avec un ordinateur).
Voila si jamais vous avez des idées de style d’affiche, ou de contenu à ajouter, n’hésitez pas
Et je notifie l’équipe de communication: @Melcore@Merwyn (si je ne me trompe pas)
Bonsoir,
Je souhaite tester, avec #pytest, des fonctions/méthodes d’un programme #python qui se connecte à un service (Mastodon ou Yunohost par exemple). Peut-on simuler facilement la connexion à ce service pour se concentrer sur les tests internes à mes fonctions/méthodes ?
En simulant la connexion j’espère m’affranchir d’une connexion réelle et donc :
pas de risques de mettre le bazar sur un compte réel
intégration des tests pytest plus facile dans la CI (gitlab dans mon cas)
Je ne sais pas trop par où commencer ma recherche… donc je suis preneur de pistes.
Merci.
Cela fait des années que j’utilise des awesome-xxx pour trouver de bonnes bibliothèques à tester. Malheureusement, je n’en trouve jamais en français. Je tombe parfois sur des articles en français du style “TOP 10 des bibliothèques python”, qui sont souvent des redites, et qui sont aussi souvent traduit de l’anglais.
Donc je voulais amener ces awesome en francophonie, avec le concept assez mal nommé d’Excellent-Python.
J’ai pensé à quelques catégories, notamment avec les bibliothèques que je trouve pas mal.
J’accepte les contributions sous ce poste
Je pense que ce qui est utile d’avoir :
Le nom de la bibliothèque,
une courte description en français (1phrase d’accroche),
le lien vers la documentation officiel (si possible en français),
[opt] un lien vers un article/tuto qui montre son utilisation si existant et si pas déjà dans la docs.
Début de la liste :
Moissonnage du Web :
Beautiful Soup Extraction de données provenant de fichier HTML ou XML
Hello, happy taxpayers!
Pycon cette année, grande nouvelle! On est restés combien de temps sans?
Mais je ne vois nulle part de discussion sur les confs, ni sur les sprints: ni sur le site pycon.fr, ni dans ce forum. ça se discute “en privé”, entre membres du CA et auteurs de propositions de conf?
Ou j’ai raté quelque chose?
Bonjour, je suis à la recherche d’un module Python (ou une solution facilement pilotable par du code Python) pour implémenter une “grille” de calcul qui lance et gère des sous-processus pour exécuter des routines.
J’ai besoin de :
lancer des sous-processus qui exécutent un module Python ;
pouvoir leur envoyer des messages, même sur une machine distante (à la mode multiprocessing.Manager). Je recherche plus qu’un pool de processus, j’ai besoin de lancer des exécuteurs qui acceptent des tâches les unes après les autres sans être tués entre deux tâches (sauf si ladite tâche prend trop de temps ou rencontre un problème lors de son exécution) ;
gérer les cas d’erreurs : le code Python à exécuter est assez complexe, il va charger et exécuter des bibliothèques déjà compilées (qui sont susceptibles de planter) qui vont elle-mêmes ré-appeler du la C-API de Python (et même recharger la libpython dans certains cas). J’ai aussi besoin de récupérer les informations d’erreurs (pile d’appel Python ou vidage mémoire) en cas de problème et de décider de relancer ou non l’exécuteur.
pouvoir associer des ressources à chaque exécuteur (concrètement contrôler le nombre d’exécuteurs qui accèdent en même temps à un périphérique) ;
et bien entendu journaliser correctement le tout.
Idéalement j’aimerais aussi:
une solution pensée avec le paradigme de fils d’exécution plutôt que coroutines (c.-à-d. philosophie threading plutôt que concurrent.futures) ;
pouvoir partager de mémoire vive entre les exécuteurs (comme multiprocessing.shared_memory).
Toutes ces fonctionnalités sont couvertes par le module multiprocessing.
Il marche à merveille mais j’ai le sentiment de faire un peu trop de choses un peu trop bas-niveau à la main : lancer des processus, ouvrir des tubes de communication, envoyer-récupérer des signaux d’interruption, gérer les plantages du code fonctionnel etc.
Avez-vous une alternative à conseiller ?
J’ai regardé du côté de loky mais ça ne me semble pas assez puissant (notamment sur la gestion d’erreurs).
Bonjour, je suis à la recherche d’un module Python (ou une solution facilement pilotable par du code Python) pour implémenter une “grille” de calcul qui lance et gère des sous-processus pour exécuter des routines.
J’ai besoin de :
lancer des sous-processus qui exécutent un module Python ;
pouvoir leur envoyer des messages, même sur une machine distante (à la mode multiprocessing.Manager). Je recherche plus qu’un pool de processus, j’ai besoin de lancer des exécuteurs qui acceptent des tâches les unes après les autres sans être tués entre deux tâches (sauf si ladite tâche prend trop de temps ou rencontre un problème lors de son exécution) ;
gérer les cas d’erreurs : le code Python à exécuter est assez complexe, il va charger et exécuter des bibliothèques déjà compilées (qui sont susceptibles de planter) qui vont elle-mêmes ré-appeler du la C-API de Python (et même recharger la libpython dans certains cas). J’ai aussi besoin de récupérer les informations d’erreurs (pile d’appel Python ou vidage mémoire) en cas de problème et de décider de relancer ou non l’exécuteur.
pouvoir associer des ressources à chaque exécuteur (concrètement contrôler le nombre d’exécuteurs qui accèdent en même temps à un périphérique) ;
et bien entendu journaliser correctement le tout.
Idéalement j’aimerais aussi:
une solution pensée avec le paradigme de fils d’exécution plutôt que coroutines (c.-à-d. philosophie threading plutôt que concurrent.futures) ;
pouvoir partager de mémoire vive entre les exécuteurs (comme multiprocessing.shared_memory).
Toutes ces fonctionnalités sont couvertes par le module multiprocessing.
Il marche à merveille mais j’ai le sentiment de faire un peu trop de choses un peu trop bas-niveau à la main : lancer des processus, ouvrir des tubes de communication, envoyer-récupérer des signaux d’interruption, gérer les plantages du code fonctionnel etc.
Avez-vous une alternative à conseiller ?
J’ai regardé du côté de loky mais ça ne me semble pas assez puissant (notamment sur la gestion d’erreurs).
Salut,
j’ai créé un micro-module pour récupérer les données écowatt.
C’est disponible ici Thierry Pellé / pycowatt · GitLab,
probablement très sale (je suis encore un oeuf dans le monde du serpent et de git),
mais ça fonctionne a minima.
Tout conseil/critique est bienvenue si vous avez des idées de Grands Serpents
Pour clôturer cette année 2022, le meetup de décembre a lieu le jeudi 15 décembre à Hiptown (à la Part-Dieu). Au programme : la programmation tchou-tchou !
Bonjour la Communauté,
Je recherche pour Absys un(e) Développeur(euse) Back End Python passionné.
Bac +3 mini en développement informatique et expérience de 2 ans mini.
Notre proposition :
des projets qui font chauffer les neurones
en full télétravail ou alternance avec présentiel
35h en 5 jours ou 4,5 ou …
salaire entre 30 et 38 K€ + accord d’intéressement + titres restaurant
formation en interne au sein de l’équipe et en externe par des pros de chez pros + participation à Europython et autres grands messe de communauté de dev.
Bref, une PME différente : une ambiance sereine, du temps pour mener à bien les projets, de la solidarité entre dev, un projet RSE de forêt nourrissière …
Tu veux plus d’infos ou candidater, c’est par ici Dev Info Back End ((H/F)
A+
Michelle
Quel développeur ou administrateur système n'a pas connu un moment où un client appelle et explique que son application en ligne ne fonctionne pas correctement, alors que quand vous vous y rendez, tout fonctionne bien ? Vous constatez que les pages répondent correctement, dans un délai acceptable, que le serveur n'est pas surchargé, mais vous remarquez dans l'historique que le code a été changé récemment. Vous vous rendez sur la page qui charge la fonctionnalité qui, au dire du client, ne fonctionne pas correctement: il s'agit d'un formulaire d'authentification (mais pourtant vous avez essayé, et vous avez réussi à vous authentifier). Vous savez qu'un essai n'est pas un test, qu'un test effectue des mesures qu'avec votre essai vous ne pouvez pas réaliser, autrement qu'avec vos yeux et le débogueur du navigateur. Dans le cas de notre application, il faut savoir qu'elle tournait en production dans un environnement "haute disponibilité", c’est-à-dire que le serveur en front est redondé sur une autre machine, et qu'un équilibreur de charge s'occupe de la répartition du trafic. Nous avions remarqué qu'une portion de code avait été modifiée, et en y regardant de plus près, ce code contenait un bug qui n'était présent que sur l'un des frontaux. Ainsi, parfois l'erreur se produisait, et parfois non. Les tests de bout en bout (E2E tests) seraient parvenus à déceler l'erreur: dans le cas d'une architecture haute dispo, les 2 frontaux doivent être testés indépendamment l'un de l'autre. Les tests ne doivent pas passer par le loadbalancer, mais par les urls des frontaux directement. Pour un humain, c'est une tâche rébarbative que de jouer un document de recette sur chacun des frontaux, mais pas pour un script. Et c'est encore mieux si ce script est lancé automatiquement, idéalement après chaque commit qui a un impact sur le fonctionnement de l'application. Les tests fonctionnels permettent de tester toute la pile système, et il vaut donc mieux les lancer dans un environnement qui reproduit la production (le staging) mais aussi en production (utile dans le cas évoqué dans cet artice). Il existe de nombreux outils bien connus tels que Selenium pour automatiser des tests (lire notre article sur les tests avec browserless), mais pour cet exemple, nous allons prendre 2 autres librairies Puppeteer et Playwright (qui a le vent en poupe et semble prendre la suite de Puppeteer). Ces frameworks de tests fonctionnels permettent de tester le rendu d'une page web dans des conditions réelles, proches de celles d'un utlisateur. Ceci permet de contrôler que des éléments sont correctement affichés, de cliquer sur un lien ou un bouton, voir même dans une zone de l'écran ou sur un pixel précis. Cela permet égualement de remplir un formulaire, le poster ou encore de remplir le panier d'un site ecommerce. Ces outils permettent d'analyser le rendu de la page web tant coté backend (serveur) que frontend (navigateur). Il est ainsi tout a fait possible de tester aussi bien des applications PHP/Python/Ruby/Node que des applications Javascript utilisant des frameworks tels que React et VueJs, pour ne citer qu'eux. Pour notre cas d'usage, les tests doivent s'exécuter dans le cadre d'une chaîne d'intégration continue (CI), mise en place sur runner Gitlab qui instancie un shell. Nous aurons besoin de Docker afin de construire l'image de l'instance NodeJS qui va éxecuter Puppeteer ou Playwright. Dans les 2 cas, notre CI va jouer un scénario écrit en Javascript, orchestré par la librairie Jest vers un environnement de staging. Les tests fonctionnels doivent être bloquants afin que la CI s'arrête en cas d'erreur, avant de déployer l'application en production. Puppeteer: L'écriture du test avec Puppeteer prévoit l'utilisation d'un navigateur headless: nous allons utiliser l'image officielle Docker de Browserless. Le scénario est simple, nous allons créer le fichier browser.test.js et écrire le test qui vérifie que dans la page du site https://bearstech.com, on trouve bien le mot "Bearstech": describe("TESTING", () => { beforeAll(async () => { if (!process.env.URL) { throw "ENV key URL is missing"; }
it('should display "Bearstech" text on page', async () => { await expect(page).toMatch("Bearstech"); }); });
Ensuite, pour créer l'image qui va instancier Puppeteer, nous aurons besoin de l'installer (avec Jest) à partir du package.json: { "name": "functionnal-tests", "version": "1.0.0", "license": "MIT", "scripts": { "test": "jest" }, "devDependencies": { "jest": "^27.5.1", "jest-html-reporter": "^3.4.2", "jest-puppeteer": "^6.1.0", "puppeteer": "^13.5.1" } }
Au même endroit, il nous faudra aussi:
le fichier jest-puppeteer.config.js qui sert à définir les paramètres de connexion au navigateur headless de Browserless le fichier jest.config.js
Vous mettez ces 4 fichiers dans un répertoire "tests". Ensuite, il vous reste à écrire le Dockerfile qui doit charger une image NodeJS et copier notre dossier "tests" dans l'image. La commande à ajouter dans le Dockerfile est celle qui sera lancée par le conteneur pour exécuter le scénario: CMD ["yarn", "test"] Pour plus de détail sur la réalisation de ce test, rendez-vous sur la documentation de notre Workflow DevOps Playwright C'est un nouveau framework dédié aux tests fonctionnels, maintenu par Microsoft, et qui prend en charge par défaut 3 navigateurs headless: Chromium, Firefox, et WebKit ainsi que plusieurs langages pour écrire les tests: python, node, java et .NET. Playwright propose ses propre images Docker officielles, mais comme chez Bearstech on aime bien comprendre ce que l'on fait, il nous semble plus efficace d'en créer une qui installe juste ce qu'il nous faut. Jest a sorti un package encore en développement pour piloter playwright. Bien qu'il soit recommandé d'utiliser le "Playwright test-runner" depuis la page github du projet, on prend le risque d'utiliser Jest. Mais pas moyen d'utiliser un autre navigateur headless que ceux qui sont embarqués dans le framework. Les navigateurs sont patchés pour, d'après Playwright, mieux les piloter (ah Microsoft qui adore enfermer ses utilisateurs ...) Notre scénario sera similaire au précédent, en ajoutant un test sur le click d'un bouton (il vaut mieux préciser ici un timeout à Jest):
[x] example.test.js
// Needs to be higher than the default Playwright timeout jest.setTimeout(40 * 1000)
describe("Bearstech.com", () => { it("should have the text like 'Infogérance' in the h1", async () => { const url = process.env.URL; await page.goto(url); await expect(page).toHaveText("h1", "Infogérance") }) it("should navigate to contact once you click on 'lancer votre projet'", async () => { const elements = await page.$$('a.button'); await elements[0].click(); expect(page.url()).toMatch(/contact/) }) })
Ces 4 fichiers doivent être placés dans un répertoire "tests".
Reste ensuite à écrire notre Dockerfile NodeJS, qui doit procéder à l'installation de Playwright et de Jest, puis indiquer au conteneur quelle commande exécuter à son instanciation: FROM bearstech/node-dev:16
RUN mkdir /tests COPY tests/ /tests/ WORKDIR /tests
RUN npm install jest jest-playwright-preset playwright-chromium RUN npx playwright install RUN npx playwright install-deps
CMD ["npm", "run", "test"]
Attention, le build est assez long (l'image a une taille de 2Go au final) à cause du navigateur headless. Au final, il ne reste plus qu'à builder puis à lancer le conteneur: docker run --rm -it -e URL="https://bearstech.com" --workdir /tests testplaywright:latest
Conclusion Les tests fonctionnels peuvent vous sauver la mise et vous faire gagner du temps en prouvant la stabilité et en assurant la non régression d'une application. Pour les projets en cours de développement ou les projets matures, les tests font partie du cycle d'exploitation d'une application. Il faut pouvoir se doter d'outils qui permettent de prouver et tracer l'état dans lequel elle se trouve à chaque instant. Chez Bearstech, nous administrons des applications depuis 15 ans, et nous avons mis au point un workflow qui vous permettra d'intégrer vos tests facilement, et accompagnés d'experts qui vous guideront dans la mise en place de ces outils. N'hésitez pas à revenir vers nous pour obtenir un avis d'expert sur la performance de vos applications, l'infogérance de vos serveurs, ou juste pour de l'aide pour la réalisation de ce guide :smile:
SEOQuantum, l’entreprise dans laquelle je bosse, cherche un développeur Python orienté data/nlp ou dev logiciel. Au moins 2ans d’expérience, autonome, et à l’aise en python.
TKT est une jeune agence digitale, experte en conception et développement d’applications web, mobile et software avec des enjeux métier complexes.
Nous accompagnons nos clients en France et à l’international, des starts-up aux grandes entreprises, pour créer leurs projets numériques sur mesure (Orange, Spie Batignolles, Allianz Trade, …)
Notre équipe trouve son identité dans une combinaison équilibrée de profils mixtes et cosmopolites, tous basés dans nos bureaux à Paris.
Le poste
Pour un de nos clients, éditeur de logiciel, nous recherchons un(e) développeur(euse) Python (framework Django), capable d’appréhender et de développer des projets de grande envergure sur du long terme.
Le client est basé à Amiens, aussi quelques déplacements ( pris en charge par TKT) seront à prévoir en début de mission, afin de se familiariser avec l’équipe et le produit.
Vous participerez au développement d’un ERP et pourrez vous former ou parfaire vos connaissances sur les dernières technologies.
Nous cherchons des profils avec :
4-5 années d’expérience en développement web et/ou mobile et/ou software
Une forte envie de progresser et d’apprendre
Un besoin de partager et de faire progresser les autres
Une bonne appréciation de l’écosystème d’un projet technique contemporain (backend, architecture des données, protocoles, frameworks, expérience utilisateur…)
Rémunération: 45-55k ( selon profil )
2 jours de TT/ semaine
Profil recherché
Nous recherchons des développeurs(euses) web backend Python/Django avec quelques années d’expérience, ayant l’envie de travailler en équipe et de partager son expérience et son savoir.
À connaître :
Python / Django
Mécanismes du web et culture générale technique
Connaissance appréciée :
Django rest framework
ElasticSearch
AWS et techniques devops ( par exemple Terraform)
La connaissance d’un framework frontend comme Angular 2 ou React, ou une envie d’apprendre sur ce type de framework, serait un plus.
J’ai testé un peu de codage en Python avec PyCharms et un tutoriel en ligne mais au-delà du langage lui-même, je suis totalement dans la confusion sur le choix d’une configuration Windows adéquate pour le développement. Je ne saisis pas bien la différence entre environnement, environnement virtuel, IDE, gestionnaire de paquets et surtout comment tous ces éléments s’articulent. Je vois passer les noms Conda, Anadonca, Miniconda, VSStudio, PyCharms, notebooks, et au plus je lis à ce propos au plus c’est la confusion, d’autant que pas mal d’articles sont implicites sur l’OS utilisé.
Tout ce bazar avant même d’avoir écrit la moindre ligne de code me décourage.
Je précise que je ne suis absolument pas professionnel du développement. J’ai quelques bases en C, Javascript et j’ai fait un peu de Python au travers du logiciel de modélisation 3D CadQuery. Je suis maintenant intéressé par Python essentiellement afin de pouvoir utiliser des outils d’intelligence artificielle dans le domaine du son mais je sais à peine utiliser git.
Avez-vous des conseils à me donner afin d’avoir un environnement de développement stable, ouvert et évolutif, et dont je puisse comprendre comment il est organisé?
J’ai créé un serious game qui permet la découverte de la programmation procédurale et du langage Python. Je suis enseignant et je l’utilise avec mes élèves (lycée).
Avec un microcontrôleur (micro:bit,…) via le port série, Ropy peut devenir le jumeau numérique d’un robot réel.
Le projet est open source et utilise l’environnement open source Blender + UPBGE + Python.
Bonjour,
Je souhaite trouver un exemple (qui marche) de création d’un deb à partir d’un programme python3 sur une debian/ubuntu récente.
J’ai essayé déjà plusieurs tutoriels, mais même pour un simple hello world aucun n’a fonctionné.
Je ne souhaite pas pour l’instant étudier la doc de debian sur la création d’un deb, je cherche juste, un exemple minimal (avec une lib importée) ou le code source, de la construction du deb que je pourrais m’approprier comme un singe savant.
Merci
by Melcore,Ysabeau,Xavier Teyssier,palm123 from Linuxfr.org
Quatre journées consacrées au langage Python, la PyConFr revient après deux ans d’absence pour proposer des Sprints, où l’on se retrouve à l’Université de Bordeaux pour coder ensemble le jeudi et vendredi, et des conférences le week-end afin de découvrir les expériences de chacun avec le langage Python.
L’accès est gratuit, ouvert à toutes et tous, cependant l’inscription préalable est nécessaire.
Durant le week-end, vous aurez l’occasion de participer à des présentations sur des sujets variés, autour du langage Python, de ses usages, des bonnes pratiques, des retours d’expériences, des partages d’idées…
Codage participatif « Sprints » (jeudi et vendredi)
Les développeurs et développeuses de différents projets open source se rejoignent pour coder ensemble. Chaque personne est la bienvenue pour contribuer, et nous cherchons également à accompagner les débutant·e·s.
Restauration sur place
Des food trucks seront à disposition.
Proposer une conférence ou un atelier
Même un débutant ou une débutante a quelque chose à raconter, alors venez proposer votre conférence sur le site de l’appel à participation.
Exposition organisé·e par l’Afpy l’Université Bordeaux-Talence
Conférence annuelle des pythonistes francophones 🐍 🇫🇷
https://pycon.fr/2023/
Du jeudi 16 février au dimanche 19 février 2023
Ce wiki de communication, permet de rappeler tous les endroits où l’asso peut communiquer. Vous pouvez ajouter si vous pensez à des endroits auquel on a pas encore pensé.
qui peut prendre plusieurs minutes pour fournir un résultat. J'aimerais afficher une petite barre de progression dans la console pour indiquer que le script est pas planté.
La question est de savoir si c'est possible en laissant la ligne en l'état (et si oui comment), ou si je vais devoir forcément décomposer dans une boucle for.
Bonjour,
j’espère ne pas déclencher une polémique stérile, mais il me semble que la formulation de la phrase
Pour améliorer la diversité, l’AFPy propose d’aider les femmes à trouver un sujet, à rédiger la proposition de conférence, à rédiger le support de conférence, puis à répéter. Contactez diversite@afpy.org si vous êtes intéressées.
est maladroite, faisant passer l’exact inverse du message qu’elle souhaite faire passer.
Pourquoi ne pas mettre simplement
L’AFPy, reconnaissant la capacité de tous les profils à contribuer à son projet, encourage chacune et chacun à proposer une conférence ou un atelier. Pour plus de renseignements, contactez diversite@afpy.org.
ou quelque chose dans le genre.
Quant à la phrase
Le temps des volontaires étant limité, nous ne pourrons aider qu’un nombre limité de candidates.
Bonjour et félicitation pour ce boulot!
Je n’ai malheureusement pas trop de temps à consacrer à la traduction ces derniers temps
Ma question porte sur l’usage de cette nouvelle forge : est-elle destinée à héberger uniquement les projets de l’Afpy et de ses membre ou est-elle ouverte à tout projet aussi petit soit-il (pour peu qu’il soit écrit en python bien sûr) ?
Les inscriptions pour la PyConFr23 sont maintenant ouvertes !
Vous pouvez d’ores et déjà indiquez votre présence à la PyConFR23, qui aura lieu à Bordeaux du 16 au 19 février 2023.
L’inscription est gratuite !
La soirée dinatoire du samedi soir est proposé à 30€ et le t-shirt PyConFr23 à 10€.
Organisation de l’évènement
Le jeudi et vendredi, place aux Sprints
Les développeurs et développeuses de différents projets open source se rejoignent pour coder ensemble. Chaque personne est la bienvenue pour contribuer, et nous cherchons également à accompagner les débutant·e·s .
Durant le week-end c’est Conférences
Vous aurez l’occasion de participer à des présentations sur des sujets variés, autour du langage Python , de ses usages, des bonnes pratiques, des retours d’expériences, des partages d’idées…
Vous voulez proposer une conférence, sprint ou juste nous aider à l’organisation, inscrivez-vous sur l’ appel à participation.
Dessous le code qui fonctionne à peu près si on affiche l’item actif de tout menu, mais si je fais vocaliser le label ( avec ‘espeak’) alors je constate une mise à jour très ralentie du nouvel item focussé (après appui sur une flèche).
Si vous n’avez donc pas ‘espeak’ installé, vous ne devriez pas pouvoir m’aider.
Mais en général, l’appel à une routine du système avec ‘os.system()’ est-il très lent ?
Existe-t-il une alternative ?
#!/usr/bin/python3.8
"""
Définition d'une fenêtre comportant une barre de menus dont tous les items sont vocalisés
"""
from tkinter import *
import os
# Dictionnaire pour la définition des menus
items = {
'Fichier':
[
['Nouveau','cmd1'],
['Ouvrir','cmd2'],
['Imprimer','cmd3'],
['Quitter','cmd4']
],
'Edition':
[
['Copier','cmd1'],
['Coller','cmd2'],
['Couper','cmd3']
]
}
class MyWindow(Tk):
def __init__(self,items,font,*args,**kwargs):
Tk.__init__(self,*args,**kwargs)
self.items = items
self.geometry('400x200')
self.title('ACIAH')
self.font = font
# Dictionnaire recevant les paires "nom du menu" / instance du menu associé
self.menus = {}
self.create_menu_bar(self.font)
self.config(menu=self.menu_bar)
# Méthode qui vocalise les items (en chantier !)
def menu_select(self, event):
label = self.eval(f'{event.widget} entrycget active -label')
# print(label)
os.system(f'/usr/bin/espeak {label}')
def create_menu_bar(self,font):
self.menu_bar = Menu(self,activebackground='Black',activeforeground='White',font=font,takefocus=1)
for k in self.items:
self.menus[k] = Menu(self.menu_bar, tearoff=0,activebackground='Black',activeforeground='White',font=font)
for opt in self.items[k]:
self.menus[k].add_command(label=opt[0],command=self.event_generate('<<MenuSelect>>'))
self.menu_bar.add_cascade(label=k,menu=self.menus[k])
self.menu_bar.bind_class('Menu','<<MenuSelect>>', lambda e: self.menu_select(e))
if __name__ == '__main__':
window = MyWindow(items,('Arial',24,'bold'))
window.mainloop()
Lancement de l'appel à participation pour la #PyConFR23 qui aura lieu à Bordeaux du 16 au 19 février.
Vous avez une idée de conférence, de sprint, d'atelier à organiser, ou vous souhaitez simplement aider à l'organisation ? Venez proposer vos idées sur https://cfp-2023.pycon.fr
Dessous un code totalement en chantier qui devrait vocaliser les labels des items.
Dans une mouture simplifiée j’avais pu observer le passage de ‘normal’ à ‘active’ pour des items.
Note: contrairement à ce que semble indiquer la doc il ne s’agit pas de ‘NORMAL’ et ‘ACTIVE’ (notez les majuscules).
Pour mes premiers essais, je tente la chose avec un seul menu ‘Fichier’ et j’affiche les états (state) de ses items pour en voir passer un à ‘active’.
J’ai essayé différents évènements et ils demeurent tous ‘normal’…
J’ai un gros doute où placer le ‘bind’ et sur quoi le placer (ici je l’applique à chaque menu).
Un “pro” et patient saurait me “corriger” ?
#!/usr/bin/python3
"""
Définition d'une fenêtre comportant une barre de menus dont tous les items sont vocalisés
"""
from tkinter import *
# Dictionnaire pour la définition des menus
items = {
'Fichier':
[
['Nouveau','cmd1'],
['Ouvrir','cmd2'],
['Imprimer','cmd3'],
['Quitter','cmd4']
]
#'Edition':
# [
# ['Copier','cmd1'],
# ['Coller','cmd2'],
# ['Couper','cmd3']
# ]
}
class MyWindow(Tk):
def __init__(self,items,font,*args,**kwargs):
Tk.__init__(self,*args,**kwargs)
self.items = items
self.geometry('400x200')
self.title('ACIAH')
self.font = font
# Dictionnaire recevant les paires "nom du menu" / instance du menu associé
self.menus = {}
self.create_menu_bar(self.font)
self.config(menu=self.menu_bar)
# Méthode qui vocalise les items (en chantier !)
def speak(self,key):
for i in [0,1,2,3]:
print(self.menus[key].entrycget(i,'state'))
def create_menu_bar(self,font):
self.menu_bar = Menu(self,activebackground='Black',activeforeground='White',font=font,takefocus=1)
for k in self.items:
self.menus[k] = Menu(self.menu_bar, tearoff=0,activebackground='Black',activeforeground='White',font=font)
for opt in self.items[k]:
self.menus[k].add_command(label=opt[0],command=self.menus[k].quit())
self.menu_bar.add_cascade(label=k,menu=self.menus[k])
self.menus[k].bind('<Down>',lambda e: self.speak(k))
if __name__ == '__main__':
window = MyWindow(items,('Arial',24,'bold'))
window.mainloop()
Je me permets de vous faire suivre l’actu des Journées du Logiciel Libre.
La prochaine édition aura lieu les 1er et 2 avril 2023 à Lyon, et le thème sera Cultures en partage.
Vous souhaitez :
Animer une conférence ou un atelier ? Tenir un stand dans le village associatif ? Proposez votre intervention via l’appel à participation.
Soutenir l’événement financièrement ? Consultez la page sponsor. Une campagne HelloAsso sera également mise en ligne bientôt (avec de chouettes goodies, évidemment).
Parce qu’on a pas tous Facebook™ (je dis ça, j’ignore si l’herbe est plus verte chez Facebook pour archiver des photos, je n’y ai pas de compte …).
Je me suis dit que ça pourrait être sympa de faire une grosse archive commune des photos des différents évènements de l’AFPy (ateliers, AFPyro, PyConFr, …), alors je l’ai fait : https://photos.afpy.org
J’ai crawlé un peu le site à l’oiseau, Flickr, et mes archives personnelles pour construire ça, mais je pense que ça manque de … vos photos !
Alors allez-y ! Envoyez-moi vos photos ! Non pas en réponse à ce fil, ni sur le photo.afpy.org (qui est statique) utilisez un outil adapté et envoyez-moi les liens (soit par e-mail, soit en message privé).
Mais j’aimerai les retours de ceux qui n’ont pas de compte chez Microsoft™ alors je lance la discussion ici aussi.
Explication №1 : J’ai (presque) toujours vu le repo python-docs-fr pas juste comme un outil pour traduire la doc, mais comme un endroit où tous les francophones pouvaient venir apprendre à contribuer à un logiciel libre, sans le stress de casser quelque chose. Tous les membres du repo me semblent partager cette même idée : ils ont toujours été bienveillants, didactiques, patients, accueillants envers les nouveaux contributeurs (merci à eux ), relisant et peaufinant le CONTRIBUTING.rst sans relâche, améliorant le Makefile pour réduire au minimum les surprises pour les nouveaux arrivants, etc…
Malheureusement on enseigne l’utilisation d’un logiciel close-source.
Mais maintenant on peut faire mieux : on peut bouger ce repo sur https://git.afpy.org !
Je pose ici un petit sondage, mais n’hésitez pas à répondre aussi.
Attention « On duplique le repo » c’est pas si simple, cf. la discussion sur Github.
nb : dans cet article, je n'évoque que l'interpréteur officiel, CPython (3.4+) et l'usage de modules standard à l'interpréteur (donc pas d'exemples de cffi, quel qu’en soient les qualités par ailleurs !).
Introduction
Ce week-end, j'ai fait une énième recherche sur une bricole pour la communication Python et Rust via cTypes. Sur ces "détails" qu'on oublie aussi vite qu'on se casse les dents dessus lorsqu'on ne pratique pas.
Comme ma mémoire est encore plus limitée que le nombre d'onglets et de marques-page sur Firefox, je me suis dit que la prochaine fois autant tomber directement sur un article francophone qui fait un résumé global. Et que ça peut en aider d'autres.
Bien sûr il existe des bibliothèques toutes prêtes pour faciliter la communication entre ces deux mondes :
soit pour interagir avec l'interpréteur Python,
soit "en ramenant" Python au sein d'un applicatif.
Aujourd'hui la bibliothèque Pyo3 est probablement la plus aboutie et la mieux supportée ; j'aime bien en faire la pub car je la trouve géniale - et par extension à deux langages que j'apprécie.
Bref : c'est bien, c'est bon, mangez-en. [fin de la minute pub]
Du reste si cette possibilité semble la plus intéressante, elle s'avère complexe à mettre en œuvre si votre interpréteur Python est dans un ensemble plus large, avec beaucoup de code C ou C++ par exemple, et qu'il s'agit de rentrer dans les pas de versions précédentes ou du code partagé entre plusieurs applicatifs (dont tous ne seraient pas du Python) ; n'est-ce pas le principe des .so après tout ? La bascule de C/C++ à Rust pourrait déclencher des problématiques si vous restez sur le seul usage de Pyo3.
Mais rien n'est insurmontable, surtout pour le serpent : cTypes est votre amie.
Présente par défaut depuis les temps immémoriaux dans l'interpréteur standard, cette bibliothèque vous permet de consommer des .so (assez) facilement avec - c'est assez rare pour être souligné -, un respect strict du typage lors de l'appel de fonction. En effet, vous quittez alors le monde merveilleux (et lâche) de l'interprété, pour le terrible et cruel (et implacable) monde du C, où tout doit être connu (si possible à l'avance).
Voici un pense-bête rédigé pour s'en sortir.
Préparer l'environnement
Dans votre console préférée, créez un projet de bibliothèque :
julien@julien-Vostro-7580:~/Developpement/$ cargo new --lib rust-python
Created library `rust-python` package
A partir de cet instant, malib correspond à un objet permettant d'accéder au contenu de la bibliothèque. Lors d'un appel de fonction à celle-ci, vous pouvez indiquer les types de paramètres et du retour directement dans le code Python.
Par exemple le code suivant précise pour la fonction test_string les types attendus :
malib.test_string.argtypes=[c_char_p,]# arguments d'appel attendus, ici un seul malib.test_string.restype=c_char_p# type du retour resultat=malib.test_string(message.encode())# appel de la fonction partagée, avec la récupération du résultat
Enfin ajoutez le nécessaire dans les sources Rust (lib.rs) :
Notez que les chemins sont relatifs à votre compilation Rust :
target/debug pour cargo build ;
target/release pour cargo build --release.
A partir de là, vous pourrez ajouter les blocs de code les uns à la suite des autres et les tester avec :
cargo build && ./test-ffi.py (compilation plus rapide, message d'erreur plus complet mais moins efficace à l'usage)
cargo build --release && ./test-ffi.py (compilation moins rapide mais plus efficace à l'usage)
Morceaux choisis
nb : il existe déjà des tutoriaux sur les types simples, tels que les entiers. Je ne les mets pas directement en exemple ici. De même il y a de nombreux autres cas généraux que je l'indique pas ; cependant les exemples fournis ici me semble-t-il, permettent de s'en sortir !
#[no_mangle]pubunsafeextern"C"fntest_string(ptr_source: *mutc_char)-> *constc_char{// je récupère en argument un pointer vers un type 'c_char' // je dois d'abord en faire un CStr et grâce à "to_string_lossy" // toutes les valeurs non-conformes UTF-8, seront éliminées (remplacées précisément) // puis j'assigne à 'v' le résultat (une chaîne de caractère) letv=CStr::from_ptr(ptr_source).to_string_lossy().to_string();println!("[RUST] -( 1 )-> {:?}",ptr_source);println!("[RUST] -( 2 )-> {:?}",v);// pour renvoyer ma chaîne, je dois modifier son type pour être conforme // (par exemple : ajouter "\0" à la fin, car on perd la taille fixée en c_char) // ainsi que d'obtenir le pointeur associée lets=CString::new(v).unwrap();letp=s.as_ptr();// au regard de Rust, 's' est ma chaîne c_char et 'p' est le pointeur // si "je n'oublie pas" 's' avant de quitter la fonction, Rust va désallouer la mémoire// le pointeur 'p' renvoyé serait donc invalide // 'std::mem::forget' nous permet de forcer cet "oubli de désallocation" lors de la compilation std::mem::forget(s);p}
Côté Python :
print("--------------------")print("--- partie 1 - chaînes de caractère seules (UTF8)")print("--------------------")message="&é\"'(-è_çà)"print("--- partie 1.1 - sans précision sur le type d'argument")malib.test_string.restype=c_char_presultat=malib.test_string(# n'ayant pas indiqué le type d'argument attendu, je dois faire une transformation # moi-même. Attention cependant, il est toujours préférable d'indiquer le bon type c_char_p(bytes(message,"utf-8")))print("--- partie 1.2 - avec précision sur le type d'argument")malib.test_string.argtypes=[c_char_p,]# ici la précision du type malib.test_string.restype=c_char_presultat=malib.test_string(message.encode())# par défaut, ".encode()" est en UTF-8print("[PYTHON] ===>",resultat.decode())
Résultat :
julien@julien-Vostro-7580:~/Developpement/rust-python$ cargo build && ./test-ffi.py
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
--------------------
--- partie 1 - chaînes de caractère seules (UTF8)
--------------------
--- partie 1.1 - sans précision sur le type d'argument[RUST] -( 1 )-> 0x7f67723d3e90[RUST] -( 2 )-> "&é\"'(-è_çà)"--- partie 1.2 - avec précision sur le type d'argument[RUST] -( 1 )-> 0x7f67723d3e90[RUST] -( 2 )-> "&é\"'(-è_çà)"[PYTHON] ===> &é"'(-è_çà)
Facile.
Partie 2 - Les structures
Côté Rust :
#[repr(C)]#[derive(Debug)]pubstructMonObjet{puba: c_int}#[no_mangle]pubunsafeextern"C"fntest_structure(mutmonobj: MonObjet){// du fait que l'aligment se fait sur le C, on peut directement récupérer l'objet println!("[RUST] -(3)-> {:?}",monobj);// et comme on l'a déclaré "mut(able)" alors on peut agir dessus ; voir ci-après (1)monobj.a+=1;println!("[RUST] -(4)-> {:?}",monobj);}#[no_mangle]pubunsafeextern"C"fntest_structure_ref(ptr_monobj: *mutMonObjet){// le format '&mut *' semble étrange mais est parfaitement valide. On déréférence d'abord le pointeur, puis on créé un emprunt (mutable) au format Rust pour agir dessus ; voir ci-après (2)letmonobj=&mut*ptr_monobj;println!("[RUST] -(3)-> {:?}",monobj);monobj.a=3;println!("[RUST] -(4)-> {:?}",monobj);}
nb (1) : attention à la déclaration de l'objet en argument dans test_structure. Si mut n'était pas déclaré, il serait impossible d'agir sur l'objet, conformément aux règles de la Rouille…
error[E0594]: cannot assign to `monobj.a`, as `monobj` is not declared as mutable
--> src/lib.rs:69:5
|
67 | pub unsafe extern "C" fn test_structure(monobj: MonObjet) {
| ------ help: consider changing this to be mutable: `mut monobj`
68 | println!("[RUST] -(3)-> {:?}", monobj);
69 | monobj.a += 1;
| ^^^^^^^^^^^^^ cannot assign
For more information about this error, try `rustc --explain E0594`.
error: could not compile `analyse-terme` due to previous error
nb (2) : dans le cas que je présente, l'emprunt est nécessaire car la structure MonObjet n'implémente pas le trait de copie, comme le signale très bien le compilateur…
error[E0507]: cannot move out of `*ptr_monobj` which is behind a raw pointer
--> src/lib.rs:75:22
|
75 | let mut monobj = *ptr_monobj;
| ^^^^^^^^^^^
| |
| move occurs because `*ptr_monobj` has type `MonObjet`, which does not implement the `Copy` trait
| help: consider borrowing here: `&*ptr_monobj`
For more information about this error, try `rustc --explain E0507`.
error: could not compile `analyse-terme` due to previous error
Côté Python :
print("--------------------")print("--- partie 2 - structures et passage par référence")print("--------------------")print("--- partie 2.1 - envoi par valeur (l'objet initial n'est pas modifié)")# il s'agit d'une classe un peu particulière, qui prend l'héritage de "Structure" :# Structure permet via un attribut lui-aussi particulier "_fields_", d'indiquer à cType # ce qui est nécessaire d'envoyer à la fonction C partagée classMyStruct(Structure):_fields_=[("a",c_int)]monobjet=MyStruct()monobjet.a=2# monobjet.b = 3 --> vous pouvez essayer sans problème, mais l'attribut n'étant pas déclaré dans _fields_, le champ ne sera pas transmis # notez que je n'ai pas déclaré le type d'arguments attendus resultat=malib.test_structure(monobjet# j'envoi l'objet via un pointeur )print("[PYTHON] ===>",monobjet.a)# pas de modification sur l'objet initial, a = 2 print("--- partie 2.2 - envoi par référence (l'objet initial est modifié)")resultat=malib.test_structure_ref(byref(monobjet)# j'envoi une référence à l'objet via un pointeur )print("[PYTHON] ===>",monobjet.a)# modification sur l'objet initial, a = 3
Résultat :
julien@julien-Vostro-7580:~/Developpement/rust-python$ cargo build && ./test-ffi.py
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
(...)
--------------------
--- partie 2 - structures et passage par référence
--------------------
--- partie 2.1 - envoi par valeur
[RUST] -(3)-> MonObjet { a: 2 }
[RUST] -(4)-> MonObjet { a: 3 }
[PYTHON] ===> 2
--- partie 2.2 - envoi par référence (l'objet initial est modifié)
[RUST] -(3)-> MonObjet { a: 2 }
[RUST] -(4)-> MonObjet { a: 3 }
[PYTHON] ===> 3
Simple non ?
Partie 3 - Les tableaux
Le cas de transfert des tableaux est un peu plus délicat. Il n'est pas comparable à une chaîne de caractère. En effet une chaîne de caractères représente, comme son nom l'indique, un tableau contigu de caractères (peu importe leur taille individuelle). Cependant pour le tableau d'entiers par exemple, ce procédé ne fonctionne pas… car la valeur "0" est une valeur légitime.
Il faut donc passer deux éléments :
le tableau en lui-même, ici sous la forme d'un pointeur,
#[repr(C)]#[derive(Debug)]pubstructValeurRetour{puba: c_int,pubcontenu: Vec<c_int>}#[no_mangle]#[allow(improper_ctypes_definitions)]pubunsafeextern"C"fntest_array(nbre: c_int,ptr_tab: *mut[c_int]){lettab=&mut*ptr_tab;println!("[RUST] -(5)-> {:?}",nbre);foriin0..(nbreasusize){println!("[RUST] -(6)-> [{:?}] {:?}",i,tab[i]);}}#[no_mangle]#[allow(improper_ctypes_definitions)]pubunsafeextern"C"fntest_array_retour_simple(nbre: c_int,ptr_tab: *mut[c_int])-> *mutc_int{lettab=&mut*ptr_tab;println!("[RUST] -(7)-> {:?}",nbre);letnbre=nbreasusize;// une version courte (mais sale) du casting : attention aux valeurs max admissibles par le système pour 'usize' dans un tel cas foriin0..nbre{println!("[RUST] -(8)-> [{:?}] {:?}",i,tab[i]);tab[i]+=1;println!("[RUST] -(8')-> [{:?}] {:?}",i,tab[i]);}letmutnouveau_vecteur: Vec<c_int>=vec![42;nbre+1];// pas propre mais fonctionnel letp=nouveau_vecteur.as_mut_ptr();std::mem::forget(nouveau_vecteur);p}#[no_mangle]pubunsafeextern"C"fntest_array_retour_complexe(nbre: c_int)-> *mutValeurRetour{// notre 'nbre' reçu depuis le monde Python via un c_int, devra changer pour être utilisé dans deux contexte différent println!("[RUST] -(9)-> {:?}",nbre);letnbre_c_int: c_int=(nbre+1).try_into().unwrap();letnbre_usize: usize=(nbre+1).try_into().unwrap();letvecteur_retour=Box::new(ValeurRetour{a: nbre_c_int,// ici un entier au format c_int contenu: vec![42;nbre_usize]// ici un usize pour définir la taille finale du vecteur, même si ce dernier aurait pu être conçu "à la volée" en ajoutant progressivement des valeurs - ici c'est juste plus efficient });println!("[RUST] -(10)-> {:?}",vecteur_retour);// plus propre que 'mem::forget()' Box::into_raw(vecteur_retour)}
Côté Python :
Peut-être une expression va vous choquer : (c_int * len(tab_valeurs))(*tab_valeurs). Elle est pourtant tout à fait correcte ! Une fois décomposée, elle est très simple à comprendre :
… La dernière partie est l'assignation des valeurs contenues dans tab_valeurs vers taille_fixe_tableau_c_int, comme si l'on faisait une boucle for. Attention une telle boucle n'est pas réellement possible (d'où l'appel de fonction) :
julien@julien-Vostro-7580:~/Developpement/rust-python$ python3
Python 3.10.4 (main, Jun 292022, 12:14:53)[GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license"for more information.
>>> from ctypes import *
>>> tab_valeurs=[1, 2, 3, 4]
>>> taille_tab_valeurs= len(tab_valeurs)
>>> taille_fixe_tableau_c_int= c_int * taille_tab_valeurs
>>> taille_fixe_tableau_c_int
<class '__main__.c_int_Array_4'>
>>> for i, v in enumerate(tab_valeurs):
... taille_fixe_tableau_c_int[i]= v
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
TypeError: '_ctypes.PyCArrayType' object does not support item assignment
Vous aurez noté au passage le type : Class __main__.c_int_Array_4 (avec 4 qui correspond à la taille) ; notre multiplication est en réalité la construction d'un objet.
Pour l'étoile, c'est exactement le même principe que l'argument du reste pour une fonction ou lors de la construction des listes ou dictionnaires:
julien@julien-Vostro-7580:~/Developpement/rust-python$ python3
Python 3.10.4 (main, Jun 292022, 12:14:53)[GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license"for more information.
>>> a=[0,1,2,3]
>>> b=[*a,]
>>> b
[0, 1, 2, 3]
>>> c={"ok":1}
>>> d={**c,}
>>> d
{'ok': 1}
>>> d={**c,'ko':0}
>>> d
{'ok': 1, 'ko': 0}
… plus de mystère !
print("--------------------")print("--- partie 3 - tableaux et passage par référence")print("--------------------")print("--- partie 3.1 - envoi par référence (l'objet initial est modifié)")tab_valeurs=[1,2,3,4]tableau=(c_int*len(tab_valeurs))(*tab_valeurs)malib.test_array(len(tableau),byref(tableau))print("[PYTHON] ===>",len(tableau),list(tableau))print("--- partie 3.2 - envoi par référence x2 et acquisition pré-connue retours")malib.test_array_retour_simple.restype=POINTER(c_int)r1=malib.test_array_retour_simple(len(tableau),byref(tableau))print("[PYTHON] =( r1 )=>",len(tableau),list(tableau))print("[PYTHON] =( r1 )=>",len(tableau)+1,[r1[i]foriinrange(0,len(tableau)+1)])r2=malib.test_array_retour_simple(len(tableau),byref(tableau))print("[PYTHON] =( r2 )=>",len(tableau),list(tableau))print("[PYTHON] =( r2 )=>",len(tableau)+1,[r1[i]foriinrange(0,len(tableau)+1)])print("--- partie 3.2 - création d'un objet de retour de taille indéterminée à l'appel")classValeurRetour(Structure):_fields_=[("a",c_int),("contenu",POINTER(c_int))]malib.test_array_retour_complexe.restype=POINTER(ValeurRetour)r3=malib.test_array_retour_complexe(len(tableau))a=r3.contents.av=r3.contents.contenuprint("[PYTHON] ===>",a,[v[i]foriinrange(0,a)])
Parfait.
Conclusion
Nous avons fait un tour rapide mais j'espère assez complet du propriétaire. En fonction de vos retours (coquilles ou ajouts majeurs), je demanderais peut-être à un admin de pouvoir passer un dernier coup de polish sur l'article…
ELDA (Agence pour l’évaluation et la distribution de ressources linguistiques), société spécialisée dans les technologies de la langue dans un contexte international, cherche à pourvoir immédiatement un poste de chef de projet, spécialisé dans les technologies vocales.
Meetup Django le 16 novembre dans les locaux de Polyconseil 14-16 Bd Poissonnière · Paris.
L’occasion de se retrouver et entre autre en apprendre davantage sur la performance backend avec Django et de comprendre comment débogguer avec l’outil Kolo.
Un ancien (lead) développeur web reconverti depuis 3 ans dans la Data précise quelles sont les compétences minimales de Python nécessaires pour démarrer en Data Science
Dans un projet informatique, les tickets d'anomalie (bug ou incident) et d'évolution sont des moyens de communication
entre les utilisateurs ou les clients, et l'équipe technique, mais font aussi office d'outil d'organisation, de documentation ou de support de réflexion.
Un ticket d'anomalie est généralement rédigé après avoir constaté un comportement inattendu d'un outil informatique.
L'auteur cherche à transmettre à l'équipe technique les détails qui vont lui permettre de comprendre ce qu'il s'est passé, trouver les causes du problèmes, et enfin le résoudre.
Cela prend généralement la forme de cette suite d'actions : communiquer, diagnostiquer, enquêter, résoudre.
Les trois dernières étapes sont la responsabilité de l'équipe technique, mais la compréhension de l'évènement anormal se passe souvent dans le ticket d'anomalie.
L'enjeu pour l'auteur de celui-ci est donc de décrire son expérience de manière à ce que l'équipe technique la comprenne, et puisse être efficace pour résoudre le problème.
Tout le temps que l'équipe passer à lever les ambiguités ou demander des informations complémentaires repousse d'autant la résolution finale du problème.
Voici quelques pistes pour bien communiquer avec une équipe technique :
Comment rédiger un rapport d'anomalies
Le titre
Le titre d'un ticket devrait être le plus court possible en contenant les mots les plus signifiants.
Il devrait à lui seul donner une idée du contenu du ticket.
Il devrait être descriptif plutôt qu'interrogatif :
Lorsqu'il s'agit d'une tâche programmée ou d'une évolution souhaitée, utilisez de préférence des verbes à l'infinitif.
Par exemple « Traduire la page d'accueil », « Maquetter la page abonnement », « Importer le jeu de données des contours des communes françaises ».
Lorsqu'il s'agit d'une anomalie, utilisez plutôt des phrases nominales, c'est à dire sans verbe, qui décrivent factuellement l'anomalie observée.
Par exemple « Message d'erreur lors de la validation du formulaire d'inscription », « Résultats de recherche incohérents pour les achats vieux d'un an », « Pas d'affichage des véhicules sur la carte après connexion ».
La description
Il est beaucoup plus efficace de ne décrire qu'un seul et unique problème à la fois.
Ne décrivez pas tout ce qui est survenu lors d'une session d'utilisation/de test par exemple mais faites autant de tickets que nécessaires si vous avez constaté plusieurs anomalies.
Ne cherchez pas non plus à faire des groupes de problèmes : si deux problèmes se révèlent en fait liés ou en doublon, c'est l'équipe technique qui les fusionnera, puisque le diagnostic du problème est de sa responsabilité.
C'est toujours ça de moins à faire au moment d'écrire le rapport !
S'il existe un modèle de rapport d'anomalie, utilisez-le bien sûr. Celui-ci vous fera gagner du temps et vous guidera pour ne pas oublier d'information. Sinon rappelez-vous de ce que devrait contenir un rapport (et n'hésitez pas à suggérer à l'équipe technique de créer un modèle) :
1. ce que j'ai fait.
La première chose que va tenter de faire l'équipe technique, c'est de tenter de constater l'anomalie, et donc reproduire la situation qui vont a amenées à l'anomalie. C'est de votre responsabilité de transmettre les bonnes informations pour que les techniciens réussissent cette étape.
Donnez le contexte dans lequel l'anomalie est survenue, éventuellement énumérez la suite d'actions qui a emmené jusqu'au bug. Rappelez avec quel compte vous êtes connectés, donnez le lien de la page web concernée par le bug, et l'heure à laquelle il a survenu.
Donnez ces informations à chaque fois, même si ça vous semble rébarbatif ou non pertinent. Ce sont des informations précieuses pour l'équipe technique. Un bug est peut être spécifique à ce contexte précis et difficilement reproductible en dehors. La date par exemple sert à retrouver les informations susceptibles d'aider à la compréhension dans les journaux d'erreurs techniques.
Exemple : « J'ai rencontré l'anomalie sur la plateforme de recette, jeudi 30 juin vers 14h30. J'étais connecté avec le compte Alice et après avoir ajouté un vélo dans son compte avec la position géographique (48° 52.6 S, 123° 23.6 O), j'ai cliqué sur l'icône carte qui amène sur http://monservice.example/carte. »
2. ce que j'ai constaté.
Expliquez le comportement non attendu qui a été observé, si possible illustré d'une capture d'écran ou d'une vidéo.
Exemple : « La carte s'affiche bien : on voit la rue dans laquelle habite Alice mais le point "vélo" n'apparait pas. »
3. ce que j'aurais du voir.
Parfois c'est évident, mais souvent ça ne l'est pas. Expliquez brièvement le comportement que vous espériez, et pourquoi ce que vous observez n'y correspond pas.
Exemple : « La carte devrait montrer l'endroit où est situé le vélo, puisque le vélo est situé en France métropolitaine. »
Enfin, un rapport d'anomalie ne devrait probablement PAS contenir :
un diagnostic : Astreignez-vous à ne décrire que les comportements observés, éventuellement les impacts réels ou anticipés sur votre usage ou celui des autres utilisateurs. Établir le diagnostic d'un problème fait partie du travail de l'équipe technique, ne perdez de temps sur cet aspect au risque de brouiller les pistes.
un brainstorming : N'ouvrez pas de nouvelles questions. Les tickets de bug ont pour fonction de décrire l'existant, les idées d'évolution et les brainstorming doivent avoir une place distincte ! Selon les méthodes de travail, cela peut être dans un autre outil ou bien dans un ticket avec une priorité dédiée à celà.
La priorité
Si vous faites partie de l'équipe produit et que c'est à vous de juger la priorité entre plusieurs tickets (via un indicateur sur le ticket par exemple), celle-ci doit être bien choisie.
La répartition des tickets doit avoir une forme de pyramide : peu de priorité très haute, un peu plus de priorité haute, encore un peu plus de priorité moyenne etc.
Si tout est en priorité très haute alors les tickets sont probablement mal priorisés.
Considérez que les tickets les plus prioritaires seront dans la mesure du possible traités en premier. S'ils sont tous au même niveau, cela devient chronophage voire impossible pour l'équipe technique de déterminer l'ordre de réalisation le plus pertinent.
Pour organiser efficacement les tickets en fonction de leur priorité, pensez à ce à quoi vous êtes ou n'êtes pas prêts à renoncer, en cas de réduction des moyens de production. Si demain la capacité de développement était divisée par deux et que vous deviez vous séparer de la moitié des tickets, lesquels gardriez-vous ?
L'assignation
Même si l'outil utilisé le permet, n'assignez pas des tickets à des membres de l'équipe technique. C'est le rôle de l'équipe technique de se répartir les tickets. Par exemple même si vous utilisez simplement le mail, utilisez une adresse non nominative pour adresser le rapport.
Par contre, faites en sorte que les tickets d'anomalie et d'évolution parviennent de façon efficace à l'équipe technique : ne mélangez pas tickets non techniques et tickets techniques. Les sujets de communication ou de commerce devraient avoir leur propre listes de tickets. Utilisez par exemple une adresse mail spécifique dédiée dans le cas d'emails.
Un projet intéressant pour creuser les optimisations de Python 3.11, c’est un outil qui surligne notre code en fonction des optimisations appliquées par Python, démo :
Le vert signifie que Python 3.11 a pu spécialiser les instructions, par exemple utiliser une multiplication et une soustraction fonctionnant spécifiquement avec des floats dans ce cas.
Le rouge signifie que l’interpréteur n’a pas pu optimiser. Typiquement ici l’accès à la globale TEST_VALUES n’a pas pu être optimisé (alors qu’il est optimisable) puisqu’il n’a été exécuté qu’une seule fois.
La boîte où je bosse - arolla - organise un webinaire qui je pense pourra vous intéresser.
Voici un court descriptif:
Python est un langage très simple à apprendre et à utiliser. Par conséquent, il offre un grand niveau de liberté lorsqu’on code. Mais cette liberté peut aussi se retourner contre nous, mener à bidouiller et donc créer de la dette technique sans s’en rendre compte. Mais pas de panique. Ce n’est pas une fatalité. Alors que diriez-vous de faire du Python, mais de la bonne manière ?
Je serai l’un des animateurs donc n’hésitez pas à poser vos questions ci-dessous.
Si vous souhaitez participer, il suffit de s’inscrire sur EventBrite
Vous êtes intéressés par les opportunités de carrière à l’étranger et plus particulièrement au Canada / au Québec ?
Boostsecurity.io est une startup Montréalaise en croissance, nous sommes à la recherche d’un(e) Développeur Back End Sénior, ainsi que d’un(e) Développeur Full Stack.
La compagnie offre de sponsoriser le processus d’immigration pour les candidats sélectionnés.
À propos de la compagnie: Boostsecurity.io est en “stealth mode”, ce qui signifie que leur produit est encore confidentiel.
Ils ont une excellente réputation dans le domaine de la cybersécurité et représentent une des compagnies les mieux financées à Montréal, avec des investisseurs au Canada, en Europe et dans la Silicon Valley.
En rejoignant Boostsecurity.io, vous travailleriez sur un produit créé par des développeurs pour les développeurs: une application hautement scalable et event-driven. L’opportunité idéale pour les développeurs qui aiment résoudre des problèmes techniques et architecturaux complexes.
Responsabilités:
Concevoir, tester et implémenter des nouvelles fonctionnalités pour notre infrastructure back end hautement performante.
Développer en utilisant la méthodologie TDD (Test Driven Development).
Travailler en collaboration avec un Gestionnaire de Produit, un Designer et les autres développeurs en mode Agile; nous cherchons constamment à trouver un équilibre entre vélocité et maintenir des standard de qualité très élevé pour notre code et notre produit
Offrir du mentorat aux développeur juniors afin de les aider à grandir
Expérience recherchée:
Une expérience confirmée sur des applications hautement performantes, scalable et event-driven
Expérience sur des architectures micro-services et dans le développement Back End sur des applications cloud-based
Une expérience éprouvée dans le développement d’application axée sur la qualité et des équipes orientées produit.
Poste permanent avec stock options à la clé, nous cherchons à bâtir une équipe sur le long terme
Travailler aux côtés d’une équipe expérimentée, très avancée avec les pratiques TDD, DevSecOps, Infra as Code
Boostsecurity.io ont un bureau à Montréal, mais le poste s’effectuera principalement en télétravail (possibilité de 100% remote également à partir du Canada)
Si vous êtes intéressés ou souhaitez plus d’informations, n’hésitez pas à me contacter directement à pauline@bridgeeleven.ca.
je vous joins une offre d’emplois pour laquelle nous recrutons potentiellement plusieurs personnes (~10 d’ici 1 an).
Cette offre est donc assez ouverte et peut déboucher sur plusieurs postes possibles en fonction de l’équipe dans laquelle vous travaillerez.
La job description est en anglais mais si vous voulez plus de détails je serais heureux de vous donner plus de renseigner.
Job description
We are looking for a passionate software engineer to help us develop a developer-first cybersecurity solution.
You will be a part of GitGuardian’s journey, that protects the open source community against hackers and makes it a robust, scalable and globally trusted product!
You will build a set of tools that scan GitHub public activity and git private repositories.
By joining our team, you will take an active part in:
Doing hands-on software development
Working closely with other highly-skilled developers
Working with an agile methodology with your Product Manager and your Lead Developer on 2 weeks sprints releases
Maintaining and ensuring an excellent quality of developed code
Participating in the growth of our technical teams! We are growing from 30 to 50 developers to support our growth in 2022.
Depending on your preferences and the team you will integrate your mission may be vary:
Backend web developer, private and public api
Full-stack python/react to work on user facing dashboards
Backend / sre, working on on premise solution for big tech
R&D to improve analyze the performance of our algorithms in specific cases, suggest and implement improvements
R&D to develop our next generation of code security scanners from scratch to production
As a post Series B startup, we are facing many exciting & strategic challenges and we are experiencing very rapid growth: our goal is to recruit +100 people in 2022!
A remote-friendly environment up to 3 days / week for people in “Ile de France” and full-remote policy for people living outside
An attractive package that includes stock-options
The latest setup equipment including cool apps, tools and technologies
Working to develop a meaningful product → we already helped more than 200k developers!
Lots of team-building activities
Many opportunities for career development in the long term
A strong engineering culture
Pet-friendly offices → every Guardian gets to bring their dogs to the office and we love it!
Lots of trust & autonomy on your perimeter with a very transparent internal communication
Preferred experience
Degree in engineering, computer science or similar technical field
2+ years of web software development experience, with a strong Python knowledge
Experience working with the following: web application development, Unix/Linux environments, distributed and parallel systems.
Dynamic and proactive personality with good communication skills
Bonus points:
You know how to set up a development environment with Docker
You don’t embed API keys in your code
Experience handling big data ( 100 Go < < 10 To) with PostgreSQL, MongoDB, ELK stack
Deep understanding of the startups dynamics and challenges
Have experienced strong team growth in a previous company
About GitGuardian
GitGuardian is a global post series B cybersecurity startup, we raised $44M recently with American and European investors including top-tier VC firms.
Among some of the visionaries who saw this unique market value proposition, are the co-founder of GitHub, Scott Chacon, along with Dockerco-founder and CTO Solomon Hykes.
We develop code security solutions for the DevOps generation and are a leader in the market of secrets detection & remediation.
Our solutions are already used by hundreds of thousands of developers in all industries and GitGuardian Internal monitoring is the n°1 security app on theGitHub marketplace. GitGuardian helps organizations find exposed sensitive information, that could often lead to tens of millions of dollars in potential damage.
We work with some of the largest IT outsourcing companies, publicly listed companies like Talend or tech companies like Datadog.
Based in Paris we are a true citizen of the world with more than 80% of our customers in the United States.
The Guardians are young, passionate and aiming high!
GH-90908 - Introduction des groupes de tâches dans asyncio
GH-34827 - Groupes atomiques ((?>...)) and quantifieur possessifs (*+, ++, ?+, {m,n}+) sont maintenant supportés dans les expressions régulières
Le Faster CPython Project fournit des résultats intéressant. Python 3.11 est jusqu'à 10-60% plus rapide que Python 3.10. En moyenne, une amélioration de 1.22x a été mesurée avec la suite de test de performance standard. Voir la page Faster CPython pour plus de détails.
Un peu de suivi sur la question de la gestion des mots de passe au quotidien. Il y a deux ans, nous vous présentions dans cet article les pré-requis et les choix technologiques (Seafile + KeePass) que nous avions retenu. Cette solution est restée fonctionnelle et satisfaisante, mais quelques (presque) nouveautés nous ont convaincu.
Nous vous avions parlé de syspass en mentionnant discrètement un "élégant clone de Bitwarden". Après 6 mois d'utilisation personnelle, il fut proposé au reste de l'équipe. Et après 6 mois d'utilisation collective, on vous en parle. Il va être compliqué de parler de Vaultwarden sans parler de sa version open source certes, mais surtout commerciale, Bitwarden. Pour faire court et laisser à sa réimplémentation en Rust les lauriers de ses fonctionnalités, reconnaissons principalement l'efficacité de ses clients, qui fonctionnent parfaitement avec Vaultwarden. Que vous soyez sous Firefox, Chromium/Chrome, Android, iOS, vous retrouverez le même client, avec la même interface, sans grand reproche à lui faire (et nous n'avons pas testé les clients desktop, mais vu l'uniformité sur le reste des plateformes, on vous les conseille sans trop prendre de risque). Passons maintenant à Vaultwarden! Des fonctionnalités en pagaille Un point essentiel dans l'acceptation de l'outil, on trouve rapidement dans l'interface l'outil pour importer vos anciens mot de passe avec plus de 50 formats supportés. Outre l'import de notre vieux fichier au format KeePass2, nous avons validé pour vous les imports : Chrome, Password Safe et Passbolt
Comparé à notre précédent système (un unique fichier chiffré avec une passphrase connue de l'ensemble de l'équipe), on a gagné quelques fonctionnalités. Tout d'abord, Vaultwarden nous permet maintenant une gestion des comptes utilisateurs et de groupes ("Organizations"). La gestion de compte permet facilement l'arrivée ou le départ d'utilisateurs, chacun possédant d'ailleurs son "Vault" privé dans lequel il peut stocker ses mots de passe. La gestion de groupes nous a permis d'étendre grandement le partage des mots de passe (pour atteindre le même niveau de satisfaction, on aurait dû faire plusieurs fichiers KeePass avec chacun leur passphrases, une lourdeur qui nous avait jusqu'alors bloqué dans un entre-deux où seulement la part minimum de nos mots de passe se retrouvaient partagés). On retrouve évidemment ce que l'on attend, les différents types d'utilisateurs ("User", "Manager", "Admin", "Owner"), la limitation d'accès à un groupe, voir même uniquement à un ou des dossiers d'un groupe. On notera en particulier la possibilité très appréciable de donner un accès en "Hide Passwords" (l'extension de l'explorateur sera capable de remplir le mot de passe mais l'utilisateur ne le verra pas !), parfait pour un intervenant externe, un stagiaire, ... Vaultwarden fournit aussi un ensemble de rapports sur vos mots de passe. Vos mots de passe ont-ils (encore) été exposés dans des leaks récentes ou anciennes ? Utilisez-vous (encore) le même mot de passe pour différents comptes ? Avez-vous (encore) des mots de passe que l'on peut considérer comme faibles ? Est-ce que vous n'utilisez (encore) pas de 2FA alors que le site le propose ? Toute une série de questions auxquelles il est difficile de répondre manuellement vu le nombre de mots de passe utilisés. Vaultwarden vous offre ça en deux clics.
On trouve aussi un bon générateur de mot de passe et de passphrase configurable à souhait et appelable directement sur une page de création de compte avec un clic droit. Et last but not least, l'intégration 2FA. Elle existe théoriquement sous KeePassXC, mais suivant les plateformes elle était accessible... ou non. Ici on la trouve directement dans chaque fiche de mot de passe et on peut même scanner directement via les applications sur téléphone pour renseigner le champ "automagiquement". On pourrait reprocher aux extensions de ne pas détecter le champ TOTP et le remplir automatiquement, mais il semblerait que ces champs soient moins bien uniformisés que ceux des identifiants/mots de passe. Au moment de la rédaction de ce paragraphe, j'ai tout de même découvert que l'extension de mon explorateur mettait dans le presse-papier le TOTP après avoir automatiquement rempli les identifiants, un simple "ctrl-v" à la page suivante suffi donc à remplir le code TOTP! Enfin un petit bonus (pour utilisateurs paranoïaques) ou malus (pour celui qui oubliera sa passphrase), il n'y a pas de fonction de récupération de compte. D'un côté vous serez responsable de la perte de vos mots de passe, mais de l'autre vous n'avez pas à vous poser la question de la bienveillance ou non de votre admin préféré. Sans votre passphrase, ni récupération ni intrusion possible. Installation et build de Vaultwarden Utilisé dans un premier temps avec l'image Docker fournie, l'usage a été pérénisé en automatisant les deux builds bien documentées nécessaires au fonctionnement de Vaultwarden (Vaultwarden, le coeur en Rust, et web-vault, l'interface web). Vous pouvez aussi bien utiliser les releases de l'un comme de l'autre. La configuration Apache et le service Systemd sont triviaux. Un peu de sucre d'admin parano Le premier point qui nous a gêné était la perte d'historique par rapport à notre Seafile et donc la possibilité de corriger une erreur humaine. On s'est accordé que le problème n'était pas tant d'identifier le coupable que la possibilité de revenir en arrière. Nous avons donc décidé de rester sur une base de données sqlite3 (avec une petite quinzaine d'utilisateurs pour plus de 1 500 mots de passe stockés, on est à 6M) en se gardant un backup local de la base toutes les 5 minutes sur 24h (on pousse à un peu plus de 600M de backups, bien penser à utiliser la command backup de sqlite). Couplé avec notre système de backup glissant (8 derniers jours, 4 dernières semaines et 12 derniers mois), on s'est donné un niveau de stress minimal sur le risque de perdre des données. Le deuxième point de tension était sur l'exposition au monde de l'interface de Vaultwarden. Bien que l'équipe de dev de Vaultwarden ait l'air très sérieuse, il nous a semblé difficile de l'être, nous, en utilisant Vaultwarden ouvertement via une URL publique (pour l'interface utilisateur, Vaultwarden propose une interface admin, celle là reste cachée, point). La solution la plus appropriée est bien évidemment le VPN de l'entreprise, ce qui a été mis en place. Mais ce faisant, on perdait son usage sur nos téléphones (et qui veut connecter son iDevice à un réseau sérieux ?). Ce n'était pas vraiment acceptable ni professionnellement, ni dans l'objectif de fournir aux employés ce gestionnaire de mots de passe y compris à usage personnel. Un compromis a été trouvé en bloquant l'accès public à l'URL publique de notre Vaultwarden aux IP fixes des ours qui en ont (le très simple "Require ip" d'Apache fait le job) et en laissant aux autres l'accès via le VPN.
Pour ceux avec IP fixe, on peut synchroniser ordinateur et téléphone de chez soi, et utiliser le cache lors de déplacement. Pour ceux sans IP fixe, on peut assez facilement faire un reverse proxy sur un ordinateur ayant accès au VPN pour donner à son téléphone l'accès sur son réseau local, et retomber donc sur le cas précédent (avec un petit jeu pour que votre CA et celui de l'entreprise soit reconnu).
Bilan Après 6 mois d'utilisation chez Bearstech et un peu plus d'un an pour ma part, Vaultwarden s'impose comme une solution fiable pour la gestion de vos mots de passe et bénéficie du sérieux commercial de Bitwarden pour ses clients (extensions, apps, ...). L'essayer c'est l'adopter ! Et pour la suite on a promis de tester Cozy Pass, à dans 2 ans.
Dans le cadre de l’évolution d’un projet d’espace client dans le domaine du BTP (location d’équipements de chantier B2B), nous cherchons un freelance python (python3.9, django, django rest framework) pour prendre en charge dans un premier temps en binôme avec moi puis au sein d’une équipe autonome plus complète (ajout d’un designer et d’un développeur front) des évolutions mineures puis majeures du projet.
La base de code actuelle est maîtrisée à 100% et sa couverture de teste est excellente (chaque feature est testée), et la partie backend est principalement constituée d’une API REST (DRF) consommée par le frontend et d’une administration django.
Le projet est développé en suivant des pratiques pérennes : sprints hebdomadaires (roadmap, estimations, développement, livraison, démo, rétro), tests systématiques, intégration continue, déploiement continu capable de monter des environnements par branche, builds dans des conteneurs déployés sur google cloud (12factor), pair-programming régulier …
Modalités
Freelance (contrat)
Télétravail (en France depuis un lieu fixe)
4 jours par semaine
Démarrage en Novembre 2022
Facturation mensuelle
Tarif jour à déterminer ensemble en fonction du profil
Recherche
Au moins 5 ans d’expérience en développement Web (backend)
Compétences/connaissances requises
Bases d’algorithmique (structures de données, complexité, …)
Fonctionnement du Web (HTTP, échanges réseau client/serveur, …)
Python (3.9)
Django (3.2) + Django REST Framework
PostgreSQL (ou autre moteur de bases de données relationnel)
Pytest (ou expérience avec un autre outil de tests python)
Git
Compétences/connaissances optionnelles mais appréciées
Docker / K8S
Google Cloud Platform
Typescript / React
Le projet étant réalisé par une équipe 100% distribuée / à distance (et ce depuis le premier jour du projet, il est impératif pour le bon déroulé d’être capable de communiquer efficacement et de collaborer dans l’intérêt du projet malgré la distance physique. L’outillage moderne nécessaire à cette collaboration à distance est fourni (voire adapté par l’équipe au fil des besoins) mais les outils ne font pas à notre place, et il est donc important de mettre un effort particulier sur cette communication qui est un vrai point clef de succès du projet.
Si ce projet vous semble correspondre à vos recherches, discutons en plus en détails par mail ou téléphone :
C’est un membre de la ML debian-user-french qui me conseillait d’aller sur votre site, que j’ai donc découvert.
Je découvre Python et étant proche d’être aveugle je tente de réaliser des apps avec tkinter qui seraient entièrement vocalisées avec ‘espeak’.
En effet je m’aperçois que ce que j’ai su coder jusque présent n’est pas compatible avec mon lecteur d’écran Orca.
Je galère sur le sujet des items des sous-menus que je ne parviens pas du tout à vocaliser (quand ils prennent le focus mais avant qu’il y ait clic de la souris ou surtout de la frappe de Return) pour que leurs labels puissent être passés au module os.
Par contre, je n’ai pas de difficultés avec les widgets classiques.
Je passe d’un item au suivant avec les touches fléchées.
J’ai examiné moult alternatives avec les événements.
Je poste ici, car on me l’a suggéré dans le discord. J’organise une série d’ateliers virtuels gratuits entre le 1er novembre et le 19 décembre. J’ai préparé un programme ici https://placepython.fr.
Je suis toujours hésitant avant de poster un lien externe sur un forum, donc dites-moi si ce n’est pas opportun.
Ce matin j’ai reçu un spam (qui ne commençait pas par « Dear Python, » cette fois, ça c’était hier, faut suivre !
J’ai donc voulu le remonter à signal-spam.fr mais en ce moment j’utilise Protonmail…
Depuis Protonmail c’est simple de télécharger un email, donc je me retrouve avec un .eml et à coup de xclip c’est vite copié dans le formulaire de signal-spam.fr, mais bon, on peut faire mieux.
J’ai donc vite fait écrit :
Voilà, ça m’évite un copier-coller.
Je sais que tu as le flag « une parenthèse n’est pas fermée » levé dans ton cerveau depuis la première ligne, c’est pas agréable ? Aller je suis gentil, voilà ) tu peux baisser ton flag et passer une bonne journée.
Dans la doc de Python, la syntaxe utilisée pour les arguments optionnels fait mal aux yeux des débutants, n’est pas de la syntaxe Python, et se mélange avec la syntaxe des listes, par exemple :
complex([real[, imag]])
Je propose de convertir ça en syntaxe Python :
complex(real=0, imag=0)
complex(string, /)
En faisant d’une pierre trois coups :
C’est de la syntaxe Python, donc les “débutants” découvrent que / c’est valide, sans pour autant découvrir ce que ça veut dire.
Ça permet de documenter les valeurs par défaut lorsqu’il y en a.
Parfois, comme pour complex j’en profite pour rajouter les constructeurs alternatifs manquants à la doc, comme le fait que complex accepte aussi une chaîne.
C’est dans cette PR :
Et je me demande encore si c’est plus lisible avant ou après, j’aimerai l’avis de la communauté
Je me lance dans un side-project, libre et gratuit, d'une envergure encore inédite pour moi.
Je vais vous esspliquer un peu ce que je compte faire, et comment. Si certains d'entre vous, en passant par là, avait envie de donner un avis constructif, voire des conseils, des idées, bienvenue à eux.
L'idée est de programmer un synthétiseur FM virtuel, dans la lignée de FM8 de Native Instruments, par exemple. Il en existe déjà quelques uns dans le monde du libre, mais pour les avoir à peu près tous essayés, aucuns ne me satisfont vraiment, que ça soit dans l'ergonomie, les possibilités, ou la qualité de rendu du son. J'ai donc envie de produire une "killer app" qui fasse concurence aux plus grands du domaine (ça semble peut-être un peu prétentieux dit comme ça, mais j'aime pas trop partir en me disant que je vais faire de la merde, voyez-vous ?).
Voilà pour le résumé du projet. J'ai déjà pas mal bossé en amont. En programmant déjà quelques synthés plus simple pour voir si j'étais à la hauteur de la tâche, en réunissant un peu toutes les maths nécessaire à la simulation de cette synthèse particulière, en réfléchissant à comment faire "discuter" toutes ces équations pour obtenir le résultat voulu, en étudiant de près ce que devrait-être l'ergonomie d'un tel soft pour garder un minimum d'intuitivité sans rien sacrifier aux fonctionnalités et à la modularité, et d'autres choses. Bref, je pars pas les mains vides.
Non, si je viens vous parler de ça aujourd'hui, c'est parce qu'il est temps de me lancer à tapoter du code, et si j'ai déjà une idée assez précise de comment je vais articuler le tout, j'ai besoin de savoir si mon approche est déjà techniquement possible, et si oui, à quel point vais-je m'arracher les cheveux/me casser les dents, ou si mes compétences hétéroclites ne m'ont pas permis de voir qu'il y à beaucoup mieux à faire.
Alors d'avance merci pour vos avis éclairés.
D'abord, c'est quoi un synthé FM ? (si vous le savez déjà, vous pouvez sauter à la partie suivante)
C'est un ensemble d'opérateurs (entre deux et huit en général, pourquoi ne pas en imaginer plus) qui intéragissent entre eux via une matrice de modulation.
Un opérateur est constitué d'un oscillateur, d'une ou plusieurs enveloppes ADSR pour contrôler ses parametres (niveaux de sortie, d'entrée, fréquence, etc.), éventuellement de filtres passe-haut/bas/bande/notch pour modeler ses harmoniques, d'une entrée de modulation, et d'une sortie.
Ces opérateurs entrent et sortent joyeusement les uns dans les autres pour se moduler réciproquement suivant des algorithmes (le plus souvent programmés dans une matrice) pour nous procurer du (parfois bon) son.
Ok, comment j'ai prévu de faire ça ?
Alors moi, je sais faire des interfaces en python avec Pyside, et je sais faire des synthés en C. Fort de cette constatation, j'ai envie d'utiliser Pyside pour la partie UI, et le C pour la partie synthèse (ou C++ peut-être, mais j'avoue être un peu frileux à cette idée). Jusque là, tout va bien =D
Mais comment articuler tout ça ? Petit schéma, avec essplications en dessous :
Légende :
Chaque rectangle est un thread,
En bleu, c'est du python,
En rose, c'est du C,
Les flèches grasses signifient "crée ce thread",
Les flèches maigres (rouges) -> échange de données,
L'entrée d'exécution est indiquée par "Entrée d'exécution"
Résumé :
On appelle un programme en C, qui crée un thread Python pour nous présenter une zoulie interface utilisateur. De là on demande au thread principal de nous créer une matrice de modulation et des opérateurs à mettre dedans (chacun dans des thread séparés), et on fait boucler le tout pour faire du bruit.
Le truc qui me chiffonne, c'est que je ne suis pas vraiment très à l'aise avec la création/gestion de threads (mais ça me fera une bonne occasion d'apprendre), surtout dans les langages différents. Alors déjà, est-ce seulement possible de faire ça d'après vous ?
Ça à l'air complexe, mais quand pensez-vous ? Vous croivez que je vais y arriver comme même ?
Merci en tout cas d'avoir lu jusqu'au bout, et d'avance merci encore pour les idées, conseils, pistes, et encouragements (ou découragements aussi).
Nous recherchons un·e développeur·se avec déjà une première expérience professionnelle significative en Vue / Typescript pour poursuivre le développement de notre application. Avoir également de l’expérience avec Python, Docker ou Ansible est un plus.
Type d’emploi : CDI ou CDD, temps plein ou 4/5, télétravail en France possible.
Ce n’est pas un poste de data scientist.
Qui est OctopusMind ?
OctopusMind, spécialiste de l’Open Data économique, développe des services autour de l’analyse des données. Nous éditons principalement une plateforme mondiale de détection d’appels d’offres : www.j360.info
L’entreprise, d’une dizaine de personnes, développe ses propres outils pour analyser quotidiennement une grande masse de données, en alliant intelligence humaine et artificielle www.octopusmind.info
Nos bureaux, dans le centre ville de Nantes, sont adaptés au télétravail (de 0 à 4 jours par semaine, en fonction des envies de chacun·e).
Un télétravail complet est envisageable, si résidence hors de la région nantaise, sous réserve d’une présence continue en début de contrat (pour faciliter l’intégration), puis quelques jours (3/4 fois par an).
Nous vous proposons
L’équipe IT, sans lead developer, est en lien avec l’équipe R&D ML et l’équipe de veille des marchés. Nous suivons un SCRUM maison, ajusté régulièrement selon nos besoins. Nous discutons ensemble de nos priorités et nous les répartissons à chaque sprint selon les profils et envies de chacun·e.
Vous participerez :
Au développement front de l’application j360 (Vue3/Quasar/Typescript).
Au développement back de j360 (Python/Django/DRF).
À la définition et à l’évolution du design dans le respect de la charte graphique.
À la relecture de code et l’accompagnement vos collègues en leur fournissant du mentorat sur les bonnes pratiques, l’architecture, les design patterns, etc.
En fonction de vos centres d’intérêts :
Au développement du back-end de j360 (Python/Django, PostgreSQL, ElasticSearch).
Au déploiement des applications (Docker/Docker-Compose, Ansible).
Aux scripts de collecte de données (Python/Scrapy).
À la réflexion produit, analyse technique et à la définition des priorités de l’entreprise (Trello).
À l’ajustement de nos méthodes de travail au sein de l’équipe et de l’entreprise.
Avantages :
Horaires flexibles - RTT - Titres-restaurant - Participation au transport - Épargne salariale - Plan d’intéressement et plan épargne entreprise
Télétravail en France possible
Statut cadre en fonction du diplôme/l’expérience ( Syntec)
Processus de recrutement :
CV + présentation de vous et de ce qui vous intéresse à adresser par mail à job @ octopusmind.info
Vous pouvez illustrer vos compétences techniques avec des exemples de projets ou passer notre test technique.
Echanges et précisions par mail ou téléphone avec le dirigeant d’OctopusMind (~ 30 minutes).
Test technique.
Entretien final dans nos bureaux (avec quelques membres de l’équipe IT, ~1h), puis vous serez invité·e à déjeuner avec nous.
Offre (salaire en fonction de l’expérience/niveau)
SVP pas de démarchage pour de l’outsouring ou cabinet RH, merci
Nous recherchons un·e développeur·se avec déjà une première expérience professionnelle significative en Python pour poursuivre le développement de nos services. Avoir également de l’expérience avec Vue, Typescript, Docker ou Ansible est un plus.
Type d’emploi : CDI ou CDD, temps plein ou 4/5, télétravail en France possible.
Ce n’est pas un poste de data scientist.
Qui est OctopusMind ?
OctopusMind, spécialiste de l’Open Data économique, développe des services autour de l’analyse des données. Nous éditons principalement une plateforme mondiale de détection d’appels d’offres : www.j360.info
L’entreprise, d’une dizaine de personnes, développe ses propres outils pour analyser quotidiennement une grande masse de données, en alliant intelligence humaine et artificielle www.octopusmind.info
Nos bureaux, dans le centre ville de Nantes, sont adaptés au télétravail (de 0 à 4 jours par semaine, en fonction des envies de chacun·e).
Un télétravail complet est envisageable, si résidence hors de la région nantaise, sous réserve d’une présence continue en début de contrat (pour faciliter l’intégration), puis quelques jours (3/4 fois par an).
Nous vous proposons
L’équipe IT, sans lead developer, est en lien avec l’équipe R&D ML et l’équipe de veille des marchés. Nous suivons un SCRUM maison, ajusté régulièrement selon nos besoins. Nous discutons ensemble de nos priorités et nous les répartissons à chaque sprint selon les profils et envies de chacun·e.
Vous participerez :
Au développement back de j360 et son back-end (Python/Django, PostgreSQL, ElasticSearch).
Aux scripts de collecte de données (Python/Scrapy).
À la relecture de code et l’accompagnement vos collègues en leur fournissant du mentorat sur les bonnes pratiques, l’architecture, les design patterns, etc.
En fonction de vos centres d’intérêts :
Au développement front de l’application j360 (Vue3/Quasar/Typescript).
Au déploiement des applications (Docker/Docker-Compose, Ansible) et intégration des services R&D (Gitlab CI).
À la réflexion produit, analyse technique et à la définition des priorités de l’entreprise (Trello).
À l’ajustement de nos méthodes de travail au sein de l’équipe et de l’entreprise.
Avantages :
Horaires flexibles - RTT - Titres-restaurant - Participation au transport - Épargne salariale - Plan d’intéressement et plan épargne entreprise
Télétravail en France possible
Statut cadre en fonction du diplôme/l’expérience (Syntec)
Processus de recrutement :
CV + présentation de vous et de ce qui vous intéresse à adresser par mail à job @ octopusmind.info
Vous pouvez illustrer vos compétences techniques avec des exemples de projets ou passer notre test technique.
Echanges et précisions par mail ou téléphone avec le dirigeant d’OctopusMind (~ 30 minutes).
Test technique.
Entretien final dans nos bureaux (avec quelques membres de l’équipe IT, ~1h), puis vous serez invité·e à déjeuner avec nous.
Offre (salaire en fonction de l’expérience/niveau)
SVP pas de démarchage pour de l’outsouring ou cabinet RH, merci
Pour le prochain meetup Python, on se retrouve à 19h dans les locaux de l’IPI Lyon le mercredi 19 octobre.
Benjamin viendra nous parler du métier de développeur à 50 ans !
Poste basé sur l’un des huit bureaux OVHcloud en France.
Département
Nous recherchons une Développeuse Python H/F pour notre département IT, technology & Product qui conçoit et développe les produits, les services, les infrastructures qui construisent ensemble l’avenir d’OVHcloud.
Toujours en quête d’innovation, ces passionnés s’attachent à résoudre des problèmes technologiques complexes.
Vous intégrez l’équipe Object Storage qui a pour ambition de construire l’offre Object Storage la plus performante du marché.
Missions
Rattachée au Team Leader, vous relevez les défis suivants :
Développer les évolutions sur les différents services constituant notre produit, en assurant un haut niveau de performance et en garantissant la qualité, la scalabilité, et l’efficacité des développements réalisés.
Participer aux phases de conception en analysant les besoins et en préconisant les solutions techniques à mettre en œuvre.
Participer à la maintenance corrective du produit.
Rédiger la documentation technique.
Participer aux revues de code.
Participer aux phases de recette du produit.
Chez OVHcloud, nous encourageons l’audace et l’initiative. Au-delà de ces missions, nous attendons donc de vous que vous soyez proactif et que vous participiez à l’amélioration continue de votre périmètre.
Profil
Vous justifiez d’une expérience significative dans le développement de systèmes distribués.
Vous êtes à l’aise en programmation Python et/ou C++.
Vous maitrisez les bonnes pratiques de développement (tests unitaires, code coverage, CI,…).
Vous maitrisez idéalement les outils suivants est importante : MySQL, SQLite, Redis, Zookeeper, Git, Docker, Nginx, Puppet, CircleCI, Travis.
Dotée d’un grand sens du service, vous avez à cœur d’avoir un impact positif sur vos interlocuteurs internes et/ou externes.
Vous êtes ouverte sur le monde et travailler dans un contexte international est un critère important pour vous.
Vous êtes autonome et capable de travailler dans un environnement rapide et challengeant.
Vous voulez utiliser vos talents et votre énergie pour soutenir un projet ambitieux ? Vous êtes au bon endroit.
Oui, je sais que ça peut paraitre bizarre et/ou étrange, mais figurez-vous que j’ai découvert que “gaufre” était à la fois un truc sucré qui se mange et un mammifère qui vit dans des trous. Il s’agit de la traduction (l’orthographe gauphre existe également) du mot “gopher” en anglais.
Tout ça pour dire que j’ai donc créé récemment un serveur gopher (Gopher — Wikipédia) en python3. Pour le moment il s’agit d’un truc minimaliste (moins de 200 lignes de code) mais qui semble tenir le coup.
Je vais y ajouter des morceaux au fur et à mesure, et peut-être également y ajouter d’autres protocoles…
Bonjour,
J’ai un devoir de créer une calculatrice sur Python mais je suis novice en programmation et n’est donc pas toutes les bases.
J’ai réussi à faire l’affichage d’un écran et des boutons mais pour l’instant la calculatrice ne sait pas calculer. J’ai un inconvénient qui est d’apprendre à la calculatrice à faire toutes les opérations (je sais que Python sait les faire, mais pour mon sujet il n’est pas censé savoir les faire), en partant de l’addition, en lui apprenant chaque addition de 0 à 9, si quelqu’un à des idées pourrait - il m’en faire part ?
De plus il faut que j’ajoute un bouton effacé “Del” mais je ne sais pas comment le définir pour qu’il efface l’écran de la calculatrice
Certains logiciels fournissent aussi la possibilité de vérifier la syntaxe des fichiers de configuration qu’ils utilisent. Cela permet d’éviter des erreurs ou interruptions de service dûes à une erreur dans le fichier. Voici trois exemples :
1. Apache
Apache2 fournit apachectl. Si la syntaxe des sites actifs est correcte, la sortie sera :
# apachectl -t
Syntax OK
Avec un fichier de configuration incorrect nommé conte.conf contenant
<VirtualHost a.oree.du.bois:80>
ServerName le.grand.mechant.loup.example
CustomLog /il/etait/une/fois combined
RencontreChaperonRouge on
</VirtualHost>
la sortie sera
# apachectl -t
[Sun Sep 18 22:18:32.305781 2022] [core:error] [pid 14382:tid 139846731306112] (EAI 2)Name or service not known: AH00547: Could not resolve host name a.oree.du.bois -- ignoring!
AH00526: Syntax error on line 4 of /etc/apache2/sites-enabled/conte.conf:
Invalid command 'RencontreChaperonRouge', perhaps misspelled or defined by a module not included in the server configuration
Action '-t' failed.
The Apache error log may have more information.
Attention, les vérifications d’apachectl ne sont pas exhaustives et une erreur peut encore survenir lors du redémarrage du serveur Apache. Ici le chemin vers le fichier n’existe pas mais n’a pas été détecté. Si apachectl -t détecte une erreur, il y a un problème. S’il n’en détecte pas, il n’y a peut-être pas de problème.
(test réalisé avec Apache/2.4.38)
2. OpenSSH
La commande sshd -t exécutée avec des droits root permet de vérifier la validité de la configuration du serveur openSSH (le fichier /etc/ssh/sshd_config sous Debian).
Si le fichier est correct, alors rien n’est affiché et la valeur de sortie est 0.
Avec un fichier sshd_config commençant par :
PetitPotDeBeurre on
Tartiflette off
La sortie sera :
# sshd -t
[sudo] password for stephane:
/etc/ssh/sshd_config: line 1: Bad configuration option: PetitPotDeBeurre
/etc/ssh/sshd_config: line 2: Bad configuration option: Tartiflette
/etc/ssh/sshd_config: terminating, 2 bad configuration options
avec une valeur de sortie de 255.
(test réalisé avec OpenSSH_7.9p1, OpenSSL 1.1.1d)
3. Sudo
Si une erreur est faite dans le fichier /etc/sudoers qui empêche sa relecture par l’exécutable sudo, il devient impossible d’utiliser la commande sudo. visudo permet d’éviter ce désagrément.
Supposons que l’utilisateur ait ajouté à la ligne 12,
Hello MereGrand
puis enregistre le fichier :
% sudo visudo
/etc/sudoers:12:25: erreur de syntaxe
Hello MereGrand
^
Et maintenant ?
Lorsque le fichier est incorrect, trois choix sont possibles :
remodifier le fichier
quitter sans enregistrer
quitter en enregistrant (une déception pourrait arriver peu de temps après)
L’éditeur par défaut utilisé par visudo est vi. Cela est modifiable en paramétrant des variables d’environnement comme $EDITOR. (En réalité, c’est plus compliqué: il y a deux autres variables d’environnement possibles et deux variables de configuration de sudo permettent de modifier de comportement des éditeurs par défaut. man sudo si vous pensez que cette complexité a un intérêt dans votre cas.)
(testé avec visudo version 1.9.5p2, version de la grammaire de visudo : 48)
Faim de loup, fin d’article
Ces outils sont pratiques pour éviter de mettre un service en panne ou s’enfermer dehors. Ils sont complémentaires de vérificateur générique de syntaxe JSON, YAML, etc.
Bonjour,
J’ai compilé python3.10 via make altinstall (/ubuntu 20.04). J’ai bien maintenant python3.10 disponible sur mon PC, cependant pas tkinter.
Comment puis-je avoir tkinter pour ce python3.10 compilé?
Merci.
comme chaque année la PyConFr est gratuite afin d’être ouverte à toutes et tous. Cependant, ce n’est pas gratuit à organiser. Bien que les membres de l’AFPy sont bénévoles, et que les locaux nous sont mis à disposition gratuitement par l’Université de Bordeaux, il reste encore quelques dépenses à faire pour la sécurité, les boissons chaudes et fraîches, le nettoyage, la captation vidéo…
Si vous êtes ou connaissez une entreprise ou une entité qui serait intéressée à sponsoriser une conférence francophone de python, n’hésitez pas à nous contacter à tresorerie@afpy.org
Présentation de l’entreprise (2 min) en conférence plénière (samedi)
-
-
Stand dans le hall
-
-
-
Trois niveaux « Platine » sont également disponibles. Ces niveaux spéciaux comportent les bénéfices du niveau « Or », plus une contrepartie particulière :
Transcription (4000 €)
Votre logo sur l’écran de transcription textuelle et sur les vidéos sous-titrées grâce aux transcriptions.
Boissons et viennoiseries (4000 €)
Votre logo sur les tables accueillant les viennoiseries et les boissons.
Vidéo (6000 €)
Votre logo au début des captations vidéos.
Les contreparties sont effectives dès réception du réglement.
by liZe,Benoît Sibaud,Xavier Teyssier,Ysabeau from Linuxfr.org
WeasyPrint est un générateur de documents qui transforme du HTML/CSS en PDF. C’est écrit en Python, c’est libre (bah oui, sinon on n’en parlerait pas ici), et nous en avions déjà discuté ici il y a quelques années dans un petit article.
Avec le temps (plus de 11 ans depuis le premier commit, que le temps passe vite ma p’tite dame…), le logiciel a gagné une sacrée ribambelle d’utilisateurs avec plus de 750 000 téléchargements par mois. Parmi tous ces gens qui utilisent WeasyPrint, on a forcément rencontré plein de gens avec plein d’idées pour générer plein de drôles de trucs ! Nous avons croisé entre autres des rapports de sécurité informatique 🖥️, des livres de jeu de rôle 🎮️, des tickets 🎫️, des documents scientifiques 🧮️, des factures de sites de vente en ligne 📄️, des compte-rendus biologiques ⚛️, des modes d’emploi de fours 🧑🍳️, des lettres officielles 💌️, des étiquettes électroniques 🏷️, des affiches promotionnelles en pharmacies ⚕️, des diplômes universitaires 🎓️…
Forts de ce petit succès, Lucie Anglade et moi (Guillaume Ayoub) avons créé depuis deux ans une structure qui s’appelle CourtBouillon (oui, parce que notre autre passion est la bonne nourriture) dédiée au développement de WeasyPrint et de ses dépendances. Nous avons donc pu passer beaucoup de temps à travailler sur le logiciel et apporter plein de nouveautés, tout en nous posant beaucoup de questions pour assurer un modèle économique viable. Voilà ce que l’on aimerait partager avec vous.
Depuis le début de l’an dernier, nous avons publié 4 versions majeures qui englobent une bonne liste de fonctionnalités dont voici les plus importantes :
les notes de bas de page,
les coupures de blocs après un certain nombre de lignes (pour que le texte ne dépasse pas de la page),
les coupures forcées ou interdites dans les colonnes,
le respect de la norme PDF/A (pour avoir des documents archivables),
les coupures de pages dans les cellules d’un tableau, les blocs flottants et les blocs absolus,
la gestion des polices bitmap (pratique pour faire des étiquettes électroniques parfaites au pixel près),
l’insertion de points de suite (mais si, vous savez ce que c’est, ce sont les petits points entre le nom d’un chapitre et le numéro de page dans une table des matières),
la génération reproductible de fichiers PDF,
le support des principaux sélecteurs CSS de niveau 4 (comme :is(), :where(), :has()),
sans oublier une génération bien plus rapide et des fichiers générés plus petits.
Nous en avons également profité pour créer pydyf, une bibliothèque bas niveau de génération de PDF, histoire d’avoir les mains libres pour ajouter certaines fonctionnalités. C’était une volonté depuis de longues années (pour supporter le format PDF/A par exemple) mais la spécification PDF a nécessité un peu de temps avant d’être apprivoisée 😉️.
Pour parler de tout cela, nous avons écrit une toute nouvelle documentation que nous espérons mieux organisée et plus claire. Nous avons également rédigé une longue série d’articles avec nos copains de Madcats qui ont créé de très jolis documents dont vous pouvez vous inspirer pour créer les vôtres.
En bref, on n’a pas chômé. Mais où a-t-on trouvé tout ce temps ?
Le temps et l’argent
La raison d’être de CourtBouillon est de créer, développer et maintenir des logiciels libres. Et pour cela, il faut avoir du temps, beaucoup de temps, vraiment beaucoup de temps.
Tout le monde veut toujours plein, plein, plein de fonctionnalités, et nous avons un avantage de ce côté-là : CSS en voit fleurir de nombreuses à un rythme soutenu. Comme nous nous appuyons rigoureusement sur ces spécifications, nous avons donc « juste » à les implémenter. Évidemment, à chaque fois qu’une nouvelle propriété est supportée par les navigateurs, les gens se ruent sur nous pour demander pourquoi WeasyPrint ne la supporte toujours pas alors que Chrome et Firefox la gèrent très bien depuis au moins 2 semaines (j’éxagère à peine 😁️). Pour la faire court : ça prend du temps.
Au-delà du code et de ses fonctionnalités, nous passons des jours entiers à trier les tickets, répondre aux questions, tweeter, écrire des articles, corriger des bugs et peaufiner la documentation. Ce travail est peu visible mais il prend bien plus de temps que ce que la plupart des utilisatrices et des utilisateurs imaginent. C’est pourtant un travail de fond nécessaire pour garder nos projets en bonne santé et ne pas crouler rapidement sous les demandes insatisfaites.
Encore au-delà ce travail peu valorisé se cache tout le travail de l’ombre que l’on ne voit pas du tout. Lire des spécifications, que ce soit pour CSS ou PDF, est devenu une seconde nature pour nous, et nous nous sommes habitués au langage étrange que l’on trouve dans ces documents. Certaines rumeurs disent même que nous en rêvons la nuit… Nous devons également faire particulièrement attention à la qualité du code. Nous sommes une toute petite équipe et nous avons, mine de rien, à maintenir un moteur de rendu HTML/CSS… Il est par conséquent très important de s’assurer au quotidien que la dette technique ne s’accumule pas et que l’architecture globale est toujours bien solide, sous peine de se retrouver sous l’eau dans le futur à l’ajout de la moindre fonctionnalité. Au-delà de l’interminable suite de tests (car oui, dans WeasyPrint nous avons plus de lignes de Python pour les tests que pour le code), il est nécessaire de retoucher l’architecture de nos bibliothèques de temps en temps, tout comme nous devons supporter les dernières versions de Python et des diverses dépendances que nous avons.
Pour avoir tout ce temps et en même temps gagner quelque argent pour manger (parce qu’on aime beaucoup ça, je vous le rappelle), nous fournissons divers services à des clients utilisateurs un peu partout dans le monde. Certaines fonctionnalités sont ainsi payées par des entreprises qui ont des besoins spécifiques et sont ensuite ravies d’avoir une belle version toute neuve qui répond parfaitement à leurs besoins. D’autres nous contactent pour avoir de l’aide à la création de documents, nous nous occupons alors de créer du HTML et du CSS aux petits oignons (miam) en accord avec leurs maquettes et leur charte graphique. Nous avons enfin un système de sponsoring et de dons qui ouvre droit à afficher un beau logo sur notre site et à avoir un support prioritaire par mail pour les questions techniques.
Et pour l’instant, ça marche.
Le futur
Même si CourtBouillon est jeune, nous arrivons actuellement à vivre en passant la grande majorité de notre temps de travail sur le libre.
Bien sûr, c’est une situation extrêmement grisante et souvent très épanouissante : qui n’a jamais rêvé de vivre du libre dans ce bon vieux repaire de libristes extrémistes qu’est LinuxFR 😍️ ? Nous avons travaillé notre communication pour toucher des personnes qui partagent nos valeurs, ce qui nous a amenés à rencontrer des gens absolument formidables. Nous avons pu croiser la route de clients disséminés un peu partout dans le monde, nous ouvrir à des problématiques que nous ne connaissions pas et apporter notre aide à des personnes pour lesquelles nous avons beaucoup d’estime et de sympathie…
Il y a bien sûr des contreparties à tout ce bonheur. Au niveau financier, si l’activité actuelle nous permet de nous rémunérer (et c’est déjà appréciable au bout de deux ans), nous sommes loin des standards auxquels nous pourrions postuler en tant qu’ingénieurs en informatique. Nos sponsors et nos clients nous apportent aujourd’hui la majorité de nos revenus, nous sommes donc évidemment soumis aux aléas de la demande avec une alternance de semaines chargées lorsque nous avons beaucoup de clients et des semaines plus creuses où nous pouvons nous atteler au travail invisible. Nous essayons donc au maximum de développer les dons et les sponsors récurrents pour assurer autant que possible la stabilité de notre modèle.
Au niveau des fonctionnalités qui arrivent (parce que c’est ça qui intéresse les gens, hein !), nous avons ouvert un sondage pour mieux connaître les besoins attendus. Celui de l’an dernier nous avait éclairés sur les points à traiter en priorité, nous avons donc pu mettre notre énergie au service des attentes les plus grandes… et bien sûr des clients qui ont gracieusement financé certains de ces développements ! Plusieurs fonctionnalités toutes fraîches sont déjà bien avancées : nous proposerons par exemple dans les prochains mois la possibilité de générer des fichiers PDF plus accessibles (avec le support partiel de PDF/UA) et le support des polices variables.
Et un jour, peut-être, nous pourrons enfin nous lancer à corps perdu dans le support de CSS Grid… si le temps nous le permet 😀️.
En attendant la suite
En attendant la suite des aventures, n’hésitez pas à nous suivre, à jeter un coup d’œil à WeasyPrint si vous ne l’avez jamais essayé, à ouvrir des tickets pour râler si vous rencontrez des problèmes, à nous soutenir si vous aimez ce que l’on fait, et à nous solliciter si vous avez des envies particulières.
Pour celles et ceux qui sont moins intéressés par le côté technique, nous sommes également ouverts pour discuter de gestion de projets libres, du lien à la communauté, de modèles économiques, et de tout ce qui pourrait vous intéresser sur le sujet !
Nous recherchons une nouvelle ou un nouveau camarade pour développer
avec nous une application de suivi énergétique à destination des
professionnels : collecter des données (factures fournisseurs, données
de consommation des distributeurs / capteurs, données de météo, etc)
pour les brosser, les croiser, bref, les rendre fiables,
compréhensibles, puis de les exploiter pour détecter les dérives, faire
des plans d’actions et afficher de beaux tableaux de bords dans le
navigateur de nos clients. Nous ne manquons pas d’occasion de nous
intéresser à des sujets tant pointus techniquement que d’actualité.
Nous appliquons au quotidien les principes agiles et les bonnes
pratiques du développement (gestion de sources distribuée, revue de code
par les pairs, intégration continue, etc).
Nous sommes basés autour de Toulouse et télé-travaillons majoritairement
(coworking 1 à 2 jours par semaine). Temps partiel et télétravail total
possible selon profil.
Profil
Nous recherchons une développeuse ou un développeur expérimentée,
capable de maintenir, développer et prendre des initiatives sur la
partie frond-end. Vous serez néanmoins amené à travailler sur l’ensemble
de l’application ainsi que sur les projets clients l’utilisant.
L’autonomie, la capacité à travailler en équipe et à intéragir avec les
clients sont indispensables.
Notre plateforme de suivi énergétique est construite sur une pile de
technologies libres dont il faudra maîtriser tout ou partie sur un poste
sous linux :
python (fastapi, pandas) / postgresql / kubernetes pour le back-end,
typescript / react (mui, echarts) pour le front-end.
Entreprise et philosophie
Lowatt est une jeune société, créée en 2018 qui accompagne ses clients
vers des économies d’énergies.
Nous hébergeons nous même notre plateforme et utilisons uniquement des
logiciels libres pour nos besoins quotidiens : element/matrix,
nextcloud, jenkins, vault, wekan, odoo pour ne citer qu’eux.
Nous proposons un cadre de travail attractif et motivant, avec des
valeurs d’ouverture et de partage. Nous sommes également attachés à la
transparence et offrons des possiblités d’implications en dehors du
cadre purement technique.
Je suis retraité depuis Janvier 2022, et j’ai un peu décroché.
Mais je fais une initiation pour un proche, on n’habite pas la meme ville, et je voudrais poursuivre cette initiation en remote.
Je cherche une solution facile à mettre en place pour partager un interpréteur, ipython de préférence, autre sinon.
Mon élève est sous windows, sinon screen aurait pu etre le bon support (je suis moi sous linux).
Jupiterlab: un peu trop lourd à mettre en place.
J’ai fait de telles sessions partagées, sur un interpréteur situé sur un site web, mais je ne sais plus ou.
Une idée, quelqu’un?
Je n’ai pas de vm sur le net, je ne suis pas à l’aise avec l’ouverture de mon firewall (freebox) à l’extérieur, utiliser un interpréteur mis à disposition par une communeauté serait l’idéal.
Merci!
Bon je peux ouvrir mon firewall
J'ai découvert l'ellipsis operator de python (...). Dans le contexte où je l'utilise, c'est équivalent à pass, autrement dit ne rien faire. C'est utilisé principalement pour quand python attend qu'un bloc syntaxique soit rempli (corps d'une fonction, d'une boucle, …), mais qu'on a vraiment rien à y faire. Je trouve que ça permet de faire des interfaces plus élégantes.
La perte de l'exception n'est pas un problème car elle n'est de toute façon jamais lancé, abc (Abstract Base Classes, module python ajoutant les notions de classes abstraites et d'interfaces s'occupant d'en lancer une automatiquement:
$ ipython
Python 3.10.6 (main, Aug 3 2022, 17:39:45) [GCC 12.1.1 20220730]
Type 'copyright', 'credits' or 'license' for more information
IPython 8.4.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: from abc import ABC, abstractmethod
...:
...: class CarElementVisitor(ABC):
...: @abstractmethod
...: def visitBody(self, element):
...: ...
...:
...: @abstractmethod
...: def visitEngine(self, element):
...: ...
...:
...: @abstractmethod
...: def visitWheel(self, element):
...: ...
...:
...: @abstractmethod
...: def visitCar(self, element):
...: ...
...:
In [2]: CarElementVisitor()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [2], in <cell line: 1>()
----> 1 CarElementVisitor()
TypeError: Can't instantiate abstract class CarElementVisitor with abstract methods visitBody, visitCar, visitEngine, visitWheel
Bonjour à tous,
Je souhaite absolument faire la meilleure formation python possible. Pouvez-vous me conseiller les meilleurs organismes SVP ? Je suis directeur logistique et ai créé un super outil hyper performant qui apporte une solution logistique globale dans mon entreprise (Groupe national de +ieurs usines). Je n'ai aucune formation informatique et j'ai fait ça avec VBA que j'ai appris seul. J'y ai pris beaucoup de plaisir et aimerai apprendre à programmer "pour de vrai lol" et créer mes propres solutions logistiques. Merci beaucoup pour vos conseils.
Vous le savez peut-être déjà, avec @liZe on développe WeasyPrint.
C’est une librairie écrite en Python (bien sûr), qui permet de convertir des documents HTML/CSS en magnifiques PDFs :).
Il y a deux ans on s’était regroupé sous le nom CourtBouillon pour s’en occuper comme il faut, et en vue de cet anniversaire des deux ans, on a lancé un nouveau sondage pour connaître mieux les usages et attentes sur WeasyPrint et aussi pour évaluer un peu notre com sur CourtBouillon.
Donc si vous êtes utilisateur (en pro ou en perso) de WeasyPrint (ou d’un autre projet CourtBouillon), hésitez pas à répondre au sondage, il est ouvert jusqu’au 10 octobre.
Vous intégrez l’équipe CTI du CERT dédiée au développement et à la maintenance d’une offre SaaS de Threat Intelligence commercialisée depuis 2020. Le service a pour mission de récupérer, en temps réel, des millions de données afin qu’elles soient contextualisées, agrégées, corrélées et scorées afin de protéger nos clients. La connaissance du domaine cybersécurité et de la Threat Intelligence sont un plus.
La plateforme est basée sur des technologies Big Data telles que ElasticSearch, Apache Kafka & Cassandra, ArangoDB, Redis, PostgreSQL et MongoDB ainsi que des process et outils de CI/CD tels que Jenkins, et Docker.
Le cœur de la plateforme est développé en langage Python.
Vous intégrerez l’équipe OCD en tant que lead developer. Le service est développé en suivant la méthodologie et un cadre agile mature. Il est soutenu par une quinzaine de développeurs à temps plein sur l’ensemble des composants.
Pour cela, vous participerez aux développements :
· En coordonnant les études techniques associées aux évolutions du service en concertation avec les développeurs
· En participant au développement et au design des nouveaux composants ainsi que l’évolution des composants existants
· En garantissant le suivi et le respect des bonnes pratiques et critères de qualité du code (tests unitaires, fonctionnels, revue de code, etc.)
· En garantissant le maintien en conditions opérationnelles de la plateforme via du monitoring, de la maintenance préventive et si nécessaire des hotfix
· En anticipant les problématiques de scalabilité et de résilience
· En participant aux recettes et mise en production
Et pourquoi vous ?
Vous êtes diplômés d’un bac+3 minimum et vous disposez de 3 à 4 ans d’expérience réussie en tant que développeur.
Vous disposez de compétences avancées sur les technologies Python, ElasticSearch et Docker.
La connaissance d’autres technologies utilisées par le projet, ou du domaine de la cybersécurité et la Threat Intelligence sont un plus.
Votre niveau d’aisance en anglais doit vous permettre d’échanger de manière quotidienne à l’oral comme à l’écrit sur le projet.
Capable d’analyser des problèmes non structurés, vous savez être force de proposition sur les solutions à mettre en place.
Autonome et motivé(e), vous savez faire preuve de curiosité et de créativité pour contribuer à notre innovation.
Et si vous avez un attrait pour le secteur de la cybersécurité ou l’envie d’en découvrir plus, c’est encore mieux.
Le poste, basé de préférence à Lyon (69) peut également être ouvert à La Défense (92) et est à pourvoir dès à présent.
by franckdev,Julien Jorge,Benoît Sibaud,Pierre Jarillon,Ysabeau from Linuxfr.org
La conférence Mercurial Paris 2022, est une conférence internationale dédiée au gestionnaire de version Open Source Mercurial. Elle se tiendra fin septembre 2022 à Paris, Université Paris Sorbonne.
Mercurial est un gestionnaire de versions, libre et multi-plateforme, qui aide les équipes à collaborer sur des documents tout en conservant l’historique de l’ensemble des modifications. Équivalent fonctionnellement aux biens connus Git ou Svn, il s’en distingue sur de nombreux points techniques, ergonomiques et pratiques.
Doté d’une interface orientée utilisateur facile d’accès et simple à comprendre, il offre des capacités avancées de personnalisation du workflow et s’illustre aussitôt qu’il y a besoin de performances adaptées aux très gros dépôts. (Les équipes de Google et Facebook utilisent en interne des solutions basées sur Mercurial pour gérer l’ensemble de leur code source.).
Après une première édition en 2019, l’équipe d’Octobus aidée de Marla Da Silva, organisent cette nouvelle mouture qui se déroulera du 21 au 23 septembre dans les locaux de l’Irill (Initiative de Recherche et Innovation sur le Logiciel Libre), Université Sorbonne, Paris.
La participation à l'évènement nécessite votre contribution pour absorber les frais d'organisation. 40€ pour la journée de workshop, 40€ pour la journée de conférence, repas du midi compris. Les sprints sont gratuits. Réserver mon ticket.
Si vous avez un statut étudiant et n'avez pas le budget pour participer aux trois jours, contactez-nous.
Vous trouverez l’ensemble des informations sur le site https://mercurial.paris dont voici le programme résumé :
Mercredi 21 septembre, Workshops
La première journée sera dédiée aux ateliers. L’occasion de découvrir, se former, évoluer sur le sujet.
Mercurial usage and workflow
Heptapod: Using Mercurial with the GitLab DevOps platform
Jeudi 22 septembre, Talks
Présentations d’experts internationaux et retours d’expérience en entreprise.
Stability and innovation
Mercurial and Logilab
Using Mercurial, evolve and hg-git in an academic context
Mercurial usage at XCG Consulting
XEmacs and Mercurial: fifteen years of good experiences
Toolings
Heptapod, three years of Mercurial in GitLab and growing
Lairucrem presentation
Mercurial at Scale
How Mercurial is used to develop Tryton
Mercurial usage at Nokia: scaling up to multi-gigabyte repositories with hundreds of developers for fun and games
Mercurial usage at Google
Development Update
Mercurial Performance / Rust
State of changeset evolution
Vendredi 23 septembre, Sprints
Enfin, le vendredi 23 se dérouleront les “sprints”, groupes de travail pour faire évoluer Mercurial, sa documentation, son eco-système, etc. Pour toute personne contributrice, développeuse expérimentée ou simplement curieuse, c’est le moment de contribuer !
À propos d'Octobus
Octobus est une société de service française dédiée au logiciel libre, spécialiste des langages Rust et Python, son équipe totalise le plus grand nombre de contributions au logiciel Mercurial dont elle maintient l’infrastructure de développement et est en charge de la distribution des nouvelles versions.
Octobus est également éditrice de la solution Heptapod, forge logicielle libre prenant en charge Mercurial Hg mais aussi Git. Une solution d’hébergement en France clef en main est également proposée en partenariat avec Clever Cloud. Une instance publique dédiée à l'hébergement de logiciels libres est disponible sur foss.heptapod.net (pour y soumettre).
Comme vous le savez peut-être, la prochaine PyConFr devrait avoir lieu en février 2023 à Bordeaux (on a encore quelques points de détails à régler avant d’annoncer officiellement les dates) !
Dans cette optique on va remettre au goût du jour le site de la PyConFr et on serait à la recherche d’une personne avec des talents de graphiste pour travailler sur le logo de cette nouvelle édition.
Voici donc un démineur en Python, en mode textuel et graphique Tk.
En mode textuel, il faut prendre la main en interactif après avoir exécuté demineur.py
>>> explorer((5,5))
False
>>> print_cases()
__________________________1X1___
________111_______111_____1X1___
______113X2_______1X1_____111___
______1XXX2_______111___________
11____11211_____________________
X1______________________________
11___________________111________
_____________________1X1________
_____________111_____111________
_____________1X1________________
_____________111________________
________________________________
________________________________
111_____________111_____________
XX1_____________1X1_____________
XX1_____________1X1_____________
Sur les 10 bombes, il vous en reste 10 à trouver.
demineur-g.py permet d’avoir une interface graphique. Le nombre de bombes se trouve indiqué dans la barre de titre.
Je l’ai fait dans le cadre du cours que je commence à donner à mes élèves pour apprendre Python.
Moi-même j’apprends le langage depuis peu. Il y a donc certainement plein d’améliorations à faire sur ce code. Je compte sur vos commentaires pour m’aider à améliorer celui-ci.
Je pense devoir faire une version sans récursivité car avec de trop grands terrains, Python atteint une limite… À moins qu’il ne soit possible (dans le code-même ?) de paramétrer cette limite ?
Bien entendu, d’un point de vue didactique, cela doit rester simple, pas trop long, etc.
Note: ceci est la traduction de ce billet de mon blog, avec plus de blagues reloues dedans parce que je suis quand même plus à l'aise en français.
Après un an et demi de travail ~acharné (presque autant que pour un album d'Asterix), une très longue pause et quelques ré-écritures, c'est avec joie et fierté que je vous annonce une nouvelle révolution dans le monde de l'informatique, et dans l'histoire de l'humanité en général, la sortie de la première bêta de Slidge.
Slidge? Kekecé?
Slidge te permet d'utiliser ton client XMPP habituel pour parler à tes potes qui n'ont pas encore entendu parler de notre seigneur et sauveur XMPP et qui utilisent d'autres réseaux de messagerie instantanés "historiques". C'est un composant serveur XMPP, qui se comporte comme un client alternatif pour l'autre réseau tout pourri (=pas XMPP), en utilisant ton compte sur cet autre réseau. Tes potes "historiques" ont un "JID marionnette" (gros-naze@msn.example.com) et tu leur parles en oubliant que ces nazes t'ont dit que tu étais relou la dernière fois que tu as entamé ta diatribe sur les protocoles ouverts, la décentralisation, et Meta qui tue des bébés phoques; et qu'ils ont refusé d'essayer Quicksy sur leur ordiphone.
Slidge à proprement parler n'est en réalité qu'une bibliothèque, et n'est utile pour un utilisateur final qu'à travers ses plugins. Bonne nouvelle, il existe déjà des plugins pour 7 différents réseaux tout pourris (+ 1 pour être notifié de réponses à ses commentaires sur hackernews, mais c'est vraiment un gadget).
Mais pourquoi tu as fait ça?
Après avoir découvert la messagerie instantané avec mIRC, ICQ et ensuite MSN dans les années 90/début 2000, j'ai été émerveillé par pigdin et j'en ai été un utilisateur ravi pendant des années (et j'ai sacrément impressionné du monde avec son mode "madame Irma").
Mais depuis quelques années, depuis que j'ai finalement cédé aux sirènes de la téléphonie mobile intelligente, j'étais assez frustré de ne pas avoir la même chose, mais en mode "multi périphériques" (waou).
Heureusement, c'est possible -théoriquement- avec les passerelles XMPP, mais à part l'excellent biboumi pour IRC, ça n'a jamais marché aussi bien que j'aurais voulu, pour les réseaux tout pourris qui m'intéressent, du moins. Spectrum2 est le logiciel généralement recommandé pour les passerelles XMPP, mais il n'est plus tellement mis à jour et notamment, ne compte pas implémenter les nouveaux trucs modernes™ comme les réactions aux messages (que je trouve pas aussi inutiles qu'elles n'y paraissent à première vue; seul movim les implémente à ma connaissance, j'espère que d'autres clients suivront).
Mais ça marche vraiment?
Pour moi oui.
Mais pour l'instant que pour les messages directs; les groupes devraient faire partie de la version 0.2.0, un jour.
Je serais ravi si vous le testiez chez vous et/ou que vous jetiez un œil au code source. Je suis avide de retours de tout types, rapports de bogue comme critiques sur l'implémentation, les technos utilisées, le style, n'importe quoi ! Écrire du code un peu moins dégueu est une des raisons qui m'ont poussé à m'investir dans ce projet, et je suis pas susceptible (enfin pas trop, quoi).
Des détails techniques
Slidge est écrit en python asynchrone, avec slixmpp. J'essaye d'y utiliser mypy de manière intelligente, et y a même quelques tests (trop peu…) qui se lancent avec pytest.
Mon plan c'est de rendre l'écriture de plugins facile avec l'interface des plugins, qui devrait raisonnablement abstraire les spécificités de XMPP et exposer des méthodes et classes faciles à utiliser. Normalement, grâce à la richesse de l'écosystème python, les plugins ne devraient être que de fines couches entre bibliothèques spécifiques à un réseau tout pourri et l'interface des plugins.
Faire ça est une très bonne idée, comme ça vous aurez déjà votre environnement de développement tout prêt pour réparer le bug que vous avez trouvé et/ou implémenter une nouvelle fonctionnalité. ;-)
Débutant voir même, extrêmement novice avec Python, je viens de réussir à créer et alimenter via une BDD une QTableWidget.
Certes, mon code est certainement loin d’être parfait mais pour le moment, il fonctionne plus ou moins.
Pour des raisons d’esthétisme, j’utilise une feuille de style CSS qui, ajoute une image lors de la coche des QCheckBox.
Si je vous parle de ça ! C’est tout simplement parce que j’ajoute à la QTableWidget, l’objet QCheckBox avec un appel de fonction lors du clique sur celle-ci.
L’appel de la fonction lors du clique fonctionne correctement, cependant, pour les besoins de mon utilisation, je n’arrive pas à récupérer le n° de la ligne où est située la QCheckBox qui vient d’être cochée.
Je vous note ci-dessous le code pour que cela soit le plus compréhensible pour vous.
# boucle de lecture de la requête
try:
while self.query.next():
# widget checkbox
checkbox_widget = QWidget()
checkbox_widget.setStyleSheet('background-color: transparent;')
layout_cb = QtWidgets.QHBoxLayout(checkbox_widget)
self.table_ep_cb = QtWidgets.QCheckBox()
layout_cb.addWidget(self.table_ep_cb)
layout_cb.setAlignment(Qt.AlignmentFlag.AlignCenter)
layout_cb.setContentsMargins(0, 0, 0, 0)
checkbox_widget.setLayout(layout_cb)
tablerow = self.table_ep.rowCount()
self.table_ep.insertRow(tablerow)
self.table_ep.setItem(tablerow, 0, QtWidgets.QTableWidgetItem((self.query.value('col1'))))
self.table_ep.setItem(tablerow, 1, QtWidgets.QTableWidgetItem((self.query.value('col2'))))
self.table_ep.setItem(tablerow, 2, QtWidgets.QTableWidgetItem((self.query.value('col3'))))
self.table_ep.setItem(tablerow, 3, QtWidgets.QTableWidgetItem((str(self.query.value('col4')))))
self.table_ep.setItem(tablerow, 4, QtWidgets.QTableWidgetItem((str(self.query.value('col5')))))
self.table_ep.setItem(tablerow, 5, QtWidgets.QTableWidgetItem((str(self.query.value('col6')))))
self.table_ep.setItem(tablerow, 6, QtWidgets.QTableWidgetItem((self.query.value('col7'))))
self.table_ep.setItem(tablerow, 7, QtWidgets.QTableWidgetItem((str(self.query.value('col8')))))
self.table_ep.setItem(tablerow, 8, QtWidgets.QTableWidgetItem((str(self.query.value('col9')))))
self.table_ep.setCellWidget(tablerow, 9, checkbox_widget)
self.table_ep.resizeRowsToContents()
self.table_ep_cb.stateChanged.connect(self._itemClicked)
except self.query.lastError() as error:
print("Erreur de chargement de la requête SQL", error)
self.query.finish()
Si vous pouvez être intéressés par intervenir en donnant des TD ou TP de programmation en Python à l’université de Saint-Étienne (UJM, Fac. des sciences, Licence 1 principalement), contactez moi pour les détails !
Il y a des possibilités aussi au premier ou second semestre.
Merci de faire tourner le message aux gens qui pourraient être intéressés autours de vous.
Il est de bon ton de nos jours pour chaque langage de programmation qui se respecte de débarquer avec un système intégré de dépendances (ou plusieurs, mais nous y reviendrons) permettant plus ou moins automatiquement de télécharger des paquets logiciels. Souvent, il est possible de faire tourner un dépôt de paquets en interne, où l'on pourra d'une part cacher ses dépendances externes, et d'autre part envoyer ses propres paquets. L'on nommera Maven pour Java, Npm pour Javascript, Cpan pour Perl, Cargo pour Rust, Opam pour Ocaml, et même Conan pour C++ (je vais me laver la bouche au savon et je reviens). Et Pip et Conda pour Python.
J'essaie d'aimer le Python. J'essaie vraiment fort. C'est juste Python qui ne m'aime pas. Et en particulier la daube infecte qu'est Conda, Miniconda, Mamba et tous leurs amis.
Déjà, le concept d'environnement. Alors ça semble vachement malin sur le papier, pouvoir dire "aujourd'hui, je mets ma casquette de data scientist, je veux Panda, Keras, et Numpy, bim, je charge l'environnement kivabien, demain je mettrai ma casquette de webdev, et je voudrai Flask et Selenium". Sauf qu'en pratique, c'est vite le bordel, dans quel environnement je suis, comment j'en change, qu'est-ce qu'il y a dedans, comment je le mets à jour. Au point que Conda décide sans rien me demander d'aller bidouiller mon prompt pour y ajouter le nom de l'environnement courant. Non mais de quoi je me mêle ? Ça va vite être un mélasse sans nom si chaque technologique que j'utilise décide d'aller se torcher dans mon .bashrc !
Ensuite, histoire que ça marche chez tout le monde, mon équipe a mis en place des environnement partagés, c'est à dire que quand je récupère la dernière version de notre code source, régulièrement y'a des scripts qui pètent, et il faut simplement aller faire tourner une bordée de scripts moches qui vont aligner l'environnement sur ma machine. Quand ça marche.
Finalement, bien sûr, ce tas de bouse se retrouve à partir en Prod. Et comme une certaine catégorie de développeurs a décidé que la modernité, c'était d'aller chercher des petites briques partout et de les combiner de manière plus ou moins heureuse parce que ça ressemble furieusement à une compétition de qui aura le plus de dépendances, on se retrouve avec des petits scripts tout simples qui ne peuvent s'empêcher d'aller appeler un obscur paquet Python pour faire quelque chose qui tenait en une ligne de bash. Et qui débarquent avec toutes leur dépendances à la noix. Bon, et puis, ces paquets, ils sont sûrs ? Ils ont des bugs ? Est-ce que la mise à jour risque de causer des problèmes ? On s'en tamponne, #YOLO !
Pouf pouf.
Ne prenons pas les enfants du bon dieu pour des canards sauvages. Les gens qui ont développé ces trucs savaient ce qu'ils faisaient, du moins je l'espère : il s'agit à mon sens d'une approche très monoposte (et monolangage) du développement, justement d'une manière très data scientist, comme on dit. Je bidouille un truc dans mon notebook Jupyter, tiens, je ferais bien tel traitement, une ligne de commande et hop, j'ai téléchargé la chose, je teste, ça marche, super, ça marche pas, je teste autre chose. Mais le raisonnement ne tient plus lorsqu'il s'agit d'utiliser le Python comme langage de script secondaire, en équipe, et de déployer des services un poil stables en production.
Je ne connais pas la solution parfaite. Les paquets système (RPM, deb) sont stables, testés, et mis à jour de manière intelligente, mais parfois on a besoin d'une version plus récente. Faire ses propres paquets systèmes et les charger dans un Docker ou un Puppet semble bien, mais c'est un investissement en temps (et en larmes). Les systèmes de paquets liés à un langage en particulier sont vite invivables, moches et instables et pètent quand ils veulent.
Donc, allez vous faire voir, Mabma, Conda, et tous vos amis. Et non, chef, je refuse catégoriquement d'intégrer Conan à notre base de code C++ juste parce que "les systèmes de dépendances, c'est le futur", parce que là ça juste marche, alors pas touche.
Alors, s'il vous plaît, dites moi comment vous faites pour échapper à l'enfer des dépendances.
NordVpn ne délivre pas de GUI pour linux, contrairement à Windows. Mais il fournit un utilitaire et une liste de commandes qui permettent de faire fonctionner correctement ce VPN. Pour les amateurs de la ligne de commande, cela est suffisant.
Pour les autres : ce programme Python3 ne fait que composer et lancer lui-même ces commandes en présentant des fenêtres de choix (choix du pays et de la ville de sortie du VPN, choix de la technologie OpenVpn ou Nordlynx, Obfuscation du serveur, Killswitch, autoconnect) dans lesquelles il suffit de cliquer pour ouvrir le VPN NordVpn.
Ce programme ne peut intéresser que ceux qui utilisent sous linux NordVpn. Il fonctionne bien sous Debian, Mint, Kubuntu.
Mais mais mais … : je ne suis pas programmeur, et débutant en Python3 TK. Une relecture et des conseils seraient bien utiles. Comment partager et montrer le source ?
Programme Python3 (linux) pour modifier, ajouter, supprimer, créer des lignes de boot_loaders dans la NVRAM d’un PC multi-système. Ce programme fonctionne très bien sur des PC et vieil Appel avec OS Debian, Mint, Kubuntu. Il permet en particulier de replacer en tête de liste de NVRAM le loader qu’une installation de Grub ou de Windows10 ou Windows 11 a repoussé en seconde position, sans passer par le BIOS. En fait, il compose et lance les commandes “efibootmgr” qui sinon auraient dû être laborieusement écrites et lancées dans un terminal avec de forts risques d’erreurs graves (exemple : sur un PC comportant 2 SSD et 3 HDD, systèmes, CM Asus, systèmes Win10, Mint, Debian, Win 11, et lanceur habituel Refind)
Mais mais mais… je suis débutant autodidacte en programmation Python et pas du tout programmeur. Une relecture et des conseils seraient bienvenus. Comment partager le code et montrer les ScreenShots ?
Environ 50% des participants actuels sur Debian ne programment pas en Python; c’est l’occasion d’associer à ce sondage une ou deux réponses de remerciements tout en faisant la promotion de l’activité principale de l’AFPy par une ligne ou deux.
Pas de doute, pour beaucoup de développeurs, il y a une complémentarité dans les deux sens entre ce forum et celui sur https://www.debian-fr.org !
by nojhan,Benoît Sibaud,Florent Zara from Linuxfr.org
Tunnelmon, un moniteur de tunnels sécurisés SSH, sort en version 1.1. Il est publié sous GPLv3. Le code est en Python.
Il propose une interface de supervision et de gestion des tunnels SSH s'exécutant sur un système.
Il peut afficher soit une liste des tunnels sur la sortie standard, soit une interface interactive en mode texte dans le terminal.
Il peut également afficher la liste des connexions réseaux issues de chaque tunnel et leur état.
Tunnelmon gère aussi les tunnels mis en place avec autossh, une application qui peut redémarrer automatiquement vos tunnels en déroute.
Avec cette version 1.1, il gère maintenant les trois méthodes de redirection de ports proposées par SSH.
Il s’agit d’un court site web ludique dédié à l’apprentissage de la programmation en Python, et adapté à des débutants complets comme des enfants ayant déjà découvert Scratch.
Ce projet est issu d’une thèse en didactique de l’informatique portant sur l’enseignement-apprentissage de la programmation informatique dans l’enseignement secondaire.
J’ai contacté l’auteur à propos des sources et de la licence logicielle, et il m’a répondu ceci :
Concernant le code source, il est pour l’instant dans un repository privé sur GitHub. Je diffuserai le code en GPL quand je trouverai le temps de le faire. Cette année, je suis sur la rédaction de mon manuscrit de thèse donc je suis bien occupé.
Je vous encourage en tout cas à tester le site, il est très amusant et bien conçu, et à partager cette belle ressource pédagogique autour de vous !
J'ai commencé il y a peu (une semaine), une autoformation sur Python (avec l'aide Pluralsight).
Je pense avoir compris les bases, mais je bute principalement sur la recherche de documentations.
Premièrement, je n'arrive pas à trouver un équivalent des man pour les modules python. Ça me semble quand même plus simple de ne pas sortir de mon terminal.
Genre ce qui m’intéresse, c'est de trouver la documentation de sys.path.insert(). Or dans la doc Python pour ce module, je ne trouve pas la référence à la méthode insert().
J'ai vu que la méthode existait bien pour ce module :
Bon OK, finalement je m'en sortirai avec ça. Mais finalement, y a-t-il une documentation facilement accessible (dans mon terminal) sur Python quand on débute ?
Bonjour'nal
Il y a quelques temps je me suis décidé a monter un blog perso pour raconter quelques idées que j'ai en tête. Je me suis donc mis en quête d'un outil qui me conviendrait.
Je ne voulais pas d'un mastodonte lié à une BDD, mes besoins étant modeste je voulais quelque chose de léger et hébergable facilement. Donc j'ai assez rapidement exclu les Wordpress, DotClear et autre supertanker du domaine.
J'ai jeté un œil aux «Flat file CMS», tel que Grav. Ils sont sympa avec une jolie interface mais requière PHP pour fonctionner. Pas insurmontable pour l'hébergement, mais je voulais quelque chose d'encore plus simple.
C'est aussi à ce moment que je me suis posé des questions sur la pérennité de ce que j'allais produire. C'est à dire sous quel format ma production allait être stocké. Mes besoin n'étant pas immense du Markdown me paraissait tout à fait suffisant, mais en grattant un peu j'ai découvert «ReStructuredText» qui semble plus poussé et un peu mieux normalisé. Cette deuxième possibilité entrait en ligne de compte sans être discriminatoire.
Enfin j'arrête mon choix sur un «Static Site Generator», tout se passe en fichier plat avec une phase de construction pour obtenir du pur HTML. Avantage non négligeable, pas de sécurité a prendre en compte, ce qui m'allait bien. En plus avec les «worker» Git[lab|hub] et leur possibilité de «pages», il est possible avec un commit sur un dépôt d'automatisé la génération et publication, TOP !
Passons aux choses sérieuses, quel produit prendre. Je vous passe les heures de recherche (merci Jamstack pour finalement opter pour «Pelican». Pourquoi ? Parce que je suis plus a l'aise avec du Python que du Go. Donc même si Hugo a le vent en poupe avec des performance largement supérieur, mes petits besoins n'ont pas besoin de grosse perfs.
Et me voilà partis a essayer de monter tout ça. Je passe un temps certains a me battre avec l'automatisation sous Gitlab (le modèle proposé faisait des choix «étrange», heureusement corrigé maintenant) et je regarde les thèmes proposés. Première déception : ils sont datés, et pas qu'un peu pour certains, sans compter ceux qui ne sont même plus fonctionnel :-(
J'arrive tout de même a en trouver un a mon goût et le test, malheureusement il n'est qu'a moitié fait et remonte des erreurs. Je me dit que je vais pouvoir ajouter ma pierre a l'édifice en corrigeant ça et terminant le travail. La correction est finalement assez trivial et j'en profite pour faire quelques retouches. Je découvre aussi la source du thème et voie qu'il y a mieux. Donc je me dit que je pourrais repartir de zéro sur un thème encore plus joli !
Je monte donc un environnement pour faire tout ça, récupère tout ce qu'il faut et commence à m'atteler à la tâche. Je découvre un peu plus Jinja pour le templating, que je trouve assez bien fait et intuitif. En dédupliquant le code HTML, j'arrive rapidement a vouloir utiliser l'héritage de Jinja. Et là c'est la catastrophe :-( je n'arrive pas a comprendre pourquoi ça fonctionne avec certains block déjà présent et pas le nouveau que j'essaye de faire. Je retourne le soucis dans tous les sens pour finalement comprendre que le soucis ne viens pas de moi.
Deuxième déception : en lisant cette demande de changement et relisant attentivement la doc, sans la survoler et comprendre ce qu'il veulent vraiment dire) je comprend que Pelican souffre d'un soucis de chargement des ressources lors de la processus de Jinja. Donc soit on se base sur leur thème «simple» pour avoir un bout d'héritage, soit on duplique le code dans tous les coins :-(
Au vu de l'ancienneté du bug remonté (2013) il est peu probable que ça se débloque. Il y avait un petit espoirs avec cet autre bugmais fermé automatiquement par manque d'activité :-( il semble tout de même y avoir une voie de contournement mais pas super propre.
Bon dans tout ça je me dit que je devrais peut être changer d'outil, tel que MkDocs qui a l'air d'avoir une bonne popularité mais est plus orienté documentation technique …
by Startrek1701,Benoît Sibaud,Xavier Teyssier,palm123 from Linuxfr.org
PyPI (de l’anglais « Python Package Index ») est le dépôt tiers officiel du langage de programmation Python. Son objectif est de doter la communauté des développeurs Python d’un catalogue complet recensant tous les paquets Python libres.
Google, par l’intermédiaire de l’Open Source Security Foundation (OpenSSF) de la Linux Foundation, s’est attaqué à la menace des paquets malveillants et des attaques de la chaîne d’approvisionnement des logiciels open source. Elle a trouvé plus de 200 paquets JavaScript et Python malveillants en un mois, ce qui pourrait avoir des « conséquences graves » pour les développeurs et les organisations pour lesquelles ils écrivent du code lorsqu’ils les installent.
PyPI déploie le système 2FA (pour double authentification ou authentification à deux facteurs) pour les projets critiques écrits en Python.
Ainsi, comme il est possible de le lire sur le compte twitter de PyPI (version nitter fdn.fr ou censors.us), le dépôt va implémenter le 2FA obligatoire pour les projets critiques écrits en Python.
Nous avons commencé à mettre en place une exigence 2FA : bientôt, les responsables de projets critiques devront avoir activé 2FA pour publier, mettre à jour ou modifier ces projets.
Pour s’assurer que ces mainteneurs puissent utiliser des méthodes 2FA fortes, nous distribuons également 4000 clés de sécurité matérielles !
Les 4000 clés de sécurité matérielles sont des clés de sécurité Google Titan. Ces clés seront distribuées aux responsables de projets, avec l’aide de l’équipe de sécurité open source de Google.
Vente autorisées, mais pas partout
La vente des clés Titan n’est autorisée que dans certaines régions géographiques. Ainsi, seuls les développeurs d’Autriche, de Belgique, du Canada, de France, d’Allemagne, d’Italie, du Japon, d’Espagne, de Suisse, du Royaume-Uni et des États-Unis peuvent en recevoir une gratuitement.
Le 2FA en progressions
Il y a déjà un certain nombre de développeurs qui ont activé le 2FA, ainsi, et en toute transparence selon PyPI, le dépôt publie les données sur les comptes 2FA.
Selon PyPI, il y a déjà plus de 28 600 utilisateurs avec 2FA activé, dont près de 27 000 utilisant une application TOTP (par exemple FreeOTP+ sur mobile Android ou via KeepassXC sur un ordinateur).
La PSF (Python Software Foundation) indique qu’elle considère comme critique tout projet figurant dans le top 1 % des téléchargements au cours des six derniers mois. Actuellement, il y a plus de 350 000 projets sur PyPI, ce qui signifie que plus de 3 500 projets sont considérés comme critiques. PyPI calcule ce chiffre quotidiennement, de sorte que le don de Titan devrait permettre de couvrir une grande partie des mainteneurs clés, mais pas tous.
Bien que la plupart des développeurs soient familiers avec le système 2FA, cette exigence pourrait créer des difficultés de connexion.
En effet, si, par exemple, un utilisateur perd sa clé 2FA et qu’il n’a pas configuré d’autres options 2FA, il risque de perdre l’accès à son compte et donc la nécessité de récupérer entièrement un compte, ce qui est lourd et prend du temps à la fois pour les mainteneurs et les administrateurs de PyPI. Il serait donc préférable d’avoir plusieurs méthodes 2FA pour réduire les perturbations potentielles si l’une d’entre elles est perdue.
Conclusion
Est-ce que le 2FA va réellement sécuriser les projets Python ? C’est l’avenir qui le dira. En attendant, il semblerait que PyPI et plus globalement la PSF ait décidé de prendre les choses en main quant à la sécurité des projets Python.
N. D. M. : voir aussi le journal PyPI et les projets critiques sur le même sujet, abordant notamment l'ajout de contraintes supplémentaires (complexité, temps, éventuel coût matériel, vérification régulière du 2FA à effectuer, etc.) pour les passionnés/hobbyistes.
Je souhaiterai intégrer une équipe 1 ou 2 semaines au mois d’août pour voir si le boulot de développeur à temps plein est vraiment ce que je souhaite faire.
J’espère retirer de cette expérience la confirmation de cette réorientation profesionnelle et pouvoir juger de mon niveau afin de savoir sur quoi travailler pour m’améliorer.
Mon métier à la base est le developpement de produits (conception 3D), j’ai fait de la plasturgie, de la fonderie, etc… mais ce n’est pas ce qui nous interesse ici.
J’ai obtenu le diplome «développeur d’application Python» d’OpenClassroom en 2019, j’ai donc théoriquement des bases HTML/CSS/JS/Django mais il faudra que je rafraichisse (j’ai fait des sites web en amateur plus jeune donc je n’etais pas parti de rien).
Depuis l’obtention de mon diplome je n’ai finalement pas quitté ma boite car j’ai proposé un nouveau projet basé sur des outils d’automatisation que j’ai développé moi même en Python:
une librairie d’interface pour automatiser le logiciel 3D (opensource: creopyson) et une autre basée sur la 1ere qui permet de simplifier son utilisation (propriétaire coup)
une librairie d’analyse de fichiers 3D (STL) issue de scans (utilisation de Open CV pour récupérer des coordonnés sur des images)
une application desktop (tkinter) qui permet de lancer tout un process de création de fichiers dans un intranet à partir d’un fichier de commande Excel (openpyxl), il n’y a pas vraiment d’API et intranet ultra sécurisé donc j’ai utilisé Selenium pour certaines actions (J’ai créé une liraire pour cette partie et j’ai eu l’occasion de l’utiliser sur un autre petit projet)
et le programme principal qui permet d’automatiser la réalisation de fichiers 3D. J’ai pour ambition de faire une interface avec Django pour faire le suivi et d’autres choses mais je ne m’y suis pas encore mis, pour l’instant c’est juste un bat qui lance la console et demande le numéro de commande à réaliser, cela convient parfaitement aux utilisateurs à l’heure actuelle.
J’ai un peu joué avec Jupyter/pandas/numpy/matplotlib pour faire des analyses de production et de jolis graphiques.
J’ai suivi une formation sur les design patterns il y a quelques mois et c’est quelque chose qui m’interesse beaucoup, la logique d’architecture, la structure du code.
Tout ce que j’ai développé pour le boulot est testé, j’ai mis du temps mais j’ai eu le «déclic» du TDD.
J’arrive à la fin de mon projet actuel et je me pose la question de faire le grand saut vers le développement «pour de vrai».
Je recherche donc une boite qui pourrait m’accueillir pendant mes vacances afin que je puisse filer un coup de main et me mettre dans la peau d’un développeur.
Je peux développer une petite fonctionnalité, faire des tests, etc…
Je n’ai pas de convention de stage donc je ne sais pas si légalement cela pose un problème que je vienne passer du temps dans une entreprise, j’ai mon PC donc pas besoin de m’en mettre un à disposition. Je suis en vacances les 3 premières semaines d’août mais j’aimerai quand meme prendre un peu de temps pour autre chose donc l’idéal serait 1 ou 2 semaines. J’habite en banlieu parisienne, donc idéalement sur Paris.
Github ou l'émergence d'une plateforme centralisée Git apparait dans sa première version en 2005. Il s'est rapidement imposé comme un outil de gestion de versions moderne et robuste. Initialement conçu pour le développement du noyau GNU Linux par Linus Torwald lui-même, il rencontre son succès pour ses singularités, à commencer par son architecture décentralisée, ses performances et la scalabilité de ce qui constitue son coeur, c'est-à-dire son système de stockage de fichiers. Les traditionnels Subversion, CVS ou Mercurial sont peu à peu remplacés par Git. En 2008, c'est le lancement de Github qui au fil des ans vient assoir l'hégémonie de Git en offrant un service d'hébergement gratuit pour de nombreux projets libres. Le revers de la médaille c'est qu'il devient un point de centralisation incontournable du libre offrant une plateforme alliant fonctionnalités sociales et utilitaires à destination des développeurs. A peine deux ans après son lancement, Github accueille plus d'un million d'utilisateurs, et plus de deux millions l'année suivante pour environ le double de dépôts. Le rachat de Github par Microsoft Si Github, la plateforme sociale du code a grandement aidé à la popularisation de Git en offrant une forge logicielle gratuite à des millions de développeurs de logiciels libres à travers le monde (Github héberge à ce moment-là 75 millions de projets), il attire la convoitise de Microsoft, alors gros utilisateur de la plateforme, qui finit par se l'offrir pour 7,5 milliards de dollars. Le jour même de l'annonce, ce sont plus de 100 000 projets qui quittent Github, donc plus de 50 000 pour migrer sur GitLab. En juillet 2019 et jusqu'à janvier 2021 Github a restreint les comptes de développpeurs situés en Iran, en Syrie, en Crimée, à Cuba et en Corée du Nord, appliquant les sanctions du gouvernement américains sur ces pays concernant les exportations de technologies. L'accès à ses services via des VPN était dans le même temps bloqué pour ces mêmes utilisateurs. L'État Américain s'octroie donc le droit de vie ou de mort sur le code, et sur des projets de logiciels libres sous couvert de sanctions économiques. Cet épisode avait mis toute la communauté du logiciel libre en émoi. Gitlab.com SaaS , une deuxième offre centralisée alternative mais toujours insuffisante en terme de souveraineté Si l'offre SaaS GitLab.com vient proposer des fonctionnalités appréciables (CD/CI), son service d'hébergement des projets n'en demeure pas moins lui-même également soumis aux droits et aux restrictions américaines sur les exportations technologiques ou sur le copyright (le service avait migré de Microsoft Azure à Google Cloud Platform en 2019). En ce sens, il n'apporte pas, au sens de la CNIL, un niveau satisfaisant de compatibilité avec le règlement européen sur la protection des données (RGPD), comme indiqué sur cette carte du monde affichant le niveau de protection des données par pays et leur compatibilité avec le droit communautaire européen.
La concentration des services et des données que l'on connait aux USA est de fait problématique, d'autant que le pays est loin d'offrir, aux yeux de l'Union européenne, un niveau de protection des données satisfaisant pour se montrer en adéquation avec le RGPD. Avoir conscience de la mécanique qu'implique nos choix d'architecture est un premier pas, agir pour une meilleure décentralisation et protection de nos données est souvent une question plus délicate. On peut aisément le constater à l'heure où le "cloud souverain de confiance" se met en place en France avec le renfort assumé de Microsoft. Des instances Gitlab hébergées de manière indépendante et sécurisée en France Bon nombre d'entreprises européennes ont parfaitement assimilé cette problématique et se refusent de courir le moindre risque, que ce soit en matière de propriété de leur code, qu'il soit propriétaire ou sous licence libre, et beaucoup font l'effort de se responsabiliser en matière de protection des données induites par le RGPD. En France la CNIL publiait fin 2021 un ensemble de guidelines à destination des développeurs. On notera dans ces directives la fiche n°4 sur la gestion du code source et la fiche n°5 concernant les choix d'architecture. Convaincu de la puissance de Git et de Gitlab qui constituent des outils essentiels de notre organisation depuis plus de 10 ans, Bearstech fait le choix de proposer une offre infogérée d'hébergement de votre Gitlab, pour permettre à votre code de rester sur le territoire national et ainsi de contribuer à la nécessaire déconcentration du patrimoine logiciel. Notre nouvelle infrastructure couplée à plus de 10 années d'expérience en matière d'hébergement de Gitlab pour nous comme pour nos clients nous confère une expertise pour assurer une haute disponibilité de votre code et de votre production. Nous assurons également les mises à jour de la plateforme, un support expert à taille humaine, et nous proposons une facturation mensuelle qui sera en plus moins chère à nombre d'utilisateurs comparé.
Hello, y a t-il des personnes intéressées pour reprendre les Meetups Python sur Nantes? https://www.meetup.com/fr-FR/nantes-python-meetup/
Je pars en vacances outre-manche bientôt et j’imagine que c’est similaire pour pas mal de monde alors peut-être a partir de la rentrée ?
La télédétection par satellite est un domaine de recherche actif, avec des applications dans les sciences de l'environnement, de l'agriculture et du changement climatique. Plusieurs missions satellitaires ont été lancées au cours des dernières décennies, comme le programme européen Copernicus, et fournissent des données massives d'observation de la Terre en libre accès.
Parmi les différents produits issus de ces missions, la cartographie à grande échelle de l'occupation du sol est sûrement le plus opérationnel. De nos jours, une telle cartographie est utilisée pour une large gamme d'applications environnementales et revêt une importance primordiale dans le contexte du changement climatique. Plusieurs réalisations ouvertes et privées ont été annoncées récemment (par exemple, https://www.theia-land.fr/en/ceslist/land-cover-sec/ ou https://viewer.esa-worldcover.org/worldcover). Ce sujet est toujours un domaine actif de recherche et d'ingénierie. L'un des principaux problèmes limitants est la capacité à traiter efficacement la très grande quantité de données auxquelles les chercheurs et les ingénieurs sont confrontés.
Dans ce cadre, le logiciel open-source iota2 a été initié par le laboratoire CESBIO comme une chaîne de traitement générique pour traiter intégralement les séries temporelles satellitaires récentes, telles que SENTINEL-1 et SENTINEL-2 ou Landsat-8. Elle a permis de produire la première carte de l'occupation du sol sur le territoire français métropolitain (e.g., https://theia.cnes.fr/atdistrib/rocket/#/collections/OSO/21b3e29b-d6de-5d3b-9a45-6068b9cfe77a).
Pour étendre le développement du logiciel, en dehors du laboratoire du CESBIO, le projet CNES PARCELLE a été mis en place pour favoriser l'utilisation de iota2 à d'autres problèmes de cartographie à grande échelle. Trois thèmes principaux sont considérés dans le projet.
1. Une évaluation quantitative et qualitative des performances de iota2 pour différents types de paysages (par exemple, Afrique du Sud ou Amérique du Sud) et/ou différents types d'occupation du sol.
2. L'intégration méthodologique des algorithmes de pointe des partenaires du projet.
3. Promouvoir l'utilisation d'iota2 par le biais de formations et de réunions scientifiques.
Activités
La première mission de la personne recrutée est de travailler sur le développement de nouvelles fonctionnalités pour iota2, comme l'inclusion d'algorithmes de deep learning (super-résolution, classification, inversion…). Le candidat peut consulter le dépot du projet pour plus de détails (https://framagit.org/iota2-project/iota2/-/issues).
La troisième mission de la recrue sera de coordonner les différents développements menés par les partenaires.
Compétences
Le candidat doit avoir une solide expérience en python (numpy, pandas, scikit-learn, pytorch), en informatique scientifique, en linux et en système de contrôle de version distribué (git). Une expérience en documentation de logiciels (docstrings, sphinx) sera appréciée, ainsi que des connaissances en traitement d'images de télédétection, en géomatique, en systèmes d'information géographique et en bases de données.
Contexte de travail
Le poste est au CESBIO, à Toulouse pour 12 mois plus 12 mois renouvelable. Le travail à distance est autorisé après 6 mois de services, deux jours par semaine.
Au hasard de mes pérégrinations, j’ai souhaité vérifié qu’un fichier correspond à une extension précise, parmi une liste d’extensions bien entendu.
Je fais donc une recherche, pour chaque fichier, parmi toutes les extensions listées pour voir s’il en fait partie ou pas.
J’ai donc commencé par un truc tout bête, genre :
if name[:-3] in (liste des extensions):
Et forcément, ça ne fonctionne que pour des extensions de 3 caractères. Oubliées les “.md” et autres “.epub”
J’ai donc amélioré la chose avec une simple liste de compréhension :
[1 for extension in test_extensions if name.endswith(extension)]
Ici, name est le nom du fichier, test_extensions est la liste d’extensions à tester. Je crée donc une liste qui contiendra un élément si mon fichier correspond à une extension, sinon la liste sera vide. Il me suffit alors de vérifier la longueur de la liste résultante.
Et puis j’ai pensé à utiliser filter qui est souvent bien pratique :
C’est plus court, mais pas forcément plus lisible je trouve. Pour faire plus court, on peut remplacer list par set (oui, on y gagne 1 seul caractère, c’est de l’optimisation de forcené qui n’a rien d’autre à faire de ses journées )
Et c’est encore plus court finalement ! Ah ah ah ! Mais peut-être encore moins lisible ?
Bon, et forcément, vu que mon projet n’est pas si important, j’ai largement le temps de faire un poil de benchmark :
import pathlib
import random
import timeit
# On prépare les données
extensions = ("txt", "png", "md", "ico", "gif", "zip", "rst", "epub",)
test_extensions = (".txt", ".rst", ".md")
files = []
for i in range(10):
files.append(f"test.{random.choice(extensions)}")
# On lance les banchmarks
print("set, filter map")
print(timeit.timeit("[len(set(filter(None, map(name.endswith, test_extensions)))) for name in files]", globals=globals(), number=100000))
print("list, filter map")
print(timeit.timeit("[len(list(filter(None, map(name.endswith, test_extensions)))) for name in files]", globals=globals(), number=100000))
print("set, filter lambda")
print(timeit.timeit("[len(set(filter(lambda x: name.endswith(x), test_extensions))) for name in files]", globals=globals(), number=100000))
print("list, filter lambda")
print(timeit.timeit("[len(list(filter(lambda x: name.endswith(x), test_extensions))) for name in files]", globals=globals(), number=100000))
print("simple")
print(timeit.timeit("[len([1 for extension in test_extensions if name.endswith(extension)]) for name in files]", globals=globals(), number=100000))
print("pathlib")
print(timeit.timeit("[pathlib.PurePosixPath(name) in test_extensions for name in files]", globals=globals(), number=100000))
Et voici les résultats (obtenus sur mon PC, sous Windows 10 (je suis au bureau, désolé)) :
Émerveillement de la nature, on s’aperçoit que list est légèrement plus lente que set, mais surtout qu’on s’en sort très bien sans filter.
Pour information, l’ajout du calcul de la longueur ne joue pas sur les temps de réponse.
La morale de cette histoire ?
Les fonctions intégrées sont souvent intéressantes, mais elles ne font pas tout
J’ai vraiment du temps à perdre ce matin
Voilà, et bonne journée à vous !
EDIT : Ajout de pathlib, qui est donc à oublier même si très pratique
Je viens à l’instant d’ajouter Python au comptoir du libre :
Ça nous permet de se déclarer utilistateur, formateur, prestataire, …
Pour ceux qui découvrent, le comptoir du libre est un service de l’ADULLACT :
Fondée en 2002, l’ADULLACT a pour objectifs de soutenir et coordonner l’action des Administrations et Collectivités territoriales dans le but de promouvoir, développer et maintenir un patrimoine de logiciels libres utiles aux missions de service public.
HashBang est une société coopérative (SCOP) de services informatiques basée à Lyon. Nous sommes une équipe de 12 personnes.
Nous développons des applications sur mesure avec une approche de co-construction. Nous intervenons sur toute la chaine de production d’un outil web, de la conception à la maintenance. Nos technologies préférées sont Python, Django, Vue.js, Ansible. Nos méthodes s’inspirent des méthodes agiles. Nos clients sont des startups/TPEs/PMEs/associations et en particulier des organisations qui font partie de l’Économie Sociale et Solidaire (associations, coopératives).
Nous sommes attachés aux questions de qualité du code et de maintenabilité, ainsi qu’au bien-être au travail.
Nous privilégions la prise de décision collective. Notre organisation est horizontale, basée sur la sociocratie. Après une phase d’intégration, chaque salarié·e est amené·e à intervenir et participer à la gestion de la coopérative dans différent domaines (ressources humaines, comptabilité, gestion du planning, commercial, etc.)
Le poste
Contexte
Hashbang crée un poste de développeuse/développeur, en contrat à durée déterminée pour accroissement temporaire d’activité de 7 mois.
Missions
Vous aurez pour principales missions :
Développer des applications web à l’aide des frameworks tels que Django et Vue.js
Développer des outils d’administration de bases de données
Développer des outils en Dash, Flask, Plotly, et SQLAlchemy
Tester votre code
Faire des revues de code
Savoir traduire les besoins du client en une solution fonctionelle
Participer à la vie de la coopérative
Conditions
Le poste est à pourvoir dans nos locaux : Hashbang, 13 ter Place Jules Ferry, 69006 LYON
Le contrat proposé est à durée déterminée pour accroissement temporaire d’activité. Le temps de travail est de 35h par semaine. Le salaire est fixé selon une grille en fonction de votre ancienneté et de votre expérience passée. Nous proposons des tickets restaurants et un forfait mobilité durable qui prend en charge les frais de transport en commun et/ou de déplacement à vélo. En tant que SCOP, une partie des bénéfices est reversée aux salarié·e·s.
Compétences recherchées
Pré-requis techniques
Pour occuper ce poste, vous aurez besoin de :
Savoir chercher de l’information par vous-même, rester en veille technologique
Savoir utiliser un logiciel de gestion de version (Git / …)
Etre à l’aise avec Python / Javascript / HTML et CSS
De préférence, avoir déjà utilisé Django et Vue.js
Etre à l’aise dans la relation client et la gestion de projet
C’est un plus si vous avez déjà utilisé :
numpy
pandas
Postgresql
Dash, Flask, Plotly, Elasticsearch et SQLAlchemy
Qualités professionnelles
Pour ce poste et pour vous épanouir dans notre coopérative, vous aurez besoin :
D’être curieux ;
D’une forte attirance pour le travail collaboratif ;
D’un sens de la communication afin de vous exprimer en groupe, ainsi qu’avec nos clients;
D’une capacité à prendre des décisions en groupe et individuellement ;
D’être force de proposition ;
Prendre des initiatives, tester, rater, recommencer, réussir;
D’être capable de travailler en autonomie.
Vous êtes en phase avec nos valeurs et êtes intéressé·e par le modèle coopératif, l’informatique libre et l’organisation horizontale.
Candidater
Envoyez un mail de candidature à rh@hashbang.fr avec un CV et la description de vos motivations pour cette offre en particulier.
HashBang est une société coopérative (SCOP) de services informatiques basée à Lyon. Nous sommes une équipe de 12 personnes.
Nous développons des applications sur mesure avec une approche de co-construction. Nous intervenons sur toute la chaine de production d’un outil web, de la conception à la maintenance. Nos technologies préférées sont Python, Django, ArchLinux, Vue.js, Ansible. Nos méthodes s’inspirent des méthodes agiles. Nos clients sont des startups/TPEs/PMEs/associations et en particulier des organisations qui font partie de l’Économie Sociale et Solidaire (associations, coopératives).
Nous sommes attachés aux questions de qualité du code et de maintenabilité, ainsi qu’au bien-être au travail.
Nous privilégions la prise de décision collective. Notre organisation est horizontale, basée sur la sociocratie. Après une phase d’intégration qui permet d’appréhender les enjeux de chaque groupe de travail, chaque salarié·e est amené·e à intervenir et participer à la gestion de la coopérative.
Le poste
Contexte
Dans le cadre de son développement, Hashbang crée un poste d’ingénieur d’affaire / Technico commercial.
Missions
Vous aurez pour principales missions d’être l’interface entre Hashbang et son environnement commercial. A ce titre, vos principales missions seront:
Développer le portefeuille clients de HashBang :
Prospecter de nouveau clients, en participant/organisant à des événements du monde du logiciel libre et de l’univers de scop
Fidéliser des clients existants, en réalisant des entretiens de suivi client avec nos chefs de projet
Suivre les objectifs de ventes et de l’état du carnet de commande
Communiquer : créer des posts LinkedIn, twitter, des articles de blog sur notre site internet, créer et diffuser des supports de communication sur notre offre de service.
Réaliser la vente :
Analyser les besoins client
Etre en lien avec l’équipe projet pour traduire le cahier des charges
Faire des propositions technico-commerciales adaptées
Participer à la rédaction de réponses à appel d’offres / devis
Participer à la vie de la coopérative
C’est un plus si vous savez réaliser et présenter des éléments marketing pour nos projets de développement.
Conditions
Le poste est à pourvoir dans nos locaux : Hashbang, 13 ter Place Jules Ferry 69006 LYON
Le contrat proposé est à durée indéterminée. Le temps de travail est de 35h par semaine.
Le salaire est fixé selon une grille en fonction de votre ancienneté et de votre expérience passée. Nous proposons des tickets restaurants et un forfait mobilité durable. En tant que SCOP, une partie des bénéfices sont reversées aux salarié·e·s.
Compétences recherchées
Pré-requis techniques
Pour occuper ce poste, vous aurez besoin de :
Savoir chercher de l’information par vous-même,
Prendre des initiatives, tester, rater, recommencer, réussir
C’est un plus si vous avez une connaissance technique suffisante pour proposer des solutions aux prospects / clients
Qualités professionnelles
Pour ce poste et pour vous épanouir dans notre coopérative, vous aurez besoin :
D’être curieux/curieuse ;
D’une forte attirance pour le travail collaboratif ;
D’un sens de la communication afin de vous exprimer avec les prospects / clients mais aussi en groupe ;
D’une capacité à prendre des décisions en groupe et individuellement ;
D’être force de proposition ;
D’être capable de travailler en autonomie.
Vous êtes en phase avec nos valeurs et êtes intéressé·e par le modèle coopératif, l’informatique libre et l’organisation horizontale.
Candidater
Envoyez un mail de candidature à rh@hashbang.fr avec un CV et la description de vos motivations pour cette offre en particulier.
Salut, pour la Pycon DE 2022 j’avais envisagé de faire tourner Pygame directement dans les navigateurs internet ( via WebAssembly, sans installation, ni serveur web dynamique* ).
Ayant réussi à temps, j’ai ultérieurement créé un petit outil d’aide à la publication pour que tout le monde en profite ( même sans linux ni compilateur, juste python 3.8+ ):
Nouveau meetup sur Lyon le jeudi 16 juin !
Nous serons accueilli par IT Solutions Factory (vers Charpennes) et @HS-157 nous parlera d’adminstration système avec Python.
Nous recherchons une ou un développeur(se) avec déjà une première expérience significative en python/open source pour poursuivre le développement de nos services autour de l’analyse de données. Vous souhaitez développer des briques innovantes front ou back autour de la data, contactez-nous ! Ce n’est pas un poste de data scientist même si vous pourrez y goûter…
Qui est OctopusMind ?
OctopusMind, spécialiste de l’Open Data économique, développe des services autour de l’analyse des données. Nous éditons, notamment, www.J360.info, plateforme mondiale de détection d’appels d’offres.
L’entreprise d’une dizaine de personnes développe ses propres outils en mode agile à partir de technologies Open Source pour analyser une grande masse de données quotidiennement. Elle est engagée dans des projets innovants axés sur l’intelligence humaine et artificielle (TALN & Deep Learning).
L’équipe IT fonctionne en mode scrum / sprint sans lead developer.
Nous vous proposons
Nous recherchons une ou un développeur(se) avec déjà une première expérience en python/open source pour poursuivre le développement de nos services autour de la valorisation des données.
Vous souhaitez développer des briques innovantes front ou back autour de la data, contactez-nous !
Vous participerez :
Au développement des applications web de l’entreprise sur la base de Python, Django, VueJS, REST, PostgreSQL, Docker, Ansible, ElasticSearch…
Aux tâches d’administration système, de maintenance de l’infrastructure, déploiement des applications, problématiques de performance
Aux scripts de collecte de données
L’organisation de travail est rythmé par des sprints. Les missions sont discutées et réparties à chaque cycle selon les profils de chacun.
Si vous êtes enthousiaste, vous aimez apporter votre touche personnelle, vous êtes à l’aise avec l’agilité… notre entreprise vous plaira.
Candidature
2 ans minimum d’expérience professionnelle
Salaire : Selon le niveau
Horaires flexibles
Bureau : Nantes (44)
CV + Lettre de motivation (pourquoi vous souhaitez nous rejoindre notre entreprise) à adresser par mail à job @ octopusmind.info
Merci d’illustrer vos compétences techniques avec des exemples de projets ou codes
Echanges et précisions par mail ou téléphone, suivi d’entretiens physiques ou visio, et un entretien final dans nos bureaux.
CDI ou CDD, temps plein ou 4/5, télétravail en France possible
En février 2020 on avait tenté un petit meetup sur Strasbourg (qui avait tout de même rassemblé 14 personnes). Ensuite il y a eu une pandémie qui a cassé notre élan et notre motivation.
J’aimerais bien savoir si des personnes présentes sur ce discuss sont de Strasbourg (ou des environs) et serait interessées pour des meetup (en présentiel)
Si oui je vous laisse faire un signe, sinon vous pouvez toujours relayer cette information (sur le discord par exemple)
Après plusieurs années d'attente, nous venons de recevoir le Librem 5 que nous avions commandé chez Purism.
C'est un téléphone orienté vie-privée dont les fonctionnalités notables sont :
l'utilisation de PureOS, une distribution GNU/Linux basée sur Debian, à la place d'Android ou iOS ;
l'interface graphique est GNOME avec quelques modifications ;
la présence de boutons permettant de physiquement éteindre le Wifi, le Bluetooth, les données mobiles, le microphone ou la caméra (c'est à dire couper l'arrivée électrique).
Utiliser Linux sur un téléphone mobile ouvre à de nouveaux usages qui concernent surtout des personnes technophiles, mais cela vient aussi avec son lot d'inconvénients.
Les plus notables sont que les téléphones sous Linux sont quelque chose de nouveau, et les applications ne sont simplement pas prêtes : les interface ne sont adaptées aux écrans mobiles, les interactions pratiques sur un téléphone mobile (comme le glissement du pouce) ne sont pas utilisées, et plus généralement les applications n'ont pas encore été assez testées par des utilisateurs mobiles.
Les développeurs de logiciels libres font de leur mieux, et un sacré travail a déjà été fait.
Cependant nous ne sommes pas encore à un point où les téléphones sous Linux peuvent être mis entre toutes les mains.
Avec notre regard vierge (c'est la première fois que nous voyons un téléphone sous Linux), nous voulons lister ici ce que nous pensons qu'il manque à l'écosystème pour fournir un bonne expérience utilisateur (du moins pour notre usage biaisé de technophiles).
Nous nous sommes concentrés sur les applications GNOME Core et Circle, ainsi que sur les applications mobiles développées par Purism.
Ce que nous attendons d'un téléphone est qu'il nous permette de :
passer des appels
recevoir et envoyer des SMS
recevoir et envoyer des emails
être utilisé comme réveil
gérer ses contacts
gérer des listes de tâches
être utilisé comme un appareil de géolocalisation
naviguer sur internet
jouer de la musique
prendre des photos
prendre des notes
afficher des documents
partager sa connexion internet
être utilisé comme lampe-torche
discuter avec des gens
Comme produire des correctifs a encore plus de valeur que rapporter des bugs, cette liste pourrait nous servir de liste de tâches à faire si nous (ou vous ?) nous ennuyons un jour.
Nous avons testé le téléphone sous PureOS byzantium, et mis à jour les applications grâce à Flatpak quand c'était possible afin de bénéficier des avancées de GNOME 42.
Bloquants
Dans cette catégorie nous listons les problèmes qui nous découragent fortement pour une utilisation quotidienne.
Cela concerne principalement du stress et de la friction dans l'expérience utilisateur, ainsi que des fonctionnalités manquantes ou inutilisables.
Librem5 - L'interface n'est pas traduite : Au premier lancement la langue préférée de l'utilisateur est demandée, mais l'interface reste affichée en anglais par la suite. C'est assez simple à corriger à la main, mais c'est assez surprenant.
Clavier virtuel - Indicateurs d'interaction : Lorsqu'une lettre est pressée, on devrait avoir un indicateur visuel pour indiquer de quelle lettre il s'agissait.
Librem5 - Lumière nocturne : GNOME a une fonctionnalité de lumière nocturne qui rougit l'écran automatiquement en fonction de l'heure. Il semblerait qu'il y a des choses à faire dans le noyau pour utiliser cette fonctionnalité avec le Librem5.
Appels - Barre latérale de navigation alphabétique : L'application manque d'un outil pour rapidement sauter à une lettre donnée de l'alphabet, ce qui est très utile lorsqu'on a des centaines de contacts.
Contacts - Barre latérale de navigation alphabétique : L'application manque d'un outil pour rapidement sauter à une lettre donnée de l'alphabet, ce qui est très utile lorsqu'on a des centaines de contacts.
Tâches - Interface mobile : L'interface n'est pas adaptée aux mobiles, donc l'application est inutilisable pour le moment.
Fractal - Chiffrement de bout en bout : À Yaal Coop nous chiffrons tous nos salons, donc le chiffrement de bout en bout est nécessaire pour que nous puissions utiliser Fractal.
Cartes - Navigation : L'application peut calculer des itinéraires, mais ne fournit rien pour les suivre. On ne peut donc pas encore l'utiliser dans une voiture.
Cartes - Appui long pour ouvrir le menu contextuel : Certaines actions sont cachées derrière le menu contextuel sur bureau, qui s'ouvre avec un clic droit. Sur mobile on ne peut donc pas ouvrir ce menu. Un appui long devrait permettre d'ouvrir le menu.
Logiciels - L'interface n'est pas réactive : Lorsque les dépôts Flatpak sont actifs, chaque action prend une éternité à s'exécuter, au point qu'il faille de temps en temps redémarrer l'application.
Phosh - Glisser pour ouvrir et fermer le menu : Pour le moment les menus du haut et du bas ne s'ouvrent qu'en tapant, or glisser est plus naturel sur mobile. Le correctif est développé mais pas encore déployé.
Librem5 - Choix de la phrase de chiffrement au premier démarrage : Au premier démarrage, une phrase de chiffrement par défaut est demandée à l'utilisateur, en anglais, avec un clavier qwerty. Il nous semblerait plus accessible de demander à l'utilisateur de choisir sa phrase de déchiffrement au premier démarrage, une fois qu'il a choisi sa langue et son clavier.
Dans cette catégorie nous listons toutes les autres choses que nous avons rencontrées, il s'agit surtout de petites améliorations d'interface et quelques fonctionnalités qui permettraient par exemple un usage hors-ligne.
Agenda - Indicateur visuel de sélection : Lorsque l'on sélectionne une période, on n'a aucun indicateur visuel de ce qui est sélectionné avant d'avoir terminé la sélection.
Agenda - Interface mobile : Agenda ne s'affiche pas trop mal sur mobile, mais certains détails manquent. Par exemple, les infobulles peuvent être plus larges que l'écran.
Horloges - Widget de montre analogique : Taper à multiple reprises pour changer les minutes ou les heures n'est pas pratique. Afficher un cadran d'horloge analogique permettrait de faire la même chose en tapant seulement deux fois sur l'écran.
Disques - Interface mobile : Le menu de chiffrement n'est pas adapté aux mobiles, mais l'application reste utilisable.
Evince - Passer automatiquement en mode nocturne : Evince permet de manuellement inverser les couleurs. Il serait pratique que le système fasse ça automatiquement en fonction du mode nocturne.
Cartes - Taper deux fois pour zoomer : Sur bureau un double clic permet de zoomer. Taper deux fois sur la carte devrait le permettre aussi.
After several years of waiting, we just received our Librem 5 phone from Purism.
The Librem 5 phone is a privacy-oriented phone which notable features are:
it uses PureOS, a GNU/Linux distribution based on Debian, instead of Android or iOS;
the interface is based on GNOME with a few modifications;
it has kill switches to physically disable wifi, bluetooth, cellular data, camera and microphone.
Running a Linux on a cellular phone enables new uses, especially for tech savvy, but it comes with its lot of drawbacks.
The main notable ones is that Linux phones is a brand new field, and a lot of apps are simply 'not ready'.
Either because their UI is not adaptive, because they have not been adapted to mobile user interactions (swiping and other gestures), or just because they have not been tested enough by users, so some actions feels convoluted.
FOSS developers do their best, and a whole lot of great work has been done so far.
However we are not yet at a point where Linux phones can be put in the hands of a larger audience.
With our fresh eyes of new Linux mobile users, we want to list here the main things that we felt were really missing to provide a good user experience (at least for our biased geeky use).
We focused on GNOME Core and Circle apps, and mobile/Librem5 specific apps developped by Purism.
What we expect from a phone is to:
place calls
receive and send SMS
receive and send emails
be used as an alarm clock
manage contacts
manage tasks
be used as a geolocation navigation device
browse the internet
play music
take photos
take notes
display documents
share internet connection
be used as a torchlight
discuss with people
As patching has even more value than reporting, this list could be used by us (or you?) as a to-do list for some day if we get bored.
We have tested the phone running PureOS byzantium, and we updated all the apps through Flatpak when possible so we could get the latest GNOME 42 fixes.
Blockers
In this category we put the issues we feel are very discouraging for a daily use.
This mainly concerns UX friction and stress, and missing or broken features.
Squeekboard - Alternate characters popovers: We Europeans use a lot of diacritics, the keyboard should offer us a way easily write any common accentuated character.
Librem5 - Translation have to be forced: At first launch, the welcome panel asks the user for their language, but this action is uneffective and the system is displayed in English after that. This is easy to fix with a command-line, but surprising for a first-launch.
Clocks - Alarms should wake the system up: If an alarm has been set, it should ring on time, no matter what. Alarms should wake the system up if needed.
Squeekboard - Input indicator: When a key is tapped, users should have a visual indication of which key is actually pressed.
Librem5 - Night light support: GNOME provide a night light feature that reddish the screen automatically depending on the hour. It seems there are some kernel thing to do to enable this. Without this, watching to the screen at night just kill your eyes.
Calls - Alphabet side bar: The application lacks an alphabet side bar to quickly jump to some letters in the contact list. With thousands of contacts this would become more than useful.
Contacts - Alphabet side bar: The application lacks an alphabet side bar to quickly jump to some letters in the contact list. With thousands of contacts this would become more than useful.
To-Do - Adaptive UI: The UI is not adaptive at the moment, so To-Do is not usable.
Fractal - End-to-end encryption: At Yaal Coop we encrypt our conversations, so E2EE in Fractal is a blocker to us.
Maps - Adaptive UI: The side-menu is not usable on a Librem 5 at this point.
Maps - Navigation view: The application can calculate itineraries, but do not provide anything to follow the itineraries. Is is not usable in a car yet.
Maps - Long-press to open the contextual menu: Some actions are only accessible via right click on desktop, so on mobile they just cannot be done. A long press on the map should have the same effect as a right click.
In this category we put the issues that would improve our comfort.
This mainly concern mobile UX improvements.
Phosh - Automatic light and dark theme switch: Along with the screen warmness adaptation, switching from a light to a dark theme when the night comes is a bliss for the eyes. This is achievable with GNOME Shell with the Night Theme Switcher extension for instance.
Phosh - Swipe to open and close the menu: As of today, the application menu and the top menu can only be opened by tapping. However swiping to open the menu feels more natural on mobile. This have been implemented but not yet deployed.
Phosh - Automatically unlock the keyring: When opening a new session with a PIN, it is then asked a second time to unlock the GNOME keyring. This feels redundant.
Librem5 - Ask the encryption passphrase at first boot: At first boot, a (default) passphrase is asked to decrypt the disk, in English, with a qwerty keyboard. It would be friendlier to not ask it a the first boot and let the user choose it.
Librem5 - Disk decryption screen l10n: The disk decryption screen is in English, with a qwerty keyboard, so it is not adapted to other languages.
Phosh - Keep the time displayed when the top menu is opened: The time is hidden when the top menu is opened. Time is still an interesting information to display when the menu is opened, and without this the top bar appears strangely empty. This seems to be fixed but not yet deployed.
In this category we put everything else that we met during our test, from nice-to-have features to slight mobile UX improvements:
Chatty - Swipe to return to the message list: When a message is displayed, there is an arrow button that allows to go back to the message list, but the more natural action on mobile would be to swipe left.
Geary - Swipe to return to the message list: When a message is displayed, there is an arrow button that allows to go back to the message list, but the more natural action on mobile would be to swipe left.
Calendar - Adaptive UI: Calendar displays good enough on mobile, but some details are missing. For instance, the tooltips can be larger than the screen.
Clocks - Analog watch widget: Tapping multiple times on the screen to select hours and minutes is cumbersome. An analog watch widget could achieve the action in on two taps.
Disks - Adaptive UI: The encryption menu is not adaptive, but this is still usable.
Evince - Automatically switch to night mode: Evince allows to manually invert the background color at night. This should be done automatically depending on the system dark mode.
Maps - Double-tap to zoom: On desktop double-clicking zooms, as should do double-tapping on touchscreen.
Squeekboard - Bépo support: This one does only concerns a few nerds, but bépo (a French dvorak layout) support would be awesome.
Dans le but d’organiser un peu la communication, j’ai préparé des “thumbnails” pour communiquer plus facilement sur les réseaux sociaux. Les médias étant mis en avant sur certains réseaux sociaux. J’ai fait des tests sur figma.
Si vous avez d’autres idées ou des remarques sur ceux-ci, n’hésitez pas !
(Remplacez ce paragraphe par une courte description de votre nouvelle catégorie. Cette information apparaîtra dans la zone de sélection de la catégorie, veillez donc à saisir moins de 200 caractères.)
Utilisez les paragraphes suivants pour une plus longue description ou pour établir des règles :
À quoi sert cette catégorie ? Pourquoi les utilisateurs choisiraient-ils cette catégorie pour leur discussion ?
En quoi est-elle différente des autres catégories existantes ?
Quels sont les sujets qui devraient figurer dans cette catégorie ?
Avons-nous besoin de cette catégorie ? Devrions-nous fusionner celle-ci avec une autre catégorie ?
Chez ProcSea, nous croyons à un futur où la ressource de notre planète est protégée, où la sécurité alimentaire est assurée et où les échanges de produits frais sont simples, fluides, transparents et responsables. Pour cela, nous développons une technologie innovante et moderne qui permet de connecter les acteurs de la filière agroalimentaire entre eux afin d’améliorer le quotidien des opérateurs, de collecter et fiabiliser les données et consolider la traçabilité des produits.
Si vous êtes motivé(e) à l’idée de digitaliser toute une industrie et de construire son avenir, rejoignez-nous!
A propos du rôle
Nous recherchons un(e) développeur(se) back-end en CDI pour nous aider à construire la meilleure expérience utilisateur possible et permettre aux opérateurs de marché de faire levier sur les dernières technologies web pour gérer des milliers de transactions.
Vous rejoindrez une équipe dynamique de 4 développeurs back-end talentueux qui travaillent sur tous les aspects de notre application en coordination avec l’équipe front-end et produit. Vous êtes créatif(ve) et vous avez plein d’idées à partager ? Parfait ! Chaque ingénieur peut challenger et influencer la direction des fonctionnalités sur lesquelles il ou elle travaille.
Nous sommes basés majoritairement à Rennes, mais toutes nos équipes sont en télétravail.
Vos tâches au quotidien consistent à :
Développer des nouvelles fonctionnalités innovantes
Implémenter des concepts ou des maquettes
Garantir la qualité et la performance des applications
Nous offrons un environnement de travail basé sur la confiance et l’indépendance. Nous nous engageons à vous former sur notre solution et à accompagner votre développement en tant que développeur(se). Nous sommes toujours à la recherche d’approches innovantes et maintenons nos technologies à jour.
Votre évolution et votre rémunération seront à la mesure de votre investissement et de vos réussites. Vous serez éligible aux stock-options.
Vous réussirez chez nous si vous avez le profil suivant:
Une solide expérience dans le développement d’applications web complexes
Une connaissance approfondie des de Python / Django
L’habitude de travailler en test + intégration continue
ProcSea a été créé en 2016 et a développé sa propre marketplace B2B dédiée aux professionnels des produits de la mer. Avec des milliers d’utilisateurs et des centaines de milliers de transactions, nous avons démontré qu’il était possible de digitaliser une industrie et de changer ses habitudes. Depuis Janvier, nous nous concentrons exclusivement sur notre business SaaS en mettant à disposition des grands acteurs de la filière (Grossistes, Centrales d’Achats, Grande Distribution) nos solutions techniques.
Aujourd’hui plusieurs clients prestigieux nous font confiance ainsi que des investisseurs solides qui nous soutiennent depuis nos débuts.
Nos équipes sont composées de talents internationaux et divers basés partout en France. Le bien-être et la convivialité sont importants pour nous. C’est pourquoi, nous organisons régulièrement des événements pour tous nous réunir et partager des moments forts autour d’une activité.
Processus de recrutement
Appel d’introduction avec le recruteur - 15’
Visio avec le CTO - 60’
Test technique - 60’
Visio avec deux développeurs de notre équipe - 60’
Hello.
Je fais parti de l’équipe de traduction de la documentation en français, menée par l’incroyable JulienPalard !
Pas mal d’entre-nous utilisent PoEdit, un logiciel d’édition de fichiers .po (le format de fichier des traductions), souvent en version gratuite. La version payante a une intégration poussée avec DeepL, qui génère en un clic des traductions extrêmement fidèles et correctes, qui permet de faire gagner énormément de temps… Jusque là je payais la license moi-même (40€/an). Je me demandais si l’AFPy pouvait financer la license aux plus gros traducteurs qui en font la demande (à priori, seulement moi pour l’instant).
L’équipe de traduction abat un gros travail, c’est extrêmement chronophage, et comme pourra vous le confirmer Julien, l’équipe de traduction en français est l’une des équipe les plus avancée dans la traduction de la documentation et la plus réactive.
L’entreprise dans laquelle je travaille, Alma, vient d’ouvrir ses nouveaux bureaux rue des petites écuries à Paris et se propose de proposer l’espace pour des meetup.
Est-ce que certaines et certains d’entres-vous serait intéressé par un Afpyro ? On pourrait également en profiter pour faire 1 ou 2 talk et parler des dernières nouveautés de Python.
En vrac je pense à des sujets tels que (httpx, FastAPI, Pydantic, Async SQLAlchemy, OpenAPI, HTTP/3, etc) mais ce n’est pas restrictif.
L’idée serait d’en faire un premier courant juin.
Merci de me contacter par mail si vous souhaitez proposer un talk.
Au sein de la DINUM, beta.gouv, l’Incubateur de services numériques met en œuvre une politique de transformation de l’État par le truchement d’un programme d’intraprenariat. Ce programme permet à des agents publics de devenir intrapreneurs et d’être accompagnés par de petites équipes autonomes et agiles. Souvent nommées Startups d’État, ces équipes sont pilotées par l’impact et développent des produits numériques en cycles courts, en lien direct avec leurs usagers et les parties prenantes.
En parallèle de ce programme d’intraprenariat, la DINUM lance la Brigade d’Intervention Numérique, une équipe produit de 15 personnes (développeur, chargé(e)s de déploiement, coach produit, designer UX/UI) dont la mission est d’accompagner le gouvernement et l’administration dans la construction de services publics numériques à fort impact et à aider les différents ministères dans leur capacité à répondre aux commandes politiques.
Les missions de la Brigade
Proposer et mettre en oeuvre rapidement des solution dans une situation de crise ou d’urgence
Santé Psy Étudiant
Je veux aider
Renforcer l’impact de politiques prioritaires à travers le développement de services publics numériques
Plateformes de l’inclusion
Mission Apprentissage
Soutenir l’action du réseau d’incubateurs beta.gouv par la création de communs réutilisable par d’autres Startups d’États
Tchap
Audioconf
Vos missions
En tant que développeur, vous participerez au développement de services numérique à fort impact, au sein d’une équipe travaillant selon l’approche Startup d’État, grandement inspirée du lean startup et notamment :
Organiser, planifier et assurer le développement de produits numériques ;
Contribuer à l’amélioration continue du produit, des outils et de l’organisation de l’équipe pour gagner en efficacité ;
Livrer en continu un produit aux utilisateurs afin d’en tester l’usage et l’utilité en continu ;
S’assurer de la qualité du code grâce aux outils d’analyse automatisés et la mise en place les bonnes pratiques adéquates ;
Automatiser les procédures de déploiement et autres outils de productivité en utilisant des services PaaS ;
Participer aux événements de la communauté (OpenLabs, séminaires, ateliers, formations etc…).
Les thématiques peuvent être diverses (transports, emploi, aides sociales, handicap, insertion, santé, etc.) et les modalités d’interventions peuvent varier en fonction des contextes.
Votre profil
Vous avez entre 3 et 5 années d’expérience dans le développement de produits numériques. Vous avez envie de rejoindre un programme dédié à la construction de services numériques publics et vous souhaitez travailler au sein d’une culture produit.
Vous disposez de bonnes connaissances en développement logiciel (algorithmique, structuration de données, architecture, etc.)
Vous avez des connaissances en intégration et déploiement continu
Vous avez une bonne connaissance en méthodes agiles et/ou lean startup
Vous prenez au sérieux les questions de sécurité des systèmes d’information
Vous avez une compréhension des enjeux RGPD
Vous êtes pragmatique et vous vous préoccupez du coût à long terme de vos choix technologiques
Vous disposez d’une sensibilité pour l’expérience utilisateur et l’accessibilité
Vous avez des expériences avec des langages du web (NodeJS ou Python ou Ruby)
Vous avez un bon sens de l’écoute et un bon esprit d’équipe
Vous aimez vous engager avec fiabilité, rigueur et responsabilité pour livrer un produit.
Rejoindre la Brigade
Intégrer la Brigade, c’est obtenir :
Un CDD au sein de la Direction Interministérielle du Numérique jusqu’au 31 décembre 2023.
Une rémunération selon le profil et l’expérience.
L’accès à une communauté d’entrepreneurs publics d’environ 700 personnes présentes dans l’ensemble des Ministères et sur tout le territoire.
Le droit de télétravailler à raison de 2 jours par semaine et 3 jours dans nos bureaux de Lyon, Paris ou Rennes.
Vous souhaitez rejoindre une jeune entreprise française à taille humaine et en forte croissance, tournée vers l’innovation et l’international ?
Vous êtes soucieux(se) des défis énergétiques et environnementaux de notre époque, et vous voulez contribuer concrètement à la sobriété énergétique et à la réduction des émissions de CO2 ?
Alors rejoignez-nous !
Implantée à Lyon et à Singapour, et forte d’une expertise transdisciplinaire (IT, data-science, génie thermique), BeeBryte propose des services innovants de contrôle prédictif optimal distant 24/7 et de support à l’opération & maintenance pour aider nos clients industriels et tertiaires à augmenter l’efficacité énergétique et la performance de leurs systèmes de CVC-R (chauffage, ventilation, climatisation, réfrigération).
Pour cela nous mettons en œuvre une surcouche intelligente, portée par notre plateforme Industrial-IoT, qui exploite les informations profondes des systèmes existants et de leur contexte pour maximiser en permanence leur performance énergétique. En anticipant besoins et facteurs d’influence, nous permettons à nos clients de réduire efficacement leur empreinte carbone, de circonscrire leurs risques, et de réaliser jusqu’à 40% d’économies sur leurs factures énergétiques
INFORMATIONS POSTE
Missions :
Concevoir et réaliser des solutions logicielles innovantes et performantes répondant à des problématiques industrielles
Définir et mettre en œuvre des architectures extensibles, évolutives et scalables
Concevoir et développer des interfaces ergonomiques pour une meilleure expérience utilisateur
Industrialiser et automatiser les tests et le déploiement des applications
Maintenir les solutions BeeBryte à la pointe de la technologie pour l’amélioration énergétique
Génie logiciel (conception & développement logiciel, gestion de versions, tests automatisés, tests d’intégration et intégration et déploiement continus)
Principes de conception et architectures logicielles (Architecture 3-tiers / MVC / Micro Services)
Structures de données et algorithmique
Autres compétences appréciées :
Connaissances en DevOps / GitOps (Container, CI CD)
Connaissances en Data Science et Informatique industrielle (Protocoles MODBUS / BACNET) est un plus
Maîtrise de méthodes agiles (Scrum / Kanban)
Connaissance de Jira Software est un plus
Connaissance UML
Bonne maîtrise de l’anglais
Vous recherchez une certaine diversité dans votre activité et la possibilité d’intervenir sur différents projets.
Vous considérez que le développement d’une application serveur robuste et scalable et le design d’une interface ergonomique et intuitive constituent les deux faces d’une même pièce
Vous êtes autonome, rigoureux(se) et animé(e) d’un fort esprit d’équipe
PROCESSUS DE RECRUTEMENT
Poste cadre en CDI, à pourvoir à partir de Juillet 2022
Alors je suis pas recruteur ou CEO de startup mais une place s’est liberée dans notre équipe de Strasbourg et vu que les ESN/SSII fournissent pas des profils au top, je lance cette annonce.
En résumé c’est un poste de développement Web python Django (et C++ si jamais tu connais, ça serait apprécié), sur du Linux (RHEL) avec beaucoup de tests en tout genre et des morceaux de DevOps et de la sécurité (des certificats, du CORS et pleins de choses chouettes). Si t’es interessé(e) pour parfois faire du painless (Elastic-Search) ou du Prométheus c’est un bon plus. Faut aussi connaitre l’anglais (lu, écrit).
Mais c’est un milieu assez contraignant avec des procédures, des règles parfois fastidieuses, et un besoin de réactivité au top et d’organisation en permanence (découper son travail en étapes, communiquer sur l’avancement etc) . Faut beaucoup de rigueur (vérifier, re-vérifier, re-re-vérifier), d’autonomie (OBSERVER et savoir chercher soit même), de capacité à communiquer (résumer, extraire l’essentiel, écrire/maintenir de la doc et parler a l’équipe mais sans la saturer de truc futiles) et faudra savoir remettre en cause plein de chose que tes études t’ont appris et qu’on ne fait pas dans la vraie vie.
Dans les bon côtés l’équipe (7 personnes) est sympa (sauf moi), on utilise des outils cool (Gitlab/Mattermost) et on prend le temps d’améliorer nos outils/process.
En cas d’interêt pour cette annonce il faut me contacter très vite par message privé/“Direct”, ou me contacter via LinkedIn pour qu’on échange.
Ces derniers mois nous avons principalement contribué à canaille, le serveur d'identité que nous développons,
ainsi que le menu d'autocomplétion simple-svelte-autocomplete et le greffon
nextcloud-oidc-login qui permet à nextcloud de se connecter à des serveurs d'identité.
async def search(query):
# query
url = 'https://lite.duckduckgo.com/lite/'
async with httpx.AsyncClient() as http:
response = await http.post(url, data=dict(q=query))
if response.status_code != 200:
raise StopIteration()
content = response.content.decode('utf8')
# extract
html = string2html(content)
hits = html.xpath('//a[@class="result-link"]/@href')
for hit in hits:
yield hit
Note: httpx.AsyncClient() peut-être recyclé / re-use dans l’application, alors que la cela crée un client pour chaque appel, ce qui est moins performant.
Dans frontend.py on peux trouver un langage qui permet d’embarqué du HTML dans du python, sans passer par un décodeur pour implémenter un truc a la jsx, a la place ca ressemble a h.div(Class="hero")["coucou"]. La fonction serialize fonctionne de concert avec preactjs. preactjs est un clone de reactjs, qui a l’avantage d’être livré avec un seul fichier .js ie. pas besoin d’installer nodejs et webpack. Le journal The Guardian utilise preactjs pour son frontend. Le serveur va transformer la représentation sous forme d’objet python en bon vieux JSON, un petit algorithme JavaScript va prendre la main pour traduire le JSON en appel dom / virtual dom kivonbien pour preactjs (indentation approximative):
function translate(json) {
// create callbacks
Object.keys(json[PROPERTIES]).forEach(function(key) {
// If the key starts with on, it must be an event handler,
// replace the value with a callback that sends the event
// to the backend.
if (key.startsWith('on')) {
json[PROPERTIES][key] = makeEventHandlerCallback(key, json[PROPERTIES][key]);
}
});
let children = json[CHILDREN].map(function(child) {
if (child instanceof Array) {
// recurse
return translate(child);
} else { // it's a string or a number
return child;
}
});
return preact.h(json[TAG], json[PROPERTIES], children);
}
Les events du DOM sont forward au backend a travers une websocket, voir makeEventHandlerCallback, remarque: c’est le strict minimum que j’ai implémenté, il est souhaitable d’étendre le support des évents du DOM pour sérialiser plus finement les évents et supporter plus de cas.
Ce bout de code ne se generalise pas c’est un cas spécifique a l’implémentation de la gui de babelia, mais le reste peut se généraliser en framework dans l’esprit de phoenix liveview.
Les parties indexation et recherche sont implémentées dans pstore.py a la racine du depot, c’est un fork du pstore.py de asyncio-foundationdb qui n’utilise pas de map-reduce.
Je vous présente l’ensemble de la fonction d’indexation:
async def index(tx, store, docuid, counter):
# translate keys that are string tokens, into uuid4 bytes with
# store.tokens
tokens = dict()
for string, count in counter.items():
query = nstore.select(tx, store.tokens, string, nstore.var('uid'))
try:
uid = await query.__anext__()
except StopAsyncIteration:
uid = uuid4()
nstore.add(tx, store.tokens, string, uid)
else:
uid = uid['uid']
tokens[uid] = count
# store tokens to use later during search for filtering
found.set(
tx,
found.pack((store.prefix_counters, docuid)),
zstd.compress(found.pack(tuple(tokens.items())))
)
# store tokens keys for candidate selection
for token in tokens:
found.set(tx, found.pack((store.prefix_index, token, docuid)), b'')
Première étape: enregistrer le document représenter par un sac de mot (bag-of-word) appelé counter, c’est l’index avant [forward] qui associe l’identifiant docuid a son contenu le simili dico counter;
Deuxième étape: créer les liens arrières [backward] aussi appelées inversés [inverted] qui associent chaque mot / clef avec le docuid et donc le sac de mots counter par jointure.
async def search(tx, store, keywords, limit=13):
coroutines = (_keywords_to_token(tx, store.tokens, keyword) for keyword in keywords)
keywords = await asyncio.gather(*coroutines)
# If a keyword is not present in store.tokens, then there is no
# document associated with it, hence there is no document that
# match that keyword, hence no document that has all the requested
# keywords. Return an empty counter.
if any(keyword is None for keyword in keywords):
return list()
# Select seed token
coroutines = (_token_to_size(tx, store.prefix_index, token) for token in keywords)
sizes = await asyncio.gather(*coroutines)
_, seed = min(zip(sizes, keywords), key=itemgetter(0))
# Select candidates
candidates = []
key = found.pack((store.prefix_index, seed))
query = found.query(tx, key, found.next_prefix(key))
async for key, _ in query:
_, _, uid = found.unpack(key)
candidates.append(uid)
# XXX: 500 was empirically discovered, to make it so that the
# search takes less than 1 second or so.
if len(candidates) > 500:
candidates = random.sample(candidates, 500)
# score, filter and construct hits aka. massage
hits = Counter()
coroutines = (massage(tx, store, c, keywords, hits) for c in candidates)
await asyncio.gather(*coroutines)
out = hits.most_common(limit)
return out
L’algorithme va sélectionner dans la requête de l’utilisateur représenté par keywords le mot le moins fréquent, ça élague en une short liste qu’y s’appelle candidates. J’ai hard code un sampling a 500 items que j’ai déterminé empiriquement mais qui idéalement ne devrait pas exister, ou au moins devrait se configurer au démarrage de l’application en faisant un benchmark. Les candidates sont ensuite masser, en fait il s’agit de calculer le score de tous les documents candidats issues de l’étape précédente:
Je suis lead tech dans une scale-up et je sens que mon niveau en Python stagne. Disons que j’arrive à m’en sortir avec ce que je sais et que j’ai du mal à passer le niveau au dessus pour profiter pleinement des avantages de Python
J’aimerais appronfondir mes connaissances (entre intermédiaire et avancées) et si possible obtenir une certification ou quelque chose qui pourrait justifier mon niveau.
Peu importe le coût (CPF bienvenue) et la durée de la formation. Je préfère simplement éviter les formations en ligne qui sont juste des suites de vidéos.
Est-ce que vous avez des recommendations à ce sujet?
Nos recruteurs recherchent de bons ingenieurs Python pour rejoindre nos equipes. Personellement, je ne suis pas recruteur mais ingenieur.
Quand je vois le faible niveau des candidats qu’on a en interview, je me suis dit qu’il fallait faire un truc pour avoir de meilleurs talents dans notre team, sinon on allait jamais y arriver.
En gros:
il faut parler anglais
creation de bibliotheques, d’outils devops, de gros projets
Bonjour,
je viens d’essayer de comprendre comment relire et commenter une PR… J’ai peut-être manqué un truc.
Pour relire et commenter une PR, je n’ai pas trouvé d’autre moyen que de consulter le fichier diff des .po, ce qui me semble assez pénible. Quel est donc l’autre moyen (l’idéal étant de relire les HTML générés par la version PR sur ma machine mais je vois pas comment).
Salut les pythonistes,
vous avez peut-être remarqué le superbe tutoriel d’ @entwanne arriver sur Zeste de Savoir.
Pour l’occasion et pour célébrer les nombreux contenus concernant python sur la plateforme Zeste de Savoir, on compte promouvoir nos contenus sur Python durant une semaine. On vous en parle en avance si vous voulez participer à la mise en avant de contenu Python durant cette occasion (même si c’est pas du contenu ZdS). La date n’est pas encore fixée.
On serait ravi que vous vous appropriez le concept.
by Stéphane Blondon <stephane@yaal.coop> from Yaal
Les 2 et 3 avril 2022, plusieurs associé·es de Yaal Coop étaient présents aux 23ièmes Journées du Logiciel Libre qui se déroulaient à Lyon. C'était l'occasion d'approfondir des sujets qui nous intéressaient, de faire quelques découvertes ainsi que de rencontrer des acteur·ices du Libre en personne.
Comme nous construisons un service d'hébergement nommé nubla, assister aux présentations sur le collectif des CHATONS (Collectif des Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires) et sur zourit ont été un moyen pour nous de confirmer (ou d'infirmer) nos choix sur le fonctionnement du service. Découvrir cette communauté donne du coeur à l'ouvrage !
Cela fait aussi plaisir de constater l'intérêt pour le mouvement coopératif, comme ce fut le cas lors des discussions animées de la session d'échange "Gouvernance du libre/Gouvernance des coopératives : quels points communs ?". Tout un programme... Qui nous conforte dans notre choix de transformer Yaal en SCIC fin 2020. Un choix loin d'être unique comme l'a encore démontrée cette discussion organisée par d'autres coopératives du numérique : Hashbang, Tadaa et Probesys.
D'un point de vue moins politique (quoi que...) à Yaal Coop nous avons un usage quotidien de claviers plus ou moins originaux (TypeMatrix, Truly Ergonomic, ErgoDox) et, pour certains, de personnalisations de disposition de clavier bépo. De fait, la présentation sur la fabrication personnalisée de clavier et sur la disposition récente tentant d'avoir une disposition agréable pour écrire en français, en anglais et pour programmer - ergoL -, ont piqué notre curiosité.
Cette conférence était l'occasion de parler avec des passionnés mais aussi celle de recroiser et discuter avec des personnes déjà rencontrées lors d'autres conférences (en l'occurence DebConf et PyconFr).
Le village associatif en particulier a été pour nous un lieu d'échanges, notamment avec Framasoft sur les avantages et les différences des formats coopératifs et associatifs.
Du coup, encore merci à tous les organisateurs et présentatrices, et vivement la prochaine ?
Element vs Cwtch : de la confidentialité à l'anonymat Alors que le Web3 promet de mettre à l'honneur l'open source, la décentralisation, la confidentialité, l'interopérabilité et plein d'autres vertus qu'on trouvera en route, il est une promesse de messageries respectueuses de votre vie privée, toujours décentralisées, et pour certaines, susceptibles de vous proposer par défaut de l'anonymisation. Il s'agit d'ailleurs là de deux notions que l'on a souvent tendance à confondre. Nous avons choisit de poser notre dévolu sur deux de ces messageries (et une en bonus), toutes deux hautement recommandables, mais qui ne répondent pas forcément aux mêmes besoins, et donc aux mêmes usages. Elles sont ainsi parfaitement complémentaires.
La notion de confidentialité Pour résumer et avec des mots simples, la confidentialité consiste à protéger vos communications et non votre identité. L'étape la plus évidente et la plus critique est la phase du transport des données. Ces données transitent sur le réseau et sont sujettes à l'interception par des tiers. On parle alors de chiffrement de bout en bout pour protéger vos données, tant pendant leur transport que pendant leur stockage. Attention, lorsqu'on vous parle de chiffrement de bout en bout, on parle rarement de chiffrement au repos (lors du stockage), cette notion ne couvre que le transport des données et implique que le service utilisé propose un moyen d'assurer un chiffrement qu'il ne peut lui même casser / déchiffrer (à l'aide d'une clé unique)... et c'est souvent là que les gros acteurs des messageries vous promettent plein de belles choses, mais il ne faut surtout pas trop gratter. On découvrirait par exemple que Zoom ne chiffrait pas de bout en bout (il a fini par se décider en octobre 2020), que Messenger peut tout à fait lire vos messages, mais que comme ça commence à se voir, on va quand même faire un truc mais pas par défaut... les exemples sont légion. On ajoutera pour les GAFAM que l'Europe, chargée de plein de bonnes intentions sous la bannière de l'interopérabilité, pourrait même casser (bien involontairement) le chiffrement de certaines applications comme WhatsApp et Signal... un comble. Mais là encore, il y a peut-être un standard cryptographique interopérable pour les messageries et respectueux de la confidentialité qui pourrait naître de cette initiative, même si en l'état, on peut avoir des raisons de se méfier des effets de bords sur les services de ces géants de l'IM (en termes de nombre d'utilisateurs). Depuis que Google s'est dé-Jabberisé, on a vu éclore de gros acteurs, chacun y allant de son protocole maison et d'implémentations cryptographiques plus ou moins exotiques, faisant systématiquement peser de sérieux doutes sur cette notion même de confidentialité de nos échanges. L'anonymat L'anonymisation fait appel à des mécanismes plus avancés et des mesures simples et logiques pour protéger votre contexte. Ainsi vous pourrez trouver des solutions de messagerie apportant un niveau satisfaisant de confidentialité, mais trouver une application qui vous apporte un niveau satisfaisant d'anonymisation, c'est un non-sens. L'anonymat ne se fait pas à moitié, on est anonyme ou on ne l'est pas. Un niveau de confidentialité se mesurera par les algorithmes de chiffrement choisis, sur leur robustesse tant pendant le transport que dans le stockage, ainsi que dans l'architecture. Sur ce point tout le monde s'accorde à reconnaitre les bénéfices de la décentralisation, bien que ce ne soit pas ici un critère essentiel si l'on s'en tient à la stricte confidentialité et que le protocole demeure respecteux d'appliquer les meilleures pratiques de chiffrement. Une messagerie centralisée peut ainsi apporter un niveau satisfaisant de confidentialité, mais pour l'anonymat, c'est tout de suite bien plus discutable. Lorsque l'on commence à dealer avec l'anonymat, c'est une autre paire de manches. Il n'est plus ici question de la protection des données seules. Certes, les applications sur lesquelles nous porterons notre choix devront au bas mot répondre aux critères de confidentialité, mais elles se doivent d'apporter des mécanismes de protection du contexte supplémentaires pour répondre à une problématique bien différente. Il ne s'agit plus de protéger la charge utile seule, il convient de protéger l'identité (que nous prendrons soin de définir un peu plus précisément) de l'émetteur et du récepteur. Pour vous illustrer au mieux les différences entre ces deux notions, nous allons nous pencher sur deux systèmes de messagerie très respectables, c'est à dire : libres, décentralisés, chiffrés, dont un fait la promesse de protéger la confidentialité de vos échanges : Element, et l'autre, la promesse de protéger votre anonymat, il s'agit de Cwtch (à vos souhaits). Element : libre, élégant, moderne et respectueux de votre confidentialité Element (que l'on connaissait préalablement sous le nom de Riot et reposant sur le protocole Matrix) permet les discussions de groupes, elle remplacera avantageusement un Telegram, un Slack, ou tout simplement notre bon vieil IRC que l'on a souvent tendance à oublier. Element est proposé en open source (vous pouvez héberger votre serveur de discussion et le code des clients est également disponible). Niveau fonctionnalités, Element propose l'échange de fichiers, les appels audio, la visioconférence de groupe en P2P, et des salons (via WebRTC). La plus grosse communauté se concentre sur le réseau de matrix.org et regroupe bon nombre de salons de projets open source. Oui; Element peut se permettre d'être aussi complet car il n'a pas pour promesse l'anonymisation. Et puisque c'est de chiffrement dont il est question, la première étape pour pouvoir jouir d'Element convenablement sera d'aller faire un tour dans les paramètres de l'application afin de générer votre clé privée.
Pour encore plus de confidentialité et surtout vous assurer que vous parlez bien avec la bonne personne, vous pourrez activer l'option de vérification manuelle de chaque session.
Element a su montrer patte blanche au sein de nombre d'organisations dites sensibles, c'est par exemple lui que l'on retrouvera au sein de structures gouvernementales comme celle de l'État français, puisque Matrix peut agir comme une glue avec différents protocoles comme celui de Slack, Telegram, IRC ou encore Jitsi. On trouvera parmi ses contributeurs actifs Protocol Labs à qui nous devons IPFS qui mériterait un article à lui seul, ou d'autres projets comme libp2p et Filecoin. Bref il y a du lourd derrière Element. A l'heure actuelle, Element serait le condidat parfait pour "remplacer" s'il en était besoin IRC, mais il s'agit là d'un autre débat et je vais donc me passer de donner mon avis sur ce point. Cwtch : l'anonymat over Onion v3 On ne présente plus Tor et les services qu'il rend depuis des années, son écosystème, sorti du Torbrowser peu sembler plus obscur même si on voit des implementations de ce protocole dans des applications modernes. Tor c'est avant tout un protocole de routage dit en "Onion", que l'on peut faire tourner comme un service (par exemple lancé au démarrage de votre machine). Il écoute par défaut sur le port 9050 et vous pouvez, si votre application le permet, faire passer son trafic sur le réseau de Tor en la faisant écouter sur ce port, en mode proxy Socks). Tor a récemment fait évoluer son protocole et la transition de Onion v2 à Onion v3 a été initiée au courant de l'été 2021 pour une dépréciation de Onion v2 en octobre 2021. Pour une couche supplémentaire de protection de votre identité, vous pouvez par exemple entrer sur Tor via un VPN (VPN qui rappelons le, n'est en aucun cas garant de votre anonymat). Cependant, si vous utilisez Tor avec votre navigateur du quotidien ou avec d'autres applications, sachez que ces dernières ne sont par défaut pas configurées afin de restreindre au maximum la transmission de certaines métadonnées pouvant trahir des éléments de votre identité (les locales, les extensions, les thèmes, les versions de librairies tierces... sont autant de petits détails qui peuvent fuiter). C'est d'ailleurs dans cette optique que les développeurs de Tor proposent le TorBrowser et vous expliquent dans leur documentation les choses à éviter de faire pour une protection optimale. Et c'est également avec ces préoccupations en tête que Cwtch se propose d'être une messagerie optimisant tout ces petits détails pouvant paraitre anodins mais qui constituent le plus important avec l'anonymisation : la protection de l'intégralité de votre contexte.
Cwtch (à prononcer "Keutch") est une messagerie multipartite décentralisée qui tire parti du protocole Onion V3, la colonne vertébrale protocolaire du réseau Tor (The onion router). Cependant vous ne trouverez pas, comme sur Element un réseau tel que celui proposé par matrix.org. Cwtch offre donc une solution de messagerie anonymisante, elle supporte les profils multiples (pour choisir vos identités en fonction des contextes). Rappelons au passage la notion d'identité :
l'identité déclarative : qui je déclare être (on choisira le plus souvent un pseudonyme) ; l'identité agissante : ce que je fais et ce que je dis sur un réseau ; l'identité calculée : celle qui est "vue"/calculée/déduite par le système informatique sur lequel j'évolue en se basant en grande partie sur les métadonnées.
L'objectif de Cwtch est donc de vous laisser déclarer ce que vous voulez et agir comme bon vous semble mais de rendre impossible (ou bien plus compliquée) toute déduction/calcul par un SI de votre identité. Pour échanger avec une personne, vous n'avez besoin que de lui communiquer une clé publique, que cette dernière devra explicitement ajouter (cette notion de consentement explicite est au coeur de la logique de Cwtch). Si vous nous avez suivis jusque-là, vous avez la démonstration de la différence entre pseudonymat et anonymat et vous aurez le droit de la replacer lors de vos conversations mondaines ou lorsque vous entendrez tonton Augustin s'indigner à propos du sempiternel poncif "Internet : ce repaire de lâches anonymes". Cwtch est l'oeuvre d'une petite équipe de développeurs officiant pour une non profit d'origine canadienne, OpenPrivacy. Niveau fonctionnalités, c'est moins fournit qu'Element, vous pourrez transférer des fichiers mais vous ne pourrez pas passer des appels vocaux ou video par exemple. Chaque action dans Cwtch est soumise à consentement et les options disponibles inspirent confiance, on voit que c'est bien d'anonymat dont il est question.
En activant les "expériences", vous vous ouvrirez la porte à des fonctionnalités supplémentaires, mais attention, ces dernières ne garantiront pas à 100% l'anonymisation, vous serez susceptibles de faire fuiter certaines métadonnées.
Le serveur est disponible ici et vous trouverez des implémentations PC et mobiles, avec leur code. Le gros avantage que Cwtch offre, c'est de pouvoir être contacté et de contacter de manière anonyme, et ce en toute simplicité. Il s'agit d'une fonctionnalité que l'on imagine tout de suite ultra pratique pour des journalistes qui souhaitent offrir des garanties d'anonymat à leurs sources. Ou pour offir la possibilité, à des sources, de transmettre des informations de manière sécurisée et anonyme, en passant outre un système de surveillance et de censure élaboré. Et sur mobile ? Olvid ! C'est là que tout se corse lorsque l'on souhaite s'anonymiser. Si votre objectif se borne à la confidentialité, Element sera dans son rôle. Il semble qu'il est encore un peu tôt pour Cwtch d'être en mesure d'offrir ses fonctionnalités avec la même assurance d'anonymisation. Mais tout n'est pas perdu. Nous allons donc vivement vous recommander de jeter un oeil à Olvid qui a fait un travail remarquable. Cette application de messagerie étant en outre d'origine française et auditée par l'ANSSI, on ne boudera pas notre plaisir à l'utiliser en lieu et place d'un Signal (et non, pas pour vos SMS, mais vous pourrez l'utiliser dans votre navigateur via le client web). Elle offre de l'authentification forte, du chiffrement de bout en bout avec confidentialité persistante (PFS) et elle offre même la promesse d'anonymisation en exposant aucune métadonnée... une véritable prouesse sur mobile. On souhaiterait qu'elle prenne en charge les SMS comme Signal le propose, attendu que là encore, si vous faites confiance à Google, vous vous faites gentiment pigeonner. Enfin sur plateforme mobile, n'oubliez pas que la confidentialité et l'anonymat que vous obtiendrez ne pourra pas aller au-delà de la confiance que vous placez dans Apple ou Google si vous utilisez respectivement iOS et Android : ce n'est pas vous mais ces entreprises qui décident du code qui tourne sur votre téléphone et ont tout loisir d'intercepter s'ils le veulent vos messages avant même qu'ils soient chiffrés par les applications. N'oubliez pas qu'un logiciel de confiance, ça ne marche que sur un OS de confiance - comme par exemple LineageOS.
Quelques personnes ici ont donné quelques conférences techniques et j’avais le souvenir d’articles qui avaient été partagés durant les meetup en-ligne.
Dans la mesure où (ne vous emballez pas) on commence à vivre avec la pandémie et que des présentations (meetup, conférences) reprennent, ça pourrait être sympa de lister quelques ressources (articles, conseils, thread twitter…) pour aider à préparer de futures présentations, des personnes novices qui aimeraient se lancer etc.
Il y a eu un sujet sur les outils techniques: présenter en markdown
Je pense qu’il serait utile d’avoir quelques articles sur “comment vulgariser un sujet technique”, “apprendre à résumer” “bien expliquer” etc etc.
J’aurais aimé initier le mouvement mais mes trois articles sont désormais en 404
assigner le badge aux membres (prérequis: l’email helloasso est associé au compte de l’adhérent): automatiquement via l’API ou manuellement via l’interface ?
Qui peut créer la clef d’API helloasso ? Un compte admin de bot Discourse pourrait-il être créé ?
Trax est une filiale du groupe Iliad (maison mère de l’opérateur Free), dédiée à la diffusion de contenu multimédia via l’application OQEE.
Fondée en 2019, Trax est une structure à taille humaine, organisée par pole de compétences: Produit, Graphisme, développement iOS, Android, Smart TV et Backend.
Le projet
L’objectif d’OQEE est de proposer une expérience TV moderne, à la fois sur les Freebox, mais également en dehors de l’écosystème des box.
Nous sommes aujourd’hui présents sur box Android TV, Apple TV, Smart TV Samsung, mobile iOS et Android, avec plus d’un million d’utilisateurs
Le poste
Compétences humaines & techniques :
Maîtrise de Python et Django,
Autonomie et force de propositions,
Connaissances de base en réseau (DNS, HTTPS, websocket, …),
Maîtrise des processus de développement (git, gitlab, CI, …).
Formation & Expériences :
Vous avez une formation d’ingénieur en informatique, et vous avez déjà réalisé plusieurs projets Django et avez une bonne expérience des APIs web,
Vous avez au moins :
4 ans d’expérience en développement Python minimum
(et puis relisez votre pyproject.toml qui aura typiquement la section [build-system] en double à fusionner à la main, et peut être quelques petites retouches stylistiques à faire.)
Préproduction Une préprod doit être un environnement le plus similaire possible à la production (versions et services déployés), mais en plus petit, histoire de limiter les coûts. Il ne faut pas oublier les proxys applicatifs, les CDN, les services tiers, tout, absolument tout doit être similaire à la production. Les préprods sont tellement pratique, que maintenant, on peut en avoir une par branche de développement, pour peu que l'on utilise des conteneurs. L'anglicisme pour désigner ça est app review. Les préprods sont utiles et pratiques, mais on ne souhaite pas forcément que n'importe qui puisse y jeter un oeil (pour faire des tweets moqueurs ou casser le suspens), et surtout qu'elles soient indexées par un moteur de recherche. Robots Pour les moteurs de recherche, il existe le célèbre robots.txt et le un peu moins célèbre header X-Robots-Tag reconnu au moins par Google et Yahoo. Ces outils ne sont qu'indicatifs, mais bon, un peu d'hygiène ne fait jamais de mal. Mot de passe Il est techniquement facile de coller un mot de passe en basic-auth sur n'importe quel serveur web, mais ça va stresser les personnes qui devraient y avoir accès mais qui ne connaissent pas le mot de passe, et à la fin, le mot de passe est connu de la Terre entière. La bonne approche est de passer par de l'OAuth2, comme le permet l'incontournable OAuth2-Proxy dont on vous a déjà parlé, vu qu'il y a des pull requests à nous dedans. Ces deux approches sont parfaites (la seconde est même encore plus parfaite) pour un site qui sera public, mais empiler les authentifications est une très mauvaise idée. Si votre site a des utilisateurs authentifiés, il va falloir trouver autre chose pour protéger la préprod. VPN Un VPN (Wireguard, what else?™) va garantir un accès exclusif à votre application, mais va poser des problèmes avec https. Ou alors, vous fournissez un certificat racine à vos utilisateurs, et donc la possibilité de forger n'importe quel certificat, et là c'est assez flippant. Les certificats modernes peuvent s'engager à ne signer qu'une liste de domaines bien spécifiés, mais ce n'est pas encore géré par tout le monde. Letsencrypt a besoin d'accéder au site en HTTP pour aller chercher une preuve, avec le challenge HTTP, ce qui ne fonctionnera pas derrière un VPN. Il faut passer à un challenge DNS, et donc avoir une API pour modifier automatiquement votre DNS (ce que propose la plupart des DNS, la liste est large). Le soucis va être de déployer le VPN de partout, sur toutes les machines. Bon courage si vous bossez dans l'IOT, l'Internet Des Machins qui se connectent alors qu'on ne leur avait rien demandé. Filtrage par IP Finalement, la protection un peu naïve, est de filtrer par IP, soit vous êtes dans la liste, soit rien du tout, le serveur, ou le firewall, bloque les autres IPs. Pour les entreprises c'est assez facile de connaitre les IPs. Pour les connections personnelles (xDSL, Fibre, cable), ça va dépendre du fournisseur. Certains vicelards s'amusent même à déco/reco au milieu de la nuit pour assigner une nouvelle IP, et on ne va même pas évoquer ceux qui attribuent la même IP publique à l'intégralité de leurs abonnés en leur fournissant un gros LAN, merci le CGNAT. Pour les connections itinérantes ([1-5]G) ça va aussi être le bazar. Pour les gens dans un café/gare/coworking ça va être la foire. Filtrage par IP dynamique Pour avoir une solution de filtrage par IP simple et souple à mettre en place, il est possible d'utiliser un service authentifié (votre cher Gitlab, par exemple), qui va utiliser votre user agent (massivement tweaké pour des raisons de tracking publicitaire) et votre IP, pour les mettre dans la bonne liste pour votre préprod. N'utilisez pas ce système dans un salon, un coworking space et autre wifi nébuleux. Lire les logs Spoiler : la paire IP/User agent se trouve dans les logs du serveur HTTP. Vous n'avez pas envie de patcher votre application pour qu'elle fournisse la liste des invités, il est tellement plus sage de se brancher depuis l'exterieur, de la manière la moins intrusive possible. Coup de chance, l'arrivée des micro services, qui tournent "quelque part" sur le cluster a obligé à normaliser les flux de logs. J'exclu Syslog avec son routage trop petit, ses messages trop courts et son UDP trop YOLO. Mais oui, techniquement, c'est faisable.
Logstash est bien gentil, mais les cycles de debug avec un reboot de 2 minutes, non merci. Le protocole pour faire transiter ses logs, lumberjack, est décrit et il existe même une lib officielle pour golang. Filebeat a lui aussi sa place dans la galaxie ELK, mais sans l'exotisme de Jruby utilisé par son meilleur ennemi, Logstash. Lumberjack est une solution crédible. Le lobby des conteneurs, aka CNCF a désigné Fluentd comme solution de gestion de logs. Le protocole est documenté, docker le cause en natif, et le client officiel, fluentbit s'installe facilement sans dépendance pénible. Grafana conforte sa position de hub universel, en ajoutant à sa pile un serveur de logs : Loki. Plein de gens parlent le Loki : Fluentbit, Vector, Docker, via un plugin de chez Grafana et bien sur Promtail le client fournit avec Loki. Avec les premiers protocoles cités, vous allez devoir créer un serveur ad hoc pour récupérer le flot de logs. Avec Loki, c'est dans l'autre sens : vous allez demander à Loki de vous abonner à un flot de logs. Loki va apporter une indirection, mais aussi un buffer (1h par défaut) et donc la possibilité de bidouiller vos analyses de logs sans perdre de message, ou même d'aller explorer le passé. Il faut visualiser Loki comme un data lake suffisamment rangé pour pouvoir router simplement les différents flots de log, en batch, et en temps réel. Autre arme secrète, Loki propose une nouvelle syntaxe pour parser les logs bien systématique, sans recourir aux expressions régulières (et au terrible Grok). Ça s'appelle pattern et il faut chercher dans la documentation pour en avoir une description. Chevillette Chevillette est un projet en Go, sous licence AGPL-3.0. Il va lire des logs d'un serveur web, filtrer sur des chemins avec des status 200, par exemple le chemin d'un projet Gitlab, il va garder dans sa liste la paire IP/user agent pendant quelques temps.
Pour l'instant, Chevillette sait écouter du fluentd (il se comporte comme un serveur, avec les différentes authentifications implémentées). L'abonnement à un serveur Loki est en cours. Si il y a de la demande, la bibliothèque officielle est disponible, avoir un server Lumberjack sera pas trop compliqué à mettre en place. De l'autre coté, Chevillette implémente le auth_request de Nginx (que Traefik sait aussi utiliser). Auth_request permet de déléguer le filtrage de requêtes à un service HTTP, en se mettant à coté, et non devant comme le ferait un proxy HTTP. HAproxy, pour sa part, utilise un protocole spécifique, SPOE pour déléguer la qualification des requêtes à un service tiers. La lib golang est disponible, et le sujet est passionnant, il est donc possible que son implémentation arrive rapidement. Les logs sont un flot d'événements plus ou moins qualifiés, ce n'est pas juste le truc qui explique pourquoi le service est vautré. Il y a clairement des choses à faire avec, et Loki est manifestement un bon point de départ (avec son ami Grafana) pour explorer et déclencher des actions.
Annalect est l’agence Data Expertise au sein d’Omnicom Media Group France (OMG), la division française d’Omnicom Group Inc, un des leaders mondiaux de la publicité, du marketing et de la communication d’entreprise. Nos principales missions sont l’aide au pilotage stratégique et opérationnel des investissements média au service du business ainsi que l’optimisation de l’achat média via l’usage de la data science et de l’IA.
Descriptif du poste
Au sein de l’équipe de développement et sous la responsabilité du Director of Engineering, vous intégrerez Annalect en tant que développeur·euse Python Back-end et Data.
Le rôle de notre squad est de collecter / enrichir / optimiser la donnée issue de sources différentes afin de les rendre accessible dans une solution de visualisation de données.
Vos missions :
Vous développez de nouveaux connecteurs data
Vous assurez la maintenance des connecteurs existants
Vous contribuez à l’élaboration de nouveaux outils de scraping / datamining
Vous développez des interfaces orientées web pour l’enrichissement de la data ou la gestion d’aspect métier
Avec le reste de l’équipe, vous trouvez des solutions simples et rapides à des problématiques complexes
Vous créez et optimisez des pipelines data complexes
Vous monitorez la plateforme d’exécution des jobs data
Vous faites des code review des autres membres de l’équipe
Notre stack actuelle :
Majorité du code en Python
pySpark et Pandas pour la manipulation de données
Django pour les webapplications
Plotly / PowerBI pour la dataviz
Airflow pour la gestion des workflows
Ansible pour le déploiement automatique
GitLab pour le versionning et la partie CI/CD
JIRA pour la gestion des tâches et l’organisation
Produits déployés sur AWS et sur des serveurs internes
Profil recherché
Vous êtes passionné·e par le développement. Vous êtes familier·ère avec les API REST, le développement dirigé par les tests et la documentation (dans le code ou à destination d’utilisateurs techniques).
Vous avez plus de 2 ans d’expérience en tant que Développeur Python et vous êtes idéalement diplômé·e d’un master en computer science, d’une école d’ingénieur / université (BAC+5).
Code :
Vous avez de l’expérience sur des projets de traitement de données complexes
Vous codez couramment Python; la connaissance de Django est un plus
Vous connaissez les notions de DataLake, DataWarehouse ainsi que le CI/CD
Vous écrivez des tests (unitaires ou fonctionnels) et vous connaissez le TDD
Vous avez des notions de développement orienté Web
Vous maîtrisez GIT et GIT flow et vous n’oubliez jamais le CHANGELOG dans vos PR J
Attitude :
Vous connaissez les méthodes agiles et vous aimez être intégré·e dans les phases d’estimation et de planification des tâches
Vous comprenez l’intérêt de la documentation
Vous aimez réfléchir en équipe aux questions d’architecture d’un produit ou d’un projet
Vous êtes débrouillard·e et curieux·euse, vous n’attendez pas qu’on vous donne la solution aux problèmes.
Vos avantages chez Annalect :
Vous travaillerez avec des grands comptes et aussi en collaboration avec des équipes internationales
De la formation, des certifications et la possibilité d’évoluer au sein du Groupe
Remote hybride : 2 jours de télétravail possible par semaine
RTT mensuel
Des avantages avec le CSE (chèques cadeaux, subventions culture…)
by ploum,Ysabeau,ted,Benoît Sibaud from Linuxfr.org
Alors que sort la version audiolivre de mon roman cyberpunk Printeurs, dont il a été question sur ce site, j’ai le plaisir de vous annoncer une autre sortie très punk, la version 1.0 du logiciel Offpunk, un navigateur optimisé pour la navigation déconnectée sur le « smolnet », incluant les protocoles https, gemini, gopher et spartan.
Offpunk est un logiciel écrit en Python et utilisable entièrement en ligne de commande : il s’affiche dans un terminal et n’utilise ni souris ni raccourci clavier. Chaque action nécessite une commande. Le rendu des pages et des images se fait dans l’afficheur « less » (en utilisant chafa pour les images).
Il n’a échappé à aucune personne intéressée par l’informatique que le web prend de l’ampleur, au point d’être souvent confondu avec Internet. Ce qui n’était au départ qu’un protocole parmi d’autres tend à devenir le réseau sur lequel il s’appuie. Ce monopole du web s’accompagne d’une surcharge des contenus. Charger une simple page web représente aujourd’hui des dizaines voire parfois des centaines de connexions et, le plus souvent, plusieurs mégaoctets de téléchargement. Beaucoup de ces données et connexions sont au détriment de l’utilisateur : les requêtes servent à le pister et l’espionner, les données téléchargées cherchent à lui afficher des publicités ou à le renvoyer vers des réseaux sociaux monopolistiques. Le tout en ralentissant sa connexion et le forçant à mettre à jour régulièrement son matériel pour faire tourner des navigateurs de plus en plus gourmands.
Face à ce constat, de plus en plus d’utilisateurs se tournent vers un minimalisme matériel, un minimalisme d’usage voire un minimalisme dans le design de leur propre site. D’autres réinvestissent le vénérable protocole Gopher, inventé un peu avant le web et qui permet d’afficher du texte brut à travers des listes de liens (les « GopherMaps »).
En 2019, le dévelopeur Solderpunk, utilisateur du réseau Gopher, s’est décidé de l’améliorer et a créé les spécifications d’un nouveau protocole : Gemini. Le nom est une référence au programme spatial Gemini qui était à peine plus compliqué que le programme Mercury (référence à Gopher) et beaucoup plus simple que le programme Apollo (symbolisant le web). Le réseau Gemini s’appuie sur un format de texte, le « Gemtext », bien plus simple que la syntaxe des menus Gopher (le Gemtext est un markdown très simplifié et optimisé pour être facile à interpréter). Gemini impose également une connexion chiffrée par SSL entre le client et le serveur. Le but de Gemini était de créer un protocole simple, sécurisé, utilisable et ne pouvant pas être étendu pour afficher des publicités ou pister les utilisateurs.
Accéder au réseau Gemini demande l’installation d’un client, comme Offpunk. Un client graphique populaire est Lagrange. Ceux ne pouvant installer un client peuvent utiliser un proxy sur le web. Mais je recommande bien entendu Offpunk, qui ne nécessite pas d’installation (il suffit de lancer le fichier python dans un terminal).
Le succès de Gemini est de plus en plus important. Le nombre de « gemlogs » (les blogs sur Gemini) ne cesse d’augmenter et des applications originales voient le jour, voire complètement délirantes comme Astrobotany qui permet de faire pousser et de récolter des plantes virtuelles. Grâce à jpfox, il est d’ailleurs possible de lire Linuxfr sur Gemini.
Notons également la page Antenna, qui agrège les derniers posts des gemlogs choisissant de s’annoncer sur ce service. Un autre explorateur de l’espace Gemini est Cosmos, qui liste les réponses entre les posts.
Anecdotiquement, quelques utilisateurs de Gemini ont souhaité rendre le protocole encore plus simple en supprimant le chiffrement et en simplifiant la structure des requêtes pour créer le protocole Spartan.
gemini://spartan.mozz.us/
Avec Offpunk, mettez-vous torse-nu et tentez : go spartan://mozz.us/.
La navigation déconnectée
Alors que je préparais l’idée de passer une année essentiellement déconnectée, ne m’autorisant qu’une synchronisation de mon ordinateur avec Internet par jour, je me suis rendu compte qu’aucun outil ne me permettait de garder contact avec le réseau Gemini. J’avais Newsboat pour télécharger régulièrement mes flux RSS favoris et je pouvais envoyer, par mail, les sites que je voulais visiter au service forlater.email (un service dont le code est opensource qui renvoie le contenu d’une URL reçue par mail). Rien de similaire n’existait pour Gemini.
Avec le protocole Gemini, Solderpunk avait développé un client minimaliste appelé AV-98, inspiré de son propre client Gopher, VF-1. Je me suis alors dit que je n’avais qu’à hacker ce logiciel assez simple pour sauvegarder sur le disque mes gemlogs préférés.
L’idée de base est assez simple : sauvegarder sur le disque chaque capsule (les sites geminis s’appellent « capsules ») visitée et utiliser le client sans connexion réseau. Si un lien suivi n’a jamais été visité auparavant, il est stocké dans une liste to_fetch.
Lorsque je me connecte pour synchroniser mes courriels et mes RSS, il me suffit de lancer un moteur de synchronisation que j’ai intégré qui va aller chercher ce qui est dans to_fetch mais également rafraichir mes gemlogs favoris.
Bien entendu, l’implémentation se révéla plus compliquée que prévu.
Jusqu’au jour où je me suis rendu compte que je ne recevais plus rien du service forlater.email. Joint par mail, le créateur me confirma une erreur qu’il corrigea quelques jours plus tard. Quelques jours que je mis à profit pour trouver une solution de rechange.
Vu que je pouvais désormais naviguer déconnecté sur Gemini, pourquoi ne pas en faire autant sur le web ? Après tout, il ne s’agissait « que » de créer un moteur de rendu HTML en console. Avec conversion des images en caractères Unicode grâce au logiciel Chafa.
Je fis le choix de me concentrer sur la lecture d’article. Les pages HTML sont donc passées à la moulinette de python-readability pour en extraire le contenu pertinent. Cela rend Offpunk impropre à la navigation web sur les pages d’accueil (il est possible de court-circuiter readability en utilisant la commande « view full » ou « v full » mais le résultat est rarement joli à voir).
Mais la plupart des pages d’accueil disposent, parfois sans même le savoir, d’un flux RSS. J’ai donc ajouté le support des flux RSS dans Offpunk (« view feed »). Au point de désormais me passer de Newsboat. Un simple « subscribe » sur une page va me proposer de m’abonner aux changements de cette page ou, si détecté, au flux RSS/ATOM lié à cette page.
Les supports de Gopher et de Spartan furent ajoutés pour le fun. Je pensais que Gopher était trivial à implémenter.
Bien entendu, l’impl…
Synchronisation
Pendant la journée, Offpunk peut donc être utilisé entièrement hors-ligne (commande « offline »). Toute requête non-connue est ajoutée à la liste « to_fetch ».
La navigation se fait essentiellement à travers un « tour » car il n’y a pas d’onglets. La commande t 5 8-10 ajoute les liens 5, 8, 9 et 10 de la page courant au tour. La commande t affiche la prochaine page à lire dans le tour. t ls affiche le contenu du tour et t clear le vide.
Si vous disposez d’une version de less récente (v572+), il est même pratique d’accomplir ces tâches au milieu de la lecture d’un long article empli de liens. q pour quitter less, suivi de t 12 13 14 pour ajouter les liens et v(ou view ou l ou less) pour revenir dans less à l’endroit exact de la lecture (cela ne fonctionne malheureusement pas pour les versions plus anciennes de less). La commande open permet d’afficher le fichier en cours dans un programme externe (surtout utile pour les images ou pour ouvrir une page donnée dans un navigateur graphique).
Les pages peuvent être ajoutées dans des listes personnalisables. La commande add toread ajoute la page courante à la liste "toread" (qui doit être créée préalablement avec list create toread). Cette liste est un simple fichier au format gemtext qui peut être édité avec la commande list edit toread. Il est possible de rajouter des commentaires, des notes. La commande help list donne plus d’informations sur les possibilités.
La commande subscribe, déjà évoquée plus haut permet de s’abonner à une page ou un flux RSS (si un flux RSS est détecté, il sera proposé).
Lors d’une connexion, la commande sync permet d’effectuer une synchronisation. Au cours de celle-ci, les contenus de la liste to_fetch seront téléchargés et ajoutés au prochain tour. De même, les pages auxquelles l’utilisateur est abonné seront rafraichies. Si un nouveau lien est trouvé dans ces pages, il sera immédiatement ajouté au tour. Pour rafraichir les abonnements, la commande sync nécessite une période, en secondes. sync 3600 rafraichit toute page de plus d’une heure. Ceci est bien sûr automatisable en ligne de commande avec offpunk --sync --cache-validity 3600 (la ligne de commande permet également d’accepter les erreurs de certificat, fréquente sur Gemini, avec --assume-yes et de modifier la profondeur avec laquelle Offpunk doit pré-télécharger du contenu. Par défaut, --depth 1 est utilisé afin de télécharger les images d’une page. Une profondeur plus grande est à utiliser à vos risques et périls).
La commande help permet d’avoir un aperçu de toutes les fonctionnalités d’Offpunk. Notons le très pratique cp url pour copier l’URL de la page en cours dans le presse-papier et le fait que la commande go, sans argument, propose automatiquement d’accéder aux URLs présentes dans le presse-papier.
Offpunk est un seul et unique fichier python qui peut être lancé sans installation avec python3 offpunk.py ou ./offpunk.py. Les fonctionnalités de base fonctionnent sans dépendance particulière. La commande version vous permettra de voir les dépendances qui manquent pour activer certaines fonctionnalités. Un appel est lancé aux empaqueteurs pour rendre Offpunk disponible dans les différentes distributions.
L’un des objectifs de développement post-1.0 est de réduire ces dépendances en implémentant ce qui peut l’être directement sans trop d’effort. J’ai notamment le projet de réécrire le moteur de rendu HTML d’Offpunk pour ne plus dépendre de la libraire Ansiwrap. Bien entendu, je subodore que l’implémentation se révèlera… plus compliquée que prévu.
L’un des points importants d’Offpunk est son cache, sauvegardé dans ~/.cache/offpunk/ (ou autre suivant les variables $XDG). Ce cache ne comporte aucune base de donnée mais est le simple reflet des fichiers téléchargés. Par exemple, le contenu de https://linuxfr.org/journal/ sera dans ~/.cache/offpunk/https/linuxfr.org/journal/index.html.
Cette structure est très simple à comprendre et à manipuler. (Certains utilisateurs ont même rapporté utiliser offpunk comme une alternative à wget pour les capsules Gemini). L’utilisateur peut à sa guise effacer des fichiers si le cache prend trop de place ou utiliser le contenu du cache dans d’autres logiciels. Le principal défaut est que le mimetype annoncé par le serveur pour chaque fichier n’est pas préservé et qu’il faut donc le déduire du fichier lui-même lors de la navigation hors-ligne (ceci est fait en combinant les fonctions standards python-mime avec la librairie python-magic).
Conclusion
Alors que je pensais vivre une année vraiment déconnectée, force est de constater qu’Offpunk permet de « tricher ». Ceci étant dit, le confort apporté par Offpunk dans mon terminal configuré à mon goût rend le web traditionnel particulièrement agressif. Je saigne des yeux chaque fois que je dois lancer un véritable navigateur web sur une vraie page pleine de couleurs et de JavaScript.
Offpunk s’est également révélé très utile en voyage. Le manque de connexion n’est plus du tout un problème. Je peux passer plusieurs jours à simplement lire des contenus intéressants de ma liste toread, les trier et les relire (je crée une liste par projet, rajoutant parfois des notes dans la liste. Par exemple list edit freebsd me permet d’annoter les articles que j’ai sauvegardé sur le sujet freebsd). Offpunk ne dispose pas (encore?) d’un moteur de recherche mais quelques coups de ripgrep dans le cache me permettent de trouver des articles que j’ai lu et archivé voire, dans plusieurs cas, des informations que je n’avais jamais lues mais qui avaient été emmagasinées préemptivement. J’explore l’idée d’intégrer python-whoosh pour rechercher directement dans le cache.
À noter que la commande gus permet de faire une recherche sur le réseau Gemini à travers le moteur geminispace.info et de récolter les résultats à la prochaine connexion.
Je conseille Offpunk à celles et ceux qui veulent passer plus de temps en ligne de commande et/ou moins de temps sur leur navigateur. D’une manière générale, je conseille l’expérience d’utiliser Offpunk pendant quelques heures, quelques jours ou plus si affinités pour simplement vous interroger sur le rapport que vous avez au Web et à la connexion permanente.
Si le sujet de la déconnexion vous intéresse, je vous invite à lire mon journal de déconnexion (sept chapitres parus à ce jour). J’ai bien entendu dû noter une exception pour proposer cette news…
Bonjour,
Je connais l'architecture MVC mais pas vraiment d'autres architectures…
Est ce que vous connaissez de bonnes ressources pour apprendre?
Là j'apprend avec les projets open source et les tests unitaires à déployer le code sur plusieurs fichiers et éviter les gros blocs d'un seul coup, mais je ne suis pas encore au top…
L’AFPY contient déjà des projets open-source (notamment au niveau d’outils de traduction) mais on pourrait développer un projet (ou reprendre un existant) afin de travailler ensemble sur un projet open-source.
Ainsi chaque personne pourrait faire des contributions et recevoir des retours de merge-request (du mentoring en quelque sorte). ça peut être utile pour des ceux qui débutent d’avoir des retours un peu axé “monde professionnel” (maintenance, sécurité, modularité).
On pourrait éventuellement communiquer en français si les personnes ne sont pas à l’aise en anglais. On pourrait fixer la durée dans le temps / se charger juste d’un lot d’évolutions.
Voila c’est un premier pas pour recenser les personnes interessées, si vous avez une idée de projet un peu générique, avec une approche simple - N’hésitez pas à faire un retour ici, je vais attendre quelques avis d’abord
Letsignit est une société marseillaise créée en 2013 et née de notre expertise sur le métier de l’email. Notre solution BtoB permet la gestion et le déploiement automatisé de signatures emails personnalisées, les transformant ainsi en canaux de communication pour les marques.
Tout cela à grande échelle et pour plus de 300 000 collaborateurs dans des entreprises comme Pernod Ricard, Sephora, Rouge Gorge, FFF, Carglass, Médiamétrie, Alstom, Suez, Stéphane Plaza.
La croissance actuelle et notre statut de Microsoft Gold Partner renforcent notre position de leader sur le marché de la signature mail marketing.
Le poste
Nos plateformes, présentes dans 5 pays, enrichissent plus de 6 millions d’emails chaque jour pour plus de 4000 entreprises dans le monde.
Pour soutenir la croissance du nombre de clients et donc du volume d’emails traités nous recrutons des développeurs Backend dont la principale mission sera de créer et faire évoluer nos microservices en collaboration avec nos ingénieurs infrastructure.
L’essentiel du backend est écrit en Python (Flask, asyncio/aiohttp), hébergé principalement sur Azure et les challenges sont multiples.
Responsabilités
Développement et maintenance de nos microservices
Collaboration avec notre équipe infrastructure (philosophie DevOps)
Elaboration de nouvelles features et enrichissement de nos APIs
Mise en place de metrics et de dashboards pour monitorer vos microservices en production
Déployer plusieurs fois par jour
Participer au design de l’architecture et aux spécifications techniques
Collaboration avec l’équipe, partage de bonnes pratiques
Votre profil
Expérience précédente dans la gestion de microservices et le scaling
Très bonnes connaissances en programmation backend (Python, MongoDB, Redis, Elastic Search)
Bonne expérience dans la mise en place de tests automatisés
Habitué à travailler en petites équipes Agiles (Squad)
Capable de collaborer avec des équipes hétérogènes (infrastructure, front-end, produit)
Fort intérêt pour l’amélioration continue du produit, des méthodes et des outils DevOps
Ambitieux et attiré par les challenges liés à l’augmentation de la volumétrie
Les bonus qui nous plairont
Expérience dans un environnement Infra-As-Code (Terraform, Pulumi)
Ceinture noire en monitoring et observabilité des microservices
Vous connaissez les architectures Cloud-Native et vous savez que la CNCF ne fait pas du transport ferroviaire
Expérience sur d’autres protocoles et technologies importantes chez nous comme SMTP ou LDAP/Active Directory
Vous n’êtes pas allergique au frontend
Environnement de travail
Dare, Care, Fair, Fun des valeurs qui nous tiennent à et qui sont représentées par :
Des bureaux grandioses à 2 pas du Vieux port avec : bar, cheminée et espace de pause (y a même une tireuse à ).
Une dimension CARE ++ pour collaborer en sérénité : 12 jours de congés payés supplémentaires, un forfait mutuelle aux petits oignons, financement de cours de Yoga/Pilate & Fitness, carte Swile, etc.
Une formule télétravail sur-mesure : de 0 à 100 % télétravail selon les équipes.
La possibilité de participer à des projets de bénévolat et à des initiatives à impact social : jours de congés offerts et soutien financier des projets des collaborateurs par Letsignit.
Une dynamique et une culture incroyable avec de nombreux évènements internes : petits dej, after work, team building, kick off, etc.
Un attachement pour la formation, l’apprentissage et la montée en compétences des collaborateurs : financement de meet up.
Des Innovation Days organisés 2 fois par an.
Une culture internationale : Letsignit a des bureaux à Seattle et Montréal et a des ambitions de croissance mondiale.
La société lyonnaise PEAKS cherhce un développeur Python pour un de ses clients (Lumapps). Prévoir 6 mois d’intervention, avec possiblité full remote.
Contact : 04 78 69 69 80/https://www.peaks.fr/
" Notre client accompagne les entreprises dans leur transformation digitale sur la communication, la collaboration et aussi l’engagement de leurs clients, partenaires, et surtout des employés.
Depuis ses débuts notre client est devenue une entreprise internationale avec des bureaux à New York, Austin, San Francisco, Paris, Lyon, Londres et Tokyo. Lumapps compte plus de 4 millions d’utilisateurs et a levé 30 millions d’euros auprès de fonds leaders européens. Notre client accompagne aujourd’hui des entreprises telles que Veepee, Colgate-Palmolive, Airbus…
L’équipe
L’équipe data travaille tous les jours pour améliorer le produit.
Elle est en charge de deux aspects fonctionnels:
une partie analytics qui permet à nos clients d’avoir accès à des statistiques sur l’utilisation de leur plate-forme
une partie intelligence artificielle qui a pour but de faire descendre le bon contenu, à la bonne personne
Dans cette équipe, on aime les collaborateurs:
curieux : ils s’intéressent aux nouveautés du domaine de la data et se remettent régulièrement en question
impliqués : ils ont à cœur l’amélioration permanente de l’équipe, du produit et de l’entreprise.
bienveillants : ils s’efforcent de chercher des solutions plutôt que des responsables.
On considère qu’une grosse partie de notre métier c’est de travailler à comment bien travailler.
Les missions
En 2021, on a construit une base solide d’analytics dans le produit.
En 2022, on veut s’interfacer beaucoups plus avec le travail des autres équipes de l’engineering :
Tracking plus fin dans le produit
Rendre cette data utilisable par les autres micro-services
Créer des agrégats encore plus pertinent
Pousser sur l’application de recommender systems
On a besoin de toi pour nous aider à y parvenir: l’analytics est remonté comme le point #1 sur lequel on doit progresser dans le produit d’après une étude faite auprès de nos clients.
Dans ce poste, tu seras amené à garantir l’intégrité de l’infrastructure logicielle qui traque le parcours utilisateur. tu seras responsable avec l’équipe de concevoir, calculer et de servir des statistiques d’utilisation de la plate-forme. On aura besoin de toi et de ton expérience pour améliorer la qualité du produit et les processus de l’équipe. Tu seras également amené à travailler sur nos projets de machine learning : mieux comprendre nos utilisateurs et leurs contenus pour rendre l’intranet plus intelligent.
L’environnement technologique
Produit intégralement SAAS
Python principalement, mais aussi du Go dans d’autres équipes.
Infrastructure sur Kubernetes
Choix de la machine: PC/Mac
Choix de l’OS libre
Choix de l’IDE libre
Hébergement Google Cloud Platform (GCP) & Azure
Bases de données SQL (PostgreSQL), BigData (BigQuery)
Messaging (pubsub / eventhubs)
Pipelines de données fait avec Apache Beam pour un déployment sur Dataflow sur Google Cloud Platform
Architecture en services
Frontend en React avec du legacy en AngularJS
Compétences
Expérience de développement avec un ou plusieurs langages objet : Python
Expérience en base de données relationnelles : PostGreSQL, BigQuery
Expérience sur une architecture Data
Architecture logicielle
Design d’API
Intérêt pour le machine learning est un plus. En particulier : le MLOps, le text mining et les systèmes de recommandation.
"
SportEasy veut révolutionner la pratique du sport en simplifiant la vie de toutes les équipes, clubs et associations sportives et récréatives.
Son application web & mobile permet aux dirigeants et entraîneurs de gagner du temps dans leur gestion administrative et sportive, aux joueurs et parents de partager leurs émotions avec leurs coéquipiers.
Lancée fin 2012 par Albin Egasse et Nizar Melki, elle a été adoptée par 1.900.000 utilisateurs dans le monde.
Vainqueur de plusieurs récompenses (Prix de l’innovation sportive numérique, Prix d’Innovation de la Ville de Paris, Trophée Sporsora, Sport Stratégies Award), leader sur le marché francophone, SportEasy va effectuer une troisième levée de fonds cette année pour enrichir ses services, accélérer sa croissance et ainsi devenir l’écosystème digital n°1 sur le sport amateur en Europe.
Descriptif du poste### ### Le produit et la tech chez SportEasy
Le produit et la tech sont au coeur de la culture et de la stratégie de SportEasy : nos deux fondateurs sont ingénieurs, nos premiers employés étaient tous développeurs - et notre moteur de croissance est le bouche à oreille, i.e. la qualité de nos applications et notre capacité à mettre régulièrement en production des fonctionnalités utiles à nos utilisateurs.
SportEasy développe des applications web, iOS et Android, ainsi que des intégrations techniques avec différents partenaires. La plateforme repose sur un backend en Python/Django, et notre stack technique est décrite dans le détail ici.
Nous recherchons des développeurs ingénieux et passionnés pour rejoindre un projet qui grandit plus vite que nous, et nous force à progresser avec lui !
Le poste de développeur back-end
En tant que développeur backend, tu auras des responsabilités essentielles et variées :
maîtriser le backend de la conception aux mises en production, et le maintenir à un excellent standard de qualité
implémenter la logique de nouvelles fonctionnalités de SportEasy, en lien avec le product owner
développer les API pour alimenter nos applications web, iOS et Android, en lien avec les développeurs frontend
s’assurer d’une couverture de tests optimale
travailler en intégration et déploiement continus (CI/CD)
mettre en place et suivre des métriques d’utilisation des fonctionnalités
mener des projets d’intégration avec des partenaires techniques (ex. : fédérations, centres sportifs, autres startups)
améliorer l’existant (enrichir des fonctionnalités, pérenniser et scaler notre architecture, optimiser les temps de réponse)
proposer des outils internes pour rendre les équipes tech/produit, support et sales/marketing plus efficaces
être force de proposition quant à la vision tech de SportEasy
collaborer avec tous les devs pour garantir une cohérence entre les plateformes et faire progresser l’équipe tech
Ce que nous t’apportons- Une opportunité unique : devenir un pilier d’une équipe tech encore petite, mais qui développe un produit déjà utilisé par 1,9M de personnes
Un challenge à relever : mettre ton expertise et un haut niveau d’exigence au service d’une startup aux ambitions internationales
Une grande autonomie : possibilité de télétravailler régulièrement, grande marge de manoeuvre tech (architecture, choix d’implémentation, refactoring, maintenance, deploy)
Un esprit d’équipe exceptionnel : ambiance décontractée, équipe hyper soudée, sport toutes les semaines (si tu en as envie), séminaires mythiques
Profil recherché- Diplôme d’ingénieur, master ou école d’informatique (bac +5)
4+ années d’expérience en développement (2+ années d’expérience en Python/Django)
Solide connaissance de l’écosystème web (API, bases de données, contraintes navigateurs/mobiles, Docker, culture data-driven, bonnes pratiques, etc.)
Expérience sur (ou appétence pour) des services proches des utilisateurs
Rigueur, excellence technique, forte exigence individuelle
Curiosité, créativité, envie d’apprendre et d’expérimenter de nouvelles choses
Autonomie, esprit entrepreneurial et forte capacité d’adaptation
Esprit d’équipe, capacité à bien communiquer, énergie et motivation
Process de recrutement1. Tests techniques en ligne
Echange téléphonique avec le CTO et/ou un fondateur
Entretiens dans nos bureaux avec le CTO, un product owner, un développeur et un fondateur
Le 15 février 2022 est sortie la version 2.3 du logiciel de gestion de la relation client Crème CRM (sous licence AGPL-3.0). La précédente version, la 2.2, était sortie quasiment un an auparavant, le 19 janvier 2021.
Pas mal de choses au programme, notamment la possibilité de personnaliser le menu principal, la disponibilité comme un paquet Python classique et une image Docker de démonstration. Les nouveautés sont détaillées dans la suite de la dépêche.
Crème CRM est un logiciel de gestion de la relation client, généralement appelé CRM (pour Customer Relationship Management). Il dispose évidemment des fonctionnalités basiques d’un tel logiciel :
un annuaire, dans lequel on enregistre contacts et sociétés : il peut s’agir de clients, bien sûr, mais aussi de partenaires, prospects, fournisseurs, adhérents, etc. ;
un calendrier pour gérer ses rendez‐vous, appels téléphoniques, conférences, etc. ; chaque utilisateur peut avoir plusieurs calendriers, publics ou privés ;
les opportunités d’affaires, gérant tout l’historique des ventes ;
les actions commerciales, avec leurs objectifs à remplir ;
les documents (fichiers) et les classeurs.
Crème CRM dispose en outre de nombreux modules optionnels le rendant très polyvalent :
campagnes de courriels ;
devis, bons de commande, factures et avoirs ;
tickets, génération des rapports et graphiques…
L’objectif de Crème CRM est de fournir un logiciel libre de gestion de la relation client pouvant convenir à la plupart des besoins, simples ou complexes. À cet effet, il propose quelques concepts puissants qui se combinent entre eux (entités, relations, filtres, vues, propriétés, blocs), et il est très configurable (bien des problèmes pouvant se résoudre par l’interface de configuration) ; la contrepartie est qu’il faudra sûrement passer quelques minutes dans l’interface de configuration graphique pour avoir quelque chose qui vous convienne vraiment (la configuration par défaut ne pouvant être optimale pour tout le monde). De plus, afin de satisfaire les besoins les plus particuliers, son code est conçu pour être facilement étendu, tel un cadriciel (framework).
Du côté de la technique, Crème CRM est codé notamment avec Python/Django et fonctionne avec les bases de données MySQL, SQLite et PostgreSQL.
Principales nouveautés de la version 2.3
Voici les changements les plus notables de cette version :
Les dépendances
Django 2.2 arrivant en fin de vie en avril 2022, nous sommes passés à Django 3.2, la dernière version LTS.
Notre version de la bibliothèque JavaScript jQuery était franchement ancienne, et une grosse mise à jour a été faite en passant à la version 3.6. Au passage nous avons aussi augmenté la version de notre calendrier FullCalendar qui est désormais la 3.10.
Jusqu’à présent, la minification du JavaScript et du CSS était faite, par défaut, par des logiciels en Java (respectivement Closure et YUICompressor). Il y avait certes moyen de ne pas faire de minification du tout, afin de ne pas avoir à installer Java, mais c’était dommage. Désormais la minification du JavaScript est faite par rJSmin, et celle de la CSS par csscompressor, tous deux codés en Python. Pour le CSS la taille des fichiers finaux est identique, mais la phase de minification est beaucoup plus rapide. Pour le JavaScript, la minification est là aussi très rapide, mais les fichiers finaux sont un peu plus gros qu’avant (installation par défaut: on est passé de 355Kio à 457Kio ; pour information c’est 822Kio sans minification). Les résultats sont suffisamment bons pour l’installation par défaut (et vous pouvez toujours utiliser Closure si vous le souhaitez).
La communication avec le gestionnaire de job, qui permet l’exécution de tâches longues et/ou périodiques, peut (sous Unix) se passer de Redis et plutôt utiliser une socket Unix.
La disponibilité en tant que paquet
Le travail pour faire de Creme un paquet Python classique avait été entamé dans les versions précédentes, mais n’était jusqu’ici pas complet. Lorsque vous déployiez une instance, vos fichiers de configuration (ainsi que votre propre code dans le cas où vous vouliez avoir vos modules personnalisés) traînaient encore au milieu du code de Creme (il y avait en fait moyen de bidouiller pour éviter ça, mais ce n’était ni documenté ni tout à fait fonctionnel). Ce n’est, désormais, plus le cas, vos fichiers sont complètement séparés, et Creme peut être installé comme un paquet Python comme les autres, typiquement dans un virtualenv.
Ainsi nous avons rendu disponible Creme sur PyPI, le dépôt de paquets Python bien connu, ce qui permet de l’installer avec un simple pip install creme-crm (ce qui est un poil moins rebutant que devoir faire un git clone).
Le menu principal configurable
Il est maintenant possible de modifier graphiquement le menu principal : on peut rajouter ou enlever des conteneurs et des entrées. Avant il fallait forcément le faire via du code, ce qui limitait à des utilisateurs plus avancés, et rendait les modifications bien plus pénibles à déployer en production.
Les champs optionnels (c’est-à-dire qu’on peut laisser vides dans les formulaires) peuvent être configurés comme obligatoires, comme on pouvait déjà le faire avec les champs personnalisés.
Les formulaires personnalisés peuvent maintenant être spécifiques à un rôle utilisateur.
L’historique a été amélioré : les valeurs des textes longs, des champs Many-To-Many (choix multiples) sont désormais enregistrés, les modifications des champs personnalisés sont enfin historisés.
La recherche globale peut désormais se faire dans les champs personnalisés (de type texte uniquement).
Les types de Propriétés (un peu l’équivalent de tags dans Creme) peuvent désormais être désactivés ; ils ne sont alors plus proposés dans les formulaires.
Les alertes et les Todos validés peuvent être affichés (ils étaient forcément cachés jusqu’à présent).
L’interface de configuration des blocs des fiches a été améliorée ; elle est plus intuitive, compacte, et des descriptions s’affichent pour chaque bloc, ce qui amène une meilleure « découvrabilité » de leurs fonctions.
L’image Docker de démo
Si notre démo en ligne a l’avantage d’être accessible en un clic, elle a quelques inconvénients. Nous sommes obligés de rendre inaccessible l’interface de configuration (pour éviter que des configurations « cassées » par les uns soient utilisées par les autres), il n’est pas conseillé d’y mettre des données sensibles (car visibles par les autres) etc.
Bien que l’installation ne soit pas très complexe (surtout avec la disponibilité sur PyPI), nous proposons aussi désormais une image Docker de démo qui permettra à ceux qui le désirent de se faire rapidement une idée des capacités du logiciel.
Cette image a été conçue comme plutôt légère, à des fins de démonstration :
- elle utilise SQLite, pour ne pas dépendre d’une image pour PostGreSQL/MySQL.
- l’absence par défaut de Java dans la nouvelle configuration par défaut nous a permis d’alléger l’image (il y aurait sûrement encore à gratter).
- nous avons utilisé la nouvelle possibilité d’utiliser des sockets Unix plutôt que Redis pour ne pas dépendre d’une image pour ce dernier.
Que nous prépare la prochaine version ? Au moins le passage à Python 3.7 comme version minimale, et une refonte des imports de données depuis les e-mails. La feuille de route n’est pas encore totalement établie, mais peut-être que vos propres contributions (en code ou en argent) en feront partie.
Améliorer les transports, faciliter les déplacements des gens, faire avancer les solutions de mobilités éco-responsables, voilà ce qui nous anime.
Créée en 2019, Entropy développe des outils d’aide à la décision pour l’organisation et la gestion des services de mobilité.
Nous sommes les premiers à avoir développé un modèle de prédiction des déplacements des personnes, par intelligence artificielle, précis et fiable.
La R&D est au cœur de notre stratégie de développement d’entreprise car nous voulons rester à la pointe des avancées technologiques et scientifiques dans notre domaine.
Contexte et missions
Vous êtes passionné d’informatique et souhaitez intégrer une entreprise en phase de développement en étant à la base de sa construction. Vous souhaitez mettre vos compétences au service d’Entropy pour :
Développer les nouvelles fonctionnalités de nos logiciels d’aide à la décision
Améliorer les performances des applications
Trouver et réparer les bugs répertoriés par notre Q/A
Création d’un client pour récupération de données Web (web scraping)
Profil recherché
Vous êtes capable de développer des serveurs et des d’interfaces graphiques pour des applications web.
Vous maîtrisez l’anglais technique.
Vous savez être force de proposition de nouvelles idées ou améliorations de design et d’architecture.
Vous avez une appétence pour l’UX design et aimez les interfaces pensées-utilisateur.
Vous avez par ailleurs une bonne culture technique et faites preuve de curiosité pour l’informatique en général.
Vous accordez de l’importance à un code de qualité, simple et propre.
Vous justifiez d’expériences avec les langages informatiques et leurs utilisations:
Typescript React: interface Web dynamique
Python: client Web et/ou serveur Web
Go: client Web et/ou serveur Web
Vous avez le goût de la création et de l’invention.
Enfin, vous avez la capacité de présenter vos développements techniques, vous êtes proactif et savez travailler en équipe.
Pourquoi nous ?
Si vous souhaitez travailler dans un environnement de haut niveau scientifique, ambitieux et solidaire, Entropy est fait pour vous. Nous vous proposons également :
Une prime sur objectifs
Une participation au CA généré par vos inventions
Des congés illimités
Les mutuelle et prévoyance Alan prises en charge à 100 %
Le remboursement de votre Navigo à 100 %
Informations complémentaires
Contrat : CDI
Salaire : Selon profil, entre 33 000 et 40 000 € brut annuel
Date de début : Dès maintenant
Lieu de travail : Versailles (78), ou télétravail.
Processus de recrutement
Un premier entretien téléphonique de contact (20’) avec notre CTO
Un test technique composé de deux exercices indépendants
Un entretien physique avec les équipes Produit et R&D
je cherche du renfort pour ma startup Netsach - du coup en freelance.
Ca serait pour rejoindre une team composée de CTO + 2 dev backend + 3 dev frontend ; ouvert à du full remote ou possibilité de venir dans nos locaux à Paris Bastille pour profiter du café gratuit et des restaus autour
Plus d’info sur la mission :
Intervention sur une plateforme de traitement vidéo en cloud hybride (AWS + On Prem) pour réaliser du dev Python
Il y a peu j’ai décidé de participer un peu au fonctionnement de ce site que j’ai beaucoup aimé, et vous le connaissez, HackinScience !
Je ne suis pas développeurs mais j’aime beaucoup le langage python (avec lequel j’ai appris à coder), j’ai donc voulu partager des choses que je trouvais intéréssantes dans le langages.
Alors bien sûr, il peut y avoir des incompréhension, des petites erreurs à corriger, etc. N’hésitez surtout pas à venir vers moi pour que j’essaie de les corriger. J’essaie de m’améliorer pour ensuite, pourquoi pas, proposer de nouveaux exercices mieux écrits !
La DSI de mon client vient de créer une nouvelle direction IT pour refondre une partie de son métier.
Cette nouvelle direction intègre aussi bien dans son parc des applications en mode SaaS que des développements internes.
Ces applications sont utilisées / déployées par de multiples canaux :
On Premise sur des VMs interne (BDD)
Sur du CaaS (OpenShift)
en mode SaaS via des éditeurs.
Descriptif du poste :
Vous interviendrez en tant que développeur python d’une application permettant la communication entre plusieurs services distants.
L’application au cœur du SI permet de faire transiter des messages entre plusieurs applications avec une revalorisation au milieu.
Les connexions aux services se font via des API REST et SOAP (1 seule faut pas abuser )
L’enjeu est de fiabiliser l’envoie et la reception des messages (alerte, retry etc…).
Des tests unitaires (pytest) et d’intégration sont en place.
L’application est appelée par un ordonnanceur jenkins qui permet de gérer la queue d’entrée.
Le déploiement de l’application se fait dans des pods sur un cluster OpenShift et la gestion des dépendances se fait via poetry.
Vous serez rattaché aux architectes transverses et travaillez en amont des équipes de développement des services.
Le poste est situé à Paris, la majorité du travail peut être fait en remote mais il faut pouvoir se déplacer si nécessaire sur site.
C’est ouvert aux freelances comme à un personne en CDI (42K-52K)
N’hésitez à revenir vers moi en MP si vous êtes intéressé ou à partager cette offre.
selon la procédure recommandée dans le document sur la traduction de la documentation, il faut créer une branche par fichier modifié.
en tant que traducteur débutant je fais beaucoup de traduction de fuzzies pour me faire la main.
en conséquence j’ai plein de branches (comme me l’a fait remarquer Jules hier à juste titre, et je sais pas si ma réponse à été très claire :-/ ) dans mon dépôt…
Je ne sais pas si cette approche “casserait” le traitement usuel des valideurs, mais je me demande si, pour les fuzzies uniquement, il serait possible de faire une unique branche.
Nous sommes à la recherche d'un ingénieur junior pour rejoindre l'équipe responsable du développement des outils permettant à Linaro de tester l'ensemble des RC du noyaux linux.
Grâce à nos outils, LKFT (Linux Kernel Functional Testing) a été capable de compiler et tester 1 203 113 variantes du noyaux linux en 2021. Évidemment l'ensemble du processus de compilation et de test est entièrement automatisé.
Nous développons principalement deux outils :
* LAVA : automatisation du déploiement, boot et test sur une ferme de boards (rpi, juno, …). LAVA est depuis quelques années l'outils open source de référence pour le test sur boards. LAVA est utilisé par de nombreuses entreprises/organisation de part le monde (Linaro, Collabora, bootlin, …).
* TuxSuite : un service de compilation et de test (via QEMU) dans les nuages. C'est ce service qui nous permet de compiler une si grande variété de noyaux linux et qui nous permettra prochainement d'augmenter les capacités de tests. Le service est propriétaire mais est basé sur un ensemble d'outil open source que nous avons créé (tuxmake et tuxrun entre autre).
Le poste :
* développer et maintenir les outils open source et privés de l'équipe (LAVA, tuxmake, tuxrun, tuxsuite, …)
* ajouter le support pour une nouvelle board dans LAVA
* debugger une erreur de compilation ou régression dans un test
* full remote avec une semaine tous les 6 mois tous ensemble (si possible avec le covid)
Prérequis :
* dévelopeur junior
* python
* english (l'équipe est distribué globalement)
Si possible :
* boards: rpi ou autre
* cloud: terraform, docker/podman, packer, lambda, s3, …
Il est évidement qu'un développeur junior ne peux pas connaître l'ensemble des technologies listé ci-dessus. L'équipe proposera donc des formations internes.
Dependabot, notre ami de github About alerts for vulnerable dependencies - GitHub Docs permet de surveiller les différentes dépendances de votre projet python, il analyse simplement le fichier requirements.txt et vous tiens informé des différentes mises à jour des dépendances.
Il prépare un merge automatique avec une description de la vulnérabilité concernée, il vous demande ensuite si vous souhaitez l’appliquer, si votre projet n’est simplement pas concerné ou si vous souhaitez l’ignorer.
Voyons un peu pourquoi ces choix.
Pourquoi cet article?
Déjà, j’ai vu qu’on développe ici un projet similaire, et c’est très bien, mais ce forum est aussi fréquenté par des débutants qui vont sauter sur la mise à jour continuelle des dépendances de leurs projets et… vont vite apprendre comme nous tous le revers de la médaille.
Mettre une librairie à jour n’est pas anodin!
Déjà, elle peut nécessiter une version différente de python, ce qui peut briser le code de votre applications, prenons par exemple, le changement d’une version 3.5 à 3.10, alors que dans la 3.5 vous pouviez tranquillement déclarer vos variables globales depuis un import et les utiliser dans une fonction d’un autre module (le scope était fonction, module). Votre code ne fonctionnera plus avec la version 3.10, pourquoi? Et bien parce que la vie est injuste et les programmeurs malveillants (je plaisante). Le scope à changé, maintenant on doit obligatoirement importer une variable avec le mot clé global.
Une librairie peut aussi dépendre d’autres librairies, et certaines de vos dépendances de librairies… incompatibles!
Recoder l’intégralité de votre programme pour la mise à jour d’une librairie qui ne contient aucune vulnérabilité applicable à votre projet est quelque peu contre-productif.
Suis-je concerné?
Oui, une mise à jour même d’une vulnérabilité majeur peut ne pas concerner votre projet pour plein de raisons, soit vous n’utilisiez simplement pas la fonction incriminée, soit vous aviez déjà appliqué de solutions correctives sur une ancienne librairie (surcharge de fonctions, réécriture partielle ou complète d’objets, logique programme différente… le choix est vaste).
Donc prudence avant d’appliquer tout et n’importe quoi.
Démarrer ses projets avec la dernière version stable de python est un bon réflexe, ainsi qu’avec les dernières librairies bien à jour et tout, mais ensuite on fige!
Le temps passera, il vous faudra mettre à jour votre projet de façon progressive, envisager le passage à une version plus récente de python par exemple sera une bonne chose, une fois que celle-ci sera significative ou que vous aurez avancé dans votre projet.
En revanche, le faire à chaque mise à jour de dépendance, là c’est une autre histoire qui peut coûter énormément de temps pour un gain inexistant.
Dans github, pour activer notre ami dependabot c’est dans l’onglet “security” >> “Enable Dependabot Alerts” il y a plein de bricoles sympa dans cette section, mais ça sort du cadre de ce post ;-).
J’ai fait une bibliothèque pour un dictionaire ordonné sans copie. Contrairement au dict python, qui utilise l’ordre d’insertion, cela utilise la comparaison < entre les objets. Aussi, cela crée une nouvelle structure plutôt que de se modifier sur-place, ce qui permet d’implémenter (sans copier, voir le paragraphe suivant) une fonction “annuler” / “revenir a la version précédente”.
Les benchmarks montrent que c’est plus intéressant que faire des copies de dict a partir de 1000 éléments sur cpython et 100 éléments sur pypy.
Si vous avez une idée d’application n’hésitez pas a partager.
J’ai fait une bibliothèque pour un dictionaire ordonné sans copie. Contrairement au dict python, qui utilise l’ordre d’insertion, cela utilise la comparaison < entre les objets. Aussi, cela crée une nouvelle structure plutôt que de se modifier sur-place, ce qui permet d’implémenter (sans copier, voir le paragraphe suivant) une fonction “annuler” / “revenir a la version précédente”.
Les benchmarks montrent que c’est plus intéressant que faire des copies de dict a partir de 1000 éléments sur cpython et 100 éléments sur pypy.
Si vous avez une idée d’application n’hésitez pas a partager.
by Stéphane Blondon <stephane@yaal.coop> from Yaal
AlpineLinux est une distribution souvent utilisée pour des conteneurs (lxc/lxd, Docker, etc.) car la taille des images d'AlpineLinux est minuscule (seulement 6 Mo !).
C'est un avantage réel, surtout si on a beaucoup de conteneurs. Si cette performance est remarquable, il est cependant nécessaire de prendre en compte l'ensemble des choix réalisés par la distribution.
Sur le site web, il est clairement indiqué « Alpine Linux is a security-oriented, lightweight Linux distribution based on musl libc and busybox. ». Voyons quelles contraintes cela apporte :
Les performances de musl
AlpineLinux a fait le choix de musl comme bibliothèque C, contrairement à la plupart des distributions Linux qui utilisent la libc GNU. Il peut y avoir des problèmes de compilation ou d'exécution de logiciel qui ont été testées avec la glibc et pas avec musl mais nous n'avons jamais rencontré ce problème.
À l'exécution, musl est plus lente que la glibc. Par exemple, une compilation de cpython est deux fois plus lente qu'avec la glibc. C'est un problème connu des mainteneurs qui pourrait être résolu dans le futur en changeant d'allocateur mémoire. Mimalloc semble être une bonne piste à l'avenir, mais pour l'instant, il faut vivre avec ce niveau de performance.
L'environnement espace utilisateur
busybox
AlpineLinux utilise busybox pour les outils Unix de base. Busybox est un projet éprouvé et utilisé depuis de nombreuses années dans l'embarqué.
Ce choix permet de minimiser la taille des outils embarqués par Alpine.
Mais, si le développement de script shell est réalisé sur un système disposant des outils GNU, il est possible qu'il y ait des erreurs lors de son exécution sur un système Alpine car le comportement n'est pas exactement le même : par exemple, il peut manquer des paramètres à certains outils (en particulier lorsque ce sont des extensions GNU à la norme Unix). Dans ce cas, il faut modifier le code ou installer un paquet pour embarquer l'outil GNU que l'on souhaite.
systemd
AlpineLinux utilise les scripts de démarrage classique Unix (dans /etc/init.d/) et non systemd. Selon les besoins et préférences de chacun, cela peut être une qualité ou un défaut.
Les mises-à-jour
Mettre à jour une version mineure d'alpine à l'autre (par exemple de 3.14 à 3.15) est très vite réalisé en quelques minutes. Comparé à la migration d'une version stable de Debian à la suivante, c'est étonnant et confortable puiqu'il n'y a pas de messages bloquants affichant les Changelog de changement incompatible ou des différences de fichiers de configuration entre la version du maitenant et celle du système en cours. L'inconvénient étant que les services peuvent être non fonctionnels ensuite...
Ce comportement n'est pas forcément un problème si l'usage est celui de conteneurs Docker qui sont supprimés et reconstruits à chaque modification. Dans le cas d'un usage classique avec des mises-à-jour, ça l'est beaucoup plus. L'usage d'instantanés (snapshot) peut permettre de limiter le problème : une fois la mise-à-jour faite, si des problèmes sont présents, il faut restaurer l'instantané fait avant la mise-à-jour puis chercher quel est le problème sur la version mise-à-jour.
Conclusion
Ces différents défauts ne sont pas forcément rédhibitoires selon l'usage fait d'AlpineLinux (par exemple pour des environnements docker locaux jetables). Il semble cependant important de les prendre en compte et se demander s'ils sont bloquants ou non avant de décider d'utiliser AlpineLinux selon l'usage prévu.
Après avoir utilisé AlpineLinux pour nos conteneurs lxc, nous avons conclu que l'utilisation de Debian était plus adapté à nos besoins dans ce cadre. Les prochains conteneurs seront donc basé sur Debian et les anciens migrés au fur et à mesure.
Je cherche, et ce n’est pas directement pour moi, aussi aimerais je bénéficier de votre expertise, des vidéos d’apprentissage de Python, pour débutant.
S’il y a une série de vidéos qui avance doucement, c’est encore mieux
Et enfin, je cherche ça en anglais.
C’est un peu une bouteille à la mer, car trouver des vidéos c’est facile, mais les vidéos pertinante c’est difficile.
Si vous vous souvenez de cours particulièrement intéressant, (pour débutant) Je suis preneur.
J’ai eu besoin d’analyser les paquets d’un projet Django pour le boulot, et n’ayant rien trouvé de suite, j’ai pris 3h pour monter un truc moche et rapide.
L’idée de base était de pouvoir :
Lister les paquets installés avec leur version en cours
Visualiser si des paquets avaient une version à la rue (par rapport à la dernière sortie)
Visualiser également le statut de développement des paquets
Visualiser si la dernière release était pas très vieille indiquant, potentiellement, un paquet moins/plus maintenu…
Depuis, j’ai découvert (merci IRC) tout un tas de choses intéressantes depuis pip lui-même jusqu’à des outils plus ou moins intéressants/obsolètes/payants :
pip list --outdated
pip-check
pip-chill
pip-date
pip-outated
piprot
pur
safety
Certes, ces projets peuvent être intéressants, mais je trouve qu’ils ne répondent jamais à tout ce que j’en attends.
J’ai donc repris mon premier jet un peu moche et me suis ajouté la contrainte de ne dépendre d’aucun paquet externe. Voici ce que ça donne pour le moment en prenant le requirements.txt du site de l’AFPy (https://github.com/AFPy/site/blob/master/requirements.txt) :
On voit donc bien ici en jaune (warning) les paquets qui sont dans des statuts pas idéaux, les versions un peu en retard, et les dernières releases qui date de plus de 360 jours (oui, j’ai dit que c’était moche). On voit également en rouge (danger) les paquets vraiment en retard…
J’ai eu besoin d’analyser les paquets d’un projet Django pour le boulot, et n’ayant rien trouvé de suite, j’ai pris 3h pour monter un truc moche et rapide.
L’idée de base était de pouvoir :
Lister les paquets installés avec leur version en cours
Visualiser si des paquets avaient une version à la rue (par rapport à la dernière sortie)
Visualiser également le statut de développement des paquets
Visualiser si la dernière release était pas très vieille indiquant, potentiellement, un paquet moins/plus maintenu…
Depuis, j’ai découvert (merci IRC) tout un tas de choses intéressantes depuis pip lui-même jusqu’à des outils plus ou moins intéressants/obsolètes/payants :
pip list --outdated
pip-check
pip-chill
pip-date
pip-outated
piprot
pur
safety
Certes, ces projets peuvent être intéressants, mais je trouve qu’ils ne répondent jamais à tout ce que j’en attends.
J’ai donc repris mon premier jet un peu moche et me suis ajouté la contrainte de ne dépendre d’aucun paquet externe. Voici ce que ça donne pour le moment en prenant le requirements.txt du site de l’AFPy (https://github.com/AFPy/site/blob/master/requirements.txt) :
On voit donc bien ici en jaune (warning) les paquets qui sont dans des statuts pas idéaux, les versions un peu en retard, et les dernières releases qui date de plus de 360 jours (oui, j’ai dit que c’était moche). On voit également en rouge (danger) les paquets vraiment en retard…
Je vois souvent des personnes hésitantes, “je veux bien lancer un projet, mais oulala, t’as vu le prix de l’hébergement?” et ma réponse est: “Oui! Pas toi?”
Ok, fini de rigoler, le problème de Python, comme d’autres langages c’est que c’est chouette de réaliser une application, mais pour la rendre publique, lorsqu’on sort de github, ça devient un peu compliqué.
Pas de problème, tonton cGIfl300 va tout expliquer et gratis en plus, c’est pas bien?
Prenons un projet en django, j’aime bien parce que là c’est pas facile, il faut un serveur web qui supporte ton backend, installer quelques librairies exotiques parfois et pire, une base de données.
Alors là, c’est foutu, homme ou femme de peu de foi qui va balancer direct le tout sur github avec un “débrouillez vous moi j’ai juste testé en dev” ça va être limite.
La solution que je propose est volontairement orientée, je ne proposerais pas ici de solutions alternatives afin de ne pas compliquer la vie de chacun, l’objectif de cet article est de fournir une solution opérationnelle, pour le choix, chacun est libre d’adapter à ses besoins mes bons conseils.
Prérequis:
Avoir un projet django opérationnel, le projet de démo ira bien.
Avoir ouvert 3 comptes gratuits:
Delà il faut cliquer sur “Templates”, là vous trouverez le modèle “Django App Template”.
Vous pouvez alors cliquer dessus, lui choisir un joli nom, ou conserver celui suggéré.
Vous arriverez ensuite sur un joli éditeur de code.
Appuyez sur “Run”.
Vous devriez voir l’application de démonstration de Django se lancer dans le volet de droite. https://drive.google.com/uc?id=1RxfnYAzA-XP7L16NCpAxWnjRsZJlcxoY
Replit.com c’est en gros une image docker, le contenu dynamique est donc clairement non stocké, il sera au mieux effacé lorsque votre image se mettra en sommeil.
Vous avez au dessus de l’aperçu l’URL de votre site, tant que celui-ci est lancé, n’importe qui peut le lancer depuis la page de votre profil en appuyant sur play, pour peu que votre projet soit publique.
Vous pouvez aussi le synchroniser avec un dépôt github, ce qui est indéniablement très pratique.
La première chose à faire est donc de remplacer la base de données sqlite par une base de données postgres hébergée ailleurs, c’est là qu’entre en jeux elephantsql, ils offrent des bases de données gratuites, elles sont limitées à 100_000 enregistrements environ. Mais ce n’est pas bloquant pour une démonstration de projet, si vous désirez quelque chose d’un peu plus conséquent je vous donne toutes les clés à la fin.
Une fois votre compte créé sur elephantsql, prenez une base de données tortue pour votre projet. Notez bien le nom d’utilisateur, celui de la base de donnée (c’est le même si je me souviens bien) ainsi que le mot de passe et l’adresse du serveur.
Avant toute chose, ajoutez psycopg2 aux packages de votre application, depuis votre repl, à gauche, cliquez sur packages et ajoutez psycopg2. Il s’installera automatiquement.
Ce n’est pas nécessaire, on peut tout coder en dur, mais j’aime bien conserver une configuration dynamique, il faut maintenant ajouter quelques variables d’environnement à votre replit ce qui est facile, depuis votre projet, cliquez sur le cadenas à gauche, puis ajoutez les différentes variables nécessaires:
ENV = PRODUCTION
DATABASE_SERVER = <serveur de la base de données>
DATABASE_NAME = <nom de votre base de données>
DATABASE_USER = <nom d’utilisateur de la base de données>
DATABASE_PASSWORD = <mot de passe pour accéder à votre base de données>
DJANGO_SECRET = <votre django secret>
Il vous faudra aussi ajouter ceci à la fin de votre fichier settings.py de façon à ce que Django soit configuré convenablement.
Ensuite, depuis l’onglet shell, lancez la migration:
python manage.py migrate
Si tout est convenablement configuré, vous utilisez maintenant la base de données postgresql en ligne.
Ultérieurement, pour continuer le développement, il vous suffit de changer la valeur de la variable d’environnement “ENV” et de la passer à DEV par exemple.
Maintenant on a une jolie application django qui fonctionne bien, avec sa base de donnée toute jolie.
Que faire du contenu statique?
Je conseil d’utiliser simplement Google Drive, et oui, je n’avais pas noté Google Drive dans les prérequis pour rien, il va nous être d’une grande utilité immédiate.
ou 14BnqXW_m71UGlTRxmj_zdwqytteYlJCT est l’ID de votre document permet par exemple d’utiliser une image de votre drive dans un template.
Utilisez Heroku, une vrai base de donnée et un stockage amazon s3, c’est une autre histoire qui prends fin ici, si on me le demande beaucoup tout plein et si un jour j’ai le temps, pourquoi ne pas vous expliquer tout ça, sinon, allez explorer l’internet par vous même, vous pouvez même tout déployer depuis un petit VPS l’histoire de ne pas trop avoir de frais pour une application commerciale au début de sa vie.
Avec 6€ par mois, on peut commencer avec un joli VPS chez OVH et le surcharger à mort avec notre premier site, si le trafic augmente il faudra alors envisager une migration vers d’autres cieux, pour les connaissances, je dirais qu’il vous faut savoir déployer un service systemd, configurer nginx et postgresql, du reste, je déconseil l’utilisation de gunicorn derrière nginx, ce truc ne fait que ralentir le trafic pour rien.
J’espère que ce tutos express vous permettra de déployer un peu tout et n’importe quoi assez facilement avec python.
Maintenant que vous avez autant de machine en ligne que nécessaires, une jolie base de données et que vous savez héberger du contenu à moindre coût, j’attends vos créations avec impatience.
Docker est l'implémentation de référence pour gérer des conteneurs : le moyen simple et systématique de créer un service, sur son poste de travail et/ou dans de l'intégration continue, de le livrer, pour finalement le lancer dans un contexte bordé. Une application est rarement constituée d'un service unique, mais d'un ensemble de services, avec souvent une base de données dans la boucle. Docker-compose Au départ nommé Fig, le projet est rapidement absorbé par Docker pour devenir docker-compose. Docker-Compose permet de décrire un ensemble de services, pouvant être dépendants les uns des autres. En suivant le paradigme 12 factors, l'utilisateur pousse des variables d'environnement pour avoir des paramètres différents en fonction de la cible de déploiement (développement local, préprod, prod…). Le projet est écrit en python, et clairement, il fait le job. Kubernetes Très vite, un an après Docker, apparait Kubernetes, qui mise tout sur l'environnement de production, constitué de plusieurs machines, avec une automatisation de la répartition des conteneurs en cas d'incidents matériels, ou d'ajouts de nouveaux noeuds au cluster. Kubernetes, k8s pour les intimes, cible des projets de taille conséquente, et permet plein de réglages liés à l'exploitation, bien au-delà de la définition du service par le développeur. K8s utilise une abstraction réseau (enfin, une interface, c'est à vous de choisir l'implémentation), qui est souvent le point douloureux de k8s, mais ne vous inquiétez pas, les offres des gros du Cloud utilisent leur propre abstraction réseau, ce qui de fait, met le ticket d'entrée trop haut pour pas mal d'hébergeurs. AWS, Google Cloud et Azure ont rapidement proposé des offres infogérées de k8s. Vous avez un VLAN, un load-balancer qui pointera vers votre Ingress, des disques distants, un stockage objet à la S3, un rangement des logs. Vous pouvez ajouter des VMs dans votre cluster, et k8s va ventiler les conteneurs sur les VMs. Profiter d'une offre managée est clairement le moyen le plus serein de faire du k8s, mais clairement pas celui de déployer du conteneur. Il existe une passerelle, Kompose qui permet de convertir un docker-compose.yml pour l'utiliser dans Kubernetes. Docker Swarm Docker a travaillé sur Swarm, qui permet de déployer son docker-compose sur un cluster, mais sans arriver à sortir de l'ombre de k8s. Nomad Hashicorp propose une approche inverse, avec Nomad, un outil de gestion de cluster qui peut, entre autres, utiliser des conteneurs. Principal différence avec k8s, il n'y a pas d'abstraction réseau, c'est à vous de gérer ça. Il n'y pas non plus de YAML, mais bon, il y a du HCL le concurrent maison. Comme Nomad est poli, il expose toutes les options pour lancer un conteneur, tout comme Docker-Compose; il est donc aisé de mouliner un docker-compose.yml vers Nomad, mais si il n'existe pas d'outils tout prêt: vous allez devoir prendre des décisions liées aux choix techniques que vous avez pris pour votre Cluster. Retour à Compose
(Photo Katieleeosborne, CC BY SA, trouvée ici) OK, il y a plein de façons de déployer ses conteneurs, mais il y a clairement un moyen évident de définir la topologie de son application : Compose. Le fichier docker-compose.yml est devenu le standard de fait pour décrire l'architecture de son application, utilisable par l'équipe de développement, et comme contrat pour l'hébergement. AWS et Azure ont découvert qu'il y avait aussi un marché pour le conteneur raisonnable, et que le plus simple était d'exposer directement du docker-compose.yml (et une registry privée pour les images). C'est ces offres qui ont poussé le développement de compose v2, dans le README, à la section remerciements, il y a les noms de gens du Cloud qui ont bossé dessus. L'écosystème de Docker (mais aussi celui de k8s, Nomad…) est intimement lié à Golang, pourtant, pour des raisons historique, Docker-Compose v1 est écrit en python. Python s'est toujours intégré avec élégance dans l'environnement Docker, le client python docker est beau, mais… ce serait quand même plus simple d'avoir un compose en golang, directement intégré au cli docker. Il y a eut un libcompose jamais abouti, toujours stressé de gérer les avancées du Docker-Compose v1. Le plus simple est d'avoir un Compose en golang, qui remplace la V1 en Python et qui prends le lead. Normaliser Docker Docker est parti très vite, très fort, avec des décisions clivantes. Une fois la concurrence éradiquée (RKT, LXC …), les partenaires de l'écosystème (k8s essentiellement), ont collé la pression pour normaliser tout ça. Docker a créé son pendant libre Moby qui contient les couches basses avec plein de kits, et surtout containerd, la couche basse et consensuelle sur laquelle s'appuie Docker et sa série de choix opiniated. Kubernetes a récemment décidé de remplacer Docker par la couche bas niveau Containerd. Rien de révolutionnaire, on continue à pousser des images docker dans une Registry pour déployer dans son cluster, mais c'est plus simple. K8s gère ses conteneurs avec des RPC adéquat (grpc et ttrpc), plutôt que du REST. Ensuite, pas mal de spécifications (avec des implémentations de référence) :
Création de l'OCI, Open Container Initiative, aka opencontainers image-spec, les images, un gros chroot avec un manifest, rien de bien compliqué runtime-spec, un runtime, le kernel Linux avec ses Namespaces, Cgroup et autres outils. Les specs évoquent aussi Solaris. runtime-spec précise comment lancer un conteneur, avec runc comme implémentation de référence, mais il a des alternatives, comme crun, gVisor, youki. Oui, pour le dernier, Gotainer n'assume pas la référence. distribution-spec qui définit la livraison et le stockage des images (la Registry, quoi). image-spec définit le format des images avec artifacts, l'implémentation de référence. compose-spec normalise la définition d'une application composée de services, ce qui a permis l'émergence de podman-compose ou de nerdctl compose (le cli qui utilise directement Containerd).
RedHat a profité de tout ça pour sortir son Podman qui se focalise du conteneur rootless, Buildah qui permet de construire des images sans fichier Dockerfile, et OpenShift une surcouche à K8s. Nerdctl propose aussi du rootless (tout comme Docker maintenant), mais aussi du stream d'images, leur partage en P2P, leur chiffrement… Tout ces outils ne sont pas forcément super convaincants, mais c'est toujours bien d'avoir plusieurs implémentations d'une norme, cela permet de valider la spécification, et d'essayer des choses qui profiteront à tout le monde. Desktop Docker a bien stabilisé son produit sur le poste de développeurs, avec Docker Desktop, un gros effort sur Mac et Windows, pour gérer la virtualisation native, mais surtout proposer du réseau (vpnkit) et exposer des fichiers (avec grpc-FUSE, et plus tard virtio-FS). Dans la machine virtualisée, un docker daemon docker tourne, et un docker client natif peut lui causer depuis l'hôte. Toute cette gestion de virtualisation n'est pas utile sur un poste Linux, qui va tout simplement utiliser le daemon et client Docker, avec peut-être des pinaillages comme btrfs pour les layers. Docker-Desktop est maintant disponible en béta pour Linux. Docker-Desktop intègre un ensemble de services autour de Docker, ainsi qu'une interface minimaliste. AMHA, la réelle utilité de Docker-Desktop est de permettre un cycle rapide de mises à jour, et de proposer des fonctionnalités en béta, pour avoir rapidement des retours utilisateurs. Un Docker-Desktop sous Linux est prévu à courte échéance, sans toute la stack de virtualisation, mais avec une petite UI... curieux de voir ce que ça apportera. Compose 2 Dans les nouveautés importantes fournies par Docker-Desktop, il y a la mise en place de Compose v2, aka docker compose (et non plus docker-compose).
Compose arrête d'embêter les gens en exigeant un numéro de version. Le format est maintenant stable et spécifié. On peut faire les fous à distance avec des offres clouds. docker compose convert normalise le fichier, en utilisant les formats longs et explicites. C'est indispensable pour le confier à une validation ou conversion. Les profiles permettent de définir des services outils qui ne seront pas déployés en production.
Sous le capot Docker-compose v1 fait le job, mais il n'a jamais proposé une API stable, permettant de coder des applications qui lancent des grappes de services. Le plus sage est de passer par un subprocess.Popen qui va lancer le cli, en se branchant sur STDIN/STDOUT/STDERR. Pragmatique, mais rustre. Docker-compose v2, lui, part de l'autre pied : API first. Il y a un projet dédié au modèle objet qui implémente les spécifications : compose-spec/compose-go. Le typage fort de Golang adore cette spécification de bout en bout, tout le bazar JSON/YAML est définit dans des structs ou des interfaces, laissant très peu de place aux interprétations. Pour créer un compose, compose.NewComposeService part d'un client Docker avec sa configuration, pour créer un api.Service. Vous avez là un projet compose théorique, impalpable. Vous pouvez naviguer dans le graphe acyclique des services avec un compose.NewGraph. Pour rattacher votre compose au monde réel, vous allez ajouter à votre api.Service un types.ConfigDetails, soit un dossier de travail, des variables d'environnement, et une suite de fichiers docker-compose.yml. On est sur un mapping un pour un avec le cli : vous êtes dans un dossier avec un .env et un docker-compose.yml. On load ensuite son types.ConfigDetails dans un loader.Load où l'on peut spécifier le nom du projet, d'activer l'interpolation et d'autres options, pour obtenir un types.Project Il est possible de bidouiller le projet, lire les labels, changer les chemins des volumes, débrancher des services, ajouter des contraintes, tout ce que permet Docker en fait. Le types.Project permet d'utiliser des api.Service qui est l'équivalent des actions disponibles à docker compose, comme run, up, start… avec un io.Writer pour STDOUT et un autre pour STDERR. Pour modifier des actions "juste à temps", il est possible d'utiliser un api.ServiceProxy plutôt que directement un api.Service. L'API permet d'utiliser et de maitriser de bout en bout un projet Compose. Microdensity Que peut-on faire avec une si belle API? Microdensity est un simple service REST permettant de mettre à disposition des outils d'analyse fonctionnelle de sites webs, et de fournir des badges. Un docker-compose.yml contient l'outil d'analyse (pa11y, sitespeed, lighthouse…). Un bout de javascript va valider et convertir les arguments venant du body HTTP POST en ENV, ou en fichiers de conf. Les arguments, env et conf, sont confiés au docker compose run, les résultats seront écrits dans un volume, qui sera exposé en HTTP, pour qu'ils puissent être lus. Ces outils peuvent utiliser un Chrome en boîte fournit par browserless, avec du CPU dédié, pour avoir des mesures reproductibles. µdensity ne se contente pas d'exposer en REST des Docker-compose, mais propose une intégration simple à Gitlab, profitant du jeton JWT mis à disposition dans la CI. Ceci nous permet d'avoir des analyses de qualité, asynchrones et donc non bloquantes pour se soucier de la qualité sur un temps plus long que le rythme de développement avec ses tests unitaires et fonctionnels. Compose a clairement sa place dans la chaine de développement d'un site/service web, du poste de dev à la production.
Ici les nouveaux, nouvelles, et les autres peuvent se présenter (ce qu’ils font, pourquoi ils sont là, en quoi ils peuvent aider, en quoi ils ont besoin d’aide, ou juste dire bonjour !)
Afin de devenir le leader européen des solutions SaaS génératrices de revenus pour les hôtels et restaurants, MyBeezBox recherche un Lead développeur Python Full Stack.
En quelques chiffres, MyBeezBox, c’est :
1 200 clients dans 6 pays avec une volonté d’atteindre les 5 000 d’ici 5 ans
Une équipe passionnée de 15 personnes
6 solutions (et plus à venir) créées grâce à une écoute active de nos clients
Plus de 200 000 transactions par an
Le monde de demain ne sera pas celui d’avant. La gastronomie et l’hôtellerie doivent se réinventer,
notamment au travers du digital. MyBeezBox a une vision humaine de la technologie avec un fort
accompagnement de ses clients sur le long terme. MyBeezBox crée des solutions avec ses clients et les soutient dans le développement de leurs nouvelles activités.
Ce que nos clients aiment chez MyBeezBox :
Ils sont au top !! Pédagogues, compétents, disponibles et bienveillants pour nous accompagner au quotidien
— L’équipe de Quatrième Mur
Valeurs
Esprit d’équipe
Chez MyBeezBox, il y a toujours quelqu’un pour vous aider ou répondre à vos questions. Vous
bénéficiez d’un parrainage dès votre arrivée et d’un programme de formation avec des membres de chaque équipe.
Bienveillance
Nous prenons soin de soi et des autres, nous nous entraidons et accueillons toujours volontiers les idées des autres sans jugement ni critique.
Satisfaction client
Nous nous levons chaque matin pour nos clients et nous nous engageons à les aider à développer
leurs revenus pour qu’ils puissent continuer à grandir. Jetez un oeil sur leurs témoignages sur notre site web. Ha oui, nous sommes aussi très réactifs !
Respect
Nous valorisons l’apport de chacun au sein de MyBeezBox et nous le disons ! Nous cherchons à être le plus honnête et intègre possible tout en respectant les autres.
Sérieux
Nous nous sentons responsables, ensemble, de la réussite de nos clients. Nous les écoutons et
cherchons en permanence à innover avec et pour eux. Nous aimons le fait qu’ils puissent compter sur nous, à tout moment.
Mission
Dans une perspective de scale-up et d’industrialisation, nous souhaitons faire grandir l’équipe technique en accueillant un(e) Lead Developer.
Sous la responsabilité directe du CEO et en relation avec l’ensemble de l’équipe technique et produit, vous formerez un binôme complémentaire avec notre lead dev historique, pour encadrer, à terme, une équipe de 6 développeurs.
Résumé des missions :
● Développement web complet (full stack) d’une plate-forme Saas multi-produits
● E-commerce, monétique, internationalisation
● Intégration de données, passerelles d’import / export / synchronisation via APIs
● Gestion et formation d’une équipe de développeurs
● Participation à la stratégie technique de l’entreprise
DESCRIPTIF DU POSTE
Vous étudiez la stratégie technique actuelle, la challengez et l’améliorez : infrastructure,
processus, organisation, release management, gestion des données, sécurité…
Vous participez à la scalabilité technique et au lancement d’au moins un produit par an dans
un fort contexte international.
Vous travaillez en agilité en respectant les process.
Vous rejoignez une équipe internationale composée d’un lead dev et de 3 développeurs.
Vous développez du code de qualité et rédigez de la documentation.
Vous êtes force de proposition tout en étant opérationnel.
Vous effectuez une veille technologique et concurrentielle régulière.
Vous collaborez quotidiennement avec les autres services de MyBeezBox.
Vous aidez l’équipe à résoudre les problèmes rencontrés.
Vous faites monter en compétence votre équipe.
Vous participez aux futurs recrutements (3 recrutements prévus en 2022).
Vous disposez d’au moins 8 ans d’expérience en développement, vous maîtrisez parfaitement Python et vous avez un très bon niveau d’anglais écrit et oral.
PROFIL RECHERCHÉ
● Au moins 8 ans d’expériences en développement.
● Expérience significative de développement en Python & Django
● Connaissances en VueJS (ou un autre framework front-end)
● Connaissance d’ELM (https://elm-lang.org/) serait un très gros plus
● Excellent niveau d’anglais écrit et oral
● Aisance managériale avec une première expérience significative
Vous trouvez que les tests unitaires vous aident à écrire du meilleur code.
Qualités requises pour ce poste : organisé, rigoureux, ouvert d’esprit, aisance relationnelle, sens de l’écoute, force de proposition, capacité d’adaptation.
Vous savez concilier qualité et rapidité.
AVANTAGES
PC ou Mac + Tickets resto + 50% Mutuelle
Travail en 100% Remote possible mais pas obligatoire (Le bureau est localisée à Marcel Sembat à Boulogne-Billancourt)
DÉROULÉ DES ENTRETIENS
Entretien 1 avec la Product Owner : découverte mutuelle, méthodologie, partage de valeurs,
correspondance humaine
Case Study
Entretien 2 avec le CTO (en anglais) : debrief du case study, vérification des compétences clés,
approfondissement
Bonjour
Je ne sais pas si ce message est au bon endroit mais comme je suis un nouveau venu dans l’association je maitrise pas encore les codes du forum.
Comme je n’ai pas pu suivre la réunion de présentation mercredi j’aimerais poser directement mes question sur le forum.
Comment peut-on contribuer aux activités de l’asso lorsqu’on est débutant en programmation ?
Quels sont les événements en ligne ou en physique qui sont organisés par l’association ?
Merci pour vos réponses
Je me retrouve souvent à parler avec des gens qui, après avoir appris les bases de Python, ne savent pas quoi faire pour s’améliorer. À défaut d’un projet personnel qui leur tiendrait à cœur, je leur propose de contribuer aux logiciels libres / open source. Seulement voilà, ma connaissance de ceux-ci est partiel, et je me retrouve à conseiller les mêmes projets qui ne leur conviennent pas forcément.
Un tel projet pour un débutant, c’est l’occasion d’apprendre du code de meilleure qualité, d’apprendre à faire parti d’une équipe, apprendre les outils de gestion (versionning, intégration continue, etc.) et surtout une fierté d’avoir du code qui est vraiment utile/utilisé.
C’est pourquoi je pense qu’il serait intéressant de créer et maintenir une liste de projet libre/open-source en Python et Francophone.
Je pense que l’AFPy, au travers de ses membres et de son rayonnement est capable de créer une tel liste et de la partager.
Le Laboratoire Interdisciplinaire des Sciences du Numérique recrute un ingénieur de recherche en ingénierie logicielle. Nous recherchons un développeur backend et frontend mobile pour une plateforme de compétitions d’algorithmes d’apprentissage automatique appliqués à la recommandation d’articles d’actualité en ligne. La plateforme Renewal permet à des compétiteurs de comparer l’efficacité en temps réel de leurs algorithmes d’apprentissage en établissant un classement entre différents systèmes de recommandations connectés en ligne. Son originalité est le traitement de jeux de données dynamiques : des articles d’actualité du web. C’est l’intérêt scientifique de cet outil unique en son genre. Les articles d’actualité sont moissonnés à la volée sur le web et proposés via une application mobile à des utilisateurs. L’ingénieur recruté aura en charge l’ajout de nouvelles fonctionnalités, l’exploitation des infrastructures de test et de production de la plateforme et l’animation de l’événementiel lié à la plateforme.
Activités
Dans ce cadre, les activités principales de l’ingénieur seront :
prendre en main l’architecture existante et doubler l’infrastructure actuelle d’une deuxième infrastructure de production afin d’isoler les futurs développements;
compléter le code existant par des procédures de tests facilitant l’interfaçage des systèmes de recommandation avec le backend ;
proposer des solutions pour rendre le fonctionnement de la plateforme plus robuste;
développer des nouvelles fonctionnalités ;
maintenir à jour la documentation nécessaire au déploiement, à l’utilisation, à la maintenance et aux futurs développements des paquets livrés ;
assurer le support aux utilisateurs dans le cadre des évènements organisés autour de la plateforme ;
diffuser son savoir-faire et ses connaissances au niveau de son équipe et des collaborateurs.
Compétences souhaitées
Connaissance et maîtırise des techniques d’architectures web à microservices docker (asyncio python, MongoDB, RabbitMQ, crawlers…), des API, des web sockets;
Connaissance et maîtrise du langage et des outils de programmation Python, en particulier dans le domaine du Machine Learning;
Pratique des environnements de développement logiciels (forges gitlab, intégration continue);
Expérience souhaitée dans le domaine de la programmation d’applications mobiles pour android et/ou pour IOS (expo, javascript, React);
Expérience appréciée dans l’un des domaines suivants : techniques d’analyse du langage naturel et de recommandations (popularité, mots clef, analyse de sentiments…), connaissances d’interfaçage avec les réseaux sociaux (ex : Google Firebase) ;
Bonne maîtrise de l’anglais scientifique ;
Travail en équipe.
Contexte
Le LISN est une unité de recherche rattachée à l’Institut des Sciences de l’Information et leurs Interactions du CNRS, à la Graduate School Computer Science de l’Université Paris-Saclay. Le laboratoire intègre aussi des équipes de recherche Inria et CentraleSupelec, qui sont les deux autres partenaires institutionnels du laboratoire. Les forces de recherche du LISN couvrent d’une part des thématiques coeur des sciences du numérique et des sciences de l’ingénieur, et d’autre part des thématiques interdisciplinaires par nature : intelligence artificielle et science des données, interaction humain- machine, traitement automatique des langues et de la parole, et bio-informatique. Le LISN accueille plus de 380 personnes dans 4 départements. Le recrutement concerne le département de Science des Données.
Le projet Renewal est coordonné par le Service d’Accompagnement et Soutien aux Activités de Recherche et Développement du LISN dont le rôle est de soutenir la production logicielle du laboratoire en vue de la capitalisation des bonnes pratiques de développement. La plateforme est opérationnelle dans une version prototype. Elle est très bien documentée. Nous recherchons un ingénieur polyvalent, doté d’une solide formation en IA, motivé pour relever des défis et disposant d’une bonne autonomie. Il aura l’opportunité d’organiser des compétitions lors d’ateliers et d’accompagner pédagogiquement les compétiteurs. Le candidat, bénéficiant déjà au moins d’une première expérience, tirera profit au terme des 12 mois de contrat d’une connaissance valorisante dans les domaines précités: des formations pourront lui être proposées, il aura aussi des contacts au sein des équipes scientifiques dans lesquelles le projet est hébergé : séminaires, échanges et discussions, partages de compétences.
Conditions
Salaire : 30 - 36 k€ brut annuel
Prise de poste : 01/05/2022
Expérience : Minimum 2 ans
Métier : Ingénieur en études et développement informatiques
Chez Bearstech on retombe régulièrement sur un client avec un schéma de stockage utilisant des chemins particulièrement profonds, par ex. : /var/ww/app/release/shared/html/public/media/images/cache/crop/rc/Ds/1L/PbzH/uploads/media/image/20201207122604000000_pre_322.jpg.webp Quel est le problème ? Si votre filesystem possède plusieurs millions de fichiers, au minimum d'assez fortes chances de performances dégradées, quel que soit votre filesystem. Au pire des performances fortement dégradées si ce chemin est sur un stockage réseau (GFS, Gluster, NFS, dans une moindre mesure pour du stockage block comme Ceph). Si l'intention d'un tel chemin vient uniquement d'un désir maniaque de rangement hiérarchique, alors tâchez de contrôler vos pulsions. Vous savez bien qu'il n'existe aucune hiérarchie définitive qui permet de représenter une taxonomie, ça finit toujours par "hum, mais /images je le met dans /media ou /cache ? Ou alors dans /cache/media/ ? Ou /media/cache ?". Et ça ne résoud aucun problème technique. Préférez des hiérarchies peu profondes, mettez tous vos objets au même niveau dans un seul répertoire de premier niveau, et c'est réglé (c'est d'ailleurs un des mantras de REST). Par ailleurs petit rappel sur la constitution d'un filesystem : un répertoire est l'équivalent d'un index. Il est conçu de telle sorte que la question à "quelle est l'adresse sur disque de foo/bar.txt ?" permette de demander au répertoire foo/ de fournir la réponse de façon efficiente, donc normalement en o(log(n)) où n est le nombre d'éléments répertoriés par le ... répertoire. Révisez vos classiques de base de données, on ne peut pas faire mieux. Mais alors tout est au mieux si ces répertoires sont des indexes efficents ? Sauf que pour résoudre un chemin, s'il faut consulter 15 indexes, vous mettez en échec le principe même d'utiliser un index. C'est comme si comme en SQL vous décidiez de faire une jointure sur 15 tables pour trouver un objet élémentaire : ça ne vous viendrait jamais à l'idée, et vous savez que ce serait un échec algorithmique. Stockage local Sur un SSD/NVMe local ça peut presque ne pas se sentir : une opération ponctuelle (mettons démarrer votre superbe framework qui charge 5000 classes, ce qui est hélas en dessous de la vraie vie) qui mettait 0,1 s va soudainement en prendre 1,5 s. Ça peut aller, mais sur des opérations à forte fréquence, ça peut être douloureux. Si vous êtes sur disque rotatif (ça existe encore), ce sera bien pire. Le contenu des répertoires est stocké à des endroits arbitraires, et la tête de lecture du disque va s'affoler : non seulement votre application sera beaucoup plus lente, mais toutes vos IOs sur ce même serveur seront plus lentes. Une grande quantité de répertoires sur un filesystem peut souvent faire écrouler les temps de réponses de vos IOs. Dans le meilleur des cas, votre disque SATA qui faisait du 150 MB/s en accès séquentiel, va chuter à quelques kB/s car il ne faut pas lui demander plus de 50 à 100 IOPS en accès aléatoire. Mais en théorie ça devrait être compensé par un cache me dites-vous ? Il y a effectivement un cache très stratégique appelé dentry cache chez Linux qui sert précisément à éviter de trop consulter sur le disque le contenu de moults répertoires éparpillés, mais il a une taille limite. Par ailleurs c'est un cache, et Linux va donc le réduire en priorité si les applications demandent de la mémoire avec malloc(). Ces mauvaises conditions croisées arrivent hélas souvent. Stockage réseau Vous avez le même problème qu'avec un disque SATA, mais vous remplacez le délai minimum de positionnement de tête de lecture (environ 15 ms) par le RTT du réseau de stockage (0,1 ms max si tout va bien). La résolution des chemins ne peut être que séquentielle : la consultation de bar/ dans foo/bar/ ne peut se faire qu'une fois que foo/ a été consulté pour obtenir l'adresse de bar/ et également vérifier que vous avez le droit de le traverser. Donc les RTTs se multiplient proportionnellement à la profondeur de votre chemin, résoudre un chemin complet devient plus long. Et bonus, les IOPS sont également multipliées par autant, chargeant d'autant plus votre backend de stockage. Au mieux vos IOs sont légèrement plus lentes, au pire vous devenez très dépendant de la météo de votre réseau de stockage (que par ailleurs vous surchargez). Et que vous soyez on premises ou sur un cloud, êtes-vous sûr de maîtriser la météo de votre réseau ? Ce dernier est quasiment toujours mutualisé, alors que pour un stockage local vous avez en général une forte garantie de performances minimales (beaucoup moins de contention, voire aucune quand votre opérateur met directement un NVME physique en passthru dans votre VM). Vieilles habitudes tenaces Si on remonte fin des années 90, la plupart des filesystems étaient petits, et implémentaient la structure de leur répertoire comme de simples listes. Comme pour SQL, vous savez peut être que pour des petites structures (cela dépend de votre CPU, cache L1/L2, etc) il est plus efficient de scanner une liste que d'invoquer une structure de type B-Tree. C'était simple et efficient pour le contexte de cette époque. Mais les limites ont été vites ressenties par des applications stockant beaucoup plus de fichiers que ce que prévoyaient les concepteurs des filesystems, et les développeurs d'application ont rapidement contourné le problème en implémentant un index à base de ... répertoires imbriqués ! Si chaque répertoire reste petit et est donc considéré o(1), alors consulter une arborescence de répertoires ramène à une complexité de o(log(n)) (c'est le principe du "Diviser pour régner"). C'était malin et assez efficace. Mais les développeurs système n'ont pas tardé à améliorer leurs filesystem, on voit par exemple que Linux a obtenu des répertoires indexés dans ext3 en 2002. A partir de là stocker jusqu'à environ 100,000 fichiers par répertoire ne pose pas de problème - mais pas non plus des millions car la conception de l'index reste assez loin de la sophistiquation moteur SQL ! Cependant le mythe tenace du folder hashing s'est installé précisément à cette époque, et une foule d'applications (caches comme Squid, moteurs de template comme Smarty, etc.) se sont mises à être contre-productives. Il est temps que l'on sorte de cette ornière. Aimez votre filesystem Certains vont alors rebondir sur ces problèmes : "mais justement S3 a résolu ce problème, il n'y a plus de hiérarchie mais seulement une clé dans un unique index logique !". Certes, au niveau de la conception c'est aussi scalable qu'une base de données peut l'être, et les noSQL clé/valeur sont très scalables. Mais vous avez peut être remarqué (ou pas si vous n'ouvrez jamais le capot), la machinerie derrière un stockage S3 est autrement plus complexe qu'un filesystem. Un filesystem bien utilisé, c'est plusieurs ordres de grandeurs performants que n'importe quel stockage S3. Il y a des problèmes d'échelle, de réplication ou de distribution que ça ne peut pas régler, mais tant que vous n'en avez pas besoin, utilisez votre filesystem : utilisez le bien, il vous le rendra bien. Notes pratiques Pour un administrateur, des répertoires avec beaucoup de fichiers peuvent être lents à manipuler. Un gros répertoire peut rester efficient en tant qu'index (donc pour obtenir le descripteur d'un fichier dont vous connaissez le nom), mais moins pour lister son contenu. Et ce n'est en général pas la faute du filesystem ni de son index. Truc 1 : oubliez les fonctions de tri de ls puisque par design vous n'aurez la réponse qu'une fois tous les fichiers énumérés. Avec gnu ls, c'est ce que l'option -f fait. Truc 2 : ne dépendez pas des méta-données des fichiers listés, car si obtenir la liste peut être très rapide, ensuite demander les méta-données de chacun de ces fichiers avec lstat() va être très coûteux. Là encore l'option -f résoud ce problème, mais évitez aussi les -l et consorts. Truc 3 : préférez le format -1 avec un fichier par ligne, qui simplifie plein de traitements subséquents que vous pourriez faire à ce long listing. Nous avons déjà eu des cas ou lister le contenu de gros répertoires sous NFS ou GlusterFS prenait plusieurs minutes, et nous avons pu le réduire à quelques secondes avec ces observations. Moralité : quand ls ne semble pas aboutir, remplacez-le par ls -f1.
Superbe opportunité de rejoindre une équipe technique au top (2 professeurs d’université, énormément de prix techniques international gagnés) et juste après l’obtention d’une superbe subvention de 2.5M€. Tu seras arrivé pile au bon moment !
On cherche aussi un Product Manager Senior, un CTO de scale up, un UX/UI.
A propos de nous :
Les grands projets (centrale énergie, immeubles, autoroutes, ponts) sont au coeur de l’amélioration du bien être de la société : transportation plus rapide, logements moins chers, énergie plus propre, etc. Or les grands projets sont plus connus dépassent régulièrement. En effet, les équipes projets sont noyées sous l’information échangée; aucun humain n’arrive à lire assez vite pour suivre les modifications et leurs impacts pour organiser efficacement leurs projets. Depuis presque 5 ans, LILI.AI travaille auprès de leaders en grands projets pour transformer la documentation projet hétérogène en un knowledge graph et en extraire des informations permettant de détecter le retard dans les grands projets.
Lauréat de plusieurs prix deeptech (cogX AI 2018, dernière équipe française du AI X-prize 2019, Deeptech BPI 2020, EIC Accelerator Deeptech 2021)
Une super équipe avec notamment un prof en computer science et un en NLP/ML dans l’équipe; et d’autres talents hypra passionnés et talentueux
De supers problèmes techniques et produits nécessitant de mettre en oeuvre des solutions state-of-art: création de knowledge graph automatique, extraction automatique d’information avec classificateur
A propos de vous :
Passionné par l’informatique: toujours en veille sur les développement récents
Capable tout aussi bien de concevoir que de développer des solutions optimisées à un problème précis
Capable de communiquer et d’expliquer efficacement votre expertise avec des non-techniques
Capable de s’organiser pour atteindre des deadlines
Le reste est dans l’offre sur le site. Une très belle journée ensoleillée à vous et au plaisir,
screenshots.debian.net est un service qui permet d’afficher des captures d’écran de logiciels. C’est assez pratique pour se faire une idée d’une interface par exemple. Une capture d’écran montrait déjà l’interpréteur Brainfuck beef affichant un classique Hello Word!. Mais on peut aussi personnaliser en affichant un Hello Debian! :
Brainfuck
Brainfuck est un langage dont l’intérêt principal est d’être difficilement compréhensible par un humain. Pas la peine de s’étendre sur ses spécificités, wikipedia le fait très bien. Il ressemble à une machine de Turing: le programme déplace un curseur dans un tableau et modifie les valeurs contenues dans les cellules du tableau.
Voici une version commentée du programme utilisé (le début est quasi-identique au hello world fourni sur la page wikipedia puisqu’on veut écrire la même chose) :
++++++++++ affecte 10 à la case 0
[ boucle initialisant des valeurs au tableau
> avance à la case 1
+++++++ affecte 7 à la case 1
> avance à la case 2
++++++++++ affecte 10 à la case 2
> avance à la case 3
+++ affecte 3 à la case 3
> avance à la case 4
+ affecte 1 à la case 4
> avance à la case 5
+++++++++++ affecte 11 à la case 5
<<<<< retourne à la case 0
- enlève 1 à la case 0
] jusqu'à ce que la case 0 soit = à 0
La boucle initialise le tableau en 10 itérations et son état est alors :
Case
0
1
2
3
4
5
Valeur
0
70
100
30
10
110
Suite du programme :
>++ ajoute 2 à la case 1 (70 plus 2 = 72)
. imprime le caractère 'H' (72)
>+ ajoute 1 à la case 2 (100 plus 1 = 101)
. imprime le caractère 'e' (101)
+++++++ ajoute 7 à la case 2 (101 plus 7 = 108)
. imprime le caractère 'l' (108)
. imprime le caractère 'l' (108)
+++ ajoute 3 à la case 2 (108 plus 3 = 111)
. imprime le caractère 'o' (111)
>++ ajoute 2 à la case 3 (30 plus 2 = 32)
. imprime le caractère ' '(espace) (32)
<<< revient à la case 0
++ ajoute 2 à la case 0 (0 plus 2 = 2)
[ une boucle
> avance à la case 1
-- enlève 4 à la case 1 (72 moins 4 = 68)
> avance à la case 2
----- enlève 10 à la case 2 (111 moins 10 = 101)
<< retourne à la case 0
- enlève 1 à la case 0
] jusqu'à ce que la case 0 soit = à 0
> va case 1
. affiche 'D'
> va case 2
. affiche 'e'
--- enlève 3 à la case 2 (101 moins 3 = 98)
. affiche 'b'
>>> va case 5
----- enlève 5 à la case 5
. affiche 'i'
<<< va case 2
- enlève 1 à la case 2
. affiche 'a'
>>> va case 5
+++++ ajoute 5 à la case 5
. affiche 'n'
<< va à la case 3
+ ajoute 1 à la case 3
. affiche un point d'exclamation
> va à la case 4
. imprime le caractère 'nouvelle ligne' (10)
screenshots.debian.net
Une capture de l’exécution du programme est disponible pour les interpréteurs beef et hsbrainfuck sur screenshot.debian.net.
Les images disponibles sur screenshots.debian.net sont aussi réutilisées par le service packages.debian.org (par exemple packages.debian.org) et par certains gestionnaires de paquets.
Si vous avez envie d’ajouter des captures d’écran à des paquets qui n’en auraient pas (les plus courants sont déjà faits), sachez que l’affichage n’est pas direct car il y a une validation manuelle des images envoyées. Le délai reste limité à quelques jours (voire à la journée).
J’ai installé Spyder et ensuite le notebook par
conda install spyder-notebook -c spyder-ide
puis relancé Spyder… plusieurs fois
Je ne vois toujours pas le Notebook dans le menu.
Quelqu’un a-t-il déjà rencontré ce problème ?
Merci d’avance,
L.
j’ai pondu un nouveau petit jouet (entre 2 revisions de coréen / 두 개정 사이) foxmask / shaarpy · GitLab tout droit adapté de Shaarli le très répandu projet (en PHP) permettant de partager ses bookmarks, ses notes etc. C’est grandement inspiré de feût delicious.
Donc pour ceux qui ne connaissaient pas Shaarli : Le principe est de sauvegarder des articles sur son instance shaarpy pour les partager ou les relire plus tard. Mais pas que, on peut aussi blogger, partager des snipset etc. Si on n’a pas la possibilité de sauvegarder les liens sur une instance online, on a toujours la possibilité, depuis son PC, après avoir enregistré quelques liens, de synchroniser le tout sur son smarpthone, puisque l’appli produit les articles dans des fichier markdown et qu’avec syncthing, c’est juste l’bonheur;)
Et pour finir cela est fait avec Django 4.x et python 3.10 .
Salut,
lors de mon premier test de traduction, j’ai suivi la procédure décrite
Vérifiez alors le rendu de la traduction « en vrai ». Lancez un serveur de documentation local :
make serve
La documentation est publiée l’adresse http://localhost:8000/library/sys.html (ou tout autre port indiqué par la sortie de la commande précédente). Vous pouvez recommencer les étapes de cette section autant de fois que nécessaire.
Or j’ai un serveur sur le port 127.0.0.1:8000 et j’ai du essayer du l’arrêter avant de poursuivre.
Après avoirs farfouillé dans les sources, je me suis rendu compte que la syntaxe pour changer de port est
make serve IP port
Ne serait-il donc pas judicieux de le préciser dans la doc?
Thierry
Petit constat en mettant à jour mon graph d’utilisations de Python :
Python 3.9 a bien dépassé Python 2.7 ! Le premier dépassement timide à eu lieu en septembre 2021, mais là 3.9 est clairement devant \o/
Pendant qu’on y est, à la même date Python 3.8 a dépassé Python 3.6.
Et 3.7, la version la plus adoptée de toute les 3 est à environ 40% depuis un an, en nombre de téléchargement par mois ça représente environ 5_000_000_000 de téléchargements par mois.
Bonjour,
afin de m’essayer à la traduction de la documentation, je souhaite réserver un fichier pour un dépôt non GitHub.
Je vois dans la documentation :
en créant un sujet sur le discuss de l’AFPy dans la section Traduction en indiquant sur quoi vous travaillez et l’URL de votre dépôt.
Bonjour,
Je suis débutant en Python et j’aimerais un conseil sur le problème suivant.
J’ai un tableau T de taille n de valeurs numériques et je voudrais connaître les indices des p (p<n) valeurs les plus faibles de ce tableau.
Merci d’avance,
lm
Bonsoir,
Avant que je ne finalise ma PR pour la traduction de la page Introduction informelle à Python de la doc python, je me demande si c’est pertinent de traduire certains commentaires dans le code. Si oui, comment faire puisque ces chaînes ne sont pas dans le fichier tutorial/introduction.po.
cf exemple ci dessous où traduire les commentaires me semble important.
# this is the first comment
spam = 1 # and this is the second comment
# ... and now a third!
text = "# This is not a comment because it's inside quotes."
Que penseriez-vous de remplacer le lien Actualités du site www.afpy.org par un lien vers une catégorie Discourse #Actualités ?
objectifs
avoir une section Actualités plus vivantes
dédupliquer le contenu entre le site et le forum, réutiliser le contenu présent sur le forum de l’association (5 articles sur le site qui sont à peu près tous repris sur le forum)
remarques
Comme le site actuel : Discourse permet de modérer à priori les sujets
inconvénients
Que faire des actualités existantes : importer ces actualités dans Discourse ou rendre accessible ce contenu sous un autre chemin (du type /historique) ?
La création d’un compte sur le forum deviendrait requise pour proposer une actualité (à moins qu’il soit possible d’interagir par mail avec le Discourse dans sa configuration actuelle).
je découvre aujourd’hui, via le Pycoders Weekly, le projet pipenv, qui est présenté ici comme l’outil de gestion de packages officiellement recommandé.
Un peu surpris, et en parcourant rapidement quelques pages de docs, je lis, sur la doc officielle :
While pip alone is often sufficient for personal use, Pipenv is recommended for collaborative projects as it’s a higher-level tool that simplifies dependency management for common use cases.
En regardant un peu ce que ça fait, j’ai l’impression d’y voir une philosophie très proche de npm : un gestionnaire de dépendance de projet, qui vient tirer des dépendances locales.
Node et Python ont pourtant une différence de paradigme fondamentale concernant les environnements. Là où Python va installer les librairies au niveau du système, en utilisant le PYTHONPATH pour retrouver ses petits, node, de part l’historique du langage, va par défaut télécharger les dépendances dans le répertoire courant (le fameux node_modules) à moins qu’on l’invite à installer un package de manière global, dans le but d’utiliser une application au niveau système, sans que ça ait rapport avec un projet (newman, vue-ui, etc).
Les environnements virtuels de python ont beau ressembler à un répertoire node_modules, ce n’est pas du tout le même concept, puisque le principe consiste peu ou prou à tricher sur les variables d’environnements pour installer les dépendances à un autre endroit sur le système.
Et par là même, ça ne remplit pas le même rôle. Virtualenv crée des environnements python différents, avec son propre interpréteur, ses propres librairies.
Le fonctionnement de pip n’est pas affecté par virtualenv, il fonctionne comme il le ferait en “global”, il n’a pas conscience d’être dans un virtualenv.
Et ça permet du coup de faire des choses super intéressantes, avec des environnements contextuels, qui, du coup, ne se contentent pas de simplement décrire les dépendances de mon petit projet Django, mais peuvent aussi préparer et documenter (un minimum) l’environnement python dans lequel on va se trouver. Dans les faits, on voit souvent des projets avec ces niveaux de dépendances :
requirements/base.py
requirements/dev.py
requirements/jenkins.py
requirements/prod.py
requirements/doc.py
avec l’environnement de développement qui tire les dépendances de base et de la doc, l’env de prod qui vient tirer du gunicorn et d’autres paquets dont on a pas besoin à la maison, l’environnement jenkins qui va aussi tirer la doc, etc.
Beaucoup de souplesse, qu’on ne retrouve pas avec pipenv, puisqu’il semble qu’il n’y ait que des dépendances générales et des dépendances de dev. C’est un peu léger et surtout ça ressemble comme deux gouttes d’eau à ce qu’on voit côté npm.
J’ai spontanément quelques questions sur le sujet :
Quels sont les problèmes rencontrés avec une utilisation de pip (dans un virtualenv ou non) que pipenv se propose de régler ?
J’ai vraiment le sentiment que c’est pour coller à ce qui se fait ailleurs, indépendamment des spécificités du fonctionnement du langage. Est-ce que ce n’est pas faire une erreur de vouloir reproduire ce qui se fait chez node alors que la gestion de l’installation des librairies est vraiment différente ? C’est pour rendre l’explication des dépendances dans python plus compréhensibles pour des développeurs qui travaillent moins proche du système et qui ont des habitudes ailleurs ?
Est-ce qu’il n’y a pas un distinguo à apporter entre package manager, gestionnaire d’environnement, et gestionnaire de dépendance projet ?
Comment est-ce que pipenv va me rendre plus heureux, alors que finalement je n’ai jamais eu aucune douleur à utiliser pip et les virtualenv ces 10 dernières années ?
j’aimerai présenter ici un projet sur lequel nous travaillons depuis 2016 environ. Il s’agit d’HARFANG, un moteur 3D (écrit en C++) que nous avons très tôt décidé de rendre accessible en Python 3.
HARFANG a connu plusieurs itérations et est utilisé sur de nombreux projets plutôt destinés au secteur industriel. Le dernier en date est une étude pour la SNCF, exploitant la réalité virtuelle, entièrement développée en Python, pour plonger des usagers dans une simulation et en extraire des données aussi précises que possible.
Depuis quelques mois, le source complet du moteur est disponible en license GPL/LGPLv3. Les wheel Windows et Linux sont également disponibles.
Pour finir, je linke ici une très courte demoreel qui montre le type de rendu 3D que le moteur peut délivrer (enregistré sur une GeForce GTX 1080, la techno de rendu n’a pas besoin de RTX ) :
Et après tout ce temps écoulé, la marchandisation d'une ressource publique devenue rare est devenue un état de fait.
Gérer une infrastructure a un coût, les ressources matérielles en sont une des plus visibles. N'importe qui peut se douter qu'acheter des machines qui répondent à des requêtes d'internautes, ce n'est pas gratuit. La bande passante et les coûts liés à l'infrastructure réseau sont également quelque chose dont tout le monde peut avoir plus ou moins conscience, ce même si en France, nous nous sommes habitué à payer le prix d'un forfait fixe illimité en débit. Mais en tant que simple abonné à un abonnement chez son fournisseur d'accès Internet, vous ne vous êtes probablement jamais dit que votre adresse publique IPv4, que votre fournisseur d'accès vous offre sans que cette dernière ne fasse l'objet d'une ligne sur votre facture... pouvait s'échanger à prix d'or. Fly.io s'est fendu d'un excellent article sur cette nouvelle problématique "insoluble", comprenez ce nouveau marché. Nous vous en proposons une petite adaptation afin de la rendre accessible au plus grand nombre. Quelques bases pour les profanes Pour accéder à un service ou à une ressource sur Internet (un site web, un serveur de jeu, une visioconférence...), vous avez l'habitude de passer par un nom de domaine (ex : toto.com). Les noms de domaines, comme les adresses IP sont des ressources rares. Pour expliquer ce concept de ressource rare, prenons l'exemple du numéro de téléphone : si vous attribuez à deux foyers différents le même numéro de téléphone, vous avez une chance sur deux de tomber sur la bonne personne quand vous cherchez à la joindre. Il existe donc des registres (nous allons évacuer pour le moment le problème de la gouvernance de ces registres), qui nous permettent de nous assurer que tel domaine ou telle adresse IP nous permet bien d'accéder au service ou à l'organisation demandée. Concernant les noms de domaine, le problème de l'épuisement des ressources rares s'est assez naturellement réglé par l'apparition de nouveaux TLD (les .com, .net, .fr, .io, .tv .toutcequevousvoulezsivouspouvezpayer). Le toto français prendra son toto.fr et le toto chinois prendra son toto.cn ça leur coutera moins de $10 par an et tout le monde sera content. Pour les IP c'est plus compliqué : une IPv4 se compose d'un nombre entre 4 et 12 caractères (codée sur 32 bits) exclusivement numériques, soit un maximum d'un peu moins de 4,3 milliards d'adresses. Et quand il n'y en a plus de disponibles, on ne peut pas en ajouter devant ou derrière comme on pourrait ajouter un nouveau TLD ou un sous-domaine... la pénurie est réelle. Tout fournisseur de service Internet a un besoin d'adresses IP routables pour rendre ses services accessibles au public. IPV6 a le bon goût d'évacuer le problème de rareté en proposant des adresses sur 128 bits soit 2 puissance 128 d'adresses, ce qui fait... beaucoup. Assez pour envisager d'attribuer une adresse publique aux brosses à dents, aux rasoirs électriques (absolument pour tout ce que vous voulez bien connecter sur cette planète). Mais voilà, et c'est le cas pour Fly.io, IPV6 peut aussi avoir ses limites. La première, c'est l'adoption, si vous lisez cet article sur combien coûte mon IPv4 gratuite, il y a quand même pas mal de chances que vous n'utilisiez pas IPV6. L'autre limite, c'est l'hébergement basé sur un nom (les applications peuvent partager des adresses IPv4 à l'aide de TLS SNI). Les navigateurs web bougent vite et ont vite adopté le SNI, mais les autres protocoles, peu habitués au partage, n'ont pas suivi. Vous trouverez bien un ou deux fournisseurs d'accès qui tentent de faire un peu de magie noire avec le CGNAT, mais c'est comme la chirurgie esthétique, quand ça pète, généralement, ce n'est pas beau à voir. Si vous offrez autre chose que des applications web, ça pose vite un problème. On pourrait donc utiliser SNI pour la majorité de nos applications web et des adresses IPv4 pour les exceptions, mais c'est tout de suite moins naturel et plus lourd à gérer. Du commun au marché Techniquement, il est important de comprendre que l'on ne possède pas une adresse IP, elles sont allouées par les 5 registres Internet régionaux (ARIN, RIPE, APNIC, AFRINIC et LACNIC) et revêtent plus d'un avantage public que du titre de propriété. Ces registres (RIR), avaient donc jusque là pour mission d'allouer des blocs aux organisations en faisant la demande. Aujourd'hui, comme il n'y a plus rien à allouer, les RIR se contentent de tenir à jour leur registre afin de garder une trace de qui a autorité sur tel ou tel bloc IP. "Posséder" une adresse IP, c'est le simple fait de la contrôler pour lui dire "toi, tu pointes sur tel ou tel service", ce que vous allez ensuite annoncer à tout Internet, et ça, c'est le rôle de BGP4 (Border Gateway Protocol). Vous annoncez vos préfixes d'adresses IP et AS (système autonomes) avec lesquels vous effectuer du peering vont relayer vos annonces. Lorsque qu'il y a une offre inférieure à la demande il y a un marché spéculatif. Le pire dans tout ça, c'est que lorsque l'on parle de marché, tout peut devenir irrationnel. Des gens peuvent chercher à accumuler des richesses. Ainsi, des sociétés ont accumulé des blocs IP sans réelle justification... juste parce qu'ils étaient gros et qu'ils les avaient demandé à une époque ou l'abondance était la règle. Ils sont aujourd'hui à la tête de fortunes qui "dorment dans la banque des internets"... et ils sont prêts à vous les vendre. Si vous avez tenu jusque là, bravo. Vous avez compris qu'un truc gratuit, devenu un peu trop rare, pouvait avoir de la valeur et donc motiver l'émergence d'un marché. Vous vous demandez peut-être si vous pouvez vous acheter un petit /24 d'IPv4 publiques (255 adresses) ? Techniquement, c'est relativement simple, vous disposez d'un système autonome, vous trouvez un autre AS qui accepte de vous céder un bloc, vous organisez le transfert avec le RIR et ce bloc est désormais intégré à votre propre AS. Une fois le transfert effectué, vous pouvez lancer vos annonces et vous trouverez sans grand problème d'autres fournisseurs de services prêts à relayer ces annonces. Fly.io décrit IPv4 comme le marché immobilier d'Internet, avec ses logements vacants devenus objets de convoitises. Il y a de gros propriétaires, des plus petits, et surtout beaucoup qui souhaiteraient accéder à la "propriété". Apple ou Ford disposent par exemple d'un /8... mais en ont-ils vraiment besoin ? Si vous avez investi dans des blocs IPv4 il y a plusieurs années, vous vous en sortez assez bien. En septembre 2021, il fallait compter environ $50 par IP pour de petits blocs (contre $25 en mars 2021) et plus vos blocs sont importants, plus la valeur de l'IPv4 peut grimper. Si vous cherchez des taux de rentabilité supérieurs à ceux du bitcoin, c'est vers IPv4 qu'il faut se retourner. Si on se penche sur le cas AWS avec ses plus de 65 millions d'adresses IPv4, ce dernier est à la tête d'une capitalisation en IPv4 estimée à... 3 milliard de dollars ! Au début des années 90, l'allocation d'IPv4 relevait d'un caractère un peu chaotique, on vous attribuait un /16 ou un /24 (mais rien au milieu, c'était ce que l'on appelait la "swamp zone", le marais). Si vous vouliez faire une annonce de votre bloc, il fallait au moins un /16 (soit 65 534 adresses IPv4). Aujourd'hui, comme pour un logement, on trouve du petit qui vaut de l'or et vous pourrez donc sans problème annoncer votre /24 (soit 254 adresses IPv4). Là où ça devient compliqué maintenant, c'est que jusqu'à une certaine époque, une IP pointait sur une machine. Puis nous nous sommes mis à acheter de plus grosses machines, des machines énormes (en terme de ram, de cpu et de stockage), puis à les découper en une multitude de machines virtuelles. Et ces machines virtuelles n'ont en soi d'utilité que si elles communiquent avec Internet. Si on déploie 512 vm sur une machine il vous faut donc 512 IP, à disons $45, ce qui nous fait rien qu'en adresses IP un coût (en plus de celui du serveur, du réseau...), de $23 040. Dans le temps, votre gros serveur va perdre de la valeur; et la bonne nouvelle c'est que vous pourrez amortir cette dépréciation grâce à vos 512 IPv4. La bascule full IPV6 est devenue une chimère pour certains experts dont plusieurs pensent que nous auront indéfiniment besoin d'IPv4. Et si vous êtes à la tête d'une fortune en IPv4 aujourd'hui, le meilleur moyen de vous enrichir c'est de vous offrir au plus vite un autre /8. Ainsi il devient même intéressant de contracter un prêt pour vous payer un bloc, comme vous le feriez pour un appartement. Vous habiterez votre bloc IP et vous rembourserez votre emprunt, puis réaliserez une plus-value. Sauf que si vous arrivez chez votre banquier pour lui dire que vous cherchez à faire l'acquisition d'adresses IP, ce dernier risque de vous regarder avec un air de... de banquier qui aurait trouvé une IP. "Dites, c'est pas donné vos suites de chiffres là, mais concrètement vous achetez quoi ?". Un NFT, ça peut-être de l'art, mais une adresse IP ? Un commun rare ? A moyen ou à long terme, nous serons en mesure d'exécuter des applications sans adresse IPv4 dans 2, 10 ou 20 ans... probablement plutôt 20 ans pour que ça se généralise. En attendant, ces IPv4 continueront à s'arracher à prix d'or, et ainsi le coût global de la mise en production d'un service. Mais comme toute bulle spéculative, la bulle de l'IPv4 éclatera un jour ou l'autre.
TL;DR : L’adhésion c’est par ici et la réunion c’est par là.
Un petit message pour vous informer que les adhésions à l’association pour l’année 2022 viennent d’être ouvertes sur HelloAsso. Nous vous rappelons que les adhésions comptent pour l’année civile uniquement et est nécessaire pour participer aux votes lors des assemblées générales.
Et tant qu’on parle d’assemblée générale, il serait également bien de penser à l’organiser. En effet, à cause du contexte sanitaire, il ne nous a pas été possible d’organiser la PyConFR et traditionnellement l’AG se déroule pendant l’événement. Avec le comité directeur, il a été décidé d’organiser l’AG “exceptionnellement” en ligne mais pour cela il faut choisir une date.
Voici le framadate associé pour qu’un maximum de personnes puisse participer à cette AG :
Sinon bonne année 2022 en espérant qu’elle soit bien meilleure que la précédente !
Copie du courriel de convocation envoyé à tous les membres :
by Ysabeau,Nils Ratusznik,palm123 from Linuxfr.org
En 2019 Oliver commençait une série de dépêches sur le langage Python, série qu’il nous promettait pour la rentrée 2019. Divers aléas ont fait que cette série n’a pu être terminée qu’en juin 2021.
Et, comme cela forme un tout cohérent et qu’il y avait, dès le départ, l’idée de les réunir, l’aboutissement est un, en fait plutôt deux epub qui compilent les dépêches et leurs commentaires parce que la maison ne se refuse rien. Ils sont sur un dépôt github avec les images de couvertures en version svg et png. Idéalement, ils devraient être sur un dépôt plutôt LinuxFr que celui-là.
Vous n’échapperez, évidemment, pas aux petits secrets d’ateliers en fin de dépêche.
Merci à toutes les personnes qui ont contribué d’une façon ou d’une autre à ces dépêches, ou qui les ont commentées. Cela forme un corpus précieux qui réunit à la fois l’aspect didactique et les expériences.
Sans oublier le remotivateur, j’ai nommé : tisaac.
Le, ou plutôt les livres électroniques
Les sujets traités
Vous retrouverez les liens en bas de la page, mais une présentation succincte s’impose. Donc, on commence par la popularité de Python (idéalement j’aurais dû mettre ça à jour, mais bon), pour dire ensuite au revoir à Python 2.
Et enfin, pour conclure en beauté, il y a une série d’entretiens d’utilisateurs du langage. Chacun avec une utilisation, et donc une expérience différente.
Une compilation commentée
On a ainsi la compilation de la série de dépêches plus les commentaires. Les commentaires n’ont, toutefois, pas été tous été repris, pas uniquement par volonté de censure de ma part, mais était-il nécessaire de garder une série de commentaires portant sur une coquille ou complètement hors-sujet ? Ce qui, au final fait très très peu de commentaires en moins (dont des miens soit dit en passant). En revanche, tous les avatars sont partis à la trappe, c’est comme ça1. J’ai opté pour ajouter un titre « Commentaires », balisé <h2> et d’insérer des filets (que je ne vois pas sur ma liseuse) entre chaque bloc de commentaires pour les différencier. La balise <h2> permet d’arriver directement sur les commentaires.
Par ailleurs, les seules images purement décoratives qui ont été gardées sont celles des entrées de chapitre sur lesquelles est basée la couverture des livres, soit dit en passant.
Il n’y a plus qu’une seule table des matières qui les réunit toutes. J’ai également supprimé des informations redondantes (licence par exemple) ou dépassées (PyConFR de 2019).
Le résultat final est très sûrement perfectible.
Des ? Pourquoi deux fichiers epub ?
Sur ma liseuse, les tableaux de la première dépêche sur la popularité de Python ne rendaient pas du tout et étaient illisibles. J’ai donc fait deux versions, identiques, à cela près qu’il y en a une qui a les tableaux, comme des tableaux et l’autre pour laquelle ils sont en texte, ce qui les transpose dans l’autre sens pour une meilleure lisibilité. Les classements en colonne par année et en ligne pour les langages, c’est bien quand il s’agit d’un tableau. Pour le texte, il vaut mieux avoir une ligne par année.
De cette façon, en plus c’est plus lisible pour les personnes qui ne peuvent pas lire avec leurs yeux. Et ça me paraît extrêmement important.
Où il est question de licence
Les dépêches et les commentaires d’Oliver sont sous licence CC0. Celle par défaut de LinuxFr.org est la licence CC-BY-SA 4 (Attribution ― Partage dans les mêmes conditions). Les epub sont donc sous cette dernière licence, ce qui me paraît un bon compromis.
Dans la fabrique des epub
Les logiciels utilisés
Pour arriver au résultat, j’ai utilisé l’extension pour Firefox Save as eBook dont j’avais touché deux mots ici-même en septembre 2020 et sélectionné le texte (dépêches plus commentaires) pour chaque dépêche. Ça a généré un fichier epub de base mais pas du tout communicable en l’état pour plusieurs raisons outre les éléments déjà donnés :
il y avait la « décoration » LinuxFr : notes, le couple pertinent-inutile, plus les « Discuter », etc. qui n’avaient plus, de mon point de vue, aucun intérêt en dehors du site ;
il fallait ajouter les fichiers images (qui, sinon n’apparaissent pas sur l’epub, ou nécessitent une connexion) ;
plus quelques fautes ici et là (je n’ai pas la prétention d’avoir tout corrigé).
Sans parler des titres des chapitres qui avaient besoin d’être homogénéisés. Et enfin, le fichier généré n’est pas terriblement bien formé apparemment. Il a fallu donc utiliser Sigil (formidable éditeur epub) pour corriger tout ça. Et, évidemment, la postface, les remerciements et la transposition des tableaux en texte ont été faits à partir de LibreOffice. La couverture, quant-à-elle a été concoctée avec Inkscape.
Travailler dans Sigil deux trois astuces
Petit rappel et au cas où : un fichier epub c’est en fait une collection de fichiers texte, ici un par chapitre, images, styles, etc. Le tout dans des dossiers bien spécifiques. Donc, quand on navigue dans Sigil pour modifier un epub, on navigue par fichier texte.
Pour tout dire, j’ai vraiment fait la connaissance de l’éditeur d’epub avec ce travail. Les éléments ci-dessous ne sont là que pour vous donner une idée de comment moi je l’ai utilisé.
Sigil a des boites détachables, comme Inkscape par exemple, je trouve ça très pratique avec deux écrans. Le principal avec le fichier à travailler, le Navigateur et la Prévisualisation dans l’autre ainsi que la boite Insérer un caractère spécial, très utile notamment pour les espaces insécables. En effet, on ne peut pas utiliser le clavier pour ça, à moins d’écrire le code html. Cela dit, avoir des connaissances de base en html est plutôt utile, ça permet de gagner du temps.
Je suggère très fortement de commencer par ouvrir l’Éditeur de métadonnées (menu Outils ou touche F8), en indiquant la langue (par défaut, chez moi c’est l’anglais apparemment), vous pourrez utiliser le module adéquat de correction orthographique (s’il y a du code, ce n’est pas forcément très utile) et en profiter pour donner un titre au document (dc:title), ainsi que d’indiquer le nom de l’auteur (dc:creator, ici j’ai mis « Collectif », c’est mieux qu’inconnu) et, éventuellement, l’éditeur (dc:publisher, ici LinuxFr.org). On peut en ajouter d’autres2. Ces métadonnées sont vraiment importantes.
On peut utiliser les fonctions de recherche et de remplacement soit par fichier, soit pour tous les fichiers.
Revoir la table des matières est également indispensable, ne serait-ce que pour lui donner son nom, chez moi c’était « Table of Contents », pour un livre en français, ça ne sonne pas terrible. Noter que, quand on la génère, on peut sélectionner les niveaux retenus.
Pour les images, il faut commencer par les ajouter dans le dossier Images via le Navigateur et ensuite on peut les insérer dans le fichier texte sur lequel on travaille. Et, c’est aussi dans le Navigateur qu’on réorganise l’ordre des chapitres et on met la table des matières où on veut (par défaut elle est en deuxième position, je l’ai déplacé tout à la fin). Curieusement, si Sigil accepte les images au format svg pour les illustrations, il les refuse pour la couverture.
Et, évidemment, le logiciel est capable de corriger un fichier epub pas très correct.
Transposer les tableaux
J’imagine qu’il est possible de faire un script pour ça, mais j’en serais bien incapable. Donc la procédure que j’ai utilisée, plus rapide à faire qu’à décrire :
copie du tableau à partir de la dépêche ;
collage dans Calc puis à nouveau copie de ce tableau dans Calc ;
toujours dans Calc, collage transposé ;
ajout des colonnes supplémentaires là où il faut, pour ici ajouter le rang du langage, les balises (ici <p>et </p> pour chaque ligne mais aussi <b> et </b> pour la mise en relief), rentrer le premier élément d’une colonne (par exemple le numéro avec les fioritures pour la lecture), sélectionner les cellules de la colonne et faire un Ctrl + D pour que tout ça se recopie vers le bas ;
copier et coller sans mise en forme le tableau dans Writer pour le transformer en texte ;
copier le texte obtenu et le coller dans Sigil.
La question finale
Il y en aura d’autres ?
Non !
Sur ce bonne lecture et bonne fin d’année.
Il aurait peut-être été intéressant de les garder, malgré le travail supplémentaire que cela impliquait de les ajouter, si tout le monde avait eu un avatar personnalisé. Ce qui n’est pas le cas. ↩
DC : pour métadonnées du Dublin Core qui traite de la description des ressources informatiques. ↩
Je suis nouvelle sur python et j’aurais besoin de votre aide svp.
Je travaille avec un fichier Google Sheet qui est renouvelé chaque semaine. Je le récupère automatiquement avec son id (qui change chaque semaine) via un drive, je fais qq traitements en back avec un dataframe, puis je l’ajoute dans un nouveau google Sheet. Jusqu’ici aucun problème.
Sur ce nouveau book, j’ai des TCD (tableaux croisés dynamiques) à réaliser, 1 par feuille. Mes TCD sont créées et fonctionnels (voir ci-dessous le schéma pour un).
Ce que j’aimerais est qu’ils se réalisent automatiquement car pour l’instant je créée une feuille et récupère son ID à la main puis l’ajoute dans la partie du code où sera créé le TCD.
Auriez-vous une idée de comment récupérer un id d’une feuille qui n’existe pas encore puis l’ajouter sur mon schéma de TCD ?
by volts,Yves Bourguignon,Nÿco,Ysabeau,Barnabé,Naone from Linuxfr.org
Fredrik Lundh était un contributeur Python ayant créé les bibliothèques de traitement d’image PIL et de GUI Tkinter. Il était connu pour avoir mis en ligne le site de tutoriel effbot.org couvrant ces bibliothèques. Son décès a été annoncé le 10 décembre 2021 sur la liste de diffusion des développeurs principaux du langage Python.
Fredrik Lundh a été un contributeur influent des débuts du langage Python et a beaucoup participé à la promotion de ce langage à travers l’édition de diverses bibliothèques et par l’aide qu’il apportait sur Usenet comp.lang.python aux débutants aussi bien qu’aux utilisateurs avancés.
Il a cofondé dans les années 90 une des premières startups Python « Secret Labs AB » au sein de laquelle il a développé entre autres, l’IDE PythonWorks. En 2001, il a publié chez O'Reilly « Python Standard Library » dans le but de fournir une documentation testée et précise de tous les modules de la Python Standard Library, avec plus de 300 exemples de scripts annotés utilisant les modules.
Guido van Rossum dans son hommage destiné à toute la communauté des développeurs Python termine avec ces mots : « Il va nous manquer ».
À une conférence, un spectateur nous a demandé à quoi ressemblerait le métier d'hébergeur dans 10 ans. 10 ans dans le futur, ça fait loin, 10 ans dans le passé, et ce n'est pas si long que ça si on est né au XX° siècle. Quoi de neuf depuis 10 ans Hardware On va partir sur du Dell, par ce que c'est très commun, et que leur logo est un hommage à Evil Corp, dans Mr Robot.
Donc, chez Dell, un petit serveur génération 11, en 2011, c'est 1U, 1 CPU Intel avec 4 coeurs hyperthreadés et 16Go de RAM. En 2021, on est en génération 15, et un petit serveur, toujours en 1U, c'est un 1 CPU AMD avec 64 coeurs, et 2To de RAM. La fréquence plafonne autour de 3GHz, pour embêter Moore. Donc, en 10 ans, au doigt de Dell mouillé, on a 8 fois plus de coeurs, 125 fois la RAM (le ratio RAM par core est multiplié par 15). Les SSDs sont déjà bien implantés en 2011, avec des tailles et des tarifs crédibles. En 10 ans, le SSD arrête de tricher en se faisant passer par un disque à plateau SATA, pour directement se coller au cul du PCI Express, avec le NVMe, pour des débits niagaresques. Pour les gros volumes, les disques à plateaux passent de 3 à 16To. Attention, le SATA n'a pas augmenté son débit, pour reconstruire un RAID avec ce genre de titan, prévoyez de la place dans votre planning. Les gros hébergeurs ne vont pas forcément racker du Dell comme à la belle époque, mais utiliser du matériel spécifique, voir maison, pour densifier et optimiser sa consommation énergétique. Quand la limite au gigantisme de votre datacenter est la puissance électrique disponible il faut commencer à travailler correctement, et pas tout passer en force. Les hébergeurs communiquent quelquefois sur leurs innovations (les tours à air sans clim d'OVH, le mur de gouttes de Facebook…), mais sans trop s'étendre dessus et quantifier leur progrès. Processeurs Intel pensait pouvoir profiter pépère de son monopole, mais non, les ARMs, propulsés par les smartphones et autres tablettes ont continué de progresser. Conflit classique de petit boutiste et grand boutien : est il plus simple d'améliorer la consommation énergétique d'un Xeon, ou de rajouter de la puissance à un ARM ? Autre surprise pour Intel, il est simple d'acheter une licence ARM et de rajouter un peu de sa magie, pour avoir des puces maisons. Apple l'a fait avec son M1, mais sans cibler le marché du serveur, par contre AWS, lui, déploie son processeur maison, le Graviton. Scaleway avait été le pionnier du serveur en arm64, mais sans arriver à avoir du matériel fiable (et avec une gestion du réseau farfelue). Trop tôt, pas assez sec pour Scaleway, Amazon lui, sort sa 3° itération avec fierté. Pour continuer a embêter Intel, AMD sort sa gamme Epyc qui ringardise les Xeons (et sans recompiler, on reste dans une architecture amd64 comme Intel). Un processeur, c'est pratique, c'est versatile, mais sur un serveur, tout le monde ne fait pas des maths ou de la compression vidéos. De toutes façons, quand on a besoin de cruncher des chiffres, une carte dédiée pourra faire des merveilles. D'abord avec des GPU, aka les cartes graphiques de Nvidia, qui ont évolué pour bosser avec autre chose que des float (utilisé en 3D), pour arriver aux TPU de Google suivi par des offres de Nvidia (comme le V100 disponible dans les P3 d'AWS). Le monde de l'IA a rapidement mis en place des abstractions, comme Tensorflow pour travailler sur son code métier, sans trop se soucier d'où ça tournera. Pour héberger du site web classique, les processeurs font peu de calculs compliqués, mais beaucoup de coordination et de gestions d'IO. Pour faire ça, et pour partager l'usage d'un serveur, avoir plein de coeurs est plus interessant que des coeurs qui vont vite. ARM est plutôt bon pour empiler des coeurs sur une puce, ce qui donne des monstres comme le ThunderX3, 96 coeurs pour 384 threads (x3 donc, mieux que le x2 de l'hyperthread d’Intel). Abstractions hébergement Cloud Les 3 gros cloudeurs sont bien implantés, mais ça n'empêche pas l'apparition de nouveaux challengers. Petits et teigneux comme DigitalOcean en 2011, Vultr en 2014. À une autre échelle, Baidu, en 2012, sort son offre cloud, se positionnant tout de suite comme un Amazon chinois. OVH sort son offre de Cloud public en 2015, basée sur OpenStack, qui deviendra par la suite un des plus gros cluster OpenStack. Toujours en 2015, Free sort propre Cloud, novateur et ambitieux : Scaleway. Quelques temps après, la marque Scaleway remplace les noms Free et Illiad. Du côté des morts importants, on notera Rackspace qui lâche son matériel en 2016 pour se recycler dans le consulting, ainsi que Joyent trublion du cloud (basé sur un fork maison de Solaris) qui nous a légué Nodejs, qui lâchera son cloud public en 2019. Virtualisation En 2010, la virtualisation est bien en place, avec Xen depuis 2003, et KVM depuis 2007. OpenStack En 2010, la NASA et Rackspace mettent en place OpenStack, une solution libre pour gérer son propre cloud. C'est gentil de leur part, mais ça part en sucette très vite : en 2010, on a le choix entre C++, Java et Python pour ce genre de projet, Python est choisi, mais à cette époque Python n'a pas de stack asynchrone décente, et son GIL n'empêche d'utiliser des threads. Le vrai problème, c’est la gouvernance du projet, OpenStack est un complot de lobbyistes, il y a plein de spécifications pour arriver à brancher son offre propriétaire sur les services qui composent le nuage. Dans le vrai monde, il faut un référant technique par brique de service, et des montées en version dantesques. Le ticket d'entrée d'OpenStack est monstrueux, l'idée est de mutualiser les coûts des gros acteurs, surtout pas de faciliter l'entrée de nouveaux arrivants. En France, dans les hébergeurs connus, seul OVH a eu le courage d'affronter OpenStack. Provisioning Le provisioning se généralise dans les années 2010, on passe de la bête gestion de configuration a du déclaratif : on réclame un état, le logiciel se charge de ne faire que les actions nécessaires, et ne relance que les services dont la configuration a changée. Puppet) (2005) sert d'inspiration pour créer Chef) en 2009. On est dans le monde confortablement blingbling pour l’époque du Ruby, avec de l'héritage magique et des abstractions élégantes. L'autre monde possible est celui de Python, avec Salt) qui apparait en 2011, puis enfin Ansible) en 2012, avec plus de YAML que de Python. Ansible se fait racheter par RedHat en 2015. Normaliser les API clouds L'histoire est simple, AWS sort des tonnes d'acronymes avec des nouveaux services derrière; les autres galèrent pour suivre, et pour déterminer ce qui est un standard de fait méritant un clone. libcloud tente de proposer une API neutre qui va normaliser à la truelle, pour exposer une API censée être universelle. Libcloud veut être neutre, il est finalement fade et naïf. Les API cloud ne sont pas conçues pour des humains, mais pour du code, qui lui, sera utilisé par un humain. Terraform Terraform) apparait en 2014, et secoue les îlots de l'hébergement cloud. Terraform attrape le problème par l'autre bout, en passant au déclaratif : on décrit ce que l'on souhaite avoir, le logiciel établit un plan des modifications à appliquer pour y arriver (en parallélisant ce qui le peut). Terraform, c’est clairement de l'infra as code, mais pas du provisioning. Terraform est devenu un standard de fait, et les gros hébergeurs cloud (AWS, GCE, Azur…) sortent le plugin terraform adéquat lorsqu'ils annoncent un nouveau service dans leur offre. Terraform ne va pas se perdre dans la recherche d'un dénominateur commun entre les différentes offres cloud, et permet d'utiliser toute les finesses de votre cloud préféré. Changer d'hébergeur ne sera pas magique, mais le portage de la configuration Terraform sera simple. Si vous voulez un cloud portable, ce qui est un oxymore, le cloud n'a pas du tout envie que vous alliez voir aiileurs, il faudra utiliser des services libres qui pourront être déployé sur les différents cloud, en profitant des spécificité. Hashicorp, auteur de Terraform se positionne sur ce créneau avec Vault, Consul, Nomad (concurrent de k8s). Conteneurs Google, qui a eu besoin de scaler avant que les processeurs soient adaptés à la virtualisation, a développé le concept de conteneur qui permet une isolation et une juste répartition des ressources, sur un simple process, et en partageant le kernel avec l'hôte. Les outils de base sont les namespaces pour isoler, et les cgroups pour répartir l'accès aux ressources. Docker 2013 voit la naissance de Docker) qui normalise la notion de conteneur, en utilisant les briques kernels libérées par Google utilisé pour leur projet Borg). Docker prends rapidement le dessus sur les alternatives telles que Rkt et LXC. Kubernetes Kubernetes apparait peu de temps après, en 2014. En 2015, K8s impose la normalisation des conteneurs sur Linux avec containerd, sous l'égide de la Cloud Native Computing Fundation. Containerd sert de base à Docker et K8s. K8s est le baiser de la veuve de Google Cloud à Amazon Web Service. K8s permet enfin de tenir la promesse "le cloud est élastique", mais sans dépendre d'un cloud spécifique. Petit détail important, sur un gros cloud, personne ne déploie son Kubernetes, mais tout le monde s'appuie sur l'offre infogérée du cloud, qui va proposer des solutions propriétaires pour gérer correctement l'abstraction réseau de k8s, point faible du produit. k8s devient la spécification pour que Google Cloud et Azur puisse proposer une alternative au rouleau compresseur AWS. Podman Redhat sort, un poil aigri, son Podman en 2017, en implémentant les spécifications issues de Docker, mais en se focalisant sur le rootless et l'absence de daemon. Unikernel Des chercheurs se sont demandés ce qui empêchait d'entasser plus de machines virtuelles sur un serveur. La conclusion est qu’avec de plus petites VM, on peut en mettre plus. Pour diminuer la taille d'une VM, les Unikernel proposent de tout enlever, de n'avoir plus qu'un seul espace mémoire, quelques libs pour accéder à des trucs comme le réseau, et du code métier. Ça marche plutôt bien, il est possible d'avoir un serveur web qui spwan une VM par requête, à un débit infernal. La radicalité de l'approche peut être tentante, mais dans le monde réel, c'est une tannée à débuguer, et il faut tailler une roue avec son petit couteau pour chaque service. lightvm Les conteneurs sont fort pratiques, mais leur isolation n'est pas suffisante pour faire cohabiter des projets agressifs entre eux. Ça tombe bien, la virtualisation, avec les instructions spécifiques du processeur, ont une faible surface d'attaque, et sont considérés comme sécurisés. Ok, kvm a quelques CVEs, mais tous les services d’hébergements Cloud vous ferons partager une machine avec des inconnus. Le principe de la lightvm est de partir d'un conteneur (un bout d'arborescence et une commande), mais de le lancer dans une vraie VM, avec un kernel minimaliste (aucun vrai driver, que du virtio), un init dépouillé. Baidu utilise katacontainer alors que AWS utilise firecracker. Les lightvms sont particulièrement adaptées au lambda (parfois nommé serverless) : elles démarrent vite, font une action avec un timeout rigoriste, et repartent tout aussi vite, le tout sur une machine massivement mutualisée. Virtualisation matérielle AWS, pour pousser encore plus loin le rendement de sa virtualisation utilise maintenant Nitro, des cartes dédiées pour exposer des disques durs, des cartes réseaux ou des enclaves pour la sécurité. Ces cartes permettent de simplifier le travail de l'hyperviseur (et donc libérer du CPU pour les hôtes), et même de partager des services avec des bare metals. Sécurité et chiffrement Au début des années 2010, Les outils et technologies de chiffrement étaient dans un drôle d'état, avec pas mal de drama pour OpenSSL, avec fort peu de ressource dédiées en comparaison avec son importance et de son nombre d'utilisateurs. TLS passe en 1.3 en 2018 et apporte les courbes elliptiques, et moins d'aller-retour pour établir une première connexion. Des outils matures et agréables apparaissent enfin : cfssl remplace l'infâme easy-rsa pour se faire une PKI en ligne de commande. Vault, en 2015, permet de bien gérer ses secrets et de générer des certificats temporaires. Letsencrypt (2015) défonce le monde des certificats auto signés, et permet de rendre obligatoire la connexion chiffrée aux différents services Internet. HTTPS partout ! Wireguard (2016) rebat les cartes du VPN, pour tenter d'éradiquer IPsec, et déprécier OpenVPN. Intégré au kernel Linux, disponible sous plein d'OS, il est largement déployé par les offres VPN qui sponsorisent tant de contenus Youtube Keybase (2014) permet enfin de lier une clef GPG à des identités publiques, et enfin arrêter le système de réseaux de confiance qui n'a jamais réellement fonctionné. 2020, coup de froid, Zoom se paye un peu de karma en rachetant Keybase et en gelant le projet. Authentification L'informatique adore les mots de passe, et le post-it collé sous le clavier, pour pas l'oublier. Un mot de passe faible, ou utilisé sur plusieurs sites, c'est la garantie d'un drame. D'ailleurs, allez jeter un oeil dans les listes de mots de passe compromis pour savoir si vous êtes contaminés : https://haveibeenpwned.com/ Sur cette décennie, une partie de l'effort a été fait en pédagogie, comme ces recommandations de l'ANSSI, l'autre partie avec les trousseaux et des mots de passe générés aléatoirement, renforcés par une double authentification. La dématérialisation a bien avancé sur cette décennie, exposant plus de trésors à piller, rendant indispensable un réel effort sur la sécurité. OAuth2 Oauth2 permet de déléguer l'authentification sur un site de confiance. La version 2, la première version recommandable sort en 2013. D'abord adoptée par des sites grands publiques (pour avoir tout de suite des utilisateurs qualifiés, pas pour rendre service), il s'avère redoutable pour déprécier les SSO corporate, et le compte centralisé sur un LDAP. Si votre application ne gère pas de base l'OAuth2, allez jeter un oeil à OAuth2-proxy il ya des patchs à nous dedans, pour mieux gérer Gitlab. Deux facteurs Pour limiter les risques d'avoir un de ses comptes compromis, il faut empiler les authentifications. L'usage des SMS pour ce genre de chose est maintenant déprécié (grâce à des arnaques de doublets de cartes SIM), il faut utiliser un outil normalisé comme OTP, ou des outils spécifiques. Ces outils sont disponibles sur les téléphones/tablettes, ou au travers de petits objets, comme une Yubikey. Web Terminaux Les appareils mobiles deviennent majoritaires sur le web en 2017. Si vous lisez cette page depuis un ordinateur, vous êtes minoritaire. HTTP HTTP/2 arrive en 2015, et permet le multiplexage, chose fort utile pour se passer de la concaténation souvent baroque des assets d'une page web. HTTP/3 propose de se passer de TCP, pour encore améliorer les latences sur les connexions intermittentes, mais ça ne devient testable qu’en 2021, pas encore bien sec. Navigateurs Internet Explorer disparait : déprécié en 2015, fin de vie en 2021. Il est remplacé par un outil utilisant le moteur de Chrome. Ni oubli ni pardon pour la version 6 d'Internet Explorer. Firefox continue son chemin, avec des choix excellents comme l'utilisation de Rust et autres optimisations sioux. Ça n'empêche pas son déclin face à l'envahissant Chrome : il passe de 28% à 6% entre 2011 et 2021, pendant que Chrome passe de 21% à 63%. Firefox tente un Firefox OS à destination des smartphones en 2013, pour finalement l'enterrer en 2015, laissant un amer goût de gâchis. Multimédia Flash est mort. Déprécié en 2017, fin de vie en 2020. Il est dignement remplacé puisque du multimédia arrive dans la stack HTML5. WebRTC (2011) amène la visioconférence dans le web, WebGL (2011 aussi) permet de faire souffler les ventilateurs, et WebAssembly permet de lancer des applications dans les navigateurs web. Serveurs web Après une longue et un peu vaine bagrare, Nginx dépasse Apache httpd en 2021 (Apache passe de 71% à 31% en 10 ans). Nginx fait maintenant partie des boring technologies, et c'est très bien comme ça, si vous voulez du frais, c'est vers Caddy qu'il faut aller zieuter. Cloudflare (2009), une offre de CDN et WAF représente en 2021 plus de 20% des serveurs http}(https://w3techs.com/technologies/history_overview/web_server/ms/y). Ça marche bien, mais ça centralise un truc qui devrait être décentralisé, et ça s'occupe de votre terminaison TLS. Une nouvelle niche apparaît : l'ingress, un proxy http devant votre nuée de conteneurs, qui va router vers qui de droit, en suivant le cycle de vie des conteneurs. Il existe des outils pour configurer des proxys traditionnels (Nginx ou Haproxy), mais on voit apparaître des ingress native, comme Traefik qui sort sa v1 en 2016. Développement Méthodologie Le développement logiciel s'industrialise, et se concentre sur la collaboration entre les différents membres participants (tous métiers confondus) au projet. Pour accompagner cette approche collaborative, apparaît Github (lancé en 2008, racheté par Microsoft en 2018), puis Gitlab en 2011. Pour améliorer cette collaboration apparaît l'incontournable pull-request, une interface web pour discuter du développement fait sur une branche git. Pour améliorer la qualité (et couper court à toute une famille de polémiques), l'intégration continue lancera une analyse statique et surtout les différents tests, à chaque push. De fait, la CI participe à la discussion d'une pull request en râlant dés qu'une modification pète un truc. Jenkins), sorti en 2011 est un pionnier de l'intégration continue, mais il est ringardisé par des produits plus récents (les Gitlab-runners sont tellement plus élégants). L'étape suivante est le déploiement continu (la CI déploie si les tests passent), pour faire des micro livraisons (et un éventuel rollback en cas de drame). Corriger le petit bout qui a changé est de fait plus simple que de faire le pompier sur une livraison big bang qui explose dans tous les sens. Éditeur La décennie commence pépère, coincée entre les tous vieux (vim et emacs) et les tout gros (Eclipse et Netbeans). Github, clairement de culture web sort Electron) en 2013, un mashup de Chrome et Nodejs, pour créer des clients lourds. En 2014, Github sort Atom) utilisant son Electron. Ça fait le job, la courbe d'apprentissage est plate (take that vim!), les plugins sont nombreux, et le partage d'éditeur facilite le peer coding avec un autre utilisateur Github. Le rachat de Github par Microsoft, qui a déjà un éditeur dans le même style éteint le projet. Github récidive en 2021 et lance de nouveau un éditeur, Zed bien plus ambitieux, en Rust, et toujours centré sur l'édition collaborative. Curieux de voir ce que ça va donner. En 2015, Microsoft humilie Atom en démontrant comment utiliser correctement Electron, et sort VSCode. La complétion et le debug sont fluides, tout tombe sous la main, cet éditeur est impressionnant : on retrouve les fonctions d'un Eclipse mais sans l'impression de rouler en semi-remorque dans un centre ville. Vim a toujours la cote, tous les éditeurs se doivent de fournir un plugin pour avoir les commandes Vim, mais son code est raide, et son dialecte pour écrire les plugins est en fin de vie. Du coup, paf, un fork, et en 2014 sort Neovim, avec une architecture asynchrone (les plugins ne peuvent plus bloquer l'édition), et le Lua remplace l'infame vim-script. nvim est toujours un éditeur dans le terminal, avec différents projets pour proposer des interfaces utilisateur. Analyse statique La profusion d'éditeurs (qui s'ajoute à ceux qui existent déjà), et l'apparition de nouveaux langages met en valeur un nouveau drame : Pour que les éditeurs gèrent correctement tous les langages, ça oblige à remplir toutes les cases d'un tableau éditeur/langage. Originellement développé par Microsoft pour les besoins de VSCode, normalisé avec l'aide de RedHat, en 2016, sort https://langserver.org/. Un protocole simple qui permet de développer un serveur par langage, et avec juste un client LSP, n'importe quel éditeur pourra profiter du langage. LSP fonctionne si bien qu'il est maintenant utilisé pour effectuer des recherches dans du code (et pas juste en full text) et même de naviguer dans l'affichage web d'un projet comme le propose Github. Sourcegraph, pionnier de l'indexation de code est libéré en 2018. Chaque langage propose maintenant ses outils d'analyse statique, mais dans un fouillis assez pénible. Il existe un méta analyseur pour ajouter un analyseur à la liste. Sonarqube existe depuis toujours (en 2006). Code climate apparaît en 2015, et Gitlab l'intègre a son offre. Code Climate est juste un méta analyseur avec une config et un format de sorti normalisé. Semgrep fork d'un des outils de Facebook, datant de 2020, permet de définir des règles pour attraper du code dangereux. Cette approche, lancée sur l'intégralité de Github doit permettre de trouver de chouettes 0day. Github le fait, avec son CodeQL et offre des analyses à ses utilisateurs. Typage statique L'analyse du code permet aux éditeurs de faire du coloriage pour l'affichage (comme le fait pygments), mais le vrai confort vient de la complétion. Pour avoir de la complétion correcte (et pas juste la magie crédible que propose Vim), il faut que le langage utilise du typage statique. En proposant Typescript comme dialecte Javascript, Microsoft apporte surtout le typage statique qui permet aux éditeurs de faire de la complétion correcte. Eclipse le propose depuis toujours pour Java, et bien il n'y a pas de raison que les autres langages ne puissent pas le faire. Le gain du typage fort pour qu'une personne entre sur un projet existant est énorme. Python a longtemps daubé le typage fort, pour aller plus vite, mais en 2014, sort la PEP 484, qui permet d'annoter les types, mais promis juré, le runtime n'en tiendra pas compte, Python reste Python avec son typage mou. Javascript doit avoir un des typages les plus yolo, les versions successives d'ecmascript amènent une rigueur et un déterminisme bienvenu, mais il faut se tourner vers Typescript pour avoir un vrai typage. Les PHP récents apportent le typage, mais pas d'inquiétude, Wordpress ne l'utilise pas. Java et ses dialectes l'ont de base, tout comme Golang ou Rust. Langages Le petit monde des langages utilisés sur les serveurs a bien bougé ces 10 dernières années. On a vu doucement s'éteindre Perl, mais pas de nostalgie, le flambeau du code de poète est repris courageusement par Ruby. Erlang qui a eu son heure de gloire retombe dans les limbes, mais les rubyistes ont décidé de créer Elixir, même runtime sans la syntaxe masochiste. Crypto-élitiste, Elixir est quand même un bel hommage à Joe Amrstrong (1950-2019)) qui n'a jamais eu peur de la parallélisation et la résilience. JavaScript Nodejs, en 2009 montre qu'il est possible d'avoir un langage de script nativement asynchrone et avec des performances correctes grâce au JIT. Nodejs est un emballage de V8, le moteur javascript de Chrome, et il a démarré avant que les spécifications de ecmascript atteignent leur rythme de croisière, frileux à l'idée de proposer une idée qui sera contredite dans la prochaine release de V8, nodejs refuse d'avoir une stdlib ambitieuse et délègue tout à la notion de micro-libraries : on va piocher dans plein de petites bibliothèques que l'on serait capable de réécrire si le mainteneur change de hobby. Le résultat est catastrophique, les dossiers de vendoring ont des tailles indécentes, et on peut être assurés que n'importe quel code de plus d'un mois renverra des alertes de sécurité. Nodejs apparaît au moment où le javascript coté client gagne en ambition (poussé par Chrome, suivi par Firefox). Il est maintenant impensable qu'un développeur web ne maîtrise pas javascript, ne serait-ce que pour farcir son HTML5. De fait, le vivier de développeur javascript (front et back) devient énorme. Les performances et la tenue à la charge de Node en font un bon choix, pour peu que votre pm2 compense votre mauvaise maîtrise des erreurs, et que vous publiez régulièrement votre code, mis à jour à chaque livraison. Le créateur de Nodejs, cramé par son oeuvre, revient plus sereinement en 2018 avec Deno) toujours basé sur V8, mais avec minimalisme et hygiène : la glue est en Rust, une stdlib rigoureuse est fournie… Le but premier du JS est de rendre possible la création d'applications, sans dépendre d'un OS, et de permettre les mises à jour sans demander l'avis de quiconque. Google l'a utilisé pour pousser ses produits sans demander l'avis de Microsoft. Microsoft qui se venge en créant Typescript en 2012, un dialecte qui se compile en javascript, mais qui apporte le confort d'esprit du typage fort, et une belle intégration aux éditeurs de code (complétion et analyse statique). Autre effet surprenant, javascript annihile la guéguerre des langages (PHP vs Python vs Ruby vs Whatever) pour s'imposer dans le build des assets. Techniquement, le JIT de javascript n'est pas actif lors de la première itération et donc les outils en ligne de commande en JS sont de gros veaux, mais c'est trop tard, Sass, Less et autre webpack sont dans la place. Electron, une créature de Frankenstein basé sur Chrome et Nodejs, permet de créer des clients lourds cross plateform, avec uniquement des technos web. Il faut compter 2Go de RAM par application, sans avoir de gain réel par rapport à une application web. Globalement décevant, Electron sert de socle à quelques pépites comme VSCode. Golang Google en a marre de perdre du temps à compiler du C++ qui n'utilise pas de manière correcte et systématique les IOs. Java qui était censé corriger les problèmes de C++ n'a pas réussit, et Python, autre langage officiel de Google est complètement inadapté à la programmation système. Du coup, Google crée un nouveau langage, compilé, qui gère bien les IOs, et n'est pas freiné par la cryptographie. Conçu dés le départ comme non innovant (il n'apporte aucun nouveau concept), il ne fait pas d'effort pour être aimé, mais ce n'est pas possible de le détester. Golang commence sa vie comme boring technology. Golang compile vite et livre un gros binaire qu'on a qu'à déposer sur un serveur pour déployer son application. Golang, poussé par la volonté (et la thune) de Google se permet de débuter avec une stdlib de référence, et une implémentation en assembleur de tout ce qui touche à la cryptographie. Aucun langage basé sur une communauté de fanboys ne peut se permettre ça (et c'est un poil frustrant). Golang fait exploser la barrière technique pour écrire du code système, et taille des croupières à Java pour cette spécialité. Sa stabilité et sa parcimonie dans l'utilisation de la RAM en font l'ami des administrateurs. Sans Golang pas de Docker, Influxdata, Hashicorp, Kubernetes ou Prometheus. Rust Rust, lancé en 2006 montre qu'il est possible d'avoir un langage de bas niveau, concurrent crédible du C, tout en maitrisant la mémoire pour enfin éradiquer toute une famille de failles de sécurité. Son adoption par Firefox le propulse du labo de recherche à la hype du monde réel. Beaucoup de petits outils, quelques applications, mais avec son potentiel, on peut s'attendre à de chouettes surprises. WASM Des gens se sont amusés à brancher une sortie javascript sur le compilateur LLVM, avec emscripten. Bon, ça fonctionne bien, mais livrer des tonnes de javascript généré, c'est loin d'être efficient. Des tâtonnements ont été faits, comme livrer un javascript déjà parsé, pour finalement prendre du recul et bosser à la fois sur le format et le runtime, c'est ainsi que WASM naquit en 2015. Initialement conçu pour les navigateurs web (et les processeurs Intel et ARM), WASM s'avère être un format pour livrer du code sans surcoût de performance, isolé dans un bac à sable vigoureux. Rust étant le langage de prédilection pour fournit du WASM, il est maintenant courant que des applications en Rust acceptent des plugins en wasm. Ça nous change de Lua, et surtout ça vexe bien Golang qui est incapable de proposer quelque chose d'aussi élégant et efficace. L'abstraction du langage et la qualité de son bac à sable font de WASM un format universel pour créer des plugins ou des offres serverless. WASM aurait-il tenu la promesse du Java des origines ? React React apparait en 2013, et bouscule le monde des applications web. L'ère de jquery est enfin close. React permet de faire des applications monopage web performantes, mais il impose aussi un workflow de compilation (webpack et ses amis). Le concept de React est de confier à son moteur de rendu le soin de ne modifier que les portions de page nécessaires. React promeut la création de composants réutilisables. PHP PHP s'emmèle les pinceaux dans un PHP6 qui ne verra jamais la lumière du soleil, mais permettra la sortie d'un PHP 7 en 2015. PHP tente le grand écart entre garder une compatibilité ascendante (et une logithèque vieillissante) et devenir un langage moderne et performant, adapté à la complétion des IDE et à l'analyse statique. Une 8.0 sort en 2021 et amorce l'ère du JIT et de l'asynchrone. On peut ricaner sur les PHPteurs, mais en 2021, PHP est utilisé par presque 80% des sites webs répertoriés par W3tech Wordpress atteint son sommet de hype en 2015, pour redescendre à la même vitesse que sa montée. Drupal rentre dans le rang avec sa version 7 en 2011, et bazarde sa lib perso pour utiliser Symfony. Symfony reste le boss en France, mais dans le reste du monde, c'est Laravel qui ravit la place en 2014 Python Python tente la migration vers une nouvelle version majeur, la 3.0 en 2008, il faut attendre 2015 pour avoir une version 3.x correcte, avec de l'asynchrone. Python 2 est déprécié en 2020. Cette migration n’a été rien de moins que traumatisante. Python qui n'a jamais vraiment aimé le web (mais il a des amis pour ça, comme requests, django ou flask), est devenu l'ami des scientifiques et des startups. Numpy est une base saine pour manger de la matrice, et donc construire des outils comme du machine learning (sklearn) ou du traitement du langage (Spacy). L'arme secrète de Python pour la science est Jupyter, sorti en 2014, une console disponible via une interface web, pour faire tranquillement des itérations en visualisant ce que l'on fait. Le notebook peut être repris et rejoué par une autre personne, ou utilisé pour générer un document. Java Il y a 10 ans, Java a eu un coup de mou (il passe dans le giron d'Oracle via le rachat de Sun), et Scala) (sorti en 2004) donne un peu de fraicheur avec une double approche objet/fonctionnel et de la parallélisation efficace.. Avec du recul, la syntaxe ambiguë en hommage à Ruby n'aide pas à la maintenance et Twitter se dit que finalement, du java lisible, c'est pas plus mal. Surtout que l'arme secrète de Scala est une lib en Java : Akka pour avoir du passage de message pour avoir des applications résiliantes et distribuées (à la Erlang, quoi). La montée en puissance des applications web propulsées par la reprise de l'évolution des navigateurs web, fait de l'ombre aux applications natives des smartphones. Cordova, liberé en 2011, mouline des sites web en applications pour téléphone. Pour avoir de l'exclusivité et de meilleures performances (une meilleure gestion de l'énergie essentiellement), les smartphones doivent avoir des applications natives, et non des portages automatiques. Pour attirer plus de développeurs, Google, en 2017, recommande pour Android Kotlin) (sorti en 2011), un dialecte Java. Kotlin est le pendant Android du Swift) d'Apple pour iOS, en 2014. Télémétrie Avant, le Web consistait à avoir une présence en ligne, si la home s'affichait, tout le monde était heureux, et on passait à autre chose. Ça, c'était avant. Maintenant, on veut des sites qui ont des utilisateurs, qui font des trucs, et si ça rame, ils vont voir ailleurs. Mesures Un des pionniers de la télémétrie est New Relic, sorti en 2008. Ses tarifs et son ton alarmiste (avec des images de serveurs qui prennent feu) ont lassé. En 2010 sort Datadog, plus rationnel. En libre, graphite et Statsd sont dans la place, mais bof, on ne peut pas en faire grand chose. Grafana est à l'origine un obscur projet pour visualiser des métriques. Il servira de base au projet Grafana, qui en profite pour refaire le backend en golang, et aussi de fork pour Kibana le K de ELK. En ce début de décennie, le stockage de mesures passe par des bases à taille fixe, comme les rrdtools ou le whisper de graphite. Basé sur l'outil employé en interne par Google, en 2012 sort Prometheus). Prometheus a une approche originale, c'est lui qui va chercher les mesures (du pull plutôt que du push), et il débarque avec Alertmanager pour qu'un peu de mathématiques et des mesures déclenchent une alerte. Influxdb sort 2013 et propose une base de données orientées timeseries plus classique, accompagné de Telegraf, qui va aller chercher des mesures à pousser dans Influxdb. Influxdb fait le pari d'utiliser un presque SQL, erreur fatale, un SQL est complet ou n'est pas, du coup, sa version 2 propose un élégant dialecte orient flux, nommé Flux, qui permet de faire des jointures et autres mathématiques évoluées. Influxdb, devenu Infludata était fourni avec Kapacitor, un outil de requête pour générer des alertes. Fausse bonne idée, l'outil s'avère inutilisable, en plus d'être inadapté à l'infra as code. Qu'à cela ne tienne, Flux permet tout aussi bien de requêter dans le but d'afficher des trucs que de lever des alertes. Les timeseries, c'est bien, mais ça gère mal l'arité (pour Prometheus tout comme Influxdb). Le concept d'une timeseries, c'est d'avoir des événements horodatés avec un ensemble d'étiquettes pour faire du tri, et de valeurs, pour faire des maths. Dans les labels, on met le nom du projet et de la machine par exemple. L'arité sera le nombre de projets ou de machines, dans cet exemple, et ça passera tranquillement. Si par exemple, vous avez comme label le nom des conteneurs, qu'ils sont déterminés aléatoirement, et relancés régulièrement parce que ce sont des crons, et là… l'arité va exploser. Influxdb promet IOx un moteur de stockage en Rust s'appuyant sur Arrow, DataFusion (pour avoir du vrai SQL), Parquet pour un stockage orienté colonnes dans des fichiers à la S3. IOx promet plein de choses, mais il reste beaucoup de travail. Influxdb, tout comme Prometheus, promettent de ne plus craindre les grosses arités, en 2022. On attend de voir. Traces En 2015 sort Zipkin suivi en 2016 de Jaeger (par Uber) qui fait maintenant partie du CNCF, deux outils de tracing. Le principe du tracing est d'échantillonner des mesures de toute une grappe de services. Par exemple, une page web va faire quelques requêtes SQL et des appels à des services tiers. Le tracing permettra de voir ce qui est parallélisé, ce qui bloque, et comment est composé la latence de cette requête. Grafana lance Tempo, en 2020 pour lui aussi manger de la trace. Journaux Ranger ses journaux, ça existe depuis la nuit des temps, avec syslog par exemple. Depuis, on a évolué, avec des services non bloquants, mais en TCP, qui envoie des lots compressés, peut attendre un peu, relancer un envoie raté, et en face, on peut maintenant ranger et rechercher (pas juste un gros grep). Logstash pousse des trucs bien rangés dans Elasticsearch depuis 2009. Bon, le jruby qui met une minute à se relancer pour lire sa nouvelle configuration, c'est maintenant ringard. Filebeat fait moins de choses, mais en Golang, et à un coût bien moindre que Logstash. Fluentd transporte et range les logs depuis 2011. Fluentd est en Ruby, et juste comme forwarder de logs, ce n'est pas raisonnable. Fluentbit vient épauler le gros Fluentd en 2014, il est en C, sans dépendance pénible pour le déployer et permet de ranger vos logs avant de l'envoyer a un endroit approprié, pas juste vers Fluentd. En 2018, Grafana ajoute le dernier éléments de sa stack, Loki, son mangeur de logs. L'architecture basée sur celle de Prometheus, a commencé par être ambitieuse (gros volume entassé dans du S3, index en Cassandra, services distribués) avant de revenir à la raison avec sa version 2, et une installation avec un simple binaire. Normalisation de la télémétrie Les clouds sont friands de télémétrie, et comme c'est tellement facile de mettre du bazar dans le cloud, la visibilité est importante. Les services fournis par les clouds sont maintenant équipés de sonde, mais le Graal est d'arriver à assembler les mesures métiers, et les mesures des services. Grafana a atteint le statut de standard pour la visualisation de données, et des plugins permettent de taper dans des mesures propriétaires, spécifiques aux hébergeurs. Fouiller dans les mesures, c'est bien, mais normaliser leur recueil est encore mieux. Google s'est attelé à cette tache, car il adore défoncer les exclusivités d’AWS, avec Open Telemetry, qui va clairement faciliter l'instrumentation du code métier, sans dépendre d'un hébergeur spécifique. Bases de données Belle décennie pour Postgresql, qui passe de la 9.1 à la 14. Poussé par la concurrence, Postgresql lâche son approche rigoriste, et gère maintenant le JSON, des droits fins, une réplication intégrée, des tables orientées colonne. Le rachat de Mysql par Sun, lui-même racheté par Oracle, met en avant un de ses forks Mariadb. Debian acte cette transition en mettant du Mariadb par défaut depuis sa version 9. Les bases de données qui apparaissent montrent que le SQL reste un standard incontournable. Facebook prouve le contraire en proposant en 2012 une approche inverse avec graphql, qui permet à l'application de naviguer dans des données relationnelles avec une syntaxe simple, sans passer par un ORM, sans avoir à créer un backend spécifique. Orienté fichiers Mongodb (2009) a survécu, saluons l'effort de communication pour y arriver, ainsi que la haine grandissante du SQL qui a permis cela. AWS propose de cannibaliser Mongodb avec son service DocumentDB, entrainant un changement de licence (en 2019) pour ne plus permettre de proposer une offre as a service Riak et Couchdb, eux, n'ont pas survécu. Rethinkdb fait un départ en fanfare en 2009, pour finalement être lâché par son éditeur 2016, et confié aux bons soins de sa communauté. Orienté colonnes Une surprise arrive de Russie, avec Clickhouse en 2016, par Yandex. Un plugin pour Postgresql, Citus permet de goûter aux joies des colonnes depuis 2016. Mail Le mail se fait martyriser par les outils de discussion comme Télégram, Whatsapp et Slack. Le mail sert maintenant à récupérer un mot de passe et recevoir des notifications de Linkedin. Pourtant, il y a des nouveautés importantes, comme DKIM en 2011, SPF en 2014 et finalement DMARC en 2015, pour tenter d'endiguer une partie du SPAM. GPG, en 10 ans n'a pas évolué d'un iota, même si Thunderbird le gère en natif depuis peu. GNU/Linux GNU/Linux poursuit son chemin et apporte son lot de nouveautés. La blague "est-ce que Linux est enfin prêt pour le Desktop" n'a plus droit de cité, la faute à Android, mais ça n'empêche pas les développeurs d'avancer sur le sujet. Les namespaces (2002) et les cgroups (2008) permettent de bien ranger ses process. NetworkManager (2004) pour retrouver son wifi et ses différents VPN. D-bus en 2006, pour pouvoir faire des trucs sans être root, et pour avoir des bureaux intégrants différents services. iwd pour avoir du wifi (avec du DBus dedans). systemd remet à plat l'init de Linux en 2010, Debian le déploie dans sa version 8, Jessie en 2015. Wayland) Dans Debian 10, en 2019. Pour avoir une interface graphique, et aller au delà de ce que peut proposer X11. Btrfs 2013 pour pimper vos disques durs. XFS est ringard, Ext4 fonctionne, ReiserFS s'est fait assassiner, il reste "Better FS" qui comble la frustration amenée par ZFS, le dernier cadeau de Sun pour les BSD. eBPF 2019. Les Berkley Packet Filter ont démontré leur utilité pour filtrer du réseau. Solaris a depuis des lustres le magnifique DTrace, que les linuxiens lui envient. Pour améliorer le tracing et le debug de bas niveau, Linux a maintenant eBPF, une généralisation de BPF pour coller du bytecode dans le kernel, et démultiplier les possibilités d'exploration. polkit 2006, nouveau nom en 2012. Pour avoir une gestion des droits fine, sans la violence de sudo, mais avec de chouettes CVE comme CVE-2021-4034. Ligne de commande et outils Une partie des outils que l'on pensait immuables ont maintenant des alternatives, et encore, ce n'est que le début, les rustacéens ont décidé de tout recoder en Rust : coreutils.
ip remplace ifconfig (pour tripoter le réseau) zsh détrône bash (le shell) ss remplace netstat (pour voir qui cause) tmux remplace screen (pour partager un terminal) curl détrône wget (le client réseau universel) libvps détrône imagemagick (pour bidouiller du pixel) sftp remplace scp (pour bouger des données)
Quoi de neuf dans 10 ans Faire une rétrospective n'est pas si compliqué, faire de la prospective est d'une autre envergure, avec la certitude de se vautrer sur une partie des points.
Laurent Alexandre sera backupé dans un bucket S3, mais on aura perdu la clef de chiffrement, ce qui est ballot. OS On aura un réel usage pour Fuchsia plutôt qu'une chouette hégémonie de Linux ? On aura certainement plus de Rust dans le kernel (Linux et Windows, ne soyons pas sectaire), et finalement du Rust à tous les étages. License Le laminage de la GPL par les BSD va continuer, Stallman va bouder. La SSPL va devoir être dégainer fréquemment pour limiter le pillage du libre par les gros du cloud. Communauté Plus de fondations pour limiter le nombre de mainteneurs qui meurent de faim, alors que leur projets sont utilisés par tant d'autres. L'échec de l'UX libre ne va pas s'arranger, le libre va progresser, mais dans les entrailles, pas au contact des utilisateurs finaux, sur le modèle d'Android ou même iOS. Langages Tous les langages vénérables comme Python, PHP, Ruby, sont des langages de script développés à l'époque ou les machines avait un seul processeur qui passait son temps à attendre le disque dur qui grinçait. Maintenant que le stockage se fait en SSD sur des bus de carte vidéo (le NVMe), ou utilise de la RAM persistante avec des connexions réseau approchant les 100Go, la donne est différente. Le langage ne fait plus confiance à l'utilisateur pour ne plus faire d'erreur, et il faut optimiser l'utilisation du CPU, les IOs n'étant plus un frein. Les langages doivent être a minima asynchrones, utiliser une compilation (implicite avec du JIT ou explicite). La vélocité de développement et le coût des ressources restent évidement un critère, mais la composition avec un peu de code métier (un peu lent) avec des services (performants) va devenir la norme. Le développement côté front est maintenant déverrouillé par l'écosystème Javascript et Webassembly, et le code côté serveur n'a plus à se soucier de générer du HTML à la demande, il se contente de fournir des services, composables côté client, et même avec des technologies non web, spécifiques aux smartphones. La personnalisation se fait côté client, ou sur du edge computing lié à un CDN. Materiel Pour continuer à créer de la données et du calcul, en diminuant la facture énergétique, il va falloir continuer à densifier, et spécialiser une partie des tâches (FPGA, puis silicone pour les grandes séries). Les notations sur le coût de l'hébergement (énergie et extraction de matière première) vont favoriser les gros cloud, qui vont bénéficier des économies d'échelle et d'une maitrise de bout en bout de leur offre, du matériel au logiciel. La sur-spécialisation des usines s'avère être très fragile, une inondation suffit à créer une pénurie de disques durs. On peut espérer un retour du silicone près de chez nous. Les nouveautés issues des smartphones vont continuer d'irriguer les laptops et ensuite les serveurs. La notion de mises en veille, de tâches de fonds, et de périodes de burst vont avoir leur place sur les serveurs. En plafonnant les débits des différents bus, la notion de localité d'un service va être de plus en plus floue. Cette mobilité permettra de concentrer les tâches sur une partie des machines physique, et de mettre en veille le reste. Ce flou existe déjà dans les smartphones. Vous savez ce qui est fait sur place ou à distance, stocker sur place ou plus loin vous ? Le stream de tout et n'importe quoi (musique, vidéos, jeux) va avoir du mal à se verdir, surtout avec l'augmentation des possibilités de stockage. Les améliorations réalisées pour les réseaux chaotiques, tout comme l'accès à une énergie intermittente devrait amener un peu de résilience, les technologies anciennes (radio LO, FM, HF…) vont continuer de rendre service. Les accès Internet via les flottes de satellites qui salopent les photos d'astronomie devrait décoincer les zones blanches et pallier la promesse qui a fait pshitt de la fibre partout. Les réseaux maillés et peer to peer, pourront aider pour les zones mal couvertes, mais surtout pour contourner des histoires de censures, la carte compact flash à dos de mules a fait ses preuves, on peut espérer des trucs à base d'ondes radio. Coté terminaux, l'obligation de pouvoir réparer, et d'avoir cycles de vie plus longs vont changer le rythme et l'apparence du matériel, et . Les 3 ans pour un laptop, 18 mois pour un smartphone, était clairement pousse au crime. Le parc de terminaux va devenir plus hétérogène. iFixit va pouvoir distribuer de la bonne et mauvaise note! Le dilemme entre optimiser et attendre la prochaine génération de matériel va trouver une réponse définitive. Le chargement par induction va se faire engueuler, son rendement est lamentable. Attendez-vous à un retour des écrans LCD verdâtres, des claviers mécaniques et des batteries que l'on peut changer. Moore a terminé son cycle, on avait le ciel pour limite, et bien on a atteint le ciel. Nos yeux ne peuvent pas voir plus de pixel qu'un écran retina, les latences réseau sont bien souvent meilleures que celles de votre cerveau, les débits largement décadents (pour peu que vous soyez dans une mégapole), vous n'avez déjà plus le temps de tout écouter, tout voir, tout liker, les besoins en RAM et en calcul ont aussi atteint un plafond. Black Mirror n'est pas une prophétie ou un mode d'emploi. Ce n'est pas grave, hein, c'est juste le passage de l'adolescence avec sa forte croissance et l'exploration de tous les excès, vers l'âge adulte. Il restera toujours du contenu à produire et découvrir, des humains avec qui partager.
Je suis en train de me demander comment construire mon data model avec Django pour représenter une structure / bâtiment avec plein de composants (poutres, équipements, chacun représenté par un model Django) qui peuvent se composer de différentes manières selon mes projets. Je ne veux donc pas créer un foreignkey de mon poutre vers le building parent car son ‘parent’ pourrait être plutôt une column ou un wall ou …
J’aimerais par la suite pouvoir trouver le parent de mon objet et aussi trouver rapidement l’ensemble des enfants d’un parent.
Quelqu’un aura un retour d’expérience / des conseils pour ce type de situation? Me faut-il une structure séparée de graph (DAG) pour définir et modifier ces relations ? Comment constuire un tel DAG?
WhosWho est un logiciel permettant de réaliser facilement des trombinoscopes, comme utilisés dans les collèges, lycées ou universités. Fonctionnant sur Linux, il est codé en Python, utilise GTK3, s’appuie sur ImageMagick pour la mise en page et sur OpenCV pour le recadrage automatique des photos.
J’ai travaillé quelques années dans un lycée agricole. La réalisation des trombinoscopes se faisait à mon arrivée par un logiciel propriétaire, dont le rôle de base est de simplifier la gestion d’un domaine Active Directory : on lui donnait la liste des élèves au format CSV, et pour chacun on pouvait fournir une photo. Ça marchait plutôt bien mais :
il fallait une photo du visage de chaque élève, correctement cadrée. Ça a l’air tout simple mais ce n’est pas forcément évident : les photos d’identité fournies à l’inscription sont souvent trop anciennes, donc il faut reprendre en photo tous les élèves, dont la moitié préfère se cacher sous une table plutôt que d’être pris en photo ;
il fallait sélectionner manuellement (oui, avec la souris) la photo pour chaque élève ;
c’est un logiciel non libre :-(
Et puis un jour ce logiciel fut abandonné, il fallait trouver une alternative. Le besoin me semblait simple (comme souvent me direz-vous), mais les logiciels libres y répondant n’étaient pas nombreux… En fait, je n’en ai trouvé qu’un : block_faces, un module pour l’environnement d’apprentissage Moodle. C’est probablement une bonne solution, mais je rêvais d’une solution dans l’esprit « KISS » donc je n’ai même pas pris le temps de l’essayer.
La technique
ImageMagick
J’ai eu la bonne idée d’aller voir du côté d’ImageMagick, que je connaissais de réputation comme « le couteau suisse » du traitement d’image, et j’y ai trouvé exactement ce dont j’avais besoin : la commande montage.
montage permet de mettre en page des images avec des labels, en précisant assez finement la géométrie de l’ensemble. Exemple tiré du lien précédent :
Ce qui donne, à partir des images rose.jpg et red-ball.png le résultat suivant (ici le label est %f, soit le nom de l’image) :
En parcourant la documentation d’ImageMagick, je découvrais dans la foulée un autre utilitaire fort utile, convert, qui non seulement permet de changer le format d’une image (pour passer de JPG à PDF par exemple) mais aussi de la redimensionner (ou même d’appliquer d’autres effets si l’envie vous en prend).
Malgré mon peu de compétences en programmation, l’idée de faire un petit logiciel répondant à mon besoin devenait envisageable. Je décidais de me lancer avec Python.
OpenCV
À mon propre étonnement, j’arrivais assez vite à quelque chose de fonctionnel. Grisé par le succès, je rêvais maintenant que mes photos se recadrent toute seules : je n’arrivais toujours pas à prendre les photos correctement cadrées sur le visage, et faire ça à la main après coup est vraiment fastidieux.
En cherchant de quoi faire de la détection de visage, je trouvais OpenCV. L’utilisation me paraissait très complexe, mais je tombais heureusement sur la bibliothèque Python Willow qui simplifie à l’extrême le traitement d’image de base (rotation, découpe…) et la détection de visage.
Le résultat
Après l’ajout d’une interface graphique en GTK3 (fastoche ; hum…), WhosWho était né !
Il suffit de lui fournir un répertoire contenant les photos des élèves et, idéalement, un fichier CSV contenant leur nom et prénom (l’ordre des élèves dans le fichier CSV devant correspondre à l’ordre des photos lorsqu’on les trie par nom de fichier).
WhosWho a été conçu pour s’adapter aux cas d’usage qui me semblaient habituels :
on peut changer l’intitulé du trombinoscope ;
on peut préciser qu’un élève n’a pas de photo, et une image « par défaut » sera utilisée (on peut d’ailleurs la changer si on le souhaite) ;
il est possible de corriger ou d’aider à la reconnaissance des visages, qui n’est pas parfaite (et même très étonnante parfois) ;
différents formats sont possibles, en 150 et 300ppp :
A4, portrait, 4x5
A4, portrait, 5x6
A4, landscape, 6x4
A4, landscape, 7x4
A3, portrait, 6x8
A3, landscape, 9x6
on peut choisir de trier les élèves par nom ou par prénom ;
si l’utilisation d’un fichier CSV est trop complexe pour l’utilisateur, il est possible de s’en passer complètement.
Les perspectives
Je pense être le seul à me servir de ce logiciel, une fois par an, pour quelques trombinoscopes d’une université. Je suppose que le code est très mal structuré, mais je n’ai pas les compétences et encore moins le temps pour améliorer ça. Ça n’empêche que je suis sûr que ce logiciel pourrait profiter à d’autres presque en l’état, si deux défauts étaient corrigés :
bien qu’internationalisé, aucune traduction n’est publiée (le français est fait mais pas commité) : je voulais utiliser Weblate pour faciliter le travail des traducteurs, mais n’ai pas eu le temps de le faire ;
la méthode d’installation actuelle via pip est trop compliquée pour beaucoup de monde. J’avais fait la promotion de WhosWho sur la liste de diffusion debian-edu dans l’espoir de voir apparaître un paquet Debian, mais sans succès. J’ai tenté de créer un paquet Flatpak pour le distribuer via Flathub, mais je suis resté coincé sur une erreur de nom d’application et d’icône manquante…
Si vous avez des compétences sur l’un de ces sujets et l’envie d’aider, n’hésitez pas à me contacter !
Il y a quelques années, j'utilisais intensivement un petit outil que je trouvais merveilleux: latex-to-unicode. Pour faire simple, c'était un outil minimaliste, qui lançait une petite fenêtre, on lui tapait un peu de maths en LaTeX (par exemple \forall\alpha, \exists\beta, 2\beta=\alpha, et on obtenait ∀α, ∃β, 2β=α dans le presse papier. Bref, un petit outil bien pratique pour mettre un peu d'unicode, sans se rappeller de toutes les tables (il faut être inhumain pour cela).
Sauf qu'il se trouve que cet outil était buggé, il suffisait d'imbriquer un \sqrt et une \frac ou ne serait-ce qu'un \mathbb sur la même ligne qu'un \frac et ça déconnait. De plus, le parser n'était pas vraiment conforme au LaTeX (par exemple, il fallait faire un \frac{a}{2} et on ne pouvait pas se contenter d'un \frac a2 comme en LaTeX.
Quand un outil est buggé, il suffit de contribuer me direz-vous. J'ai essayé de rentrer dans le code, mais j'ai échoué. Que faire ? En faire un soi-même.
Après avoir vu plein de trucs marrants au 33C3, (et ayant jeté la première ligne sur une illumination pendant la conf), sur le trajet retour (le train c'est bien, mais long), je me suis attelé à l'écriture d'un convertisseur de maths en LaTeX vers Unicode. flatlatex était né. En quelques centaines de lignes, j'avais un outil fonctionnel pour convertir des maths simples en LaTeX vers de l'unicode:
qui donne ∵ X∼𝓟(λ), ∴ ∀k∈ℕ, ℙ(X=k) = λᵏexp(-λ)/(k!), ce qui n'est pas dégueulasse il faut l’admettre.
Cet outil n'était alors qu'un bout de code python, pas forcément très utilisable, mais ça marchait.
Quelques heures plus tard, un ami bien plus compétent en python que moi, (surtout à l'époque où je travaillais plus dans d'autres langages) m'aida à mettre tout en forme pour en faire un module propre, ayant sa place sur pypi.
Et donc, dans les premiers jours de 2017, un outil de conversion confidentiel (bien que public) de maths en LaTeX vers unicode était né. Seulement utilisable en tant que module python certes, mais je l'utilisais, et j'ai abandonné à cet instant latex-to-unicode.
Quelque temps plus tard (je ne me souviens plus des dates exactes), un autre ami bien plus compétent que moi en packaging (et impliqué dans debian) proposa de faire une CLI (à coup d'argparse) et de packager le module et sa CLI dans debian, ce fût chose faîte.
Et cela en resta là, pour quelques années. J'utilisais mon propre outil en CLI, et sous forme de module, et je ne suis pas certain qu'il ait servi à d'autres que moi, sans faire de bruit. J'ai corrigé quelques bugs de temps en temps, mais c'était du détail.
Il y a un peu moins d'un an, j'ai appris que flatlatex était utilisé dans un outil expérimental de génération de rendu de documentation, j'ai une oreille qui a bougé pendant ¼ de secondes, puis c'est tout.
Puis, il y a environ une semaine, je me suis rappelé tout d'un coup, à quel point latex-to-unicode était pratique, c'est qu'il avait une petite interface, et que utiliser flatlatex en CLI n'était vraiment pas pratique (car bon, il faut avouer que escaper tous les \, ça devient vite barbant). Je me suis dit que faire une petite GUI sur le même principe, ça ne devait pas être très dur.
Étant très mauvais en GUI (ce n'est que la seconde GUI que je dev en python, et la troisième GUI de ma vie en tout, pour plus d'une centaine de petits outils en CLI), sachant que je n'aime pas ça, je suis tout de même content du résultat. J'ai obtenu flatlatex-gui, que j'ai aussitôt mis sur pypi.
(Et c'est au passage que j'ai découvert que flatlatex avait une rev-dep sur PyDetex, qui est un outil similaire, mais qui ne vise pas que les maths, et qui est moins simple d'usage que la petite GUI.
En tout, j'aurai donc mis 5 ans à faire un outil qui remplaçait l'outil précédent que j'utilisais. J'ai atteint mon but, et en faire un petit journal sur dlfp m'a paru une bonne idée.
Aller, quelques petits trucs en unicode pour la route:
- ℙ( μ∈[X̅±1.96σ] ) = 1-α, car Φ⁻¹(1-ᵅ⁄₂)=1.96
- 𝕆𝕟 𝕡𝕖𝕦𝕥 𝐮𝐭𝐢𝐥𝐢𝐬𝐞𝐫 𝑑𝑒𝑠 𝑐𝑎𝑟𝑎𝑐𝑡𝑒𝑟𝑒𝑠 𝓭𝓮𝓯𝓲𝓷𝓲𝓼 𝓭𝓪𝓷𝓼 𝔩𝔢 𝔰𝔱𝔞𝔫𝔡𝔞𝔯𝔡 𝔘𝔫𝔦𝔠𝔬𝔡𝔢
by Cédric Krier,Maxime Richez,palm123,Benoît Sibaud,Florent Zara,Xavier Teyssier from Linuxfr.org
Le 2 novembre dernier est sortie la version 6.2 de Tryton un progiciel de gestion intégré (ERP). Cette nouvelle version supportée un an apporte son lot de correctifs et intègre pas moins de 13 nouveaux modules dont une base pour la gestion d’un POS et l’intégration avec Shopify.
Comme d’habitude, la migration depuis les versions précédentes est prise en charge (et pour la première fois depuis 5 ans, il n’y a aucune opération manuelle à faire).
Tryton est un progiciel de gestion intégré — communément appelés PGI ou ERP — modulaire basé sur une architecture trois tiers écrite en Python (et un peu de JavaScript). Il vient avec un ensemble de plus de cent cinquante modules couvrant la majorité des besoins d’une entreprise (achats, ventes, gestion de stock et de production, facturation et suivi, compatibilité, etc.). Il est accessible via un client Web, une application native ou bien une ligne de commande en Python. Le projet est supervisé par la fondation privée Tryton qui garantit la pérennité du statut de logiciel libre.
Voici une liste non-exhaustive des nouveautés qu’apporte cette version 6.2 (voir l’annonce officielle pour une liste plus complète):
Il est maintenant possible de connecter des boutiques en ligne Shopify avec Tryton. Il suffit de configurer l’URL de Shopify et Tryton poussera automatiquement la définition des produits (avec les images, les catégories et la quantité disponible) qui sont configurés pour être vendus sur cette boutique. Ensuite, périodiquement, il récupérera les ventes passées en créant si nécessaire le client dans la base de Tryton et les paiements. Tryton clôturera la vente sur Shopify une fois qu’elle aura été traitée.
Une gestion d’images a été ajoutée sur les produits et variants. Les images sont accessibles publiquement. La taille souhaitée peut être passée comme argument et Tryton la redimensionnera à la volée et la gardera en cache. Des cases à cocher permettent de définir des filtres d’usage. Par exemple, le filtre « Web Shop » limite l’usage aux web shops de Tryton.
La gestion de budgets est prise en charge. Ils peuvent être définis autant sur les comptes comptables (par année ou période fiscale) que sur les comptes analytiques (par dates). Plusieurs budgets peuvent être définis pour la même période avec, par exemple, un scénario optimiste et un autre pessimiste. Un assistant permet de dupliquer un budget existant en appliquant un facteur. Ensuite, on peut comparer les montants budgétisés au réel.
Un nouveau module ajoute les bases pour supporter les points de ventes. Il gère l’enregistrement des paiements (avec calcul de la monnaie à rendre), met à jour le stock et la comptabilité. Les paiements par cash sont vérifiés par session et par poste. À la clôture d’une session, on peut transférer une partie du cash de la caisse par exemple en banque.
En plus du support des transporteurs UPS et DPD, cette version ajoute MyGLS et Sendcloud pour l’impression d’étiquettes de transport. Sendcloud est particulièrement intéressant puisque c’est une plateforme qui supporte plus de 35 transporteurs.
Tryton pouvait déjà récupérer automatiquement les taux de changes de la Banque Centrale Européenne. Maintenant, il supporte aussi ceux des banques nationales de Roumanie et de Serbie.
Il est fréquent de retrouver dans les projets python une liste impressionnante
de dépendances qui deviennent rapidement ingérable. Il est inutile de lister
toutes les dépendances de second, voir de troisième niveau. J’imagine
parfaitement comment on arrive à ce genre de résultats : on lance la commande
pip freeze > requirements.txt
Bonjour,
Existe t-il en Python une librairie permettant de traiter des fichiers en accès séquentiel indexé, à l’image du c-isam d’Informix ?
Merci
Claude
Hello, je vois que tout un lot de vidéo a été récemment publié sur le youtube de l’asso.
C’était des restes?
J’imagine que si l’incrustation de l’écran de présentation n’y est pas c’est qu’il n’était pas dispo?
Actuellement, j’essaie de développer un outil opérationnel pour les prévisionnistes. L’interface est construite avec tkinter. Dans celle-ci, on a crée des onglets. Je souhaiterai quand les données sont validées de changer la couleur des onglets. Je n’ai pas réussi à trouver.
Faut-il utiliser : tkinter.ttk.Style(OngletStation) ? faut-il changer "TNotebook.Tab": { "configure": { mais comment ?
Pour info, je commence à programmer en python depuis 1 an.
Une question pour les formateurs et profs qui passent par là.
Récemment, on m’a demandé sur Mastodon:
Faut-il enseigner Python aux débutant en évitant les sujets trop spécifiques à celui-ci, de façon à transmettre des connaissances sur la programmation qui soient indépendantes du langage utilisé?
Ma réponse : un grand “non”. Pour moi, la seule façon de progresser sur la programmation en générale, c’est de suivre l’enseignement de Python par un autre langage (genre Javascript, Java, C, ou même Rust, soyons fous) - et je ne me prive pas d’aborder des sujets ultra-spécifiques à Python dans mes formations aux débutants.
Apparemment, ce n’est pas une posture très courante, du coup je suis curieux de savoir ce que vous en pensez.
Il y a quelques années, insatisfait par les contenus francophones sur l’apprentissage du Python pour les débutants (que je trouvais souvent assez peu pythoniques voire erronés dans leurs explications), j’avais réfléchi à me lancer dans la rédaction d’un tel cours.
Je voulais apporter une nouvelle approche, enseigner les choses comme elles se font en Python et dans l’ordre qui va bien : ne pas se méprendre sur les variables, présenter les listes avant de parler des boucles, utiliser des exemples réalistes, ne pas présenter le for comme “un while qui avance tout seul sur des nombres”, etc.
Éviter les écueils classiques et fournir les outils pour produire du bon code.
Devant la montagne de travail que ça représentait, j’avais préféré laisser le projet de côté le temps qu’il mûrisse.
Fin 2019 / début 2020, j’ai commencé la rédaction à proprement parler et le travail m’a pris pas loin de 2 ans puisque j’ai terminé (une première version du moins) début octobre.
Le cours n’est actuellement pas publié car il est en attente de validation sur Zeste de Savoir, néanmoins je vous en propose ici un export HTML afin de recevoir vos avis et/ou vos corrections.
Bonjour,
Pour ceux qui souhaitent initialiser rapidement un projet Python
(principe de project scaffolding avec génération de code)
voici ma présentation faite le 10 Novembre à Open Source Exprerience Paris
“Comment créer une application web en quelques minutes avec un générateur de code Open Source simple et utilisable avec tous types de langages ou frameworks.”
Cette présentation est essentiellement basée sur la création d’un application web en Python (avec Bottle et SQLAlchemy). https://www.slideshare.net/lguerin/my-web-application-in-20-minutes-with-telosys
Le livre reçu, le plaisir a été total, et sans triche cette fois :)
Après quelques runs et pas mal de surprises (c'est très bien écrit, on se laisse prendre au jeu), je me suis demandé où j'en étais dans la progression du livre, et quel volume du livre il me restait à découvrir.
Je me suis donc lancé dans l'écriture d'une application pour suivre l'avancée au sein du livre et ses différents succès: https://github.com/naparuba/fdcn
Sous licence MIT, elle est composée en plusieurs blocs:
* un gros fichier json d'entrée (remplis à la main forcément) qui liste les chapitres, leurs sauts, les conditions de sauts (tel objets et/ou telle classe par exemple)
* un script python qui lit le fichier, fait quelques calculs de graphes, et génère d'autres fichiers json et une image complète des sauts du livre (https://github.com/naparuba/fdcn/raw/main/graph/fdcn_full.png pour les curieux)
* une application écrire en Godot (http://godotengine.org/) qui permet de suivre une partie dans le jeux (quel personnage, quels objets ont a eu, etc), avec en bonus une partie dédiée au Lore du livre
Note: ici un seul saut est disponible car nous sommes un personnage "Guerrier".
Si j'ai pris Python par facilité, j'ai choisi le Godot:
* car il ressemblait au Python, ça aide :)
* il est performant (là il diffère de Python, tant mieux :) )
* il permet d'exporter l'application en Web ou Android assez facilement (après le faire accepter dans le Google play ça a été une autre histoire, mais passons :) )
Si certains souhaitent se faire un diagramme complet de leur livre favori, ou se faire une appli de suivi d'avancée, vous n'avez qu'à forker et remplir le json d'entrée (comptez quelques soirées côté temps nécessaire :) )
Je ne sais pas encore s'il y a moyen depuis une application de l'appeler sur un chapitre bien particulier, a voir donc si je pourrai éviter de recoder cette partie, ça serait bien :)
En tout cas, si la partie Python ne m'a rien appris de nouveau (juste du json et des graphes, pour ça que le code de cette partie est très brut de fonderie), j'ai mis plus d'attention dans la partie Godot vu que c'était ma première application avec et j'avoue que j'ai été plutôt conquis, hormis un ou deux faux-frères avec des fonctions et leur équivalent en Python, je le conseille :D
Je travaille sur un projet python de jeu de domino à rendre pour demain. C'est super important pour mon orientation mais je suis bloquée.
Je dois utiliser le module tkinter et créer une fenêtre de saisir de mot de passe pour pouvoir entrer dans le jeu (elle est créée mais je n'arrive pas à définir le mot de passe à l'intérieur et afficher "veuillez ressayer" si le mot de passe est incorrect. Au niveau du reste du programme je dois afficher 2 fenêtres tkinter pour la saisie des noms des deux joueurs cela fonctionne.
Je dois ensuite réaliser le plateau de jeu avec les boutons en bas j'ai rattaché chaque bouton à une fonction mais ces boutons ne fonctionnent pas car je ne parvient pas à faire fonctionner les fonctions derrière. Les boutons sont piocher rejouer commencer et abandonner.
Ce projet est super important toute aide est la bienvenue. Au niveau du jeu notre professeur ne veut pas que l'on utilise la bibliothèque pygame et nous a imposé de mettre des photos pour chaque domino. Ce pourquoi j'ai créé un dossier compréssé nommé domino avec chacun des 28 dominos.
Voici mon programme ci-dessous aidez moi svp je suis foutu sinon. Pour toute question/info contactez moi en mp.
Mon code ci-dessous :
importtkinterasTKfromtkinterimportCanvas#Pour éviter d'écrire TK.CanvasfromPILimportImageimporttimeastmimportrandomdomino=['.\domino\domino-0_0.PNG','.\domino\domino-1_0.PNG','.\domino\domino-2_0.PNG','.\domino\domino-3_0.PNG','.\domino\domino-4_0.PNG','.\domino\domino-5_0.PNG','.\domino\domino-6_0.PNG','.\domino\domino-1_1.PNG','.\domino\domino-1_2.PNG','.\domino\domino-1_3.PNG','.\domino\domino-1_4.PNG','.\domino\domino-1_5.PNG','.\domino\domino-1_6.PNG','.\domino\domino-2_2.PNG','.\domino\domino-2_3.PNG','.\domino\domino-2_4.PNG','.\domino\domino-2_5.PNG','.\domino\domino-2_6.PNG','.\domino\domino-3_3.PNG','.\domino\domino-3_4.PNG','.\domino\domino-3_5.PNG','.\domino\domino-3_6.PNG','.\domino\domino-4_4.PNG','.\domino\domino-4_5.PNG','.\domino\domino-4_6.PNG','.\domino\domino-5_5.PNG','.\domino\domino-5_6.PNG']defSTART(*args):print("start function")Domino=['.\domino\domino-0_0.PNG','.\domino\domino-1_0.PNG','\domino\domino-2_0.PNG','\domino\domino-3_0.PNG','\domino\domino-4_0.PNG','.\domino\domino-5_0.PNG','\domino\domino-6_0.PNG','.\domino\domino-1_1.PNG','.\domino\domino-1_2.PNG','.\domino\domino-1_3.PNG','.\domino\domino-1_4.PNG','.\domino\domino-1_5.PNG','.\domino\domino-1_6.PNG','.\domino\domino-2_2.PNG','.\domino\domino-2_3.PNG','.\domino\domino-2_4.PNG','.\domino\domino-2_5.PNG','.\domino\domino-2_6.PNG','.\domino\domino-3_3.PNG','.\domino\domino-3_4.PNG','.\domino\domino-3_5.PNG','.\domino\domino-3_6.PNG','.\domino\domino-4_4.PNG','.\domino\domino-4_5.PNG','.\domino\domino-4_6.PNG','.\domino\domino-5_5.PNG','.\domino\domino-5_6.PNG']noms[0]=[]Rnd_1=[]forjinrange(6):while(1):idx=random.randint(1,27)ifidxnotinRnd_1:noms[0].append(Pdmn(Domino[idx]))Rnd_1.append(idx)breaknoms[1]=[]Rnd_2=Rnd_1.copy()forjinrange(6):while(1):idx=random.randint(1,27)ifidxnotinRnd_2:noms[1].append(Pdmn(Domino[idx]))Rnd_2.append(idx)breakphoto=TK.PhotoImage(file=".\domino\domino-00.PNG")#ou 0_0photo.resize((40,40),Image.ANTIALIAS)canvas.create_image(100,300,image=photo)returndefABANDON(*args):print("hey")returndefPIOCHER(dominoafficher):x=random.randint(0,27)dominoafficher=PhotoImage(file=domino[x])#Canevas.create_image(50,50, image=domnioafficher)canvas.create_image(50,50,image=dominoafficher)defREJOUER(*args):print("rejouer")returndefQUITTER(*args):globalfenfen.destroy()if__name__=='__main__':noms=[]forjoueursinrange(2):defshow():nom=Nom_du_joueur.get()noms.append(nom)#print(p)app.destroy()app=TK.Tk()app.title("Saisie nom des joueurs")app.geometry('400x400')canvas=TK.Canvas(background="#B0E0E6",height=300,width=300)img0=TK.PhotoImage(file="C:\\Users\\leila\\OneDrive\\Bureau\\joueur_image.PNG")canvas.create_image(150,150,image=img0)canvas.pack()Nom_du_joueur=TK.StringVar()nomEntry=TK.Entry(app,textvariable=Nom_du_joueur).pack()sumbmit=TK.Button(app,text='Saisir le nom des joueurs',command=show).pack()app.mainloop()print(noms)fen=TK.Tk()fen.title("Jeu de Domino")canvas=Canvas(fen,width=600,height=600,background='#B0E0E6')#1ère ligne du quadrillagec11=Canvas.create_rectangle(canvas,100,100,140,140,fill="white")c12=Canvas.create_rectangle(canvas,140,100,180,140,fill="white")c13=Canvas.create_rectangle(canvas,180,100,220,140,fill="white")c14=Canvas.create_rectangle(canvas,220,100,260,140,fill="white")c15=Canvas.create_rectangle(canvas,260,100,300,140,fill="white")c16=Canvas.create_rectangle(canvas,300,100,340,140,fill="white")c17=Canvas.create_rectangle(canvas,340,100,380,140,fill="white")c18=Canvas.create_rectangle(canvas,380,100,420,140,fill="white")c19=Canvas.create_rectangle(canvas,420,100,460,140,fill="white")c1A=Canvas.create_rectangle(canvas,460,100,500,140,fill="white")#2ème lignec21=Canvas.create_rectangle(canvas,100,140,140,180,fill="white")c22=Canvas.create_rectangle(canvas,140,140,180,180,fill="white")c23=Canvas.create_rectangle(canvas,180,140,220,180,fill="white")c24=Canvas.create_rectangle(canvas,220,140,260,180,fill="white")c25=Canvas.create_rectangle(canvas,260,140,300,180,fill="white")c26=Canvas.create_rectangle(canvas,300,140,340,180,fill="white")c27=Canvas.create_rectangle(canvas,340,140,380,180,fill="white")c28=Canvas.create_rectangle(canvas,380,140,420,180,fill="white")c29=Canvas.create_rectangle(canvas,420,140,460,180,fill="white")c2A=Canvas.create_rectangle(canvas,460,140,500,180,fill="white")#3ème lignec31=Canvas.create_rectangle(canvas,100,180,140,220,fill="white")c32=Canvas.create_rectangle(canvas,140,180,180,220,fill="white")c33=Canvas.create_rectangle(canvas,180,180,220,220,fill="white")c34=Canvas.create_rectangle(canvas,220,180,260,220,fill="white")c35=Canvas.create_rectangle(canvas,260,180,300,220,fill="white")c36=Canvas.create_rectangle(canvas,300,180,340,220,fill="white")c37=Canvas.create_rectangle(canvas,340,180,380,220,fill="white")c38=Canvas.create_rectangle(canvas,380,180,420,220,fill="white")c39=Canvas.create_rectangle(canvas,420,180,460,220,fill="white")c3A=Canvas.create_rectangle(canvas,460,180,500,220,fill="white")#4ème lignec41=Canvas.create_rectangle(canvas,100,220,140,260,fill="white")c42=Canvas.create_rectangle(canvas,140,220,180,260,fill="white")c43=Canvas.create_rectangle(canvas,180,220,220,260,fill="white")c44=Canvas.create_rectangle(canvas,220,220,260,260,fill="white")c45=Canvas.create_rectangle(canvas,260,220,300,260,fill="white")c46=Canvas.create_rectangle(canvas,300,220,340,260,fill="white")c47=Canvas.create_rectangle(canvas,340,220,380,260,fill="white")c48=Canvas.create_rectangle(canvas,380,220,420,260,fill="white")c49=Canvas.create_rectangle(canvas,420,220,460,260,fill="white")c4A=Canvas.create_rectangle(canvas,460,220,500,260,fill="white")#5ème lignec51=Canvas.create_rectangle(canvas,100,260,140,300,fill="white")c52=Canvas.create_rectangle(canvas,140,260,180,300,fill="white")c53=Canvas.create_rectangle(canvas,180,260,220,300,fill="white")c54=Canvas.create_rectangle(canvas,220,260,260,300,fill="white")c55=Canvas.create_rectangle(canvas,260,260,300,300,fill="white")c56=Canvas.create_rectangle(canvas,300,260,340,300,fill="white")c57=Canvas.create_rectangle(canvas,340,260,380,300,fill="white")c58=Canvas.create_rectangle(canvas,380,260,420,300,fill="white")c59=Canvas.create_rectangle(canvas,420,260,460,300,fill="white")c5A=Canvas.create_rectangle(canvas,460,260,500,300,fill="white")#6ème lignec61=Canvas.create_rectangle(canvas,100,300,140,340,fill="white")c62=Canvas.create_rectangle(canvas,140,300,180,340,fill="white")c63=Canvas.create_rectangle(canvas,180,300,220,340,fill="white")c64=Canvas.create_rectangle(canvas,220,300,260,340,fill="white")c65=Canvas.create_rectangle(canvas,260,300,300,340,fill="white")c66=Canvas.create_rectangle(canvas,300,300,340,340,fill="white")c67=Canvas.create_rectangle(canvas,340,300,380,340,fill="white")c68=Canvas.create_rectangle(canvas,380,300,420,340,fill="white")c69=Canvas.create_rectangle(canvas,420,300,460,340,fill="white")c6A=Canvas.create_rectangle(canvas,460,300,500,340,fill="white")#7ème lignec71=Canvas.create_rectangle(canvas,100,340,140,380,fill="white")c72=Canvas.create_rectangle(canvas,140,340,180,380,fill="white")c73=Canvas.create_rectangle(canvas,180,340,220,380,fill="white")c74=Canvas.create_rectangle(canvas,220,340,260,380,fill="white")c75=Canvas.create_rectangle(canvas,260,340,300,380,fill="white")c76=Canvas.create_rectangle(canvas,300,340,340,380,fill="white")c77=Canvas.create_rectangle(canvas,340,340,380,380,fill="white")c78=Canvas.create_rectangle(canvas,380,340,420,380,fill="white")c79=Canvas.create_rectangle(canvas,420,340,460,380,fill="white")c7A=Canvas.create_rectangle(canvas,460,340,500,380,fill="white")#8ème lignec81=Canvas.create_rectangle(canvas,100,380,140,420,fill="white")c82=Canvas.create_rectangle(canvas,140,380,180,420,fill="white")c83=Canvas.create_rectangle(canvas,180,380,220,420,fill="white")c84=Canvas.create_rectangle(canvas,220,380,260,420,fill="white")c85=Canvas.create_rectangle(canvas,260,380,300,420,fill="white")c86=Canvas.create_rectangle(canvas,300,380,340,420,fill="white")c87=Canvas.create_rectangle(canvas,340,380,380,420,fill="white")c88=Canvas.create_rectangle(canvas,380,380,420,420,fill="white")c89=Canvas.create_rectangle(canvas,420,380,460,420,fill="white")c8A=Canvas.create_rectangle(canvas,460,380,500,420,fill="white")#9ème lignec91=Canvas.create_rectangle(canvas,100,420,140,460,fill="white")c92=Canvas.create_rectangle(canvas,140,420,180,460,fill="white")c93=Canvas.create_rectangle(canvas,180,420,220,460,fill="white")c94=Canvas.create_rectangle(canvas,220,420,260,460,fill="white")c95=Canvas.create_rectangle(canvas,260,420,300,460,fill="white")c96=Canvas.create_rectangle(canvas,300,420,340,460,fill="white")c97=Canvas.create_rectangle(canvas,340,420,380,460,fill="white")c98=Canvas.create_rectangle(canvas,380,420,420,460,fill="white")c99=Canvas.create_rectangle(canvas,420,420,460,460,fill="white")c9A=Canvas.create_rectangle(canvas,460,420,500,460,fill="white")#dernière lignecA1=Canvas.create_rectangle(canvas,100,460,140,500,fill="white")cA2=Canvas.create_rectangle(canvas,140,460,180,500,fill="white")cA3=Canvas.create_rectangle(canvas,180,460,220,500,fill="white")cA4=Canvas.create_rectangle(canvas,220,460,260,500,fill="white")cA5=Canvas.create_rectangle(canvas,260,460,300,500,fill="white")cA6=Canvas.create_rectangle(canvas,300,460,340,500,fill="white")cA7=Canvas.create_rectangle(canvas,340,460,380,500,fill="white")cA8=Canvas.create_rectangle(canvas,380,460,420,500,fill="white")cA9=Canvas.create_rectangle(canvas,420,460,460,500,fill="white")cAA=Canvas.create_rectangle(canvas,460,460,500,500,fill="white")font3=('Times',30,'bold')Canvas.create_text(canvas,300,55,text="SCORE",font=font3,fill="#517369")Canvas.create_text(canvas,50,55,text="00",font=font3,fill="#517369")Canvas.create_text(canvas,550,55,text="00",font=font3,fill="#517369")Canvas.create_text(canvas,50,105,text=noms[0])Canvas.create_text(canvas,550,105,text=noms[1])d11=Canvas.create_rectangle(canvas,30,140,70,180,fill="white")d12=Canvas.create_rectangle(canvas,30,190,70,230,fill="white")d13=Canvas.create_rectangle(canvas,30,240,70,280,fill="white")d14=Canvas.create_rectangle(canvas,30,290,70,330,fill="white")d15=Canvas.create_rectangle(canvas,30,340,70,380,fill="white")d16=Canvas.create_rectangle(canvas,30,390,70,430,fill="white")d17=Canvas.create_rectangle(canvas,30,440,70,480,fill="white")d21=Canvas.create_rectangle(canvas,530,140,570,180,fill="white")d22=Canvas.create_rectangle(canvas,530,190,570,230,fill="white")d23=Canvas.create_rectangle(canvas,530,240,570,280,fill="white")d24=Canvas.create_rectangle(canvas,530,290,570,330,fill="white")d25=Canvas.create_rectangle(canvas,530,340,570,380,fill="white")d26=Canvas.create_rectangle(canvas,530,390,570,430,fill="white")d27=Canvas.create_rectangle(canvas,530,440,570,480,fill="white")#Ajouter le bouton startB1=Canvas.create_rectangle(canvas,60,530,130,580,fill="#6db4bf",tags="START-Button")B2=Canvas.create_rectangle(canvas,160,530,230,580,fill="#6db4bf",tags="ABANDON-Button")B3=Canvas.create_oval(canvas,250,520,340,590,fill="#6db4bf",tags="PIOCHER-Button")B4=Canvas.create_rectangle(canvas,360,530,430,580,fill="#6db4bf",tags="REJOUER-Button")B5=Canvas.create_rectangle(canvas,460,530,530,580,fill="#6db4bf",tags="QUITTER-Button")font1=('Calibri',11,'bold')#Ajouter le nom de chaque boutonCanvas.create_text(canvas,95,555,text="START",font=font1,fill="white",tags="START-Button")Canvas.create_text(canvas,195,555,text="ABANDON",font=font1,fill="white",tags="ABANDON-Button")Canvas.create_text(canvas,295,555,text="PIOCHER",font=font1,fill="white",tags="PIOCHER-Button")Canvas.create_text(canvas,395,555,text="REJOUER",font=font1,fill="white",tags="REJOUER-Button")Canvas.create_text(canvas,495,555,text="QUITTER",font=font1,fill="white",tags="QUITTER-Button")canvas.pack()#Ajout des actions aux boutonscanvas.tag_bind("START-Button","<Button-1>",START)canvas.tag_bind("ABANDON-Button","<Button-1>",ABANDON)canvas.tag_bind("PIOCHER-Button","<Button-1>",PIOCHER)canvas.tag_bind("REJOUER-Button","<Button-1>",REJOUER)canvas.tag_bind("QUITTER-Button","<Button-1>",QUITTER)#canvas.pack()fen.mainloop()###--------------------------------CODE MOT DE PASSE---------------------------------------fromtkinterimport*importtkinterastkfen=tk.Tk()fen.title("login")fen.geometry("350x100")fen.configure(bg='#B0E0E6')font2=('Times',16,'bold')l1=tk.Label(fen,text='Mot de passe :',font=font2,bg='#B0E0E6')l1.grid(row=1,column=1,padx=10,pady=10)str=tk.StringVar()e1=tk.Entry(fen,font=font2,width=15,show='*',textvariable=str)e1.grid(row=1,column=2,padx=5,pady=5)c_v1=IntVar(value=0)defmy_show():if(c_v1.get()==1):e1.config(show='')#mot de passe visibleelse:e1.config(show='*')#mot de passe cachéc1=tk.Checkbutton(fen,text='Afficher',variable=c_v1,onvalue=1,offvalue=0,command=my_show,bg='#B0E0E6')c1.grid(row=2,column=1)fen.mainloop()###defsaisie():#programme de saisie de mot de passemot_de_passe=input("Entrer le mot de passe \n-->")ifmot_de_passe!='domino':saisie()else:print("Accès autorisé")saisie()
Ça y est, c'est décidé, vous avez une nouvelle machine, ou bien vous voulez repartir sur des bases propres et vous aimeriez chiffrer votre disque pour protéger vos données.
Dans votre fougue, vous vous dites qu'il serait également intéressant de séparer l'OS de vos données perso, avoir un /home sur une autre partition car vous savez que cela présente pas mal d'avantages : réinstaller ou changer de système d'exploitation sans perdre vos données, partager ces données entre plusieurs systèmes, les récupérer plus simplement en cas d'incident... Partitionner est une très bonne idée.
Actuellement, il est facile de chiffrer un disque en faisant une nouvelle installation d'Ubuntu 21.04, il est également facile de partitionner son disque avec une nouvelle installation d'Ubuntu 21.04. L'installeur est assez bon pour faire ces deux choses, mais il reste limité. Si vous voulez faire les deux en même temps à l'installation sur une machine, il va falloir faire ça à la main.
Pas de panique, vous êtes au bon endroit, cet article va vous donner les étapes à suivre pour installer Ubuntu 21.04 (mais également beaucoup de versions précédentes et probablement beaucoup de futures versions) en ayant des partitions, notamment votre /home, sur un disque chiffré.
Backup de vos données
Tout d'abord, vous voulez protéger tout ce qui fait de votre ordinateur quelque chose d'unique. Vous sauriez le trouver parmi d'autres et il sait vous reconnaître. Vous avez vos habitudes avec lui et il en sait pas mal sur vous, vous aimeriez le retrouver tel quel.
Bref, il faut sauvegarder vos fichiers personnels, vos identités, vos configurations particulières, noter vos applications préférées...
Fichiers
Rien de très surprenant ici, votre dossier /home est probablement un bon endroit pour commencer.
Faites un backup de tout ce que vous voulez garder quelque part, comme un ssd, une clé usb, ou sur un Nextcloud de chez Nubla ☁️ par exemple, un super service de cloud hébergé par une petite coopérative Bordelaise sympathique.
Mais vous faites probablement déjà tout ça, faire des sauvegardes régulières ou bien synchroniser vos fichiers important quelque part, n'est-ce pas ? Bien sûr que oui, car comme tout le monde, vous êtes prudent et intelligent. Personne ne serait assez étourdi pour ne pas faire de sauvegarde, évidemment.
Applications
Cette partie dépend de votre façon préférée d'installer des applications. Avec apt, snap, Ubuntu Software Center ? Probablement un peu de tout...
pour générer une liste des paquets qui ont été manuellement installés et les enregistrer sur un fichier apps_backup.txt. Ce n'est qu'une seule manière de faire, vous pouvez modifier cette commande pour avoir une liste plus exhaustive si vous préférez valider que tout va bien.
apt-mark showmanual donne les paquets apt installés manuellement ainsi que ceux installés avec l'installeur d'Ubuntu. On peut récupérer cette liste de paquets d'installation initiale dans le log /var/log/installer/initial-status.gz. On compare ces deux listes et on ne garde que ce qui reste de la première avec la commande comm pour l'inscrire dans un fichier apps_backup.txt.
Vous trouverez beaucoup de commandes similaires sur les internets, trouvez celle qui vous conviendra le mieux, celle-ci a bien fonctionné pour moi. Évidemment, vous devez garder ce fichier en lieu sûr.
snap
Il est possible que dans certains cas vous ayez eu besoin de snap pour installer certains logiciels. vous pouvez les lister avec :
snap list
Malheureusement, je n'ai pas trouvé de de moyens de lister ceux qui ont été installés manuellement, mais vous serez capable de faire le tri, retenez ceux que vous utilisez.
Ubuntu Software
Vous pouvez aussi lancer Ubuntu Software Center et afficher la liste des applications installées.
Fichiers de configuration
En tant que personne maline, vous n'avez pas besoin de lire cette partie, car vos fichiers de configuration perso, vos "dotfiles", sont déjà copiés quelque part, probablement partagés et peut-être même versionnés.
Alors, je vais seulement lister les quelques fichiers importants que j'utilise, juste pour mon futur moi, lui éviter la jobardise et atteindre, qui sait, cet état d'intelligente prudence :
les fichiers .profile ou .bash_profile ou .bash_login... pour les sessions
.bashrc, .zshrc et/ou autres pour le shell
les aliases
.gitconfig et/ou .hgrc pour la config de vos VCS
la config de votre prompt
.vimrc pour la config de vim
...
Identités
À moins que vous ayez envie de recommencer depuis zéro avec vos identifiants, comptes, etc., vous devriez garder précieusement vos configurations ssh (où toutes vos connections serveur sont paramétrées), votre base de donnée pass ou keepass (ou tout autre manager de mot de passe local), vos paires de clés publiques ET privées SSH, GPG et autres..., vos vaults et probablement beaucoup d'autres choses dont comme moi, vous vous souviendrez malheureusement trop tard. Je ne vous le souhaite pas, soyez organisé...
Installation d'Ubuntu
Vous êtes détendu, frais, tout est en sécurité, alors vous êtes prêt.
Lancer Ubuntu
Vous avez besoin d'une clé usb bootable, d'au moins 4gb, que vous pouvez créer avec le paquet usb-creator-gtk (ou usb-creator-kde).
Il faudra ensuite redémarrer votre ordinateur avec la clé usb branchée. Pour booter sur la clé, vous devez lancer le menu de boot normalement en pressant "F12", mais cela peut changer selon les machines. En général, un message sera affiché sur l'écran de lancement pour vous indiquer quelle touche il faudra enfoncer (pour moi, il s'agissait d'appuyer frénétiquement sur "Enter" jusqu'à ce qu'un son soit émis...).
Une fois qu'Ubuntu a été lancé depuis la clé, l'installeur se lance automatiquement. Vous pouvez cliquer sur "Try Ubuntu" ou bien aller un peu en avant dans l'installation de votre Ubuntu ce qui pourra peut-être vous faciliter la suite.
À titre d'exemple, de mon côté j'ai choisi l'anglais comme langue d'installation et donc la langue d'Ubuntu (principalement pour trouver plus simplement des ressources sur le web) puis sur l'écran suivant, j'ai sélectionné la disposition correspondant à mon clavier (ce qui facilite nos prochaines manipulations). J'ai ensuite quitté l'installateur sans aller plus loin pour pouvoir paramétrer le disque.
Une fois sur l'interface classique d'Ubuntu (mais lancé depuis la clé), vous pouvez si c'est nécessaire formater votre disque avec l'application gnome disks pour avoir une machine "comme" neuve.
Partitionner le disque
Nous allons utiliser fdisk depuis le terminal avec "ctrl-alt-t" (ou bien "super-a" et rechercher le terminal).
Pour simplifier le processus et comme la plupart des commandes nécessitent un niveau de permission superuser, il faut entrer :
sudo -s
Ensuite, vous pouvez lister les disques disponibles avec :
fdisk -l
Le disque en question sera probablement /dev/sda ou /dev/vda pour moi c'était plutôt /dev/nvme0n1. La suite de cette doc suivra les particularités de ma machine.
Pour partitionner ce disque, entrez :
fdisk /dev/nvme0n1
Il nous faut une partition EFI, une partition de boot, et une autre partition (celle qui sera chiffrée) qui occupera le reste du disque. Dans fdisk, pour obtenir de l'aide, appuyez sur "m" et en cas de doute sur les différentes partitions, vous pouvez appuyer sur "q" pour quitter sans sauvegarder vos modifications.
EFI
Pour créer la première partition EFI, appuyez sur
n
Le prompt va alors vous demander le numéro de la partition, gardez la valeur par défaut en pressant
↵
Ensuite, il vous demande quel est le premier secteur à allouer. Par défaut, ce sera le premier qu'il trouve, appuyez donc sur
↵
Et enfin le dernier secteur. Cette partition de EFI de nécessite pas de beaucoup de place. Mais suffisant, ce n'est pas assez pour moi, j'ai donc arbitrairement préféré 2G parce que mon disque est assez gros pour supporter un sacrifice de cette valeur. Indiquez dans le prompt
+2G
Boot
Pour la partition de boot, même procédure, 2G c'est trop, généralement, 512M sont suffisant, mais trop, c'est pas grave aussi :
n
↵
↵
+2G
À chiffrer
Enfin pour la dernière partition, même procédure, sauf que l'on veut occuper le reste du disque. Le dernier secteur de cette partition doit donc être le dernier secteur du disque, et ça tombe bien, c'est la valeur par défaut :
n
↵
↵
↵
Il faut maintenant sauvegarder toutes ces modifications de la table de partition en pressant
w
Les partitions sont maintenant créées, nous pouvons passer au chiffrement de cette dernière partition nommée nvme0n1p3.
Chiffrer votre partition principale
Il est temps de choisir un nom pour votre volume chiffré. Vous pouvez par exemple choisir le nom que vous voulez donner à votre machine. Lors du lancement de votre ordinateur, c'est ce nom qui apparaîtra lorsque vous sera demandé votre mot de passe pour déchiffrer le disque. Ici, pour l'exemple, nous l'appellerons pasvraimentcrypté.
Nous pouvons lancer la procédure de chiffrement avec
cryptsetup luksFormat /dev/nvme0n1p3
Le prompt demandera confirmation en entrant YES ce que nous pouvons faire en toute sérénité. Il demandera ensuite d'entrer la passphrase, ce sera votre clé pour déchiffrer votre disque à chaque démarrage, ne l'oubliez pas !
Nous avons ensuite besoin d'ouvrir cette partition chiffrée, pour en faire un volume physique et pour y créer un groupe de volume nommé ubuntu et différents volumes logiques. Entrons
Comme nous ouvrons un volume chiffré, le prompt nous demande la passphrase. Cette commande va créer un nouveau device nommé /dev/mapper/pasvraimentcrypté.
Nous allons ensuite utiliser LVM2 (Logical Volume Manager) pour partitionner ce nouveau device. Dans notre cas, nous voulons une partition root de minimum 8G pour l'OS, une partition home pour l'utilisateur et une partition swap de 8G pour la mémoire. Vous pouvez être imaginatif sur vos partition, vous trouverez beaucoup de ressources et différents avis sur la question de la taille à allouer, mais ce cas suffit à mes besoins.
Nous allons faire de notre partition déchiffrée un volume physique :
Nous pouvons maintenant relancer l'installeur. Lorsque celui-ci demandera de choisir le type d'installation, cliquez sur le bouton "Autre chose", ce qui nous permettra d'utiliser les partitions et volumes créés. Configurons les trois volumes logiques :
/dev/mapper/ubuntu-root
Utiliser comme : Ext4 journaling filesystem
Formater la partition
Point de montage : /
/dev/mapper/ubuntu-swap
Utiliser comme : Swap area
/dev/mapper/ubuntu-home
Utiliser comme : Ext4 journaling filesystem
Formater la partition
Point de montage : /home
Et pour les devices :
/dev/nvme0n1p1
Utiliser comme : EFI
/dev/nvme0n1p2
Utiliser comme : Ext2 filesystem
Formater la partition
Point de montage : /boot
Un petit récapitulatif des changement sera affiché. Nous pouvons poursuivre l'installation d'Ubuntu. Une fois l'installation terminée, choisissez "Continuer à tester", nous devons encore faire un peu de configuration.
Instructions de déchiffrement au démarrage
Ubuntu est installé sur votre machine. Il nous faut maintenant décrire quel device doit être déchiffré au démarrage et comment. Nous avons donc besoin d'éditer la crypttab pour donner ces instructions. Pour que tout cela soit pris en compte, il nous faut reconstruire initramfs qui gère le répertoire racine temporaire pendant le démarrage du système. Enfin, cette reconstruction ne peut être réalisée que depuis la nouvelle installation.
Mais avant tout, il nous faut copier l'UUID du disque chiffré. Ouvrez un nouveau terminal (ou un nouvel onglet) et entrez
sudo blkid /dev/nvme0n1p3
vous pourrez par la suite retourner sur cet onglet, il vous suffira de le mettre en surbrillance pour qu'il soit copié dans le buffer de votre souris (et collé avec le bouton du milieu de votre souris). Vous pouvez aussi utiliser "shift+ctrl+c" pour copier le texte en surbrillance et "shift+ctrl+v" pour le coller.
Basculer sur la nouvelle installation
Nous allons utiliser chroot pour passer dans le nouveau système. Entrez les commandes suivantes :
mount /dev/mapper/ubuntu-root /mnt
mount --bind /dev /mnt/dev
chroot /mnt
mount -t proc proc /proc
mount -t sysfs sys /sys
mount -t devpts devpts /dev/pts
mount -a
Nous sommes maintenant dans le nouveau système, avec différents devices montés sur différents répertoires.
Instructions de démarrage
Nous devons créer le fichier /etc/crypttab. Le fichier doit contenir la ligne suivante, vous pouvez l'éditer avec nano, vi, emacs, bref, votre éditeur préféré et il n'est évidemment pas nécessaire ici de débattre de la supériorité de l'un par rapport aux autres 😘
Nous avons donc quatre champs : le nom du device à déchiffrer, son UUID (remplacez-le par celui de votre device chiffré, celui que vous avez copié précédemment, sans guillemets), le mot de passe (à none puisque l'objectif est qu'il vous soit demandé à chaque démarrage) et des options.
Sauvegardez ce fichier et quittez l'éditeur (pas le terminal).
Mettre à jour initramfs
Une fois l'éditeur quitté, toujours dans le terminal, il nous suffit de rentrer la commande suivante :
update-initramfs -k all -u
Nous pouvons maintenant quitter chroot en tapant
exit
Depuis notre shell de départ, il nous faut maintenant démonter mnt avec
umount -R /mnt
Fin
Nous pouvons maintenant fermer le shell et relancer la machine. Au démarrage, elle devrait nous demander la passphrase pour déchiffrer le device pasvraimentcrypté puis Ubuntu se lancera normalement.
La commande :
lsblk
nous permet d'avoir un visuel sur le résultat de nos différentes manipulations :
Les ateliers traduction reprennent ! Retrouvez nos équipes motivées de l'association pour une nouvelle session de traduction de la documentation #Python ! On se retrouve sur notre BBB ce mercredi 27 octobre 19h CEST, tout le monde est le bienvenu !
Jusqu'à la fin de l'année Bearstech participera à 3 évènements majeurs de l'Open Source, du Cloud et de la culture DevOps. Venez rencontrer les ours sur leur stand ou en conférences dans les semaines et mois à venir : Open Source Experience, 9-10 novembre 2021 Cet événement réunira les principaux acteurs de la communauté Open Source européenne. Bearstech y sera présent avec plus de 70 exposants, venez nous y rencontrer en mentionnant notre newsletter, il y aura des cadeaux à gagner :-)
Plus d'infos sur le salon : https://www.opensource-experience.com/
Cloud Expo Europe, 23-24 novembre 2021 Rendez-vous BtoB français dédié au Cloud, à la Cyber Sécurité, au DevOps, au Big Data & IA. Bearstech y présentera une conférence. Cloud, DevOps, cybersécurité, big data, IA… toutes ces technologies s’imbriquent et se complètent ! Venir au salon c’est l’occasion unique de retrouver les experts de ces domaines sous un seul et même toit.
Plus d'infos sur l'événement : https://www.cloudexpoeurope.fr/
La Convention Annuelle du CRiP ; Les 8 et 9 décembre 2021
Nous serons présents sur les thématiques : CICD/DevOps , Cloud - Architectures, Technologies & Services , Cyber résilience (PCA/PRA). Cette convention réunit plus de 1110 participants : DSI, CTO, Responsables d’Infrastructure, de Technologies de 561 entreprises.
Plus d'infos sur la convention : https://www.crip-asso.fr/crip/event/detail.html/idConf/889
Découvre avec moi toutes les nouveautés de la version 3.10 de Python qui est sortie début octobre.🔗 Article complet sur le blog :● https://www.docstring.fr/…
Mars 2020, un moment pas très bien choisi pour tenter de faire des entretiens d'embauche. Pourtant, je vois Yaal en visio d'abord, et j'apprécie beaucoup ce que j'entend pendant cet entretien !
On garde le contact, on se dit qu'on se verra après le confinement, mais comme les semaines s'étirent, on continue à distance et c'est le premier juillet 2020 et que je suis officiellement embauché⋅e dans Yaal en tant que graphiste webdesigner.
Ma première mission ?
Développer l'identité visuelle du projet tout neuf de quelques associé⋅es de Yaal : Une brasserie !
La Brasserie du Sabot, c'est quoi ?
Le projet d'associé⋅es de Yaal. Une brasserie artisanale installée à Villenave d'Ornon, au sud de Bordeaux.
Un projet coopératif et militant. D'ailleurs, c'est pas pour rien que ça s'appelle le Sabot : Si au premier abord on va penser à l'aspect artisanal de la chaussure en bois d'antan, c'est plutôt du symbole révolutionnaire dont on parle ici. Le sabot qu'on coince dans les rouages de la machine à l'usine en signe de protestation. Le sabotage, quoi !
Pour moi, en tant que graphiste, ça fait deux grands axes à explorer pour concilier tout le monde :
L'esthétique de l'engagement, de la contreculture, un truc un peu révolutionnaire. Militantisme, anarchisme, affichage sauvages, tracts syndicaux, pochoirs et graffitis, affiches déchirées, c'est ce genre d'images là que j'ai eu en tête.
L'artisanal. Le bois, le recyclé, le matériau brut, l'écologie. C'est aussi un sujet clé pour les associé⋅es de la brasserie.
Des idées en vrac
Inspirations de dessin à la ligne claire, mais aussi de découpage de pochoir, puis de gravure.
et ça sur des bouteilles, ça donnerait quoi ?
Ces pistes, déclinées pleeein de fois sur des formats d'étiquette pour se donner une meilleure idée de ce que ça donne, ci-dessous un petit florilège :
Toujours avec une texture un peu papier dans le fond, on se rappelle à la fois de l'aspect artisanal et des tracts de manif', une pierre deux coups.
Et pour s'y croire encore plus, j'en ai intégré certaines sur des mockups de bouteilles. Toujours plus d'immersion.
Le choix final
Avec ces prévisualisations en tête, plus simple de se faire une idée et de savoir ce qui nous parle vraiment.
Voilà le logo choisi, qui servira aussi pour les étiquettes d'expérimentation :
Déclinaison
Les étiquettes finales mettront à l'honneur des figures de l'anarchisme, et principalement des femmes !
En voilà quelques unes, à l'image d'Emma Goldman et Louise Michel.
Le logo principal quand à lui, se prête à l'exercice des brassins de test, du site internet, des flyers, des sous-bock et de la devanture de la brasserie elle-même.
Les étiquettes finales, après retouches faites en interne à la brasserie.
Le site
Dans un premier temps, j'ai développé un site internet vitrine pour la Brasserie, dont l'objectif principal était d'annoncer sa future ouverture et de la faire découvrir.
Puis dans un second temps est venue la partie boutique, celle qui permet de commander ses bières en ligne !
Tada !
Et surtout, n'hésitez pas à aller jeter un oeil par vous même sur 🍺 https://sabot.beer 🍺 !
Yaal Coop est officiellement née le 1er septembre 2020 et a accueilli ses premier·es salarié·es 2 mois plus tard, en novembre 2020.
C'est la petite soeur de Yaal SAS, créée il y a bien plus longtemps, en 2010 (ce qui ne rajeunit pas ses fondateurs Arthur et Colin !).
Comme je sais que la co-existence des deux entreprises peut être source de confusion, voici ma tentative pour raconter l'aventure Yaal Coop.
Disclaimer : mon point de vue est personnel et forcément biaisé. Et pas forcément très synthétique non plus. 😗🎶
Yaal kézako ?
Yaal est une vieille entreprise d'informatique (sisi 2010 c'est forcément vieux, je n'avais même pas entamé ma première carrière professionnelle de bio-physicienne à cette époque !).
Mais une entreprise qui n'a de classique que son statut juridique de SAS, car pour le reste, on dévie pas mal des standards du milieu.
Auto-organisation et auto-gouvernance sont des principes qui font partie de l'ADN de Yaal depuis toujours.
Si l'entreprise a grossi, jusqu'à atteindre une trentaine de personnes en 2019, elle a eu à coeur de maintenir ces principes en effaçant la hierarchie et en proposant aux salarié·es de s'associer après un an de collaboration.
Transparence des salaires et des finances permet à chacun·e, associé·e comme salarié·e, de saisir les enjeux, de se forger une opinion et d'en discuter lorsqu'il le désire.
Une autre particularité de Yaal est son modèle économique reposant sur l'investissement technique. L'ambition est grande : casser les règles habituelles du couple client/prestataire informatique en partageant les risques aussi bien techniques que financiers avec les porteur·euses de projets innovants auxquels elle s’associe.
Pour se donner les moyens de ces ambitions, les associé·es touchent tous le même salaire, sensiblement plus faible que le prix du marché pour permettre à l'entreprise d'investir dans les projets, et se partagent plus tard les bénéfices en cas de succès collectif. Finalement, sur 10 ans, les revenus des associés chez Yaal sont comparables à ceux d'autres entreprises informatiques.
Avec le rachat de Myelefant par Sinch, une partie de l'équipe quitte Yaal pour suivre ce projet et rejoint Sinch en mars 2020.
Parmi ceux et celles qui font le choix de rester, des associé·es de Yaal de longue date mais aussi des salarié·es plus récent·es, dont je fais partie.
Embauchée à Yaal en octobre 2018, je n'ai pas eu le temps d'y devenir associée, l'opération de vente de Myelefant ayant gelé les opérations d'entrée et sortie du capital à l'été 2019.
Et après le rachat, la situation financière de Yaal a évidemment pas mal changé. Il n'est d'un coup plus aussi simple de rentrer au capital de Yaal SAS dont la valorisation financière a pas mal évolué. 😅
Pour autant j'aime toujours Yaal et son modèle inspirant qui m'a séduite d'entrée !
Et je ne suis pas la seule.
Alors que certain·es profitent de ce tournant pour se lancer dans une aventure de production de bière, je commence un sacré remue-méninges avec mes collègues pour imaginer un Yaal 2.0 encore plus beau, encore plus fort, et encore plus autogestionné. 💪
Tant qu'à devoir changer de structure pour assurer à tous ses membres un même niveau d'engagement et de pouvoir décisionnel, pourquoi ne pas remettre les choses à plat et changer de statut ?
En passant à celui officiel de coopérative, cela clarifie notre fonctionnement (1 personne = 1 voix) et nos valeurs (recherche d'équilibre entre toutes les parties prenantes et d'une rentabilité compatible avec cet objectif).
Qu'est-ce qui change alors dans Yaal Coop ?
Yaal Coop est une Société Coopérative d'Intéret Collectif (SCIC). Entre autre, ça veut dire que :
Tout·e salarié·e peut un jour devenir associé·e. Chez nous, c'est même devenu une obligation après un an de salariat, inscrite dans nos statuts. On souhaite ainsi aligner nos intérêts et nos engagements, éviter de créer un fossé entre coopérateur·rices associé·es et salarié·es. Fin 2019 à Yaal, un tiers seulement des salarié·es étaient associé·es et il nous semble nécessaire d'inverser la dynamique au sein de Yaal Coop.
Le processus d'entrée et sortie des associé·es au sein de la coopérative est simplifié car il est décrit dans nos statuts et détaché de la valorisation financière de l'entreprise, au contraire d'une entreprise classique. Cela assure également une lucrativité limitée puisque'aucune plus-value n’est possible lors du remboursement des parts en cas de départ.
Au contraire d'une SCOP (un autre statut plus connu des entreprises coopératives), le capital et le pouvoir n'est pas réservé aux seul·es salarié·es. Plusieurs collèges d'associé·es existent, dont celui des salarié·es, mais ce n'est pas le seul.
Aujourd'hui à Yaal Coop nous avons désigné 4 collèges :
celui des salarié·es qui dispose de 50% des voix, le maximum possible en SCIC, car il nous semble primordial que les travailleur·euses soient majoritaires pour décider des orientations de leur entreprise
celui des bénéficiaires (composé de clients, usagers ou fournisseurs). Collège obligatoire en SCIC, il fait toute la particularité de ce statut et concrétise la recherche de l'intérêt collectif, en intégrant les autres parties prenantes du travail réalisé au sein de l'entreprise
celui des investisseur·euses qui nous a permis d'accueillir Yaal SAS et de bénéficier d'un premier apport pour lancer l'activité !
et celui des observateur·rices et soutiens, qui vise à accueillir toute personne morale ou physique qui contribuerait par tout moyen à l'activité de Yaal Coop : professionnel·le collaborateur·rice, réseau ou organisme partenaire (acteur·rice de l'ESS, des biens communs...), bénévole, etc.
Pour créer Yaal Coop, nous nous sommes fait accompagner par Finacoop Nouvelle Aquitaine, qui est aujourd'hui notre cabinet comptable mais aussi le premier membre officiel de notre collège des bénéficiaires 💚, ainsi que par l'URSCOP.
Nous avons aussi procédé à un rachat de l'activité partielle de Yaal SAS pour basculer nos contrats de travail, et nous avons signé un contrat de licence d'exploitation de la marque Yaal pour pouvoir porter fièrement l'héritage de Yaal jusque dans notre nom. ✊
Mais concrètement au quotidien ça fonctionne comment ?
Pour l'instant la mise en oeuvre de nos principes coopératifs et d'auto-gouvernance est plutôt simplifiée : en passant de plus de 30 salarié·es à 5 coopérateur·rices salarié·es associé·es, on a naturellement beaucoup fluidifié la communication et le partage d'informations entre nous (même si la crise sanitaire ne nous a, elle, pas beaucoup aidés 😩).
Aujourd'hui on se retrouve la plupart des jours de la semaine en présentiel dans notre local pour travailler sur nos différents projets.
Même lorsqu'on ne travaille pas sur la même chose au même moment, c'est d'autant plus facile de discuter des autres sujets autour d'une pause thé ou du déjeuner.
Le mardi en particulier est sanctuarisé pour pouvoir discuter et travailler sur des sujets collectifs : tout le monde se retrouve au bureau et personne ne travaille isolé en prestation. (Au contraire le mercredi est le seul jour où tout le monde télétravaille alors ne prévoyez pas de passer au local ce jour là pour boire un café !).
Lorsque tout le monde est arrivé, on commence notre weekly où l'on discute à tour de rôle des activités de la semaine passée et celle à venir en s'appuyant sur notre trello* d'équipe qu'on met à jour à ce moment là. On y met en particulier toutes les tâches de gestion, projets internes et pistes/prospects pour assurer un suivi partagé.
Avec notre instance de cloud nextcloud qui nous permet de numériser et ranger tous les documents de l'entreprise (notamment les factures, contrats, fiches de paie, etc.) et de partager des agendas (par exemple celui de nos congés/absences), c'est notre outil principal pour la gestion.
On a aussi une petite interface maison héritée de Yaal qui nous permet à tous d'avoir un oeil sur l'évolution du compte en banque, un bon gros tableau libre office à l'ancienne en guise de plan de tréso et un mini-wiki dans un simple document texte partagé pour documenter nos habitudes de gestion, qu'on étoffe au fur et à mesure (comment on commande des tickets resto ? Comment on range une facture ? Comment on fait la paie (sans risquer d'oublier la dernière étape de bien fêter la fête 🎉) ?).
Les mails et surtout la messagerie Element complètent nos outils de communication interne, en particulier les jours où nous sommes à distance et/ou asynchrones.
De manière plus macro, on a fait le choix du salaire unique et du temps plein pour les associé·es.
Notre salaire est donc indépendant de notre expérience, de notre fonction et du montant que l'on facture.
Et son montant est encore bas pour continuer de pouvoir investir à la manière de Yaal SAS.
On a eu pas mal de discussions riches sur le sujet, en particulier une session animée par David Bruant, extérieur à la coop, qui aime réfléchir au sujet de la rémunération juste (merci d'être venu en parler avec nous l'année dernière !).
Je suis assez curieuse d'autres modèles alternatifs, comme celui de Scopyleft par exemple, où chacun se paie ce dont il a besoin après avoir pris soin d'en discuter avec tout le monde.
Mais pour l'instant le salaire unique nous convient et nous permet de démarrer simplement. On aimerait s'augmenter dès que la coopérative aura atteint un régime de croisière mais on est aussi plus dans la team "réduisons notre temps de travail" que "gagnons toujours plus", donc on verra bien...
Côté projets, on continue l'investissement technique (comme avec notre premier projet Lum1 !), mais on fait aussi un peu de bénévolat à Supercoop (le supermarché coopératif de Bordeaux) et d'autres projets internes : bientôt Nubla ☁️ ?! On fait aussi un peu de prestation plus classique vu qu'on continue notamment à travailler pour Sinch, ce qui assure une certaine stabilité financière.
Au fond on cherche encore l'équilibre qui conviendra (et qui évoluera probablement !) et on est ouvert sur les modes de collaboration possibles.
Ce que l'on veut surtout c'est participer à des projets qui ont du sens et avec des personnes qui partagent nos valeurs.
Enfin côté vie coopérative élargie, et en particulier animation des autres collèges d'associé·es, on a encore un tas de chose à explorer. On a la chance de pouvoir commencer petits, avec peu d'associé·es qui nous connaissent et nous font confiance. Donc nos efforts sont pour l'instant concentrés ailleurs. Mais on a en tête que c'est une chose à laquelle on va devoir consacrer plus de temps ensuite ! Et on a hâte d'avoir les moyens de le faire.
Yaal Coop n'a même pas un an, on n'est qu'au début de l'aventure et de l'expérimentation ! 🌱
Et Yaal SAS alors ?
Je suis sans doute mal placée pour parler de Yaal SAS car je n'en fais plus partie. Son activité est aujourd'hui en sommeil, il n'y a d'ailleurs plus aucun salarié : seulement 9 associé.es dispersés entre Yaal Coop, Sinch, La Brasserie du Sabot et d'autres projets personnels. Dispersés mais pas bien loin, alors rendez-vous à la prochaine bière ! 🍻
*Oui Trello. L'outil détonne au milieu des autres outils libres qu'on utilise et dont on est plus friand. Mais pour l'instant on n'a pas trouvé d'alternative cool et aussi pratique pour la gestion de projet donc on fait avec 🙂 (vous utilisez quoi vous ?)
Le Bitcoin est une monnaie cryptographique dont la validation des transactions est faite par une preuve de travail. La preuve de travail consiste à trouver un condensat (hash) commençant par un certain nombre de zéros.
Nombre de zéro au début du hash d’une transaction
Un hash de transaction (Transaction Hash ID) ressemble, par exemple, à 000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f. Dans ce cas, 10 zéros débutent le hash.
Plus le nombre de zéro exigé est élevé, plus il est difficile de trouver une solution. Ce nombre évolue au fil du temps : si une solution est trouvée rapidement, le nombre de zéro augmente pour les transactions suivantes (et inversement).
Évolution jusqu’à aujourd’hui
En bleu, les statistiques de l’ensemble des transactions contenues dans la chaîne. En orange, la moyenne des transactions de chaque journée. Les points noirs représentent les moyennes mensuelles.
La difficulté est croissante, avec parfois des plateaux. Cela montre indirectement l’augmentation de la puissance de calcul au fil du temps (le nombre de machines minant augmente, les processeurs sont plus performants, etc.).
Cela mesure encore plus imparfaitement la pollution générée par l’utilisation :
d’énergies renouvelables : à une période où le prix du Bitcoin était faible, une stratégie de minimisation des coûts a poussé certains à se limiter à la consommation d’excédents d’énergie hydroélectrique ou éolienne.
Il est possible de voir les informations d’une transaction sur des services web mais autant extraire les informations à partir de la chaîne Bitcoin avec le client grâce à un script shell suivant :
#! /bin/sh
MAX_BLOCK=$(./bin/bitcoin-cli getblockcount)
for i in $(seq 1 $MAX_BLOCK); do {
HASH=$(./bin/bitcoin-cli getblockhash $i)
./bin/bitcoin-cli getblock $HASH | jq '[.time, .hash] | @csv' | sed 's/[\"]//g' >> stats_brutes.csv
}
done
Le script nécessite que la chaîne complète soit disponible sur la machine. La chaîne consomme presque 400 Go d’espace disque. La version du client et serveur était la 0.21.1.
Les commandes du binaire bitcoin-cli sont documentées sur https://developer.bitcoin.org/reference/rpc/index.html.
La production des statistiques au format .csv est très loooongue car le client bitcoin met du temps à répondre.
Une fois les données extraites au format .csv, un script python utilise la bibliothèque matplotlib pour produire le graphique :
import csv
import datetime
import time
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import numpy as np
def draw_graph(csv_path):
SIZE = 0.5
stats_completes, stats_quotidiennes, stats_mensuelles = stats(csv_path)
fig, ax = plt.subplots()
ax.plot_date(stats_completes["x"], stats_completes["y"], markersize=SIZE, label="Tous", color="blue")
ax.plot_date(stats_quotidiennes["x"], stats_quotidiennes["y"], markersize=SIZE*2, label="Quotidien", color="orangered")
ax.plot_date(stats_mensuelles["x"], stats_mensuelles["y"], markersize=SIZE*2, label="Mensuel", color="black")
fmt_year = mdates.YearLocator()
ax.xaxis.set_major_locator(fmt_year)
fmt_month = mdates.MonthLocator()
ax.xaxis.set_minor_locator(fmt_month)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.fmt_xdata = mdates.DateFormatter('%Y-%m-%d %H:%M:%S')
fig.autofmt_xdate()
ax.grid(True)
plt.xlabel("Temps")
plt.ylabel("Nombre de zéros")
plt.legend(loc="upper left", markerscale=4)
plt.savefig("./graph_bitcoin_zeros.png", dpi=150)
def stats(path):
x_toutes, y_toutes = [], []
with open(path, newline='') as csv_file:
stats_reader = csv.reader(csv_file)
for ligne in stats_reader:
date = _from_timestamp(ligne[0])
nb_zeros = _nb_zeros(ligne[1])
x_toutes.append(date)
y_toutes.append(nb_zeros)
stats_quotidiennes = _stats_quotidiennes(x_toutes, y_toutes)
stats_mensuelles = _stats_mensuelles(x_toutes, y_toutes)
return {"x": x_toutes, "y": y_toutes}, stats_quotidiennes, stats_mensuelles
def _stats_quotidiennes(x_toutes, y_toutes):
dates_possibles = set([(date.year, date.month, date.day) for date in x_toutes])
stats_quot = {date: [] for date in dates_possibles}
for index, x in enumerate(x_toutes):
stats_quot[x.year, x.month, x.day].append(y_toutes[index])
x, y = [], []
for mois in sorted(dates_possibles):
x.append(datetime.datetime(mois[0], mois[1], mois[2]))
y.append(_moyenne(stats_quot[mois]))
return {"x": x, "y": y}
def _stats_mensuelles(x_toutes, y_toutes):
dates_possibles = set([(date.year, date.month) for date in x_toutes])
stats_mois = {date: [] for date in dates_possibles}
for index, x in enumerate(x_toutes):
stats_mois[x.year, x.month].append(y_toutes[index])
x, y = [], []
for date in sorted(dates_possibles):
x.append(datetime.datetime(date[0], date[1], 15))
y.append(_moyenne(stats_mois[date]))
return {"x": x, "y": y}
def _moyenne(valeurs):
return sum(valeurs) / len(valeurs)
def _from_timestamp(data):
return datetime.datetime.fromtimestamp(int(data))
def _nb_zeros(data):
count = 0
for lettre in data:
if lettre == "0":
count += 1
else:
return count
if __name__ == "__main__":
draw_graph("stats_brutes.csv")
Le script python utilise un type de graphique idéal pour le besoin, déjà inclus dans Matplotlib.
3 de nos experts Data partagent leur vision sur leur métier respectif et l’écosystème Data. Ils présentent différentes technologies dont Python et Scala.
L’erreur est maintenant affichée à la ligne de début du problème, et non plus lorsque l’interpréteur n’y comprend plus rien, l’exemple le plus marquant étant avec l’oubli d’une parenthèse fermante, ou d’une mauvaise indentation
Les messages ont été corrigés de manière à ce qu’ils soient plus clairs, avec des suggestions très utiles qui correspondent souvent à l’erreur
Le match/case
Le match/case de Python est similaire à l’instruction switch/case, qui est reconnue comme un « pattern matching structurel » en Python.
Le match/case de Python se compose de trois entités principales :
Le mot-clé match
Une ou plusieurs clauses case
Du code pour chaque case
Là où Python se démarque des autres langages, c’est que l’on peut faire un match sur des patterns !
Exemples de match, du plus simple au plus avancé :
Match très simple, avec le « or »
exemple = True
match exemple:
case (True|False):
print("C'est un booléen")
case _ :
print("Ce n'est pas un booléen")
Récupérer les sous-patterns
def alarm(item):
match item:
case [time, action]:
print(f"{time} ! C'est l'heure de {action}!")
case [time, *actions]:
print(f'{time} !')
for action in actions:
print(f"C'est l'heure {action}!")
alarm(['Bon après-midi', 'de travailler'])
alarm(['Bonjour', 'du petit déjeuner', 'se laver les dents'])
Nommer les sous-patterns
def alarme(item):
match item:
case [('bonjour' | 'bonsoir') as time, action]:
print(f"{time.title()} ! Il faudrait {action} !")
case _:
print('Mot-clé invalide.')
alarme(['bonsoir', 'travailler'])
alarme(['bonjour', 'petit déjeuner', 'se laver les dents'])
Nommer les sous-patterns et filtres conditionnels
def alarme(item):
match item:
case ['bonsoir', action] if action not in ['travailler']:
print(f'Journée finie ! Il faut {action}!')
case ['bonsoir', _]:
print('Il faut se reposer !')
case [time, *action]:
print(f'{time.title()}! Il faut {" et ".join(action)}.')
case _:
print('Mot-clé invalide.')
alarme(['bonsoir', 'travailler'])
alarme(['bonsoir', 'jouer'])
alarme(['bonjour', 'petit déjeuner', 'se laver les dents'])
Match sur des objets
class Move:
def __init__(self, horizontal=None, vertical=None):
self.horizontal = horizontal
self.vertical = vertical
def str_move(move):
match move:
case Move(horizontal='est', vertical='nord'):
print('Dir. nord-est')
case Move(horizontal='est', vertical='sud'):
print('Dir. sud-est')
case Move(horizontal='ouest', vertical='nord'):
print('Dir. nord-ouest')
case Move(horizontal='ouest', vertical='sud'):
print('Dir. sud ouest')
case Move(horizontal=None):
print(f'Dir. {move.vertical}')
case Move(vertical=None):
print(f'Dir. {move.horizontal}')
case _:
print('? Move inconnu ?')
d1 = Move('est', 'sud')
d2 = Move(vertical='nord')
d3 = Move('centre', 'centre')
str_move(d1)
str_move(d2)
str_move(d3)
Nubla, c'est un projet de service pour fournir des e-mails, de l'espace de stockage Cloud, de messagerie instantanée et d'agenda pour tous⋅tes, sans passer sous le giron de Google et des géants du web.
On veut passer par des solutions libres, mises à disposition à des frais qui varient selon les moyens de nos utilisateurs. Ca, on y tient. C'est un souhait aussi depuis le début, s'adapter et faire un service qui puisse profiter à un maximum de monde, sans vente de données, sans fins publicitaires et sur mesure.
☁️
Design et création d'un nuage, Nubla.io ☁️
Ma priorité sur le site de Nubla, c'est de faire un site internet fonctionnel, accessible et lisible. Et quand je dis accessible, c'est au sens de l'accessibilité à tous⋅tes : Choix de polices d'écriture intelligibles, contrastes suffisants, hiérarchisation des contenus et facilité de navigation.
La seconde, c'est de créer quelque chose qui me fasse plaisir à imaginer, à dessiner, puis à intégrer.
Utiliser des outils et des techniques qui me plaisent : coolors pour le choix des palettes de couleur, me tourner vers des polices d'écriture libres, des illustrations open source aussi avec undraw, l'utilisation de CSS Grid pour l'intégration...
Premières pistes
Quand j'ai proposé au vote les différentes palettes à l'équipe, on s'en est sortis avec une égalité retentissante.
Le point commun entre toutes : Elles sont colorées. Vraiment.
Dans mes préférences, j'aimerais garder au moins une palette qui contient du jaune pour faire une petite référence discrète à Yaal Coop.
Parmi les autres couleurs, je tiens généralement à utiliser un noir qui n'est pas parfaitement noir, et un blanc pas parfaitement blanc. Juste pour ne pas trop agresser la rétine, je trouve ça plus doux. Ici, #323232 fait office de noir, et #F4F4F4 fait office de blanc.
Les fonts testées ici sont :
Jost - Une police d'écriture libre, adaptée à la technologie variable font d'OpenType, reproduisant l'esprit de la légendaire Futura.
Varela Round - Une police d'écriture ronde, sympathique, créée par le designer Joe Prince.
J'ai finalement opté pour Jost, du fait de sa grande polyvalence, mais également pour son aspect géométrique et lisible qui viendra contraster avec les motifs décoratifs plutôt ronds du site (les fameux blobs).
Côté formes, décoratives, j'ai testé le géométrique et l'anguleux, mais pour un projet cloud avec une face amicale/familiale, je lui ai préféré les courbes et les "blobs" arrondis. La police d'écriture choisie elle-même déjà tout en angles et en pointes créée un contraste et une dynamique amusants.
Wireframes
Sur la sturcture du site, j'avais très envie de travailler avec CSS Grid Je suis partie sur une structure de cinq colonnes, chacune séparée d'une gouttière de 20px, la première et la dernière colonne restant "vides" pour aérer le site. Je met vides entre guillemets, parce que c'est dans la colonne de droite que j'ai prévu de poser la navigation, fixée en haut à droite de l'écran pour rester toujours visible.
Déclinaison de maquettes
Les maquettes ci-dessous ne sont pas finales, mais sont là pour donner une idée assez claire des différents layouts qui seront mis en place sur le site et du rendu qu'on pourra obtenir.
Je suis pas vraiment adepte des maquettes pixel perfect (je vais pas m'étaler là dessus), d'autant plus lorsque je ne suis pas seul responsable des contenus du site. Je préfère poser une base, voir quels contenus sont proposés puis m'y adapter en respectant l'esprit et les déclinaisons de layouts choisis pour le site.
Pourquoi le cadre ? Jeu sur la structure du site, évite la sensation de "flottement" des éléments dans le vide. Peut aussi permettre des jeux de parallaxe.
Jouer avec le scroll à l'intérieur du cadre, avec la navigation fixe, je trouve ça assez marrant.
☁️
Le Site
Structure du site :
Le body, sur lequel je place le blob de fond.
Un conteneur, celui qui a le cadre noir et un padding qui laisse la place pour la scrollbar à droite et les notes de pied de page en bas
Un layout en grille CSS de 5 colonnes, séparées par des gouttières de 20px.
La navigation, qui semble posée sur la 5eme colonne mais est en réalitée positionnée en position:fixed; pour ne pas bouger d'un pouce lorsque l'on navigue sur la page.
Les petits détails qui font plaiz
... ou comment faire l'effet de soulignement dynamique des liens :
Ce serait dommage de se priver de ce genre de petites choses ! Ca me fait expérimenter un peu, et puis c'est toujours amusant à voir. Bien sûr, dans un souci d'accessibilité, les animations se déclenchent aussi lorsqu'un élément est placé en [focus] et pas seulement au survol de la souris.
☁️
Et voilà !
Vous voulez voir ce que ça donne en vrai ? C'est par là : 👉 https://nubla.io 👈
Et n'hésitez pas à faire un tour sur notre sondage concernant vos usages e-mail, cloud et internet, et savoir si l'offre de Nubla pourrait vous intéresser !
Python supporte désormais le type hints. Dans cet article, nous allons voir comment avoir de l’IntelliSense pour le typage ainsi qu’avoir les erreurs de typage sur Visual Studio Code.
Ajout d'un lexeur à Pygments pour le format Procfile. Les fichiers Procfile sont utilisés par des hébergeurs comme Heroku mais ils servent aussi pour des développements locaux (avec Foreman ou Honcho).
Le framework Django regorge de nombreux filtres et balises qu’il est possible d’utiliser directement dans un fichier HTML. Dans cette vidéo je vous présente 6 balises et filtres peu connus de Django qui vont vous permettre d’optimiser vos fichiers de templates.
Dans cette vidéo, je vais vous montrer comment utiliser le package django-tailwind pour utiliser Tailwind CSS à l’intérieur d’un projet Django.📖 L’article d…
Dans cette vidéo je vous explique quelques termes importants que vous retrouverez dans votre apprentissage de Python et notamment ceux qui ne sont pas toujou…
Python 3.10 (rc1) est sorti le 2 août 2021, après quinze mois de développement (dont cinq à cheval sur les bêta et les rc de Python 3.9). Il reste deux mois avec des candidats (RC) avant la sortie définitive, prévue le 4 octobre 2021.
Voyons ce que cette version apporte comme nouveautés…
Les annotations de type est une nouveauté de Python 3.5 qui est de plus en plus utilisée par les développeurs Python.Vous allez voir que cela a beaucoup d’av…
Manifeste pour le développement Agile de logiciels
Nous découvrons comment mieux développer des logiciels par la pratique
et en aidant les autres à le faire. Ces expériences nous ont amenés à
valoriser :
Les individus et leurs interactions plus que les processus et les outils
Des logiciels opérationnels plus qu’une documentation exhaustive
La collaboration avec les clients plus que la négociation contractuelle
L’adaptation au changement plus que le suivi d’un plan
Nous reconnaissons la valeur des seconds éléments, mais privilégions les premiers.
Notez que la comparaison “les individus et les interactions plus que processus et les outils” est en premier.
Comme le reste de l’article s’appuie sur ce concept je vous propose de le nommer “Principe d’Humanité” ci-dessous pour plus de lisibilité.
D’un autre côté “réagir au changement plus que suivre un plan” est en dernier et c’est pourtant la phrase qui donne son titre au manifeste - l’adjectif “agile” a été choisi pour s’y référer. Par conséquent, c’est la partie “réagir au changement” que l’on retient le plus, alors que le Principe d’Humanité est beaucoup moins connu.
Explorons ensemble ce paradoxe, en se replongeant dans l’effet du confinement en entreprise.
Du jour au lendemain, tous les salariés de la société ont été obligés de travailler depuis leur domicile. Les réactions de chaque personne ont été très différentes, entre :
Celles qui préfèrent tout simplement ne plus avoir à venir au bureau - pour un tas de raisons diverses (temps de trajet, peur de contaminer des proches, envie de passer du temps avec ses enfants, etc …)
Celles qui tolèrent mal le confinement - également pour des raisons diverses (besoin de socialiser avec les autres salariés, pas les bonnes conditions matérielles chez elles, etc …)
Celles qui ne le tolèrent pas du tout et cessent de travailler (cela peut aller de la simple perte de motivation en passant par la démission ou la dépression nerveuse)
Sans oublier les personnes qui pratiquaient le télétravail depuis déjà longtemps, ou celles qui ont simplement changé d’emploi
Nous voyons ici que la bonne façon d’aborder le problème du confinement doit nécessairement prendre en compte les individus au sens fort - c’est-à-dire pas seulement les personnes une par une, mais des personne singulières - dotées de personnalités propres.
Le confinement au niveau des interactions entre individus #
D’un autre côté, les conditions matérielles des interactions entre individus ont radicalement changé.
Prenons par exemple le cas d’une conversation entre deux personnes (je laisse de côté
les réunions à plusieurs qui mériteraient un article à part).
Voici une liste non-exhaustive des différentes façons dont une conversation de travail peut avoir lieu si les deux collègues sont face à face :
de part à et d’autre d’un bureau pour un conversation “officielle”
entre deux portes - par exemple juste avant ou juste après une réunion
autour de la machine à café pour parler de la météo
autour d’un verre dans un bar en fin d’après-midi pour décompresser après le boulot
à la table d’un restaurant le midi pour une réunion commerciale
etc.
Voici une liste exhaustive des différentes façons dont une conversation peut avoir lieu si les deux personnes ne sont /pas/ face à face :
voix seulement (téléphone)
texte seulement (SMS ou messagerie instantanée)
vidéo-conférence (audio et vidéo - avec messagerie instantanée incluse ou non)
Et c’est à peu près tout ce que la technique permet aujourd’hui - qu’on le veuille ou non !
Ainsi, la question posée par le confinement en entreprise peut être formulée ainsi : comment reproduire toute la richesse permise par les discussions face à face ?
Notez que cette question n’est ni problème technique, ni un problème financier, ni un problème de processus, mais bien d’interactions entre individus …
L’impact du confinement sur une entreprise fonctionnant sans le Principe d’Humanité #
La thèse que je veux défendre est celle-ci : si l’entreprise dans son ensemble a oublié l’importance des individus et de leurs interactions, elle n’a aucun bon moyen de gérer correctement la question du confinement !
De fait, elle va naturellement ignorer le problème principal et s’occuper à la place des problèmes qu’elle sait déjà gérer, c’est à dire les problèmes pour lesquels il existe déjà un processus.
Par exemple la perte de clients, les problèmes d’approvisionnement etc. liés au confinement sont des soucis financiers ou logistiques pour lesquelles les solutions sont connues.
Au final, les problèmes liés véritablement au confinement vont être perçus comme des problèmes “d’organisation du travail”.
Ainsi, en supposant que l’entreprise survive, elle risque de prendre des décisions qui n’adressent pas vraiment la question, comme “mettre en place un nouveau processus de travail” (phrase floue si l’en est) - en s’inspirant de processus déjà existants comme SAfe, SCRUM, ou OKR pour ne citer que les plus connus.
À l’extrême, l’entreprise va économiser sur le prix de l’immobilier en optant pour des locaux plus petits (ou pas de locaux du tout) et compenser de la sorte le manque de productivité de la “masse salariale” …
L’impact du confinement sur une organisation fonctionnant suivant le Principe d’Humanité #
La question posée par le confinement reste compliquée, bien sûr, mais au moins ce n’est pas un problème différent en nature de ceux que l’organisation sait déjà traiter.
Et en tout cas, une entreprise suivant le Principe d’Humanité aura de bien meilleures chances de gérer correctement la fin du confinement.
Conclusion et retour sur l’agilité en entreprise #
Réduire la question du confinement à “il faut trouver un moyen technique de travailler à distance”, et simplement investir dans la visioconférence et des outils collaboratifs en ligne, est, je pense, manquer l’essentiel.
Au passage, c’est aussi ignorer que l’Humanité a déjà connu dans l’histoire des conditions similaires au confinement - typiquement, un couvre-feu pendant la guerre.
J’espère vous avoir convaincu maintenant que le dernier principe agile (réagir au changement) découle en fait du premier.
En effet, les entreprises qui valorisaient les individus et leurs interactions par-dessus le le reste ont probablement pu réagir au changement qu’était le confinement bien mieux que les autres sans nécessairement avoir besoin de faire de plan - ce qui de toutes façons était très compliqué (souvenez-vous de votre propre état mental lors du premier confinement).
En réalité, les entreprises qui ont oublié le Principe d’Humanité sont finalement fort peu capables de réagir à des changements non prévus et sont finalement … peu agiles.
D’ailleurs, la seule chose qui ne changera probablement jamais dans une entreprise, c’est que c’est un ensemble complexe et mouvant d’individus et d’interactions …
La notion de secret Reprenons quelques bases. En matière d'authentification, un mot de passe c'est avant tout un secret ("ce que je sais"). Le concept d'un secret, qu'il faut le garder bien au chaud, sinon, ce n'est plus vraiment un secret. On évite par exemple de coller le Post-it avec son mot de passe sur son front pour se balader dans la rue ("ce que je suis" : dans ce cas, on parle au mieux d'identification et non d'authentification). Certains le font, ils appellent ça la "sécurité biométrique", ou "identification biométrique", mais globalement, c'est surtout du marketing et on sait que c'est au mieux un complément pour une authentification à double facteur (2FA), mais certainement pas la panacée comme secret "unique" pour confier des privilèges. Dois-je partager un secret ? Les gestionnaires de mots de passe actuels répondent cependant généralement à ces 4 besoins : Générer, centraliser, chiffrer... et partager. La notion de partage de mot de passe est "contre-nature", mais elle demeure un besoin des organisations. Cette pratique bien que dérangeante "by design" est donc une réalité. S'il faut impérativement le faire, autant le faire correctement. Et correctement, ça commence par partager uniquement ce qui doit l'être en offrant la surface d'attaque la plus réduite possible. La tendance sécuritaire actuelle, c'est l'approche ZeroTrust. Pour forcer un peu le trait, on pourrait expliquer cette philosophie par "ne faites pas confiance aux gens, et encore moins à leurs devices". La logique est d'accorder les permissions les plus faibles possibles, toujours dans un but de réduction de la surface d'attaque. Dans ces conditions, on ne peut être qu'un peu dubitutatif quand on découvre des gestionnaires de passwords en mode web, multipliant les connecteurs et les API, centralisant au milieu du web des secrets que l'on destine à être partagés. Ça peut vite donner des sueurs froides à n'importe quel RSSI. Gérer un trousseau, ce n'est pas comme bidouiller sa page perso, il est possible de se rater, comme Kaspersky, et l'impact est tout de suite à considérer comme critique sur une organisation (ou des particuliers). Les chiens aboient et les ours Syspass... leur tour S'il faut bien reconnaître que l'interface de Syspass est très aboutie et le site de présentation très bien fait , qu'en est-il vraiment à l'usage ? Niveau contexte, Syspass est le projet d'une personne, en mode "très stable" depuis 2 ans. Du LAMP très classique, avec toutes les possibilités d'inteprétation offertes par PHP, avec même une abstraction qui va gérer la sécurité, avec phpseclib qui va se débrouiller avec ce qui traine sur la machine (openssl, ou bien GMP, ou bien tout en PHP). En déployant l'application, nous avons pu analyser son architecture et son fonctionnement et avons constaté :
que l'architecture ne correspond pas à l'état de l'art ; que l'UX encourage des risques de mauvaise utilisation.
Limites de l'architecture Pour ne pas avoir à configurer le serveur http et l'hôte, l'éditeur a confié trop de tâches à PHP, comme la gestion des assets compilés. Le code s'avère très complexe à auditer, car il semble avoir été écrit pour un environnement spécifique, en utilisant des variables de contexte non standard. Il n'est pas possible de configurer à froid le service :
Le fichier de configuration est signé, ce qui empèche sa modification depuis l'éxterieur, c'est un état, complémentaire à la base de données La seule possibilité est de configurer depuis l'interface web, lors de la première connexion.
Cette combinaison est dangereuse. L'organisation des dossiers est peu claire, pouvant rendre trop facile l'exposition de données critiques. Limite et dangers UX Doublon, complexité de suivi, des risques très importants :
Notamment si l'équipe dispose d'autres outils comme Gitlab, il risque d'y avoir des données à saisir en doublon dans plusieurs outils Dans ce contexte, avoir une gestion d'utilisateurs et de projets, en dehors de sa gestion de code (Gitlab) demandera une énorme rigueur et la tentation de partager un compte, ou de faire des actions en root sera énorme.
Conclusions et recommandations Notre conseil est de favoriser les comptes individuels, les accés temporaires, et globalement de ne pas exposer aux développeurs les mots de passe, qui doivent faire partie du provisioning, et du déploiement. On observe scrupuleusement la politique de la plus faible permission possible et une définition des rôles attribuant les privilèges strictement nécessaires. Pour des paramétrages spécifiques à un projet, il est plus efficace d'utiliser un trousseau chiffré avec la clef GPG des utilisateurs, et de le versionner avec les sources du projet, ou d'utiliser les variables protégées de Gitlab. Pour passer à un niveau supérieur de sécurité, il faut s'orienter vers des solutions comme Hashicorp Vault, avec son code audité, qui propose un workflow rigoureux, et une intégration propre à Gitlab. Il faut aussi surveiller vaultwarden, un élégant clone de Bitwarden codé avec le mythique Rust (plutôt que l'éxotique C# de l'original). Sortez couvert.
Dans cette vidéo, je vous montre un exemple un peu plus concret de l’utilisation de la toute nouvelle API de Notion pour publier des annonces sur le serveur …
WD Elements Play était un boîtier multimédia vendu par Western Digital à partir des années 2010. Apparemment c’était un système assez limité dès sa sortie. Il semble que Western Digital ait simplement utilisé une conception faite chez Amlogic, en y incluant sa propre production de disque dur.
Composants
Le démontage du boîtier est aisé : il faut retourner le boîtier et déclipser le fond à l’aide d’un tournevis plat. Le disque dur se retire directement en le reculant pour le déconnecter du connecteur SATA, puis un deuxième cran pour pouvoir le sortir du boîtier. Une vidéo youtube faite par quelqu’un d’autre montre ce processus.
La carte qui fait l’intermédiaire entre les Entrées/Sorties et le disque dur est basée sur une puce Amlogic AML8626-H aux spécifications mystérieuses.
Le disque dur est au format 3,5 pouces et d’une taille de 1To. Sur le côté du disque, on peut voir les vis, chacune avec une pièce en caoutchouc pour retenir le disque dans le boîtier.
Quel format pour le disque ?
Étant donné qu’il s’agit d’un disque standard, il suffit de le brancher sur une machine quelconque pour le détecter (ici sur /dev/sdb) :
# fdisk -l
[...]
Disk /dev/sdb: 931,51 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: WDC WD10EADS-11M
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: dos
Disk identifier: 0x9a6027cc
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 1953521663 1953519616 931,5G 27 Hidden NTFS WinRE
Parted est d’accord avec fdisk :
# parted -l
[...]
Model: ATA WDC WD10EADS-11M (scsi)
Disk /dev/sdb: 1000GB
Sector size (logical/physical): 512B/4096B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 1000GB 1000GB primary ntfs msftres
L’équivalent graphique avec gparted
Il y a donc une partition unique, au format Microsoft NTFS. L’intérêt est probablement d’avoir un format reconnu nativement par des machines Windows car il est possible de brancher le boîtier en USB pour le relier à un ordinateur.
Regarder le contenu du disque est trivial :
# mkdir /tmp/ntfs
# mount -t ntfs /dev/sdb1 /tmp/ntfs
ls /tmp/ntfs montre des fichiers comme la corbeille (RECYCLER), un répertoire autorun et un fichier autorun.inf (probablement utilisé lors du branchement en USB du boîtier sur un système Windows), un répertoire System Volume Information avec un point de restauration (peut-être pour une réinitialisation usine?) et un répertoire fourni par WD contenant un peu de documentation au format pdf. Bien évidemment, on y retrouve aussi les fichiers déposés par l’utilisateur.
Les versions des logiciels qui n’auront pas été maltraités malgré une partition NTFS:
Dans cette formation de 2h je vais te montrer toutes les bases du framework Django avec la création d’un site web complet.👨💻 Apprends Python● https://www….
Oauth2 est la norme Oauth2 fait partie des standards industriels qui simplifient grandement l'utilisation du web. OAuth2 permet de gérer les autorisations pour un grand nombre d'appareils connectés à Internet, à partir d'une identification unique sur un site de confiance. Partager et divulguer un mot de passe au sein d'une équipe qui bouge n'est pas une bonne pratique, de la même manière que centraliser l'authentification sur un LDAP (so 90's) ce n’est pas efficient avec les trousseaux des navigateurs webs. Oauth2 comme tout bon acronyme amène avec lui d'autres chouettes acronymes, comme OpenID et JWT. Oauth2 permet d'utiliser divers services et sites web en se loguant une seul fois, sans avoir à créer des comptes un peu partout et de maintenir à jour les informations personnelles. OAuth2 spécifie bien le dialogue entre le fournisseur et le client, le jeton généré par le fournisseur pour le client est spécifié par JWT (Json Web Token), par contre, les données métiers contenues dans ce jeton sont plus libres. OIDC (OpenID) normalise une partie de ces informations, mais les groupes OIDC sont très vagues, et les fournisseurs OAuth2 vont donc fournir des informations spécifiques, qui nécessiteront une adaptation coté client.
Fournisseurs Il existe une multitude de fournisseurs OAuth2, comme Google, Facebook et autres mammouths de l'Internet, mais dans notre cas, chez Bearstech, notre fournisseurs OAuth2 favori est l'inégalable Gitlab. Clients Oauth2 est un standard très utilisé. Il est intégré à différents services comme Sentry ou Grafana. La majorité des langages dispose de la bibliothèque qui va bien, voir même des intégrations spécifiques à différents frameworks. On l'a testé IRL avec du Golang et du Python, avec des bibliothèques matures, agréables à utiliser. Ce qui est moins agréable, c'est que le fournisseur doit pouvoir causer avec le site client, ce qui complique le travail en local. Cela reste possible avec des fournisseurs simples à déployer comme Keycloak. L'autre défi avec OAuth2, c’est que ça parle de sécurité. Et quand on cause sécurité, on a tout de suite la pression de faire une vraie connerie, avec de vraies conséquences, pas juste une erreur 500 tout juste humiliante. Il est possible d'utiliser OAuth2 sans coder, avec un produit incontournable comme OAuth2-proxy. Avec ce genre de produit, vous externalisez les contraintes de mises à jour et autres bonnes pratiques de votre application. OAuth2-proxy OAuth2-proxy, initié par Bitly, puis forké et maintenu par une équipe communautaire, peut se placer à coté de votre serveur web (Nginx avec auth_request, Traefik avec ForwardAuth, HAproxy avec haproxy-auth-request…), votre serveur garde la main sur le flot HTTP, ou comme proxy HTTP (il sait même gérer du SSL et servir des fichiers statiques). OAuth2-Proxy permet de définir des règles fines pour établir une autorisation, comme l'appartenance à un groupe, une liste d'emails, un domaine de mail, organisation/équipe/projet/utilisateur Github, groupe/projet Gitlab, groupe OIDC… OAuth2-Proxy sait gérer ses sessions, ou les confier à Redis (avec même l'option Sentinel pour les clusters) pour pouvoir intervenir sur le service sans couper les sessions. OAuth2-Proxy est cité comme référence dans pas mal de documentations, comme celle de Kubernetes. Nos contributions La mise en application de nos valeurs passe également par des contributions au code des applications et outils que nous utilisons au quotidien. En voulant utiliser OAuth2-proxy, le constat a été simple : le produit sait faire plein de trucs avec Github, mais peu avec Gitlab. La notion de groupe qu'aime bien OIDC n'est pas primordiale dans Gitlab, et surtout protéger un site pour que seules les personnes participant au projet puissent y accéder tombe sous le sens. Notre premier travail à été d'ajouter la notion de filtrage par projet Gitlab à Oauth2-proxy, pour notre service Factory.
Au-delà de la technique, les contributions à des projets open source s'inscrivent dans un échange humain avec les contributeurs et des enjeux de maintenabilité et lisibilité du code. Depuis quelques années maintenant, la suite de tests unitaires pour valider le comportement de la fonctionnalité s'ajoute à l'ensemble. Même si les langages tendent vers une normalisation du formatage (espaces vs tabulations, retour à la ligne etc.) les choix d'organisation du code ou des frameworks de tests restent hétérogènes et l'adaptation aux règles du projet (tacites ou explicites) est à la charge du contributeur. Sur des projets de l'envergure d'OAuth2-proxy, une fois la fonctionnalité livrée, le code sera rapidement utilisé. C'est à ce moment là que démarre la partie maintenant moyen et long terme qui comprends aussi bien du support utilisateur, de la correction de bug et de l'évolution de code
Ces contributions sont essentielles et permettent aux logiciels libres d'avancer à grande vitesse en s'adaptant directement aux besoins des utilisateurs. Pour les développeurs, elles permettent d'appronfondir les connaissances tout en facilitant les échanges avec des pairs dans un objectif d'amélioration continue de l'humain et du logiciel. Ces contributions sont essentielles et permettent aux logiciels libres d'avancer à grande vitesse en s'adaptant directement aux besoins des utilisateurs. Pour les développeurs, elles permettent d'approfondir les connaissances tout en facilitant les échanges avec des pairs dans un objectif d'amélioration continue de l'humain et du logiciel.
Crédit photo : Wikimedia : Pont des arts avec cadenas
Aujourd'hui nous inaugurons l'ouverture de notre Discord pour nous rapprocher encore plus de notre communauté ! Rejoignez-nous sur https://afpy.org/discord pour être tenu au courant de l'actualité et discuter avec nous. 🐍
Dans cette vidéo, je vous montre toutes les bases de la data science avec Python et la bibliothèque pandas. Lecture d’un fichier CSV, analyse des données, aj…
Bonjour à tous ! On continue les meetups mensuels « en attendant la PyConFR » et ce mois-ci ça sera le 14 juin à 18h ! Comme d'hab', venez nombreux et n'hésitez pas à faire un tour sur notre Discuss pour proposer des sujets ! https://discuss.afpy.org/t/en-attendant-la-pyconfr-du-14-juin-2021/303 🐍
NB : excepté lorsqu’on se connecte, et se déconnecte, une seule page = aucun rechargement.
C’est totalement différent du projet que vous avez appris/fait en Php cette année.
Comment le rendre
Faites un fichier README.txt et déposez-le ici
Dans le fichier README.txt, précisez :
le sujet choisi
l’adresse de votre site
un nom d’utilisateur
un mot de passe
(et plusieurs nom/mot de passe, s’il y a plusieurs niveaux de droits (administrateur/visiteur etc.))
si vous avez utilisé des librairies spécifiques que je vous ai autorisées, merci de le re-préciser
Sujet
Ce que vous voulez tant que c’est dans le cadre de ce que l’on a vu. Vous avez tout le Web comme inspiration ! N’oubliez pas de me donner le nom et le mot de passe pour se connecter ! Si vous gérez des profils différents (admin / user ou autre), donnez moi les noms et mots de passe de différents profils !
Fonctionnalités obligatoires
Connexion + déconnexion (vu en cours)
Effets jQuery sur les éléments
Appels JSON : au moins deux appels en plus de ceux vus en cours
Sujets possibles
Site de partage de photos
Site de cocktails (cf ci-dessus)
e-rated : site d’appréciations (selon des sujets, à définir)
Ask-a-question : site où l’on pose des questions sur des sujets divers, et des gens répondent
Write-a-book-together : site où l’on se connecte et où on peut écrire un livre à plusieurs
Wedding-couple-site : site où l’on uploade + partage des photos de mariage + livre de commandes
Playing-cards-collection : site où on scanne + échange des cartes (Magic the gathering)
Polls-and-surveys : site de création de sondages (= QCM, exemple très beau ici : quipoquiz)
Poems-generator : faire un cadavre exquis qui génère des poèmes + possibilité pour les utilisateurs de les noter / d’ajouter des mots
The-future-of-post-it : faire un carnet de choses à faire pour les utilisateurs, qui envoie des mails de rappels de ces choses à des dates données
Gift-ideas : un site où l’on va faire des idées de cadeaux / suggérer des idées de cadeaux + les noter (les meilleurs ressortent en premier)
Le-bon-recoin : refaire le bon coin en plus simple
Suggest-crawlers : site de suggestions : on clique sur un mot, il en suggère plein d’autres avec + définitions / liens de sites pour chacuns
Tv-fans : site de présentations + notes d’émissions télé
Faire le jeu SokoBan vu en cours, avec la possibilité de login, enregistrement. Pour les appels JSON supplémentaires, lorsque l’utilisateur choisit un tableau, s’en souvenir (= AJAX) et lorsqu’il se reconnecte, le remettre directement. Puis enregistrer son score lorsqu’il a terminé un niveau + montrer les meilleurs scores.
Pour les sujets qui suivent, ils sont possibles mais plutôt complexes et demandent plus d’investissement. Si vous êtes motivés, demandez-moi plus d’informations, je vous expliquerai les difficultés que vous allez rencontrer.
Turn-by-turn : faire un jeu multijoueurs en tour par tour (jeu de cartes, de poker, ou de plateau etc)
Chat-with-someone : site de chat/discussion
A-maze-ing : site où l’on peut se ballader dans un labyrinthe et essayer d’en trouver la sortie
Sujet imposé si vous n’avez pas d’idée
Cocktails : on se connecte, on a une liste d’éléments (récupérés en JSON) disponibles, on coche ceux qui nous intéressent, on valide, c’est envoyé, et le retour en JSON affiche les cocktails qu’il est possible de faire avec ce que l’on a coché.
Note pour ceux qui connaissent / font / du React : la librairie est autorisée, mais il me faut le code d’origine, et non pas le code minifié / de production.
Interdiction d’utiliser une librairie JavaScript qui ne vienne pas des sites autorisés précédemment
Retard
Après le dimanche 11 avril minuit
Passé ce délai ce sera 1 pt par 2 heures de retard (je prendrai en compte la date de réception du mail).
Pour ceux qui essaient vraiment d’aller jusqu’à la dernière minute, toute heure entamée est comptée comme une heure complète. Exemple : un point en moins si je le reçois le 12 avril à 00:01.
N’oubliez pas de me donner le nom et le mot de passe pour se connecter !
Copier-coller
Copie sur une autre personne (« je se savais pas comment implémenter telle ou telle fonctionnalité dont j’avais besoin pour aller plus loin, je l’ai copiée sur un autre ») :
si la personne est clairement nommée : note pour la fonctionnalité divisée par 2 (uniquement la moitié du travail a été faite) ;
0 aux deux personnes sinon ;
Si je m’aperçois que vous avez bêtement copié collé des sources Internet, je vous convoquerai pour vous demander de m’expliquer la fonctionnalité, et :
si vous ne savez pas m’expliquer le code alors 0 ;
si vous savez m’expliquer tout le code alors votre note totale sera divisée par vous + le nombre de contributeurs à ce projet, ce qui se rapprochera certainement de 0 aussi.
Dans cette formation de près de 7h, je vais vous montrer tout ce que vous avez besoin de savoir pour commencer à créer vos premiers scripts avec Python. La f…
Dans cette vidéo, je vais vous expliquer toutes les bases de la programmation orientée objet avec Python. Classes, instances, méthodes, self, tout cela n’aur…
Bonjour à tous ! Vu les derniers événements sur #freenode, nous avons déménagé nos salons IRC vers Libera.Chat. Le site https://afpy.org reflète déjà cette modification et vous pouvez nous retrouver sur irc://irc.libera.chat:6697/afpy !
Comme tous les mois, retrouvez nos équipes motivées de l'association pour une nouvelle session de traduction de la documentation #Python ! On se retrouve sur notre BBB ce mercredi 26 mai, tout le monde est le bienvenu y compris les débutants !
Il faut aller chercher le code source qui vous intéresse.
Exemple, faire tourner un « vieux » Python 3.6, aller dans les versions ici et prendre celle qui nous intéresse.
Puis récupérer le code source et le compiler :
mkdir ~/source ; cd ~/source
wget https://www.python.org/ftp/python/3.6.13/Python-3.6.13.tar.xz
tar xvf Python-3.6.13.tar.xz
cd ~/source/Python-3.6.13
./configure && make
sudo make altinstall
Et voilà :
~/source/Python-3.6.13$ python3.6
Python 3.6.13 (default, May 21 2021, 17:12:12)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
Salut les gens ! En ce moment c'est la PyCon US mais n'oubliez pas que le jeudi 20 mai prochain nous avons notre petite édition mensuelle de "en attendant la PyConFR" en ligne ! Venez discuter de #Python avec nous !
REmote DIctionary Server Redis est la mémoire partagée de votre application en production. Redis est simple. C'est une base clef/valeur en RAM mais qui sait écrire ses données sur le disque dur (soit dans un gros log, soit des instantanés, soit les deux). Son protocole est élégant, sa gestion du réseau efficace, et il sait gérer de la réplication. Concrètement, Redis va vite, mais ne peut pas contenir plus de données que la RAM disponible, ses données sont typées, mais sans possibilité de définir un modèle ou des relations. Au-delà du simple stockage, redis est aussi capable de gérer des fils d'attente, et des messages en publication/souscription. Redis a des usages différents:
Cache (et de sessions, par extension) Fils d'attente Pubsub Lien non bloquant entre services
Cache et sessions Redis, en plus de mettre a disposition des types complexes, permet de gérer le cycle de vie des clefs : soit avec une durée de vie, soit en évinçant les clefs qui n'ont pas été utilisées récemment. Les frameworks web vous proposeront de gérer les sessions avec Redis, comme le fait PHP, et notre image Docker pour PHP, Flask, ExpressJS et bien d'autres. Fils d'attente Pour rendre soyeux le poil de son application web, il faut des temps de réponses rapides, et donc utiliser des fils d'attentes pour toutes les taches un peu longues. C'est aussi un prérequis pour encaisser des pics d'utilisation. Confortable pour les technos asynchrones (golang, nodejs, python aio…), les fils d'attente sont indispensables pour les technos synchrones (php, python, ruby…), dès que l'application va être un tant soit peu sollicité. Sidekiq est l'indispensable compagnon de Ruby On Rails (vous savez, le truc qui fait tourner Giltab), Python a lui son Celery challengé par rq, en PHP c'est plus confus, enqueue peut-être ? Pubsub Redis propose un pattern de publication/abonnement efficace, mais sans mailbox, les clients déconnectés pourront rater des messages. Dans Redis 5 est apparus la notion de STREAMS qui permet à plusieurs workers de suivre un flot d'événement. Lien Redis est de plus en plus utilisé comme lien entre différents services. Ça permet simplement à un service d'envoyer un flot d'événements sans risquer d'être bloqué, charge ensuite à un autre service de dépiler tout ça. Elastic Beats peut utiliser Redis comme output, tout comme Suricata et tant d'autres. Exploitation Voilà, vous avez un joli Redis en prod, seul ou en sentinelles, mais vous voudriez bien savoir ce qu'il se passe. Redistop C'est ici qu'entre en lice redistop, notre outil pour visualiser (une partie de) ce qu'il se passe dans un redis, dans un terminal, mais avec une interface. Il n'y avait pas grand-chose de disponible, donc "gratte ton coude" comme on dit dans le logiciel libre. Redis fournit un ensemble de commandes pour voir ce qu'il se passe à l'intérieur. INFO fournit une foule d'information sur l'état du serveur, sans le perturber. Ensuite Redis a rajouté des commandes plus précises : les * STATS comme MEMORY STATS. MONITOR est nettement plus violent : il permet de voir le flot de commandes soumises au serveur. Attention, cette commande est coûteuse, et va manger une partie des ressources, c'est très pratique pour du debug, mais mieux vaut éviter de le laisser tourner sur de longue période, surtout si le serveur est chargé. Golang (oui encore lui) est le langage adéquat pour créer un outil en ligne de commande simple à installer et disponible sans trop d'effort sur la majorité des système d'exploitation. Grâce à l'écosystème riche en librairies, le code de l'interface utilisateur est délégué à termui.
Vous pouvez amener redistop prés de votre serveur (c'est un simple binaire), ou l'utiliser en local avec un tunnel SSH vers votre serveur : ssh -N -L 6379:127.0.0.1:6379 bob@mon-serveur. Redistop va afficher un peu de contexte, un peu de statistiques, mais surtout un graphique avec le nombre de commandes, toutes les 2 secondes, et deux tableaux, un avec les commandes et le nombre d'occurrences, un autre avec les IPs des clients et le nombre de commandes. Normalement, vous devriez apercevoir votre monitoring, qui passe quelques commandes et l'application qui va être nettement plus gourmande. Attention, Redis a des usages divers, qui peuvent être cumulés, vous devriez rapidement repérer son usage, il faudra ensuite repérer les abus. Redistop est un logiciel libre sous licence GPL, tout neuf. Il doit surement manquer des fonctionnalités et c'est même imaginable qu'il y ait des bogues. N'hésitez pas à le tester, créer des tickets (qualifiés) et même des pull requests. Redistop ne remplacera jamais votre joli Grafana pour voir les usages et fluctuations sur un temps long, mais il sera là pour combler votre curiosité, et pour démarrer la réparation d'un incident.
Bearstech adore découvrir de nouveaux outils libres. Celui qui nous intéresse aujourd'hui répond au nom de CrowdSec et arbore une belle licence MIT toute propre et toute libre. Massivement collaboratif, CrowdSec est appelé à gagner en efficacité au fure et à mesure que sa communauté d'utilisateurs grandira.
Cet article vous présente un test de l'installation et des principales fonctionnalités de CrowdSec, il y a bien cet article qui était pas mal, mais il teste une version déjà bien ancienne (13 révisions depuis). On compare CrowdSec à un fail2ban copieusement dépoussiéré, mais ne vous y trompez pas, on ne parle pas ici d'un dépoussiérage mais d'une approche radicalement nouvelle de concevoir vos parefeux, ce pour l'ensemble de vos services, VM, ou containers exposés sur le Net. Pour faire simple, CrowdSec va analyser vos journaux de connexion à la recherche des ip aggressives et confier à des bouncers le soin de les bloquer. CrowdSec se base autant sur la détection du comportement d'une IP que sur sa réputation. CrowdSec se définit comme un EDR (Endpoint Detection and Response), ce qui lui confère un super pouvoir face aux poussiéreux antivirus et au désormais sénile Fail2Ban : la faculté de pouvoir corréler les analyses. Et dans notre cas précis, le fonctionnement collaboratif et crowdsourcé de ces analyses renforce leur acuité. Sur le papier, on a donc tout bon au niveau de la réponse à apporter aux nouveaux types de menaces parfois complexes à détecter. L'assistant d'installation qui nous accompagne durant le procesus de configuration va détecter vos services et vous proposer des scénarios adaptés à votre environnement. Le concept de réputation des adresses ip permet à CrowdSec d'établir des listes de blocage, sur la base d'un fonctionnement collaboratif (crowdsourcing). Si une IP attaque des machines monitorées par CrowdSec, cette IP vient alimenter en temps réel une liste de blocage mutualisée, réactualisée quotidiennement. Lorsque CrowdSec repère une adresse IP au comportement agressif, le scénario déclenché et l'horodatage sont envoyés à l'API REST pour être vérifiés et intégrés si besoin dans la liste de blocage. C'est donc automatique, ça fait forcément gagner du temps, et ça permet de détecter des choses bien plus fines qu'une analyse de logs au papier calque :) Sous le capot, on retrouve du GoLang (donc un support IPV6 by design) et des scenarios YAML. Prometheus, Metabase et Docker viennent complèter notre stack. C'est parti pour une installation avec la découverte de cet assistant Le git se trouve ici On commence par récupérer la dernière version de CrowdSec : $ curl -s https://api.github.com/repos/crowdsecurity/crowdsec/releases/latest | grep browser_download_url| cut -d '"' -f 4 | wget -i
on décompresse l'archive et on lance le wizard qui va nous guider pour configurer correctement CrowdSec $ tar xvzf crowdsec-release.tgz $ cd crowdsec-v1.0.13/ $ sudo ./wizard.sh -i
CrowdSec détecte vos services, puis vous propose ensuite une liste de collections adaptées à votre environnement, notez que j'ai recontré des difficultés à ce stade à cause d'un petit bug graphique m'empêchant de voir ce qui est sélectionné ou pas, rien de méchant et ce devrait être vite corrigé. En outre la détection préalable des services entraine un choix par défaut, donc en validant à l'aveuglette le choix par défaut, ça tombe en marche ;) Précisons que le concept de collection est de fournir à un service de quoi se défendre : c'est à dire un parser de logs adapté au service ainsi qu'un scenario de détection des attaques sur ce service. Un peu plus loin CrowdSec nous invite à nous munir d'un bouncer qui sera en charge des blocages, CrowdSec se contentant de l'analyse des journaux de connexions. Une petite visite du hub CrowdSec vous permettra de trouver les bouncers qui correspondent à votre environnement :
En fonction de vos services à protéger, vous installerez donc les bouncers qui vont bien avec la commande $ sudo cscli bouncers add nom-du-bouncer Enfin, une fois l'installation achevée, le processus se lance, et vous propose de vous familiariser avec cscli, l'utilitaire qui va vous permettre de piloter notre CrowdSec... et je vous vois venir, vous aimeriez bien un truc un peu plus sexy et graphique que de la cli pure.
On y retrouve par exemples nos listes communautaires d'IP à la fréquence énervée d'updates et absolument tout dont a besoin, sauf pour le dircom...
C'est justement grâce à cscli que nous allons pouvoir déployer un joli dashboard avec Prometheus, Metabase et Docker. Le test a été réalisé sur ParrotSec par pur masochisme, mais si vous êtes sur une Debian like, pour installer docker il vous faudra taper la commande suivante (un "apt-get install docker" ne fonctionnera pas) : $ sudo apt-get install -y docker.io Une fois docker installé, on peut lancer le setup du dashboard avec cscli : $ sudo cscli dashboard setup Cette commande va nous créer un container Metabase, avec un identifiant et un password autogénéré. Nous allons donc pouvoir nous rendre sur notre dashboard à l'url http://127.0.0.1:3000 (notez que seules les connexions depuis les IP locales sont acceptées... follow the white rabbit to whitelist).
Et vous voilà un maillon de la securité proactive sauce CrowdSec. Vous l'aurez compris, plus nous serons nombreux à l'utiliser, plus CrowdSec gagnera en acuité.
Nous avons pu échanger un peu avec l'équipe qui a su répondre à nos interrogations, notamment concernant le business model. La confidentialité de vos données est une préoccupation réelle et CrowdSec n'a aucune vue dessus, son business model s'oriente sur cette base de données de réputation d'IP, par définition très volatile. C'est donc également très respectueux du RGPD et le succès de CrowdSec nous semble assuré, tant pas les compétences de l'équipe que par la manière dont ce projet a été pensé. Un succès que beaucoup semblent sentir, puisque la team CrowdSec a récemment levé 5 millions de dollars (https://crowdsec.net/2021/05/05/fundraiser-announcement/), et la cadence de développement laisse augurer beaucoup de dynamisme et de nouveautés (on attend avec impatience les collections et bouncers - en particulier Apache !).
Internet adore les yoyos technologiques, alternants l'enthousiasme d'un pionnier bricolant un produit attirant du monde, avec des clones, puis de la normalisation, qui seront adoptés par les suiveurs, et le contexte évoluant, nouveau produit, nouveau yoyo. Dans cet article, nous vous présentons ces solutions. Okay, il n'y a pas 10 exemples et le dernier est moins surprenant qu'enthousiasmant. C'est le 1er avril il faut nous excuser pour le titre piège à clics. Discuter talk est plus vieux qu'UNIX, mais il traine encore sur les Linux et OS X contemporains, et permet à plusieurs utilisateurs d'une même machine de discuter ensemble.
talk
✅ 1 à 1
❌ groupe
❌ serveur
Plus tard, en 1988, apparaitra irc, pour discuter depuis des machines distantes, en se connectant à un serveur. Il existe des passerelles web comme Kiwiirc, et il vous faudra rapidement un bouncer comme ZNC pour ne pas perdre le fil des discussions.
irc
✅ 1 à 1
✅ groupe
✅ serveur
✅ commandes
❌ authentification
❌ présence
❌ hors ligne
Pour accompagner la démocratisation d'Internet et l'arrivée fracassante du web, icq est apparu en 1996. Premier arrivée d'une longue lignée de service de tchat propriétaire et exclusif, avec des vagues successives, avec parfois des rachats, mais toujours une grosse fascination pour isoler les communautés entre elles.
icq
✅ 1 à 1
✅ groupe
✅ serveur
✅ présence
✅ hors ligne
✅ écrit…
❌ protocole public
❌ passerelles
❌ web
Le Minitel, les SMS et les pagers, ça ne compte pas : ce n'est pas Internet, mais clairement, ils ont servi d'inspiration pour la suite. Normaliser les protocoles Une première tentative de rapprochement des réseaux se fait avec des clients multi-protocoles, se basant par exemple sur libpurple. Louable effort permettant de limiter le nombre de logiciels à lancer pour discuter avec des personnes dispersées sur différents réseaux, ça ne résout en rien les groupes de discussions, et pas grand-chose pour le chiffrage de bout en bout. Pour résoudre le problème d'interopérabilité entre différents services, bah, il suffit d'écrire un nouveau protocole qui fait mieux que tout le monde, et de proposer des passerelles vers les vieux services. XMPP XMPP proposa en 1998 d'écrire des tonnes de spécifications (les XEPs), pour faire mieux que tout ce qui existait actuellement. XMPP amène la notion de syndication, qui permet à un utilisateur sur un serveur de discuter avec un autre utilisateur sur un autre serveur, comme le propose le mail depuis toujours. Collision de dates, XMPP rate l'arrivée du Web interactif, et surtout des smartphones. Ils ont aussi raté l'arrivée des discussions chiffrées, des groupes de discussions, et de la fin de l'hégémonie du XML. Mais ils ont tout spécifié, tellement spécifiés qu'aucun client n'implémente suffisamment de fonctions parmi la pléthore de XEP, et c'est mission impossible pour trouver deux clients qui donnent envie, avec des fonctions qui se recoupent. XMPP a des implémentations serveur correctes (le terrifiant Ejabberd ou le contemporain Prosody), mais les clients sont tous vieillissants, et le protocole n'est pas adapté aux connexions intermittentes des réseaux de téléphonie mobile. XMPP a raté sa chance de devenir hégémonique, tout comme XHTML, XSLT, Atom et SOAP, mais ce n'est pas grave. XMPP a un retour de visibilité avec WebRTC, qui a besoin d'établir des connexions entre utilisateurs en se gardant bien de préciser comment, et oui, XMPP est tout à fait adapté à ce genre d'usage. Jitsi, le boss de la visioconférence libre, s'appuie sur Prosody pour gérer les utilisateurs et les groupes de discussions, mais sans trop se soucier de la possibilité qu'un client autre que l'application web se connecte, ou même de la syndication de serveurs à serveurs.
xmpp
✅ 1 à 1
✅ groupe
✅ serveur
✅ présence
✅ hors ligne
✅ écrit…
❌ images/vidéos
❌ appel voix/vidéo
✅ protocole public
✅ passerelles
✅ web
✅ syndication de serveurs
❌ utilisateurs
❌ chiffrage bout en bout
❌ adapté smartphone
La discussion d'entreprise Slack a un peu surpris tout le monde, en proposant un tchat web, en ciblant les entreprises. Techniquement, ça ne fait que reprendre la notion des forums, mais avec plus de temps réel, une vraie UX, des CSS décentes. Slack est conçu pour fonctionner dans un navigateur web (pas de soucis de logiciel à déployer et mettre à jour), avec du texte, mais en reprenant la notion de commandes d'irc (avec des lignes du type /command) Slack propose un client lourd, qui est un peu ce que l'on peut faire de pire avec Electron. 2Go de RAM pour échanger du texte et des smileys, ce n'est pas raisonnable. Slack est devenu un standard de fait, et permet au sein d'une entreprise (avec confidentialité et horaires) d'avoir des discussions en ligne. Mattermost Il existe un clone de qualité, Mattermost, qui reprends verbatim le même système de webhook que Slack, pour qu'une application puisse simplement envoyer des messages sur un chan. On échappe au client lourd, mais il y a un client smartphone, et même un client curse, en mode texte, en haskell. Mattermost propose une API REST complète, mais n'a pas vocation à être intégré dans un client multiplateforme, ni à faire partie d'une syndication. Mattermost évolue maintenant pour proposer des workflows, comme les sondages, la résolution collaborative d'incidents ou les réunions standup. Mattermost propose une intégration aux outils de visioconférence comme Jitsi. Les tchats d'entreprise ne sont pas conçus pour chiffrer les discussions entre personnes, et ont même tendance à tout indexer, avec des volontés claires d'indiscrétion pour Slack. La connexion TLS protège juste des indiscrets de l'extérieur.
Mattermost
✅ 1 à 1
✅ groupe
✅ serveur
✅ présence
✅ hors ligne
✅ écrit…
✅ images/vidéos
✅ protocole public
✅ passerelles
✅ web
✅ commandes
❌ chiffrage bout en bout
❌ adapté smartphone
Discuter dans des groupes chiffrés Whatsapp et Signal ont démontré qu'une application de discussions instantanées conçue initialement pour les smartphones, axée sur les groupes, les images, les vidéos et surtout du chiffrage de bout en bout, avait une efficacité redoutable. Conçu pour smartphone, ces applications ont besoin de votre 06, et les versions desktop sont considérées comme secondaires et il faut les apairer avec son smartphone.
Signal
✅ 1 à 1
✅ groupe
✅ serveur
✅ présence
✅ hors ligne
✅ écrit…
✅ images/vidéos
✅ appel voix/vidéo
❌ protocole public
❌ passerelles
❌ web
❌ syndication de serveurs
✅ chiffrage bout en bout
✅ utilisateurs
✅ adapté smartphone
Sur un smartphone, pour ne pas manger toute la batterie, il ne faut pas qu'une application gère un flot descendant intermittent. Recevoir des évènements ("vous avez un nouveau message") qui vont arriver de temps en temps, n'importe quand, est le pire usage possible du réseau pour un smartphone. C'est pour ça que le smartphone va le gérer à votre place, en prenant en compte les stratégies de mise en veille de certains éléments du téléphone, ou des spécificités des protocoles utilisés en téléphonie. Ce système de notification s'appelle APNS chez iOS, et Notifications chez Android. Avec les notifications natives, il est donc possible d'avoir une application qui ne mange pas toutes les piles, ce qui est un prérequis. L'autre point important pour du tchat moderne est le chiffrage de bout en bout, pour rendre impossible la censure. Le chiffrage entre deux clients est maitrisé depuis longtemps, mais pour les groupes, il faut un truc un peu plus moderne : le double ratchet de Signal. Telegram, clone russe de Signal, reprends les fonctions de son concurrent, en apportant un soin pour avoir un vrai client desktop, sans passer par Electron, et en proposant une API complète avec widget web, bot et de quoi coder un client. Matrix What is the matrix?
Matrix se positionne clairement comme un remplaçant libre de Whatsapp et Signal, avec de la syndication de serveur, et le smartphone comme première cible. La voip, grace à webrtc, en tête à tête fait partie des fonctions de base.
Pour faire ça proprement, Matrix a plein de specs. Cette stratégie reprends celle de XMPP, mais sans le XML, et en gardant HTTP. Matrix.org fournit un serveur en Python, Synapse qui est l'implémentation de référence, mais ils en ont aussi un second, en Golang Dendrite. Matrix.org fournit plein de SDK, mais pas de client de référence, pour ça, il faut aller voir Element. Profitant de son statut de standard, de l'API REST et des SDKs, il commence à y avoir des projets qui intègre le protocole Matrix, comme Thunderbird ou même l'état français avec Tchap, qui est un fork de Riot, le prédécesseur de Element. Oui, il existe un plugin weechat pour profiter de matrix dans votre terminal. Pour les passerelles, Matrix est très agressif en proposant plein de bridges ciblant autant des produits propriétaires que libre.
Matrix
✅ 1 à 1
✅ groupe
✅ serveur
✅ présence
✅ hors ligne
✅ écrit…
✅ images/vidéos
✅ appel voix/vidéo
✅ protocole public
✅ passerelles
✅ web
✅ commandes
✅ syndication de serveurs
✅ chiffrage bout en bout
✅ adapté smartphone
❌ utilisateurs
Internet gagne toujours à suivre des normes pour avoir des outils interopérables, et laisser voguer la créativité des développeurs, plutôt que de subir des coups de GAFA sur le coin de la tête. Matrix part sur de bonnes bases, mais, stable depuis 2 ans, avec seulement deux implémentations du serveur, il n'a pas encore subi le baptême du feu. À suivre, donc.
Vous avez raté l'édition précédent de "En attendant la PyConFR " ? Pas de problème ! Toutes les présentations et lightning talks sont désormais disponibles en vidéo ici : https://discuss.afpy.org/t/conferences-du-18-fevrier-2021/162/23 ! Bon (re-)visionnage !
Bonjour les francophones, la documentation #Python a de nouveau besoin de vous ! Venez rejoindre nos vétérans de la traduction ce mercredi 24 mars à 18h30 sur notre BBB, toutes les bonnes volontés sont le bienvenu ! https://bbb.afpy.org/b/jul-fss-kpj-txw
N'oubliez pas ce soir à 19h c'est notre édition mensuelle de "En attendant la @PyConFR ". Au programme : Lightning Talks #Python. Retrouvez nous sur notre BBB https://bbb.afpy.org/b/jul-fss-kpj-txw et n'hésitez pas à proposer des nouveaux sujets sur notre Discuss https://discuss.afpy.org !
Tous les professionnels du secteur ont vu leur pire cauchemar se réaliser et soutiennent à 100% OVH dans ces moments difficiles. L'expertise des datacenters Une catastrophe ça arrive. La fréquence est tellement rare qu'il est difficile de se projeter, voir d'y mettre un rapport investissement/risque tellement ça semble flou. D'ailleurs pour OVH il faut rapporter ceci à leur existence, car ils ne semblent pas avoir connu de telle catastrophe en plus de 20 ans et sur environ 32 datacenters. Ils les ont tous construits, ils sont connus pour être experts et innovants en la matière, et donc ça arrive bien entendu aux meilleurs. Avant d'aborder la question de la prévention et/ou du PRA, on peut déjà noter qu'à ce stade le choix d'un opérateur, puis en son sein d'une zone géographique, n'est pas un choix trivial. Chez Bearstech, en tant qu'exploitant de sa propre infrastructure mais également infogéreur chez des tiers comme OVH, nous avons près de 15 ans d'expertise du paysage datacentrique français et européen. Nous avions opportunément identifié des problèmes de technique et de management chez OVH/Strasbourg et depuis nous avons pris soin de ne pas y déployer de services. Nous avons de ce fait aucun client chez OVH impacté par l'incendie. En 15 ans de production nous avons nous-même vécu quelques coups de chaud, un de trop chez un opérateur que nous ne nommerons pas, présentant également des défauts de management, notamment de chaîne de sous-traitances - nous l'avons quitté malgré le travail dantesque de migration (physique!) de datacenter que cela impliquait. Exploiter des datacenters n'est pas notre métier, mais être capable d'évaluer les exploitants et bien les choisir l'est ! Notre datacenter primaire est actuellement chez Scaleway, et s'il s'agit de cet opérateur et surtout de DC3 ce n'est pas un hasard. Scaleway aussi a connu des incendies, et a pu en tirer des leçons qu'il a partagées (https://blog.scaleway.com/fr/incendie-dc5/) : nous sommes ainsi nettement moins exposés aux risques industriels et gros incendies comme celui d'OVH à Strasbourg. Ce datacenter nous garantit aussi de meilleures normes de sécurité et de redondance électrique. L'expérience de la conception Nombre de nos clients savent qu'ils pourraient être en théorie autonomes face à leurs serveurs, les commander, les provisionner et installer leurs applications. Mais en pratique, comment prévenir et gérer les incidents, à tout heure, sans en avoir géré auparavant ? Une grande partie de l'expertise de l'infogéreur, c'est son expérience. Il saura prévenir un maximum de risque avec le minimum de complexité et de coût. On ne peut pas prévoir tous les incidents, et surtout s'en prémunir de la même façon, il faut souvent étudier des solutions sur mesures, suivant les besoins de disponibilité, les budgets, et les technologies impliquées. On pense souvent à l'incident matériel sur le ou les serveurs hébergeant l'application, mais le périmètre est bien plus large : le registrar, le DNS, les APIs consommées, le CDN, les loadbalancers, les VPNs, les DDoS, les débordement de capacité, etc. Savoir comment architecturer cet ensemble afin qu'il reste simple et résilient nécessite un savoir-faire qu'on acquiert qu'en "forgeant" et en exploitant. Savoir anticiper et gérer les évolutions des architectures est également une expertise clé, on ne peut pas tout jeter et recommencer à chaque fois qu'on bute sur une limite en production. Sauvegarder et restaurer En matière d'infogérance nous considérons qu'il y a un minimum qui n'est pas discutable : 1/ les sauvegardes : C'est pour cela que nous n'avons aucune offre d'infogérance sans sauvegarde, et ce depuis toujours. Ce n'est pas négociable, et ceci nous permet de déployer des solutions de sauvegardes massives permettant des économies d'échelle. Le corolaire est qu'il est facile de commander des sauvegardes aussi exigentes que "8 quotidennes, 4 hebdomdaires, 12 mensuelles", et vous avez la garantie que derrière une équipe s'assurera que quoi qu'il arrive, les sauvegardes fonctionnent 24x7 ; 2/ les sauvegardes distantes : l'incendie d'OVH illustre tristement leur nécessité. Un incident physique n'est pas forcément conscrit à quelques serveurs ou un bâtiment, tout un site peut être touché. Ainsi une sauvegarde n'en est pas une tant qu'elle n'est pas à une distance respectable. Chez Bearstech nous utilisons d'ailleurs une inrastructure custom chez OVH (Roubaix) pour assurer une copie des données de notre datacenter à plus de 250km ; 3/ les sauvegardes locales : optionnel, mais si vous avez un grand volume de sauvegarde (comme nous), une sauvegarde distante peut impliquer des temps de restauration qui se chiffrent en jours avec le meilleur des réseaux ! Nous gardons aussi une sauvegarde locale qui permet de restaurer beaucoup plus vite in situ, et ainsi on a à chaque instant deux sauvegardes complètes. Nous considérons qu'avoir deux copies est la norme industrielle depuis l'avènement de S3. Par ailleurs savoir restaurer est une compétence symétrique bien souvent négligée. Nous vous encourageons à faire tout de suite un ticket à votre infogéreur et lui demander d'accéder aux données de votre serveur de la veille ou de demander si une restauration peut être programmée rapidement (sur une préprod! Ne soyez pas trop joueur...). S'il réagit rapidement, calmement et positivement comme il se doit, considérez que cela vaut tous les ISO 27001, c'est le résultat concret qui vous dit si votre business numérique survivra ou pas. L'expertise des sauvegardes et de la résilience Assurer la sauvegarde complète d'une application pour que sa restauration se passe bien est loin d'être une chose triviale. Il n'existe pas de solution sur l'étagère à notre connaisance. Pour une application donnée, restaurer c'est savoir faire une sauvegarde cohérente. Ceci signifie que l'ensemble des données qui la constitue correspondent à la représentation d'un instantané du modèle de donnée de l'application. Plus pragmatiquement, c'est par exemple dans la sauvegarde et le tuple [42, "doc-important.pdf"] dans le dump SQL et le fichier doc-important.pdf dans la copie du stockage objet et du filesystem. Cartographier l'état et la configuration d'une application n'est pas chose aisée. Par ex., auriez-vous pensé à sauvegarder puis restaurer la crontab planquée en général dans /var/spool/cron/crontabs/ ? Que l'envoi d'emails peut génerer une longue trainée de spam si vous oubliez de mettre à jour un champ DNS SPF ? La checklist peut être (très) longue et chaque détail peut mener à un restauration fail, bien entendu au pire moment. Enfin, capturer l'état de tous les services d'une application (la configuration, le code, le dump SQL et noSQL, l'environnement DNS/CDN/TLS, etc) et en faire un état global cohérent n'est pas chose aisée. Dès que l'on dépasse le cadre balisé de quelques stacks telles que LAMP, nous avons constaté qu'il doit y avoir un dialogue entre l'infogéreur et les développeurs afin de définir une solution adaptée. Notez qu'en ces temps d'abstraction plus élevés (Kubernetes !), beaucoup sont tentés de croire que ces problèmes ont été résolus par ces nouvelles infrastructures. Attention, il n'en est rien : ces abstractions permettent d'utiliser plus facilement des systèmes résilients, mais cette résilience n'est pas automatiquement acquise avec l'adoption de cette technologie. Les détails d'implémentation sont également importants et peuvent vous échapper (combien de clusters k8s avons-nous vu dans une unique zone...). Conclusion : ne pas perdre de données Ce billet n'aborde pas la problématique de la haute disponibilité, car il est relativement distinct des problématiques de sauvegardes. Une partie de l'analyse sur ce qu'est l'état d'une application est commune, mais ensuite les choix techniques et les implémentations sont en général distincts : faire une photo des données une fois par jour n'est pas la même chose qu'obtenir une copie en continu et quasi temps réel. Par ailleurs il faut bien comprendre que sauvegarder et répliquer pour de la H-A (Haute Disponibilité) ne sont pas mutuellement exclusifs, surtout pas ! Il suffit d'imaginer le scénario où un déploiement efface par erreur des données en production (ou une attaque destructrice, etc) : le problème sera instantanément répliqué sur votre belle infrastructure super résiliente, et votre business tombe ! La sauvegarde vous prémunit de tous les incidents, alors que la réplication/H-A seulement de quelques pannes, c'est un périmètre très différent. Nous avons donc développé un mantra précis : il ne faut pas perdre de données. En 2021, avec le prix du stockage dérisoire, et des choix technologiques en pagaille, ce n'est clairement pas une option.
Grafana, Influxdb et Telegraf permettent de moissonner vos mesures, mais parfois, il est necessaire d'aller plus loin et de créer son propre capteur. Qu'il s'agisse d'améliorer les performances, benchmarker différentes pistes, auditer un soucis de perf ou tout simplement maintenir un service, il est important de pouvoir prendre son pouls. Dans cet article nous vous présentons une maquette fonctionnelle complétant une stack standard de récupération et de visualisation de données pour l'adapter à vos besoins. Grafana Grafana est la réponse. Quel que soit vos choix, ils seront visualisés par Grafana au moins, et si vous en avez le besoin par d'autres outils. Influxdata Influxdata propose un ensemble cohérent d'outils pour collecter des données, les enregistrer, les requêter et finalement les afficher dans Grafana. +----------+ +----------+ +---------+ | Telegraf +-->| Influxdb |<---+ Grafana | +----------+ +----------+ +---------+
Telegraf Telegraf est le collecteur d'Influxdata. Architecturé sur un ensemble de plugins (aggregateurs, entrées, sorties, parseurs, processeurs, serialiseurs), ce sont ici les inputs qui nous interessent, et l'outil propose une longue liste d'inputs. Une large partie des inputs est dédiée à un service précis. Certains inputs "service" permettent de faire des requêtes libres, comme le propose redis et postgresql_extensible), mais rien pour les autres bases de données (mariadb a pourtant des trucs à dire). Une partie des inputs est générique et permet de récupérer des informations variées :
procstat mais cgroup sera plus efficace tail exec execd
Les inputs peuvent requêter des services distants :
Les inputs peuvent être un service réseau, et attendre des métriques poussées par divers clients.
influxdb_listener statsd (avec l'option tag, à la Datadog) webhooks riemann_listener
La liste des plugins est conséquente, mais il est quand même possible de ne pas trouver l'input qu'il nous faut. Il est important d'instrumenter les applications que l'on développe, mais qu'en est-il pour un service existant ? La sonde prometheus gagne son status de standard de fait et se trouve dans beaucoup de services modernes. Il existe des exporter tout prêt comme blackbox_exporter. Par contre, coder un agent, juste pour exposer un endpoint prometheus n'est pas raisonnable. Développer un agent qui va causer influxdb ou statsd est faisable, mais bon, on perds la centralisation du tempo de la mesure, et ça fera un systemd de plus. La réponse officielle de telegraf pour récupérer des données spécifiques est exec ou mieux, execd. exec va lancer une commande à chaque fois, et parser STDOUT. Simple, mais ça implique de lancer une commande plusieurs fois par minute. execd va lui aussi lancer une commande, mais sans l'éteindre, et il redemandera à chaque fois une nouvelle réponse (toujours sur STDOUT). La commande pourra réagir à une nouvelle ligne dans STDIN, un signal UNIX, ou se contenter d'écrire périodiquement de nouvelles choses dans STDOUT. telegraf recommande la première approche : STDIN, qui fonctionnera aussi sur Windows. Telegraf utilise des plugins pour parser les mesures, et son format de prédiléction est celui d'Influxdb, le line protocol. Un service avec execd Voici un exemple simple de l'utilisation d'execd avec python. Configurer un inputs.execd est trivial, il faut choisir une commande, un signal et un format. [[inputs.execd]] ## One program to run as daemon. ## NOTE: process and each argument should each be their own string command = ["./my_command.py"]
## Define how the process is signaled on each collection interval. ## Valid values are: ## "none" : Do not signal anything. (Recommended for service inputs) ## The process must output metrics by itself. ## "STDIN" : Send a newline on STDIN. (Recommended for gather inputs) ## "SIGHUP" : Send a HUP signal. Not available on Windows. (not recommended) ## "SIGUSR1" : Send a USR1 signal. Not available on Windows. ## "SIGUSR2" : Send a USR2 signal. Not available on Windows. signal = "STDIN"
## Delay before the process is restarted after an unexpected termination restart_delay = "10s"
## Data format to consume. ## Each data format has its own unique set of configuration options, read ## more about them here: ## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.md data_format = "influx"
Le line-protocol est simplissime : measurement[,tags] fields [timestamp]
measurement est le nom de la mesure. Les tags sont un ensemble de clef=valeur séparés par des ,, qui permettront de regrouper/filtrer les mesures. Attention de ne jamais avoir de tag qui peut avoir un grand nombre de valeur (comme un id unique). Les fields sont un ensemble de clef=nombre séparés par des ,. timestamp n'est pas utilisé, ce sera à Telegraf de le gérer. En python, l'implémentation du line-protocole va donner ça : def marshal(dico): return ",".join("=".join(t) for t in sorted(dico.items()))
# https://docs.influxdata.com/influxdb/v2.0/reference/syntax/line-protocol/ def write(writer, measurement, tags={}, fields={}): "Writes to the Influxdb's line protocol" print(measurement, ",", marshal(tags), " ", marshal(fields), sep='', file=writer)
La commande sera une boucle sur STDIN, qui ira chercher plusieurs mesures, et les affichera formaté sur STDOUT for _ in sys.stdin: # execd protocol, newline trigger fresh stats for tags, fields in fetch_my_measurements(): write(sys.stdout, "my_measurement", tags, fields)
Il faut bien sûr écrire son bout de code métier dans fetch_my_measurements, qui va yield des tags et des fields. Telegraf permet simplement de tester un bout de config. Il va lancer la récolte de mesure une fois, il l'affichera sur STDOUT ce qu'il enverrait à Influxdb (le line-protocol), sur STDERR les trucs bizarres, et stoppera. Attention à tester avec l'utilisateur telegraf (avec sudo ou gosu selon votre chapelle) si vous avez des contraintes de sécurité basées sur l'utilisateur. telegraf --config my_command.conf --test
Au delà de d'influxData et Grafana Il est aisé de récupérer des mesures précises pour comprendre le comportement de votre application en prod, de les stocker, et d'explorer depuis Grafana. Vous pouvez maintenant partir à la recherche de nouvelles sources, et Linux (le kernel) bosse beaucoup sur ce sujet, cgroup est là depuis longtemps, mais ebpf devrait enfin amener les outils qui faisaient la réputation de Solaris. Garder un oeil sur le sniffing réseau, avec pcap et ses successeurs, avec packetbeat comme hérault. Niveau applicatif, statsd fait le job, prometheus est la norme inévitable, mais la fusion entre mesure, trace et log avance bien avec opentelemetry d'un coté, et l'omniprésent Grafana de l'autre (avec Loki qui vient de sortir sa 2.2, et Tempo qui souhaite piquer la place de Jaeger). Et voilà ! Voila, vous êtes maintenant capable d'aller chercher les mesures nécessaires à la compréhension de vos soucis de performances, et de valider vos hypothèses en regardant ce que ça change au niveau des métriques.
J’ai publié un article dans Linux Pratique n°115 (septembre 2019) intitulé « Coloration syntaxique de votre code avec Pygments ». Il est disponible publiquement sur le site des éditions Diamond, sous licence Creative Commons BY-NC-ND.
Les éditions Diamond proposent 3 modes de cession des droits pour les articles dont une qui permet la republication sous cette licence, 6 mois après la publication papier (cession de droits type B).
Dans ce cas où l’article disparaîtrait du site Diamond, je le reproduis ci-dessous :
Mieux visualiser du code source grâce à sa coloration est une évidence. Découvrez Pygments, un outil de coloration facilement utilisable et extensible.
Pygments [1] est un outil écrit en Python permettant de colorer du code pour plus d’une centaine de langages de programmation ou de description (HTML, XML, TeX), de moteurs de templates (ERB, JSP, Jinja2, etc.) et divers scripts et fichiers de configuration (Vim, fichiers .ini, Apache, Nginx). Deux façons de l’utiliser coexistent :
comme une bibliothèque ;
grâce à un exécutable (pygmentize), il est utilisable directement dans un terminal.
Pygments est disponible pour python 2 et 3.
Nous verrons quelques usages de cet outil puis la façon d’y ajouter un langage et un thème.
1. Usages
1.1 Dans un terminal
L’usage le plus simple se résume à appeler pygmentize uniquement avec le nom du fichier à colorer en paramètre : pygmentize fichiers.pl
Cette commande affiche le contenu d’un fichier nommé fichiers.pl sur la sortie standard avec la coloration syntaxique par défaut. Cependant, pygmentize dispose de paramètres pour personnaliser la sortie selon ses préférences: pygmentize -f terminal256 -O style=friendly -g fichiers.pl
Le paramètre -f définit le type de sortie souhaitée. De nombreux formats sont disponibles, allant du HTML au Latex en passant par la génération d’une image contenant le code à colorer. terminal256 est un mode pour la sortie standard d’une console.
Le paramètre -O définit la couleur et la graisse des caractères. 29 possibilités sont disponibles dans la version 2.2.0 (nommées algol, autumn, emacs, friendly, vim, etc.).
Le paramètre -g indique que le lexeur à utiliser est déterminé par l’extension de fichier.
Application du style friendly au contenu du fichier fichiers.pl
Cependant, il est bien plus pratique d’ajouter un alias pour pouvoir l’appeler rapidement :
alias hcat='pygmentize -f terminal256 -O style=friendly -g'
Selon le shell utilisé, il faut l’insérer dans un fichier différent : ~/.bash_profile or ~/.bashrc pour bash, ~/.zshrc pour zsh et ~/.config/fish/config.fish pour fish.
1.2 Avec Latex
Minted est un paquet Latex permettant de réaliser une coloration syntaxique de code source. Il utilise pygments pour faire la coloration.
Il est utilisable en insérant le code source au sein du fichier latex :
\begin{minted}
[
% configuration du style
% (taille des caractères, numérotation des lignes, etc.)
]
{perl}
% ici le code source
\end{minted}
Ou en gardant le code source dans un fichier externe : \inputminted{perl}{fichiers.pl}
Dans les deux exemples précédents, le motif {perl} définit le lexeur utilisé par pygments.
1.3 Présentation avec rst2pdf
rst2pdf produit un PDF de présentation à partir d'un fichier texte au format ReStructured Text. Il réutilise aussi pygments pour faire la coloration syntaxique. Les présentations sont par défaut très épurées.
rst2pdf.py presentation.txt -o presentation.pdf
rst2pdf est disponible dans le paquet éponyme dans Debian et ses distributions dérivées.
1.4 Pour le web
Pygments est utilisé dans des outils web écrits en Python, comme par exemple le moteur de wiki Moinmoin ou le générateur de site statique Pelican. Hugo, un autre générateur de site statique, utilisait pygments pour la coloration syntaxique mais l'a remplacé par chroma, un outil en Go. Chroma réutilise les définitions les plus courantes de pygments pour son propre usage. Django, le framework web le plus connu du monde Python dispose aussi d'un module pour s'interfacer avec pygments.
Pour les autre langages, la tendance est plutôt à l’utilisation de solutions natives au langage (côté serveur) ou l’utilisation d’une bibliothèque javascript (côté client) comme highlight.js qui dispose de nombreux de langages/fichiers de configuration et d’une intégration aisée.
2. Ajouter un lexeur
Ajouter un lexeur permet de prendre en compte un nouveau langage ou format de fichier (texte). Le lexeur doit être défini dans une classe Python qui intégrera les expressions rationnelles analysant le texte.
À titre d'illustration, nous allons utiliser une partie du format Smart Game Format (sgf) [2] qui sert à l'enregistrement de certains jeux à deux joueurs ; le plus connu étant le jeu de Go. Le lexeur complet a été intégré dans la dernière version de pygments (2.4.0, publiée en mai 2019).
Note : Qu’est-ce qu’un lexeur ?
Un lexeur est un programme analysant un texte en le découpant en une suite d’entités lexicales (par exemple, un entier, une chaîne de caractères, une définition d’un type, etc.). La phase d’analyse lexicale faite par un lexeur est la première étape d’une compilation d’un programme.
Le développement d'un nouveau lexeur est facilité par l'utilisation de paramètres supplémentaires à pygmentize. En supposant que la classe définissant le lexeur soit nommée SmartGameFormatLexer et contenue dans le fichier sgf.py et que le fichier à analyser soit nommé partie.sgf, la commande sera : pygmentize -l sgf.py:SmartGameFormatLexer -x partie.sgf
Un extrait de partie.sgf pourrait être : (;FF[4]GM[1]SZ[19]KM[5.5]
PB[Alice]PW[Bob]
;B[pe];W[cp];B[pp];W[dd])
La structure des données est toujours basée sur le motif mot-clef[données].
Il est nécessaire de séparer :
– les mots-clefs (FF, GM, SZ, KM, PB, PW, B et W) ;
– les données qui peuvent être des nombres entiers (comme 4) ou décimaux (5.5) ou encore du texte. Ce dernier est utilisé ici pour les noms des participants (Alice et Bob) ou les coordonnées du plateau (pe représentant la colonne p et la ligne e) ;
– les séparateurs (parenthèses, crochets, deux-points et point-vigule) :
L'attribut filenames (ligne 9) est utilisé par le paramètre -g de pygmentize pour déterminer le lexeur à utiliser pour colorer un fichier (cf. le deuxième exemple de cet article). Seuls les fichiers finissant par .sgf seront analysés par SmartGameFormatLexer. Il est possible d'accepter plusieurs extensions de fichier : par exemple, pour le lexeur du C++, 12 extensions sont acceptées (.cpp, .c++, .cxx, .hpp, …).
Les expressions rationnelles permettent d'éclater le contenu du fichier et de définir le type (chaîne de caractères, opérateur, commentaire, entier, etc.).
L'analyse du dictionnaire des symboles commence par la clef root du dictionnnaire tokens en cherchant la première correspondance possible dans la liste avec l’expression rationnelle. Une fois la correspondance trouvée, l’analyse des motifs permet de connaître le type de la chaîne. Par exemple, la chaîne FF va correspondre à l’expression rationnelle r'(B|FF|GM|KM|P[BW]|SZ|W)' et donc sera analysée comme étant de type Name. Il est possible de faire reconnaître plusieurs symboles dans la même expression rationnelle : c’est le cas de la chaîne [4] qui est reconnue par l’expression rationnelle (\[)([0-9.]+)(\]). Les trois motifs entre parenthèses seront affectés aux paramètres passé à la fonction bygroups() (donc [ correspond au type Punctuation, 4 à Integer et ] à Punctuation).
Pour des besoins plus complexes, il est possible d’ajouter des clefs à tokens pour passer à une autre liste d’expressions rationnelles. Dans ce cas, il est possible d’aller une clef à l’autre puis de revenir à la précédente. Il est aussi possible d'appeler d'autres lexeurs dans un lexeur particulier ou d’appeler une fonction spécifique pour gérer des cas particuliers.
3. Ajouter un style
Pour ajouter un nouveau thème de couleur, il faut créer un fichier qui sera placé dans le répertoire contenant les styles de pygments. Pour éviter de modifier la version du système, il suffit de créer un environnement local. Python permet cela en créant un virtualenv:
Le nom du fichier et la classe définie à l'intérieur sont dépendants du nom que l'on souhaite donner au thème : pour que le style soit nommé glmf, le fichier doit s’appeler glmf.py et la classe qu’il contient doit être nommée GlmfStyle.
Pour tester le résultat en affichant le script Perl précédent : $ ./venv/bin/pygmentize -f terminal256 -O style=glmf -g fichiers.pl
À chaque type de symboles est associé un style à afficher avec une couleur, soit avec une valeur hexadécimale (ici #808 s’affiche en violet), soit avec un nom ansi (comme ansicyan). Il est possible de modifier l’affichage en soulignant (underline), en mettant en gras (bold), en définissant une couleur de fond (bg:#fff pour un fond blanc). Il est aussi possible d’utiliser des italiques(italic) mais cela n’aura pas d’incidence sur une sortie dans un terminal (mais sera visible sur une sortie html par exemple).
Application du style glmf toujours sur le même fichier. C’est tout de même plus… personnel, non ?
Conclusion
Pygments est une référence classique pour de la coloration syntaxique dans l’écosystème Python et est utilisé au-delà. La difficulté d’ajout d’un lexeur est fonction de la complexité du langage à traiter. L’ajout de style est plus simple mais sa plus-value est probablement plus faible.
N'oubliez pas ce soir à 18h30 : c'est lighting talks ! Venez partager vos retours d'expériences, vos succès ou vos échecs, ainsi que vos découvertes autour de #Python avec nous ! #AFPy
Vendredi dernier j’ai signé une rupture conventionnelle qui mettra fin
au contrat qui me lie à Tanker le 24 février 2021.
Ainsi se conclura une aventure de près de 5 années riches en
enseignements et en rebondissements. Merci à tous mes collègues, et bon
courage pour la suite!
Dans l’idéal, j’aimerais trouver une activité de professeur à temps
plein (toujours dans le domaine de l’informatique) et dans la région
parisienne, mais je suis ouvert à toute forme de contrat.
J’ai acquis de nombreuses compétences en tant que développeur
professionnel - tant chez Tanker que dans ma dans ma boîte précédente,
Softbank Robotics - compétences que je souhaite aujourd’hui transmettre.
Parmi les sujets sur lesquels je me sens prêt à donner des cours dès
maintenant:
Les bonnes pratiques de développement (tests automatiques, intégration
continue, DevOps, revue de code, …)
Les méthodes agiles (SCRUM et Lean en particulier)
etc …
Il est bien sûr possible que je n’arrive pas à trouver un poste à temps
plein tout de suite, et donc j’ai prévu de chercher également un poste
dans une coopérative ou similaire.
Je ne me vois pas du tout travailler dans une société de service ou dans
une grosse boîte, et après plus de 10 ans passés dans le monde des start-
up, j’ai besoin de changement. Je pense que je m’épanouirai davantage
dans ce genre de structure, et en tout cas, cela m’intéresse de
découvrir une nouvelle forme d’organisation.
J’écris cet article en partie pour clarifier mes objectifs pour l’avenir,
mais surtout pour que vous, chers lecteurs, puissiez le partager et
m’aider à passer cette nouvelle étape de ma carrière.
Comme d’habitude, ma page de contact est là si vous
avez des pistes à me suggérer, des questions à me poser, ou pour toute autre
remarque.
Dans une base de code source, certaines parties sont plus modifiées que d’autres. cpython ne déroge pas à la règle. En analysant les fichiers modifiés durant l’année 2020, on peut voir l’activité intégrée à la branche principale (nommée master).
L’activité d’un fichier est estimée en comptant le nombre de fois où il a été modifié. Dans cet article, l’estimation de l’activité d’un répertoire est la somme de l’activité des répertoires et des fichiers qu’il contient. Par exemple, avec un répertoire R contenant 3 fichiers F1, F2 et F3, un premier commit modifiant F1 et F2, un second modifiant uniquement F2, alors l’activité de F1 vaut 1, F2 vaut 2 et F3 vaut 0. L’activité de R vaut (1 + 2 + 0).
Activité globale
La quantité totale de modifications enregistrées est de 9956.
L’activité dans les répertoires à la racine du dépôt est principalement dans :
Doc : documentation au format reStructuredText. Elle permet la génération de plusieurs documentations visibles sur python.org (dont celle de la bibliothèque standard)
Misc : quelques fichiers divers et un répertoire résumant les nouveautés de chaque version
Modules : code python et C
Ces quatre répertoires représentent 2/3 de l’activité.
Il existe aussi quelques fichiers à la racine mais leur activité est négligeable.
Dans le répertoire Lib
60% de l’activité dans Lib se situent dans Lib/test et sont donc liés à la modification ou l’ajout de tests unitaires. Étant donné que la bibliothèque standard est couverte par des tests unitaires, il est assez logique que cela représente une part importante de l’activité. Ce répertoire ne contient pas l’intégralité des tests : certains sont placés ailleurs dans l’arborescence. Par exemple Lib/idlelib/idle_test, Lib/distutils/tests, etc.
Loin derrière, et pourtant deuxième en terme d’activité dans Lib, le répertoire idlelib contient du code de l’éditeur IDLE (4%).
Les onze premiers modules actifs (en excluant les tests) représentent 19% de l’activité :
L’activité autour de IDLE me semble étonnante car j’ai l’impression que cet éditeur est peu utilisé et donc je l’imaginais peu actif. De même pour tkinter mais son activité est probablement liée à IDLE qui l’utilise comme interface graphique.
Dans le répertoire Doc
La moitié de l’activité dans ce répertoire est liée à la bibliothèque standard (dans Doc/library). C’est assez logique puisque Lib est très modifié donc la documentation correspondante doit être mise à jour (pour signaler une changement de comportement, un nouveau paramètre, etc.).
Ensuite, avec 20% de l’activité, le répertoire Doc/whatsnew contient les notes de version. L’année a vu la sortie de python 3.9 et le début du développement de la version 3.10 donc on retrouve principalement des modifications pour ces deux fichiers. Je suppose que les autres versions sont dues à des rétroportages ou des modifications cosmétiques.
Ce répertoire contient de nombreux autres fichiers de version, commençant avec 2.0.rst, qui n’ont eu aucune activité.
Dans le répertoire Misc
L’activité dans le répertoire Misc est due à l’ajout des nouvelles qui sont placées dans Misc/NEWS.d (94%). Chaque nouveauté ou changement de comportement ajouté à une nouvelle version publiée donne lieu à un nouveau fichier. Contrairement à des fichiers .py qui sont régulièrement modifiés, ces fichiers sont ajoutés en grand nombre mais ne sont plus jamais modifiés. Cet ajout est la dernière étape à effectuer pour proposer une modification sur le code de cpython.
Le fichier ACKS contient 5% des modifications : ce fichier regroupe le nom de toutes les personnes qui ont au moins contribué une fois. Il est donc logique que ce répertoire soit souvent modifié.
Dans le répertoire Modules
Le répertoire Modules contient une partie du code C de l’interpréteur. Contrairement aux répertoires précédents, l’activité est répartie beaucoup plus largement.
Il faut les 14 premiers répertoires et fichiers pour représenter 50% de l’activité de Modules.
Méthode de calcul et limites
Le code source ayant permis de produire l’arborescence d’activité est disponible à https://github.com/sblondon/commitstats. J’espère qu’il n’y a pas d’anomalie (ou sans impact réel) sur les calculs de stats.
L’arborescence est affichée sur la sortie standard :
Les fichiers de statistiques générés sont téléchargeables. Les scripts de génération des graphiques y sont aussi (et ont encore moins d’intérêt).
Seule la branche master est prise en compte donc les développements en cours et ceux en attente d’intégration sont ignorés.
Les modifications considèrent l’ensemble de l’année 2020 donc une partie des développements de la version 3.9 et le début de 3.10 puisque la version 3.9 est sortie en octobre 2020.
Plutôt que de compter le nombre de fois qu’un fichier a été modifié, il serait peut-être préférable de compter le nombre total de lignes modifiées.
Deux exemples très courts pour vous mettre sur les rails, qui envoient et reçoivent du binaire « pur » = très peu de bande passante, avec une connexion persistante.
Je vous donne deux envois-réception qui devraient vous permettre de faire tous vos envois binaires :
C# : le client envoie un octet, qui correspond à un booléen, pour dire s’il est en big ou little endian ;
C# : le client envoie un message encodé en UTF-8 (oui j’ai trouve la solution qui fonctionne !) ;
Python : le serveur lit ce booléen ;
Python : le serveur lit le message et le dit à voix haute (sous Windows) ;
Python : le serveur envoie un entier non signé, puis deux float ;
C# : le client lit l’entier non signé puis deux floats.
Avec ça, vous avez de quoi comprendre et faire tous les échanges que vous voulez !
using System;
using System.IO;
using System.Net.Sockets;
using UnityEngine;
public class Connexion : MonoBehaviour
{
public string server;
public string message;
public ushort port;
private void Start()
{
// working sample to send text:
byte[] data = System.Text.Encoding.UTF8.GetBytes(message);
byte isLittleEndian = BitConverter.IsLittleEndian ? (byte)1 : (byte)0;
TcpClient client = new TcpClient(server, port);
NetworkStream stream = client.GetStream();
// Send the message to the connected TcpServer.
stream.WriteByte(isLittleEndian);
stream.Write(data, 0, data.Length);
Debug.Log($"Sent: {message}");
// read sample
BinaryReader reader = new BinaryReader(stream);
uint len = reader.ReadUInt16();
var x = reader.ReadSingle();
var y = reader.ReadSingle();
Debug.Log("len=" + len);
Debug.Log($"x={x}, y={y}");
}
}
Pour la note, ces deux exemples paraissent simples, mais ils m’ont pris un temps fou, et je n’ai eu aucune réponse au bout de 3 semaines sur stackoverflow…
Pourquoi cela ? Explication : l’opposé de EAFP, c’est LBYL.
EAFP : Easier to ask for forgiveness than permission
Plus facile de demander pardon que la permission. Ce style de codage très utilisé en Python suppose l’existence de clés ou d’attributs valides et intercepte les exceptions si l’hypothèse s’avère fausse. Ce style propre et rapide se caractérise par la présence de nombreuses déclarations try and except. La technique contraste avec le style LBYL commun à de nombreux autres langages tels que C.
LBYL : Look before you leap
Réfléchir avant d’agir.
Ce style de codage teste explicitement les conditions préalables avant d’effectuer des appels ou des recherches. Ce style contraste avec l’approche EAFP et se caractérise par la présence de nombreuses déclarations if.
Dans un environnement multi-thread, l’approche LBYL peut risquer d’introduire une condition de concurrence entre « la vérification » et « la validation ». Par exemple, le code : if key in mapping: return mapping [key] peut échouer si un autre thread supprime la clé du mappage après le test, mais avant la recherche. Ce problème peut être résolu avec des verrous ou en utilisant l’approche EAFP.
gitlab n’est pas 100% opensource, ils proposent une édition communautaire limité et la totalité des fonctionnalités est dispo avec la version entreprise, leur modèle économique c’est de brider la version CEE (community) dans pas mal de coin pour te pousser à prendre une licence, perso je trouve que c’est plus un freeware qu’autre chose
gitlab est pas mal mais honnêtement pour l’avoir beaucoup (vraiment beaucoup) utilisé dans le passé ce n’est pas la meilleur alternative.
Si tu cherche à mettre en place un truc je te conseille fortement de jeter un œil à :
Cette stack est un peu plus compliquée à mettre qu’un gitlab, mais c’est très puissant, surtout la partie gerrit qui transcende la manière de faire des revues de code.
Si le code Django / Python n’est pas correct, il y a des méthodes pour améliorer les choses notamment :
Il est également important de mettre en place un système de « core developer » même au sein d’un projet privé en entreprise, afin de garantir la cohérence des données et l’intégrité de l’historique. En effet, si tout le monde à les droits d’écriture sur tout, ça finira toujours à un moment donné à partir dans tous les sens… L’idée, c’est de donner les droits d’écriture à seulement 2-3 personnes de confiance qui ont un certain niveau et à tous les autres imposer de faire des forks dans leur namespace gitlab et de proposer des merge request (l’équivalent des pull requests avec github). Ainsi, la revue de code est obligatoire et il n’est plus possible de merger du mauvais code… et les développeurs « standard » (sans droits donc) ont juste 2-3 commandes de base à connaître pour bosser avec les autres. Sans ce genre de système cela ne peut pas réellement fonctionner car git à été developpé pour ce mode de fonctionnement (au même titre que svn et d’autres gestionnaire de version) et donc son workflow est idéal dans ce cadre.
Fonctionner comme ça m’a permis de :
coder un petit robot qui réagissait au merge requests proposé et donc qui checkait tout un tas de choses automatiquement et qui proposait des commandes si les choses n’allaient pas
responsabiliser les gens de l’équipe en les rendant responsables de leur propre forks
faire monter en compétence l’équipe qui était ultra frileuse à faire du versionning puis au final à pris goût au truc…
J’ai fais des petites formations au début pour leur expliquer l’intérêt et expliquer la sémantique des changement et qu’il est important de penser ses commits de manière propre. Cela permet :
dans certains cas de retirer (revert) des bugs complet d’un seul coup,
de faire du debug de manière automatique sans rien toucher et de trouver les changements responsable d’un bug (git bisect),
de faire un gain énorme de qualité au final
d’avoir des historiques clairs avec des messages de commit ayant une réelle plus value (exemple)
d’automatiser tout un tas d’actions qui vont augmenter la qualité globale du projet et vont réduire les taches inutiles et donc laisser plus de temps pour les trucs fun à faire.
C’est gagnant gagnant, mais au début les gens râlent… il faut juste s’y préparer et avec le temps ils changent d’avis !
Google Chrome a plein d’options cachées en ligne de commande, et parmi celles-ci, une option qui permet d’imprimer en PDF.
De plus, si, comme moi, vous ne voulez pas les numéros de pages / nom de fichier en haut et en bas, il vous faut ajouter l’option --print-to-pdf-no-header
J’avais besoin de décaler mes log pour voir rapidement si j’étais, ou pas, à l’intérieur d’une fonction.
Eh oui, après plusieurs années, même si on peut faire des points d’arrêt, JavaScript est là pour répondre à des événements utilisateurs et autres… donc il ne faut souvent pas arrêter pendant l’exécution ou la visualisation d’une page Web… on n’a toujours pas d’autre choix que de faire le bon console.log() des familles qui fait que le développement est extrêmement ralenti…
Je me suis donc crée les fonctions log_in(), log() et log_out().
Ainsi, quand j’entre dans une fonction, j’appelle log_in(), et tous mes log() dans cette fonction seront décalés, ce qui fait que je vois immédiatement où sont appelés mes logs ! Ensuite, ne pas oublier de faire un log_out().
let logLevel = 0;
let log = function () {
let args = Array.from(arguments);
if (logLevel > 0) {
args = [Array(logLevel).fill(' ').join('')].concat(args);
}
console.log.apply(null, args);
};
let log_in = function () {
log.apply(null, arguments);
logLevel++;
}, log_out = function (s) {
if (logLevel>0) {
logLevel--;
}
log.apply(null, arguments);
};
Ces 1er et 2 février avait lieu le FOSDEM (Free and Open Source Developer European Meeting) à l'Université Libre de Bruxelles.
Quelques 5 valeureux aventuriers de Yaal ont fait le voyage en train pour assister aux conférences et rencontrer
des développeurs libres. Et des conférences il y en avait. Beaucoup. Environ 800 conférences en deux jours, autant dire qu'aller au FOSDEM
c'est apprendre à renoncer à pouvoir assister à tout ce qui semble intéressant, ou bien rattraper les manqués sur
le site du FOSDEM.
Quant aux autres conférences, celles auxquelles nous avons assisté, les sujets sont souvent très intéressants et présentés par des speakers
de qualité. On pourra citer « Le futur de Thunderbird », « Le contributeur égoïste », « Le libre dans les municipalités », « L'accessibilité
dans Musescore », « HTTP/3 » etc.
Entre les conférences, des salles sont à disposition pour que des développeurs rencontrent leur communauté, ou que des groupes d'intérêt (autour
d'un logiciel, d'un langage...) puissent échanger. C'est ainsi que nous avons rencontré des développeurs Elixir, ou bien les mainteneurs de sourcehut
So you want to host your own mail server with opensmtpd, but you don't have
time to understand everything going on? Here is an expeditious guide for doing
just that.
In this guide I used OpenSMTPD 6.6.1 on Debian Buster.
Lets start by blindly copy-pasting this snippet to install the dependencies we
will need:
OpenSMTPD has some LDAP support with the opensmtpd-extras package, but not
enough for LDAP authentication. Someone opened a bug
report stating that you can
request some fields from the LDAP server, giving you access to the hashed user
password, but that's it. You do not know which hash algorithm was used, and
even if you did, OpenSMTPD will only use the one provided by
crypt, so there is a good
chance that comparing hashed passwords won't work. Later, an OpenSMTPD
developer
confirmed
that there was no such thing as LDAP authentication in OpenSMTPD, but that one
should rely on standard authentication mechanisms such as PAM or bsd_auth:
[...] OpenSMTPD authenticate using crypt(3) by default, which indeed will
require credentials to be adapted for that function, but it does so through
bsd_auth(3) on OpenBSD and may be configured to use pam(3) on other systems,
so you may just delegate authentication to an ldap layer if you actually
don't want the system's auth to take place.
This seems like the right approach to tackle this issue to me, if I were to
authenticate against ldap, I'd use an ldap authenticator for bsd_auth(3) or
pam(3).
Note that the userbase parameter is not directly linked with user authentication.
It actually defines the list of available recipients. Here is an example of
/etc/mail/ldap.conf:
Without further configuration, the auth keyword in smtpd.conf tells OpenSMTPD
to use PAM authentication. So this is what we should now configure.
PAM
According to its man page, PAM is a system of libraries that handle the
authentication tasks of applications (services) on the system. In Debian, it
mainly consists of a collection of configuration files in /etc/pam.d for
programs that need a generic way to handle authentication, session management,
etc. Each file is a set of rules for one program. Those rules generally use a
pam_foobar.so file depending on the method used (unix, ldap etc.). The idea
is to chain rules to define an authentication policy (e.g. try to authenticate
against the unix backend, if that fails try against LDAP, then if that fails
reject the user). By default, OpenSMTPD will look into the /etc/pam.d/smtpd
file for its rules, so this is where we want to write some configuration. The
pam_ldap.so module we are interested in is provided by the libpam-ldap
package.
Basically, this configuration tells PAM to rely on pam_ldap.so to manage user
accounts and authentication. As you can see, there is not a lot of information
in this file. The Debian documentation
explains that this is because pam_ldap.so delegates everything to Name
Service Switch. The debug keywords are
used for verbosity, and can safely be removed.
NSS
The NSS is provided by the libnss-ldap package. It is a daemon that holds the
LDAP configuration and caches the requests to the LDAP.
You can configure your ldap URI, your search DN and your bind credentials in
/etc/nslcd.conf:
On debian Buster, enabling LDAP on it has a side effect: SSH sessions will try to authenticate against the LDAP via PAM, unless you switch UsePAM to no in /etc/ssh/sshd_config.
Debug your installation
To debug this installation, let's launch all those services manually and make
them verbose:
Note : cet article reprend en grande partie le cours donné à l’École
du Logiciel Libre le 18 mai 2019.
Il s’inspire également des travaux de Robert C. Martin (alias Uncle Bob) sur la question,
notamment sa série de vidéos sur
cleancoders.com1
Comme on l’a vu, utiliser assert ressemble fortement à lever une exception. Dans les deux cas, on veut signaler
à celui qui appelle notre code que quelque chose ne va pas. Mais assert est différent par deux aspects :
Il peut arrive que la ligne contenant assert soit tout simplement ignorée 2.
assert et souvent utilisé pour signaler qu’il y a une erreur dans le code qui a appelé la fonction, et
non à cause d’une erreur “extérieure”
On dit que calc.py est le code de production, et test_calc.py le code de test. Comme son nom l’indique, le code de production sert de base à un produit - un programme, un site web, etc.
On sépare souvent le code de production et le code de test dans des fichiers différents, tout simplement parce que le code de test ne sert pas directement aux utilisateurs du produit. Le code de test ne sert en général qu’aux auteurs du code.
Une petite digression s’impose ici. Selon Robert C. Martin, le code possède une valeur primaire et une valeur secondaire.
La valeur primaire est le comportement du code - ce que j’ai appelé le produit ci-dessus
La valeur secondaire est le fait que le code (et donc le produit) peut être modifié.
Selon lui, la valeur secondaire (en dépit de son nom) est la plus importante : dans software, il y a “soft”, par opposition à hardware. Si vous avez un produit qui fonctionne bien mais que le code est impossible à changer, vous
risquez de vous faire de ne pas réussir à rajouter de nouvelles fonctionnalités,
de ne pas pouvoir corriger les bugs suffisamment rapidement, et de vous faire dépasser par la concurrence.
Ainsi, si le code de test n’a a priori pas d’effet sur la valeur primaire du code (après tout, l’utilisateur
du produit n’est en général même pas conscient de son existence), il a un effet très important sur la valeur secondaire, comme on le verra par la suite.
Avant de poursuivre, penchons-nous sur deux limitations importantes des tests.
Premièrement, les tests peuvent échouer même si le code de production est correct :
deftest_add_one():
result = add_one(2)
assert result == 4
Ici on a un faux négatif. L’exemple peut vous faire sourire, mais c’est un problème plus
fréquent que ce que l’on croit.
Ensuite, les tests peuvent passer en dépit de bugs dans le code. Par exemple, si
on oublie une assertion :
defadd_two(x):
return x + 3deftest_add_two():
result = calc.add_two(3)
# fin du test
Ici, on a juste vérifié qu’appeler add_two(3) ne provoque pas d’erreur. On dit
qu’on a un faux positif, ou un bug silencieux.
Autre exemple :
deffonction_complexe():
if condition_a:
...
if condition_b:
...
Ici, même s’il n’y a que deux lignes commençant par if, pour être
exhaustif, il faut tester 4 possibilités, correspondant aux 4 valeurs
combinées des deux conditions. On comprend bien que plus le code devient
complexe, plus le nombre de cas à tester devient gigantesque.
Dans le même ordre d’idée, les tests ne pourront jamais vérifier le
comportement entier du code. On peut tester add_one() avec des exemples,
mais on voit difficilement commeent tester add_one() avec tous les entiers
possibles. 4
Cela dit, maintenant qu’on sait comment écrire et lancer des tests,
revenons sur les bénéfices des tests sur la valeur secondaire du code.
On a vu comment les tests peuvent mettre en évidence des bugs présents dans le code.
Ainsi, à tout moment, on peut lancer la suite de tests pour vérifier (une partie) du
comportement du code, notamment après toute modification du code de production.
On a donc une chance de trouver des bugs bien avant que les utilisateurs du produit
l’aient entre les mains.
Imaginez un code avec un comportement assez complexe. Vous avez une nouvelle fonctionnalité à
rajouter, mais le code dans son état actuel ne s’y prête pas.
Une des solutions est de commencer par effectuer un refactoring, c’est-à dire de commencer
par adapter le code mais sans changer son comportement (donc sans introduire de bugs). Une fois ce refactoring effectué,
le code sera prêt à être modifié et il deviendra facile d’ajouter la fonctionnalité.
Ainsi, disposer d’une batterie de tests qui vérifient le comportement du programme automatiquement et de manière exhaustive
est très utile. Si, à la fin du refactoring vous pouvez lancer les tests et constater qu’ils passent tous, vous serez plus confiant sur le fait que votre refactoring n’a pas introduit de nouveaux bugs.
Cela peut paraître surprenant, surtout à la lumière des exemples basiques que je vous ai montrés, mais écrire des tests est un art difficile à maîtriser. Cela demande un état d’esprit différent
de celui qu’on a quand on écrit du code de production. En fait, écrire des bons tests est une compétence
qui s’apprend.
Ce que je vous propose ici c’est une discipline : un ensemble de règles et une façon de faire qui vous
aidera à développer cette compétence. Plus vous pratiquerez cette discipline, meilleur sera votre code
de test, et, par extension, votre code de production.
Commençons par les règles :
Règle 1 : Il est interdit d’écrire du code de production, sauf si c’est pour faire passer un test qui
a échoué.
Règle 2 : Il est interdit d’écrire plus de code que celui qui est nécessaire pour provoquer une erreur
dans les tests (n’importe quelle erreur)
Règle 3 : Il est interdit d’écrire plus de code que celui qui est nécessaire pour faire passer
un test qui a échoué
Règle 4 : Une fois que tous les tests passent, il est interdit de modifier le code sans s’arrêter
pour considérer la possibilité d’un refactoring. 5
Et voici une procédure pour appliquer ces règles: suivre le cycle de dévelopement suivant :
Écrire un test qui échoue - étape “red”
Faire passer le test - étape “green”
Refactorer à la fois le code de production et le code de test - étape “refactor”
Le code production a l’air impossible à refactorer, mais jetons un œil aux tests :
importbowlingdeftest_can_create_game():
game = bowling.Game()
deftest_can_roll():
game = bowling.Game()
game.roll(0)
deftest_can_score():
game = bowling.Game()
game.roll(0)
game.score()
Hum. Le premier et le deuxième test sont inclus exactement dans le dernier test. Ils ne servent donc à rien, et
peuvent être supprimés.
⁂RED⁂
En y réfléchissant, can_score() ne vérifie même pas la valeur de retour de score(). Écrivons un test légèrement différent :
Notez qu’on a fait passer le test en écrivant du code que l’on sait être incorrect. Mais la règle 3 nous interdit d’aller plus loin.
Vous pouvez voir cela comme une contrainte arbitraire (et c’en est est une), mais j’aimerais vous faire remarquer qu’on en a fait spécifié
l’API de la classe Game. Le test, bien qu’il ne fasse que quelques lignes,
nous indique l’existence des métode roll() et score(), les paramètres
qu’elles attendent et, à un certain point, la façon dont elles intéragissent
C’est une autre facette des tests: ils vous permettent de transformer une
spécification en code éxecutable. Ou, dit autrement, ils vous permettent
d’écrire des exemples d’utilisation de votre API pendant que vous
l’implémentez. Et, en vous forçant à ne pas écrire trop de code de production,
vous avez la possibilité de vous concentrer uniquement sur l’API de votre code,
sans vous soucier de l’implémentation.
Bon, on a enlevé plein de tests, du coup il n’y a encore plus grand-chose à refactorer,
passons au prochain.
⁂RED⁂
Rappelez-vous, on vient de dire que le code de score() est incorrect. La question devient donc : quel test pouvons-nous
écrire pour nous forcer à écrire un code un peu plus correct ?
Une possible idée est d’écrire un test pour un jeu où tous les lancers renversent exactement une quille :
deftest_all_ones():
game = bowling.Game()
for roll inrange(20):
game.roll(1)
score = game.score()
assert score == 20
> assert score == 20
E assert 0 == 20
⁂GREEN⁂
Ici la boucle dans le test nous force à changer l’état de la
class Game à chaque appel à roll(), ce que nous pouvons faire
en rajoutant un attribut qui compte le nombre de quilles
renversées.
deftest_score_is_zero_after_gutter():
game = bowling.Game()
game.roll(0)
score = game.score()
assert score == 0deftest_all_ones():
game = bowling.Game()
for roll inrange(20):
game.roll(1)
score = game.score()
assert score == 20
Les deux tests sont subtilement différents. Dans un cas, on appelle roll() une fois, suivi immédiatement d’un appel à score().
Dans l’autre, on appelle roll() 20 fois, et on appelle score() à la fin.
Ceci nous montre une ambiguïté dans les spécifications. Veut-on pouvoir obtenir le score en temps réel, ou voulons-nous
simplement appeler score à la fin de la partie ?
On retrouve ce lien intéressant entre tests et API : aurions-nous découvert cette ambiguïté sans avoir écrit aucun test ?
Ici, on va décider que score() n’est appelé qu’à la fin de la partie, et donc réécrire les tests ainsi , en appelant 20 fois
roll(0):
deftest_gutter_game():
game = bowling.Game()
for roll inrange(20):
game.roll(0)
score = game.score()
assert score == 0deftest_all_ones():
game = bowling.Game()
for roll inrange(20):
game.roll(1)
score = game.score()
assert score == 20
Les tests continuent à passer. On peut maintenant réduire la duplication en introduisant une fonction roll_many :
defroll_many(game, count, value):
for roll inrange(count):
game.roll(value)
deftest_gutter_game():
game = bowling.Game()
roll_many(game, 20, 0)
score = game.score()
assert score == 0deftest_all_ones():
game = bowling.Game()
roll_many(game, 20, 1)
score = game.score()
assert score == 20
⁂RED⁂
L’algorithme utilisé (rajouter les quilles renversées au score à chaque lancer) semble fonctionner tant qu’il n’y a ni spare ni strike.
Du coup, rajoutons un test sur les spares :
deftest_one_spare():
game = bowling.Game()
game.roll(5)
game.roll(5) # spare, next roll should be counted twice game.roll(3)
roll_many(game, 17, 0)
score = game.score()
assert score == 16
Ce code a un problème : en fait, c’est la méthode roll() qui calcule le score, et non la fonction score() !
On comprend que roll() doit simplement enregistrer l’ensemble des résultats des lancers, et qu’ensuite seulement,
score() pourra parcourir les frames et calculer le score.
⁂REFACTOR⁂
On remplace donc l’attribut knocked_pins() par une liste de rolls et un index:
classGame:
def __init__(self):
self.rolls = [0] * 21 self.roll_index = 0defroll(self, pins):
self.rolls[self.roll_index] = pins
self.roll_index += 1defscore(self):
result = 0for roll in self.rolls:
result += roll
return result
Petit aparté sur le nombre 21. Ici ce qu’on veut c’est le nombre maximum de frames.
On peut s’assurer que 21 est bien le nombre maximum en énumérant les cas possibles
de la dernière frame, et en supposant qu’il n’y a eu ni spare ni strike au cours
du début de partie (donc 20 lancers, 2 pour chacune des 10 premières frame)
spare: on va avoir droit à un un lancer en plus: 20 + 1 = 21
strike: par définition, on n’a fait qu’un lancer à la dernière frame, donc au plus 19 lancers, et 19 plus 2 font bien 21.
sinon: pas de lancer supplémentaire, on reste à 20 lancers.
L’algorithme est toujours éronné, mais on sent qu’on une meilleure chance de réussir à gérer les spares.
⁂RED⁂
On ré-active le test en enlevant la ligne @pytest.mark.skip et on retombe évidemment sur la même erreur :
> assert score == 16
E assert 13 == 16
⁂GREEN⁂
Pour faire passer le test, on peut simplement itérer sur les frames une par une, en utilisant
une variable i qui vaut l’index du premier lancer de la prochaine frame :
defscore(self):
result = 0 i = 0for frame inrange(10):
if self.rolls[i] + self.rolls[i + 1] == 10: # spare result += 10 result += self.rolls[i + 2]
i += 2else:
result += self.rolls[i]
result += self.rolls[i + 1]
i += 2return result
Mon Dieu que c’est moche ! Mais cela me permet d’aborder un autre aspect du TDD. Ici, on est dans la phase “green”. On fait tout ce qu’on peut
pour faire passer le tests et rien d’autre. C’est un état d’esprit particulier, on était concentré sur l’algorithme en lui-même.
⁂REFACTOR⁂
Par contraste, ici on sait que l’algorithme est correct. Notre unique objectif est de rendre le code plus lisible. Un des avantages de TDD est qu’on passe d’un objectif précis à l’autre, au lieu d’essayer de tout faire en même temps.
Bref, une façon de refactorer est d’introduire une nouvelle méthode :
# note: i represents the index of the# first roll of the current framedefis_spare(self, i):
return self.rolls[i] + self.rolls[i + 1] == 10defscore(self):
result = 0 i = 0for frame inrange(10):
if self.is_spare(i):
result += 10 result += self.rolls[i + 2]
i += 2else:
result += self.rolls[i]
result += self.rolls[i + 1]
i += 2
En passant, on s’est débarrassé du commentaire “# spare” à la fin du if, vu qu’il n’était plus utile. En revanche, on a gardé un commentaire au-dessus
de la méthode is_spare(). En effet, il n’est pas évident de comprendre la valeur représentée par l’index i juste en lisant le code. 7
On voit aussi qu’on a gardé un peu de duplication. Ce n’est pas forcément très grave, surtout que l’algorithme est loin d’être terminé. Il faut encore gérer les strikes et la dernière frame.
Mais avant cela, revenons sur les tests (règle 4) :
deftest_one_spare():
game = bowling.Game()
game.roll(5)
game.roll(5) # spare, next roll should be counted twice game.roll(3)
roll_many(game, 17, 0)
score = game.score()
assert score == 16
On a le même genre de commentaire qui nous suggère qu’il manque une abstraction quelque part : une fonction roll_spare.
importbowlingimportpytestdefroll_many(game, count, value):
for roll inrange(count):
game.roll(value)
defroll_spare(game):
game.roll(5)
game.roll(5)
deftest_one_spare():
game = bowling.Game()
roll_spare(game)
game.roll(3)
roll_many(game, 17, 0)
score = game.score()
assert score == 16
Les tests continuent à passer, tout va bien.
Mais le code de test peut encore être amélioré. On voit qu’on a deux fonctions qui prennent chacune le même paramètre en premier argument.
Souvent, c’est le signe qu’une classe se cache quelque part.
On peut créer une classe GameTest qui hérite de Game et contient les méthodes roll_many() et roll_spare() :
importbowlingimportpytestclassGameTest(bowling.Game):
defroll_many(self, count, value):
for roll inrange(count):
self.roll(value)
defroll_spare(self):
self.roll(5)
self.roll(5)
deftest_gutter_game():
game = GameTest()
game.roll_many(20, 0)
score = game.score()
assert score == 0deftest_all_ones():
game = bowling.GameTest()
game.roll_many(20, 1)
score = game.score()
assert score == 20deftest_one_spare():
game = GameTest()
game.roll_spare()
game.roll(3)
game.roll_many(17, 0)
score = game.score()
assert score == 16
Ouf! Suffisamment de refactoring pour l’instant, retour au rouge.
⁂RED⁂
Avec notre nouvelle classe définie au sein de test_bowling.py (on dit souvent “test helper”), on peut facilement rajouter le test sur les strikes :
A priori, tous les tests devraient passer sauf le dernier, et on devrait avoir une erreur de genre x != 24, avec x légèrement en-dessous de 24 :
________________________________ test_all_ones _________________________________
def test_all_ones():
> game = bowling.GameTest()
E AttributeError: module 'bowling' has no attribute 'GameTest'
_______________________________ test_one_strike ________________________________
def test_one_strike():
game = GameTest()
game.roll_strike()
game.roll(3)
game.roll(4)
game.roll_many(16, 0)
score = game.score()
> assert score == 24
E assert 17 == 24
test_bowling.py:48: AssertionError
Oups, deux erreurs ! Il se trouve qu’on a oublié de lancer les tests à la fin du dernier refactoring. En fait, il y a une ligne qui a été changée de façon incorrecte : game = bowling.GameTest() au lieu de game = GameTest(). L’aviez-vous remarqué ?
Cela illustre deux points :
Il faut toujours avoir une vague idée des tests qui vont échouer et de quelle manière
Il est important de garder le cycle de TDD court. En effet, ici on sait que seuls les tests ont changé depuis la dernière session de test, donc on sait que le problème vient des tests et non du code de production.
On peut maintenant corriger notre faux positif, relancer les tests, vérifier qu’ils échouent pour la bonne raison et passer à l’étape suivante.
Là encore, on a tous les éléments pour implémenter la gestion de strikes correctement, grâce aux refactorings précédents et au fait qu’on a implémenté l’algorithme de façon incrémentale, un petit bout à la fois.
classGame:
...
defis_spare(self, i):
return self.rolls[i] + self.rolls[i + 1] == 10defis_strike(self, i):
return self.rolls[i] == 10defscore(self):
result = 0 i = 0for frame inrange(10):
if self.is_strike(i):
result += 10 result += self.rolls[i + 1]
result += self.rolls[i + 2]
i += 1elif self.is_spare(i):
result += 10 result += self.rolls[i + 2]
i += 2else:
result += self.rolls[i]
result += self.rolls[i + 1]
i += 2return result
J’espère que vous ressentez ce sentiment que le code “s’écrit tout seul”. Par contraste, rappelez-vous la difficulté pour implémenter les spares et imaginez à quel point cela aurait été difficile de gérer les spares et les strikes en un seul morceau !
⁂REFACTOR⁂
On a maintenant une boucle avec trois branches. Il est plus facile de finir le refactoring commencé précédement, et d’isoler les lignes qui se ressemblent des lignes qui diffèrent :
classGame:
...
defis_strike(self, i):
return self.rolls[i] == 10defis_spare(self, i):
return self.rolls[i] + self.rolls[i + 1] == 10defnext_two_rolls_for_strike(self, i):
return self.rolls[i + 1] + self.rolls[i + 2]
defnext_roll_for_spare(self, i):
return self.rolls[i + 2]
defrolls_in_frame(self, i):
return self.rolls[i] + self.rolls[i + 1]
defscore(self):
result = 0 i = 0for frame inrange(10):
if self.is_strike(i):
result += 10 result += self.next_two_rolls_for_strike(i)
i += 1elif self.is_spare(i):
result += 10 result += self.next_roll_for_spare(i)
i += 2else:
result += self.rolls_in_frame(i)
i += 2return result
On approche du but, il ne reste plus qu’à gérer la dernière frame.
⁂RED⁂
Écrivons maintenant le test du jeu parfait, où le joueur fait un strike à chaque essai. Il y a donc 10 frames de strike, puis deux strikes (pour les deux derniers lancers de la dernière frame) soit 12 strikes en tout.
Et comme tout joueur de bowling le sait, le score maximum au bowling est 300 :
deftest_perfect_game():
game = GameTest()
for i inrange(0, 12):
game.roll_strike()
assert game.score() == 300
Ici, je vais vous laisser 5 minutes de réflexion pour vous convaincre qu’en realité, la dernière
frame n’a absolument rien de spécial, et que c’est la raison pour laquelle notre algorithme
fonctionne.
D’abord, je trouve qu’on peut être fier du code auquel on a abouti :
result = 0 i = 0for frame inrange(10):
if self.is_strike(i):
result += 10 result += self.next_two_rolls_for_strike(i)
i += 1elif self.is_spare(i):
result += 10 result += self.next_roll_for_spare(i)
i += 2else:
result += self.rolls_in_frame(i)
i += 2
Le code se “lit” quasiment comme les règles du bowling. Il a l’air correct, et il est correct.
Ensuite, même si notre refléxion initiale nous a guidé (notamment avec la classe Game et ses deux méthodes),
notez qu’on a pas eu besoin des classes Frame ou Roll, ni de la classe fille TenthFrame. En ce sens, on peut dire que TDD est également
une façon de concevoir le code, et pas juste une façon de faire évoluer le code de production et le code de test en parallèle.
Enfin, on avait un moyen de savoir quand le code était fini. Quand on pratique TDD, on sait qu’on peut s’arrêter dès que tous les tests
passent. Et, d’après l’ensemble des règles, on sait qu’on a écrit uniquement le code nécessaire.
1/ La méthode roll() peut être appelée un nombre trop grand de fois, comme le prouve le test suivant :
deftest_two_many_rolls():
game = GameTest()
game.roll_many(21, 1)
assert game.score() == 20
Savoir si c’est un bug ou non dépend des spécifications.
2/ Il y a probablement une classe ou une méthode cachée dans la classe Game. En effet, on a plusieurs méthodes qui prennent toutes un index en premier paramètre, et le paramètre en question nécessite un commentaire pour être compris.
Résoudre ces deux problèmes sera laissé en exercice au lecteur :P
Voilà pour cette présentation sur le TDD. Je vous recommande d’essayer cette méthode par vous-mêmes. En ce qui me concerne elle a changé ma façon d’écrire du code en profondeur, et après plus de 5 ans de pratique, j’ai du mal à envisager de coder autrement.
À +
C’est payant, c’est en anglais, les exemples sont en Java, mais c’est vraiment très bien. ↩︎
Par exemple, quand on lance python avec l’option -O↩︎
Voir cet article pour comprendre pourquoi on procède ansi. ↩︎
Il existe de nombreux outils pour palier aux limitations des tests, mais on en parlera une prochaine fois. ↩︎
Les trois premières règles sont de Uncle Bob, la dernière est de moi. ↩︎↩︎
Vous avez tout à fait le droit d’écrire du code en français. Mais au moindre doute sur la possibilité qu’un non-francophone doive lire votre code un jour, vous devez passer à l’anglais. ↩︎
Si cette façon de commenter du code vous intrigue, vous pouvez lire cet excellent article (en anglais) pour plus de détails. ↩︎
Ne vous lancez pas dans le port sans une bonne couverture de tests.
Les changements entre Python2 et Python3 sont parfois très subtils,
donc sans une bonne couverture de tests vous risquez d’introduire
pas mal de régressions.
Dans mon cas, j’avais une couverture de 80%, et la plupart des problèmes ont été
trouvés par les (nombreux) tests automatiques (un peu plus de 900)
Voici les étapes que j’ai suivies. Il faut savoir qu’à la base je comptais
passer directement en Python3, sans être compatible Python2, mais en cours
de route je me suis aperçu que ça ne coûtait pas très cher de rendre
le code “polyglotte” (c’est comme ça qu’on dit) une fois le gros du travail
pour Python3 effectué.
Lancez 2to3 et faites un commit avec le patch généré
Lancez les tests en Python3 jusqu’à ce qu’ils passent tous
Relancez tous les tests en Python2, en utilisant six pour rendre
le code polyglotte.
Assurez vous que tous les tests continuent à passer en Python3, commitez
et poussez.
Note 1 : je ne connaissais pas python-future à
l’époque. Il contient un outil appelé futurize qui transforme directement
du code Python2 en code polyglotte. Si vous avez des retours à faire sur cet
outil, partagez !
Note 2 : Vous n’êtes bien sûr pas obligés d’utiliser six si vous n’avez pas
envie. Vous pouvez vous en sortir avec des if sys.version_info()[1] < 3, et autres
from __future__ import (voir plus bas). Mais certaines fonctionnalités de six
sont compliquées à ré-implémenter à la main.
Note 3 : il existe aussi pies
comme alternative à six. Voir
ici
pour une liste des différences avec six. Personnellement, je trouve
pies un peu trop “magique” et je préfère rester explicite. De plus,
six semble être devenu le “standard” pour le code Python polyglotte.
Voyons maintenant quelques exemples de modifications à effectuer.
C’est le changement qui a fait le plus de bruit. Il est très facile
de faire du code polyglotte quand on utilise print. Il suffit de faire le bon import au début du fichier.
from__future__importprintprint("bar:", bar)
Notes:
L’import de __future__ doit être fait en premier
Il faut le faire sur tous les fichiers qui utilisent print
Il est nécessaire pour avoir le même comportement en Python2 et
Pyton3. En effet, sans la ligne d’import, print("bar:", "bar") en
Python2 est lu comme “afficher le tuple ("foo", bar)”, ce qui n’est
probablement pas le comportement attendu.
Il n’y a pas de solution miracle, partout où vous avez des chaînes de
caractères, il va falloir savoir si vous voulez une chaîne de caractères
“encodée” (str en Python2, bytes en Python3) ou “décodée” (unicode en
Python2, str en Python3)
Deux articles de Sam qui abordent très bien la question:
Personnellement, j’ai tendance à n’utiliser que des imports absolus.
Faisons l’hypothèse que vous avez installé un module externe bar,
dans votre système (ou dans votre virtualenv) et que vous avez déjà un fichier
bar.py dans vos sources.
Les imports absolus ne changent pas l’ordre de résolution quand
vous n’êtes pas dans un paquet. Si vous avez un fichier foo.py et un
fichier bar.py côte à côte, Python trouvera bar dans le répertoire courant.
En revanche, si vous avec une arborescence comme suit :
src
foo
__init__.py
bar.py
Avec
# in foo/__init__.pyimportbar
En Python2, c’est foo/bar.py qui sera utilisé, et non lib/site-packages/bar.py. En Python3 ce sera l’inverse,
le fichier bar.py, relatif à foo/__init__ aura la priorité.
Pour vous éviter ce genre de problèmes, utilisez donc :
from__future__import absolute_import
Ou bien rendez votre code plus explicite en utilisant un point :
from.import bar
Vous pouvez aussi:
Changer le nom de votre module pour éviter les conflits.
Utiliser systématiquement import foo.bar (C’est ma solution
préférée)
six est notamment indispensable pour supporter les métaclasses, dont
la syntaxe a complètement changé entre Python2 et Python3. (Ne vous amusez
pas à recoder ça vous-mêmes, c’est velu)
En Python2, range() est “gourmand” et retourne la liste entière dès qu’on
l’appelle, alors qu’en Python3, range() est “feignant” et retourne un
itérateur produisant les éléments sur demande. En Python2, si vous
voulez un itérateur, il faut utiliser xrange().
Partant de là, vous avez deux solutions:
Utiliser range tout le temps, même quand vous utilisiez
xrange en Python2. Bien sûr il y aura un coût en performance, mais
à vous de voir s’il est négligeable ou non.
Ou bien utiliser six.moves.range() qui vous retourne un itérateur
dans tous les cas.
En fait en Python3, keys() retourne une “vue”, ce qui est différent de
la liste que vous avez en Python2, mais qui est aussi différent de l’itérateur
que vous obtenez avec iterkeys() en Python2. En vrai ce sont des
view objects.
La plupart du temps, cependant, vous voulez juste itérer sur les clés
et donc je recommande d’utiliser 2to3 avec --nofix=dict.
Bien sûr, keys() est plus lent en Python2, mais comme pour
range vous pouvez ignorer ce détail la plupart du temps.
Faites attention cependant, le code plantera si vous faites :
raise MyException, message
try:
# ....except MyException, e:
# ...# Do something with e.message
C’est une très vielle syntaxe.
Le code peut être réécrit comme suit, et sera polyglotte :
raise MyException(message)
try:
# ....except MyException as e:
# ....# Do something with e.args
Notez l’utilisation de e.args (une liste), et non
e.message. L’attribut message (une string) n’existe que dans
Python2. Vous pouvez utiliser .args[0] pour récupérer le message d’une
façon polyglotte.
Comme mentionné plus haut, le développement du projet a dû continuer
sans attendre que le support de Python3 soit mergé.
Le port a donc dû se faire dans une autre branche (que j’ai appelé six)
Du coup, comment faire pour que la branche ‘six’ reste à jour ?
La solution passe par l’intégration continue. Dans mon cas j’utilise
jenkins
À chaque commit sur la branche de développement, voici ce qu’il se passe:
La branche ‘six’ est rebasée
Les tests sont lancés avec Python2 puis Python3
La branche est poussée (avec --force).
Si l’une des étapes ne fonctionne pas (par exemple, le rebase ne
passe pas à cause de conflits, ou bien l’une des suites de test échoue),
l’équipe est prévenue par mail.
Ainsi la branche six continue d’être “vivante” et il est trivial et
sans risque de la fusionner dans la branche de développement au moment
opportun.
J’aimerais remercier Eric S. Raymond qui m’a donné l’idée de ce billet suite
à un article sur son blog et m’a autorisé
à contribuer à son
HOWTO, suite
à ma
réponse
N’hésitez pas en commentaire à partager votre propre expérience
(surtout si vous avez procédé différemment) ou vos questions, j’essaierai
d’y répondre.
Il vous reste jusqu’à la fin de l’année avant l’arrêt du support de Python2 en 2020,
et ce coup-là il n’y aura probablement pas de report. Au boulot !
Vous connaissez peut-être le rôle de la variable d’environnement PATH. Celle-ci contient une liste de chemins,
et est utilisée par votre shell pour trouver le chemin complet des commandes que vous lancez.
Par exemple:
PATH="/bin:/usr/bin:/usr/sbin"$ ifconfig
# lance le binaire /usr/sbin/ifconfig$ ls
# lance le binaire /bin/ls
Le chemin est “résolu” par le shell en parcourant la liste de tout les segments de PATH, et en regardant si le chemin complet
existe. La résolution s’arrête dès le premier chemin trouvé.
Par exemple, si vous avez PATH="/home/user/bin:/usr/bin" et un fichier ls dans /home/user/bin/ls, c’est ce fichier-là
(et non /bin/ls) qui sera utilisé quand vous taperez ls.
Notez que le résultat dépend de ma distribution, et de la présence ou non du répertoire ~/.local/lib/python3.7/ sur ma machine - cela prouve que sys.path est construit dynamiquement par l’interpréteur Python.
Notez également que sys.path commence par une chaîne vide. En pratique, cela signifie que le répertoire courant a la priorité sur tout le reste.
Ainsi, si vous avez un fichier random.py dans votre répertoire courant, et que vous lancez un script foo.py dans ce même répertoire, vous vous retrouvez à utiliser le code dans random.py, et non celui de la bibliothèque standard ! Pour information, la liste de tous les modules de la bibliothèque standard est présente dans la documentation.
Un autre aspect notable de sys.path est qu’il ne contient que deux répertoires dans lesquels l’utilisateur courant peut potentiellement écrire : le chemin courant et le chemin dans ~/.local/lib. Tous les autres (/usr/lib/python3.7/, etc.) sont des chemins “système” et ne peuvent être modifiés que par un compte administrateur (avec root ou sudo, donc).
La situation est semblable sur macOS et Windows 2.
$ python3 foo.py
--------- ---
John 345
Mary-Jane 2
Bob 543
--------- ---
Ici, le module tabulate n’est ni dans la bibliothèque standard, ni écrit par l’auteur du script foo.py. On dit que c’est une bibliothèque tierce.
On peut trouver le code source de tabulate facilement. La question qui se pose alors est: comment faire en sorte que sys.path contienne le module tabulate?
Une autre méthode consiste à partir des sources - par exemple, si le paquet de votre distribution n’est pas assez récent, ou si vous avez besoin de modifier le code de la bibliothèque en question.
La plupart des bibliothèques Python contiennent un setup.py à
la racine de leurs sources. Il sert à plein de choses, la commande install
n’étant qu’une parmi d’autres.
Le fichier setup.py contient en général simplement un import de setuptools, et un appel à la fonction setup(), avec de nombreux arguments :
Par défaut, setup.py essaiera d’écrire dans un des chemins système de
sys.path3, d’où l’utilisation de l’option --user.
Voici à quoi ressemble la sortie de la commande :
$ cd src/tabulate
$ python3 setup.py install --user
running install
...
Copying tabulate-0.8.4-py3.7.egg to /home/dmerej/.local/lib/python3.7/site-packages
...
Installing tabulate script to /home/dmerej/.local/bin
Notez que module a été copié dans ~/.local/lib/python3.7/site-packages/ et le script dans ~/.local/bin. Cela signifie que tous les scripts Python lancés par l’utilisateur courant auront accès au module tabulate.
Notez également qu’un script a été installé dans ~/.local/bin - Une bibliothèque Python peut contenir aussi bien des modules que des scripts.
Un point important est que vous n’avez en général pas besoin de lancer le script directement. Vous pouvez utiliser python3 -m tabulate. Procéder de cette façon est intéressant puisque vous n’avez pas à vous soucier de rajouter le chemin d’installation des scripts dans la variable d’environnement PATH.
pip est un outil qui vient par défaut avec Python34. Vous pouvez également l’installer grâce au script get-pip.py, en lançant python3 get-pip.py --user.
Il est conseillé de toujours lancer pip avec python3 -m pip. De cette façon, vous êtes certains d’utiliser le module pip correspondant à votre binaire python3, et vous ne dépendez pas de ce qu’il y a dans votre PATH.
pip est capable d’interroger le site pypi.org pour retrouver les dépendances, et également de lancer les différents scripts setup.py.
Comme de nombreux outils, il s’utilise à l’aide de commandes. Voici comment installer cli-ui à l’aide de la commande ‘install’ de pip:
On y retrouve les bibliothèques cli-ui et tabulate, bien sûr, mais aussi la bibliothèque gaupol, qui correspond au programme d’édition de sous-titres que j’ai installé à l’aide du gestionnaire de paquets de ma distribution. Précisons que les modules de la bibliothèque standard et ceux utilisés directement par pip sont omis de la liste.
On constate également que chaque bibliothèque possède un numéro de version.
Souvenez-vous que les fichiers systèmes sont contrôlés par votre gestionnaire de paquets.
Les mainteneurs de votre distribution font en sorte qu’ils fonctionnent bien les uns
avec les autres. Par exemple, le paquet python3-cli-ui ne sera mis à jour que lorsque tous les paquets qui en dépendent seront prêts à utiliser la nouvelle API.
En revanche, si vous lancez sudo pip (où pip avec un compte root), vous allez écrire dans ces mêmes répertoire et vous risquez de “casser” certains programmes de votre système.
Supposons deux projets A et B dans votre répertoire personnel. Ils dépendent tous les deux de cli-ui, mais l’un des deux utilise cli-ui 0.7 et l’autre cli-ui 0.9. Que faire ?
La commande python3 -m venv fonctionne en général partout, dès l’installation de Python3 (out of the box, en Anglais), sauf sur Debian et ses dérivées 5.
Si vous utilisez Debian, la commande pourrait ne pas fonctionner. En fonction des messages d’erreur que vous obtenez, il est possible de résoudre le problème en :
installant le paquet python3-venv,
ou en utilisant d’abord pip pour installer virtualenv, avec python3 -m pip install virtualenv --user puis en lançant python3 -m virtualenv foo-venv.
Le répertoire “global” dans ~/.local/lib a disparu
Seuls quelques répertoires systèmes sont présents (ils correspondent plus ou moins à l’emplacement des modules de la bibliothèque standard)
Un répertoire au sein du virtualenv a été rajouté
Ainsi, l’isolation du virtualenv est reflété dans la différence de la valeur de sys.path.
Il faut aussi préciser que le virtualenv n’est pas complètement isolé du reste du système. En particulier, il dépend encore du binaire Python utilisé pour le créer.
Par exemple, si vous utilisez /usr/local/bin/python3.7 -m venv foo-37, le virtualenv dans foo-37 utilisera Python 3.7 et fonctionnera tant que le binaire /usr/local/bin/python3.7 existe.
Cela signifie également qu’il est possible qu’en mettant à jour le paquet python3 sur votre distribution, vous rendiez inutilisables les virtualenvs créés avec l’ancienne version du paquet.
Cette fois, aucune bibliothèque n’est marquée comme déjà installée, et on récupère donc cli-ui et toutes ses dépendances.
On a enfin notre solution pour résoudre notre conflit de dépendances :
on peut simplement créer un virtualenv par projet. Ceci nous permettra
d’avoir effectivement deux versions différentes de cli-ui, isolées les
unes des autres.
Devoir préciser le chemin du virtualenv en entier pour chaque commande peut devenir fastidieux ; heureusement, il est possible d’activer un virtualenv, en lançant une des commandes suivantes :
source foo-venv/bin/activate - si vous utilisez un shell POSIX
source foo-venv/bin/activate.fish - si vous utilisez Fish
foo-venv\bin\activate.bat - sous Windows
Une fois le virtualenv activé, taper python, python3 ou pip utilisera les binaires correspondants dans le virtualenv automatiquement,
et ce, tant que la session du shell sera ouverte.
Le script d’activation ne fait en réalité pas grand-chose à part modifier la variable PATH et rajouter le nom du virtualenv au début de l’invite de commandes :
# Avant
user@host:~/src $ source foo-env/bin/activate
# Après
(foo-env) user@host:~/src $
Pour sortir du virtualenv, entrez la commande deactivate.
Le système de gestions des dépendances de Python peut paraître compliqué et bizarre, surtout venant d’autres langages.
Mon conseil est de toujours suivre ces deux règles :
Un virtualenv par projet et par version de Python
Toujours utiliser pipdepuis un virtualenv
Certes, cela peut paraître fastidieux, mais c’est une méthode qui vous évitera probablement de vous arracher les cheveux (croyez-en mon expérience).
Dans un futur article, nous approfondirons la question, en évoquant d’autres sujets comme PYTHONPATH, le fichier requirements.txt ou des outils comme poetry ou pipenv. À suivre.
C’est une condition suffisante, mais pas nécessaire - on y reviendra. ↩︎
Presque. Il peut arriver que l’utilisateur courant ait les droits d’écriture dans tous les segments de sys.path, en fonction de l’installation de Python. Cela dit, c’est plutôt l’exception que la règle. ↩︎
Cela peut vous paraître étrange à première vue. Il y a de nombreuses raisons historiques à ce comportement, et il n’est pas sûr qu’il puisse être changé un jour. ↩︎
Presque. Parfois il faut installer un paquet supplémentaire, notamment sur les distributions basées sur Debian ↩︎
Je n’ai pas réussi à trouver une explication satisfaisante à ce choix des mainteneurs Debian. Si vous avez des informations à ce sujet, je suis preneur. Mise à jour: Il se trouve que cette décision s’inscrit au sein de la “debian policy”, c’est à dire une liste de règles que doivent respecter tous les programmes maintenus par Debian.↩︎
Cet article est le premier d’un tout nouveau blog (sur https://dmerej.info/blog/fr), contenant exclusivement des articles en français.
Notez l’existence de mon blog anglophone, qui est disponible sur
https://dmerej.info/blog. Pour l’instant, les deux blogs sont complémentaires:
aucun article n’est la traduction directe d’un autre, mais
cela pourra changer un jour, qui sait ?
Dernière arrivée chez Yaal (mais plus pour longtemps normalement : on recrute !), je voulais ajouter ma pierre à l'édifice de ce blog en vous parlant d'une chose assez chouette de la vie interne à Yaal : l'existence de clubs en tout genre.
En fait à la base je voulais plutôt partager les dernières actions du club-zéro-déchet mais je me suis dit qu'une petite intro plus générale au concept de club serait plus pertinente pour commencer...
Des clubs, pour quoi faire ?
La notion de club est assez floue car ils ne prennent pas tous la même forme. Grosso modo un club nait chaque fois qu'un groupe de personnes ayant un intérêt commun se dit : "tiens, et si on créait un club pour en discuter/partager des sources et des idées/organiser des trucs/trouver d'autres gens intéressés et conquérir le monde" (rayez la mention inutile).
À ce jour il doit exister une vingtaine de clubs différents sur des thèmes aussi improbables éclectiques que : club-vélo , club-ciné , club-salade (oui oui salade1), club-politique , club-dessin-écriture , club-pycharm ET club-vim, ...
Concrètement ça fonctionne comment ?
Ben concrètement ça dépend surtout de chaque club !
Vu la diversité des thèmes, ça peut ressembler à différentes choses mais le plus petit dénominateur commun de la formation d'un club semble être l'existence d'un salon dédié sur notre outil de messagerie interne SlackRiot/Matrix.2
Les clubs ont envahi notre répertoire de salons Riot
Certains clubs n'existent d'ailleurs que sous cette forme (pour l'instant le club-ciné , le club-musique ou le club-sciences par exemple, qui servent principalement à partager nos coups de cœur et débats -toujours hautement philosophiques et éclairés ça va sans dire- sur tel ou tel contenu).
C'est aussi pratique pour partager notre veille métier dans les clubs dédiés (à peine plus sérieux) que sont club-dev , club-infra , club-sécu ...
D'autres servent plutôt à programmer un temps d'activité ensemble. C'est le cas du club-sport, qui malgré une dizaine d'abonné⋅es faisant semblant d'être intéressé⋅es par le sport (j'en fais partie.....) n'est en fait actif que le jeudi matin lorsque les 3 courageux⋅ses de la boîte confirment ou annulent leur participation à la séance du jeudi midi piscine.
Le club-dessin-écriture (Yaal ne manque pas de talents artistiques 💚)(et de groupies desdits talents) programme également régulièrement de courtes sessions créatives de cette manière.
Un des derniers nés est le club-bière qui ne consiste pas (que) à consommer de la bière en groupe (ça c'est plutôt l'objectif du club-glouglou , alter ego du club-miammiam où on décide ce qu'on va manger le midi) mais plutôt à lancer la production de la yaal-beer, notre propre bière fabriquée avec amour. (On est encore au stade de prototype mais certain⋅es n'hésitent pas à voir les choses en grand et à se lancer dans des calculs de rendements industriels… Vers l'infini et au delà !).
Au club-zéro-déchet on essaie plutôt de se réunir 30 minutes tous les mardis pour décider et mettre en place des actions collectives visant à réduire notre production de déchets à Yaal : meilleure gestion de notre compost, réduction des déchets à emporter lorsque l'on va acheter à manger à l'exterieur, etc.
Ce qui est sûr c'est que les choses sont loin d'être figées. Les clubs naissent, vivent (et meurent aussi probablement) selon les volontés et l'intérêt des gens qui les composent. Aucune obligation d'y participer, aucune restriction pour en créer de nouveaux (vu qu'il suffit en fait de trouver une ou deux personnes intéressées par le même sujet et de créer un nouveau salon dans Riot).
Une façon assez simple et spontanée d'entretenir des dynamiques auto-gérées ! Et de partager de l'inspiration, des fruits, de l'eau d'source, du fun.
Nous avons migré de Slack vers Riot/Matrix avec succès en début d'année 🎉
Si vous voulez un retour d'expérience il faudra convaincre Fx, l'initiateur du projet, de vous en parler dans un autre billet de blog... 😇 ↩
Yaal monte en puissance et nous recrutons 3 développeur·ses !
Culture organisationnelle. Nous pensons que pour des résultats excellents, il est essentiel de constituer des équipes aux compétences complémentaires, prenant soin d'elles-mêmes et de leurs clients : réactives et fiables, curieuses et apprenantes, communicantes et bienveillantes.
Nous sommes une trentaine de personnes -- développeur·ses, designers, administrateurs systèmes et experts sécurité, product managers et facilitateur.rices.
Nous nous structurons en équipes auto-organisées au service d'un de nos produits, selon les besoins des produits et les appétences de chacun.
Produits. Nos produits vont du service de messenging via SMS, RCS, ou WhatsApp, en passant par des bots conversationnels comme Messenger et des outils d'interconnexions avec les systèmes informatiques de nos clients.
Recherche actuelle. Nous recherchons actuellement des personnes au goût prononcé pour la programmation, le travail en équipe, capable de prendre des initiatives, et désirant devenir excellentes.
Les compétences techniques que nous recherchons en particulier sont la conception logicielle (de l'architecture au développement dirigé par les tests), avec des enjeux de complexité fonctionnelle, de fiabilité, et de performance d'exécution sur de gros volumes de données.
Rémunération. Selon le profil et l'expérience. À titre indicatif, nous proposerons à un ingénieur débutant quelque chose autour de 30K€. Nous avons certains avantages supplémentaires, comme du matériel de travail confortable choisi par chacun, la mutuelle prise en charge à 100% pour la famille, et des vélos de fonction.
Coopération. Au bout d'un an, si l'envie se concrétise, nous vous offrirons la possibilité de devenir associé·e avec, comme en société coopérative, une voix par personne.
Dans le cadre de la mise en place de nos services, nous commençons à travailler avec un fournisseur d'accès Internet (FAI) associatif nommé Aquilenet opérant en Aquitaine, membre d'une fédération de FAI alternatifs non commerciaux .
L'intérêt pour nous est d'avoir une meilleure maîtrise de notre écosystème numérique, impliquant des interlocuteurs locaux avec qui nous pouvons parler et participer à un développement local. Pour l'aspect opérationnel, nous avons pu ainsi mettre en place un serveur et annoncer nos adresses IPv4 et IPv6 hébergées à Bordeaux.
Aquilenet, créée en 2010, fournit de l'accès Internet ADSL, VPN et bientôt fibre grand public (FTTH), et a des infrastructures hébergées en datacenter associatif ou professionnel. Aquilenet, qui est une association loi 1901, n'est pas animée par des objectifs commerciaux et nous partageons les principes de neutralité du Net qu'elle porte.
Diverses structures et projets sont hébergés chez eux et nous sommes fiers de les rejoindre pour participer au développement d'un Internet libre, solidaire et local.
Le FOSDEM (pour Free and Open source Software Developers' European Meeting) est la plus grosse conférence dédiée aux logiciels libres d'Europe. La conférence durait deux jours, pendant un week-end au début de Février, à l'Université Libre de Bruxelles.
Ce n'est pas la première fois que des membres de Yaal participent à des conférences (PyconFr, Blend Web Mix, NewsCrafts Bordeaux, etc.) mais il s'agit clairement de la plus grande à laquelle nous soyons allés jusqu'ici. En effet, la conférence est gigantesque : elle utilise 34 salles réparties sur plusieurs bâtiments de l'université. Il y a donc de nombreuses conférences en même temps sur des thèmes variés (bases de données, BSD, virtualisation, Rust, Python, micronoyaux et bien d'autres).
Avec plus de 8.000 participants, les salles sont facilement remplies. Ci-dessous, la salle plénière. Les autres salles sont plus petites (soit des salles de cours, soit des amphithéâtres) et sont parfois pleines. Lorsque c'est le cas, la salle est bloquée et il n'est plus possible d'y entrer. Si vous souhaitez voir une conférence en particulier, il est préférable d'y être un peu en avance pour être sûr de rentrer. Cette année, une présentation sur http/3 a laissé pas mal de monde hors de la salle.
Comme la conférence est généraliste, c'est l'occasion d'en apprendre un peu plus sur un domaine que l'on connait mal ou réviser ses classiques (exemple : « 25 Years of FreeBSD »). De même si l'on souhaite rencontrer des personnes impliquées dans un sujet particulier, idéalement si un BoF (Birds of a feather) est organisé. Par contre, si vous souhaitez vous concentrer sur un seul sujet, ce n'est probablement la conférence la plus adaptée. Par exemple, les conférences Python étaient limitées au dimanche uniquement, dans une seule salle. Sachant que Python était un langage bien représenté ; il n'y en avait pas autant pour Ruby ou Perl.
Certaines présentations sont disponibles sur https://video.fosdem.org/2019/ ; comparer les salles avec le programme devrait aider à trouver les présentations qui vous intéressent le plus.
Il est prévu de vérifier l'année prochaine si c'est aussi bien tous les ans. 😉
Une partie de Yaal s’est rendue à Lyon pour assister à Blend Web Mix la semaine dernière. L’occasion de participer aux « deux jours les plus web de l’année » !
Métiers du web et conscience globale
Entre questionnements sur les identités numériques, propriété des données, modèles mentaux, entreprises libérées et place du designer dans un monde en déclin, beaucoup de conférences proposaient de réfléchir à nos engagements au quotidien. Dans nos métiers du web et dans notre vie privée, comment influençons-nous le monde qui nous entoure ?
Chez Yaal, ces réflexions et ces engagements sont inhérents à notre ADN.
Prendre du recul face à nos pratiques, essayer de nous impliquer dans des causes qui nous tiennent à coeur, favoriser la résilience et la collaboration… Ce sont ces sujets d’importance globale, abordés cette année à Blend, qui nous tiennent à coeur. Nous sommes ravis de voir qu’ils passionnent de plus en plus de monde !
Une belle réussite organisationnelle…qui peut encore progresser
Encore merci aux organisateurs et aux bénévoles pour avoir fait de cet événement un moment convivial et fort en rencontres inspirantes. Seul bémol noté par notre équipe, un petit effort sur la quantité de déchets généré à l’heure du déjeuner permettrait à l’événement de passer un cap. Histoire d’éviter une dichotomie entre un engagement affiché et une gestion écologique à revoir. Une problématique que nous savons compliquée pour des événements de cette taille, et nous espérons qu'une solution sera trouvée pour les prochaines éditions
Sketchnotes et vidéos : récapitulatif en image !
Pour ceux qui n’ont pas pu être de la partie, nos designers sont revenus avec quelques sketchnotes des conférences auxquels elles ont pu assister.
Les voici, avec les vidéos des conférences correspondantes (pour celles qui ont été filmées):
Activiste et justicier social du digital (selon ses propres termes), Aral cherche les alternatives, en cours ou à venir, pour rester des Humains libres et reprendre la main notre vie privée, à l’heure du Web et des objets connectés.
“What’s in their minds? Modèles mentaux et design d'interaction”
Jean-Christophe PARIS (@akiani) - UX Researcher, Docteur en Ingénierie des Facteurs Humains, Directeur associé @Akiani
Définition des modèles mentaux, qui sont propres à chaque individu, et l’une des clés de la compréhension de ce qui se passe dans la tête d’un utilisateur qui interagit avec un système, dans la vie réelle et numérique.
La vidéo
Sketchnote de @Margauxlergo, UX Designer indépendante dont nous avons apprécié le coup de crayon.
Sketchnote sur la prise en compte des modèles mentaux pour désigner de meilleures expériences utilisateur. Par Jean-Christophe Paris de @akiani à #blendwebmixpic.twitter.com/RUpyCGAYQE
Quels sont les intérêts pour une entreprise de baser sa communication visuelle sur l'illustration ? À travers des conseils et des études de cas, J.P Cabaroc explique comment justifier la mise en place et la création d'identités visuelles illustrées.
“Un ‘joli’ template ne rendra pas votre site utilisable”
Stéphanie Walter (@WalterStephanie) - UX Designer & Mobile Expert
La collaboration entre Dévs et UX Designers est un sujet qui revient souvent dans le Web. Et pour cause, l’UX est un des plus jeunes métiers issus du marché de la toile, et qui, à l’instar des autres postes “créatifs”
La vidéo
Son article récapitulatif
En complément de la vidéo, Stéphanie a mis à disposition un article de blog récapitulatif de son intervention, dans lequel vous pouvez retrouver son support de conférence. À lire ici:
-> L'article de Stéphanie Walter
Ces deux chercheurs travaillent sur des idées d’atterrissage, de design sociétal résilient et respectueux des humains et des non-humains, sur l’avenir (ou la fin) des technologies et la réorientation (« fermeture ») du progrès. Ils partent pour ce faire de l’Anthropocène, l’ère où l’influence de l’être humain sur la planète et l’écosystème dont il fait partie est désormais indéniable.
Matthias Dugué (alias m4dz) essaie de sensibiliser aux enjeux d’aujourd’hui et de demain sur les réalités du numérique. Revenu du passé, le concept de Privacy by Design connaît une forte hausse de popularité auprès des startups qui s’empressent de s’estampiller « Privacy compliant ». Les promesses sont-elles toujours tenues pour autant?
“Améliorer la participation des personnes handicapées à la société (enfin!) grâce à l'accessibilité numérique”
Sylvie Duchateau (@sylduch) - Associée, Médiatrice en accessibilité numérique @Access42
Un fantastique plaidoyer sur l'importance de produire des contenus accessibles pour le web, parsemé de cas pratiques et de solutions à mettre en place pour creuser le sujet suite à la conférence.
On parle souvent d’UX design pour l’utilisateur final, mais l’UX des outils destinés aux équipes de développement en interne est tout aussi importante pour obtenir des interfaces plus cohérentes, utilisables et accessibles et ainsi, gagner du temps lors du design et des développements.
Comment passer d’une pratique du métier de designer à un outil d’émancipation? Quels chemins à prendre pour les designers? Comment ne pas travailler à l’encontre de ses propres idéaux? Geoffrey Dorne nous sensibilise à la collapsologie, et interroge les possibles méthodes pour atteindre la résilience et l’indépendance.
La vidéo
Son article récapitulatif
En complément à son intervention, Geoffrey Dorne a mis à disposition sur son blog son support de présentation ainsi que ses impressions personnelles concernant sa conférence. Retrouvez-les ici :
Vous voulez découvrir le sketchnoting ? Ça tombe bien, on y a consacré un article sur le blog de Livres de Proches pour bien débuter : Introduction au sketchnote
Nous sommes très fiers d'avoir sponsorisé et participé cette année à la NewCrafts Bordeaux 2018.
Zoé, Pierre, Noah ainsi que moi-même avons passé 2 journées formidables et mon seul regret est de ne pas avoir pu me joindre aux autres participants pour l'after party au Golden Apple !
Pendant ces deux jours, nous avons pu assister à des conférences aussi intéressantes qu'éclectiques, passant de la gestion des logs à la sociologie bourdieusienne.
Des présentations au tableau certes, mais également de belles rencontres et discussions !
Merci à tous pour ces échanges passionnés à l'espace pain au chocolat, l'espace chocolatine (je vous laisse trancher ce débat), ou même la terrasse où nous avons profité d'un temps exceptionnel pour une fin de septembre.
Merci également pour tous vos conseils de lectures, retours d'expériences, anecdotes, avec une mention spéciale pour Brian Marick, tout droit venu du Portugal pour nous faire part de ses connaissances sur la programmation fonctionnelle ainsi que d'anecdotes très intéressantes.
Bravo aux organisateurs qui ont effectués un travail exceptionnel durant toute cette NCraft, l'accueil était parfait durant ces deux jours.
Chercher des informations dans des logs informes ou dans des tracebacks est à bien des égards une activité frustrante. À Yaal nous utilisons donc sentry, qui est capable d'agréger, de contextualiser et de mettre en forme les logs et les tracebacks que nous générons. Couplé à un système d'alertes efficace, l'outil s'avère très utile pour savoir ce qui se passe en production, et diagnostiquer rapidement lorsque surgissent des problèmes.
Dans la phase itérative du développement d'une fonctionalité, on génère souvent beaucoup d'erreurs temporaires et sans grande valeur. Les capacités qu'a Sentry à contextualiser et mettre en forme une erreur sont intéressante, mais on se passerait bien de l'historique et des alertes dans ce cas de figure. En plus de ça, ça fait un outil (de plus) à ouvrir, une page à actualiser... Bref, lorsque l'on développe et qu'un bug se produit, on veut avoir une information riche et lisible rapidement.
D'aucuns argueront que pour débugger, on utilise un debugger. Certes, mais l'utilisation d'un debugger est assez lourde, et de fait elle n'est pas automatique. De plus, on peut chercher à obtenir une information claire et instantanée sur des exceptions dans des contextes où un debugger n'est pas forcément pertinent. Je pense notamment dans des cas où l'on exécute en même temps plusieurs programmes qui interagissent entre eux (des démons, des serveurs web...), on ne lance pas un débugger derrière chaque programme dans ces cas-là avant (du moins, pas avant d'avoir rencontré un bug).
Comparons quelques outils de mise en forme de backtrace python, en gardant quelques critères en tête :
La capacité de mettre une traceback en couleur ;
La capacité de contextualiser les appels (afficher les quelques lignes de code avant ou après) ;
La capacité d'afficher les variables locales à chaque étape de la stack ;
Les methodes d'utilisation et l'invasivité (hook qui s'installe et attrape toutes les exceptions, utilisation manuelle dans des try-except, utilisation comme module python ex:python -m foobar monscript.py) ;
L'intégration dans une stack web (middleware WSGI) ;
Le packaging avec pip et les dépendances ;
L'activité et la taille du projet.
Un exemple de traceback dans sentry
Nous ne nous intéresseront pas à l'affichage des tracebacks dans les programmes de test unitaires.
Outils orienté terminal
Prenons un exemple de code en python s'exécutant dans un terminal.
Un script simple
L'affichage par défaut des tracebacks python donne le minimum d'information, mais on pourrait sans doute faire mieux. Où est la mise en forme ? Quelles sont les variables locales à chaque étape de la pile ?
backtrace
backtrace est un petit projet (30 commits) disponible dans pip. Il s'utilise seulement en hook, s'axe sur une mise en forme succincte et colorée, avec quelques options de personnalisation. Les variables locales ne peuvent pas être affichées mais la fonctionnalité est envisagée.
backtrace comme hook
colored-traceback
colored-traceback est un petit projet (9 commits) disponible dans pip. Il se présente comme un module python ou un hook, et se contente de rajouter de la couleur aux tracebacks générées par python, en gardant la même mise en forme. Il y a un petit problème dans l'utilisation par le module python : colored-traceback apparaît lui-même dans la traceback, ce qui n'est facilite pas sa lisibilité.
colored-traceback utilisé comme module
colored-traceback comme hook
pygments
pygments est un outil de coloration syntaxique en python actif, disponible sur pip. pygments est capable de colorer des tracebacks python mais se cantonne à son rôle de coloration syntaxique, donc aucune mise en forme ou contexte ne sont ajoutés. Aucune aide n'est disponible non plus pour attraper les exceptions de manière automatique dans le code. On peut s'en sortir en écrivant un hook, ou une fonction de traitement dans un block try-except. Le binaire pygmentize fourni dans le paquet permet tout de coloriser la sortie standard d'un script python.
hook fait-main avec pygments
sortie standard capturée avec pygmentize
IPython ultratb
IPython est shell python assez puissant (avec coloration, autocomplétion et autres) disponible dans pip. Par défaut il met en forme les tracebacks avec son module ultratb. Ultratb peut s'utiliser soit comme un hook qui attrape et traîte les exception d'un script, ou dans un bloc try-except. Ultratb est surtout utilisé par défaut dans IPython, donc utiliser ipython comme interpréteur à la place de python peut suffir à afficher une traceback mise en forme. Plusieurs thèmes de couleur, et plusieurs mises en formes sont disponibles. Parmi les mises en forme proposés, on peut afficher une traceback simple, colorée avec ColorTB, ou une traceback avec du contexte, de la couleur, et le contenu des variables locales avec VerboseTB. Il semblerait qu'on ne puisse pas installer ultratb sans installer IPython.
Un script simple avec IPython
ultratab comme hook
ultratab dans un try-except
ultratab en mode verbeux
Outils orienté web
cgitb
cgitb est un mystère. C'est un module cœur de python, originellement utilisé pour générer des pages HTML mettant en forme des tracebacks, mais il peut aussi être utilisé pour du texte. Le module existe depuis Python 2.2 mais il a l'air assez peu connu du web, les deux paragraphes de documentation n'inspirent pas confiance, (deux nouveaux paragraphes ont été écrits pour python 3.8 \o/). Il existe un hook, mais il ne fait qu'écrire sur la sortie standard, sans doute est-ce un reliquat de l'époque où on l'utilisait dans des CGI. Néanmoins, en utilisant les fonctions non documentées du module, on peut arriver à générer des backtraces plutôt riches et avec du contexte. Par contre, pour des couleurs ou des pages web lisibles, on repassera. Les pages web générées sont aussi hideuses que leur code, et la sortie texte est monochrome. Les hooks, l'affichage dans un try-except sont possibles, mais en l'écrivant à la main.
try-except avec cgitb
Une magnifique page web générée par cgitb
django
Le célèbre framework web django permet de mettre en forme les tracebacks python qui peuvent survenir lors de la génération d'une page web. Le module est dans le cœur de django, et n'est pas facilement réutilisable hors django. Il ne génère une traceback monochrome mise en forme, avec du contexte et des variables locales.
Traceback web avec django
werkzeug
Werkzeug embarque un middleware WSGI qui produit des pages HTML riches et belles, avec des accordéons pour ne pas la charger. L'intégration est très facile. Werkzeug permet en plus d'ouvrir un debugger interactif si le serveur d'application le permet. On regrettera cependant l'absence de variables locales et de couleurs.
Traceback web avec werkzeug
Conclusion
Voici un tableau récapitulant les résultats des critères que nous avons observé sur les différents outils :
sentry
ultratb
backtrace
colored-traceback
pygments
cgitb
django
werkzeug
couleur
✓
✓
✓
✓
✓
✗
✗
✗
contexte
✓
✓
✗
✗
✗
✓
✓
✓
variables locales
✓
✓
✗
✗
✗
✓
✓
✗
hook
✓
✓
✓
✓
✗
✗(pour CGI)
✗
✗
try except
✓
✓
✗
✗
✗
✗
✗
✗
module python ou interpréteur
✗
✓
✗
✓(bof)
✗
✗
✗
✗
lecture sur l'entrée standard
✗
✗
✗
✗
✓
✗
✗
✗
middleware WSGI
✓
✗
✗
✗
✗
✗
✓
✓
sortie texte
✗
✓
✓
✓
✓
✓
✗
✗
sortie html
✗
✗
✗
✗
✗
✓(mais hiddeuse)
✓
✓
projet très actif
✓
✓
✗
✗
✓
✓ dans python peu soutenu
✓
✓
dédié à l'affichage de tracebacks
✓
✗
✓
✓
✗
✓
✗
✗
paquet pip
✓
✓
✓
✓
✓
✓(déjà dans python)
✓
✓
La conclusion que l'on peut tirer est qu'il n'existe pas d'outil remplissant tous les critères. ultratb semble être la meilleure option pour l'affichage en console, même s'il est embarqué dans IPython. Quant au monde du web, seul werkzeug semble sortir du lot, malgré qu'il ne soit pas dédié à la fonction d'afficher des tracebacks.
L'outil idéal pour mettre en forme des tracebacks, polyvalent, lisible et puissant, reste à développer. On peut cependant s'en tirer relativement correctement en utilisant ultratb pour l'affichage en terminal et werkzeug pour l'affichage web.
C'est pour la nouvelle année que les locaux de Yaal ont fait peau neuve. En faisant appel à l'agence Hivoa, la start-up a souhaité un espace design, convivial et confortable. L'investisseur technique est présent dans le quartier de la Victoire depuis 2014.
Yaal est un tech angel qui s'associe à des projets prometteurs et éthiques, partage le risque avec eux et développe leur solution web et/ou mobile.
L’équipe compte une vingtaine de personnes et regroupe différents métiers : développeurs, designers, graphistes, chefs de projet, communicants et commerciaux. Lors de sa création en 2010, la start-up a été incubée à l'Auberge numérique ainsi qu’à la pépinière éco-créative des Chartrons.
Yaal a acheté ce local de 140m² dans le quartier Saint-Michel en 2014. Il était important de s'implanter au coeur de la ville, pour le confort des équipes mais aussi parce que l’entreprise accueille régulièrement des événements de l'écosystème du numérique ou liés à l'ESS (Économie Sociale et Solidaire).
Les fondateurs on fait appel à l'agence Hivoa, parce qu’ils aimaient leur travail, partageaient la même vision et aussi parce qu'ils sont du cru. D'ailleurs tous les artisans qui sont intervenus sont bordelais. Yaal souhaite être acteur de l'économie locale.
Différents espaces ont été aménagés : deux openspaces accueillants chacun une dizaine de postes de travail, une cuisine, un garage à vélo vertical et en sous-sol, une grande salle de réunion, une cuisine et un espace « chill-out » et visio-conférence.
Le bien-être des équipes est ici une priorité : l'environnement de travail contribue à l'épanouissement.
Le confort d'abord, avec des postes de travail ergonomiques, des matériaux naturels et de qualité, des équipements high-tech, etc.
Mais la start-up va plus loin en visant le zéro-déchet, elle recycle et composte au maximum.
Quelles sont les prochaines étapes pour Yaal ?
Victime de son succès Yaal va devoir bientôt pousser les murs ! En perpétuel recrutement de talents, le tech angel cherche à étendre ses locaux pour accueillir une dizaine de personnes supplémentaires sur l’année 2018.
Le monde de l'open source est une vaste jungle où se cotoient des projets en taille, formes et couleurs diverses et variées.
Devant la diversité et la technicité, il est difficile de faire des choix technologiques éclairés.
Faute d'arguments tangibles, les développeurs, comme tout consommateurs, sont sujets à des biais importants liés à leurs habitudes et leur ressenti affectif.
Les projets redoublent alors d'imagination pour vanter leurs mérites : «scalable», «lightweight», «performant», «flexible», «easy to use», «no dependency»... Ces fourre-tous, à la fois subjectifs et non quantifiés, sont des exemples de discours marketing, alors qu'un professionel doit pouvoir comparer des solutions sur des bases objectives.
Je vais vous donner quelques clés d'évaluations des solutions de monitoring que je connais, ce que nous avons choisi à Yaal et pourquoi.
Je vous partage ici mon expérience, d'une part en tant que développeur de solution de monitoring, d'autre part en tant qu'utilisateur de divers outils.
Du besoin de monitoring
Le monitoring est un secteur en plein boom dans l'industrie informatique qui connait depuis plusieurs années des croissances fortes. Les études de marché lui donnent des perspectives pour le moins encourageantes : le marché devrait prendre encore 50% d'ici 2024 (source). La startup Datadog a réalisé début 2016 une levée de fond de près de 100 000 000$ (source). Une longue liste de projets de monitoring opensource ont vu s'accumuler des communautés respectables, telles que celle de Sensu (2600 «stars» sur github), et d'autres projets stables tels que Shinken, Nagios ou Zabbix...
Les raisons sous-jacentes sont liés à l'évolution des systèmes informatiques. Ils sont non seulement toujours plus nombreux, mais aussi toujours plus vastes, toujours plus complexes, leurs enjeux sont aussi économiquement critiques. Surveiller l'évolution et le bon fonctionnement des systèmes a donc intrinsèquement une valeur croissante.
Pour une entreprise technologique les enjeux du monitoring sont multiples : avoir un système monitoré, c'est se donner les chances d'être réactif en cas de panne, de cibler les optimisations, et de provisionner correctement le besoin matériel. En somme, le monitoring est à l'informatique ce que la business intelligence est au commerce : un enjeu stratégique de premier ordre.
Il existe près d'une centaine de solutions avec des approches parfois très différentes. Pour ce secteur encore plus que pour d'autres, le choix est difficile car il n'existe aucune référence incontestable. La raison est qu'il est difficile de quantifier ce qui constitue un monitoring efficace, ce qui est «le besoin» : le monitoring recouvre en fait un ensemble de besoins.
Se pose alors la question, comment mesurer l'efficacité d'une solution ? Quelles métriques choisir, et quel coût raisonnable pour les atteindre ?
Une définition claire
Tel que je définis le monitoring, le monitoring d'un système s'évalue simplement par le fait que les informations pertinentes sont accessibles.
Un fantasme communément admis serait qu'un système puisse efficacement proactivement notifier d'un dysfonctionnement. Cela peut exister pour des événements exceptionnels simple, comme par exemple avertir que le site principal ne répond plus (et encore, on s'expose à nombre de faux positifs type coupure réseau localisée momentanée, du spam pendant les maintenances etc. et bon nombre de faux négatifs également). Mais il est impossible de généraliser ce fonctionnement à l'ensemble d'un système complexe, car il est difficile ou impossible pour un système de qualifier précisément l'importance d'une 404, d'une 500, d'un crash d'application, voire même d'une machine. Cette importance est entièrement situationnelle et demande de connaître l'organisation qui utilise ce système.
Les solutions lourdes de monitoring tentent de résoudre ces problèmes par effort de configuration. L'idée est de pré-qualifier l'importance de certains systèmes ou erreurs afin de pré-filtrer les avertissements. Mais on s'aperçoit en réalité que même avec cet effort coûteux, après mise en place, les avertissements sont lus à posteriori et requalifiés par un être humain qui suit une routine - lui envoyer un mail équivalait donc à lui rendre des informations pertinentes accessibles !
Mais qu'est-ce que la pertinence et l'accessibilité d'une information ?
Patterns et anti-patterns
La pertinence
Pour qu'une information soit pertinente, elle doit être en premier lieu entièrement qualifiée :
elle doit répondre à quoi (qu'est-ce qui se passe ?), quand (un timestamp), où (sur quelle machine/processus), et assez souvent également combien (une quantité ou une fréquence).
Elle doit également répondre à une question, couvrir une éventualité impactante. Pour cela, il peut être nécessaire de la condenser ou de la coupler avec d'autres informations. Par exemple, un événement de visite sur un site, en tant que seule information, est peu pertinent, mais avoir une vue globale du nombre de visites et pouvoir rapprocher ces événements avec une charge serveur peut constituer une information pertinente. C'est pourquoi il est intéressant de collecter un vaste panel d'information.
Le panel choisi gagne à être diversifié. Il est intéressant de combiner des métriques précises et concrètes, correspondant à une réalité tangible (Exemple : un temps de réponse exprimé en ms) avec des agrégations de résultats dont les seuils sont aisément interprétés (Exemple : le load average); avoir également une approche multiniveau en combinant des métriques système, universelles, à des métriques applicatives, spécifique, de haut niveau.
C'est de cette façon que l'on peut créer à la fois la vue d'ensemble nécessaire comme de pouvoir descendre au plus près de problèmes précis.
L'accessibilité
Une fois cette collecte effectuée, il est indispensable d'avoir la possibilité de filtrer et explorer les données : filtrer par date, par type (erreur/warning/debug/métrique etc.), par application et par machine, sans que ces opérations soient pénibles : puisqu'accéder à ces informations est une routine, elle doit être au maximum simplifiée.
Sur tous ces points, certains canaux ou technologies sont plus ou moins efficaces. Les technologies classiques présentes d'ailleurs souvent de grosses faiblesses.
Prenons l'exemple d'un fichier de log : il est indexé par le temps, et son information est plutôt qualifiée. La pertinence des informations est variable : il s'agit d'informations isolées et souvent redondantes.
Il s'agit également d'un des pires média quant à l'accès à l'information : pour y accéder, je dois d'abord savoir quel fichier ouvrir sur quelle machine, et je n'ai pas beaucoup d'options de filtre.
La présentation des quantités est également crue. En bref, c'est facile à mettre en place, mais la qualité est au mieux médiocre. Le mail n'est pas beaucoup mieux : en terme pratique, il s'agit d'un log dépliable.
Le bon pattern constitue l'élaboration d'un dashboard interactif et efficacement présenté. Les informations qu'il contient sont automatiquement synthétisées et mises à jour. Il peut se compléter par un certain nombre d'options pour naviguer parmis différentes données. Il doit contenir autant des données chiffrées que des informations d'événements pouvant servir de base à un ticket de développement ou de maintenance.
Notre choix
Ce premier balayage fait, il intervient alors des considérations concernant la pérénité de la solution choisie, de manière à minimiser le risque d'avoir choisi une technologie dépréciée. Il est toujours plus confortable de bénéficier d'une solution ayant un large écosystème présent et futur. Pour cette dernière partie, j'ai tendance à penser qu'il est préférable de se tourner solutions ayant découplé la collecte, le stockage et le rendu. Ces briques logicielles faisant appel à des expertises différentes, elles bénéficient généralement à être séparées et intéragir par un standard ouvert qui permet la libre concurrence.
Dans ce cas, c'est la technologie de stockage qui définit le plus profondément la solution. Il existe deux orientations : une orientation plus orientée événement, c'est le cas en particulier de la technologie Elasticsearch (fréquemment associé à Logstash et Kibana donnant ELK) : elle est éprouvée et solide. L'autre solution est plus récente et plus orientée métrique : il s'agit de notre choix, InfluxDb. Cette base de données permet la gestion du stockage des données indexées dans le temps, à la fois métriques et logs. Lorsqu'elle est correctement structurée, la base de données permet une compression temporelle des données (retention policy et downsampling), aussi bien que la gestion des filtres par des tags qui peuvent représenter les machines, les types de logs...
Nous y avons associé Grafana qui permet de voir des dashboard, produit des graphes lisibles qu'il est possible de templater, et les deux s'interfacent avec un effort de configuration minimale. Il est par ailleurs très joli.
Notre processus de collecte est quant à lui en cours d'industrialisation, mais pourrait être réalisé soit par de simple scripts, par Collectd ou Telegraph.
Les logiciels et les services web évoluent au fil du temps, selon les redéfinitions des besoins utilisateurs, l'émergence de nouveaux besoins, l'adaptation à de nouveaux marchés, etc.
Pour cela, le code source est modifié et complété. Il faut modifier l'existant, au minimum pour insérer le nouveau code. Le plus souvent, il s'agit de raffiner l'existant et donc principalement faire des modifications. L'exemple suivant montre un an d'évolution du code sur un projet existant depuis quelques années, sur lequel plusieurs personnes travaillent au quotidien. La quantité d'évolution montre les lignes de code ajoutées, modifiées et supprimées :
En valeur absolue
En part relative
Le graphique montre bien le fait les programmeurs passent surtout du temps à relire le code existant et le faire évoluer plutôt que d'écrire des pans entiers à partir d'une feuille vierge. D'où l'importance d'avoir un code source simple et lisible.
Les projets grossissent au fil du temps puisqu'il faut surtout modifier et ajouter des nouveautés. Supprimer des fonctionnalités n'arrive quasiment jamais. Les principales opportunités pour enlever du code sont donc :
la factorisation : supprimer des duplications de code source
l'externalisation : remplacer du code spécifique au projet pour le remplacer par une bibliothèque, un framework, etc.
NB : les données proviennent d'un projet existant depuis quelques années, sur lequel plusieurs personnes travaillent au quotidien.
Comme tous les ans depuis 2013, Yaal a sponsorisé la PyConFr 2016. Arthur, Pierre, Stéphane et moi-même nous sommes rendus cette année à Rennes pour participer à l’événement.
Nous avons eu l’occasion de partager de bons moments avec la communauté Python francophone, mais également quelques intervenants internationaux. Je pense notamment à Ipsha Bhidonia qui nous a présenté les Web Push Notifications et nous fait part de son retour d’expérience sur son blog.
Nous en profitons également pour remercier tous les intervenants qui au cours de ces quatre jours ont contribué à différent projets dans les sprints et présentés des conférences de qualité dont les vidéos sont disponibles en ligne.
Yaal a également pris part à ces conférences grâce à Pierre et sa présentation Test Tout Terrain, encourageant les non-initiés à faire leurs premiers pas vers les tests en python (vidéo disponible ici) et Stéphane avec son lighning talk sur MarkdownMail, un outils créé par Yaal et disponible sur pypi.
Le développement par le test est une pratique que nous affectionnons particulièrement chez Yaal. Nous souhaitons donc mentionner Boris Feld qui a également prêché la bonne parole avec sa présentation Python testing 101.
Pour finir nous souhaitons remercier tous les organisateurs et bénévoles qui ont rendu cette PyConFr 2016 possible. En espérant vous recroiser l’an prochain !
Nous avons écrits des bibliothèques génériques qui nous simplifient la vie en réutilisant les mêmes composants génériques entre plusieurs services. Ces bibliothèques sont disponibles lors de la création de virtualenv car ils sont disponibles sur un dépôt privé (livré par devpi) que nous hébergeons. Ainsi, lorsque nous créons un virtualenv, les paquets python disponibles sont l'union des paquets disponibles sur pypi.python.org ainsi que ceux que nous avons produits.
Lorsque nous avons publié MarkdownMail, une de ces bibliothèques, directement sur pypi.python.org dans l'espoir qu'elle puisse servir à d'autres, nous en avons tiré quelques enseignements :
C'est facile ! :-)
Étant donné que la structure de la bibliothèque était déjà faite préalablement, il y avait peu de travail à ce niveau-là. Les améliorations réalisées pour la publication sont listées par la suite.
Pour publier sur pypi.python.org, il suffit de créer un compte sur le service et le valider (soit un clic dans un e-mail). Ensuite, les paramètres passé au setup.py permettent de réserver un nom disponible puis d'envoyer une nouvelle version vers pypi.python.org (cf. https://docs.python.org/3.4/distutils/packageindex.html).
Classifiers
Les classifiers du setup.py aident les utilisateurs à avoir une idée de l'application ou de la bibliothèque.
Ils servent aussi pour trouver plus facilement ce que l'on cherche parmi les paquets disponibles.
Nous nous en servions déjà en interne pour définir certains éléments, en particulier pour expliciter la compatibilité de nos bibliothèques avec python 2 et/ou python 3. Il a suffit d'en rajouter certains pour être plus complet.
README
Ajouter un fichier README à la racine est un moyen habituel de documenter la bibliothèque. En faisant lire son contenu comme description longue dans le fichier setup.py, il sera affiché sur la page du paquet et sera donc directement lisible par les utilisateurs.
Si le texte est au format reStructuredText (reST), alors il est affiché en html automatiquement. Dans le cas contraire, il sera simplement affiché comme du texte brut, dans une police à chasse variable. Dans ce cas, le rendu n'est pas très lisible, en particulier pour les exemples de code source.
reST ressemble à du Markdown mais n'en est pas. Pour ceux qui publient le code sur GitHub, GitHub fait un rendu HTML des README au format reST, et pas uniquement au format Markdown.
Tox
En rendant la bibliothèque publique, il est bon de valider les tests avec plusieurs versions de python. En interne, les versions sur lesquelles le code doit fonctionner sont connues (2.7 ou 3.4 actuellement chez nous).
Tox est l'outil classique pour le faire et son intégration avec setup.py est documentée.
Devpi + pypi.python.org
Une fois que la bibliothèque est déjà présente en interne via devpi, il n'est plus possible d'en récupérer une plus récente sur pypi.python.org. Cela est dû à des raisons de sécurité : dans le cas contraire, un attaquant connaissant le nom d'un paquet utilisé en interne pourrait envoyer un paquet plus récent sur pypi.python.org. Ensuite, lors de la création d'un nouveau virtualenv, ce paquet serait installé au lieu du paquet interne, provoquant par la suite l'exécution du code de l'attaquant et non le code développé par le créateur de la bibliothèque.
Pour rendre ce cas possible, il suffit de modifier la configuration de devpi. Nous avons ajouté MarkdownMail à une liste blanche pour limiter l'effet de la modification.
Pyroma
Pyroma permet de connaitre les éléments manquants à un paquet. Il permet de tester les différents éléments de la bibliothèque pour améliorer la qualité du paquet. Par exemple, il signale l'absence des champs « keywords » ou « licence ». Pyroma ne remplace pas des outils vérifiant PEP8.
Environnement de dév. pour pypi.python.org
pypi.python.org permet d'envoyer la bibliothèque vers un dépôt de tests pour valider une bibliothèque avant de la rendre accessible au reste du monde. Pour cela, il suffit de préciser le dépôt dans lequel insérer une nouvelle version d'un paquet (grâce au paramètre -r).
De nouvelles évolutions sont envisagées pour améliorer l'usage de MarkdownMail pour les développeurs externes à Yaal, comme le fait de simplifier la possibilité de signaler des bogues ou faire des patchs. Cependant ces évolutions sont indépendantes de pypi. Le fait de publier cette bibliothèque nous a permis de l'améliorer et, plus généralement, de progresser sur les paquets python.
C’est la première édition de Sud Web à laquelle nous participons, nous étions ainsi très curieux du format que ce rassemblement allait prendre.
La première journée proposait des conférences sur différentes thématiques. Bien accueillis par des viennoiseries et du café pour bien commencer la journée, nous avons très vite enchaîné avec le programme du jour. Les différents speakers se sont relayés tout du long via différents formats de conférences allant de 5 à 30 minutes. Les plus longues étant entrecoupées par des plus courtes pour dynamiser la programmation.
Le fil rouge qui articulait les talks entre eux, était une allégorie du fait de grandir. La maîtresse de cérémonie - une ex-ingénieur, à présent comédienne (Pauline Calmé) - jouait la carte de l’humour, en illustrant au travers de courtes scénettes les différents âges de la vie, de l’enfance à l’âge adulte. Cela permettait d’introduire les conférences sous un angle différent, évitait le moment de blanc entre les intervenants, permettait de détendre le public et symbolisait le cheminement du domaine du web, de ses balbutiements jusqu’à son âge actuel.
Côté speakers, de nombreux points positifs sont à mentionner : une envie de partager des expériences, une passion pour leur travail et une capacité de vulgarisation de leurs sujets pour qu’ils soient accessibles à tous. A Sud Web, on essaie de parler à tout le monde, que l’on soit ingénieur ou designer. Les problématiques et les expériences remontées sont suffisamment globales pour que personne ne soit mis de côté.
L’aspect très ancré dans l’actualité des thématiques abordées était fort appréciable : le talk sur le Code & Travail par Rachel Saada, avocate au barreau de Paris, les questionnements et inquiétudes concernant le marché du travail soulevés par Roxane Debruyker ou encore l’intervention de Matthew Caruana Galizia - journaliste et développeur web à l’ICIJ - sur le traitement et l’exploitation des données dans l’affaire des Panama Papers; sont le reflet de ce qu’il se passe dans la société et comment cela impacte le domaine du web dans lequel nous travaillons.
La présence d’une quasi-parité au niveau des intervenants est également un point suffisamment rare au sein des conférences pour être souligné. Sur 17 intervenants, notons la présence de 7 femmes, issues de toutes professions - de l’ingénierie au design - et d’une maîtresse de cérémonie.
Niveau organisation, les conférences étant ponctuées par des moments de pause pendant lesquels il était possible d’échanger tous ensemble et avec les speakers. L’avantage de suivre toutes les conférences est de pouvoir débattre pendant ces instants sociaux. C’est l’occasion de rencontrer des visages que l’on ne connait que via les réseaux, de se confronter à des profils nouveaux et d’échanger ensemble.
La soirée de vendredi regroupait tous les participants au Potato Head, ce qui permettait de discuter dans un cadre plus intimiste et de prolonger les échanges débutés dans la journée. L’avantage des places limitées amenant un format plus convivial aux visiteurs et favorisant l’interaction par petits groupes.
Nous avons beaucoup apprécié le retour de Stefanie Posavec sur son projet mené sur 52 semaines intitulé «Dear Data».
Avec une autre designer d’informations, elles s’étaient données pour challenge de choisir d’enregistrer différents type de données de la vie de tous les jours et de se les envoyer mutuellement par la poste, avec chaque semaine une thématique différente : le nombre de fois où elles avaient dit merci, le nombre de fois où elles avaient rit, … et de les traduire sous forme de data visualisation sur des cartes postales à l’aide de crayons de couleurs, de feutres et d’autres outils de dessin traditionnel.
La démarche regorge d’idées intéressantes et porte un regard nouveau sur ces petits gestes du quotidien que l’on fait sans s’en rendre vraiment compte et que la technologie ne peut pas (encore !) enregistrer.
Journée 2 - Le forum ouvert
La deuxième journée reposait sur un système d’auto-organisation, via un forum ouvert.
Les participants se réunissaient dans un lieu où différentes salles étaient mises à leur disposition pour organiser des ateliers, des débats, des séances de réflexion collectives sur des thématiques que tout le monde pouvait proposer et auxquelles chacun pouvait se rendre et en partir à loisir (pratique quand on a deux activités qui nous plaisent autant l’une que l’autre dans le même créneau horaire !).
A nouveau, l’avantage du nombre limité de participants rendait les activités accessibles à tous, pour que chacun y trouve son compte et dans de bonnes conditions. De ce fait, cela permettait à tout le monde de devenir un acteur de Sud Web et de favoriser de nouveau les échanges et la collaboration.
Parmi les ateliers proposés spontanément par les participants, on dénombrait de nombreux axes comme «Enseigner le web, ensemble ?» qui permettait de réfléchir sur les différentes méthodes d’enseignement existantes et sur les bonnes manières de transmettre ses connaissances, un atelier sur la revue de code et quelles étaient les bonnes pratiques, un atelier pour décrypter sa fiche de paie ou en savoir plus sur la mise en place du télétravail, une table ouverte sur le Burn out, comment le détecter et l’éviter, etc… (et même un très chouette atelier lettering et crayolas proposé par Laurence Vagner pour changer des pixels !)
Verdict : à refaire !
Cette première édition de Sud Web s’est révélée être une expérience agréable et très ancrée dans le monde du web d'aujourd'hui. Le format actuel est bien pensé et permet de proposer aux participants le passage d’une expérience de spectateur à celui d’acteur de la conférence.
Parmi les valeurs et les idées qui dominaient cette édition, le fait de se sentir bien dans sa vie et dans son travail, le partage, la participation, l’investissement des individus dans des initiatives collectives ou personnelles et l’envie d’apporter à la société et à notre domaine via des alternatives au système classique témoignent de l’évolution des métiers du web en France.
L’équipe (la «Thym» Sud Web) qui organise l’événement a effectué un travail remarquable, le mot à retenir de cette expérience est «Bienveillance». Une bienveillance que l’on retrouve aussi bien au niveau des organisateurs que des participants, qu’ils soient speakers ou visiteurs.
Nous sommes plutôt satisfaits de cette première expérience Sud Web et sommes convaincus de revenir l’année prochaine ! Et pourquoi pas, de proposer une thématique pour un forum ouvert autour du travail en équipe auto-organisée ou d’un retour d’expérience sur Yaal afin de rencontrer d’autres profils à la recherche d’alternatives plus humaines au monde du travail classique.
La première étape d'une startup est de trouver un positionnement lui permettant d'obtenir des utilisateurs satisfaits. Le cas échéant, il lui faudra pivoter à la recherche d'un meilleur positionnement. Une fois un positionnement satisfaisant obtenu, le nouvel objectif est d'obtenir de la croissance (utilisateur et/ou chiffre d'affaire).
Dans le cas d'un objectif de croissance utilisateur, une des stratégie est de ne viser en premier lieu qu'un petit groupe et d'en faire des utilisateurs convaincus. Cela permet d'en faire des prescripteurs du service, ce qui participe aussi à la croissance.
De plus, une fois que l'acquisition du marché visé est assez grande, l'entreprise bénéficie d'un effet de réseau : à l'image du réseau téléphonique, plus le service est utilisé et plus les utilisateurs ont intérêt à l'utiliser. Cela permet d'acquérir plus facilement de nouveaux utilisateurs.
Les groupes d'utilisateurs suivants
Une fois le premier groupe convaincu, le but sera d'en satisfaire de nouveaux sans décevoir les premiers. C'est ce qu'a fait Facebook, en limitant l'usage aux étudiants d'Harvard, puis à tous les étudiants, puis au reste du monde.
Les versions successives du service permettent donc d'élargir la cible au fur et à mesure de l'acquisition d'utilisateurs, parallèlement à la communication vers les nouveaux groupes visés. Développer et publier de nouvelles versions par itération est adapté à cette stratégie. L'acquisition des utilisateurs se ralentissant une fois le point d'inflexion passé, la cible suivante ne doit être visée qu'ensuite.
Si cette stratégie est séduisante, il ne faut pas en négliger les limites :
la taille des marchés visés et la puissance de l'effet réseau est connue approximativement. Des études de marchés permettent de limiter cette incertitude.
le passage d'une cible à l'autre doit se faire sans perdre les précédents. Cela oblige à une suite logique d'acquisition des cibles visées.
elle s'adapte à un service visant les utilisateurs finaux, pas aux entreprises.
Un des avantages est de permettre le démarrage sur une niche connue des concepteurs, limitant la taille du produit minimum viable et donc les coûts de démarrage. Cela permet de valider rapidemment le service et les choix de départ. L'élargissement sera fait en sortant de la niche, ce qui est un chemin assez facile à réaliser. Le service proposé sera alors plus générique, visant un public de plus en plus large.
Agilité
Nous apprécions cette vue stratégique en accord avec les moyens tactiques qu'offrent les méthodes agiles, lucides sur la nécessité d'apprendre, de s'adapter et d'innover pour une entreprise en croissance.
On vous l’annonçait il y a quelques semaines, livresdeproches.fr faisait sa première sortie en public. Communication plutôt discrète dans un premier temps, nous voulions faire évoluer le site et ses fonctionnalités afin de vous proposer une expérience des plus plaisantes.
Mais Livres de Proches c’est quoi ?
Produit d’une réflexion d’équipe et d’un désir de faciliter l’échange autour de la lecture, c’est un projet qui nous tient à coeur.
Son but est de vous proposer une plateforme virtuelle afin de partager avec vos proches, vos livres et vos lectures. Nous souhaitions toucher tous les « amoureux » de la lecture et leur apporter un outil facile d’utilisation au quotidien. Que vous soyez collectionneur, blogueur, ou simple passionné de livre, livresdeproches.fr est fait pour vous.
Dotée d’une interface claire et simple, organiser sa bibliothèque virtuelle, partager ses livres, emprunter les livres de ses proches ou de son réseau et suivre votre compte n’a jamais été aussi simple.
Vous êtes blogueur et vous avez des livres à recommander ? Regroupez-les tous sur livresdeproches.fr et permettez à vos lecteurs de les retrouver facilement à un seul endroit ou sur vos différents sites web et blogs personnels grâce à l’utilisation de l’iframe et actualisez votre contenu en quelques clics.
Collectionneur ? Listez facilement tous vos livres en un seul endroit et gérez toute votre bibliothèque facilement. Vous pouvez aussi annoter vos différents ouvrages grâce à l'ajout et l'édition manuelle et entrez-y les détails qui vous semblent important.
Ou vous aimez tout simplement lire et découvrir chaque jour de nouvelles lectures ? Livresdeproches.fr vous offrira bientôt la possibilité de vous rapprocher de vos proches ou de vos amis grâce aux réseaux sociaux ou une simple adresse email afin d’emprunter leurs livres. Vous pourrez également gérer des communautés et regrouper les personnes qui partagent les mêmes goûts que vous dans des espaces dédiés.
Beaucoup d’autres fonctionnalités sont en préparation, toujours dans le but de vous offrir le meilleur de la plateforme.
Vous découvrirez bientôt l’ajout de livre grâce au scan de code barre afin de vous permettre de remplir votre bibliothèque encore plus rapidement.
Bientôt, personnalisez votre profil et partagez via les réseaux sociaux vos étagères. Suivez les bibliothèques des personnes qui vous intéressent.
Toutes ces évolutions et améliorations seront bientôt disponibles sur livresdeproches.fr mais vous pouvez dès à présent créer votre compte, remplir vos étagères virtuelles et découvrir la plateforme. Soucieux de respecter nos utilisateurs, la plateforme est gratuite et nous mettons un point d’honneur à respecter votre vie privée.
Tous les avis et retours, qu’ils soient positifs ou négatifs sont les bienvenus. Nous souhaitons vraiment que cette plateforme devienne la vôtre et vous proposer la meilleure expérience utilisateur !
Il y a déjà un an Yaal a été choisi par Surfrider Foundation Europe pour assurer les aspects graphiques et techniques d’un nouveau projet d’envergure baptisé Open Campus. Aujourd’hui nous sommes fiers de vous annoncer la sortie de cette plateforme et par cette occasion opportune vous en parler plus en détail.
L’association Surfrider est née d’une volonté de sensibiliser le public aux problèmes environnementaux qui menacent l’océan et le littoral. Au sein de Surfrider le Campus c’est leur centre d'éducation et de formation au développement durable. Il en existe plusieurs expressions. Le Campus In étant orienté sur des activités (expositions, conférences, débats…) dans leurs locaux et le Campus Out sur des interventions sur le terrain (ramassage de déchets sur la plage) ou bien dans les écoles. Mais jusqu’à présent il n’existait pas de véritable plateforme d’e-éducation. Open Campus est la réponse à ce manque.
Aspects phares du projet
Apprendre :
On peut suivre des cours allant du niveau débutant jusqu’à avancé sur six thématiques différentes. Un cours est divisé en plusieurs chapitres dans lequel on peut retrouver une variété de contenus tel que du texte, des vidéos, des images et des quiz. Les quiz permettent, à travers trois types de questions (réponse à choix multiple, réponse libre et texte à trous), de tester ses connaissances par rapport au sujet donné.
Quiz multijoueurs :
Pour utiliser les quiz dans un contexte de groupe un mode multijoueur a été développé. Un professeur, par exemple, peut initier un quiz pour ses élèves lors d’un cours sur un sujet tel que les déchets aquatiques. Les élèves, munis de tablettes, smartphones ou ordinateurs, peuvent répondre aux questions et voir les points gagnés au fur et à mesure de l’avancement. Un gagnant est désigné à la fin.
Contribuer :
En plus des quiz proposés par Surfrider il est aussi possible pour les utilisateurs du site de créer leurs propres quiz. Ils peuvent même les rendre public afin d’en faire profiter la communauté. Une interface dédiée permet de voir ses quiz, ses favoris et ses quiz multijoueurs.
Ressources :
En complément des cours il existe aussi de nombreuses ressources vidéos.
Conclusion
Pour nous le point fort de ce projet c’est l’association réussite entre un graphisme sobre et efficace (merci Marianne), une interface fluide (merci ReactJS) et responsive et un back-end sur mesure (merci Stéphane). C’est cette association qui nous a permis de répondre efficacement au besoin que Surfrider nous a communiqué. Par ailleurs, nous avons pris plaisir à travailler sur un projet avec des valeurs qui sont en accord avec celles des membres de Yaal.
Nous venons de consacrer deux jours en équipe, accompagnés par un facilitateur externe, pour prendre un pas de recul sur notre modèle organisationnel. Je suis fier de la manière dont nous avons réussi à reformuler notre projet : permettre à chaque équipier de s'émanciper et j'apprécie aussi la formulation de notre stratégie organisationnelle : à chacun de faire vivre les dynamiques qu'il aime.
Cela fait déjà longtemps que nous progressons petit à petit dans cette voie, mais avoir su formuler aussi simplement ce que nous faisions et se confirmer mutuellement que c'est bien ce que que nous voulons, soude l'équipe et nous donne envie de continuer l'aventure !
Il faut bien sûr savoir étayer ces intentions par des pratiques, puisées par-ci par-là, évaluées concrètement, adaptées, abandonnées ou finalement appréciées et soutenues.
Aujourd'hui chez Yaal, à titre d'exemple, nous faisons vivre les pratiques suivantes :
nous réunir pour piloter les activités tous les lundis matins, façon GTD, sur un tableau Trello ;
faire suivre cette réunion par des conversations libres, ad lib, avec un bâton de parole ;
brainstormer pour les sujets particulièrement complexes ;
faire tourner ses doigts pour montrer que l'on veut avancer en réunion, pratique essentielle s'il en est ;
fournir une évaluation du temps passé en clôture des activités ROTI ;
satisfaire dans le temps le plus court les expressions de besoin (Lead Time) ;
Nous avons décidé lors de ces deux jours d'ajouter à cette liste :
faire appel à un facilitateur interne pour les sujets compliqués ;
faire appel régulièrement (annuellement ?) à un facilitateur externe ;
ralentir pour prendre les décisions importantes par consentement.
Et puis, une nouvelle pratique que je voudrais faire vivre :
la Communication Non Violente, pouvant se définir comme « le langage et les interactions qui renforcent notre aptitude à donner avec bienveillance et à inspirer aux autres le désir d'en faire autant ».
Un grand merci à notre facilitateur, que dis-je, à notre agitateur de particules démocratiques, qui, entre échauffements physiques et jeux de communication, a su nous faire travailler sur notre modèle, ouvrir les débats catalyseurs de changement et accompagner leur résolution avec subtilité. Le tout dans le respect de chacun et de notre projet collectif !
Pytong est une petite conférence autour de python qui s'est déroulée à Lyon. Nous étions sponsor de l'édition :)
Avec mes collègues Stéphane et Bruno, nous avons pu discuter sur deux jours avec d'autres professionnels experts et passionnés utilisant python dans un contexte web au quotidien.
L'occasion de discuter des nouveaux outils et de l'évolution de l'écosystème Python.
On a pu y voir (entre autre):
EventSources ou SSE, les web-sockets en read-only
EventSource un protocole comme WebSocket plus simple (en lecture seule). Attention il y a une limite sur le nombre de connexions simultanées (nombre d'onglets ouverts limités). La présentation était un premier retour d'expérience de Pierre-Yves Chibon plutôt convaincant. Il ne reste plus qu'aux différents navigateurs de se mettre à la page !
Gestion de ses dépendances
Un présentation complète dispensé par Arthur Vuillard le co-organisateur de la pytong et gentil animateur de la journée :). (Les slides sont par ici.)
Un rappel de la approuved façon de gérer les numéros de version (PEP440). J'en ai surtout retenu que l'on peut (avec de la confiance) borner les versions dans les fichiers requirements.txt plutôt que les fixer afin d'avoir les dernières corrections.
Par exemple : requests >= 2.0, < 3.0 ou requests >= 2.0, == 2.* ou requests ~= 2.7
Mock considered harmful
Une présentations à charge sur les mocks. Verdict : ils sont nuisibles au refactoring et cachent des bugs. Donc à éviter quand c'est possible ! (utilisation de stubs dans la conf). Nous sommes arrivés au même constat par la pratique (et la douleur). Cette présentation et le débat qui a suivi m'a motivé pour présenter notre façons de tester chez Yaal. Donc merci à Boris Feld @lothiraldan !
Du site dynamique au document imprimable en Python
Enfin on a terminé par une présentation de WeasyPrint par Guillaume Ayoub. Le but : imprimer des pages HTML en utilisant la spéc CSS pour le print. Une présentation très sympa par quelqu'un de très calé sur le sujet :). On a quand même tristement conclu que l'impression finale nécessite quand même de bien configurer l'imprimante.
Les ateliers
Au format libre, on a parlé de tests, et d'outils :
Pour les graphes on peut utiliser pygal qui génère des graphes en SVG et imprimables.
csvkit est un utilitaire sympa pour afficher et manipuler les CSV pour adeptes de la ligne de commande (dont conversion en SQL ou en JSON).
Tips and tricks pour obtenir un pretty print d'un fichier JSON : python -m json.tool file.json
Le dimanche matin
Après une soirée arrosée et bien remplie dans un bouchon lyonnais, on a joué à Symbioz, un jeu très sympa dont la version 2.0 est en prototypage par l'auteur. Un concept d'écosystème simple, mais difficile à gérer.
On a également beta-testé un jeu basé sur les châteaux de la renaissance : Artigiano crée par Céline Dumas avec la collaboration de Guillaume Ayoub. Un jeu sous license Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 3.0 France.
Une mécanique de jeu à base de pile très efficace !
BDX.io
Co-organisateur de la précédente édition, j'étais cette fois-ci encadrant en soutien pour gérer l'accueil des 512 participants !
Bdx.io est la plus grosse conférence dédiée au développement sur Bordeaux tant en nombre de participants qu'en nombre de conférenciers. Plus de 40 conférences !
Je n'ai pu regarder que les conférences de l'après midi :
Créer son blog en 5 minutes et publier en Asciidoc !
Une présentation par Benoit Prioux @binout qui tient d'ailleurs son blog à l'aide de hubpress.io, avis aux adeptes de github et d'asciidoc !
Moi je code ma doc
Par Mehdi Rebiai. Cette présentation m'a permis de découvrire PlantUML et franchement pour la préparation des cours, formations ou autres doc, c'est cool !
« No one at google uses MapReduce anymore » - Cloud Dataflow explained for dummies
Un retour d'expérience et une présentation live de Stéphane Lagraulet et Olivier Revial d'Ippon technologie, sur la mise en place d'une architecture de microservices face à un code legacy monolitique. Et un live coding sur toute la stack netflix.
La keynote de fin
Pilotée par Thomas Parisot sur une question très technique : monolithe ou microservices. Il a beaucoup été question de bonheur au travail et de bonheur personnel. Une keynote philosophique qui tranche avec le sérieux technique de la journée.
Agile Tour Bordeaux
Après avoir été co-organisateur en 2013, speaker en 2014, je suis venu en simple participant à l'édition 2015 dont le thème était : « le bonheur au travail » !
Bravo à toute l'équipe pour continuer ce travail bénévolement et garder cette conférence gratuite !
Réflexion autour du travail et de son utilité (ou pas)
La keynote d'ouverture par Lionel Dricot @ploum lance le ton de la journée !
Une réflexion argumentée sur la fin du travail à lire en détails sur son blog.
Cette conférence porte un message clairement politique, et d'ailleurs la première question fût sur le revenu de base qui paraît être une des mises en oeuvre possible de cette fin du travail. Pour moi cette Keynote tranche avec celle des précédentes éditions plus portées sur des pratiques agiles, et aurait plus sa place dans une conférence type TEDx. Un choix risqué mais assumé par l'équipe de cet agile tour !
Mob mob mob programming
J'ai poursuivi la journée avec la conférence proposée par Emmanuel Gaillot @egaillot et Jonathan Perret @jonathanperret de la coopérative /ut7, également les co-créateurs du coding goûter.
Un atelier live très sympa sur un serveur minecraft customisé à l'aide du CanaryMod et de ScriptsCraft voir ici pour les détails, dans la continuité de leurs activités de présentation du code aux enfants. Concernant le thème de cet agile tour : Oui on peut s'amuser en codant :). J'aurais aimé plus de discussions autour de leurs expériences « d'enseignant/coach/guru » auprès des enfants.
Lighting talks
LT : les feedbacks loops
Le premier de @rhwy Rui Carvalho sur les feedback loops, avec une image très sympa qui montre bien les boucles de contrôles (de la gestion de projet) et les boucles d'amplifications (de la qualité du code). Un autre moyen détourné de dire : l'agilité, oui, mais si vous ne faîtes rien sur ces boucles d'amplifications... vous aurez toujours une piètre qualité.
LT : le courage de vivre consciemment
Le second talk de Jérôme Avoustin @JeromeAvoustin est un retour d'expérience sur sa carrière professionelle. Un appel aux développeurs malheureux en ESN (ex-SSII) et autres grosses boites, à aller de l'avant et à prendre des risques. Chez Yaal, ce pas là on l'a déjà fait, on est un collectif d'hommes et de femmes libres. :)
LT : la recette pour développer son logiciel dans le bonheur
Le dernier talk de Guillaume St-Etienne @guillaume_agile était vraiment lent, mais je suppose que la répétition était volontaire. En résumé, Guillaume souhaite un ou des outils magiques pour avoir un logiciel de qualité, rapide, qui s'autogère, assure les besoins clients, les anticipe, met la doc à jour tout seul, s'assure d'être à la pointe de la technologie... et fait le café !
Conclusion, cet outil magique existe : c'est un développeur ! Ce qui ne colle pas à cette fin du travail de @ploum :(
Chez Yaal, on a envie de compléter : c'est une équipe de développement, parce que le design d'interface des développeurs c'est pas encore ça :)
Ca prendra combien de temps ?
Après une pause déjeuner au soleil ! Je suis allé voir comme beaucoup d'autres la conférence d'Olivier Azeau @oaz.
J'avoue avoir été pas mal déçu par cette présentation. Avec le recul je pense que c'est dû à cette volonté d'avoir un truc fiable pour estimer les développement.
C'est d'ailleurs l'idée expérimentée par Olivier : modéliser ces story points / tailles de T-shirt sous forme mathématique à l'aide de la théorie des probabilités section variable aléatoire. Olivier l'a bien annoncé : il n'est pas mathématicien, et du coup n'a pas pu vraiment répondre aux questions techniques. Je pense que c'est un premier retour d'expérience qui cherche à éliminer quelque part l'estimation d'experts au doigt mouillé. C'est dans l'optique du mouvement #NoEstimatesdont vous pouvez lire quelques articles qui cherche à se débarasser de ce besoin d'évaluer à l'avance les développements.
Je ne suis pas convaincu du résultat, car au vu des graphes présentés, le constat amer est qu'entre l'estimation basse et l'estimation haute, on reste toujours sur un facteur 10, à 80% de probabilité. Même si une garantie mathématique se trouve derrière, je reste en tant que potentiel client d'une telle solution bien trop insatisfait. Le doigt mouillé du capitaine avec 30 ans de voile me paraît plus sûr que l'indice météo calculé, même si le résultat sur le long terme est le même. Cela reste une question de confiance dans le modèle. L'avantage que j'y vois est qu'on ne passe plus de temps à évaluer (NoEstimate), à la place on fournit le résulat d'un modèle mathématique.
Bref un sujet qui n'a pas encore trouvé de solution, mais en existe-t-il une ? Est-ce vraiment un problème ? (Pour faire des devis, oui !)
L'agilité en IUT
Enfin j'ai profité du retour d'expérience de Martine Bornerie @Martine__B et Irène Doan @idetido sur « l'agilité en IUT ».
Il est très intéressant de constater que cela fait tout juste un an que les projets en mode agile sont plus nombreux dans cet IUT MMI Bordeaux que ceux en cycle en V. Le début de la fin d'une époque ?
La recherche du bonheur
Enfin, on termine par la keynote de clôture d'Alexis Monville @alexismonville sur « la recherche du bonheur ».
Les slides sont disponibles par ici.
Le constat scientifique est formel : les gens heureux vivent mieux, plus longtemps, travaillent plus efficacement et bien d'autres qualités !
Bonus : ils aident les autres à mieux travailler en équipe !
Utiliser un framework, c'est partir à l'aventure sur un paquebot : c'est joli, solide, plein de pièces et l'équipage est au grand complet. C'est a priori rassurant. Malheureusement, la vie n'étant pas un long fleuve tranquille, il vaut mieux pouvoir changer rapidement de direction et être réactif qu'apprécier la qualité des bastingages. Pour la vie d'un produit, partir en hors-bord est préférable. Donc faire simple et léger.
Chez Yaal, nous utilisons un ensemble de bibliothèques cohérentes et chacune experte en son domaine. Par exmple, nous aimons utiliser Werkzeug pour les échanges HTTP, propulsé par un uwsgi performant, avec Jinja2 pour un templating efficace, ZODB pour une base de données objet, WTForms pour la validation des formulaires, celery pour l'exécution massive de tâches asynchrones, bleach pour se prémunir des injections de code, etc. Cela permet d'avoir les avantages d'une architecture modulaire sur une architecture monolithique.
Par défaut, nous utilisons les bibliothèques directement (par exemple bleach ou WTForms). Parfois, nous avons voulu faire apparaitre une abstraction de plus haut niveau. Par exemple, une bibliothèque wgsi pour Werkzeug, que nous avons nommée ywsgi. Nos bibliothèques sont préfixées d'un « y » pour être facilement différenciable des bibliothèques externes.
Facilité de compréhension
Un code de petite taille est plus facile à appréhender, à comprendre et à faire évoluer. La base de code pour démarrer un projet est limitée à quelques bibliothèques. Les autres briques viendront s'y ajouter selon les besoins de chaque projet. La base de code reste donc minimale à chaque fois.
Réutilisation de l'existant
Il ne sert à rien de tout réécrire alors que certains problèmes ont déjà été résolus d'une manière qui nous satisfait. C'est pourquoi nous utilisons Werkzeug, Jinja, WTForms, etc.
Possibilité de changer un élément tout en gardant des autres
Les bibliothèques étant indépendantes, nous pouvons facilement en remplacer une si elle ne donne plus satisfaction. C'est grâce à cette modularité que nous avons pu remplacer SQLAlchemy par ZODB par le passé.
Mises à jour plus petites
Les bibliothèques étant indépendantes, les mises à jour sont faites au fur et à mesure de leur sortie. Les mises à jour sont plus petites et donc facilement maîtrisées.
Adaptation à nos préférences présentes et futures
Comme aucune architecture ne nous est imposée, nous pouvons faire évoluer l'architecture sans souci de compatibilité future avec un quelconque framework sous-jacent. De même les seules personnes à convaincre sont dans l'équipe. C'est plus facile quand votre lobbying se limite aux personnes qui sont dans le même bureau que vous. ;-)
Avec l'expérience accumulée, nous préférons largement cette façon de faire. Pourquoi ne pas vous aussi essayer cette voie rafraichissante ?
Mesdames, messieurs, c'est avec une certaine émotion que nous vous proposons Livres de Proches : un service en ligne de gestion et de partage de livres s'adressant à la fois :
aux partageurs cherchant un outil leur facilitant le suivi de leurs livres prêtés ;
aux blogueurs qui souhaitent mettre en avant leur sélection de livres et les proposer à l'emprunt.
Nous nous appliquerons pour l'instant à satisfaire ces premières catégories d'utilisateurs, avant d'élargir l'horizon du service à moyen-terme.
Nous souhaitons être nous-mêmes partageurs et vous pouvez consulter notre sélection de livres en fin d'article et la retrouver sur notre page dédiée aux contributions.
Livres de Proches restera gratuit pour les particuliers et nous serons particulièrement attentifs au respect de votre vie privée. N'hésitez pas à nous contacter pour toute suggestion d'amélioration : nous nous tenons prêts à travailler avec vous pour vous rendre le service toujours meilleur !
Ce matin j'ai eu la chance d'assister à la soutenance de projet professionnel de 6 jeunes étudiants d'une grande école d'ingénieurs de Bordeaux. Cinq jeunes hommes et une jeune femme, tous aux profils d'une richesse incroyable. L'un code en C depuis le lycée, l'autre réalise des solutions domotiques dans son temps libre, une autre encore veut travailler à améliorer les interfaces hommes-machines pour aller à l'encontre de ses propres difficultés à communiquer et faciliter la vie de ses semblables. Leur défaut principal ce matin était leur trop grande humilité, l'impression de ne pas mériter leur place pour le job bien réel auquel ils candidataient fictivement. Ils manquent encore de maturité, de confiance en eux, et de compétences en communication - ô combien importantes - mais ils ont par ailleurs pour la plupart une déjà assez bonne idée de ce qui fait un bon manager, ou de ce qu'ils souhaitent atteindre comme équilibre entre vie professionnelle et personnelle. Aucun ne savait combien serait payé son job, ni ne semblait s'en soucier vraiment.
Hier avait lieu à La Ruche un évènement rassemblant des dizaines d'entrepreneurs en devenir, autour des thèmes de l'entrepreneuriat au féminin, de l'entrepreneuriat de moins de 25 ans, de l'entrepreneuriat numérique, et de l'entrepreneuriat social et solidaire. Beaucoup de jeunes femmes, pas mal de jeunes hommes, encore étudiants pour la plupart, plutôt issus d'écoles de commerce si j'ai bien compris, qui se posent des questions sur la création d'entreprise pour tout un tas de raisons personnelles. De mon côté, j'ai eu une discussion très intéressante avec une jeune femme en pointe sur l'économie sociale et solidaire, sujet que je connais peu, et qui cherchait elle à comprendre ce que nous faisons dans le "numérique" et pourquoi les politiques n'ont que ce mot à la bouche dernièrement. Sujet à creuser.
L'avenir ce n'est pas la FrenchTech ou les taux de la BCE ou le dernier fait divers qui agite la presse et sera oublié dans une semaine. L'avenir c'est eux. L'avenir ce sont ces jeunes gens qui ont eu la chance de recevoir une éducation de qualité, de grandir dans un pays en paix, et qui ont l'ambition de faire de belles choses, qui ont la motivation de se lever demain pour créer leur destin.
L'avenir, ce sont ceux qui y croient qui le font. C'est à nous tous de les y aider.
Cela faisait partie de nos Espoirs : l'équipe de Yaal s'est rendue vendredi dernier à la salle Roc Altitude pour une après-midi d'escalade sous l'oeil avisé de Dominique notre moniteur. Certains d'entre nous ont ainsi pu s'initier pour la première fois à ce sport, tandis que les plus habitués ont attaqués des pentes plus ardues.
Vous pouvez retrouver les photos sur notre page Facebook.
La communauté des développeurs est très active à Bordeaux. Ces derniers se réunissent régulièrement pour de nombreux évènements comme les présentations du Bordeaux JUG, les apéros Ruby ou JS, les Creative Tuesdays, etc. Pour autant, il manquait un évènement fédérateur, de plus grande ampleur, permettant de rassembler toute la communauté du développement autour de conférences techniques. C’est l’ambition de BDX.IO qui se tiendra le 17 octobre 2014 au sein de l’ENSEIRB en pleine Semaine Digitale de la ville de Bordeaux.
Plus de 40 orateurs viendront animer 24 conférences d’une heure, 16 lightning talks, et 3 ateliers pratiques sur des sujets aussi variés que Clojure, ElasticSearch, Polymer ou DevOps et bien d’autres encore. En face, ce ne sont pas moins de 250 participants qui ont déjà pris leur place pour parfaire leurs connaissances des langages les plus modernes, des nouveaux designs ou bonnes pratiques, des techniques d’architecture et d’outillage.
Yaal est très heureux de soutenir cette première édition de BDX.IO et nous espérons vous y voir nombreux.
Yaal est à nouveau sponsor de la conférence Python francophone pour 2014, PyConFr. Cette année, la conférence et les sprints auront lieu du 25 au 28 Octobre à Lyon.
En 2013, nous avons participé aux quatre jours de conférences et comptons bien faire de même cette année ! Des conférences et des discussions enrichissantes ainsi que de nouvelles idées nous ont permis d'améliorer nos pratiques et nous motivent à recommencer cette année.
Notre participation précédente nous a apporté, entre autres, le courage de normaliser le lancement de nos applications grâce à des Makefile et l'utilisation de WebTest pour la réalisation des tests de nos applications web.
Gageons que nous allons faire de nouvelles découvertes lors de cette édition 2014 !
Yaal est fondée en février 2010 avec l'objectif de créer un contexte propice à l'agilité, sans limite. L'aventure ne fut pas de tout repos ni sans certains accrocs, mais nous sommes aujourd'hui très fiers de ce que nous avons construit. Nous allons tenter par ces quelques lignes de vous décrire ce qui fait aujourd'hui notre force et notre fierté. Peut-être cela vous sera-t-il utile pour tenter une expérience similaire à la nôtre ? peut-être cela vous donnera-t-il envie de nous rejoindre ?
Pourquoi investissons-nous ? Pour créer une confiance durable avec les porteurs de projet. Parce qu'ainsi nous avons la conviction que chacun fait du mieux qu'il peut en fonction des besoins commerciaux et des finances disponibles. Parce qu'ainsi notre contractualisation est réduite à l'essentiel : nos destins sont liés et c'est dans la collaboration que nous réussirons.
Yaal c'est une équipe d'associés-salariés : Arthur est gérant et stratège, Aurélien est pilote fonctionnel, Justin est designer web, Bruno et Stéphane sont développeurs, Colin est développeur et facilitateur.
Pourquoi sommes-nous (bientôt) tous associés ? Pour garantir le bien-être de chacun et donc de notre organisation. Pour nous assurer que chacun puisse entreprendre toutes les actions nécessaires à la satisfaction des clients, tout aussi surprenantes qu'elles puissent être. Nous sommes libres, ensemble, démocratiquement, pour nous et pour nos clients.
Yaal ce sont des processus légers, pour plus d'efficacité et plus de plaisir !
Nous nous réunissons toutes les semaines pour aborder tout sujet qui le mérite. Nous nous réunissons tous les mois pour actualiser notre vision de Yaal à 1 mois, 3 mois, 6 mois, 1 an et 3 an. Nous nous dotons de métriques de performance. La comptabilité est ouverte. Nous invitons nos clients à partager nos bureaux quand ils le souhaitent. Nous faisons du TDD et des revues de code. Nous binômons ou programmons côte à côte. Nous déployons nos logiciels en quelques secondes, en intégration, recette ou production, 10 fois par jour si besoin.
Yaal c'est enfin l'environnement de travail que nous nous sommes construit : des bureaux en plein centre de Bordeaux, des vélos de fonction haut de gamme, des doubles écrans 24'', disques SSD, Macbook air, écran Thunderbolt, téléphones et ordinateurs portables.
Et aujourd'hui, nous sommes heureux de nous lever tous les matins, fiers de notre quotidien \o/
Reddit est un excellent outil pour l’intelligence collective. Il permet notamment d’ouvrir des espaces thématiques et d’y accumuler des liens vers des articles. Ces liens peuvent être qualifiés et commentés par les usagers, et sont ainsi exploitables selon les appréciations de la communauté.
rss2reddit est un outil — réalisé par votre serviteur — qui permet de lire des flux RSS et de soumettre automatiquement sur Reddit les billets les plus récents.
Je vous invite à me soumettre de nouvelles sources de flux RSS à ajouter à la liste actuelle. Je suis évidemment ouvert à toute suggestion ou contribution pour améliorer le robot.
Merci aux organisateurs, aux orateurs, aux sponsors et partenaires, tout s’est parfaitement déroulé !
Nous sommes très heureux d’avoir pu apporter notre pierre à l’édifice en tant que partenaire technique avec la billetterie en ligne yuticket.com, et d’avoir pu y donner notre propre retour d’expérience !
J’ai particulièrement apprécié la tenue des lightning talks, synthétiques et dynamiques. Peut-être pourrait-on s’appuyer un peu plus sur ce format là pour partager nos expériences et favoriser la rencontre des acteurs du numérique bordelais autour des sujets qui les passionnent… pour le prochain Agile Tour Bordelais ou pour un nouvel événement qui lui donnerait le change au printemps ?
73 jours après notre rencontre avec un porteur de projet dynamique et 89 déploiements en plateforme de recette, le service yuticket.com est sortie en bêta privée !
17 jours plus tard, grâce aux retours de nos 3 premiers courageux utilisateurs, nous comptons 42 nouvelles livraisons en recette, 21 livraisons en production, et nous ouvrons la création d’événements pour tous !
Après une courte pause, les dojos de programmation d’Okiwi ont repris cette année. Ils sont maintenant hébergés par Arpinum les seconds lundis du mois et chez Yaal les quatrièmes lundis. Nous étions donc lundi dernier dans les locaux de… l’Auberge Numérique… qui héberge Yaal. Vous suivez ? Pour en savoir plus sur ces dojos, voire vous joindre à nous la prochaine fois, vous pouvez vous renseigner ici ou même vous inscrire à la liste de discussion de l’association.
Lundi dernier donc...
Nous n’étions qu’en petit comité lundi soir, quatre joyeux codeurs, mais le lieu doit nous permettre de monter confortablement à une dizaine de personnes comme l’an dernier. Après s’être demandé ce que nous allions coder ensemble — un jeu de la vie en Javascript — nous nous sommes demandé comment s’organiser… Aha ! et pourquoi pas avec un aquarium ?
L’aquarium !
L’aquarium — fishbowl — est un outil de facilitation de groupe dans lequel seul un sous-groupe est actif, les autres étant spectateurs. Les actifs sont assis au centre et une chaise vide supplémentaire est disponible. Si une personne spectactrice veut devenir active, elle peut venir s’y assoir. Une personne doit alors libérer sa place pour devenir spectatrice à son tour.
Et alors ?
Ben ça fonctionne plutôt bien pour un dojo de programmation. Ca veut dire trois chaises et trois claviers pour un binôme actif en permanence. C’est léger à organiser et c’est dynamique. Celui qui a de l’énergie et qui veut s’exprimer peut le faire sans demander la permission. Bref, une belle petite découverte pour ma part. Vous voulez essayer ?
Ainsi ni la qualité du logiciel, ni la qualité de l’organisation qui le produit ne sont évaluables a priori : il faut que le logiciel soit réalisé pour estimer sa valeur, puis pour évaluer l’organisation qui l’a produit.
Stratégies légères
A ces difficultés les agilistes répondent en stratèges et se dotent d’heuristiques selon les situations. Communément, ils réalisent le logiciel petit à petit sous les yeux et dans les mains des utilisateurs, qui sont alors mis en situation d’évaluer ce qui est produit aussitôt que possible.
Les utilisateurs sont mis en situation de réactualiser leur désir, et les développeurs leur organisation.
Désir et responsabilité
Réactualisant à volonté leur organisation, les développeurs agiles deviennent des acteurs responsables et désirants. Désirants parce qu’ils évaluent leur organisation, en imaginent et mettent en oeuvre d’autres possibles. Responsables parce que leur organisation n’est plus choisie pour eux, mais choisie par eux.
Cette condition du développeur agile peut s’avérer nouvelle et déroutante. Les développeurs peuvent éprouver soit un réel plaisir à mettre en oeuvre les organisations qu’ils imaginent, soit une grande frustration en cas d’empêchement.
Organisation désirante
La réussite d’une équipe de développement agile est donc fortement liée à la culture de son entreprise, et de ses réactions face à l’expression des désirs de ses membres, et de leurs propositions de ré-organisation.
Vous êtes peut-être un artisan logiciel, êtes-vous aussi un artisan de votre organisation et de ses objectifs ?
Peu citée, peu commentée, la pratique de l’interprétation généreuse me paraît être une des rares pratiques fondamentales de l’agilité. Invitant à la pensée systémique et à l’action congruente, elle peut être considérée comme le moteur de l’adaptation continue.
Une formulation courante de l’interprétation généreuse est celle de la Directive Première des rétrospectives agiles : « Quel que soit ce que nous découvrons, nous devons comprendre et croire sincèrement que chacun a fait du mieux qu’il a pu, en fonction de ses connaissances d’alors, de ses compétences, des ressources disponibles et de la situation. »
L’exercice peut devenir difficile lorsque les émotions prennent le dessus : « Puis-je trouver une, deux, voire trois interprétations généreuses de la situation ? »
Cette pratique a ces grandes vertus :
d’une part de se construire une représentation d’une situation dans laquelle le ressentiment et la culpabilité n’ont pas leur place,
d’autre part de mettre en lumière comment les actions des uns et des autres sont sur-déterminées de manière systémique.
Il s’agit donc de lever un brouillard d’émotions ou d’interprétations hâtives sur les événements pour essayer de n’en garder que des ressorts vertueux, et de communiquer ainsi sur une représentation à même d’être entendue le plus largement et de créer le consensus.
Il s’agit de se poser la question de l’action, sur un terrain constructif.

























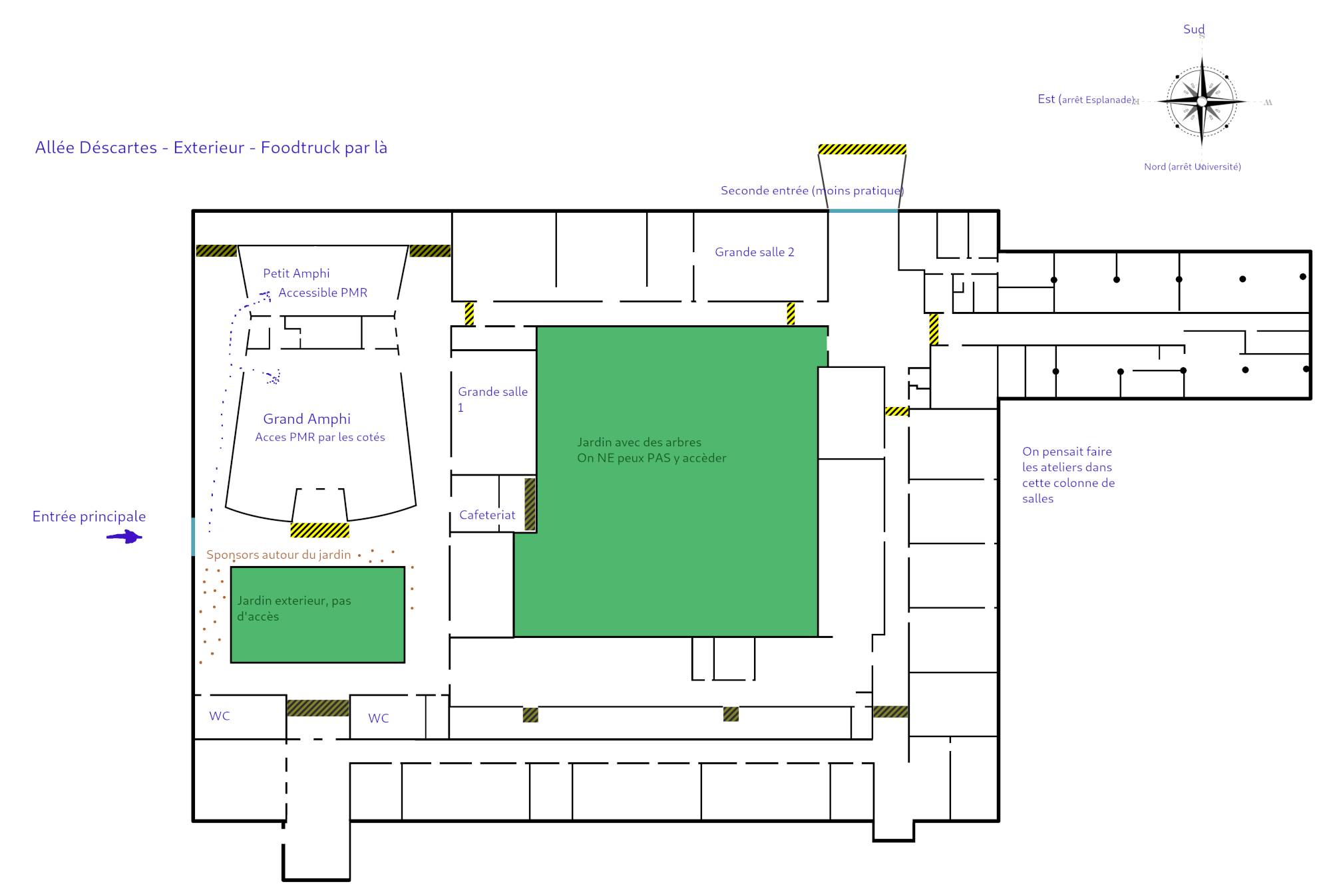





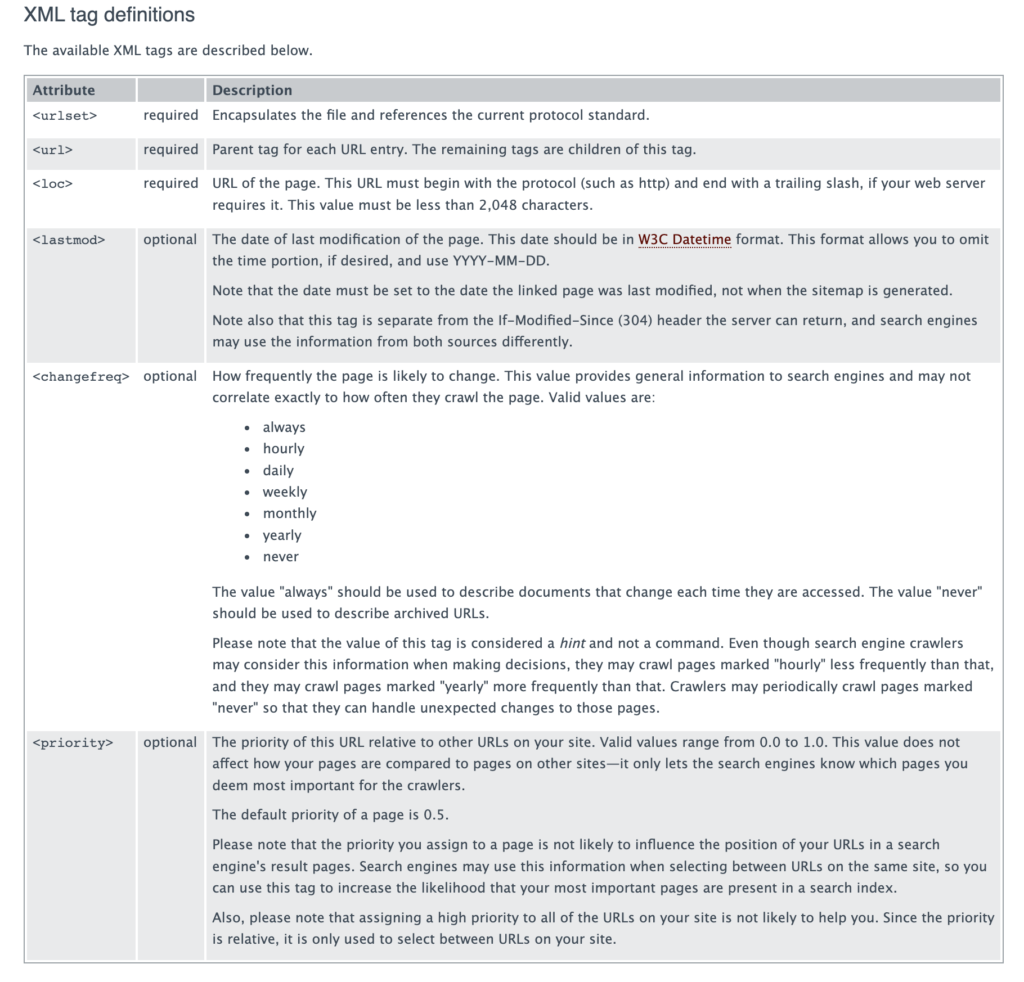



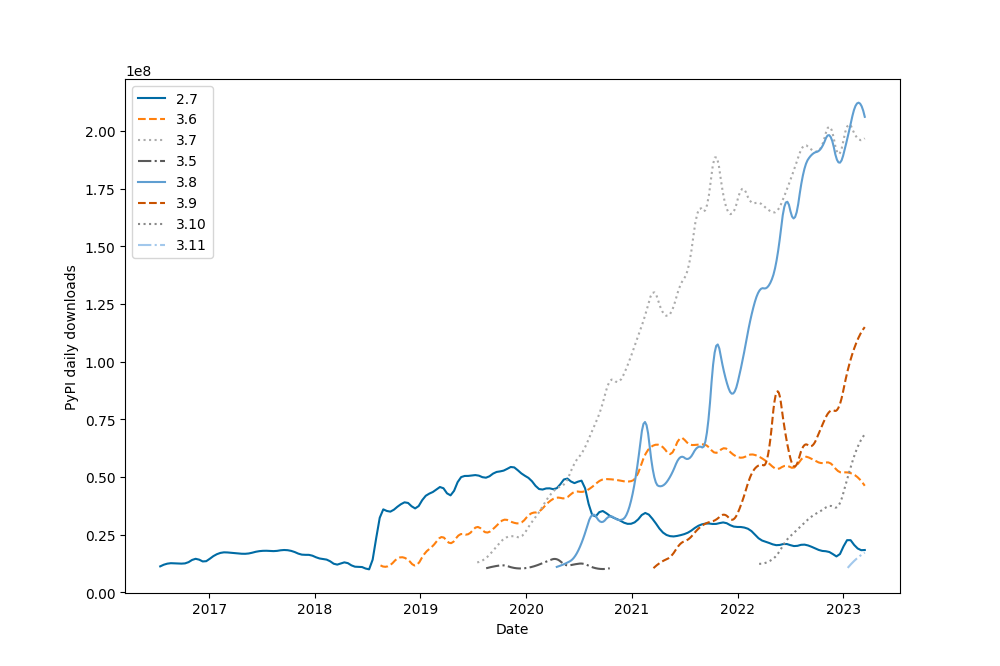
















































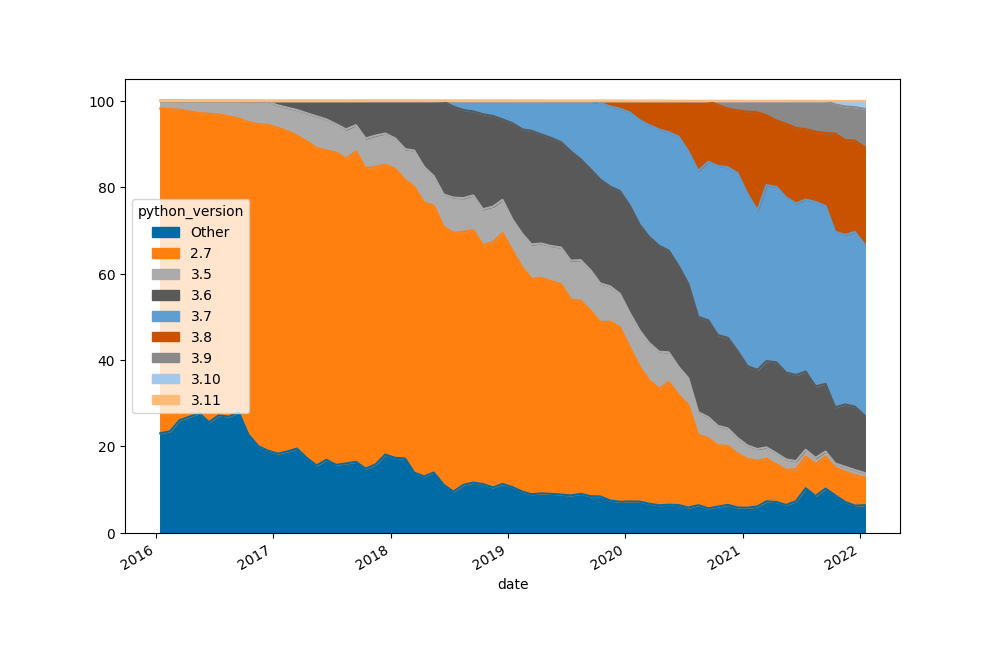

 ) :
) : )
)












 Les étiquettes finales, après retouches faites en interne à la brasserie.
Les étiquettes finales, après retouches faites en interne à la brasserie.

































 Les clubs ont envahi notre répertoire de salons Riot
Les clubs ont envahi notre répertoire de salons Riot



















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}